Kubernetes控制平面组件:Kubelet详解(二):核心功能层
云原生学习路线导航页(持续更新中)
- kubernetes学习系列快捷链接
- Kubernetes架构原则和对象设计(一)
- Kubernetes架构原则和对象设计(二)
- Kubernetes架构原则和对象设计(三)
- Kubernetes控制平面组件:etcd(一)
- Kubernetes控制平面组件:etcd(二)
- Kubernetes控制平面组件:API Server详解(一)
- Kubernetes控制平面组件:API Server详解(二)
- Kubernetes控制平面组件:调度器Scheduler(一)
- Kubernetes控制平面组件:调度器Scheduler(二)
- Kubernetes控制平面组件:Controller Manager详解
- Kubernetes控制平面组件:Controller Manager 之 内置Controller详解
- Kubernetes控制平面组件:Controller Manager 之 NamespaceController 全方位讲解
- Kubernetes控制平面组件:Kubelet详解(一):API接口层介绍
本文是 kubernetes 的控制面组件 kubelet 系列文章第二篇,主要讲解了 kubelet 架构中的核心功能层,包括核心管理模块的 PLEG、cAdvisor、GPUManager、OOMWatcher、ProbeManager、DiskSpaceManager、EvictionManager;运行时协调模块的 syncLoop、PodWorker,以及容器生命周期管理模块的 StatusManager、VolumeManager、ImageGC、ContainerGC、ImageManager、CertificateManager,对每个组件都做了详细讲解
- 希望大家多多 点赞 关注 评论 收藏,作者会更有动力继续编写技术文章
- 在 Kubernetes控制平面组件:Kubelet详解(一):API接口层介绍 中,我们对 kubelet 做了简要介绍,给出了kubelet架构,并对API接口层做了介绍,本文将对 kubelet 的 核心功能层 做详细讲解
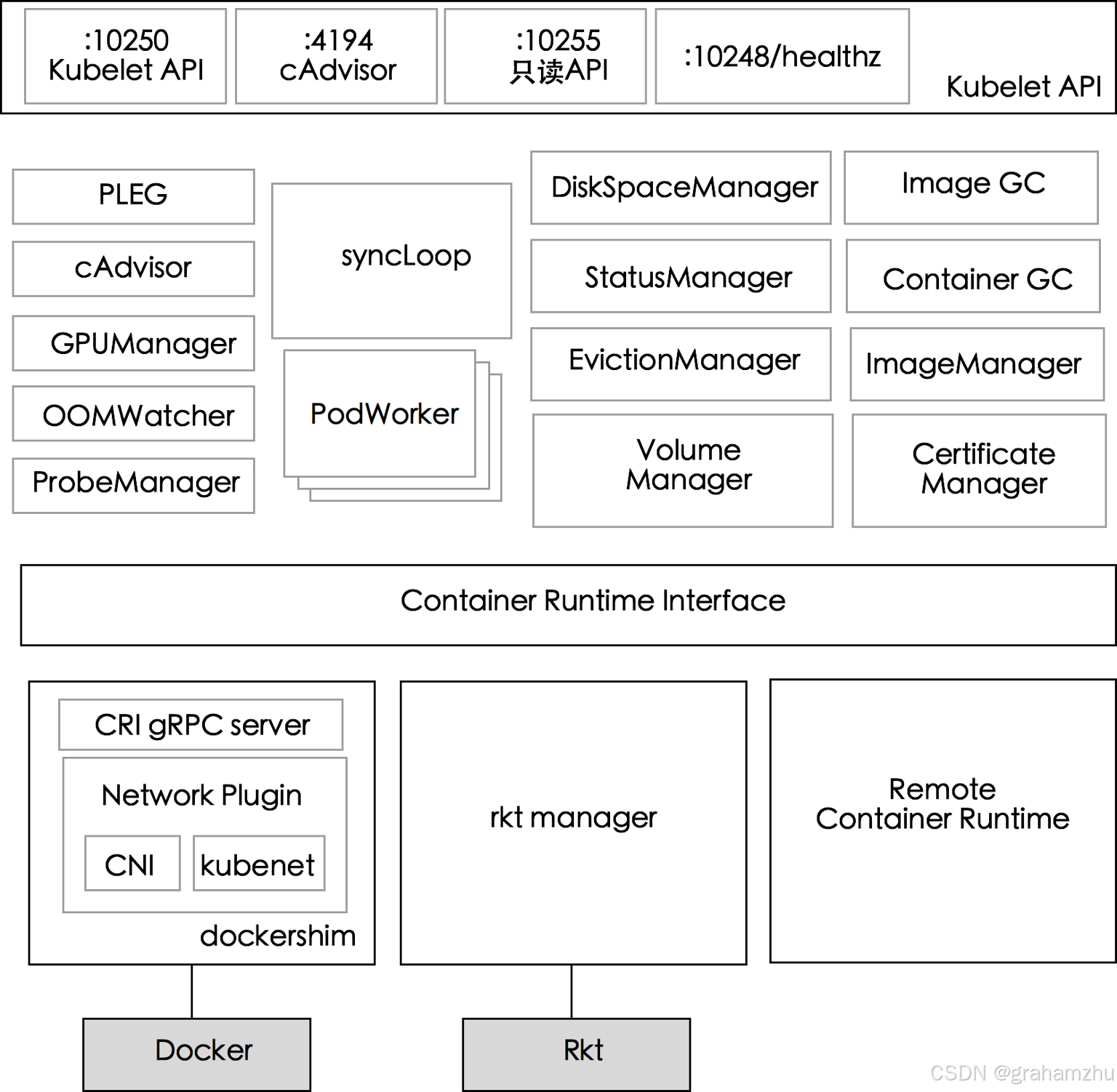
- API 接口层
- kubelet API
- cAdvisor API
- 只读API
- 健康检查 API
- 核心功能层,可分为3个模块:
- 核心管理模块:PLEG、cAdvisor、GPUManager、OOMWatcher、ProbeManager、DiskSpaceManager、EvictionManager
- 运行时协调模块:syncLoop、PodWorker
- 容器生命周期管理模块:StatusManager、VolumeManager、ImageGC、ContainerGC、ImageManager、CertificateManager
- CRI 接口层
- 容器执行引擎接口,作为grpc client 与真正的容器运行时(Dockershim/rkt/containerd)交互
1.核心管理模块
1.1.PLEG(Pod Lifecycle Event Generator,Pod 生命周期事件生成器)
1.1.1.PLEG 是什么?
