Python基础:类的深拷贝与浅拷贝-->with语句的使用及三个库:matplotlib基本画图-->pandas之Series创建
一.类的深拷贝与浅拷贝

class CPU():pass
class Disk():passclass Computer():#计算机由CPU和硬盘组成def __init__(self):self.cpu = CPU()self.disk = Disk()cpu = CPU()#创建一个CPU对象
disk = Disk()#创建一个硬盘对象#创建一个计算机对象
com = Computer(cpu,disk)
#变量(对象)的赋值
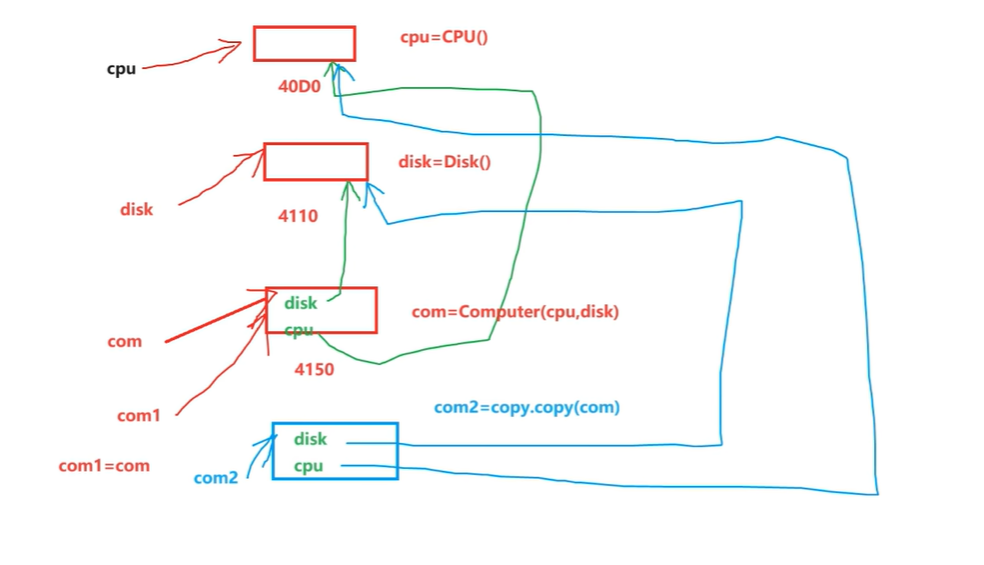
com1 = com
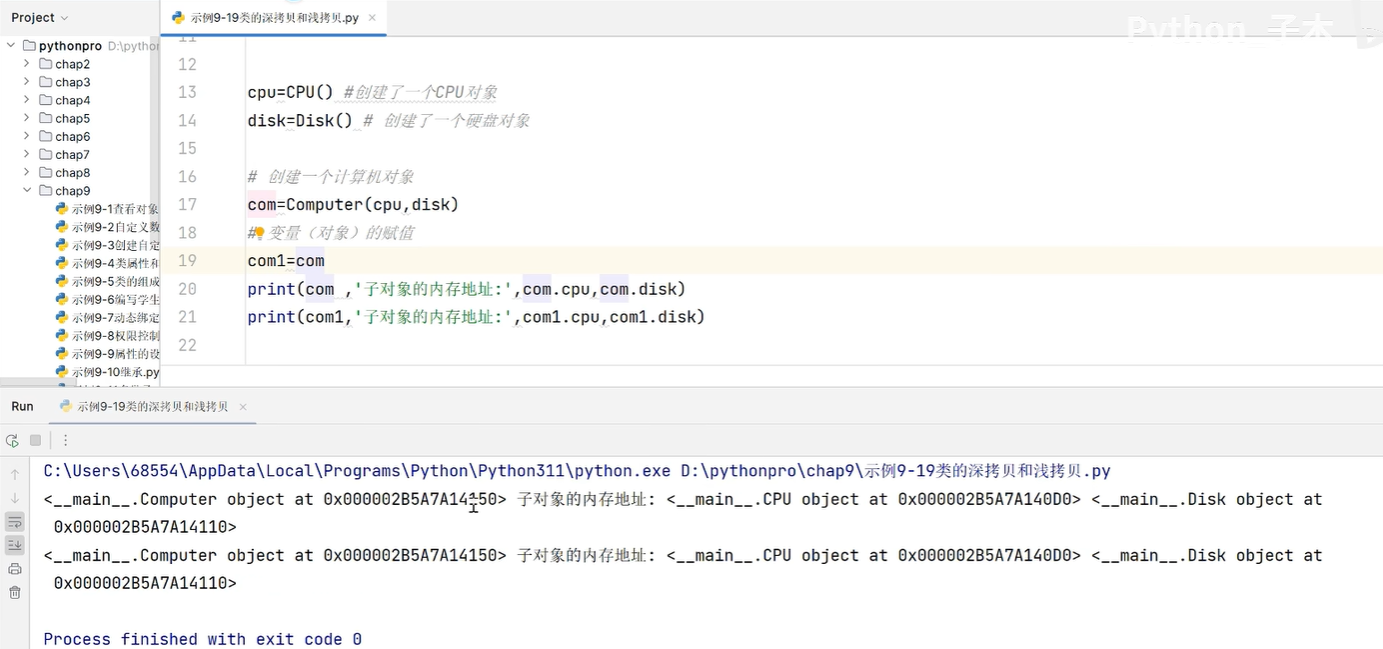
print(com,'子对象的内存地址',com.cpu,com.disk)
print(com1,'子对象的内存地址',com1.cpu,com.disk)# 类对象的浅拷贝
print('-'*40)
import copy
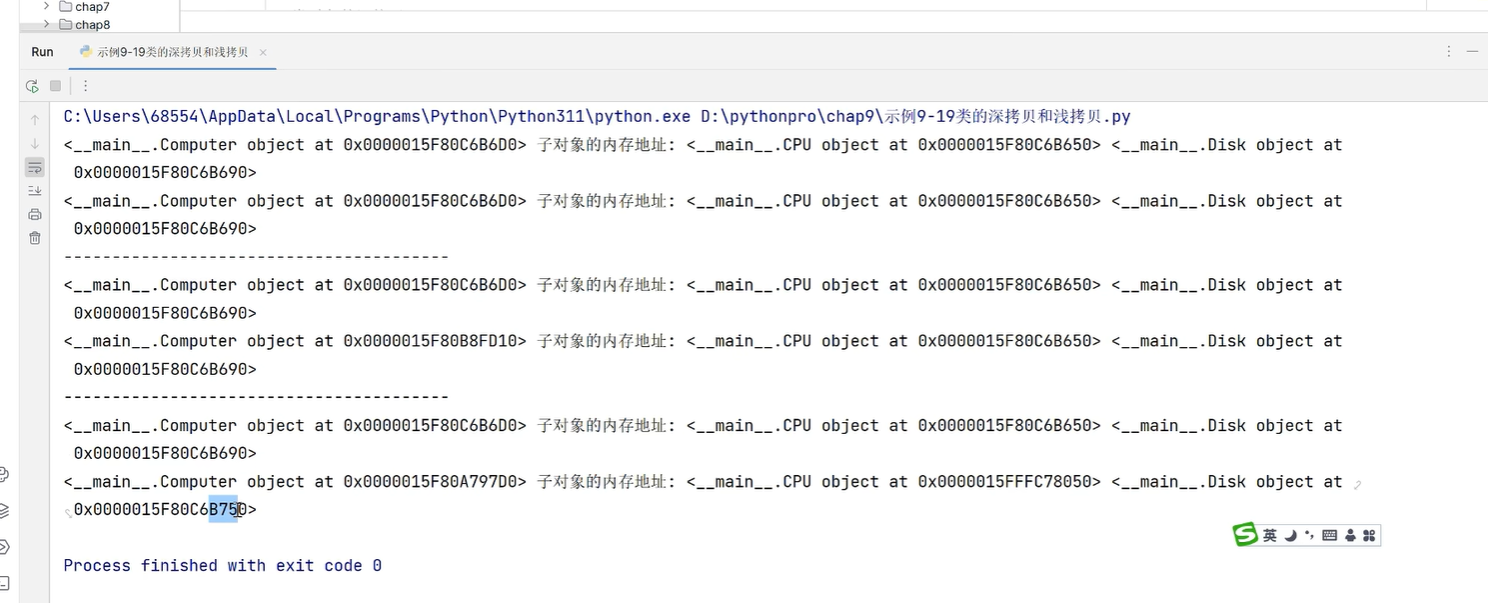
com3 = copy.deepcopy(com) # com2是新产生的对象,com2的子对象,cpu,disk不变
print(com,'子对象的内存地址',com.cpu,com.disk)
print(com3,'子对象的内存地址',com3.cpu,com3.disk)

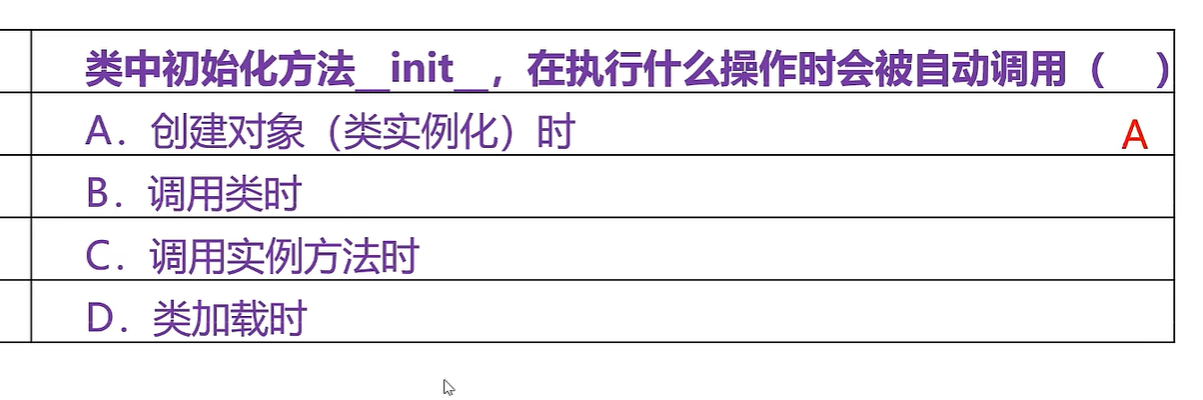
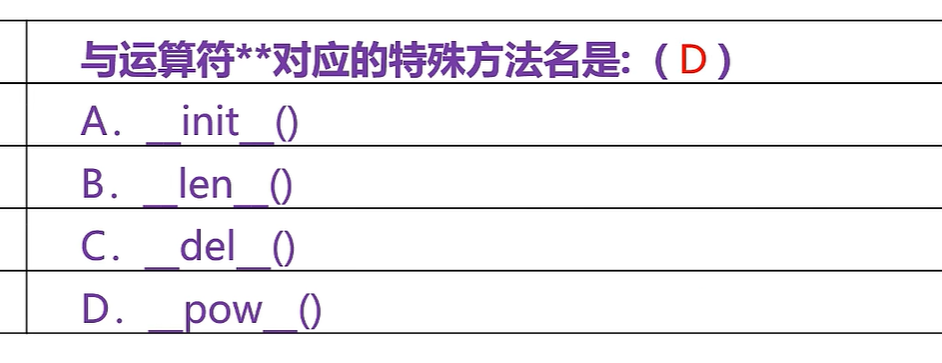
章节习题:clc是类方法的参数







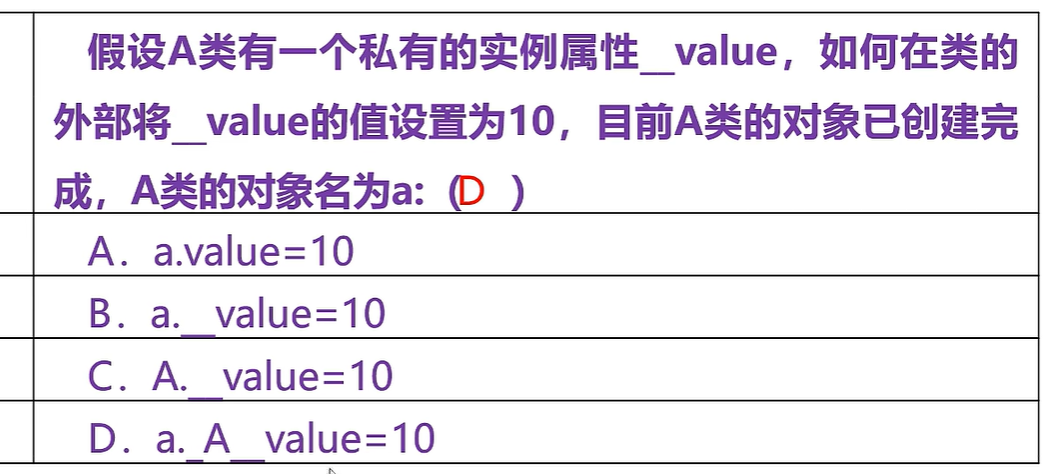
私有属性:对象名.下划线类名__属性名

计算圆的面积和周长
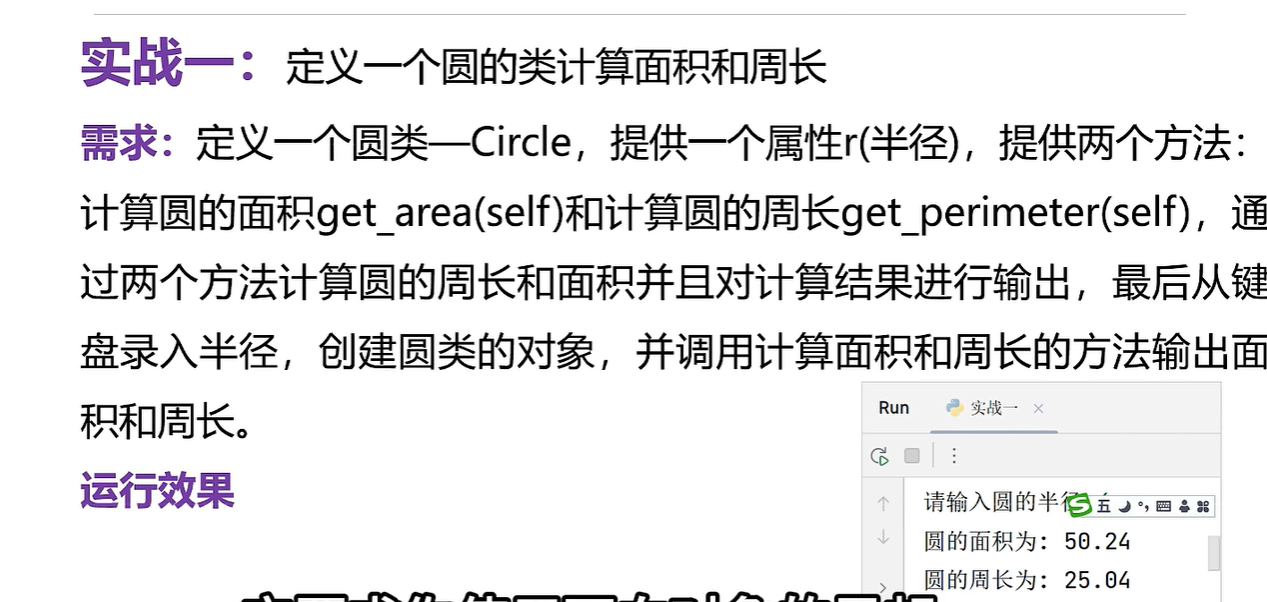
class Circle:def __init__(self, r):self.r= r# 计算面积的方法def get_area(self):return self.r * 3.14 * self.r# 计算周长的方法def get_perimeter(self):return self.r * 3.14 * 2# 创建对象
r=eval(input("Enter the radius: "))
c=Circle(r)# 调用方法
area=c.get_area() #调用面积的方法
perimeter=c.get_perimeter() # 调用计算周长的方法
print("The area of the circle is ",area)
print("The perimeter of the circle is ",perimeter)
定义学生类录入5个学生信息并存储到列表中

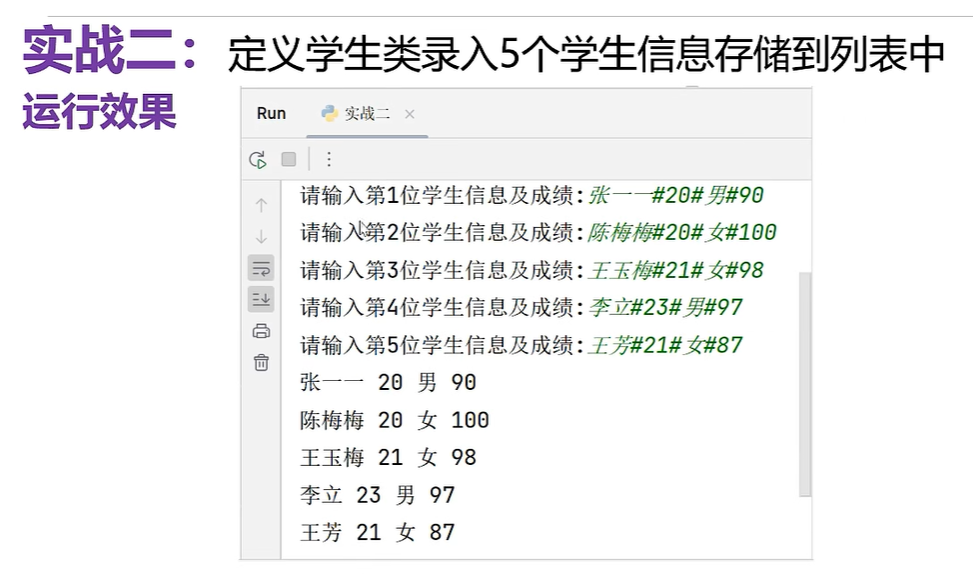
class Student:def __init__(self, name, age,gender,score):self.name = nameself.age = ageself.gender = genderself.score = score# 实例对象:def info(self):print(self.name, self.age, self.gender, self.score)print('请输入五位学生信息:(姓名#年龄#性别#成绩')
lst=[] # 用于存储5个学生对象
for i in range(1,6):s=input(f'请输入第{i}位学生信息及成绩')s_lst=s.split('#')# 索引为0的是姓名,索引为1的是年龄,索引为2的是性别,索引为3的是成绩# 创建学生对象stu=Student(s_lst[0],s_lst[1],s_lst[2],s_lst[3])# 将学生对象添加到列表当中lst.append(stu)# 遍历列表,调用学生对象的info方法
for item in lst: # item的数据类型是Student类型item.info() # 对象名.方法名()
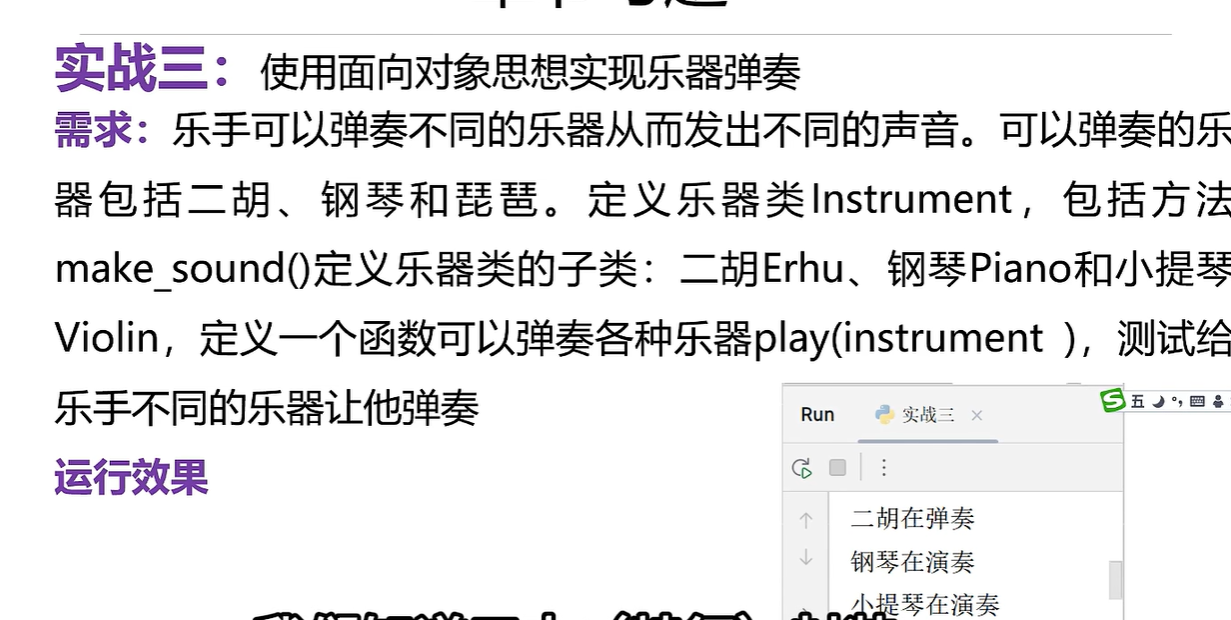
方法重写以及多态
class Instrument(): # 父类def make_sound(self):passclass Erhu(Instrument):def make_sound(self):print("Erhu在弹奏")class Pinao(Instrument):def make_sound(self):print('钢琴在弹奏')class Violin(Instrument):def make_sound(self):print('小提琴在弹奏')# 编写一个函数:
def play(obj):obj.make_sound()# 调试
er = Erhu()
pinao = Pinao()
vio = Violin()#调用方法
play(er)
play(pinao)
play(vio)
使用面相对象思想编写出租车和家用轿车

