spark的处理过程-转换算子和行动算子
(一)RDD的处理过程
【老师讲授,画图】
Spark使用Scala语言实现了RDD的API,程序开发者可以通过调用API对RDD进行操作处理。RDD的处理过程如图所示;
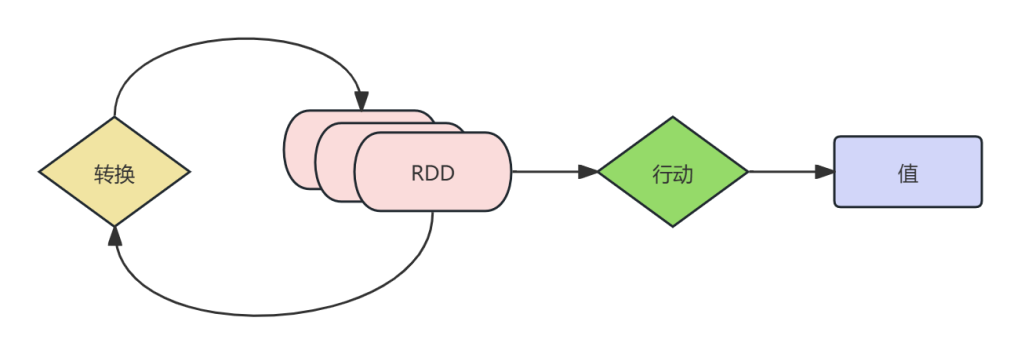
RDD经过一系列的“转换”操作,每一次转换都会产生不同的RDD,以供给下一次“转换”操作使用,直到最后一个RDD经过“行动”操作才会真正被计算处理。
这里有两点注意:【强调】
延迟。RDD中所有的转换都是延迟的,它们并不会直接计算结果。相反,他们只是记住这些应用到基础数据集上的转换动作。只有当发生要求返回结果给driver的动作时,这些转换才会真正运行。
血缘关系。一个RDD运算之后,会产生新的RDD。
(二)转换算子
转换算子用于对 RDD 进行转换操作,生成一个新的 RDD。转换操作是惰性的,即当调用转换算子时,Spark 并不会立即执行计算,而是记录下操作步骤,直到遇到行动算子时才会触发实际的计算。
从格式和用法上来看,它就是集合对象的方法。
以下是一些常见的转换算子:
1.map 算子
作用:对 RDD 中的每个元素应用给定的函数 f,将每个元素转换为另一个元素,最终返回一个新的 RDD。这个函数 f 接收一个输入类型为 T 的元素,返回一个类型为 U 的元素。
格式:def map[U: ClassTag](f: T => U): RDD[U]
示例代码
import org.apache.spark.{SparkConf, SparkContext}
object MapExample {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("MapExample").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(Seq(1, 2, 3, 4))
val newRdd = rdd.map(x => x * 2)
newRdd.collect().foreach(println)
sc.stop()
}
}
2.filter 算子
作用:筛选出 RDD 中满足函数 f 条件(即 f 函数返回 true)的元素,返回一个新的 RDD,新 RDD 中的元素类型与原 RDD 相同。
格式:def filter(f: T => Boolean): RDD[T]
示例代码
import org.apache.spark.{SparkConf, SparkContext}
object FilterExample {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("FilterExample").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(Seq(1, 2, 3, 4))
val newRdd = rdd.filter(x => x % 2 == 0)
newRdd.collect().foreach(println)
sc.stop()
}}
3.flatMap算子
作用:对 RDD 中的每个元素应用函数 f,函数 f 返回一个可遍历的集合,然后将这些集合中的元素扁平化合并成一个新的 RDD。
格式:def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U]
示例代码
import org.apache.spark.{SparkConf, SparkContext}
object FlatMapExample {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("FlatMapExample").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(Seq("hello world", "spark is great"))
val newRdd = rdd.flatMap(x => x.split(" "))
newRdd.collect().foreach(println)
sc.stop()
}}
4.reduceByKey 算子
reduceByKey 是 Spark 中用于处理键值对(Key - Value)类型 RDD 的一个重要转换算子。它的核心作用是对具有相同键的所有值进行聚合操作,通过用户提供的聚合函数将这些值合并成一个结果,从而实现数据的归约和统计。例如统计每个键出现的次数、计算每个键对应值的总和、平均值等。
格式
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
参数说明:
func: (V, V) => V:这是一个二元函数,用于定义如何对相同键的值进行聚合。函数接收两个类型为 V 的值,返回一个类型为 V 的结果。例如,若要对相同键的值进行求和,func 可以是 (x, y) => x + y。
numPartitions: Int(可选):指定结果 RDD 的分区数。如果不提供该参数,将使用默认的分区数。