- PLEG(Pod Lifecycle Event Generator)是 kubelet 的核心子模块,负责监控节点上容器的状态变化,并将这些变化转换为 Pod 生命周期事件(如
ContainerStarted、ContainerDied等),驱动 Pod 状态同步和更新。 - PLEG(Pod Lifecycle Event Generator)生成的事件完全来源于节点本地的容器运行时(如 containerd、CRI-O 等)的状态变化
- PLEG设计目标
- 替代旧版 kubelet 的 同步轮询机制,提升容器状态检测效率。
- 通过 事件驱动模型 减少资源消耗,加快 Pod 状态更新。
1.1.2.PLEG 的核心功能
-
容器状态监控
- 定期通过 容器运行时接口(CRI) 查询节点上所有容器的状态(如
Running、Exited、Unknown) - 检测容器状态变化(如崩溃、重启、OOMKilled)
- 定期通过 容器运行时接口(CRI) 查询节点上所有容器的状态(如
-
事件生成
- 将容器状态变化转换为 Pod 生命周期事件,例如:
ContainerStarted:容器启动。ContainerDied:容器终止。ContainerChanged:容器配置变更(如资源限制更新)。
- 将容器状态变化转换为 Pod 生命周期事件,例如:
-
状态同步
- 将事件传递给 kubelet 的 状态管理器(Status Manager),触发 Pod 状态的更新。
- 确保 API Server 中 Pod 状态与节点实际状态一致。
1.1.3.PLEG 的实现原理
- 定期 Relist 操作:
- PLEG 通过一个定时器(默认间隔 1秒)触发
relist过程。 - 调用 CRI(如 containerd、Docker)的
ListPodSandboxes和ListContainers接口,获取所有 Pod 和容器的当前状态。
- PLEG 通过一个定时器(默认间隔 1秒)触发
- 状态对比:
- 将当前容器状态与上一次
relist的结果进行对比,识别状态变化。
- 将当前容器状态与上一次
- 事件生成:
- 根据状态差异生成事件(如容器从
Running变为Exited生成ContainerDied)。
- 根据状态差异生成事件(如容器从
- 事件分发:
- 将事件写入 kubelet 的 事件通道(EventChannel),由状态管理器处理。
1.1.4.PLEG 的性能影响
-
性能瓶颈
- 容器数量:节点上运行的 Pod/容器越多,
relist耗时越长。 - 运行时性能:容器运行时响应
ListPodSandboxes和ListContainers的速度影响 PLEG 效率。
- 容器数量:节点上运行的 Pod/容器越多,
-
网络延迟:
- 如果容器运行时通过远程服务(如 Docker Daemon)访问,可能引入延迟。
-
监控指标
kubelet_pleg_relist_interval_seconds:记录每次relist的耗时。kubelet_pleg_relist_latency_microseconds:历史分位数统计。kubelet_pleg_last_seen_seconds:容器状态最后一次被记录的时间戳。
1.1.5.PLEG 的健康检查
- PLEG Health Check
- kubelet 会监控 PLEG 的
relist是否按时完成。 - 若
relist耗时超过 3分钟(默认阈值),kubelet 会报告 PLEG is not healthy 事件,并标记节点为NotReady。
- kubelet 会监控 PLEG 的
- 常见故障原因
- 容器运行时无响应:Docker/containerd 卡死或负载过高。
- 节点资源耗尽:CPU、内存或文件描述符不足。
- 内核问题:如磁盘 I/O 卡顿、内核死锁。
1.2.cAdvisor(资源监控代理)
1.2.1.cAdvisor 是什么?
- cAdvisor(Container Advisor)是一个开源的 容器资源监控与性能分析工具,由 Google 开发并集成到 Kubernetes 的 kubelet 中。
- 它专注于实时收集、聚合和暴露容器级别的资源使用数据,帮助用户了解容器化应用的行为和性能瓶颈。
- cAdvisor核心定位
- 轻量级:作为 kubelet 的嵌入式模块,无额外依赖。
- 全容器支持:兼容 Docker、containerd、CRI-O 等主流容器运行时。
- 实时性:提供秒级粒度的监控数据。
1.2.2.cAdvisor 的核心功能
-
资源监控
- 基础资源:
- CPU 使用率(用户态、内核态)
- 内存使用量(RSS、缓存、Swap)
- 磁盘 I/O(读写速率、吞吐量)
- 网络流量(接收/发送字节数、丢包率)
- 容器层级:
- 每个容器的资源消耗。
- Pod 级别的聚合指标(通过 Kubernetes 标签关联)。
- 基础资源:
-
数据暴露
- Prometheus 格式:通过 HTTP 端点
/metrics/cadvisor提供标准的 Prometheus 指标。 - REST API:提供 JSON 格式的容器详情(如
/api/v1.3/containers)。
- Prometheus 格式:通过 HTTP 端点
-
多运行时支持
- 通过 容器运行时接口(CRI) 兼容 Docker、containerd、CRI-O 等。
- 支持 非容器化进程 的监控(通过 cgroups 追踪)。
1.2.3.cAdvisor 的实现原理
1.2.3.1.cAdvisor数据采集机制
- cgroups 文件系统解析:
- cAdvisor 通过读取 Linux 内核的 cgroups(控制组) 文件系统(如
/sys/fs/cgroup)获取资源使用数据。 - 例如:CPU 使用时间从
cpuacct.stat读取,内存使用从memory.usage_in_bytes读取。
- cAdvisor 通过读取 Linux 内核的 cgroups(控制组) 文件系统(如
- 容器运行时交互:
- 调用容器运行时的 API(如 Docker Engine 的
/containers/json)获取容器元数据(ID、名称、标签)。
- 调用容器运行时的 API(如 Docker Engine 的
- 事件监听:
- 通过 inotify 监听容器状态变化(如创建、销毁)以触发数据更新。
1.2.3.2.cAdvisor架构设计
cAdvisor 的架构分为以下核心模块
- Manager:
- 管理所有容器的监控周期。
- 维护容器树结构(容器 -> Pod -> 节点)。
- Storage Driver:
- 存储历史监控数据(默认使用内存存储,可扩展为 BigQuery、InfluxDB 等)。
- Metrics Collector:
- 负责从 cgroups、procfs、sysfs 等收集原始数据。
- Event Handler:
- 处理容器生命周期事件(如启动、停止)。
1.2.3.3.cAdvisor集成到 kubelet
- 内置模块:kubelet 启动时自动初始化 cAdvisor,无需独立部署。
- 数据暴露路径:
- 旧版本(Kubernetes <1.12):通过独立端口 4194 暴露数据。
- 新版本(Kubernetes ≥1.12):通过 kubelet 主端口 10250 的
/metrics/cadvisor端点暴露。
1.2.4.cAdvisor 的数据采集细节
- 指标类型
| 指标类别 | 示例指标名 | 说明 |
|---|---|---|
| CPU | container_cpu_usage_seconds_total | 容器累计 CPU 使用时间(秒) |
| 内存 | container_memory_working_set_bytes | 容器工作集内存(常驻内存) |
| 磁盘 I/O | container_fs_reads_bytes_total | 容器累计读取字节数 |
| 网络 | container_network_receive_bytes_total | 容器累计接收的网络字节数 |
| 进程 | container_processes | 容器内运行的进程数 |
1.3.GPUManager(GPU设备管理)
1.3.1.GPUManager 是什么?
