Autoregressive Distillation of Diffusion Transformers
CODE: CVPR 2025 Oral
GitHub - alsdudrla10/ARD: [CVPR 2025 Oral] PyTorch re-implementation for Autoregressive Distillation of Diffusion Transformers (ARD).
具有transformer架构的扩散模型在生成高保真图像和高分辨率可扩展性方面表现出了很好的能力。然而,合成所需的迭代采样过程非常耗费资源。一系列的工作集中在将概率流ode的解提炼成几个步骤的学生模型。然而,现有的方法受到限制,因为它们依赖于最近去噪的样本作为输入,使它们容易受到暴露偏差的影响。为了解决这一限制,我们提出了自回归蒸馏(ARD),这是一种利用ODE的历史轨迹来预测未来步骤的新方法。ARD提供了两个关键的好处:1)它通过利用预测的历史轨迹来减轻暴露偏差,该轨迹不易受累积错误的影响,2)它利用ODE轨迹的先前历史作为更有效的粗粒度信息来源。ARD通过添加标记智能时间嵌入来标记轨迹历史中的每个输入来修改教师转换器架构,并采用块智能因果注意掩码进行训练。此外,仅在较低的变压器层中合并历史输入可提高性能和效率。我们在ImageNet和T2I合成上验证了ARD在分类条件生成中的有效性。与基线方法相比,我们的模型在FID退化方面减少了5倍,而在ImageNet-256上只需要1.1%的额外FLOPs。此外,在ImageNet-256上,ARD仅用4步就达到了1.84的FID,并且在快速遵守评分方面优于公开可用的1024p文本到图像蒸馏模型,与教师相比,FID下降最小。
Introduction
DMs的稳定训练有助于其扩展到高分辨率图像生成。最近,基于(Diffusion transformer, DiT)架构的模型因其出色的缩放特性和生成高分辨率图像的能力而受到广泛欢迎。然而,从dm中采样需要重复的神经网络评估,这使得高分辨率图像合成缓慢且资源密集。
去噪过程采用概率流常微分方程(ODE)公式,提供了噪声与样本之间的确定性耦合。为了降低采样成本,已经开发了一系列蒸馏模型,这些模型学习用更少的步骤预测ODE解。然而,小步学生模型存在暴露偏差,因为由于估计误差,学生的中间预测经常偏离教师的ODE。误差在迭代采样过程中积累,导致预测在接近解时变得更加错误。