以下是一个使用 reduceByKey 计算每个单词出现次数的示例:
import org.apache.spark.{SparkConf, SparkContext}
object ReduceByKeyExample {
def main(args: Array[String]): Unit = {
// 创建 SparkConf 对象
val conf = new SparkConf().setAppName("ReduceByKeyExample").setMaster("local[*]")
// 创建 SparkContext 对象
val sc = new SparkContext(conf)
// 创建一个包含单词的 RDD
val words = sc.parallelize(List("apple", "banana", "apple", "cherry", "banana", "apple"))
// 将每个单词映射为 (单词, 1) 的键值对
val wordPairs = words.map(word => (word, 1))
// 使用 reduceByKey 计算每个单词的出现次数
val wordCounts = wordPairs.reduceByKey(_ + _)
// 输出结果
wordCounts.collect().foreach(println)
// 停止 SparkContext
sc.stop()
}
}
(三)行动算子
行动算子(Action) 是一种触发 RDD 计算的操作。与转换算子(Transformation)不同,行动算子会返回一个结果给驱动程序(Driver Program),或者将结果写入外部存储系统。行动算子是触发 Spark 计算的“触发点”,因为 Spark 的 RDD 是懒惰计算的,只有在执行行动算子时,才会真正开始计算。
下面介绍集中常见的行动算子。
1. collect算子
作用:用于将分布式存储在集群中各个节点上的 RDD 元素收集到驱动程序(Driver Program)中,并以数组的形式返回。这意味着该算子会触发 Spark 作业的执行,将之前的转换操作进行实际计算,并将结果汇总到驱动程序所在的节点。
格式:def collect(): Array[T]
参数说明:该算子没有参数。
返回值:返回一个包含 RDD 中所有元素的数组,数组元素的类型与 RDD 中元素的类型一致。
示例代码
object CollectExample {
def main(args: Array[String]): Unit = {
// 省略 ...
// 创建一个包含整数的 RDD
val numbers = sc.parallelize(1 to 10)
// 使用 collect 算子将 RDD 中的元素收集到驱动程序
val collectedNumbers = numbers.collect()
// 输出收集到的元素
collectedNumbers.foreach(println)
// 停止 SparkContext
sc.stop()
}}
2.reduce算子
作用:reduce 用于对 RDD 中的元素进行全局聚合操作,例如计算 RDD 中所有元素的总和、最大值、最小值等。在分布式计算环境中,reduce 会先在每个分区内进行局部聚合,然后将各个分区的结果进行全局聚合,最终得到一个单一的结果。
格式
def reduce(func: (T, T) => T): T
参数说明:
func: (T, T) => T:这是一个二元函数,用于定义如何对 RDD 中的元素进行聚合。函数接收两个类型为 T 的元素,返回一个类型为 T 的结果。例如,若要对 RDD 中的整数进行求和,func 可以是 (x, y) => x + y。
返回值:返回一个单一的值,其类型与 RDD 中元素的类型相同。
示例代码
以下是一个使用 reduce 计算 RDD 中所有整数之和的示例:
object ReduceExample {
def main(args: Array[String]): Unit = {
// 省略...
// 创建一个包含整数的 RDD
val numbers = sc.parallelize(1 to 10)
// 使用 reduce 算子计算所有元素的总和
val sum = numbers.reduce(_ + _)
// 输出结果
println(s"RDD 中所有元素的总和为: $sum")
// 停止 SparkContext
sc.stop()
}}
3.count算子
作用:count 是 Spark 中的一个行动算子,用于统计 RDD 中元素的数量。它会触发 Spark 作业的实际执行,对 RDD 中的所有元素进行计数,并将最终的计数结果返回给驱动程序。例如在进行数据验证、抽样或者评估数据处理任务的复杂度时,都可能需要知道 RDD 中元素的数量
格式
def count(): Long
参数说明:该算子没有参数。
返回值:返回一个 Long 类型的值,表示 RDD 中元素的数量。
4. 示例代码