- GPUManager 是 kubelet 中用于管理和调度 GPU(Graphics Processing Unit)资源 的核心模块,属于 Kubernetes 设备插件框架(Device Plugin Framework) 的一部分。
- 它通过集成设备插件(如 NVIDIA GPU 插件),将 GPU 资源抽象为 Kubernetes 可识别的资源类型,实现 GPU 的自动化发现、分配和调度
1.3.2.GPUManager 的核心功能
- GPU 资源发现与上报
- 设备注册:GPUManager 通过设备插件(如
nvidia-device-plugin)与 kubelet 通信,注册节点上的 GPU 设备信息(如 GPU 数量、型号等)。 - 资源上报:将 GPU 资源信息(如
nvidia.com/gpu: 4)上报至 Kubernetes API Server,供调度器使用。
- 设备注册:GPUManager 通过设备插件(如
- GPU 资源分配与调度
- 资源分配:当 Pod 请求 GPU 资源时,GPUManager 通过
Allocate接口分配具体 GPU 设备,并生成容器启动所需的配置(如环境变量、设备挂载路径)。 - 调度协调:与 Kubernetes 调度器协同,确保 Pod 被调度到具有足够 GPU 资源的节点。
- 资源分配:当 Pod 请求 GPU 资源时,GPUManager 通过
- 容器运行时协作
- 驱动与库注入:通过
nvidia-container-runtime或CDI(Container Device Interface),将 GPU 驱动和 CUDA 库注入容器,确保容器内应用可访问 GPU。 - 设备隔离:支持多租户场景下的 GPU 隔离(如 MIG 技术)。
- 驱动与库注入:通过
1.4.OOMWatcher(内存溢出监控)
1.4.1.OOMWatcher 基本功能
- OOMWatcher(通常指 OSWatcher,Oracle 官方工具)是一种用于实时监控操作系统资源使用情况的开源工具,核心功能在于通过采集关键指标帮助用户诊断内存溢出(OOM)等性能问题。
- Kubelet 通过与 OOMWatcher 模块的深度集成,实现了对系统内存溢出(Out-Of-Memory, OOM)事件的实时监控与响应,保障节点及容器的稳定性。
1.4.2.Kubelet 对 OOMWatcher 的集成机制
- 集成架构与协作组件
- 数据源依赖:
- OOMWatcher 依赖 cAdvisor(集成于 Kubelet 中)提供容器和节点的资源监控数据。cAdvisor 通过内核接口(如
cgroups)实时采集内存使用情况,并在检测到 OOM 事件时推送信号至 OOMWatcher。
- OOMWatcher 依赖 cAdvisor(集成于 Kubelet 中)提供容器和节点的资源监控数据。cAdvisor 通过内核接口(如
- 事件通道机制:
- OOMWatcher 通过 Watch 机制 监听 cAdvisor 的 OOM 事件流,并生成
PodLifecycleEvent事件,通过eventChannel发送至 Kubelet 的syncLoop主控制循环。
- OOMWatcher 通过 Watch 机制 监听 cAdvisor 的 OOM 事件流,并生成
- 数据源依赖:
- OOM 事件处理流程
- 事件检测:
- 系统级 OOM:当节点全局内存耗尽触发内核 OOM-Killer 时,cAdvisor 捕获
/var/log/messages中的 OOM-Kill 日志,并通知 OOMWatcher。 - 容器级 OOM:若容器因内存超限被终止(如
State.OOMKilled状态),cAdvisor 通过容器运行时接口(CRI)获取状态变更并触发事件。
- 系统级 OOM:当节点全局内存耗尽触发内核 OOM-Killer 时,cAdvisor 捕获
- 事件传递:
- OOMWatcher 将事件封装为 Kubernetes 标准事件(
Event对象),通过StatusManager上报至 API Server,同时触发syncLoop同步状态。
- OOMWatcher 将事件封装为 Kubernetes 标准事件(
- 响应处理:
- 容器重启:若 Pod 配置了重启策略(如
Always),Kubelet 调用容器运行时重启容器。 - 资源回收:驱逐低优先级 Pod(通过
EvictionManager),释放节点内存资源。 - 日志记录:在 Pod 事件中记录 OOM 详情,便于运维排查。
- 容器重启:若 Pod 配置了重启策略(如
- 事件检测:
1.4.3.配置与调优
- 通过 Kubelet 的
--eviction-hard设置内存驱逐阈值(如memory.available<1Gi),提前触发资源回收。 - 调整
--container-runtime和--runtime-request-timeout优化容器响应速度。 - 安全策略:关闭匿名访问(
--anonymous-auth=false),防止未授权用户通过 Kubelet API 获取敏感 OOM 事件信息。默认true
1.5.DiskSpaceManager(存储资源管理)
1.5.1.DiskSpaceManager 是什么
- DiskSpaceManager 是 Kubernetes kubelet 的核心子系统之一,主要负责 节点磁盘空间管理,通过预设阈值防止节点因磁盘资源耗尽导致服务异常。
- 其核心功能是监控关键文件系统(如 Docker 镜像存储路径和根文件系统),当可用空间低于阈值时触发保护机制,拒绝新 Pod 的创建。
1.5.2.DiskSpaceManager 核心功能
- 磁盘空间阈值保护
- 当节点上 Docker 镜像存储路径或根文件系统的可用空间低于预设阈值时,DiskSpaceManager 会阻止新 Pod 的创建,避免因磁盘耗尽引发系统崩溃。
- 动态资源监控
- 通过集成 cAdvisor 实时采集磁盘使用数据,结合缓存机制优化性能,避免频繁的磁盘检查操作。
- 与驱逐机制协同
- 当磁盘空间持续不足时,与 EvictionManager 协作,触发 Pod 驱逐策略以释放资源。
1.6.EvictionManager(资源驱逐决策)
1.6.1.EvictionManager 是什么?