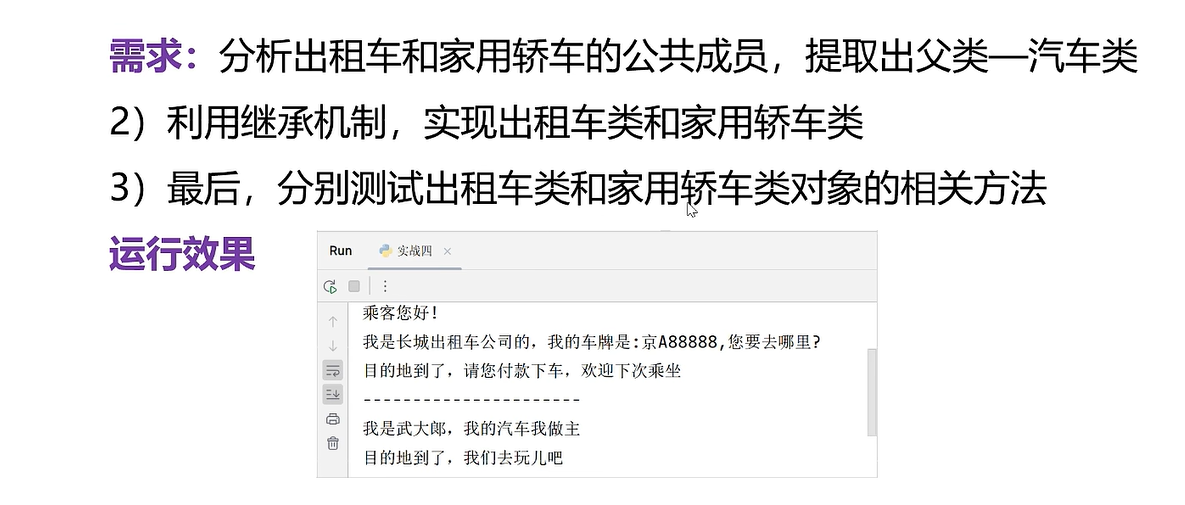
class Car:def __init__(self, type, no):self.type = typeself.no = nodef start(self):print('我是车,我能启动')def stop(self):print('我是车,我可以停止')# 出租车
class Taxi(Car):def __init__(self,type,no,company):super().__init__(type,no)self.company = company# 重写父类的启动和停止的方法def start(self):print('乘客您好')print(f'我是{self.company}出租车公司,我的车牌是:{self.no},您要去哪里')def stop(self):print('目的地到了,请您扫码')class FamilyCar(Car):def __init__(self,type,no,name):super().__init__(type,no)self.name = namedef start(self):print(f'我是{self.name},我的轿车我做主')def stop(self):print('目的地到了')# 测试
taix=Taxi('上海大众','京B6666','长城')
taix.start()
taix.stop()print('-'*40)
family_car=FamilyCar('广汽丰田','京A666','武大郎')
taix.start()
taix.stop()二.模块及常用的第三方模块



name='张三'def info():print(f'大家好,我叫{name}')
2.2 模块的导入
name='hh'
age=19
def info():print(f'姓名{name},年龄:{age}')name='张三'def info():print(f'大家好,我叫{name}')
import project1
print(project1.info())
project1.info()import project1 as a
print(a.name)
project1.info()# 2.from...import
from project1 import name # 导入的是具体变量的名称
print(name)
# info
project1.info()from project1 import info#导入的是一个具体的函数的名称
info()# 通配符
from project1 import *
print(name)
info()# 同时导入多个模块
import math,time,randomfrom project1 import *
from introduce import *
# 导入模块中具有同名的变量和函数,后导入的会将之前导入的进行覆盖
info()# 如果不想覆盖,解决方案,可以使用import
import project1
import introduce
# 使用模块中的函数或变量时,模块名打点调用
project1.info()
introduce.info()
2.3 Python中的包

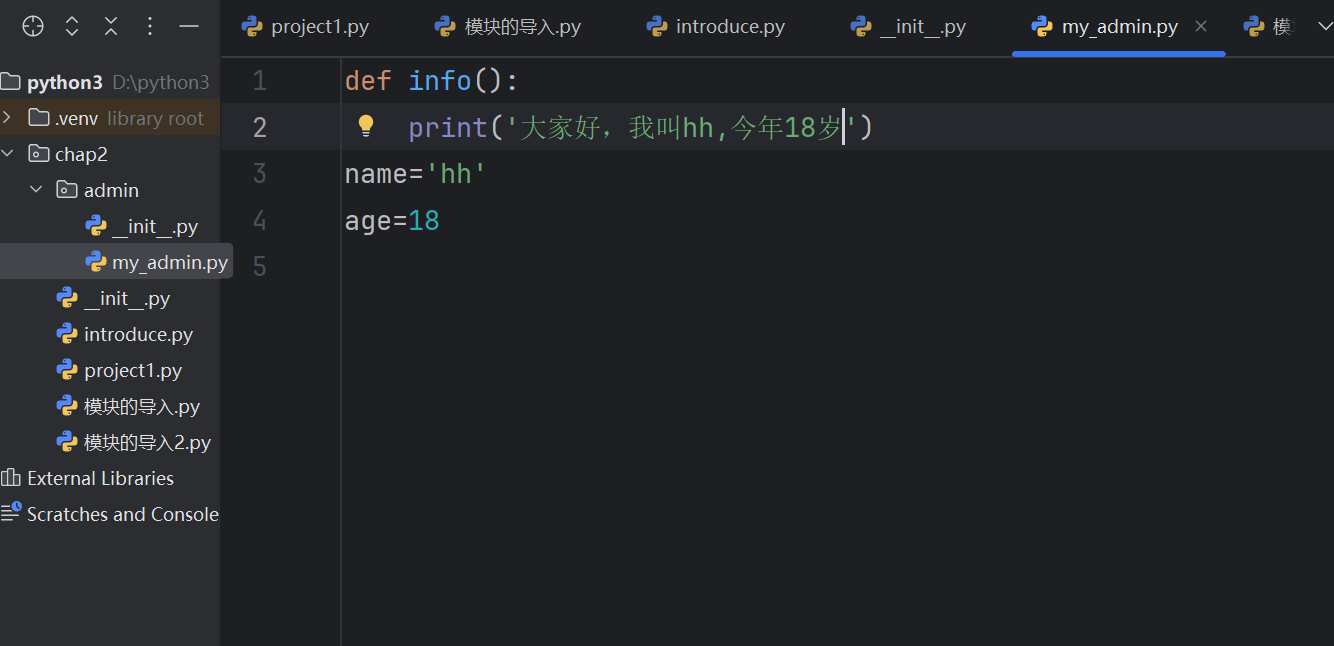
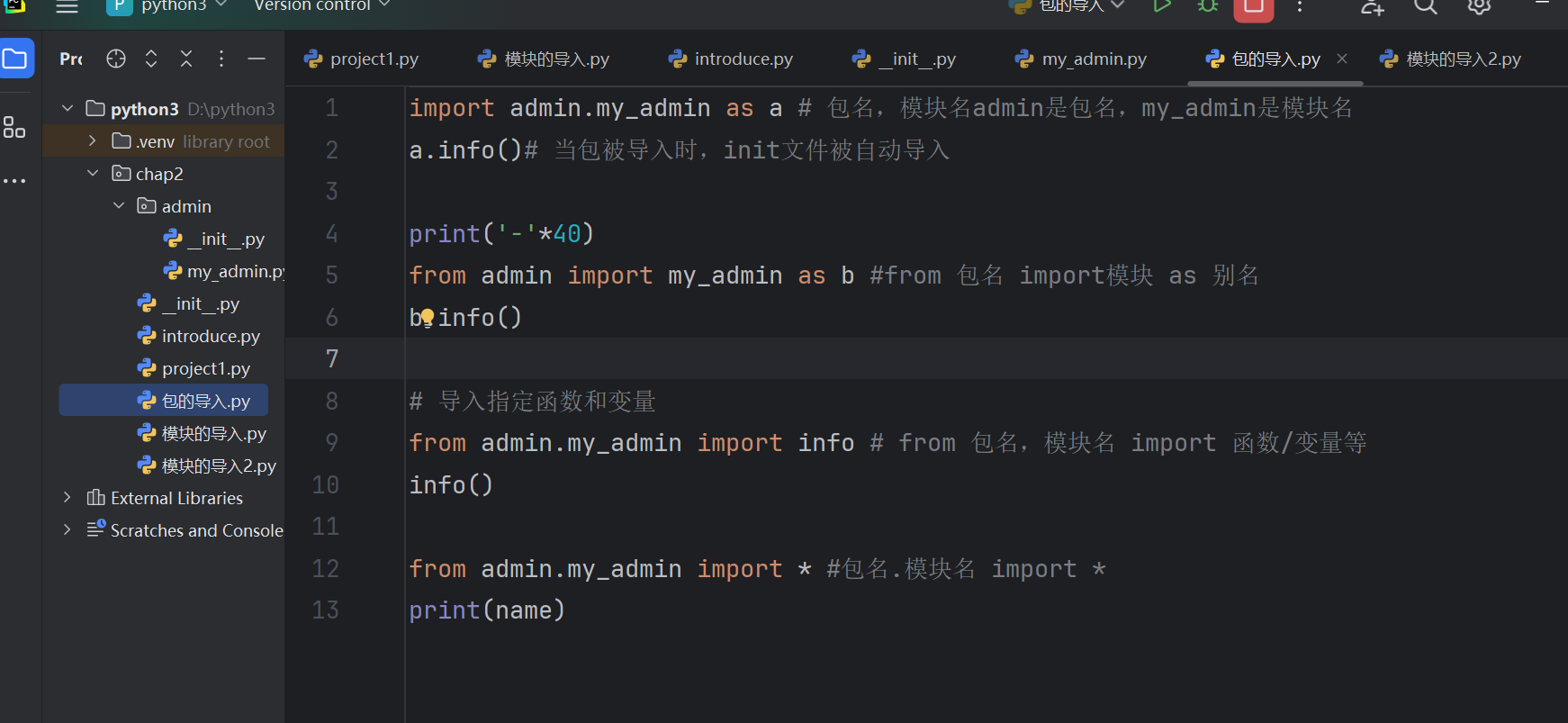
import admin.my_admin as a # 包名,模块名admin是包名,my_admin是模块名
a.info()# 当包被导入时,init文件被自动导入print('-'*40)
from admin import my_admin as b #from 包名 import模块 as 别名
b.info()# 导入指定函数和变量
from admin.my_admin import info # from 包名,模块名 import 函数/变量等
info()from admin.my_admin import * #包名.模块名 import *
print(name)
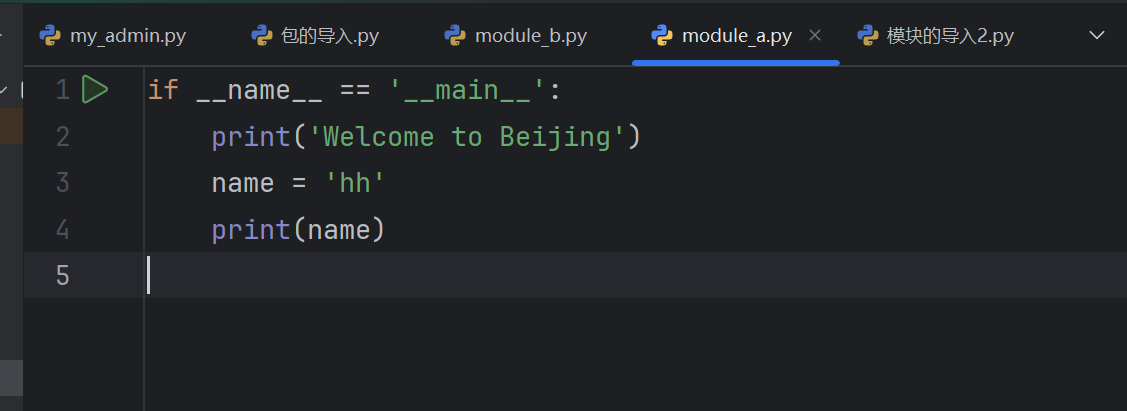
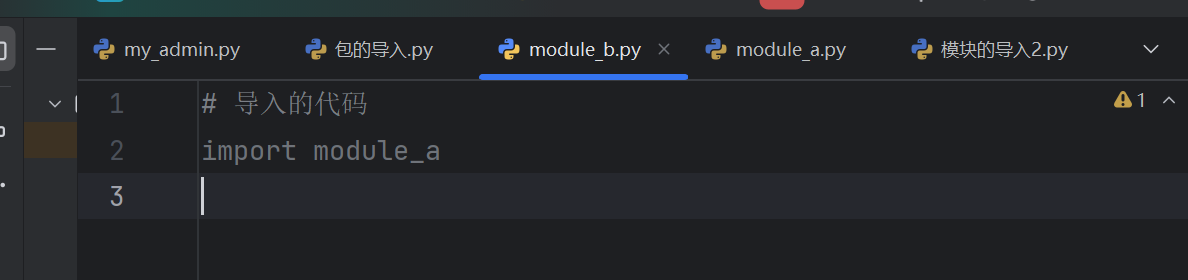
# 导入的代码
import module_a
if __name__ == '__main__':print('Welcome to Beijing')name = 'hh'print(name)
2.4 Python中常用的内置模块
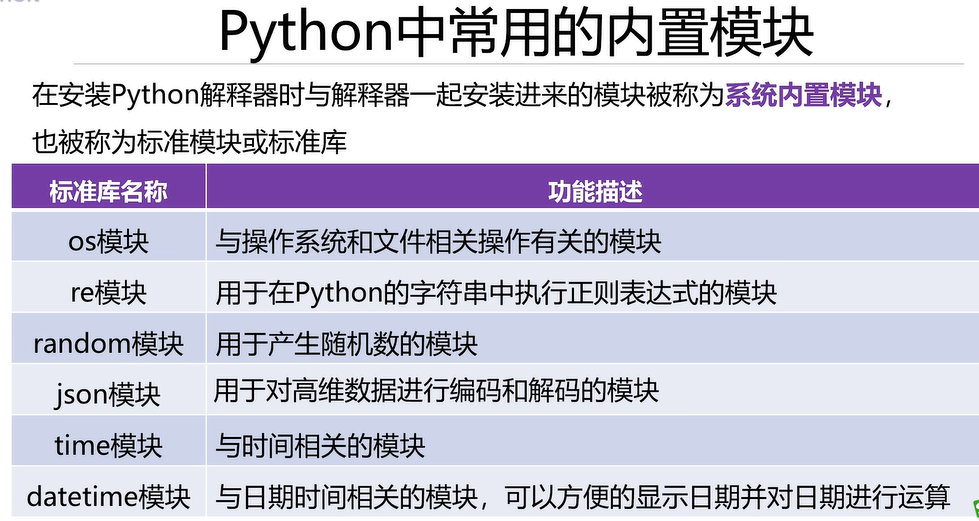
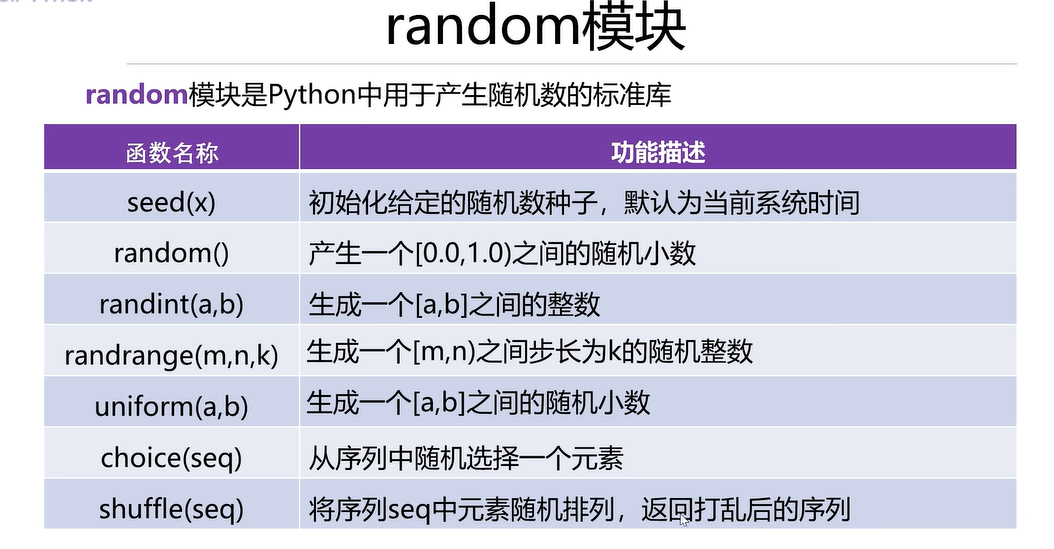
# 导入
import random
# 设置随机种子
random.seed(10)
print(random.random()) # (0.0,1.0)不包含1
print(random.random())
print('-'*40)
print(random.randint(1,100)) # [1,100]for i in range(10):# 含有m不含n,步长为k,m--->start-->1,n-->stop-->10,k->step-->print(random.randrange(1,10,3))# 11行执行了10次lst=[i for i in range(1,11)] #[a,b]随机小数
print(random.choice(lst)) # lst是列表,称为序列
# 随机排序
random.shuffle(lst)
print(lst)random.shuffle(lst)
print(lst)
2.5 time模块中常用的函数

