dfs第二次加训 详细题解 下
目录
B4158 [BCSP-X 2024 12 月小学高年级组] 质数补全
思路
B4279 [蓝桥杯青少年组国赛 2023] 数独填数、
思路
P5198 [USACO19JAN] Icy Perimeter S
思路
P5429 [USACO19OPEN] Fence Planning S
思路
P6111 [USACO18JAN] MooTube S
思路
P6207 [USACO06OCT] Cows on Skates G
P6591 [YsOI2020] 植树
思路
总结
P6691 选择题
思路
P7228 [COCI 2015/2016 #3] MOLEKULE
思路
P7995 [USACO21DEC] Walking Home B
思路
P8838 [传智杯 #3 决赛] 面试
思路
P9304 「DTOI-5」3-1
思路
P10095 [ROIR 2023] 斐波那契乘积 (Day 1)
思路
P10386 [蓝桥杯 2024 省 A] 五子棋对弈
思路
P10490 Missile Defence System
思路
P10477 Subway tree systems
思路
P12317 [蓝桥杯 2024 国 C] 树的结点值
思路
B4158 [BCSP-X 2024 12 月小学高年级组] 质数补全
题目描述
Alice 在纸条上写了一个质数,第二天再看时发现有些地方污损看不清了。
- 在大于 1 的自然数中,除了 1 和它本身以外不再有其他因数的自然数称为质数
请你帮助 Alice 补全这个质数,若有多解输出数值最小的,若无解输出 −1。
例如纸条上的数字为 1∗(∗ 代表看不清的地方),那么这个质数有可能为 11,13,17,19,其中最小的为 11。
输入格式
第一行 1 个整数 t,代表有 t 组数据。
接下来 t 行,每行 1 个字符串 s 代表 Alice 的数字,仅包含数字或者 ∗,并且保证首位不是 ∗ 或者 0。
输出格式
输出 t 行,每行 1 个整数代表最小可能的质数,或者 −1 代表无解。
输入输出样例
输入 #1复制
10 1* 3** 7** 83*7 2262 6**1 29*7 889* 777* 225*
输出 #1复制
11 307 701 8317 -1 6011 2917 8893 -1 2251
输入 #2复制
10 4039*** 2***5*5 4099961 25**757 7***0** 1***00* 41811*9 6***0*7 8***1** 6561*59
输出 #2复制
4039019 -1 4099961 2509757 7000003 1000003 4181129 6000047 8000101 6561259
说明/提示
数据范围
∣s∣ 代表 s 串的长度,对于所有数据,1≤t≤10,1≤∣s∣≤7,s 中仅包含数字或者 ∗,并且保证首位不是 ∗ 或者 0。
本题采用捆绑测试,你必须通过子任务中的所有数据点以及其依赖的子任务,才能获得子任务对应的分数。
| 子任务编号 | 分值 | ∣s∣ | 特殊性质 | 子任务依赖 |
|---|---|---|---|---|
| 1 | 35 | ≤7 | s 中没有 ∗ | |
| 2 | 30 | ≤4 | ||
| 3 | 24 | ≤7 | s 中至多包含 1 个 ∗ | 1 |
| 4 | 11 | ≤7 | 1,2,3 |
思路
这题我看了题解,整体思路我是会的,就像之前写的题一样,看有几个*然后对每个*都for循环就好,唯一的一点就是要用个数组记录哪些索引是*,最开始我把这玩意忘了,然后一直差点意思,还有就是那个字符串转为数字的函数,剩下看代码吧也没啥讲的
#include<bits/stdc++.h>
using namespace std;
bool isPrime(string nums) {int num=atoi(nums.c_str());if (num <= 1) return false;if (num == 2) return true;if (num % 2 == 0) return false;for (int i = 3; i * i <= num; i += 2) {if (num % i == 0) return false;}return true;}
string s;
int pos[10],p;
bool flag=false;
void dfs(int t,string str){if(flag) return;if(t>p){if(isPrime(str)){cout<<str<<endl;flag=1;}return ;}int c=pos[t];//取出现在要更改的*的索引if(c==0){for(int i=1;i<=9;i++){str[c]=i+'0';dfs(t+1,str);str[c]='*';}}else{for(int i=0;i<=9;i++){str[c]=i+'0';dfs(t+1,str);str[c]='*';}}
}
int main(){int t;cin>>t;while(t--){cin>>s;p=0;for(int i=0;i<s.size();i++){if(s[i]=='*'){pos[++p]=i;//用pos数组记录每一个*的索引 }}flag=false;if(p==0){if(isPrime(s)) cout<<s<<endl;else{cout<<-1<<endl;;}}else{dfs(1,s);if(!flag) cout<<-1<<endl;}}}B4279 [蓝桥杯青少年组国赛 2023] 数独填数、