为了解决小步蒸馏模型中的暴露偏差,提出了一种用于扩散变压器的自回归蒸馏(ARD)方法。ARD根据当前估计的xτs和整个历史轨迹预测下一个样本xτs−1,信息量更大。这种方法提供了两个好处:它减少了累积的错误,并提供了包含在历史轨迹中的更好的粗粒度信息来源。在较低的层中合并历史轨迹进一步引入了处理粗粒度信息的归纳偏差。我们发现,当基于整个历史轨迹进行提取时,教师的FID退化比ImageNet 256p上的基线低5倍,只需要1.1%的计算量。
Preliminary
Diffusion models
扩散模型用随机微分方程(SDEs)定义了一个正向过程和一个相应的反向过程。方程(1)中的前向过程从数据x0 ~ pdata(x0)映射到噪声xT。
![]()
![]() 是扩散项,wt是维纳过程。f 为漂移项,g为扩散系数。正向过程通常被设置为保方差或方差爆炸SDEs,以接近于t = T时的高斯分布。扩散模型通过反向过程从噪声xT ~先验(xT)生成数据。存在一个概率流ODE (PF-ODE),它是逆向过程的确定性对应:
是扩散项,wt是维纳过程。f 为漂移项,g为扩散系数。正向过程通常被设置为保方差或方差爆炸SDEs,以接近于t = T时的高斯分布。扩散模型通过反向过程从噪声xT ~先验(xT)生成数据。存在一个概率流ODE (PF-ODE),它是逆向过程的确定性对应:
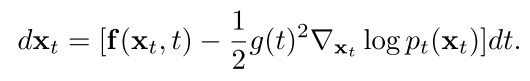
这里pt(xt)是方程(1)中正向过程定义的边际分布。PF-ODE具有与反向SDE相同的边际分布,同时提供了噪声xt和样本x0之间的确定性耦合。
-
与反向SDE具有相同的边缘分布 pt(xt)。
-
提供噪声 xT与生成样本 x0之间的确定性映射。
由于分数函数∇xt log pt(xt)是难以处理的,所以用一个具有分数匹配目标的神经网络![]() 来估计。
来估计。
常微分方程

随机微分方程

Step distillation models
方程(2)中ODE的解为:xT +![]() ;然而,它需要足够的步数来减少离散误差。为了在每一步计算dxt/ dt,我们需要评估学习到的神经评分函数
;然而,它需要足够的步数来减少离散误差。为了在每一步计算dxt/ dt,我们需要评估学习到的神经评分函数![]() ,这会导致很高的计算成本。为了提高推理效率,步进蒸馏定义中间时间τs:= T × s/S,其中S为学生步数的总数,s∈{0,1... s}。这些中间时间定义了一个轨迹
,这会导致很高的计算成本。为了提高推理效率,步进蒸馏定义中间时间τs:= T × s/S,其中S为学生步数的总数,s∈{0,1... s}。这些中间时间定义了一个轨迹![]() 在教师ODE内,从初始噪声xτS = xT开始,以干净样本xτ0 = x0结束。学生模型学习到一个联合概率p(µϕ∗),定义为:
在教师ODE内,从初始噪声xτS = xT开始,以干净样本xτ0 = x0结束。学生模型学习到一个联合概率p(µϕ∗),定义为:
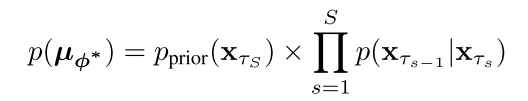
由于PF-ODE的确定性性质,每个条件概率p(xτs−1 |xτs)是一个狄拉克δ分布,因此它可以用确定性映射函数来建模;![]() 。学生模型Gθ(xτs, s)≈G(xτs, s)学习模拟真实值ODE积分。逐级蒸馏提出了一种逐级蒸馏算法。然而,这种算法有一个明显的缺点:当学生再次成为老师时,在迭代训练阶段会积累错误。利用Lstep直接从老师那里训练出一个小步的学生模型,减轻了迭代渐进蒸馏过程带来的累积误差。我们在阶梯蒸馏的基础上建立我们的方法,我们直接从老师那里学习
。学生模型Gθ(xτs, s)≈G(xτs, s)学习模拟真实值ODE积分。逐级蒸馏提出了一种逐级蒸馏算法。然而,这种算法有一个明显的缺点:当学生再次成为老师时,在迭代训练阶段会积累错误。利用Lstep直接从老师那里训练出一个小步的学生模型,减轻了迭代渐进蒸馏过程带来的累积误差。我们在阶梯蒸馏的基础上建立我们的方法,我们直接从老师那里学习
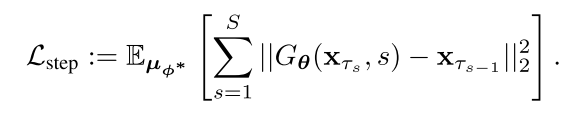

Exposure bias
在推理过程中,生成从xτS ~ prior(xτS)开始。在每一步中,学生模型仅基于当前样本的δ xτs预测δ xτs−1 = Gθ(δ xτs, s)。如果δ xτs偏离教师ODE,则学生模型Gθ根据训练期间未遇到的未见样本进行推断。例如,考虑图2a中描述的中间样本,其中显示了一条没有眼睛的鱼,尽管这些样本没有出现在训练数据中。这种不可预见的输入通过采样过程传播,最终的样本xτ0也没有眼睛。这种暴露偏差是迭代过程的固有局限性,除非达到完美的优化。误差随着迭代采样过程的进行而累积。
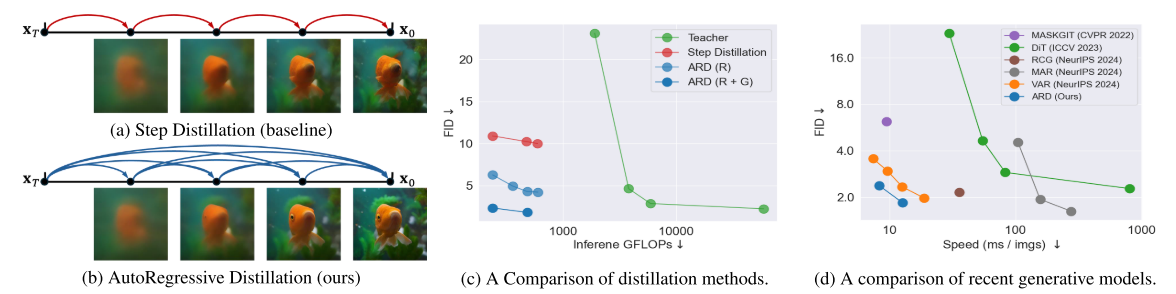

图2。(a, b)基线和拟议蒸馏方法的总体方案。训练轨迹由教师ODE给出。(c, d)在ImageNet 256p上蒸馏方法和公共生成模型的效率-性能权衡比较。
Autoregressive models
自回归模型表示多元随机变量x的联合概率分布:= [xS, xS−1… x0]将其分解为条件概率的乘积 ![]() ,其中xS:s = [xS, xS−1,…xs]。如上所述,这个提法不依赖于任何具体的假设。分解的每个分量p(xs−1| xs:s)综合了上述所有变量的信息。
,其中xS:s = [xS, xS−1,…xs]。如上所述,这个提法不依赖于任何具体的假设。分解的每个分量p(xs−1| xs:s)综合了上述所有变量的信息。