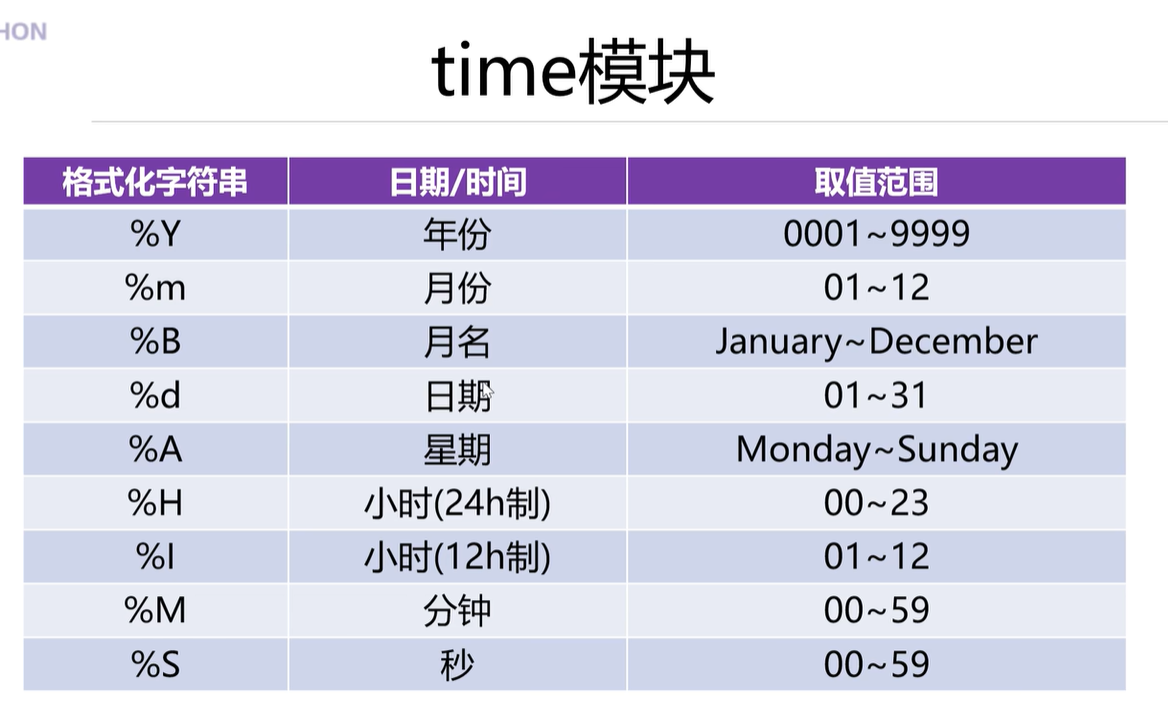
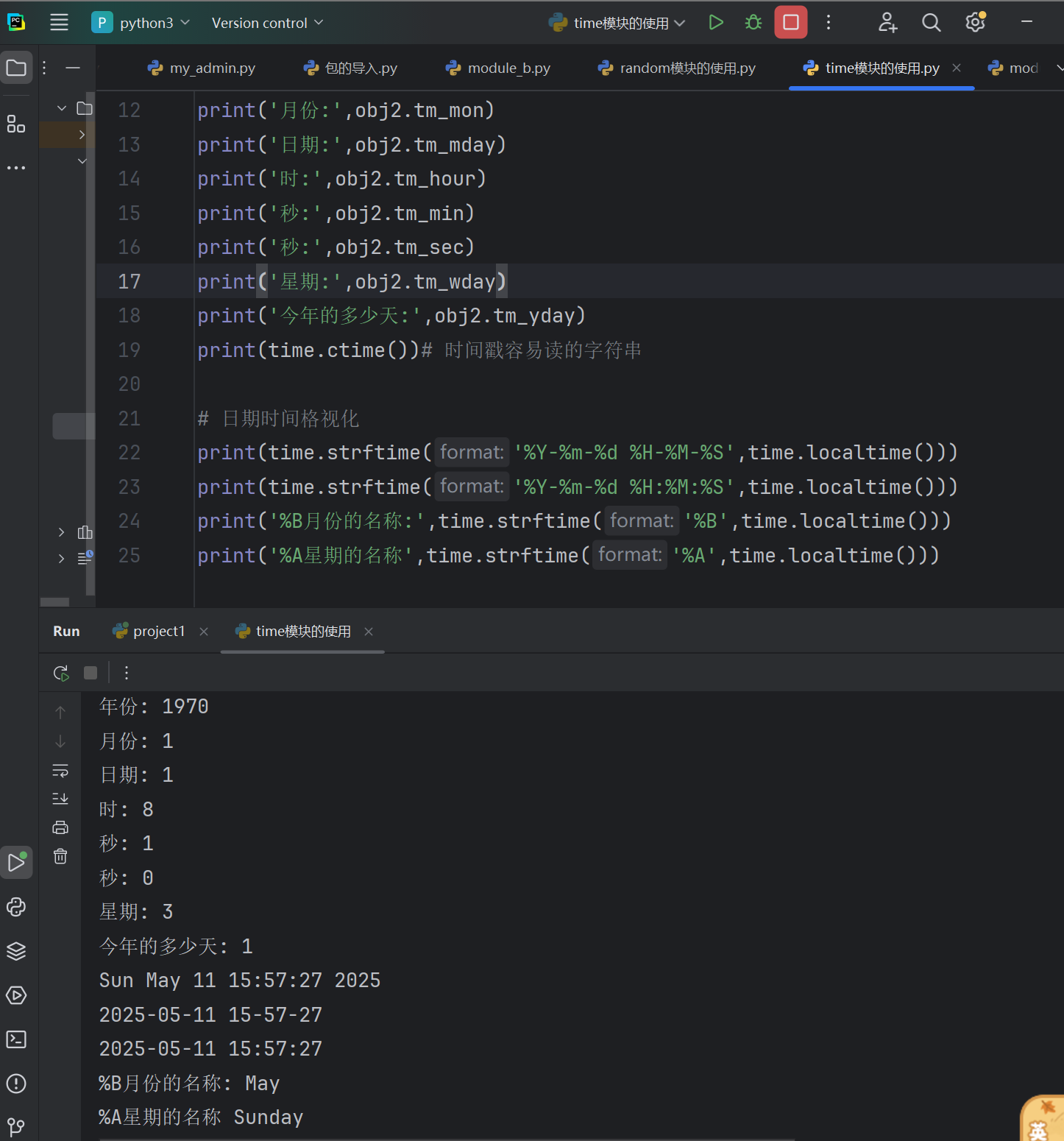
import time
now = time.time()
print(now)obj=time.localtime()#struct_time对象
print(obj)obj2=time.localtime(60) # 60秒 1970年1月1日
print(obj2)
print(type(obj2))
print('年份:',obj2.tm_year)
print('月份:',obj2.tm_mon)
print('日期:',obj2.tm_mday)
print('时:',obj2.tm_hour)
print('秒:',obj2.tm_min)
print('秒:',obj2.tm_sec)
print('星期:',obj2.tm_wday)
print('今年的多少天:',obj2.tm_yday)
print(time.ctime())# 时间戳容易读的字符串# 日期时间格视化
print(time.strftime('%Y-%m-%d %H-%M-%S',time.localtime()))# str---字符串f--time时间
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime()))
print('%B月份的名称:',time.strftime('%B',time.localtime()))
print('%A星期的名称',time.strftime('%A',time.localtime()))# 字符串转成struct_time
print(time.strftime('2008-08-08','%Y-%m-%d'))time.sleep(20)
print('helloworld')
2.6 datatime类
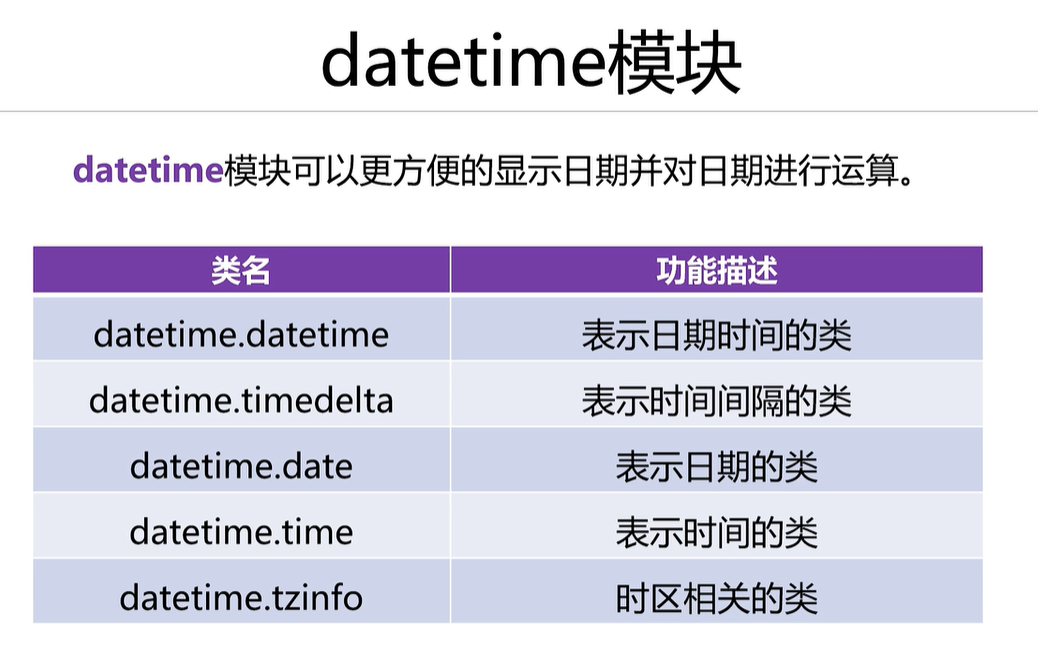
from datetime import datetime # 从datetime模块中导入datetime类
dt = datetime.now()
print('当前的系统时间为:',dt)# datetime是一个类,手动创建这个类的对象
dt2 = datetime(2028,8,8,20,8)
print('dt2的数据类型',type(dt2),'dt2表示的日期时间:',dt2)
print('年:',dt2.year,'月:',dt2.month,'日:',dt2.day)
print('时:',dt2.hour,'分:',dt2.month,'秒:',dt2.second)# 比较两个datatime类型对象的大小
labor_day=datetime(2028,5,1,0,0,0)
national_day=datetime(2028,10,1,0,0,0)print('2028年5月1日比2028年10月1日早吗',labor_day<national_day)# datetime类型与字符串类型转换
nowdt=datetime.now()
nowdt_str=nowdt.strftime('%Y/%m/%d %H:%M:%S')
print('nowdt的数据类型',type(nowdt),'nowdt所表示的数据是什么',nowdt)
print('nowdt_str的数据类型',type(nowdt_str),'nowdt_str所表示的数据是什么',nowdt_str)# 将字符串类型转成datetime类型
str_datetime='2028年8月8日8点8分'
dt3=datetime.strptime(str_datetime,'%Y年%m月%d日 %H点%M分')
print('str_datetime的数据类型:',type(str_datetime),'str_datetime所表示的数据',str_datetime)
print('dt3的数据类型:',type(dt3),'dt3所表示的数据',dt3)from datetime import datetime
from datetime import timedelta
# 创建两个datetime类型的对象
deltal=datetime(2028,10,1)-datetime(2028,5,1)
print('deltal的数据类型是:',type(deltal),"deltal表示的数据",deltal)
print('2028年5月1日之后153是:',datetime(2028,5,1)+deltal)# 通过传入参数的方式创建一个timedelta对象
td1=timedelta(10)
print('创建一个10天的timedelta对象',td1)
td2=timedelta(10,11)
print('创建一个10天11秒的timedelta对象',td2)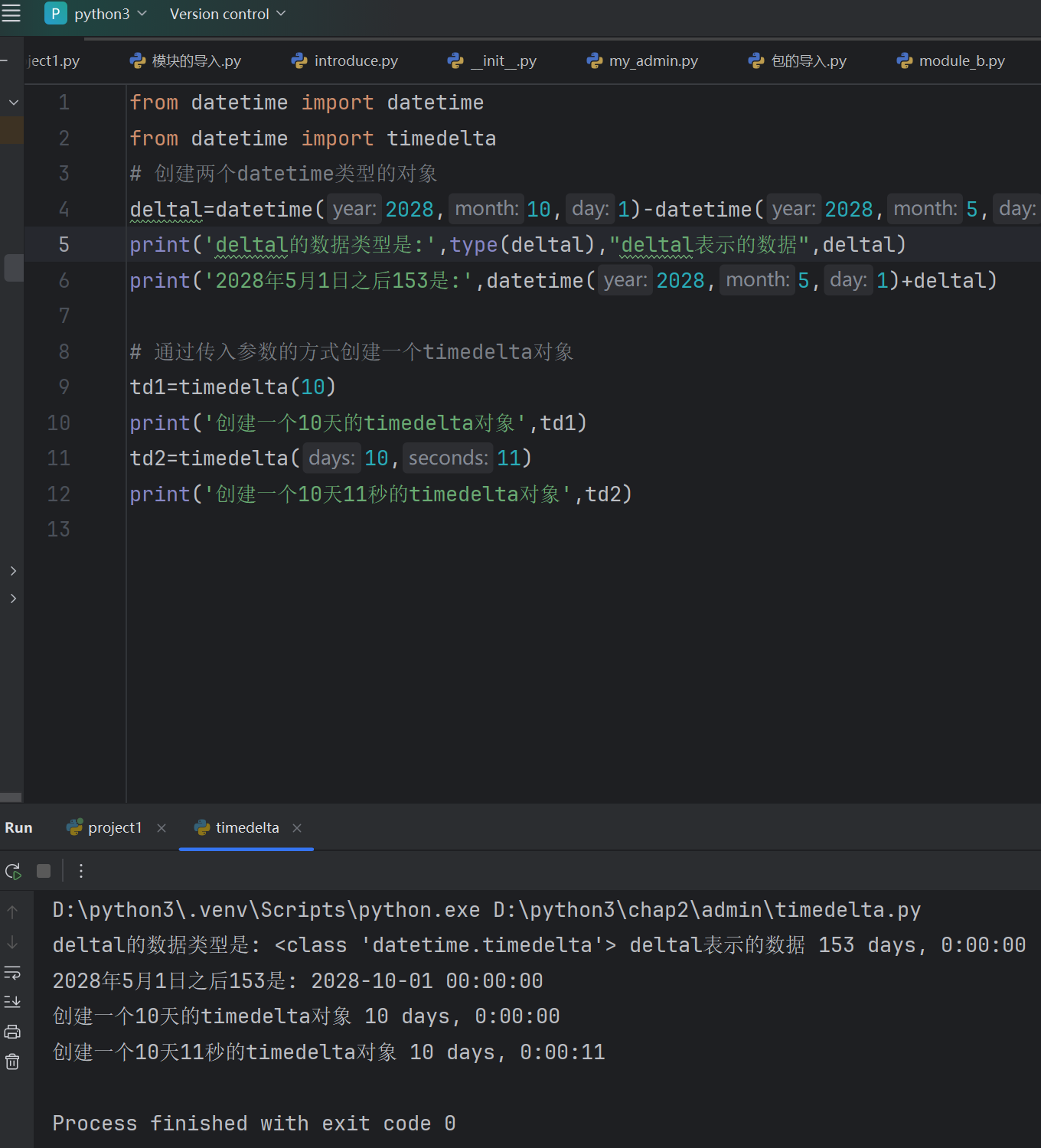
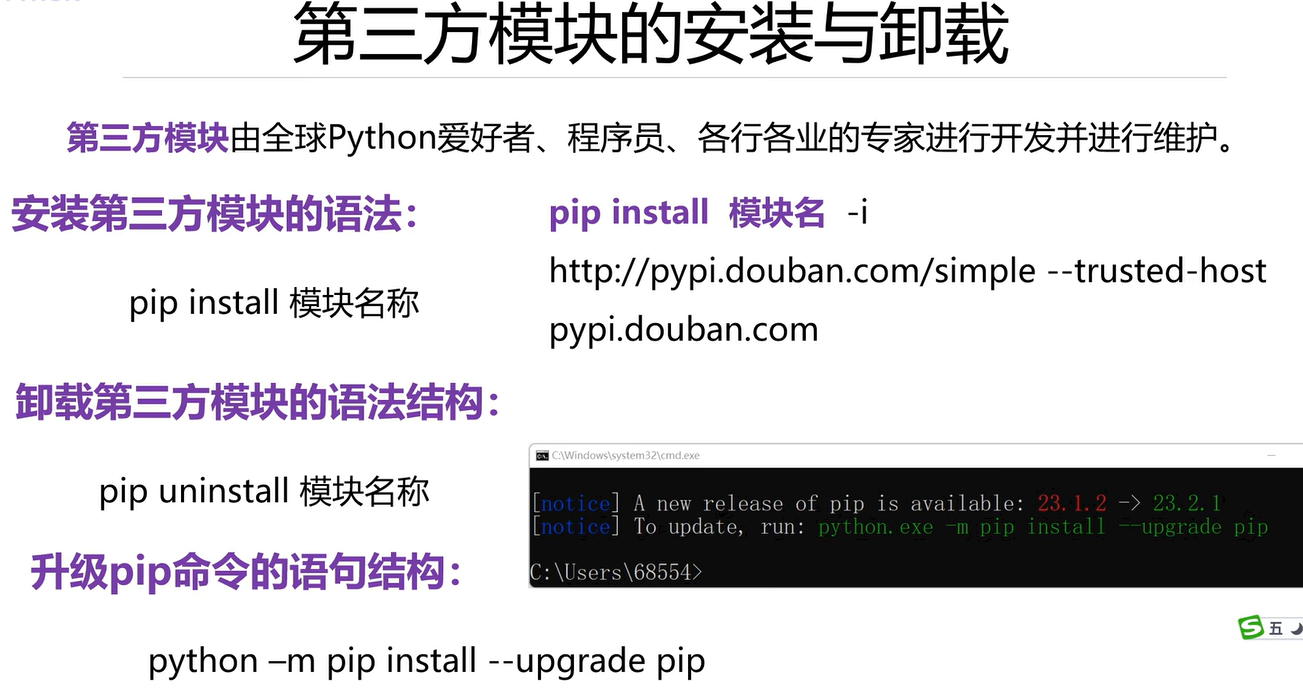
2.7 第三方模块的安装或卸载
2.8 requests模块的应用

2.9 爬取景区的天气预报
import reimport requests
url=requests.get("https://www.msn.cn/zh-cn/weather/forecast/in-%E5%8C%97%E4%BA%AC%E5%B8%82,%E4%B8%9C%E5%9F%8E%E5%8C%BA?ocid=ansmsnweather&loc=eyJsIjoi5Lic5Z%2BO5Yy6IiwiciI6IuWMl%2BS6rOW4giIsImMiOiLkuK3ljY7kurrmsJHlhbHlkozlm70iLCJpIjoiQ04iLCJnIjoiemgtY24iLCJ4IjoiMTE2LjM5OCIsInkiOiIzOS45MDgifQ%3D%3D&weadegreetype=C")resp=requests.get(url.url)# 打开浏览器并打开网址
# 设置一个编码格式
resp.encoding='utf-8'
print(resp.text) # resp响应对象, 对象名,属性名 resp.text# 从一堆字符串提取想要的数据,需要使用正则表达式
city= re.findall('<span>(.*?)</span>',resp.text)[0]
print(city)
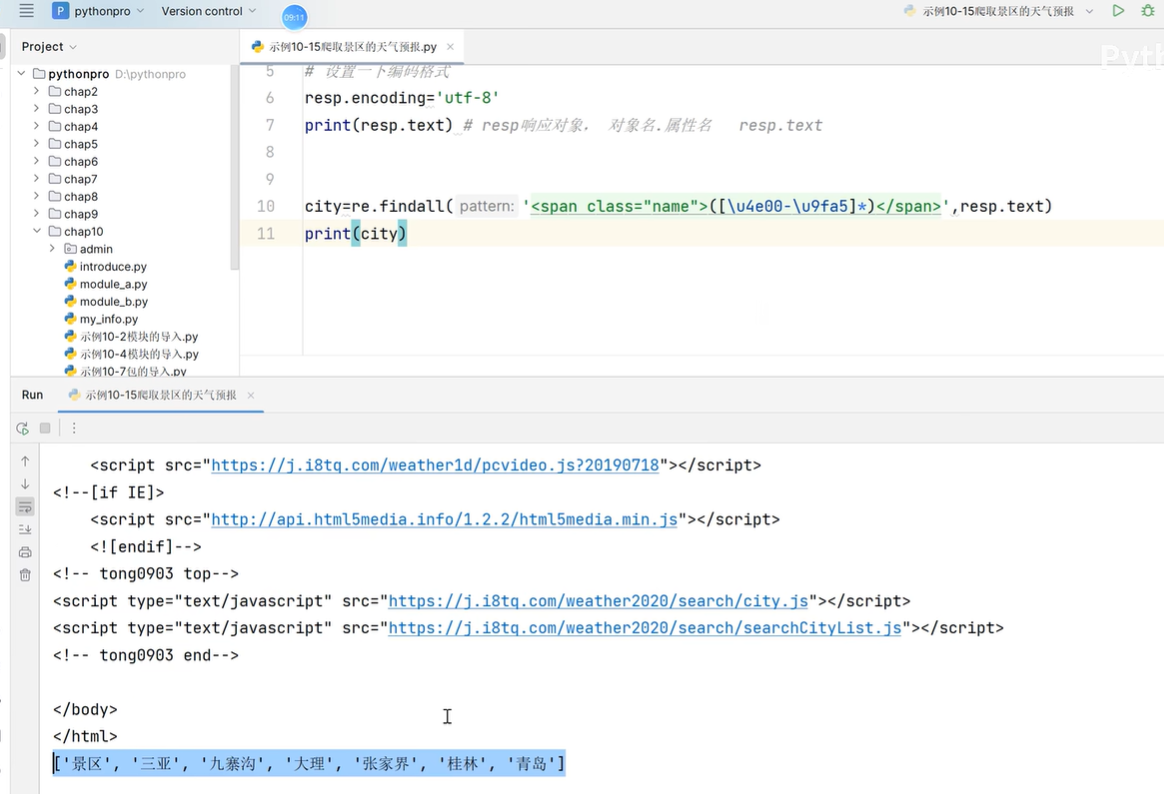
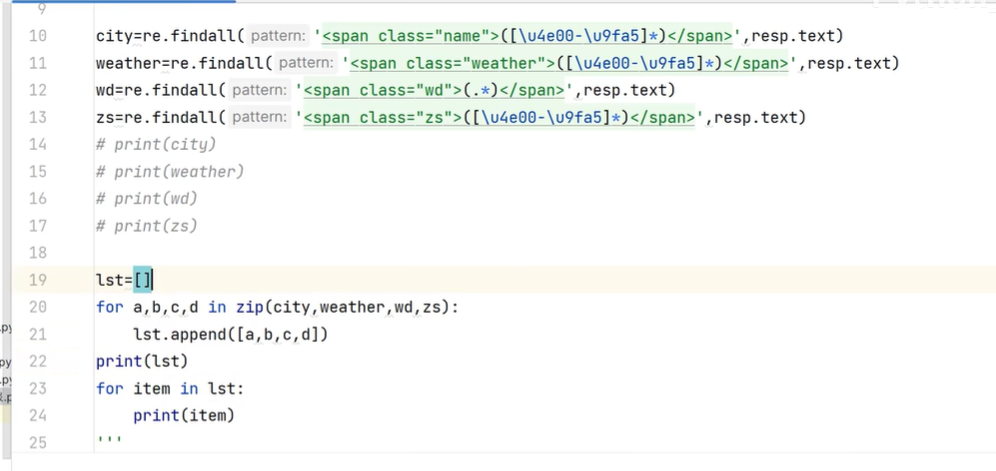
3.1 Openpyxl模块的使用
将weather封装到函数中
两个函数分别是发送函数请求结果,将数据结果进行数据解析,
将爬取的数据存取到excel中
import weather
import openpyxl
html=weather.get_html()# 发请求,得响应结果
lst=weather.get_html(html)# 解析数据
# 创建一个新的Excel工作簿
workbook=openpyxl.Workbook()#创建对象
# 在excel文件中创建工作表
sheet=workbook.create_sheet('景区天气')
#向工作表中添加数据
for item in lst:sheet.append(item)# 一次添加一行workbook.save('景区天气.xlsx')
从Excel文件中读取数据
import openpyxl
# 打开工作簿
workbook=openpyxl.load_workbook('景区天气.xlsx')
# 选择要操作的工作表
sheet=workbook['景区天气']
# 表格数据是二维列表,先遍历的是行,后遍历的是列
lst=[]#存储的是行数据
for row in sheet.iter_rows():sublst=[]#存储单元格数量for cell in row:# cell单元格lst.append(cell.value)lst.append(sublst)for item in lst:print(item)
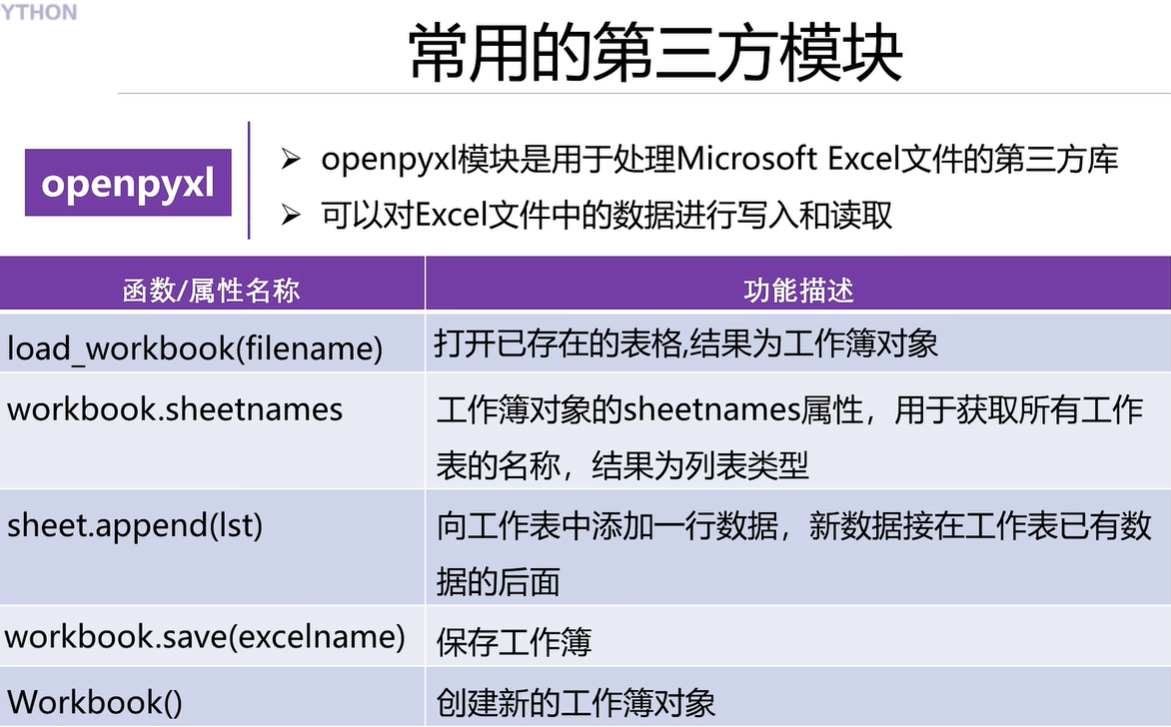
3.2 常用第三方模块