题目背景
本题使用的数独均较为简单,不接受 hack 数据,感兴趣的同学可以查看 此题目 的说明/提示部分。
题目描述
数独是源自 18 世纪瑞士的一种数学游戏。玩家需要根据 9×9 网格上的已知数字,将剩余的所有空格填上数字,使得:
- 每一行包含数字 1∼9 且不重复;
- 每一列包含数字 1∼9 且不重复;
- 每一个 3×3 方块(粗线划分)包含数字 1∼9 且不重复。
输入格式
共有 9 行,表示未完成的数独:
- 每行包含 9 个字符(字符只能为 1∼9 的数字和
.);.表示数独上的空格;- 题目数据保证数独有效且答案唯一。
输出格式
输出 9 行,表示已完成的数独:
- 每行 9 个数字,数字之间没有空格及其他字符。
输入输出样例
输入 #1复制
17.5..8.. .52.1.... .....759. .8...94.3 .197.4..8 7......15 4.1...6.. 3...2..59 ...96..3.输出 #1复制
174593826 952816347 638247591 286159473 519734268 743682915 491375682 367428159 825961734
思路
其实和八皇后差不多,就是一个一个看数,还需要个check函数来检查这个数行不行,不行就回溯没啥很难的地方,就是注意dfs函数返回值是bool,有时候会因为这个返回值的原因,我们最终这个函数一直运行不下去看代码吧
#include<bits/stdc++.h>
using namespace std;
vector<string>grid(9);
bool check(int i,int j,char k){
//看这一行是否满足for(int col=0;col<9;col++){if(grid[i][col]==k) return false;}
//看列是否满足for(int row=0;row<9;row++){if(grid[row][j]==k) return false;}
//看九宫格满足不int row=(i/3)*3;int col=(j/3)*3;for(int new_row=row;new_row<row+3;new_row++){for(int new_col=col;new_col<col+3;new_col++){if(grid[new_row][new_col]==k) return false;}}return true;
}
bool dfs(){for(int i=0;i<9;i++){for(int j=0;j<9;j++){if(grid[i][j]=='.'){for(char k='1';k<='9';k++){if(check(i,j,k)){grid[i][j]=k;if(dfs())return true;grid[i][j]='.';}}return false;//这9个都不行的话说明前面出错了,就false}}}return true;
}
int main(){for(int i=0;i<9;i++){cin>>grid[i];}if(dfs()){for(int i=0;i<9;i++){cout<<grid[i]<<endl;} }}P5198 [USACO19JAN] Icy Perimeter S
题目背景
USACO 一月月赛银组第二题
题目描述
Farmer John 要开始他的冰激凌生意了!他制造了一台可以生产冰激凌球的机器,然而不幸的是形状不太规则,所以他现在希望优化一下这台机器,使其产出的冰激凌球的形状更加合理。 机器生产出的冰激凌的形状可以用一个 N×N(1≤N≤1000)的矩形图案表示,例如:
##.... ....#. .#..#. .##### ...### ....##每个
.字符表示空的区域,每个#字符表示一块 1×1 的正方形格子大小的冰激凌。不幸的是,机器当前工作得并不是很正常,可能会生产出多个互不相连的冰激凌球(上图中有两个)。一个冰激凌球是连通的,如果其中每个冰激凌的正方形格子都可以从这个冰激凌球中其他所有的冰激凌格子出发重复地前往东、南、西、北四个方向上相邻的冰激凌格子所到达。
Farmer John 想要求出他的面积最大的冰激凌球的面积和周长。冰激凌球的面积就是这个冰激凌球中
#的数量。如果有多个冰激凌球并列面积最大,他想要知道其中周长最小的冰激凌球的周长。在上图中,小的冰激凌球的面积为 2,周长为 6,大的冰激凌球的面积为 13,周长为 22。注意一个冰激凌球可能在中间有“洞”(由冰激凌包围着的空的区域)。如果这样,洞的边界同样计入冰激凌球的周长。冰激凌球也可能出现在被其他冰激凌球包围的区域内,在这种情况下它们计为不同的冰激凌球。例如,以下这种情况包括一个面积为 1 的冰激凌球,被包围在一个面积为 16 的冰激凌球内:
##### #...# #.#.# #...# #####同时求得冰激凌球的面积和周长十分重要,因为 Farmer John 最终想要最小化周长与面积的比值,他称这是他的冰激凌的“冰周率”。当这个比率较小的时候,冰激凌化得比较慢,因为此时冰激凌单位质量的表面积较小。
输入格式
输入的第一行包含 N,以下 N 行描述了机器的生产结果。其中至少出现一个
#字符。输出格式
输出一行,包含两个空格分隔的整数,第一个数为最大的冰激凌球的面积,第二个数为它的周长。如果多个冰激凌球并列面积最大,输出其中周长最小的那一个的信息。
输入输出样例
输入 #1复制
6 ##.... ....#. .#..#. .##### ...### ....##输出 #1复制