Method
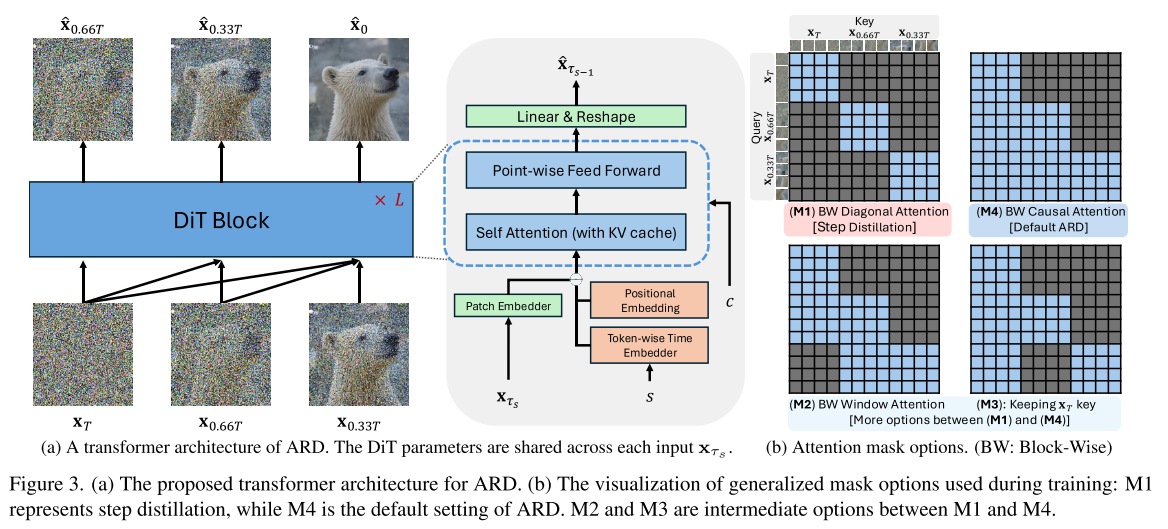
在本节中,我们介绍扩散变压器(DiT)的自回归蒸馏(ARD)。图2b提供了ARD过程的概述。我们将在3.1节中分解蒸馏的概率公式,然后在3.2节中转到我们的学生模型的变压器体系结构设计。最后,我们将在3.3节中介绍训练和推理。
Autoregressive distillation
本节将方程(3)中的阶跃蒸馏公式推广到ARD。方程(3)中的分解在没有完整历史轨迹信息的情况下是有效的。然而,当每个概率p(xτs−1 |xτs)近似为φ xτs−1 = Gθ(xτs, s)时,由于估计误差,与真实值的差异是不可避免的,从而导致第2.2节讨论的暴露偏差问题。为了缓解这个问题,我们以第2.3节的自回归方式扩展了方程(3)的公式:
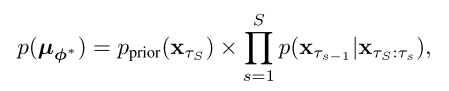
式中,xτS:τs = [xτS, xτS−1,…, xτs]为历史轨迹。这个公式有两个好处:(i)每一步都包括真实值初始噪声xτS作为输入,它与预测目标xτS−1具有确定性耦合。此外,从xτS−1到xτS +1的历史轨迹预测比最近的样本更准确,因为对它们来说,在推理过程中误差积累的机会更少。相比之下,方程(3)中的输入仅仅是当前样本的xτs,使其容易受到暴露偏差的影响。(ii)为了在每一步预测xτs−1,模型需要同时生成粗粒度和细粒度信息。最近去噪的样本xτs是细粒度信息的最佳来源,但接近xτs的历史轨迹是粗粒度信息的更好来源[13,60]。
对于修改后的学生公式,我们的目标是估计![]() ,它仍然是一个狄拉克δ分布。为了实现这一点,我们定义了一个新的映射函数
,它仍然是一个狄拉克δ分布。为了实现这一点,我们定义了一个新的映射函数![]() 。然后用学生神经网络Gθ(xτS:τs, s)逼近该函数。
。然后用学生神经网络Gθ(xτS:τs, s)逼近该函数。

Transformer design
3.1节中定义的映射函数Gθ(xτS:τs, s)的设计并不简单,因为输入大小取决于去噪步骤s。为了克服这个问题,我们修改了教师DiT主干以适应多个输入。
Architecture 3.1节中定义的映射函数Gθ(xτS:τs, s)的设计并不简单,因为输入大小取决于去噪步骤s。为了克服这个问题,我们修改了教师DiT主干以适应多个输入。为了处理历史轨迹,我们设计了基于变压器的自回归模型,如图图3a所示。使用共享补丁嵌入器将每个输入xτs标记为一系列标记。由于每个输入xτs具有与二维网格相同的空间结构,因此位置嵌入在输入之间是共享的。变压器块需要识别输入序列xτS中每个令牌的顺序,…, xτs。为此,我们为每个令牌添加了一个额外的时间步嵌入,类似于VAR[76]中的水平嵌入最近去噪的样本xτs成为查询令牌,历史序列xτs:τs成为自注意力机制块中的键值令牌。经过L个堆叠的变压器块后,对令牌进行线性变换和去令牌化,得到一个样本xτs−1。