3.3 pdfplumber模块
import pdfplumber
#打开PDF文件
with pdfplumber.open('小学数学-公示.pdf') as pdf:for i in pdf:# 遍历页print(i.extract_text())#extract_text()方法提取内容print(f'---------第{i.page_num}页结束')3.4 Numpy模块
import numpy as np
import matplotlib.pyplot as plt
# 读取图片
nl=plt.imread('google.jpg')
print(type(nl),nl)# 数组,三维数组,最高维度表示的是图像的高,次高维度是图像的宽,最低维[R,G,B]颜色
plt.imshow(nl)# 编写一个灰度的公示
n2=np.array([0.299,0.587,0.114])# 创建数组
# 将数组 n1(RGB)颜色与数组n2(灰度公式固定值),进行点乘运算
x=np.dot(nl,n2)
# 传入数组,显示灰度
plt.imshow(x,cmap='gray')3.5 pandas与matplotlib模块的使用
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sipbuild.generator.parser.rules import start# 读取Excel文件
df=pd.read_csv('JD手机销售数据.xlsx')
#print(df)
# 解决中文乱码
plt.rcParams['font.sans-serif']=['SimHei']
# 设置画布的大小
plt.figure(figsize=[10,6])
labels=df['商品名称']
y=df['北京出库量']
#print(labels)
#print(y)# 绘制饼图
plt.plot(y,labels=labels,autopct='%1.1f%%',startangle=90)#设置x,y轴刻度
plt.axis('equal')
plt.title('2028年1月北京个手机品牌出库量占比')
plt.show()
3.6 PyEcharts模块的使用

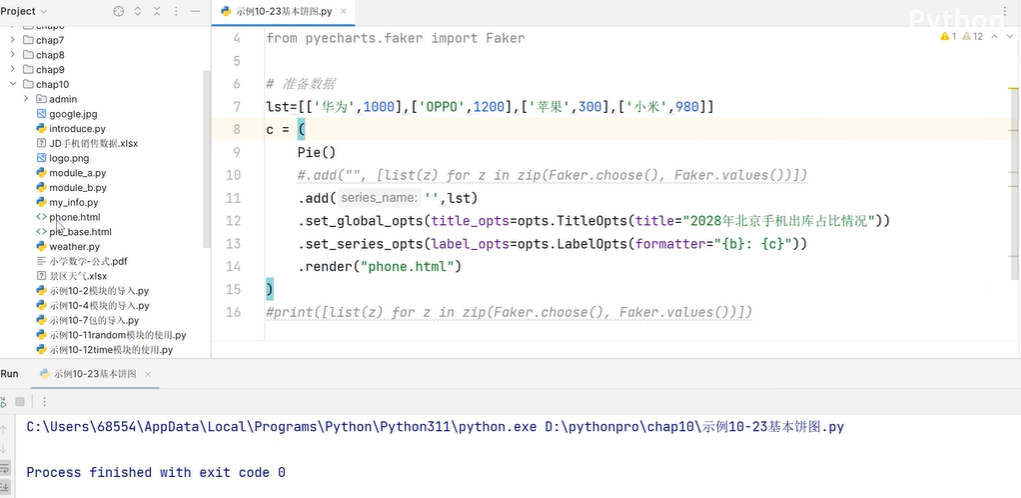
3.7 PIL 图像的交换
from PIL import Image
# 加载图片
im=Image.open('google.jpg')
# print(type(im),im)
# 提取RGB颜色通道,返回结果图像的剧本
r,g,b=im.split()
print(r,g,b)
#合并通道
om=Image.merge('RGB',(r,g,b))
om.save('new_google.jpg')
3.8 jieba模块实现中文分词
import jieba
# 读出来
with open('华为笔记本.txt', 'r', encoding='utf-8') as file:s=file.read()
# 分词
lst=jieba.cut(s)
#print(lst)#去重操作
set1=set(lst) # 使用集合实现去重
d={} #key:词,value:出现次数
for item in set1:if len(item)>=2:d[item]=item
#print(d),遍历
for item in set1:if item in d:d[item]=d.get(item)+1
print(d)new_lst=[]
for item in set1:new_lst.append(item,d[item])
print(new_lst)# 列表排序
new_lst.sort(key=lambda x:x[1],reverse=True)
print(new_lst[0:11])# 显示的是前十项3.9 第三方模块
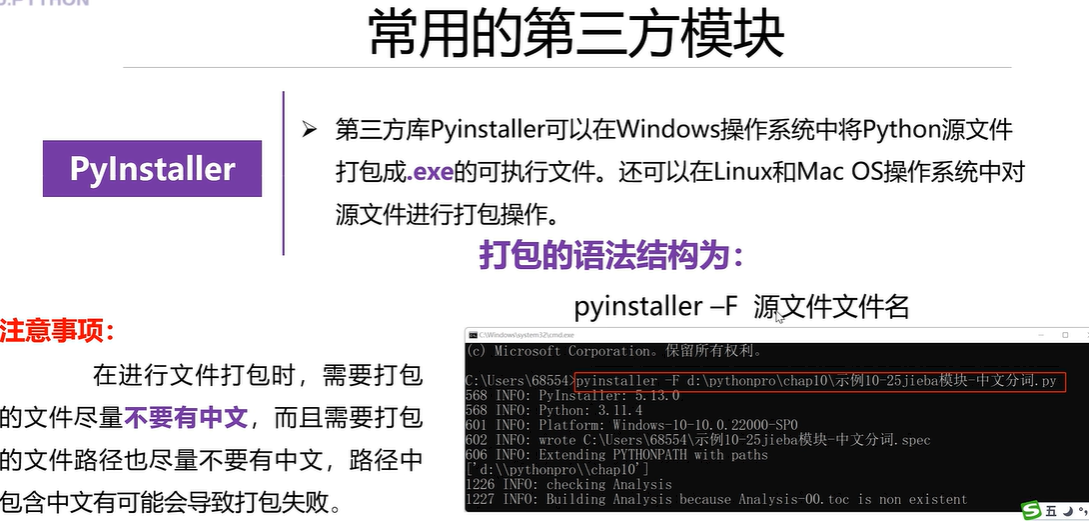
本章总结



四.文件及IO操作
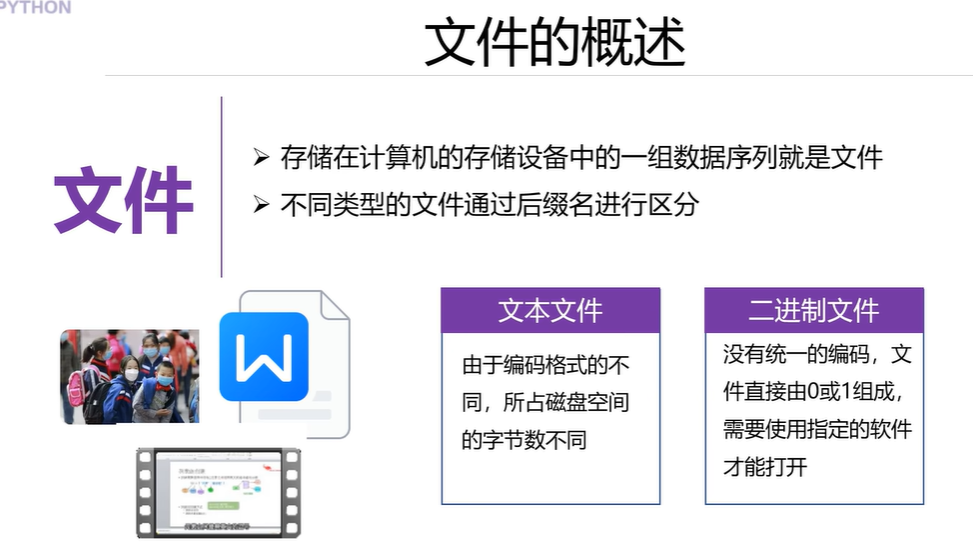

def my_write():#1.创建(打开)文件file=open('a.txt','w',encoding='utf-8')#2.操作文件file.write('伟大的中国梦')#3.关闭file.close()# 读取
def my_read():# 1.创建(打开)文件file=open('a.txt','r',encoding='utf-8')# 2.操作文件s=file.read()print(type(s),s)# 3.关闭文件file.close()# 主程序
if __name__=='__main__':#my_write() 调用函数my_read()
4.1 文件的写入操作


def my_write(s):# 1.打开(创建)文件file=open("b.txt",'a','utf-8')# 2.写入内容file.write(s)file.write("\n")# 3.关闭file.close()def my_write_list(file,lst):#1.打开文件f=open(file,'a','utf-8')# 2.操作文件f.writeline(lst)#3.关闭f.close()if __name__=='__main__':# my_write('伟大的中国梦')# my_write('北京欢迎你')# 准备数据lst=['姓名\t','年龄\t','成绩\n','张三\t','98']
4.2 文件的读取操作及文件复制
4.2.1 文件的读取操作
from fileinput import filenamedef my_write(s):# 1.打开(创建)文件file=open(filename,'w+',encoding='utf-8')# 2.操作file.write('你好') # 写入完成,文件的指针在最后# seek 修改文件指针的位置file.seek(0)# 读取# s=file.read() #读取全部# s=file.read(2) 你好 2是指两个字符# s=file.readline() 读取一行数据# s=file.readline(2) 读取一行数据的2个字符s=file.readlines() #读取所有,一行为列表中的一个元素,s是列表类型#读取“好啊”file.seek(3)# 3个字节,一个中文占3个字节,utf-8s=file.read() #读取全部print(type(s),s)# 3.关闭file.close()
if __name__=='__main__':4.2.1 文件复制
def copy(scr,new_path):# 文件的复制就是边读边写file1=open(src,'rb')# 1.打开源文件file2=open(new_path,'wb')# 2.打开目标文件file2.write(file1.read())# 3.开始复制,边读边写s=file2.read()# 源文件读取所有file2.close()# 向目标文件写入所有#4.关闭file2.close()file1.close() # 先打开的后关,后打开的先关if __name__=='__main__':src='./google.jpg' #.代表的是当前目录new_path='../chap2/copy_google.jpg' #..表示上级目录,相当于windows后退copy(src,new_path)print('文件复制完毕')4.3 with语句的使用

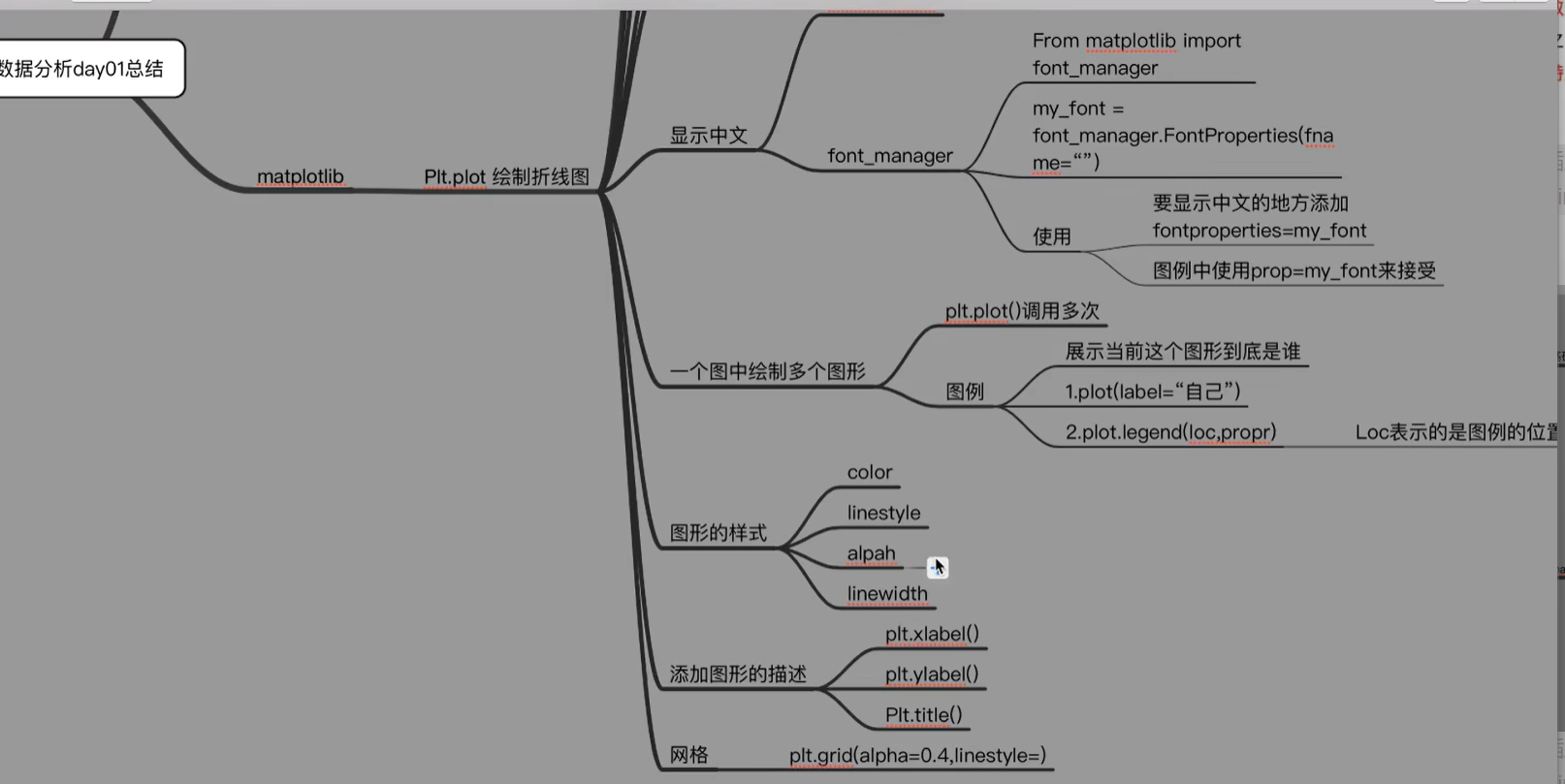
一.数据的分析介绍

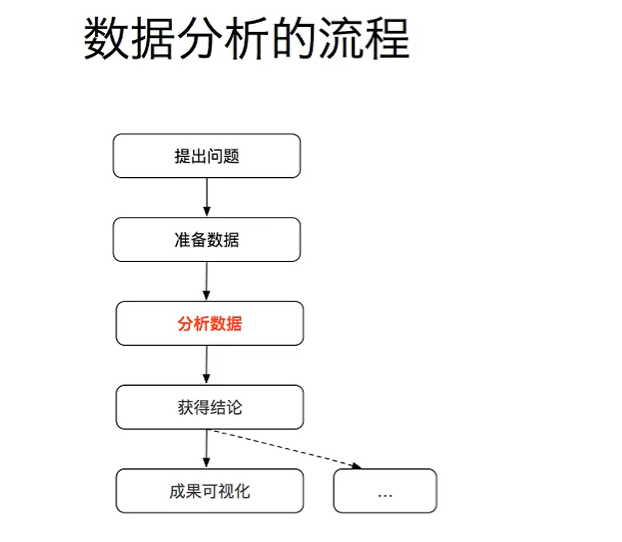
1. matplotlib的基础画图:将数据可视化
axis轴指的是x或y这种坐标轴

from matplotlib import pyplot as plt
x=range(2,26,2)
y=range(2,26,2)
#绘图
plt.plot(x,y)
# 展示图形
plt.show()

2. matplotlib的基础画图

from matplotlib import pyplot as plt
x=range(2,26,2)
y=[15,13,12,11,10,9,8,7,22,24,25,26]
# 设置图片大小
plt.figure(figsize=(20,8),dpi=80)
#绘图
plt.plot(x,y)
# 保存
plt.savefig('./t1.png')
# 展示图形
plt.show()
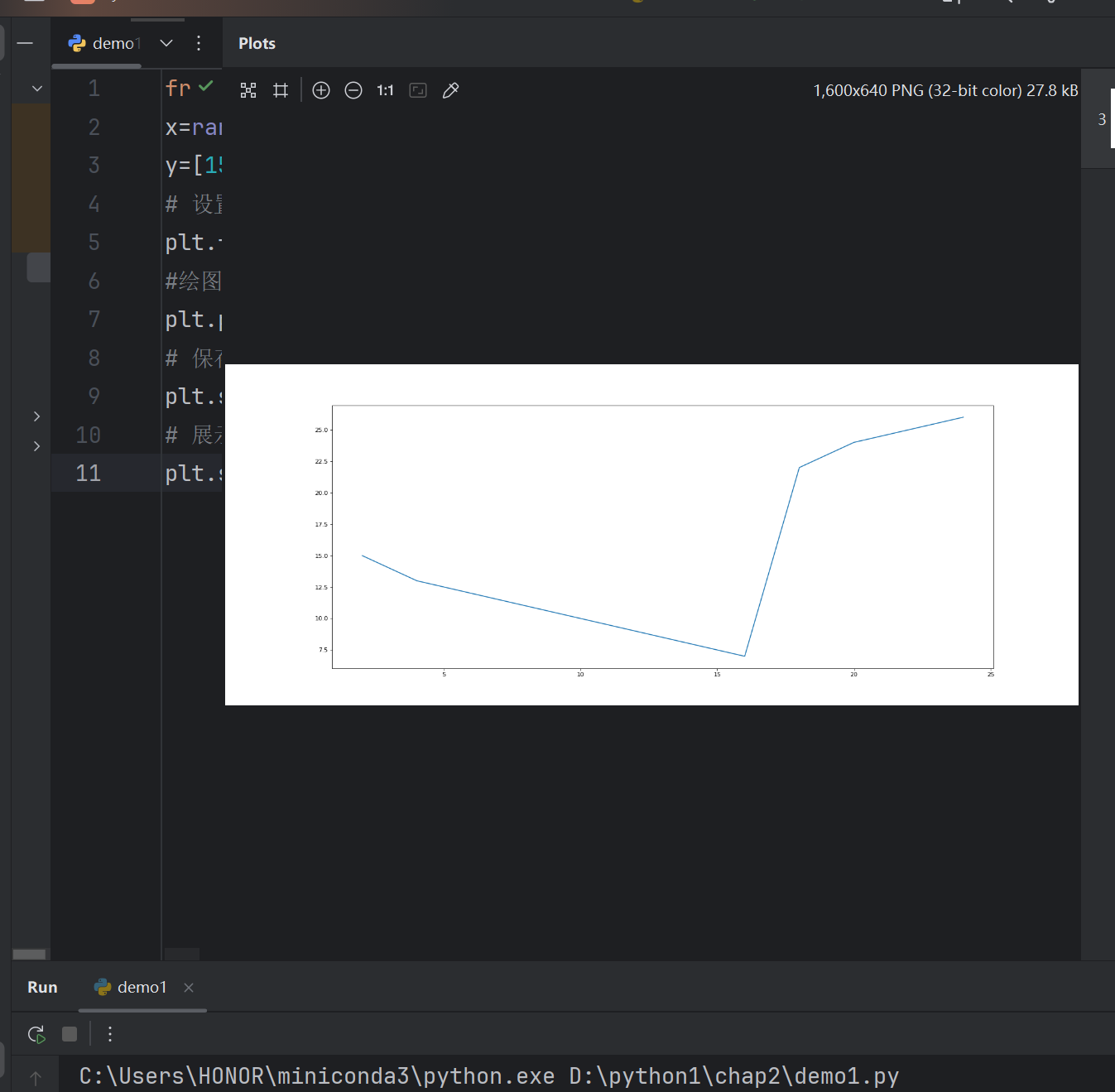
from matplotlib import pyplot as plt
x=range(2,26,2)
y=[15,13,12,11,10,9,8,7,22,24,25,26]
# 设置图片大小
plt.figure(figsize=(20,8),dpi=80)
#绘图
plt.plot(x,y)#设置x轴的刻度
_xtick_labels=[i/2 for i in range(2,49)]
plt.xticks(_xtick_labels)
plt.yticks(range(min(y),max(y)+1))
# 保存
plt.savefig('./t1.png')
# 展示图形
plt.show()
3. 调整X或者Y轴上的刻度,显示字符串,并显示中文