13 22
思路
很简单哈,就是给你输入的这个矩阵的周围都加一圈‘ .’,因为我们要求周长实际上九算出每个#周围有几个' . ',然后我们每次dfs就看一下新更新后的面积和周长跟以前以前的谁大谁小就好 ,这还是洪水填充,,,自认为写的很漂亮的代码哈哈,,其实很容易就RE了我最开始设的resize是110,然后就RE了后来改为n+2就AC了很紧凑吧这个数据范围
#include<bits/stdc++.h>
using namespace std;
vector<vector<char>>grid;
int ans_point,ans_ice;
int n;
void dfs(int i,int j){if(i<0||j<0||i>n||j>n||grid[i][j]!='#') return;grid[i][j]='x';//冰淇淋变成xans_ice++;if(grid[i+1][j]=='.') ans_point++;if(grid[i-1][j]=='.') ans_point++;if(grid[i][j-1]=='.') ans_point++;if(grid[i][j+1]=='.') ans_point++;dfs(i+1,j);dfs(i-1,j);dfs(i,j+1);dfs(i,j-1);
}
int main(){cin>>n;grid.resize(n+2,vector<char>(n+2,'.'));for(int i=1;i<=n;i++){for(int j=1;j<=n;j++){cin>>grid[i][j];}}int ans_point1=ans_point;int ans_ice1=ans_ice;for(int i=1;i<=n;i++){for(int j=1;j<=n;j++){if(grid[i][j]=='#'){dfs(i,j);}if(ans_ice>ans_ice1){ans_ice1=ans_ice;ans_point1=ans_point;}else if(ans_ice1==ans_ice){if(ans_point<ans_point1){ans_point1=ans_point;}}ans_ice=0;ans_point=0;}}cout<<ans_ice1<<' '<<ans_point1;
}P5429 [USACO19OPEN] Fence Planning S
题目描述
Farmer John 的 N 头奶牛,编号为 1…N ( 2≤N≤105 ),拥有一种围绕“哞网”,一些仅在组内互相交流却不与其他组进行交流的奶牛小组,组成的复杂的社交网络。
每头奶牛位于农场的二维地图上的不同位置 (x,y) ,并且我们知道有 M 对奶牛( 1≤M<105 )会相互哞叫。两头相互哞叫的奶牛属于同一哞网。
为了升级他的农场,Farmer John 想要建造一个四边与 x 轴和 y 轴平行的长方形围栏。Farmer John 想要使得至少一个哞网完全被围栏所包围(在长方形边界上的奶牛计为被包围的)。请帮助 Farmer John 求出满足他的要求的围栏的最小可能周长。有可能出现这一围栏宽为 0 或高为 0 的情况。
输入格式
输入的第一行包含 N 和 M 。以下 N 行每行包含一头奶牛的 x 坐标和 y 坐标(至多 108 的非负整数)。以下 M 行每行包含两个整数 a 和 b ,表示奶牛 a 和 b 之间有哞叫关系。每头奶牛都至少存在一个哞叫关系,并且输入中不会出现重复的哞叫关系。
输出格式
输出满足 Farmer John 的要求的围栏的最小周长。
输入输出样例
输入 #1复制
7 5 0 5 10 5 5 0 5 10 6 7 8 6 8 4 1 2 2 3 3 4 5 6 7 6输出 #1复制
10
思路
因为可能有好几个图,然后我们要找最小周长,所以我们就要对每个没有遍历过的点都dfs,然找到最小周长,用一个vis数组来标识是否遍历过就好
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+5;
int U,D,L,R,ans=INT_MAX,n,m;//U就是up,D就是down,
bool vis[N];
//建图
struct edge{int to;int next;
}graph[N*2];
int head[N],cnt;
void add_edge(int u,int v){cnt++;graph[cnt].to=v;graph[cnt].next=head[u];head[u]=cnt;
}
//用结构体的话就省一个数组也是比较方便哈
struct cow{int x,y;
}a[N];
void dfs(int x){vis[x]=1;U=max(U,a[x].y),D=min(D,a[x].y);R=max(R,a[x].x),L=min(L,a[x].x);for(int i=head[x];i;i=graph[i].next){int to=graph[i].to;if(!vis[to]){dfs(to);} }
}
int main(){cin >>n>>m;for(int i=1;i<=n;i++)cin>>a[i].x>>a[i].y;while(m--){int x,y;cin>>x>>y;add_edge(x,y),add_edge(y,x);}for(int i=1;i<=n;i++) if(!vis[i]){ //没遍历过说明是另一张图U=D=a[i].y,L=R=a[i].x; dfs(i);ans=min(ans,((U-D)+(R-L))<<1);}cout<<ans;return 0;