- EvictionManager 是 Kubernetes kubelet 的核心组件之一,负责在 节点资源不足时主动驱逐 Pod 以保障节点稳定性。
- 它通过预设的资源阈值(如内存、磁盘空间等)监控节点状态,当资源压力达到临界点时,按优先级策略终止部分 Pod 以释放资源。
- 与 Linux OOM Killer 的被动响应不同,EvictionManager 是 主动预防机制,避免了资源耗尽导致的节点崩溃。
1.6.2.EvictionManager核心功能
- (1)资源监控与阈值触发
- 监控关键资源指标(Eviction Signals),包括:
memory.available(可用内存)nodefs.available(根文件系统可用空间)imagefs.available(容器运行时存储镜像的磁盘空间)pid.available(可用进程数)
- 通过 cAdvisor 实时采集资源使用数据,结合 硬驱逐阈值(Hard Eviction) 和 软驱逐阈值(Soft Eviction) 触发驱逐动作。
- 监控关键资源指标(Eviction Signals),包括:
- (2)Pod 驱逐策略
- 优先级排序:根据 Pod 的 QoS 类别(BestEffort > Burstable > Guaranteed)和资源使用量(超过请求值的 Pod 优先)选择驱逐目标。
- 优雅终止:为被驱逐的 Pod 设置终止宽限期(Grace Period),避免服务中断。
- (3)节点状态同步
- 将资源压力状态映射到节点条件(Node Conditions),如
MemoryPressure或DiskPressure,并通过 kube-apiserver 同步至集群调度器,阻止新 Pod 调度到问题节点。
- 将资源压力状态映射到节点条件(Node Conditions),如
1.6.3.EvictionManager实现原理
- 驱逐流程
- 触发条件:
- 硬驱逐:资源使用达到阈值后立即终止 Pod,无宽限期。
- 软驱逐:达到阈值后等待
eviction-soft-grace-period(默认 1m30s),再终止 Pod。
- 资源回收
- 每次驱逐需保证至少释放
--eviction-minimum-reclaim指定的资源量(如 500Mi 内存),避免频繁触发驱逐。
- 每次驱逐需保证至少释放
- 触发条件:
- 策略执行细节
- QoS 优先级:优先驱逐 BestEffort Pod,其次为超出资源请求值的 Burstable Pod,最后是 Guaranteed Pod。
- 防止状态震荡:通过
eviction-pressure-transition-period(默认 5m)延迟节点压力状态的解除,避免调度器频繁调整。
1.6.4.与其他组件的协作
- 与 cAdvisor 联动
- 依赖 cAdvisor 提供容器和节点的资源使用指标,如文件系统挂载点检测、内存工作集计算。
- 与 VolumeManager 协同
- 驱逐时卸载相关存储卷,释放
nodefs空间。
- 驱逐时卸载相关存储卷,释放
- 与 Scheduler 交互
- 通过
MemoryPressure或DiskPressure状态阻止新 Pod 调度,例如:MemoryPressure时拒绝 BestEffort PodDiskPressure时拒绝所有 Pod
- 通过
1.6.5.配置与调优建议
- 关键参数
--eviction-hard:硬驱逐阈值(需谨慎设置,避免过度驱逐)。--eviction-soft-grace-period:软驱逐宽限期(平衡服务可用性与资源压力)。--eviction-max-pod-grace-period:Pod 终止最大宽限期(覆盖 Pod 自身配置)。
- 监控与调试
- 通过
kubectl describe node查看节点压力事件。 - 启用 kubelet 调试日志(
--v=4)观察驱逐决策过程。
- 通过
2.kubelet 运行时协调层
2.1.syncLoop(状态同步核心循环)
2.1.1.syncLoop 是什么?
syncLoop是 kubelet 的核心事件驱动循环,负责 监听多种事件源 并协调 Pod 的实际状态与期望状态一致。- 它是 kubelet 实现 Pod 生命周期管理(如创建、更新、删除)的中枢逻辑,通过持续监听事件并触发同步操作,确保节点上的 Pod 始终符合 API Server 中声明的期望状态。
2.1.2.syncLoop 的核心功能
- 事件聚合与分发
- 监听多种事件源(如 API Server 的配置变更、容器状态变化、定时任务等)。
- 统一调度处理逻辑,将事件分发给对应的处理模块(如
PodWorker、StatusManager)。
- 状态同步
- 根据事件触发 Pod 的创建、更新、删除操作。
- 确保容器运行时(如 containerd)中的容器状态与 Kubernetes API 中记录的 Pod 状态一致。
- 容错与重试
- 处理同步失败的情况(如容器启动失败),触发自动重试或错误上报。
- 资源清理
- 定期清理孤儿 Pod、残留的卷和网络资源。
2.1.3.syncLoop 的实现原理
2.1.3.1.事件驱动架构
syncLoop通过 多路复用(Multiplexing) 监听多个事件通道,使用select语句等待任意一个通道的事件到达,然后分发给对应的处理逻辑。- 其核心代码结构如下(简化版):
func (kl *Kubelet) syncLoop() {for {if !kl.syncLoopIteration(...) {break}}
}func (kl *Kubelet) syncLoopIteration(...) bool {select {case <-configCh: // 处理配置变更(如 Pod 的增删改)case <-plegCh: // 处理容器状态变化事件case <-syncCh: // 定时强制同步case <-housekeepingCh: // 定期清理资源case update := <-kl.livenessManager.Updates():case update := <-kl.readinessManager.Updates():case update := <-kl.startupManager.Updates():case update := <-kl.containerManager.Updates():}return true
}
2.1.3.2.事件来源与处理逻辑
| 事件来源 | 触发条件 | 处理逻辑 |
|---|---|---|
configCh | API Server 或静态 Pod 的配置变更 | 处理pod的增删改查、重新调谐 |
plegCh | PLEG 检测到容器状态变化(如崩溃、重启) | 定期 relist 环境中所有pod,对比变化后调用 HandlePodSyncs 重新同步受影响的 Pod,还负责清理终止的容器。 |
syncCh | 定时器触发(默认 1秒) | 强制同步所有标记为需要同步的 Pod。 |
housekeepingCh | 定时器触发(默认 2秒) | 调用 HandlePodCleanups 清理孤儿 Pod、残留的卷和网络资源。 |
liveness/readiness | 存活/就绪探针状态变更 | 更新容器状态,触发容器重启(存活探针失败)或服务端点更新(就绪探针变更)。 |
containerManager | 设备资源变更(如 GPU 分配) | 重新同步涉及设备资源的 Pod。 |
- 注:我们前面讲的 pod事件来源:api Server、本地静态 Pod、HTTP Server 或 HTTP Endpoint(URL)的 Pod 配置变更,最终都会被统一到 Pod 级别的事件通道 configCh 中处理。
2.1.3.3.状态同步流程
- 事件触发:某个事件(如 Pod 新增、容器崩溃)到达事件通道。
- 生成同步请求:将需要同步的 Pod 加入待处理队列。
- PodWorker 处理:异步执行 Pod 的创建、更新或删除操作。
- 状态上报:将最终状态通过
StatusManager上报到 API Server。
2.1.4.与相关模块的协作
| 模块 | 协作方式 |
|---|---|
| PLEG | 通过 plegCh 提供容器状态变化事件,触发 Pod 同步。 |
| PodWorker | 异步执行具体的 Pod 同步操作(如创建容器、挂载卷)。 |
| StatusManager | 将 Pod 的最新状态上报到 API Server。 |
| VolumeManager | 管理卷的挂载/卸载操作,确保 Pod 启动前卷已就绪。 |
| ContainerRuntime | 调用容器运行时接口(CRI)执行容器生命周期操作。 |
2.1.5.kubelet 如何区分pod为 static pod?