# coding=utf-8
from matplotlib import pyplot as plt
import randomx= range(0,120)
y= [random.randint(20,35) for i in range(120)]plt.plot(x,y)#调整x轴的刻度
_x=x
_xtick_labels=["hello,{}".format(i) for i in _x]
plt.xticks(_x,_xtick_labels)
plt.show()
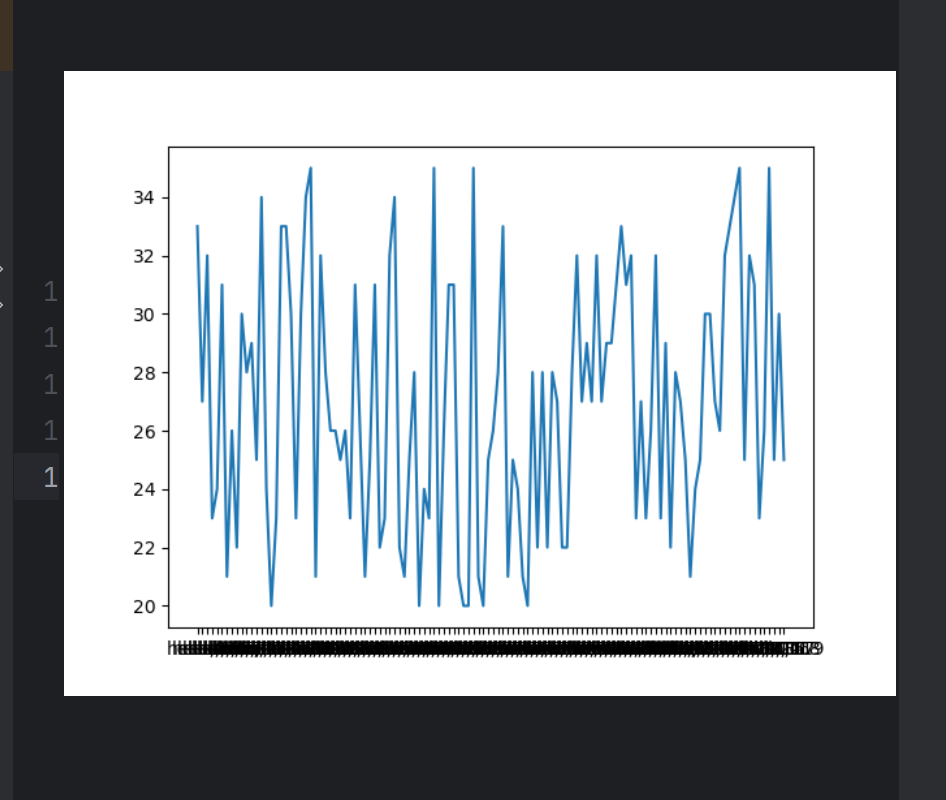
使字符串对应
# coding=utf-8
from matplotlib import pyplot as plt
import randomx= range(0,120)
y= [random.randint(20,35) for i in range(120)]plt.plot(x,y)#调整x轴的刻度
_x=list(x)[::10]
_xtick_labels=["10点{}分".format(i) for i in range(60)]
_xtick_labels+=["11点{}分".format(i) for i in range(60)]
plt.xticks(list(x)[::3],_xtick_labels[::3],rotation=90)# 取步长,数字与字符串一一对应,数据的长度一样,只有列表能够取步长
# rotation旋转90度
plt.show()
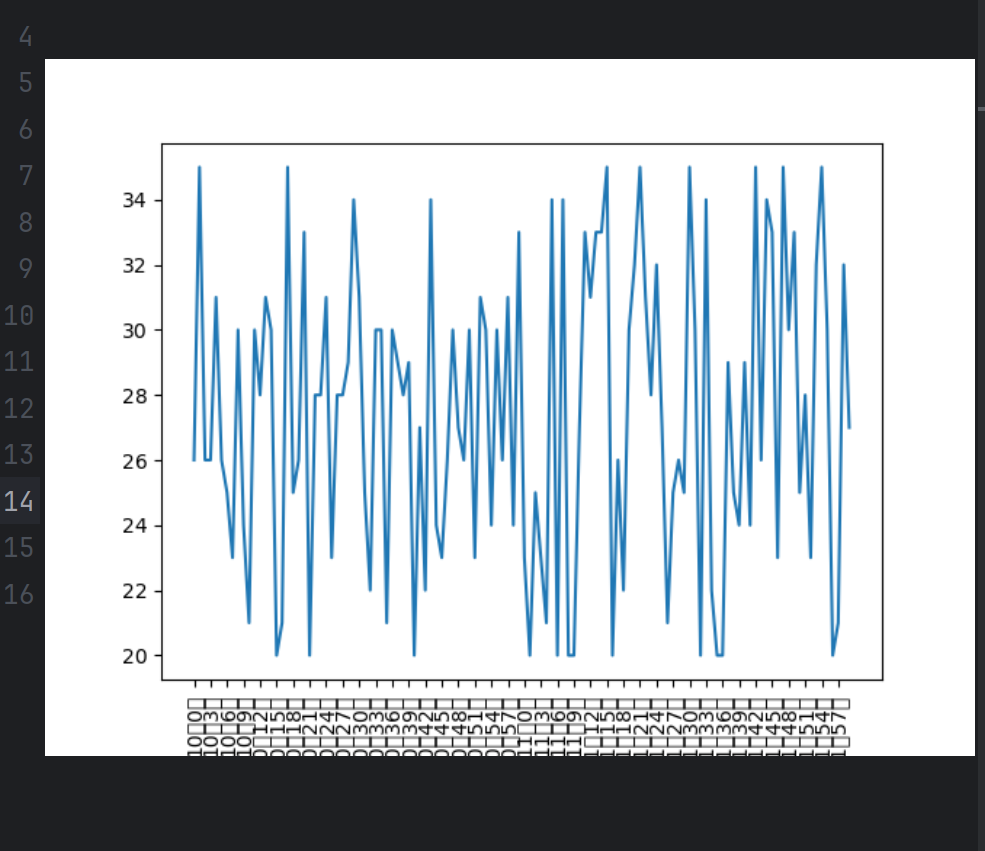

# coding=utf-8
from matplotlib import pyplot as plt
import random
import matplotlib
#matplotlib.rc
#from matplotlib.backends.backend_qt5 import NavigationToolbar2QT
# font = {'family': 'monospace',
# 'weight': 'bold',
# 'size': 'larger'}
x= range(0,120)
y= [random.randint(20,35) for i in range(120)]plt.plot(x,y)#调整x轴的刻度
_x=list(x)[::10]
_xtick_labels=["10点{}分".format(i) for i in range(60)]
_xtick_labels+=["11点{}分".format(i) for i in range(60)]
plt.xticks(list(x)[::3],_xtick_labels[::3],rotation=90)# 取步长,数字与字符串一一对应,数据的长度一样,只有列表能够取步长
# rotation旋转90度
plt.show()
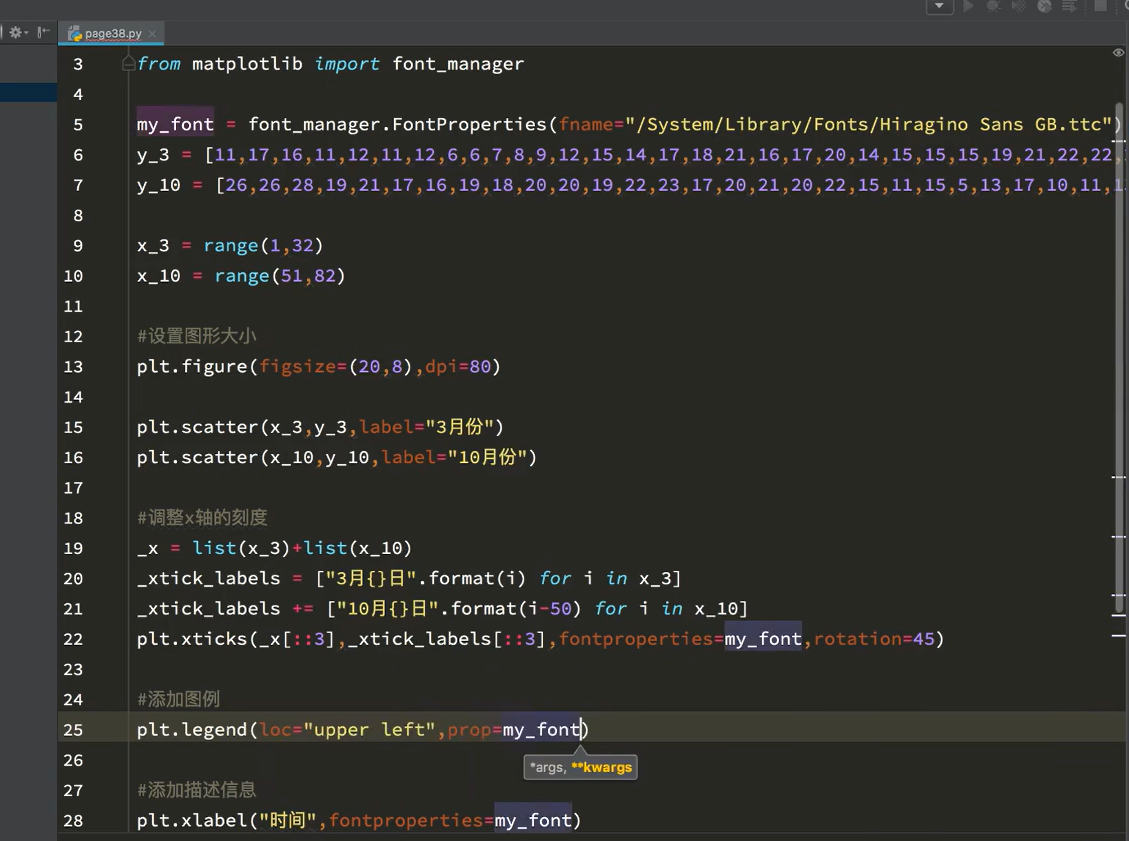
# coding=utf-8
from matplotlib import pyplot as plt, font_manager
import random
import matplotlib
#matplotlib.rc
#from matplotlib.backends.backend_qt5 import NavigationToolbar2QT
# font = {'family': 'monospace',
# 'weight': 'bold',
# 'size': 'larger'}# 另一种字体方式,实例化font_manager
my_font = font_manager.FontProperties(fname="",)# 系统中的字体大小x= range(0,120)
y= [random.randint(20,35) for i in range(120)]plt.plot(x,y)#调整x轴的刻度
_x=list(x)[::10]
_xtick_labels=["10点{}分".format(i) for i in range(60)]
_xtick_labels+=["11点{}分".format(i) for i in range(60)]
plt.xticks(list(x)[::3],_xtick_labels[::3],rotation=90,fontproperties=my_font)# 取步长,数字与字符串一一对应,数据的长度一样,只有列表能够取步长
# rotation旋转90度
plt.show()
4. 添加描述信息
# coding=utf-8
from matplotlib import pyplot as plt, font_manager
import random
import matplotlib
#matplotlib.rc
#from matplotlib.backends.backend_qt5 import NavigationToolbar2QT
# font = {'family': 'monospace',
# 'weight': 'bold',
# 'size': 'larger'}# 另一种字体方式,实例化font_manager
my_font = font_manager.FontProperties(fname="",)# 系统中的字体大小x= range(0,120)
y= [random.randint(20,35) for i in range(120)]plt.plot(x,y)#调整x轴的刻度
_x=list(x)[::10]
_xtick_labels=["10点{}分".format(i) for i in range(60)]
_xtick_labels+=["11点{}分".format(i) for i in range(60)]
plt.xticks(list(x)[::3],_xtick_labels[::3],rotation=90,fontproperties=my_font)# 取步长,数字与字符串一一对应,数据的长度一样,只有列表能够取步长
# rotation旋转90度
plt.show()# 添加描述信息
plt.xlabel("时间",fontproperties=my_font)
plt.ylabel("温度 单位(C)",fontproperties=my_font)
plt.title("10点12点每分钟气温变化情况")plt.show()
5. mat绘制多次图像
# coding=utf-8
from matplotlib import pyplot as plt, font_manager
import randommy_font=font_manager.FontProperties("")
x=range(11,30)
y=range[1,0,1,1,2,4,3,2,2,4,5,3,1,1,2,3]# 设置图形大小
plt.figure(figsize=(20,8),dpi=80)
plt.plot(x,y)# 设置x轴刻度
_xtick_labels=["{}岁".format(i) for i in x]
plt.xticks(x,_xtick_labels,fontproperties=my_font)#绘制网格
plt.grid()
# 展示
plt.show()


# coding=utf-8
from matplotlib import pyplot as plt, font_manager
import randomfrom matplotlib.lines import lineStylesmy_font=font_manager.FontProperties("")
x=range(11,30)
y_1=[1,0,1,1,2,4,3,2,2,4,5,3,1,1,2,3]
y_2=[1,0,2,2,0,0,1,2,1,3,2,1,0,0,0,0]# 设置图形大小
plt.figure(figsize=(20,8),dpi=80)
plt.plot(x,y_1,label='自己',lineStyle=':')# 设置label参数
plt.plot(x,y_2,label='同桌',linestyle='-.')# 设置x轴刻度
_xtick_labels=["{}岁".format(i) for i in x]
plt.xticks(x,_xtick_labels,fontproperties=my_font)#绘制网格
plt.grid(alpha=0.3)#添加图例
plt.legend(prop=my_font,loc='upper left')# 图例在左上角
# 展示
plt.show()

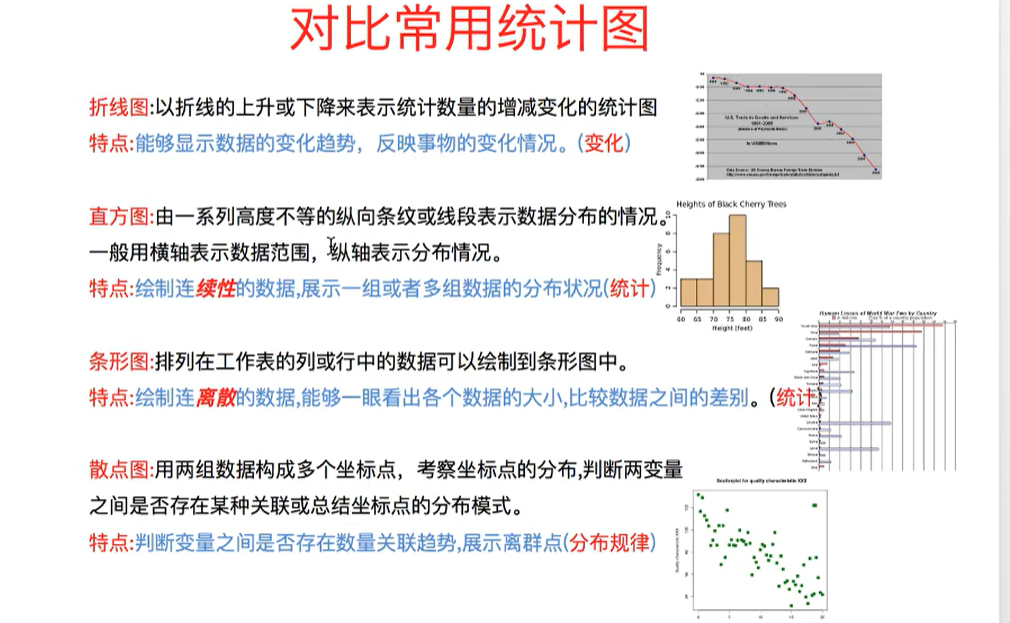

6.1绘制散点图
# coding=utf-8
from matplotlib import pyplot as plt, font_manager
from matplotlib.font_manager import fontManagery_3 =[11,23,15,17,18]
y_10=[26,25,24,27,22]x_3=range(1,6)
x_10=range(1,6)# 设置图形大小
plt.figure(figsize=(20,8),dpi=80)
plt.scatter(x_3,y_3)
plt.scatter(x_10,y_10)# 调整x轴的刻度
_x=list(x_3)+list(x_10)
_xtick_labels=["3月{}日".format(i) for i in x_3]
_xtick_labels+=["10月{}日".format(i-50) for i in x_10]
plt.xticks(x_3,_xtick_labels)
#展示
plt.show()
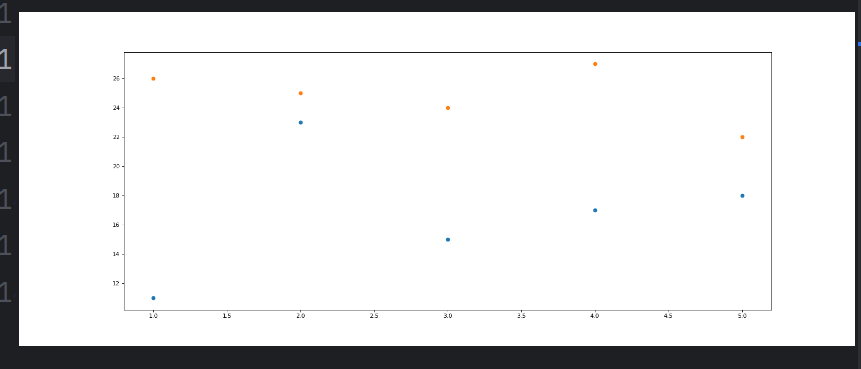
6.2 绘制条形图

from matplotlib import pyplot as plt
from matplotlib.figure import Figure
from matplotlib.font_manager import FontPropertiesa=["星球崛起:终极之战","尔克","蜘蛛侠:英雄归来","战狼"]
b_16=[15555,322,2222,111]
b_15=[12345,156,2045,168]
b_14=[2343,333,2455,234]bar_width=0.5
x_14=list(range(0,len(a)))
x_15=[i*bar_width for i in x_14]
x_16=[i*bar_width*2 for i in x_14]# 设置图形大小
plt.figure(figsize=(12,8),dpi=80)
plt.bar(range(len(a)),b_14,width=bar_width,label="9月14日")
plt.bar(x_15,b_15,bar_width,label="9月15日")
plt.bar(x_16,b_16,bar_width,label="9月16日")#设置图例
plt.legend(prop={'size':10})
# 设置x轴刻度
plt.xticks(x_15,a)
plt.show()
字体中文未设置
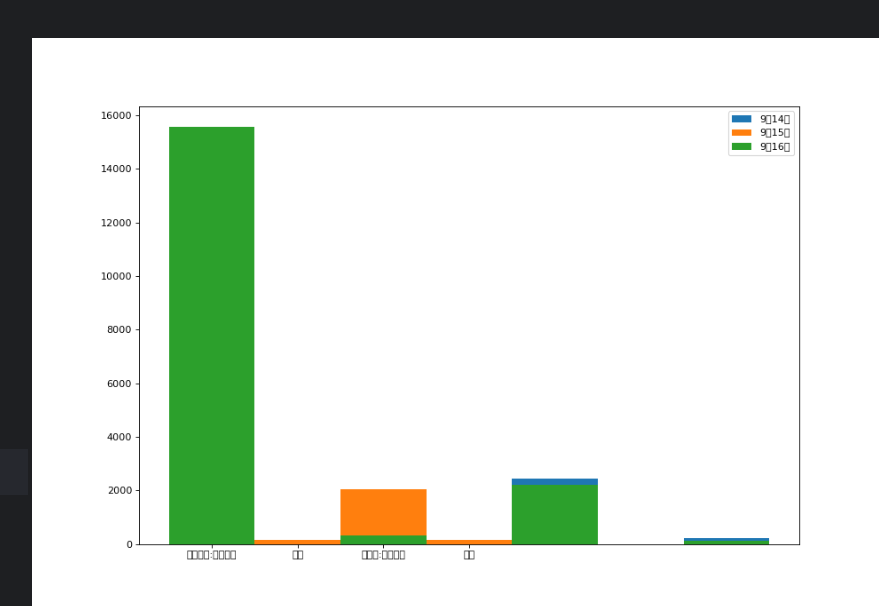
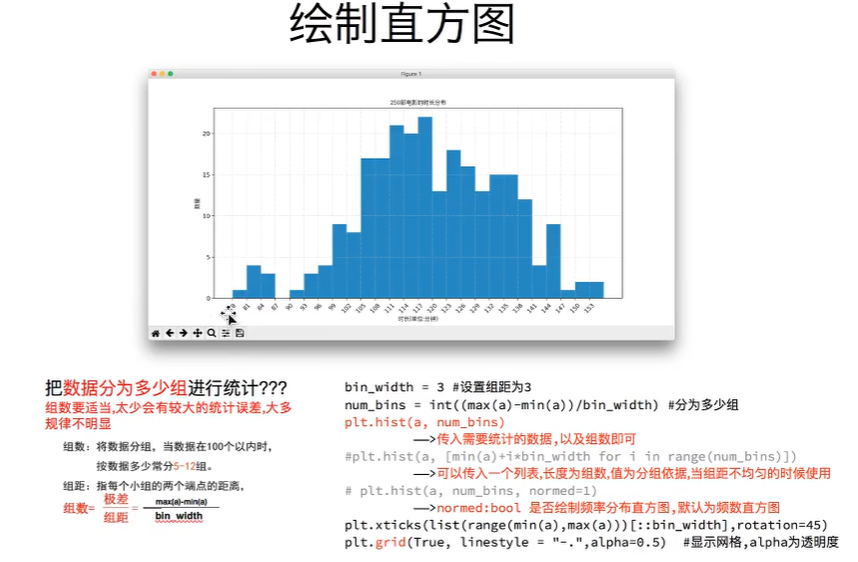
组数=极差/组距
将其分为20组
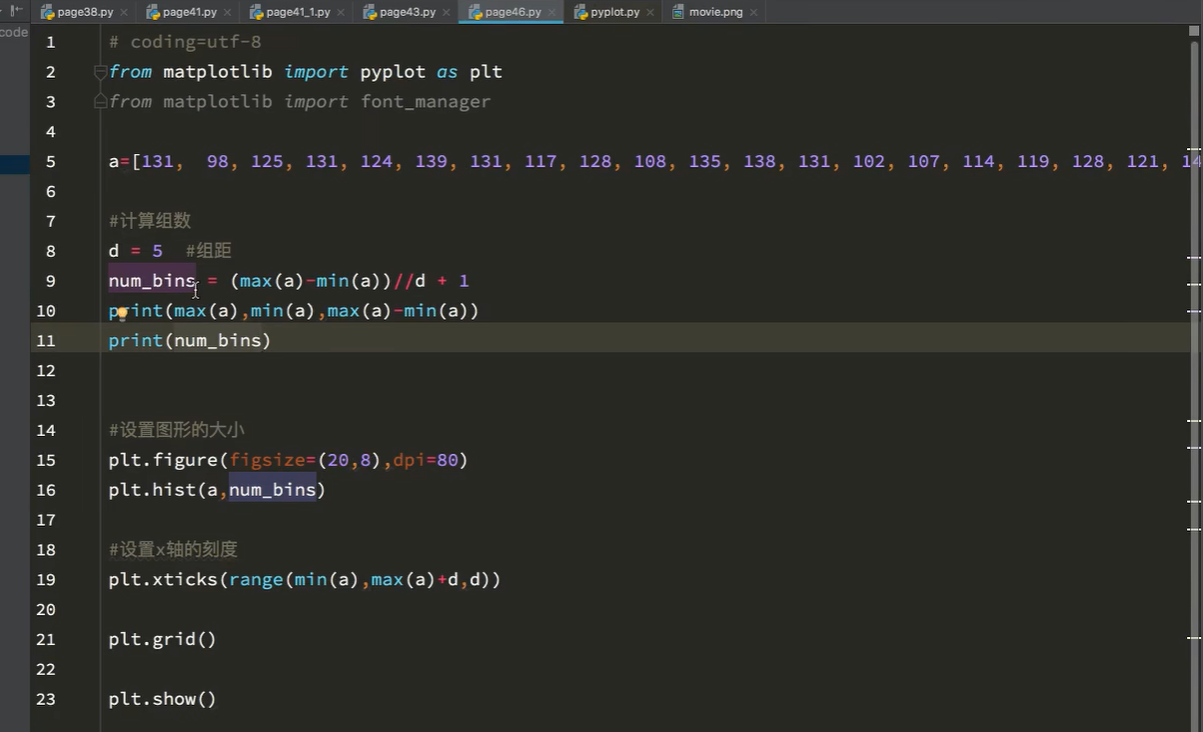
7 numpy学习