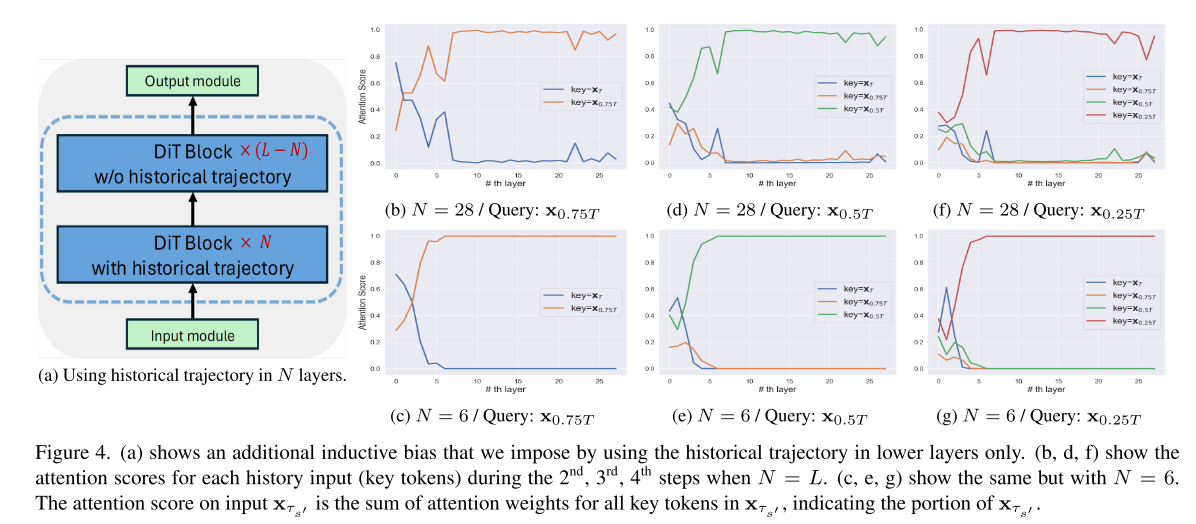
Historical trajectory only in lower N layers. 图4b、4d和4f显示了每个L变压器层(2、3、4)步中每个输入的注意力得分。最近去噪的样本xτs作为关键标记在较高层被激活,而历史轨迹xτs:τs+1在较低层被激活。DiT块中的较低层考虑粗粒度信息,而DiT块中的较高层考虑细粒度信息[19]。这个关注部分验证了历史轨迹是有用的,并且可以作为粗粒度信息的更好来源。然而,在图4b、4d和4f中,他的历史代币在较高层仍然有轻微的波动,可能是由于优化不完善。我们提出了变压器层的其他设计选择,如图图所示;只在较低的N层中使用历史轨迹。如图4c、4e和4g所示,这种感应偏置增强了低层历史轨迹的使用。

Training and inference procedure
ARD的默认训练目标是方程(6)中的回归损失LARD,它是相对于θ进行优化的。图中的变压器架构允许对所有s∈{1,…, S}计算x δ τs−1 = Gθ(xτS:τs, s)同时使用attention mask。我们可以通过设计注意力遮罩来推广我们的框架,如图图3b所示。选项M4的区块因果关注是最灵活的,因为它使用了整个轨迹历史。选项M1表示步进蒸馏,它只使用当前样本xτs作为输入。选项M2和M3是介于M1和M4之间的中间选择。M2中的窗口注意仅使用来自轨迹历史的当前和以前的样本。M3中的注意掩模使用最近去噪的样本和初始噪声xτS,这有助于始终如一地保留真实值信号。我们的框架还可以从最终预测的额外鉴别器损失中受益:xτ0 = Gθ(xτS:τ 1,1),类似于[27]。通过在这种损失中使用真实数据,我们可以进一步改善学生世代中的高频细节,甚至优于教师。
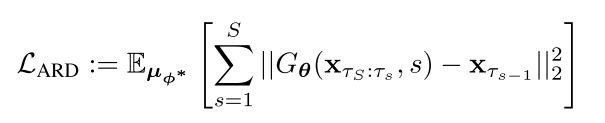
在推理过程中,生成从xτS ~ prior(xτS)开始。在每一步,学生模型根据整个历史预测![]() 预测
预测![]() 。这些信息
。这些信息![]() 在之前的推理步骤中以kv-cache的形式存储,在推理过程中不需要注意掩码。
在之前的推理步骤中以kv-cache的形式存储,在推理过程中不需要注意掩码。