- static pod 会包含多个 mirror annotation
metadata:annotations:kubernetes.io/config.source: file # 标识来源为本地文件kubernetes.io/config.hash: <hash> # 文件内容哈希值kubernetes.io/config.mirror: <hash> # 标识为镜像 Pod - 具体的请见:Kubernetes控制平面组件:Kubelet 之 Static 静态 Pod
2.2.PodWorker(Pod 操作执行单元)
2.2.1.podWorker 是什么?
podWorker是 kubelet 中用于 管理单个 Pod 生命周期操作的核心工作单元。每个 Pod 对应一个独立的podWorker,负责执行该 Pod 的创建、更新、删除等同步操作,确保 Pod 的实际状态与期望状态一致。它是 kubelet 实现 Pod 异步化、并行化管理的核心机制。
2.2.2.podWorker 的核心功能
- 生命周期操作执行
- Pod 创建:根据配置启动容器、挂载卷、配置网络等。
- Pod 更新:处理配置变更(如镜像版本更新、资源限制调整)。
- Pod 删除:优雅终止容器、卸载卷、清理资源。
- 状态同步
- 调用容器运行时接口(CRI)执行容器操作(如
CreateContainer、StartContainer)。 - 与
VolumeManager协作挂载/卸载存储卷。 - 与
StatusManager协作上报 Pod 状态到 API Server。
- 调用容器运行时接口(CRI)执行容器操作(如
- 容错与重试
- 自动重试失败的操作(如容器启动失败)。
- 处理操作超时,避免长时间阻塞。
- 并发控制
- 每个 Pod 的同步操作在独立的 goroutine 中执行,避免资源竞争。
- 通过通道(Channel)和锁(Mutex)管理操作顺序。
2.2.3.podWorker 的实现原理
2.2.3.1.工作模型
- 每个 Pod 对应一个 worker:通过
podUpdates通道接收同步请求。 - 事件驱动:由
syncLoop分发的同步事件触发操作。 - 状态机管理:维护 Pod 的同步状态(如
SyncPod、Terminating)。
2.2.3.2.关键数据结构
- Pod 配置缓存:保存当前 Pod 的期望状态(来自 API Server 或静态配置)。
- 操作队列:按顺序处理同步请求,确保最终一致性。
- 同步上下文(SyncContext):包含执行同步操作所需的运行时状态(如容器 ID、卷挂载点)。
2.2.3.3.同步流程
- 接收同步请求:
- 从
syncLoop接收事件(如ADD、UPDATE、DELETE)。
- 从
- 生成同步操作:
- 对比当前状态与期望状态,生成差异化的操作指令(如重启容器、更新卷)。
- 执行操作:
- 容器运行时交互:调用 CRI 接口管理容器生命周期。
- 卷管理:等待
VolumeManager完成卷挂载。 - 网络配置:调用 CNI 插件设置容器网络。
- 状态上报:
- 通过
StatusManager将最终状态上报到 API Server。
- 通过
2.2.4.podWorker 的并发与顺序控制
-
操作顺序性
- 串行化处理:同一 Pod 的同步操作严格按顺序执行,避免竞态条件。
- 最新配置优先:若在同步过程中收到新事件,旧操作可能被中止,直接处理最新配置。
-
同步模式
模式 触发条件 行为特性 增量同步 Pod 配置发生部分变更(如环境变量更新) 仅执行必要的变更操作(如重启容器)。 全量同步 Pod 配置发生重大变更(如镜像版本变更) 销毁旧容器并重新创建。 强制同步 定时触发或手动干预(如 kubectl replace)忽略状态缓存,全量重新同步。
2.2.5.错误处理与重试机制
- 错误分类
- 瞬时错误(如网络波动):自动重试,重试间隔指数退避。
- 持久错误(如镜像拉取失败):记录事件并停止重试,等待外部干预。
- 重试策略
- 最大重试次数:默认 5 次,超过后标记 Pod 为失败状态。
- 退避策略:初始延迟 200ms,每次翻倍,上限 7s。
- 错误日志与事件
- 日志标记:通过
klog输出错误详情(如容器启动失败原因)。 - Kubernetes 事件:生成
Warning类型事件供用户查看(如FailedCreateContainer)。
- 日志标记:通过
3.容器生命周期管理
3.1.Image GC(Image Garbage Collection,镜像垃圾回收)
3.1.1.ImageGC 是什么?
- ImageGC 是 kubelet 中负责 自动清理节点上未使用的容器镜像 的模块。它的核心目标是防止节点磁盘被冗余的镜像占满,确保系统有足够空间运行新的容器。
- ImageGC 通过周期性扫描和策略性删除镜像,平衡存储资源的使用效率。
3.1.2.为什么需要 ImageGC?