7.1 numpy数组的创建
# coding=utf-8
import numpy as np
# 使用numpy生成数组
t1=np.array([1,2,3,])
print(t1)
print(type(t1))t2= np.array(range(10))
print(t2)t3=np.arange(4,10,2)
print(t3)
print(t3.dtype)t4=np.array(range(1,4),dtype="i1")
print(t4)
print(t4.dtype)# numpy中的bool类型
t5=np.array([1,1,0,1,0,0],dtype=bool)
print(t5.dtype)# 调整数据类型
t6= t5.astype("int8")
print(t6)
print(t6.dtype)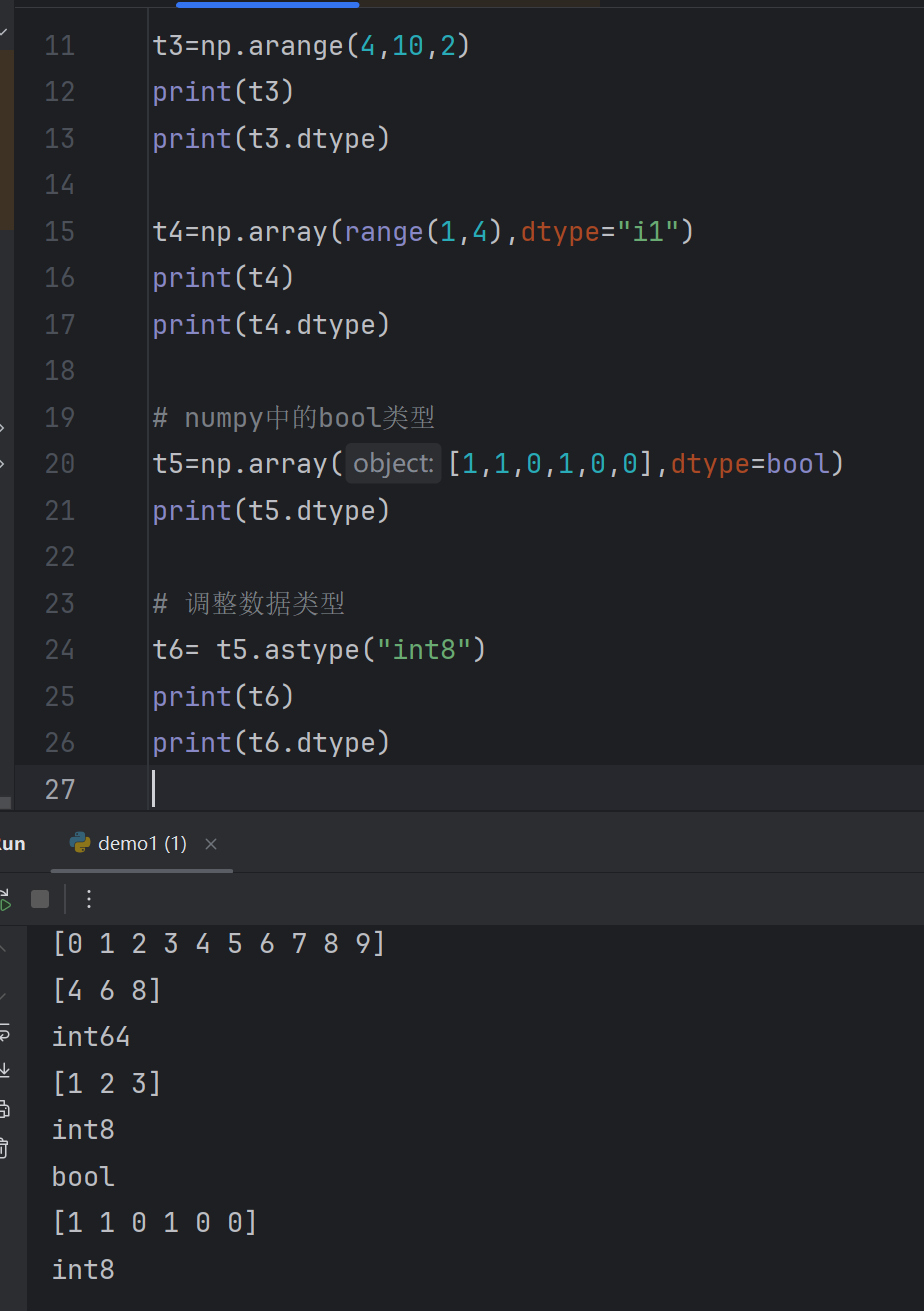

# coding=utf-8
import random
import numpy as np
# 使用numpy生成数组
t1=np.array([1,2,3,])
print(t1)
print(type(t1))t2= np.array(range(10))
print(t2)t3=np.arange(4,10,2)
print(t3)
print(t3.dtype)t4=np.array(range(1,4),dtype="i1")
print(t4)
print(t4.dtype)# numpy中的bool类型
t5=np.array([1,1,0,1,0,0],dtype=bool)
print(t5.dtype)# 调整数据类型
t6= t5.astype("int8")
print(t6)
print(t6.dtype)t7=np.array([random.random() for i in range(10)])
print(t7)
print(t7.dtype)
t8=np.round(t7,2)
print(t8)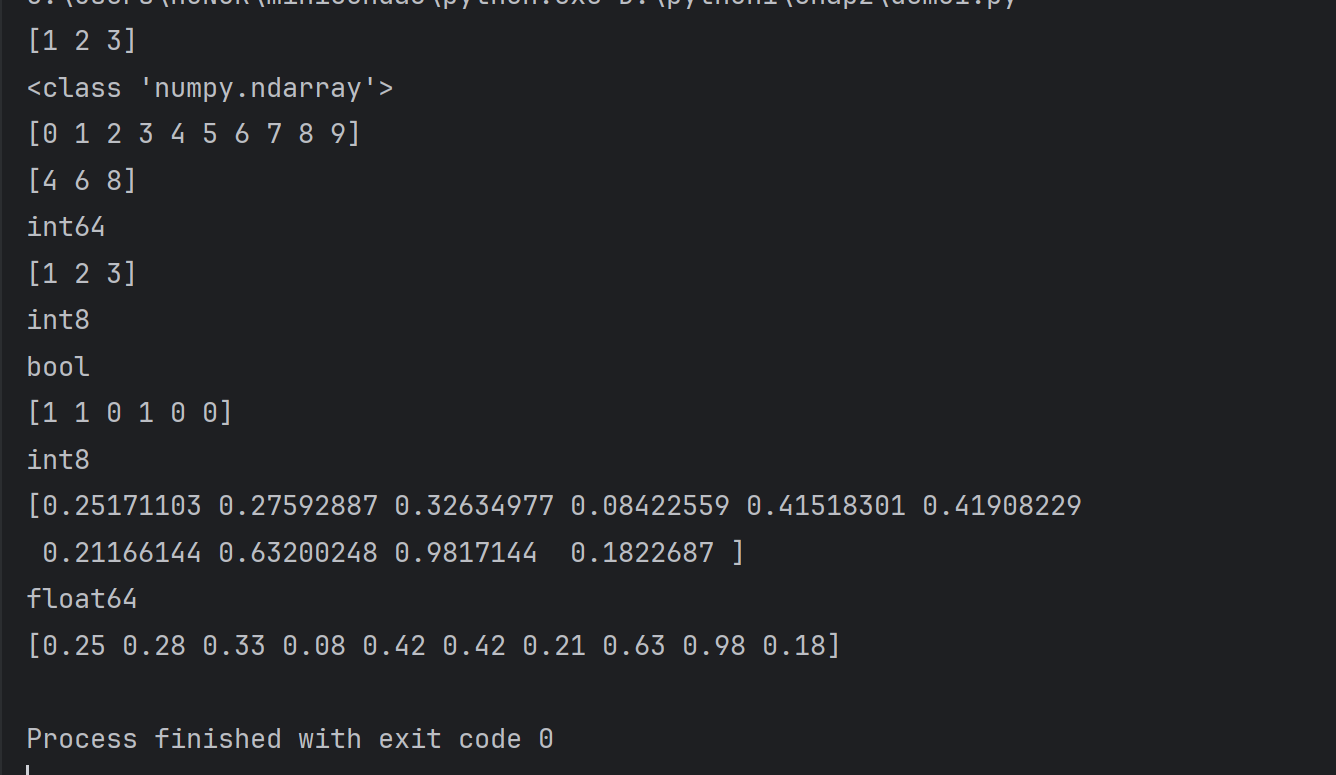
7.2 数组的计算
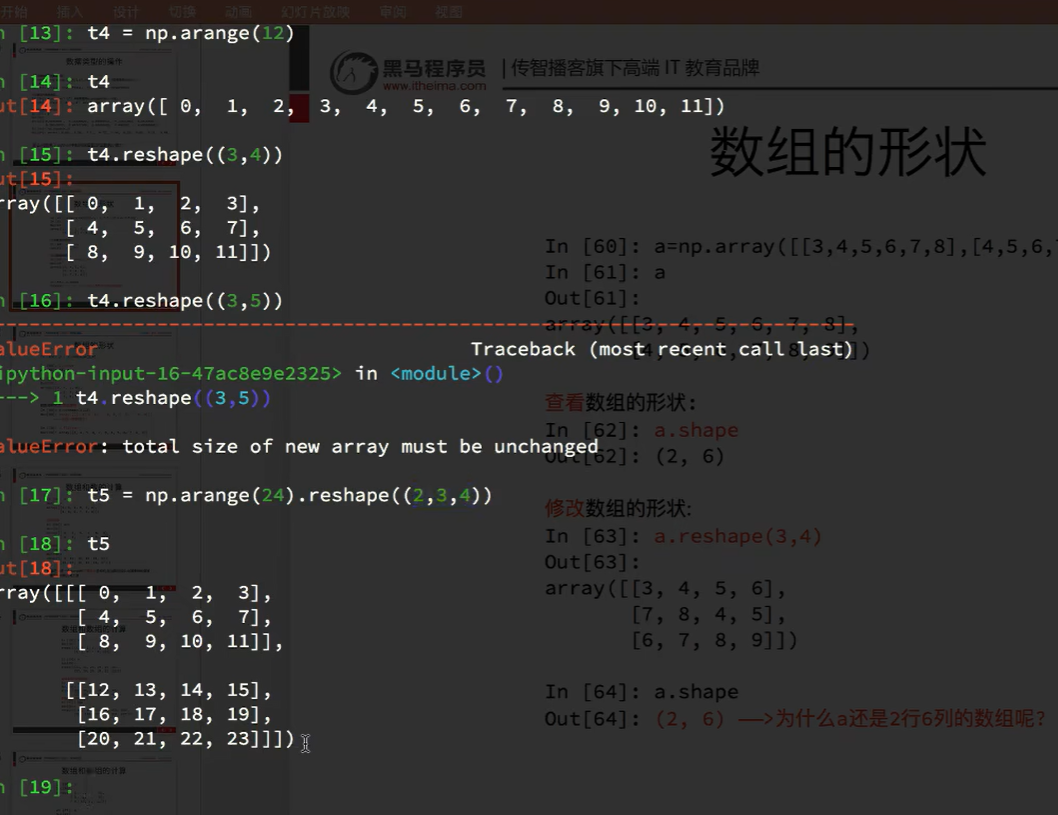
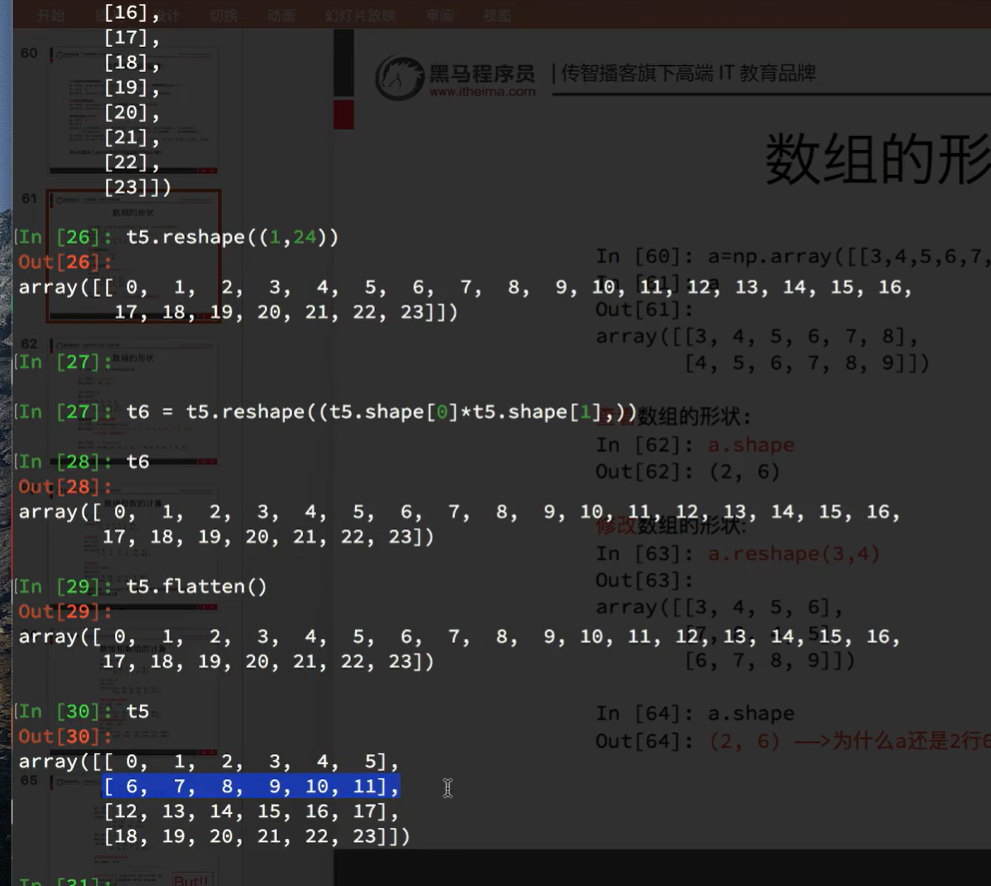

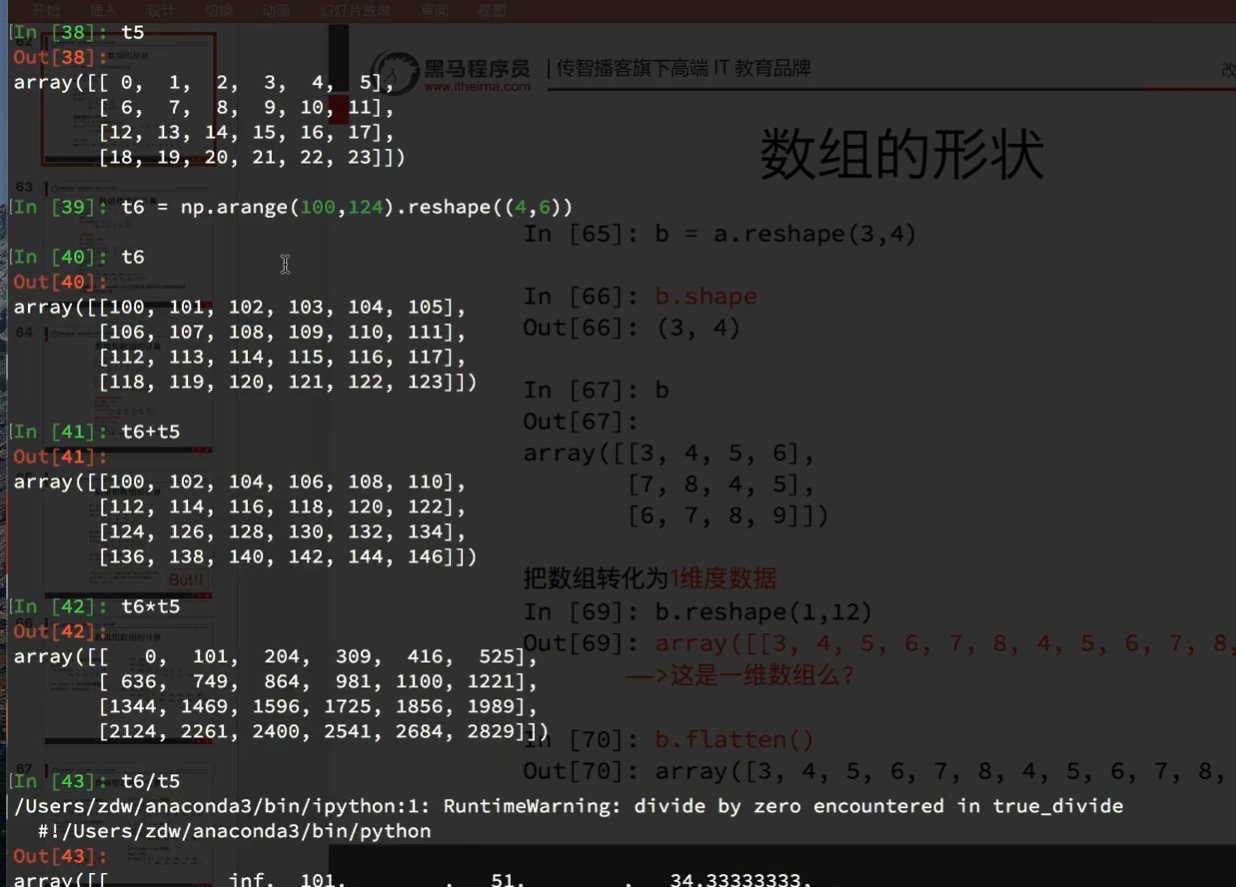
如果不是相同的形状的数组也可以运算


3块三行三列的三维和一个二维无法计算
在某一方向相同即可进行计算
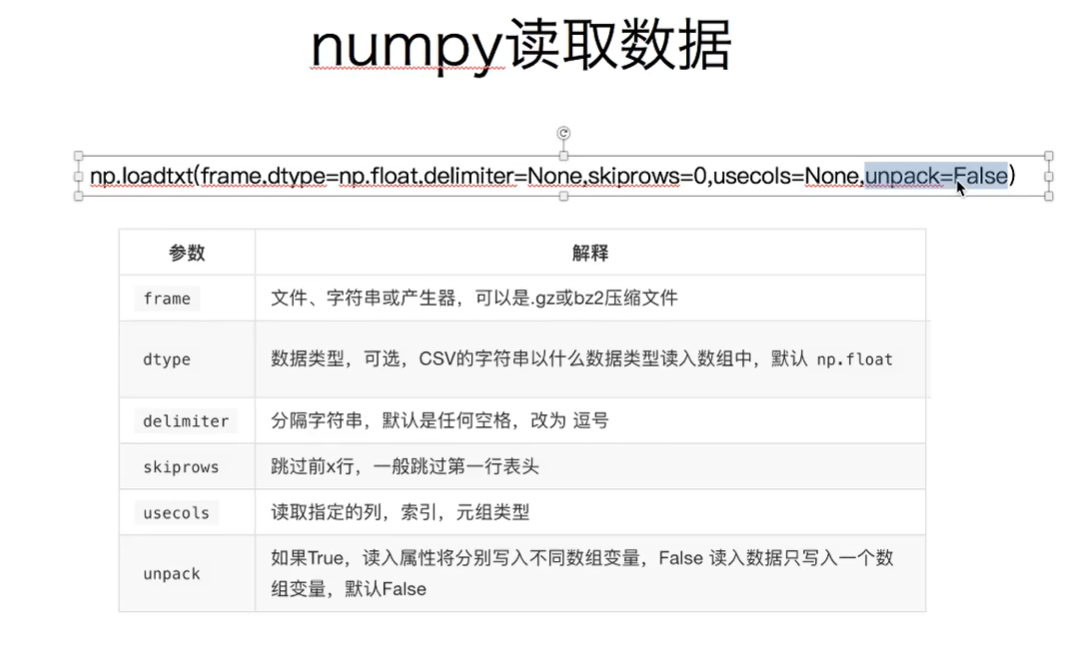
7.2 numpy读取本地数据