}P6111 [USACO18JAN] MooTube S
题目背景
本题与 金组同名题目 在题意上一致,唯一的差别是数据范围。
题目描述
在业余时间,Farmer John 创建了一个新的视频共享服务,他将其命名为 MooTube。在 MooTube 上,Farmer John 的奶牛可以录制,分享和发现许多有趣的视频。他的奶牛已经发布了 N 个视频(1≤N≤5000),为了方便将其编号为 1…N 。然而,FJ 无法弄清楚如何帮助他的奶牛找到他们可能喜欢的新视频。
FJ 希望为每个 MooTube 视频创建一个“推荐视频”列表。这样,奶牛将被推荐与他们已经观看过的视频最相关的视频。
FJ 设计了一个“相关性”度量标准,顾名思义,它确定了两个视频相互之间的相关性。他选择 N−1 对视频并手动计算其之间的相关性。然后,FJ 将他的视频建成一棵树,其中每个视频是节点,并且他手动将 N−1 对视频连接。为了方便,FJ 选择了 N−1 对,这样任意视频都可以通过一条连通路径到达任意其他视频。 FJ 决定将任意一对视频的相关性定义为沿此路径的任何连接的最小相关性。
Farmer John 想要选择一个 K 值,以便在任何给定的 MooTube 视频旁边,推荐所有其他与该视频至少有 K 相关的视频。然而,FJ 担心会向他的奶牛推荐太多的视频,这可能会分散他们对产奶的注意力!因此,他想设定适当的 K 值。 Farmer John希望得到您的帮助,回答有关 K 值的推荐视频的一些问题。
输入格式
第一行输入包含 N 和 Q(1≤Q≤5000)。
接下来的 N−1 行描述了 FJ 手动比较的一对视频。 每行包括三个整数 pi,qi 和 ri(1≤pi,qi≤N,1≤ri≤109),表示视频 pi 和 qi 已连接并且相关性为 ri。
接下来的 Q 行描述了 Farmer John 的 Q 个问题。每行包含两个整数,ki 和 vi(1≤ki≤109,1≤vi≤N),表示 FJ 的第 i 个问题询问中当 K=ki 时,第 vi 个视频推荐列表中将推荐的视频数。
输出格式
输出 Q 行。在第 i 行,输出 FJ 的第 i 个问题的答案。
输入输出样例
输入 #1复制
4 3 1 2 3 2 3 2 2 4 4 1 2 4 1 3 1输出 #1复制
3 0 2
思路
也是一个很简单的一个搜索题,只不过题上那个有一点表达不当可能,我先说一下整体思路吧
就是题上要找与vi相连的至少相关性为ki的节点,我最开始是直接搜索,只要能连起来的相关性大于等于ki的都给计算进去,但是发下样例出来不对,然后又读一遍题,发现如果最开始相连的那个节点的相关性小于ki了那我们就不能走这条路了,就不能错这个节点继续搜。还有就是每次记得memset清除一下脏数据,其他没啥,看代码就行
#include<bits/stdc++.h>
using namespace std;
const int N=5010;
//建图
int n,q,ans;
bool visited[N];
struct edge{int to;int next;int w;
}graph[N*2];
int head[N],cnt;
void add_edge(int u,int v,int w){cnt++;graph[cnt].w=w;graph[cnt].to=v;graph[cnt].next=head[u];head[u]=cnt;
}
void dfs(int x,int k){for(int i=head[x];i;i=graph[i].next){int to=graph[i].to;if(!visited[to]){visited[to]=true;if(graph[i].w>=k){ans++;dfs(to,k);} }}
}
int main(){cin>>n>>q;n--;while(n--){int u,v,w;cin>>u>>v>>w;add_edge(u,v,w);add_edge(v,u,w);}while(q--){int k,u;cin>>k>>u;memset(visited,0,sizeof(visited));ans=0;//都清0,防止上一次搜索的脏数据visited[u]=true;//最开始就已经走过来,先初始化一下,防止之后再走 dfs(u,k);cout<<ans<<endl;}
}P6207 [USACO06OCT] Cows on Skates G
题目描述
本题使用 Special Judge。
Farmer John 把农场划分为了一个 r 行 c 列的矩阵,并发现奶牛们无法通过其中一些区域。此刻,Bessie 位于坐标为 (1,1) 的区域,并想到坐标为 (r,c) 的牛棚享用晚餐。她知道,以她所在的区域为起点,每次移动至相邻的四个区域之一,总有一些路径可以到达牛棚。
这样的路径可能有无数种,请你输出任意一种,并保证所需移动次数不超过 100000。
输入格式
第一行两个整数 r,c。
接下来 r 行,每行 c 个字符,表示 Bessie 能否通过相应位置的区域。字符只可能是 . 或 *。
.表示 Bessie 可以通过该区域。*表示 Bessie 无法通过该区域。
输出格式
若干行,每行包含两个用空格隔开的整数,表示 Bessie 依次通过的区域的坐标。
显然,输出的第一行是 1 1 ,最后一行是 r c。
相邻的两个坐标所表示的区域必须相邻。
输入输出样例
输入 #1复制
5 8 ..*...** *.*.*.** *...*... *.*.*.*. ....*.*.