- 磁盘空间管理:容器镜像通常体积较大,频繁拉取新镜像可能导致磁盘耗尽。
- 自动化运维:手动清理镜像不现实,尤其在大型集群中。
- 稳定性保障:磁盘空间不足会导致容器启动失败、节点不可用等问题。
3.1.3.ImageGC 的工作原理
3.1.3.1.触发条件
- ImageGC 的执行由以下两个阈值控制(基于节点磁盘使用率):
- 高水位阈值(
--image-gc-high-threshold):- 默认值
85%。当磁盘使用率超过此阈值时,触发镜像清理。
- 默认值
- 低水位阈值(
--image-gc-low-threshold):- 默认值
80%。清理镜像直到磁盘使用率降至此阈值以下。
- 默认值
- 高水位阈值(
3.1.3.2.清理策略
- 筛选候选镜像:
- 扫描所有镜像,排除 被正在运行的容器引用的镜像。
- 剩余镜像按 最后使用时间(LRU) 排序,优先删除最久未使用的镜像。
- 删除镜像:
- 依次删除候选镜像,直到磁盘使用率低于低水位阈值。
- 每次删除操作调用容器运行时 ImageManager 的接口(如 Docker 的
docker rmi或 containerd 的ctr images rm)。
3.1.3.3.执行流程
+---------------------+
| 周期性检查磁盘使用率 |
+----------+----------+|v
+----------+----------+
| 使用率 > 高水位阈值? +--否--> 等待下一周期
+----------+----------+|是v
+----------+----------+
| 列出所有未使用的镜像 |
+----------+----------+|v
+----------+----------+
| 按 LRU 排序镜像 |
+----------+----------+|v
+----------+----------+
| 依次删除镜像直到使用率 ≤ 低水位阈值 |
+---------------------+
3.1.4.关键配置参数
| 参数 | 说明 | 默认值 |
|---|---|---|
--image-gc-high-threshold | 触发镜像清理的磁盘使用率阈值(百分比)。 | 85 |
--image-gc-low-threshold | 清理后磁盘使用率的目标阈值(百分比)。 | 80 |
--minimum-image-ttl-duration | 镜像的最小存活时间,短于此时间的镜像即使未使用也不会被删除(例如 2h)。 | 0(禁用) |
3.1.5.与其他模块的协作
- 容器运行时接口(CRI):
- 通过 CRI 获取镜像列表、删除镜像(如
ListImages和RemoveImage接口)。
- 通过 CRI 获取镜像列表、删除镜像(如
- 容器GC(ContainerGC):
- ImageGC 与容器垃圾回收协同工作,先清理已终止的容器,再清理其关联的镜像。
- Kubelet 磁盘压力处理:
当节点触发磁盘压力(Disk Pressure)时,ImageGC 是关键的回收手段之一。
3.1.6.生产环境调优建议
- 合理设置阈值:
- 根据节点磁盘大小调整高低水位阈值(如大容量磁盘可适当提高阈值)。
- 示例:若磁盘为 1TB,设置
--image-gc-high-threshold=90、--image-gc-low-threshold=85。
- 避免频繁清理:
- 增大
--image-gc-period(如15m),减少对性能的影响。
- 增大
- 保护关键镜像:
- 对于频繁使用的公共镜像(如
pause镜像),确保它们被至少一个 Pod 引用。
- 对于频繁使用的公共镜像(如
- 结合容器运行时策略:
- 某些容器运行时(如 Docker)支持自身的镜像清理策略(如
docker system prune),需与 ImageGC 协调配置。
- 某些容器运行时(如 Docker)支持自身的镜像清理策略(如
3.2.Container GC(容器垃圾回收)
以下是关于 kubelet 的 Container Garbage Collection(容器垃圾回收模块,ContainerGC) 的详细介绍:
3.2.1.ContainerGC 是什么?
- ContainerGC 是 kubelet 中负责 自动清理节点上已终止或孤立的容器 的模块。
- 核心目标是防止节点因残留容器占用过多资源(如磁盘空间、内存),确保节点资源的高效利用和稳定性。
3.2.2.ContainerGC 的核心功能
- 清理已终止的容器:
- 删除已完成运行(Exited)的容器(如
Completed或Error状态的容器)。
- 删除已完成运行(Exited)的容器(如
- 清理孤立的容器:
- 删除未被任何 Pod 引用的容器(如 Pod 被删除后残留的容器)。
- 资源回收:
- 释放容器占用的磁盘空间(如日志文件、临时存储)。
3.2.3.ContainerGC 的工作原理
3.2.3.1.触发条件
- 周期性扫描:默认每隔 1分钟 触发一次扫描。
- 主动触发:当节点资源(如磁盘空间)不足时,kubelet 的 驱逐机制(Eviction Manager) 会主动调用 ContainerGC 清理容器。
3.2.3.2.清理策略
- 确定待清理容器:
- 已终止的容器:容器运行结束(状态为
Exited)。 - 孤立的容器:容器未被任何活跃 Pod 引用(如 Pod 被删除但容器未被清理)。
- 已终止的容器:容器运行结束(状态为
- 保留策略:
- 按数量保留:默认保留最近 1个 终止的容器。
- 按时间保留:默认保留终止时间不超过 0秒,即立即删除。
3.2.3.3.执行流程
+---------------------+
| 周期性扫描容器列表 |
+----------+----------+|v
+----------+----------+
| 筛选已终止或孤立容器 |
+----------+----------+|v
+----------+----------+
| 应用保留策略 |
| - 保留最近的N个容器 |
| - 保留时间超过阈值 |
+----------+----------+|v
+----------+----------+
| 调用容器运行时删除容器 |
+---------------------+
3.3.ImageManager(镜像生命周期)
3.3.1.ImageManager 是什么?
- ImageManager 是 kubelet 中负责 管理节点上的容器镜像生命周期 的核心模块,核心职责包括镜像的拉取、缓存管理、状态同步以及与垃圾回收的协作。它确保 Pod 所需的镜像在节点上存在且可用,同时优化存储资源的使用。
3.3.2.ImageManager 的核心功能
3.3.2.1.镜像拉取(Image Pulling)
- 按需拉取:当 Pod 被调度到节点时,ImageManager 检查本地是否存在所需镜像。若不存在,则通过容器运行时(如 Docker、containerd)从镜像仓库拉取。
- 并发控制:支持并行拉取多个镜像,提升效率(通过
--serialize-image-pulls参数配置是否串行拉取)。
3.3.2.2.镜像缓存管理
- 缓存状态维护:记录本地已存在的镜像及其元数据(如镜像大小、拉取时间)。
- 镜像有效性检查:定期验证缓存的镜像是否完整可用(如通过摘要校验)。
3.3.2.3.镜像状态同步
- 报告镜像状态:向 kubelet 提供镜像信息,供调度决策和容器启动使用。
- 更新镜像列表:与容器运行时同步镜像列表,确保缓存状态与实际一致。
3.3.2.4.与垃圾回收的协作
- 标记镜像使用情况:记录哪些镜像被活跃的 Pod 引用,为 ImageGC(镜像垃圾回收)提供清理依据。
- 响应资源压力:当节点触发磁盘压力时,优先清理未被引用的镜像。
3.3.3.ImageManager 的实现原理
3.3.3.1.镜像拉取流程
- Pod 调度到节点:kubelet 接收到 Pod 的创建请求。
- 镜像检查:ImageManager 检查本地是否存在该 Pod 所有容器的镜像。