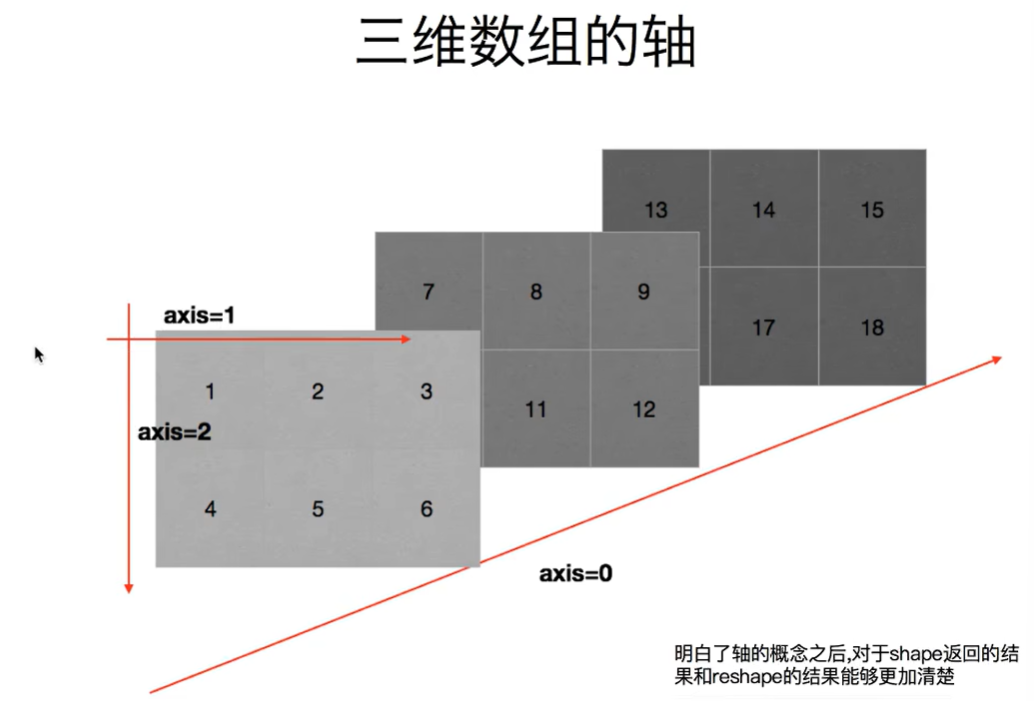
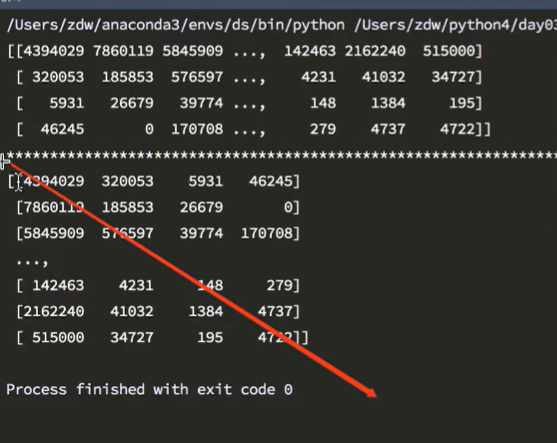
元组的第一个位置是0轴,第二个值是1轴


unpack转置




7.3 numpy索引
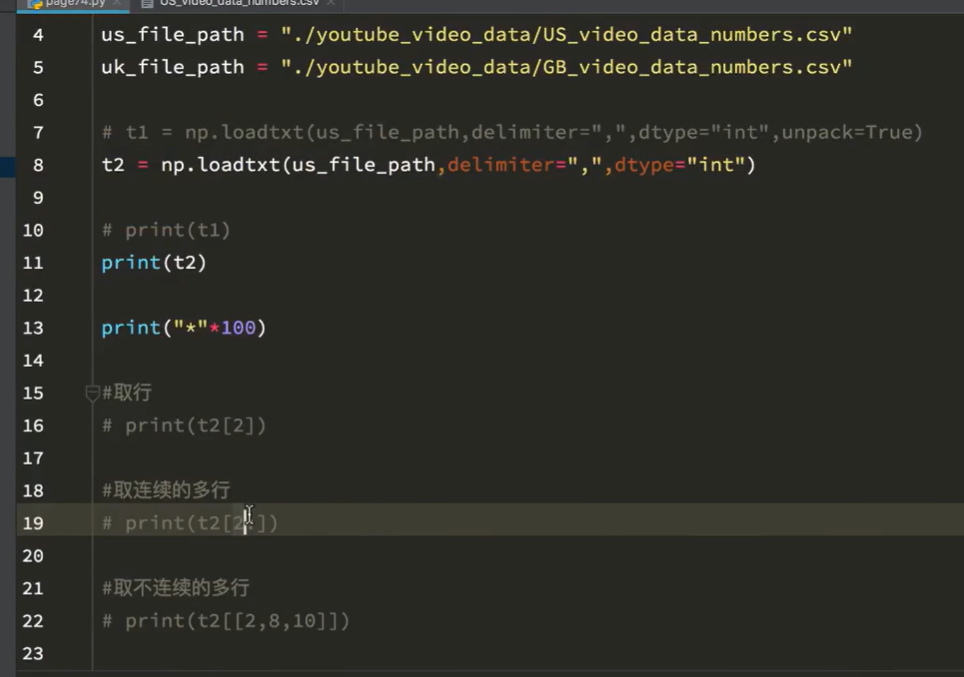
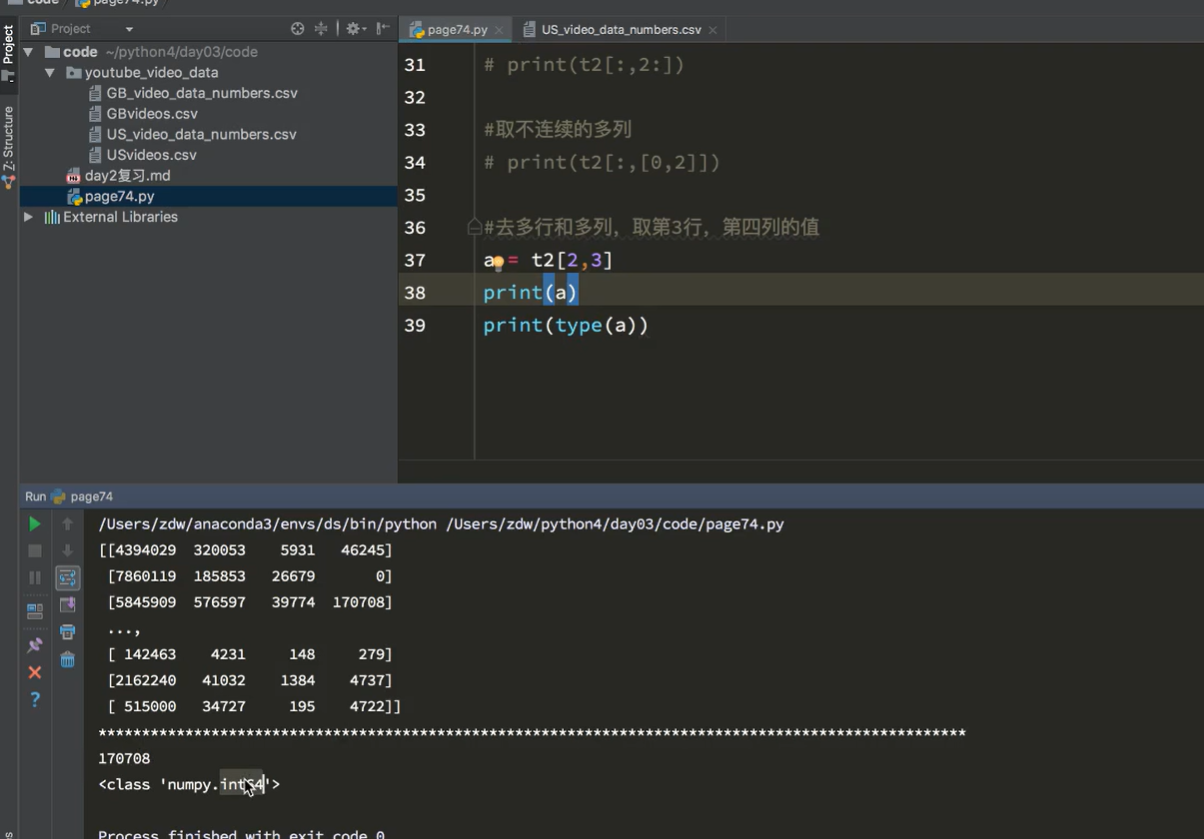
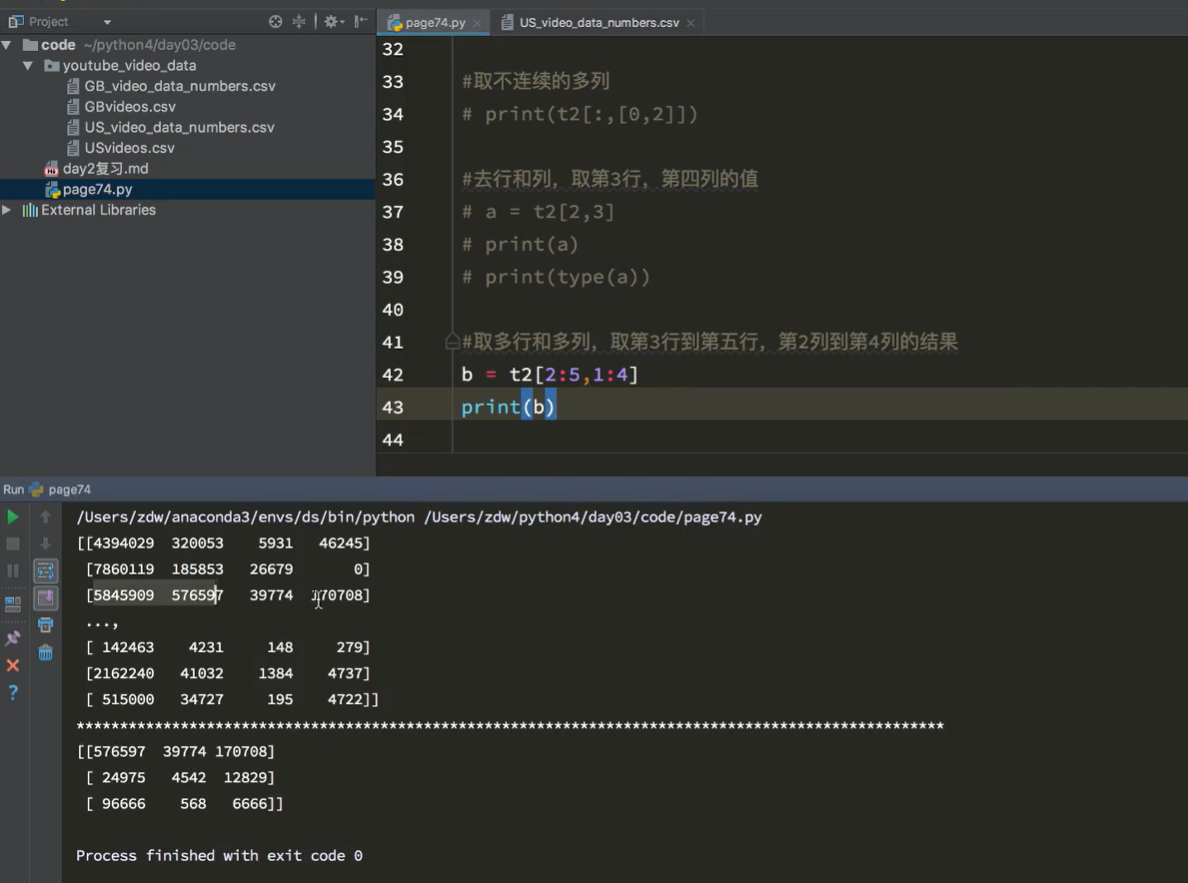
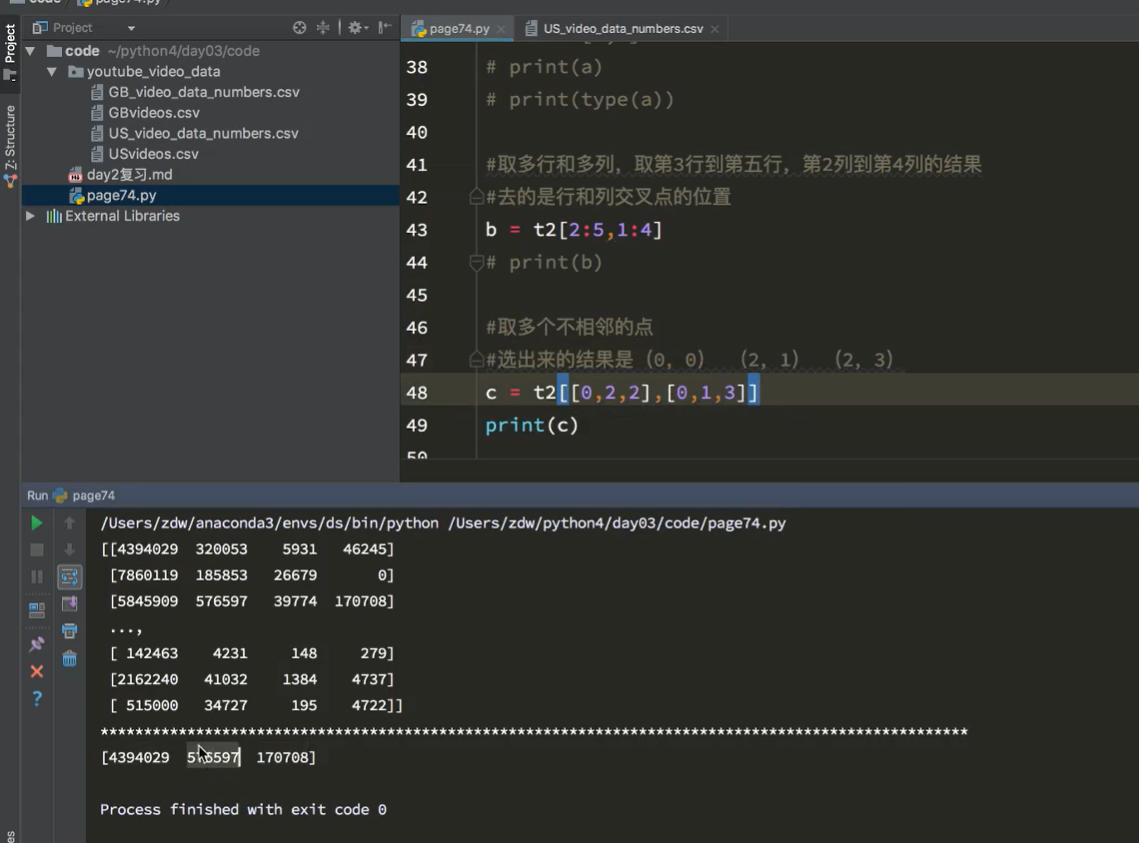
取交叉位置
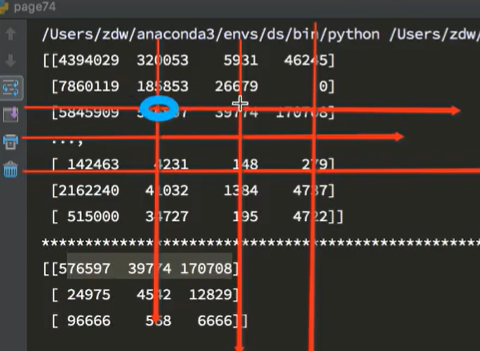
[0,0],[2,1],[2,3]
7.3 numpy索引方式
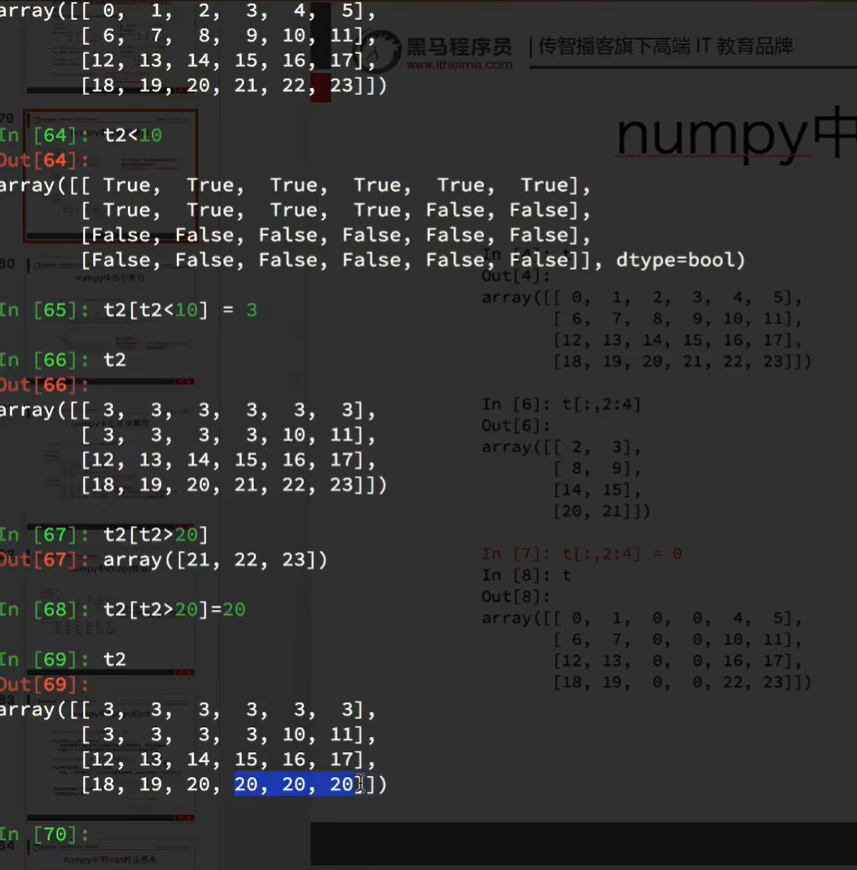
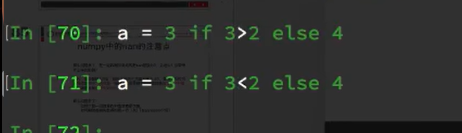

clip大于小于没有影响

nan是浮点型,要替换成int类型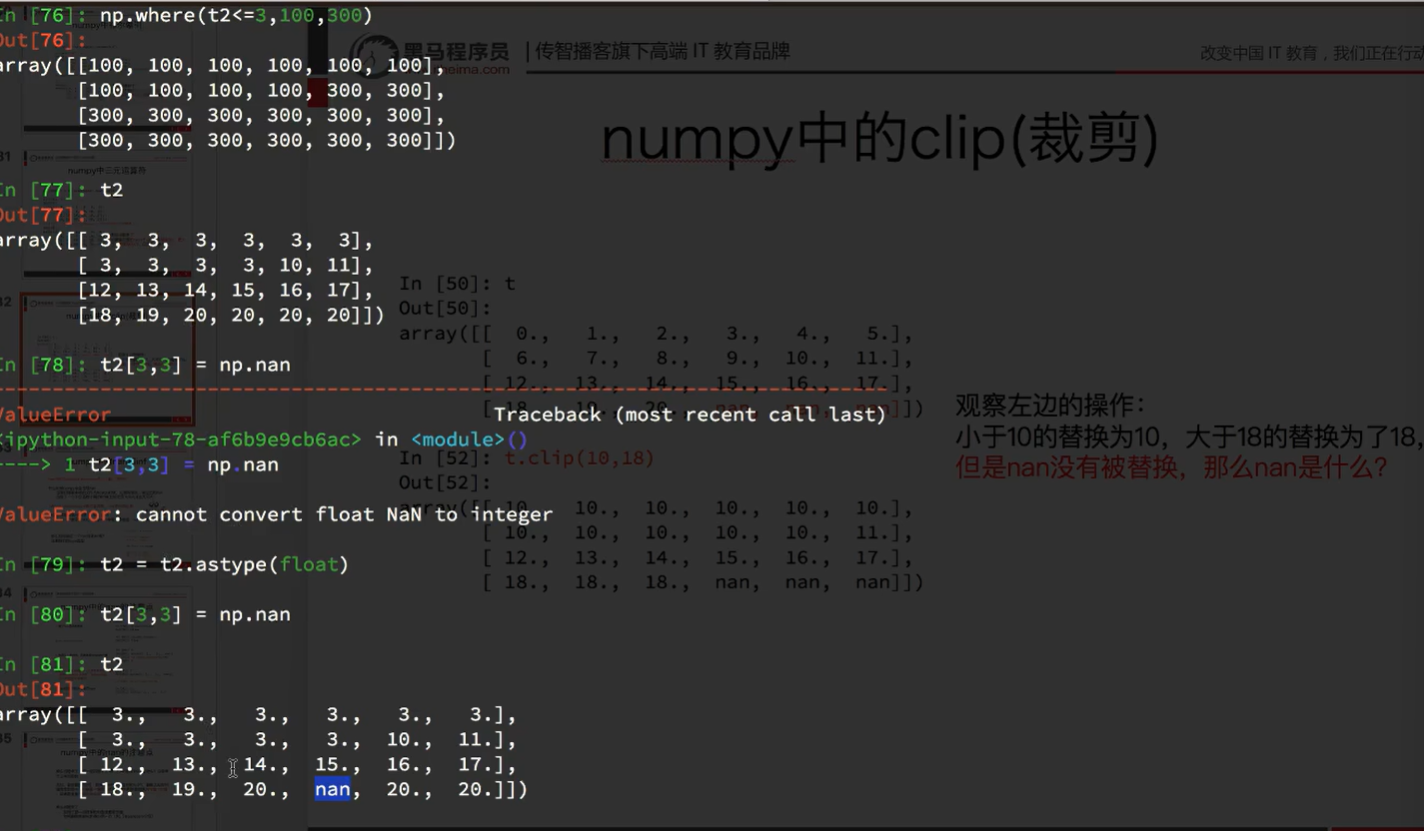
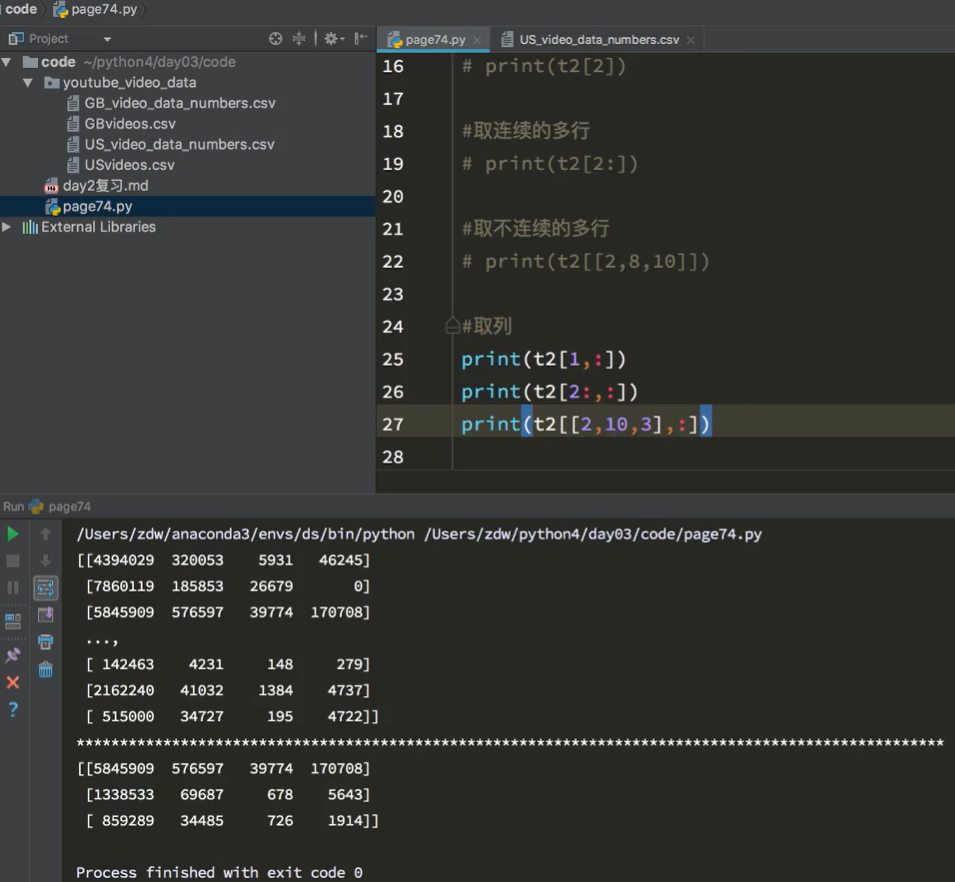
7.4 数组的索引
竖直分隔:画横线