输出 #1复制
1 1 1 2 2 2 3 2 3 3 3 4 2 4 1 4 1 5 1 6 2 6 3 6 3 7 3 8 4 8 5 8
说明/提示
【数据范围】
对于 100% 的数据,1≤r≤113,1≤c≤77。
思路
第一眼我想用bfs但是咱这个文章是dfs所以我就继续dfs了,唯一比较容易想不好的就是,怎样输出,我们用一个全局变量flag,如果输出了就一直返回就行,我们还要用一个数组来记录坐标,看代码吧不多说了 其实还可以用一个dist数组记录到达每一个位置最短距离,然后进行比较,这样我们可以求得到达最终点的最短路径,有点类似dj算法,只不过dj用的是堆
#include<bits/stdc++.h>
using namespace std;
const int N=120;
int r,c;
bool visited[120][90],flag;
char grid[120][90];
int cd[100010][2];
void dfs(int i,int j,int step){if(i<1||j<1||i>r||j>c||visited[i][j]||grid[i][j]=='*') return;if(flag) return;cd[step][0]=i;cd[step][1]=j;if(i==r&&j==c){for(int t=1;t<=step;t++){cout<<cd[t][0]<<' '<<cd[t][1]<<endl;;}flag=true;return;}visited[i][j]=true;dfs(i+1,j,step+1);dfs(i-1,j,step+1);dfs(i,j-1,step+1);dfs(i,j+1,step+1);
}
int main(){cin>>r>>c;for(int i=1;i<=r;i++){for(int j=1;j<=c;j++){cin>>grid[i][j];}}dfs(1,1,1);return 0;
}P6591 [YsOI2020] 植树
题目背景
Ysuperman 响应号召,决定在幼儿园里植树。
题目描述
Ysuperman 有一棵 n 个节点的无根树 T。如果你不知道树是什么,TA 很乐意告诉你,树是一个没有环的无向联通图。
既然树是无根的,那就没有办法种植。Ysuperman 研究了很久的园艺,发现一个节点如果可以成为根,它必须十分平衡,这意味着以它为根时,与它直接相连的节点,他们的子树大小都相同。
你作为幼儿园信息组一把手,Ysuperman 给你一棵树,你能在 1s 内找到所有可能成为根的节点吗?
输入格式
第一行一个正整数 n,表示树的节点个数。
此后 n−1 行,每行两个正整数 ui,vi,表示树上有一条直接连接 ui,vi 的边。保证每条边只会给出一次。
输出格式
不超过 n 个从小到大的整数,用空格隔开,表示每一个可能成为根的节点。
输入输出样例
输入 #1复制
2 1 2输出 #1复制
1 2输入 #2复制
4 1 2 2 3 3 4输出 #2复制
1 4输入 #3复制
9 1 2 1 3 4 1 5 1 1 6 1 9 8 1 1 7输出 #3复制
1 2 3 4 5 6 7 8 9说明/提示
样例说明
样例说明 1。
以 1 为根时,与 1 直接相连的点有 {2},因为只有一个所以大小全部相同。
以 2 为根时,与 2 直接相连的点有 {1},因为只有一个所以大小全部相同。
所以答案为 1,2。
样例说明 2
以 1 为根时,与 1 直接相连的点有 {2},因为只有一个所以大小全部相同。
以 2 为根时,与 2 直接相连的点有 {1,3},子树大小分别为 {1,2},不相同。
以 3 为根时,与 3 直接相连的点有 {2,4},子树大小分别为 {2,1},不相同。
以 4 为根时,与 4 直接相连的点有 {3},因为只有一个所以大小全部相同。
所以答案为 1,4。
数据范围
本题采用捆绑测试。
subtask n 分数 1 ≤5000 40 2 ≤106 60 对于 100% 的数据,满足 1≤n≤106。
提示
由于输入输出量较大,你可能需要快速输入/输出。
思路
这题不是很难,算每个子树有多大应该都会吧,前面有个道路修建题也是求子树大小,就是用dfs求就好,记得在搜索时给子树大小先初始化为1,因为子树也自带一个根节点哈,然后我用的是链式前向星没加速也过了,一万年给的n确实有点大了,超过1e5我们就用链式前向星速度比较快,然后如果你用的是邻接表你加速一下也能过,推荐用链式前向星,这个确实比较好,还有个难点就是,最后要统计该节点所连的子树大小是否都相同那里,如果这个节点连的是他的父亲,那就等于n-sizes[u],所有节点就、减去这个节点的树的大小就行,如果不是父亲,那就直接=这个节点所连节点树的大小,你们看代码应该就能看懂,看不懂仔细想想就行,不是很难,最后记得是从小到大,用一个res数组存起来,sort一下
#include<bits/stdc++.h>
using namespace std;
#define int long long
int n;
const int N=1e6+10;
struct edge{int to;int next;
}graph[N*2];
int cnt,head[N];