- 拉取缺失镜像:通过 CRI(容器运行时接口)调用容器运行时的
PullImage方法。 - 镜像验证:校验镜像的完整性(如使用镜像摘要)。
- 更新缓存:将新拉取的镜像加入本地缓存。
3.3.3.2.镜像缓存管理机制
- 缓存数据结构:
- 使用键值对存储镜像信息,键为镜像名称(如
nginx:latest),值为镜像的元数据(如大小、拉取时间、引用计数)。
- 使用键值对存储镜像信息,键为镜像名称(如
- 引用计数:
- 跟踪哪些 Pod 正在使用某个镜像,当引用计数归零时,该镜像可能被 ImageGC 清理。
3.3.3.3.与容器运行时的交互
- CRI 接口调用,ImageManager 通过 CRI 的以下接口操作镜像:
ListImages:获取本地镜像列表。PullImage:拉取远程镜像。ImageStatus:检查镜像的详细信息。RemoveImage:删除镜像(通常由 ImageGC 触发)。
3.3.4.关键配置参数
| 参数 | 说明 | 默认值 |
|---|---|---|
--serialize-image-pulls | 是否串行拉取镜像(设为 false 允许并行拉取,提升效率)。 | true(Kubernetes ≤1.17)false(Kubernetes ≥1.18) |
--image-pull-progress-deadline | 镜像拉取的超时时间(超过此时间未完成则标记为失败)。 | 1m |
--registry-qps | 访问镜像仓库的每秒查询次数(QPS)限制。 | 5 |
--registry-burst | 访问镜像仓库的突发请求数限制(Burst)。 | 10 |
3.3.5.与其他模块的协作
3.3.5.1.PodWorker
- 协作流程:
- PodWorker 在启动容器前,调用 ImageManager 确保镜像已存在。若镜像缺失,PodWorker 会等待拉取完成。
3.3.5.2.ImageGC(镜像垃圾回收)
- 数据共享:
- ImageManager 提供镜像的引用计数和最后使用时间,ImageGC 根据这些数据清理未被引用的镜像。
3.3.5.3.容器运行时(CRI)
- 操作代理:
- ImageManager 通过 CRI 接口实际执行镜像的拉取、删除和状态查询。
3.4.Certificate Manager(证书管理)
3.4.1.Certificate Manager 是什么
- Certificate Manager 是 kubelet 中负责管理 TLS 证书生命周期 的核心模块,用于自动轮换和更新 kubelet 与 Kubernetes API Server 通信所需的客户端证书。
- 设计目标是确保 kubelet 始终使用有效的证书进行安全通信,避免因证书过期导致的服务中断。
3.4.2.Certificate Manager 的核心功能
3.4.2.1.证书自动轮换
- 监控证书有效期:定期检查当前证书的到期时间。
- 自动申请新证书:在证书即将过期时,生成新的私钥和证书签名请求(CSR),提交到 Kubernetes API。
- 替换旧证书:获取新签名证书后,替换本地存储的旧证书。
3.4.2.2.证书签名请求(CSR)管理
- 生成 CSR:基于当前节点的身份信息(如节点名称、组信息)生成 CSR。
- 提交 CSR:通过 Kubernetes 的
certificates.k8s.ioAPI 提交 CSR。 - 监控 CSR 状态:等待集群的 CA(Certificate Authority)签名并获取签名后的证书。
3.4.2.3.证书存储与加载
- 安全存储证书和私钥:将证书和私钥存储在节点的安全目录(如
/var/lib/kubelet/pki)。 - 动态加载证书:支持在不重启 kubelet 的情况下重新加载新证书。
3.4.2.4.TLS Bootstrapping 支持
- 初始证书获取:在节点首次加入集群时,自动完成 TLS 证书的初始化(需配合 Bootstrap Token 或手动批准机制)。
3.4.3.证书生命周期管理流程
3.4.3.1.初始证书申请(TLS Bootstrapping)
- 生成 Bootstrap Token:集群管理员创建 Bootstrap Token,允许节点临时访问 API。
- kubelet 启动:使用 Bootstrap Token 向 API Server 发送首次 CSR。
- CSR 批准:管理员或自动审批控制器(如
csrapprover)批准 CSR。 - 证书下发:kubelet 获取签名后的证书,存储到本地。
3.4.3.2.证书轮换流程
- 检测证书有效期:Certificate Manager 定期检查当前证书的剩余有效期(默认提前 30% 有效期触发轮换)。
- 生成新私钥和 CSR:使用相同身份信息生成新的 CSR。
- 提交并批准 CSR:新 CSR 提交到 API Server,等待批准。
- 替换证书:获取新证书后,替换旧证书并重新加载。
3.4.4.与 Kubernetes 证书 API 的交互
3.4.4.1.CSR 的生成与提交
- CSR 内容:
apiVersion: certificates.k8s.io/v1 kind: CertificateSigningRequest metadata:name: kubelet-node1 spec:request: <base64-encoded-csr>signerName: kubernetes.io/kube-apiserver-client-kubeletusages:- digital signature- key encipherment- client auth - 提交 CSR:
kubectl apply -f kubelet-csr.yaml
3.4.4.2.CSR 的自动批准
- 条件:CSR 需满足以下条件之一:
- 节点身份已验证(如
system:nodes组)。 - 使用预定义的 SignerName(如
kubernetes.io/kube-apiserver-client-kubelet)。
- 节点身份已验证(如
- 自动批准控制器:
csrapprover控制器自动批准合法的 kubelet CSR。
3.4.5.证书存储与动态加载
3.4.5.1.默认存储路径
- 证书文件:
/var/lib/kubelet/pki/kubelet-client-current.pem - 私钥文件:
/var/lib/kubelet/pki/kubelet-client-current.pem - 符号链接机制:kubelet 使用符号链接指向当前有效的证书文件(如
kubelet-client-current.pem指向实际证书文件)。
3.4.5.2.动态加载
- 证书更新后:kubelet 自动检测新证书文件并重新加载,无需重启进程。
- 兼容性:需容器运行时(如 containerd)支持动态证书加载。
3.4.6.安全性与配置
3.4.6.1.安全实践
- 私钥保护:私钥文件权限设置为
0600,仅允许 kubelet 用户访问。 - 证书最小权限:kubelet 证书的用途限制为
client auth,避免权限过度分配。
3.4.6.2.关键配置参数
| 参数 | 说明 | 默认值 |
|---|---|---|
--rotate-certificates | 是否启用自动证书轮换。 | true |
--cert-dir | 证书存储目录。 | /var/lib/kubelet/pki |
--tls-cert-file | kubelet 服务端证书文件路径(若 kubelet 作为服务器)。 | 空(客户端模式无需配置) |
--tls-private-key-file | kubelet 服务端私钥文件路径。 | 空 |
--feature-gates=RotateKubeletServerCertificate | 启用服务端证书轮换(Kubernetes ≥1.8)。 | true(默认启用) |
3.4.7.故障排查与常见问题
3.4.7.1.证书轮换失败
- 现象:kubelet 日志中出现
certificate rotation error。 - 排查步骤:
- 检查 CSR 是否已提交并批准:
kubectl get csr。 - 检查 kubelet 日志:
journalctl -u kubelet | grep certificate。 - 验证 CA 证书是否有效:
openssl x509 -in /etc/kubernetes/pki/ca.crt -text。
- 检查 CSR 是否已提交并批准:
3.4.7.2.证书权限问题
- 现象:kubelet 无法读取证书文件。
- 解决:确保证书目录权限为
700,文件权限为600:chmod 700 /var/lib/kubelet/pki chmod 600 /var/lib/kubelet/pki/kubelet-client-current.pem
3.4.7.3.自动批准未生效
- 现象:CSR 处于
Pending状态。 - 解决:
- 确认集群的 CSR Approver 已启用。
- 检查 CSR 的
spec.signerName和spec.groups是否符合自动批准策略。
3.5.StatusManager
3.5.1.StatusManager是什么
- StatusManager 是 kubelet 中负责 同步 Pod 状态到 Kubernetes API Server 的核心模块。
- 用于确保 API Server 中记录的 Pod 状态(如
Running、Failed)与节点上实际运行的 Pod 状态一致,是 kubelet 与集群控制平面通信的关键组件。
3.5.2.StatusManager 的核心功能
3.5.2.1.状态同步
- Pod 状态上报:将 Pod 的当前状态(包括容器状态、Pod 阶段、条件等)更新到 API Server。
- 最终一致性保障:确保即使存在网络波动或 API Server 不可用,最终状态仍会同步。
3.5.2.2.状态合并
- 冲突解决:当本地状态与 API Server 中记录的状态不一致时,合并状态并选择最新版本提交。
- 版本控制:基于
ResourceVersion处理乐观锁冲突。
3.5.2.3.事件触发
- 容器状态变更:当容器启动、终止或探针状态变化时,触发状态更新。
- Pod 生命周期事件:如 Pod 被删除、节点资源不足导致驱逐等。
3.5.3.状态同步流程
3.5.3.1.状态收集
- 数据来源:
- 容器运行时(CRI):获取容器状态(如
Running、Exited)。 - ProbeManager:获取存活/就绪探针的结果。
- PodWorker:接收 Pod 的操作结果(如创建、删除成功与否)。
- 容器运行时(CRI):获取容器状态(如
3.5.3.2.状态更新触发
- 主动触发:
- 容器状态变化(如崩溃)。
- 探针结果变更(如就绪探针失败)。
- Pod 的元数据变更(如标签更新)。
- 周期性触发:默认每隔 10秒同步一次状态。
3.5.3.3.状态同步到 API Server
- 生成 Pod 状态对象:
根据收集的数据生成v1.PodStatus对象。 - 对比新旧状态:
若本地状态与 API Server 中的状态不一致,生成更新请求。 - 提交更新:
调用 Kubernetes API 的UpdateStatus方法提交状态变更。 - 错误处理:
若提交失败(如网络问题),重试直到成功(采用指数退避策略)。
3.5.4.与其他模块的协作
| 模块 | 协作方式 |
|---|---|
| PodWorker | 接收 Pod 操作结果(如容器启动成功/失败),触发状态更新。 |
| ProbeManager | 获取容器探针(Liveness/Readiness)的结果,更新 Pod 的 Ready 条件。 |
| ContainerRuntime | 获取容器实际状态(如 Running、Exited)。 |
| EvictionManager | 当 Pod 被驱逐时,更新 Pod 状态为 Failed 并添加 Evicted 条件。 |
| VolumeManager | 当卷挂载失败时,更新 Pod 状态为 Pending 并记录错误信息。 |
3.6.VolumeManager
3.6.1.VolumeManager是什么
- VolumeManager 是 kubelet 中负责 管理 Pod 存储卷(Volume)生命周期 的核心模块。它确保在容器启动前完成存储卷的挂载(Mount),并在容器终止后安全卸载(Unmount)存储卷,同时处理卷的扩容、快照等操作。
- 其设计目标是保证 Pod 对持久化存储的可靠访问,并与容器运行时、CSI(Container Storage Interface)插件协同工作。
3.6.2.VolumeManager 的核心功能
3.6.2.1.卷的生命周期管理
- 挂载(Mount):
在容器启动前,将存储卷挂载到节点的指定路径(如/var/lib/kubelet/pods/<pod-id>/volumes)。 - 卸载(Unmount):
在 Pod 终止或卷不再被使用时,卸载存储卷并清理资源。 - 扩容(Resize):
支持动态调整持久卷(PVC)的容量(需存储后端支持)。
3.6.2.2.卷的配额管理
- 容量监控:确保卷的可用空间满足 Pod 需求,触发驱逐(Eviction)或告警。
- 配额感知:对于支持配额的存储类型(如本地磁盘),限制 Pod 对卷的使用。
3.6.2.3.卷的状态同步
- 维护卷的挂载状态,确保与 API Server 中记录的卷状态一致。
- 处理卷的挂载失败、重试和错误上报。
3.6.3.卷类型与支持
- VolumeManager 支持 Kubernetes 中所有类型的存储卷,包括但不限于:
- 临时卷:
emptyDir、configMap、secret。 - 持久卷:
persistentVolumeClaim(PVC)、hostPath。 - 外部存储:通过 CSI 插件接入的云存储(如 AWS EBS、Google Persistent Disk)。
- 特殊卷:
downwardAPI、projected。
- 临时卷:
3.6.4.VolumeManager 的工作原理
3.6.4.1.卷挂载流程
- Pod 调度到节点:kubelet 接收到 Pod 的创建请求。
- 卷预处理:
- 为
emptyDir卷创建临时目录。 - 为
configMap/secret卷生成配置文件。 - 为 PVC 卷调用 CSI 插件完成卷的绑定(Binding)和挂载。
- 为
- 挂载到节点路径:
- 将卷挂载到节点的本地路径(如
/var/lib/kubelet/pods/<pod-id>/volumes/...)。
- 将卷挂载到节点的本地路径(如
- 容器挂载:
- 将节点路径通过容器运行时挂载到容器内部(如
/data)。
- 将节点路径通过容器运行时挂载到容器内部(如
3.6.4.2.卷卸载流程
- Pod 终止:kubelet 接收到 Pod 的删除请求。
- 容器停止:停止所有关联容器。
- 卷卸载:
- 卸载容器挂载点。
- 卸载节点路径上的卷(如调用
umount或 CSI 插件的Unmount接口)。
- 清理资源:删除临时文件或释放存储后端资源。
3.6.4.3.状态机管理
VolumeManager 为每个卷维护一个状态机,包括以下状态:
- VolumeNotMounted:卷未挂载。
- VolumeMounted:卷已挂载到节点。
- VolumeInUse:卷被容器使用。
- VolumeFailed:挂载失败(需重试或报错)。
3.6.5.与其他模块的协作
| 模块 | 协作方式 |
|---|---|
| PodWorker | 在启动容器前等待 VolumeManager 完成卷挂载。 |
| CSI 插件 | 调用 CSI 接口完成存储卷的挂载、卸载和扩容操作。 |
| API Server | 同步 PersistentVolume(PV)和 PersistentVolumeClaim(PVC)的状态。 |
| EvictionManager | 当卷空间不足时触发 Pod 驱逐。 |
| ProbeManager | 若卷挂载失败,可能触发容器健康检查失败。 |