交换数据的行列



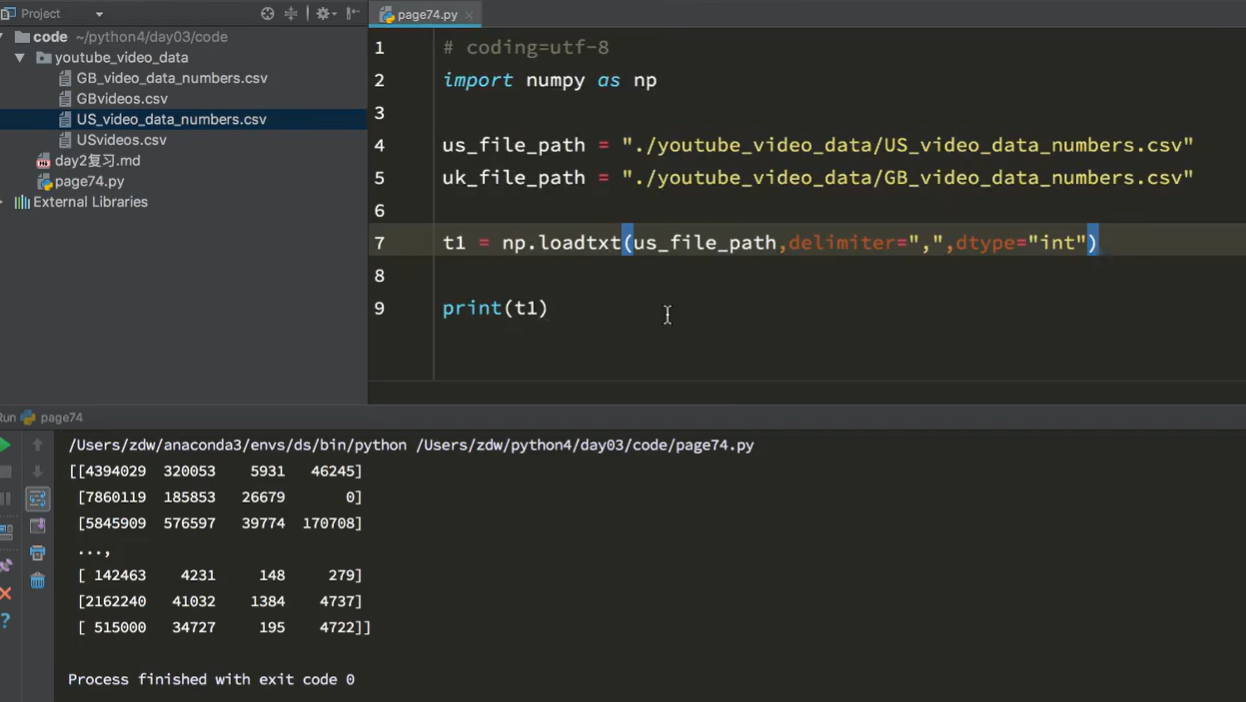
import numpy as npus_data=" "
uk_data=" "
# 加载国家数据
us_data=np.loadtxt(us_data,delimiter=",",dtype=float)
uk_data=np.loadtxt(uk_data,delimiter=",",dtype=float)# 添加国家信息
# 构造全为0的数据
zero_data=np.zeros((us_data.shape[0],1)).astype(int)#转换为int类型
ones_data=np.ones((us_data.shape[0],1)).astype(int)#分别添加一列0和1的数组
np.hstack((us_data,zero_data))#水平拼接
np.hstack((uk_data,ones_data))
#拼接两组数据
np.vstack((us_data,ones_data))
uk_data=np.hstack((us_data,ones_data))#拼接两组数据
final_data=np.vstack((us_data,uk_data))
print(final_data)


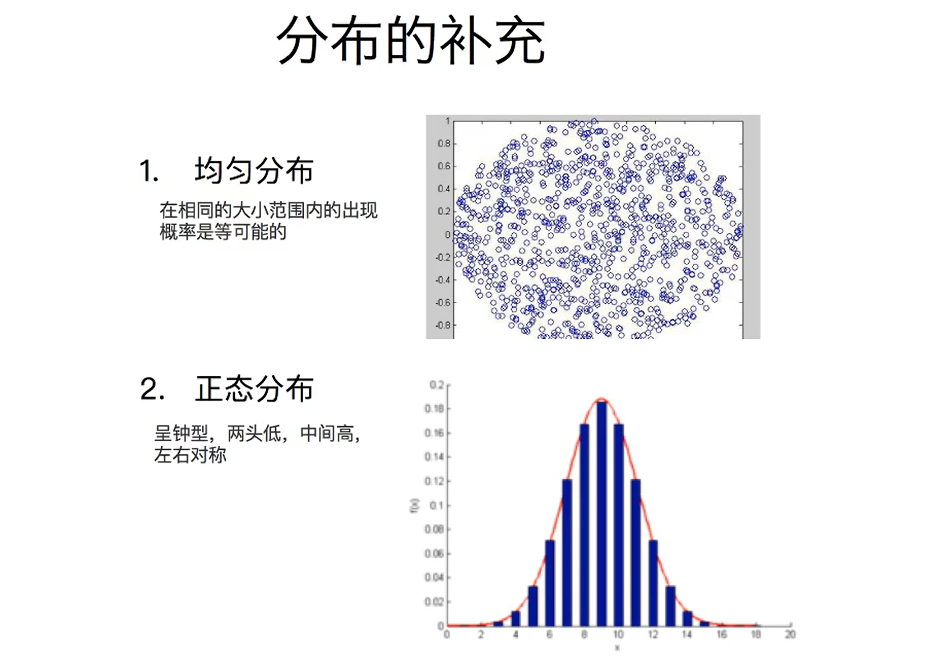
标准正态分布中心线在y轴,所以平均数为0

import numpy as np
np.random.seed(10)
t=np.random.randint((0,20,(3,4)))
print(t)

1、2相当于浅拷贝,如果啊a,b要不影响就要用copy(相当于深拷贝)
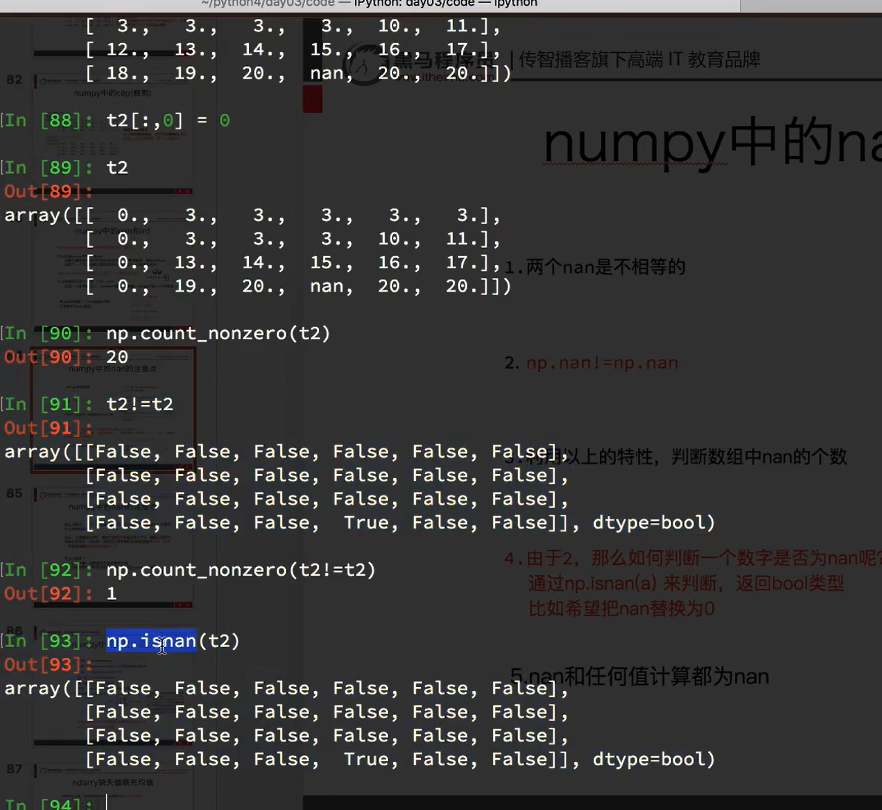
7.5 numpy中的nan和inf

nan,inf是浮点类型,nan表示不是数字的东西

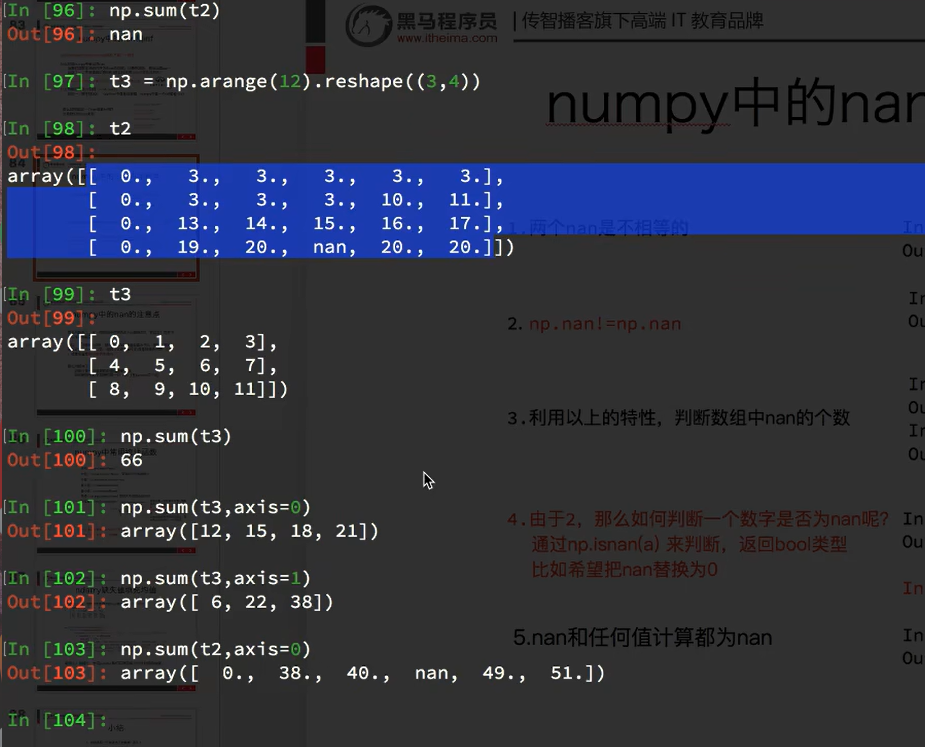
7.6 numpy中统计
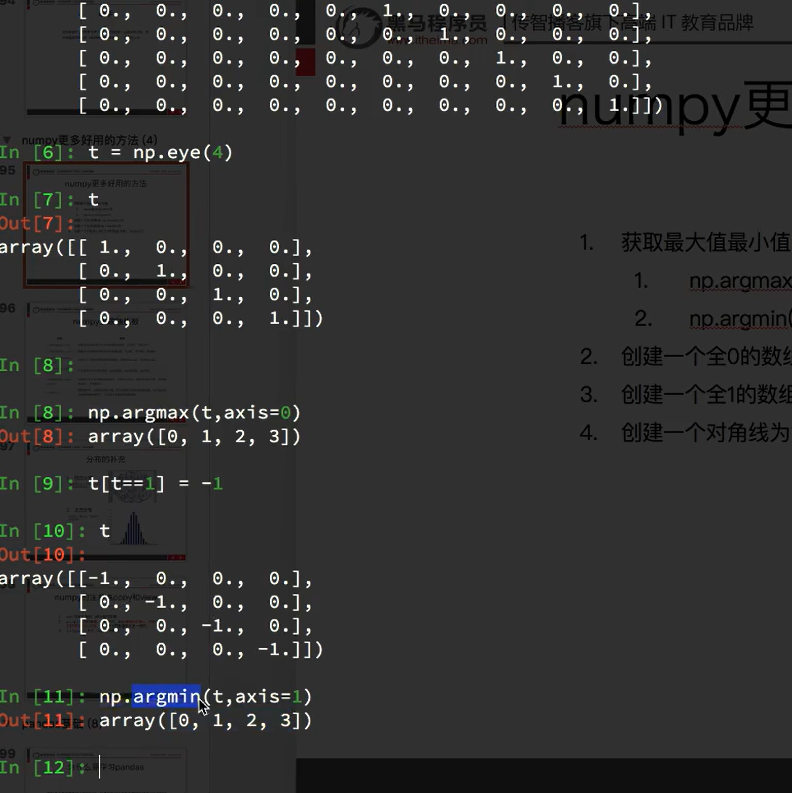
0是每一行对应列相加的行的结果,计算的是列的结果,和列的形状一样

mean是中值的意思
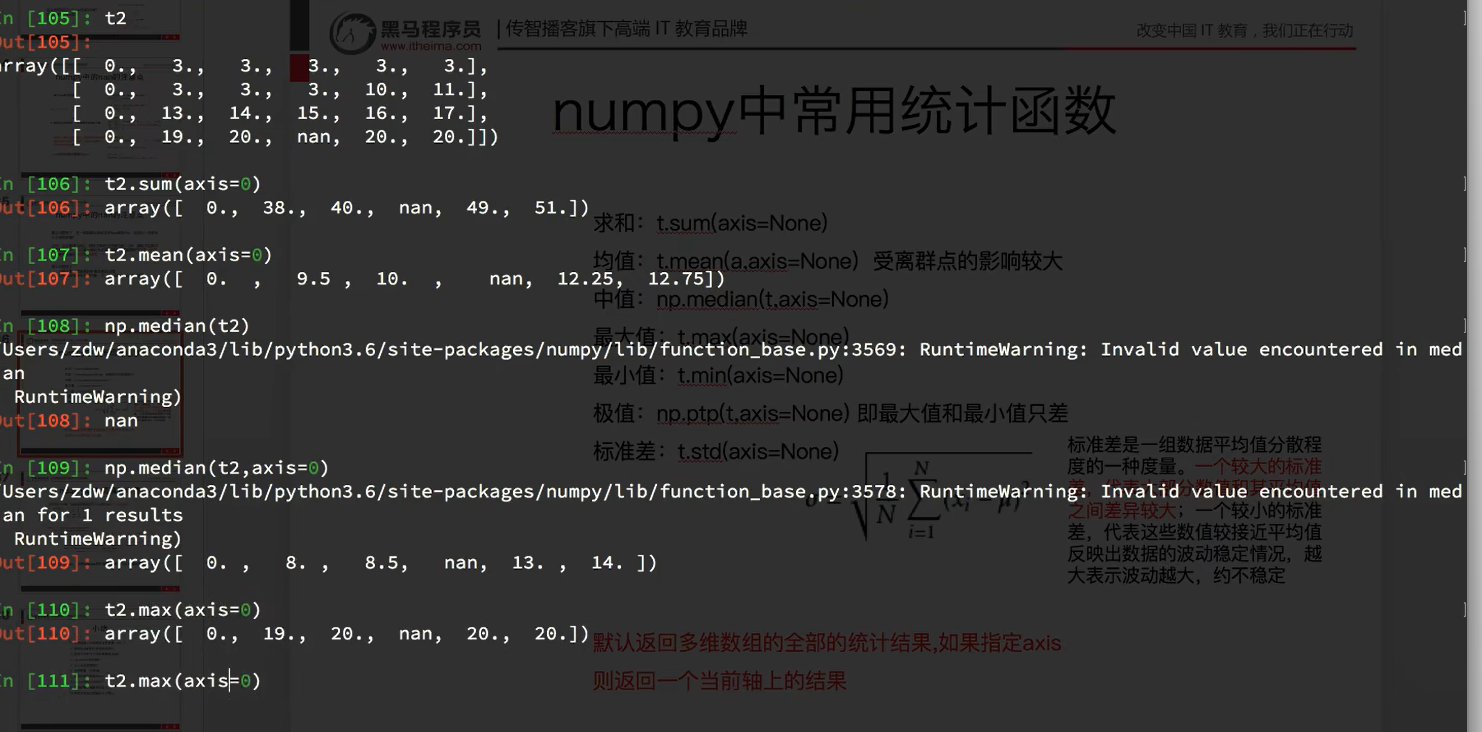

标准差比较大数据不稳定
7.7 numpy中nan和常用方法
导入不能以数字为开头
import numpy as npt1=np.arange(12).reshape(2,3).astype("float")
t1[1,2:]=np.nan
#print(t1)
def fill_ndarray(t1):for i in range(t1.shape[1]): # 遍历每一列temp_col = t1[:, i] # 当前的每一列nan_num = np.count_nonzero(temp_col != temp_col) # 统计nan的个数if nan_num != 0:temp_not_nan_col = temp_col[temp_col != temp_col] # 当前一列不为nan的arraytemp_not_nan_col.mean()# 选中当前nan的位置,把值赋值给不为nan的均值temp_col[np.isnan(temp_col)] = temp_not_nan_col.mean()return t1if __name__ == "__main__":# 调用t1 = np.arange(12).reshape(2,3).astype("float")t1[1,2:]=np.nanprint(t1)t1=fill_ndarray(t1)print(t1)
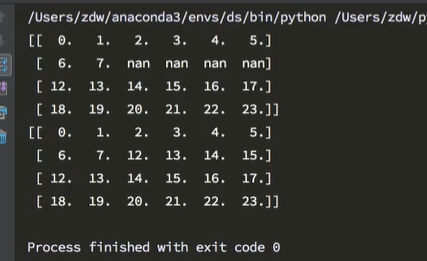
索引选一个值,切片选一部分
pandas的series

Series一维,带标签的数组。DataFrame二维,Series容器

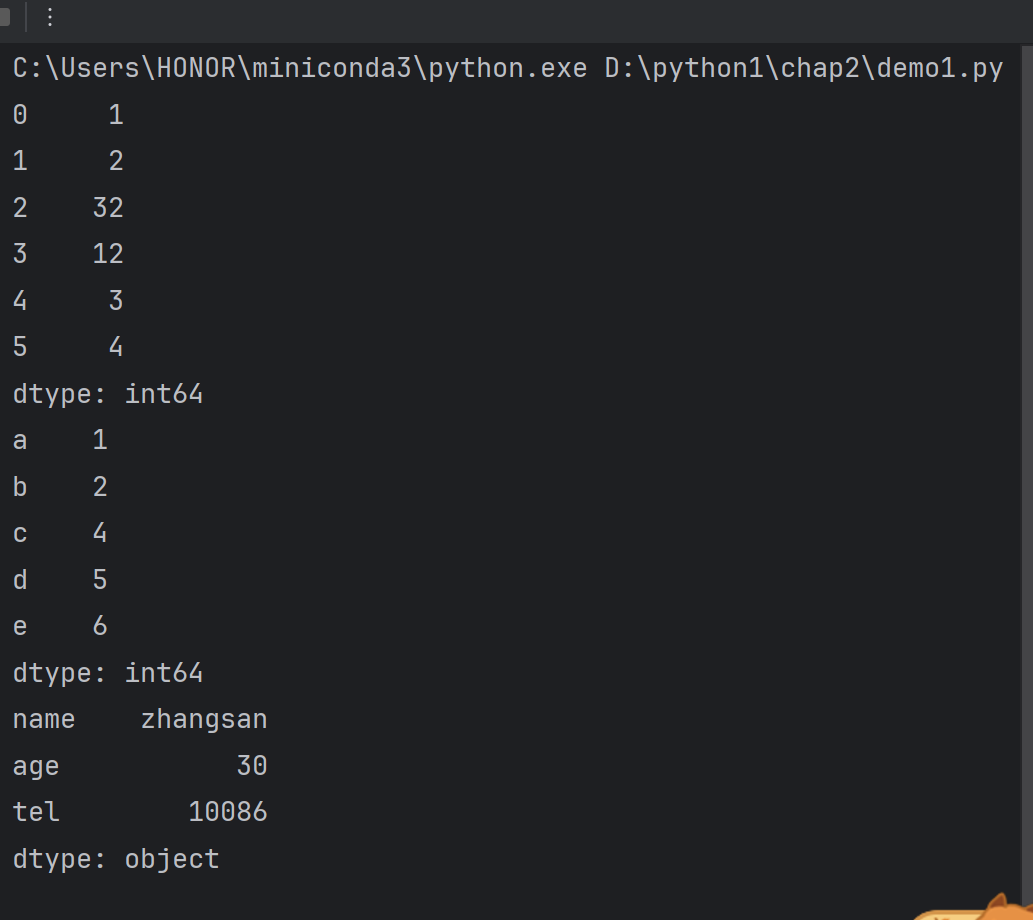
import pandas as pdprint(pd.Series([1,2,32,12,3,4]))
t2=pd.Series([1,2,4,5,6],index=list("abcde"))
print(t2)temp_dict={"name":"zhangsan","age":30,"tel":10086}
t3=pd.Series(temp_dict)
print(t3)
t2.astype(float)
print(t2)