int sizes[N],fat[N];//记录每个树枝上的孩子有几个,记录每个节点他爹是谁
void add_edge(int u,int v){cnt++;graph[cnt].to=v;graph[cnt].next=head[u];head[u]=cnt;
}
void dfs(int u,int fa){fat[u]=fa;sizes[u]=1;for(int i=head[u];i;i=graph[i].next){int to=graph[i].to;if(to==fa) continue;dfs(to,u);sizes[u]+=sizes[to];}
}
vector<int>res;//记录想要的答案
signed main(){cin>>n;//特判一下n=1,因为n等于说明就是只有一个节点 if(n==1) {cout<<1;return 0;}for(int i=1;i<n;i++){int u,v;cin>>u>>v;add_edge(u,v);add_edge(v,u);}//随便哪个开始搜索都行 dfs(1,0);//遍历一遍得到sizes,和fa数组for(int u=1;u<=n;u++){unordered_set<int> sz;for(int i=head[u];i;i=graph[i].next){int to=graph[i].to;if(to==fat[u]){sz.insert(n-sizes[u]);}else{sz.insert(sizes[to]);}}if(sz.size()==1)res.push_back(u);}sort(res.begin(),res.end());for(auto i:res){cout<<i<<' ';}}总结
突然想总结一下 就是图嘛,我们有时候会用visited数组存一下我们走过的路,有时候会弄个父节点防止我们走重复的路,第一种情况是无向有环时我们就需要visited,第二种是无向无环,大家可以自己脑子里思考一下就知道了,有向图好像不太需要这俩玩意,因为这个文章到现在好像就遇到一个有向图,然后没有用这俩,之后再说吧
P6691 选择题
题目背景
小 L 喜欢逻辑推理。
一天,他在一本由英国哲士沃·协德编写的《我也不知道为什么要叫这个名字的一本有关逻辑学的书》中翻到了一道奇特的问题,但他并不会做。他知道你善于用程序解决问题,于是决定让你来帮助他完成这些问题。
题目描述
这是一道有 n 个选项的选择题,每个选项的内容都很独特。第 i 个选项的内容的形式如下:
- 第 ai 个选项是正确/错误的
小 L 认为这种题目的答案不一定是唯一的,所以他想问题这道题有多少种合法的答案(可以全部正确或全部错误)。他还想问你这么多答案中,正确选项最多和最少的答案分别有多少个正确选项。
当然,如果这道题不存在合法的答案,你可以直接回答小 L
No answer。输入格式
第一行有一个正整数 n,表示选项个数。
接下来 n 行,每行有两个整数 ai,opti,描述一个选项。其中当 opti=1 时,表示这个选项的内容为 第 ai 个选项是正确的;当 opti=0 时,表示这个选项的内容为 第 ai 个选项是错误的。
输出格式
如果没有答案满足这道选择题,输出
No answer。否则输出三行,每行一个正整数,分别为合法答案数及正确选项最多和最少的答案分别有多少个正确选项。其中合法答案数要对 998244353 取模。
输入输出样例
输入 #1复制
4 2 1 4 0 1 1 2 0输出 #1复制
2 3 1输入 #2复制
10 4 1 7 0 2 0 3 1 7 1 5 0 9 1 10 1 8 0 1 1输出 #2复制
No answer说明/提示
对于样例一,一共有下面 2 种正确答案:
- 第 1,2,3 个选项是正确的。
- 第 4 个选项是正确的。
其中正确选项最多的答案有 3 个选项正确,正确选项最少的答案有 1 个选项正确。
数据范围
对于 10% 的数据,n≤10。
对于 30% 的数据,n≤100。
对于 60% 的数据,n≤103。
对于 100% 的数据,n≤106,1≤ai≤n,i=ai,opti∈{0,1}。
思路
这题我看题解写的,因为我没看出来这是二分图,看不出来的话想写出来就很难了,思路就是,我们从第i题开始,随便染个色(1,0都行)然后开始搜索,搜索这个节点与预期染的色不一样的话就强制终止程序cout<<"No answer"; exit(0);就这样,,,,我再但多说一下dfs里面的过程
他的两个参数分别是要染的节点,和期待染这个节点的颜色,然后如果这个节点我们染过了,那我们就看看这个节点染过的颜色和现在预期染的颜色一不一样一样就说明染的没毛病,不对就说明执行不下去,无法形成二分图,然后如果没染过我们就给他染上然后开始准备对他的邻接点搜索,
唯一比较重点的是,我们要染的色是通过异或来实现,这道题是第 i 个人说第 ai 个人说的话是真话或是假话。这个真话假话就作为权值,如果第i个人是真话,那么真^(真或假)就由括号里的决定,也就是我们期待染的色,如果是1(真)^(真)1就变成0了,所以我们要真^(!)。还有因为你染一次色把颜色反转过来就又是一个方案了,所以我们要乘2,然后可能还有多个联通块,所以我们就要用个t记录有几个联通快,然后算一下方案数,,
我再详细说一下异或那里,如果当前节点的状态是1,与邻接节点的权重是0,那就是真碰上假,那这个to的期望状态就一
#include<bits/stdc++.h>
using namespace std;
#define int long long
const int N=1e6+10;
struct edge{int to;int next;int w;
}graph[N*2];
int cnt,head[N];
void add_edge(int u,int v,int w){cnt++;graph[cnt].to=v;graph[cnt].w=w;graph[cnt].next=head[u];head[u]=cnt;
}
int n,color[N],sum[2];// color记录节点染色情况,sum统计颜色数量
bool visited[N]; // 访问标记
int t,ans_min,ans_max; // 连通块数量,最小和最大值void dfs(int x,int state){if(visited[x]){if(color[x]!=state){ // 染色冲突检测cout<<"No answer";exit(0);}return;}visited[x]=true;color[x]=state;sum[state]++;for(int i=head[x];i;i=graph[i].next){int to=graph[i].to;int expected=state^(!graph[i].w); // 邻接节点期望颜色dfs(to, expected);}
}
signed main(){ios::sync_with_stdio(false);cin.tie(0);cin>>n;for(int i=1;i<=n;i++){int v,w;cin>>v>>w;add_edge(i,v,w);add_edge(v,i,w);}int ans=1;for(int i=1;i<=n;i++){if(!visited[i]){sum[0]=sum[1]=0;dfs(i,0); // 尝试以颜色0开始染色// 统计当前连通块的两种颜色数量ans_min+=min(sum[0],sum[1]);ans_max+=max(sum[0],sum[1]) ;t++;}}for(int i=1;i<=t;i++){ans =(ans*2) % 998244353;}cout<<ans<<endl<<ans_max<<endl<<ans_min;return 0;
}P7228 [COCI 2015/2016 #3] MOLEKULE
题目描述
有 N 个点和 N−1 条无向边,定义一张有向图的代价为一条在这张有向图上的最长通路长度。
现在把这 N−1 条无向边指定方向,使得形成的有向图代价最小。
求一种指定方向的方案。
输入格式
第一行一个整数 N 代表点数。
接下来 N−1 行每行两个整数 ai,bi 代表一条边。输出格式
N−1 行每行一个整数 r:
- 如果 r=1 代表从 ai 连向 bi。
- 如果 r=0 代表从 bi 连向 ai。
输入输出样例
输入 #1复制
3 1 2 2 3输出 #1复制
1 0输入 #2复制
4 2 1 1 3 4 1输出 #2复制
0 1 0说明/提示
样例 1 解释
如下图所示:
这张图的代价为 1,注意 0 1 也是一组最优解。
样例 2 解释
如下图所示:
数据规模与约定
对于 30% 的数据,N≤20。
对于 100% 的数据,2≤N≤105,1≤ai,bi≤N。本题采用 Special Judge。
你只需要输出任意一种合法方案。
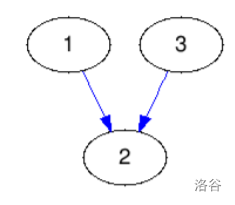
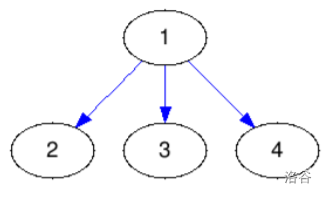
思路
这题挺有意思,就是把一个图变成下面这样,这两种都行,我不知道还有没有别的了哈,反正这俩就是我能想出来的
然后怎么变呢,我们以深度为序号,然后找出奇偶,1深度为0,2深度为1从第二个开始奇数的指向别的节点(我选择的是第一个),3深度为2,偶数被指向,那最后也就是我们可以输出他们&1的值,以他们是否为偶数来输出答案,因为题目输出的也就是0和1,其实都行,题目实际意思就是让你判断这些节点是不是偶数
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+10;
struct edge{int to;int next;
}graph[N*2];
int cnt,head[N];
void add_edge(int u,int v){cnt++;graph[cnt].to=v;graph[cnt].next=head[u];head[u]=cnt;
}
int n,depth[N];
void dfs(int x,int fa){depth[x]=depth[fa]+1;for(int i=head[x];i;i=graph[i].next){int to=graph[i].to;if(to!=fa){dfs(to,x);}}
}
int main(){cin>>n;for(int i=1;i<n;i++){int u,v;cin>>u>>v;add_edge(u,v);add_edge(v,u);}dfs(1,-1);for(int i=1;i<n;i++){int y=graph[i*2-1].to;cout<<(depth[y]&1)<<endl;//奇数的话被指,偶数的话指向别的 }
}P7995 [USACO21DEC] Walking Home B
题目描述
奶牛 Bessie 正准备从她最喜爱的草地回到她的牛棚。
农场位于一个 N×N 的方阵上(2≤N≤50),其中她的草地在左上角,牛棚在右下角。Bessie 想要尽快回家,所以她只会向下或向右走。有些地方有草堆(haybale),Bessie 无法穿过;她必须绕过它们。
Bessie 今天感到有些疲倦,所以她希望改变她的行走方向至多 K 次(1≤K≤3)。
Bessie 有多少条不同的从她最爱的草地回到牛棚的路线?如果一条路线中 Bessie 经过了某个方格而另一条路线中没有,则认为这两条路线不同。
输入格式
每个测试用例的输入包含 T 个子测试用例,每个子测试用例描述了一个不同的农场,并且必须全部回答正确才能通过整个测试用例。输入的第一行包含 T(1≤T≤50)。每一个子测试用例如下。
每个子测试用例的第一行包含 N 和 K。
以下 N 行每行包含一个长为 N 的字符串。每个字符为 .,如果这一格是空的,或 H,如果这一格中有草堆。输入保证农场的左上角和右下角没有草堆。
输出格式
输出 T 行,第 i 行包含在第 i 个子测试用例中 Bessie 可以选择的不同的路线数量。
输入输出样例
输入 #1复制
7 3 1 ... ... ... 3 2 ... ... ... 3 3 ... ... ... 3 3 ... .H. ... 3 2 .HH HHH HH. 3 3 .H. H.. ... 4 3 ...H .H.. .... H...输出 #1复制
2 4 6 2 0 0 6说明/提示
【样例解释】
我们将使用一个由字符 D 和 R 组成的字符串来表示 Bessie 的路线,其中 D 和 R 分别表示 Bessie 向下(down)或向右(right)移动。
第一个子测试用例中,Bessie 的两条可能的路线为 DDRR 和 RRDD。
第二个子测试用例中,Bessie 的四条可能的路线为 DDRR,DRRD,RDDR 和 RRDD。
第三个子测试用例中,Bessie 的六条可能的路线为 DDRR,DRDR,DRRD,RDDR,RDRD 和 RRDD。
第四个子测试用例中,Bessie 的两条可能的路线为 DDRR 和 RRDD。
第五和第六个子测试用例中,Bessie 不可能回到牛棚。
第七个子测试用例中,Bessie 的六条可能的路线为 DDRDRR,DDRRDR,DDRRRD,RRDDDR,RRDDRD 和 RRDRDD。
【数据范围】
测试点 2 满足 K=1。
测试点 3-5 满足 K=2。
测试点 6-10 满足 K=3。
思路
就是搜索,很正常的搜索,只是要注意清楚这个转向就好了,看代码吧
#include<bits/stdc++.h>
using namespace std;
const int N=60;
char grid[N][N];
int ans;
int n,k;
void dfs(int i,int j,int x,int dir){//t是转向的次数,dir是现在的方向 if(i<0||j<0||i==n||j==n||x>k||grid[i][j]=='H') return;if(i==n-1&&j==n-1){ans++;return ;}if(i==0&&j==0){//最初不管向右向下都不算转向 dfs(i+1,j,x,1);//1代表向下 dfs(i,j+1,x,0);//0代表向右 }else{if(dir==1){//向下时 dfs(i+1,j,x,1);dfs(i,j+1,x+1,0);}else{//向右时 dfs(i+1,j,x+1,1);dfs(i,j+1,x,0);} }}
int main(){int t;cin>>t;while(t--){cin>>n>>k;for(int i=0;i<n;i++){for(int j=0;j<n;j++){cin>>grid[i][j];}}ans=0;dfs(0,0,0,0);cout<<ans<<endl;}}P8838 [传智杯 #3 决赛] 面试
题目背景
disangan233 和 disangan333 去面试了,面试官给了一个问题,热心的你能帮帮他们吗?
题目描述
现在有 n 个服务器,服务器 i 最多能处理 ai 大小的数据。
接下来会有 k 条指令 bk,指令 i 表示发送 bi 的数据,需要你分配一个空闲的服务器。
请你算出一个序列 pk 表示指令 i 的数据分配给服务器 pi,且 pk 的字典序最小;如果无法分配,输出 "-1"。
对于所有数据,n,k≤6,ai,bi≤10。
输入格式
输入共 3 行。
第 1 行输入 2 个正整数 n,k。
第 2 行输入 n 个正整数 ai,表示服务器 i 最多能处理的数据大小。
第 3 行输入 k 个正整数 bi,表示指令 i。
输出格式
输出共 1 行 k 个正整数 p1…pk,或者输出 "-1"。
输入输出样例
输入 #1复制
6 6 1 9 1 9 8 1 1 1 4 5 1 4输出 #1复制
1 3 2 4 6 5说明/提示
样例解释
第 1 条指令分给服务器 1;
第 2 条指令分给服务器 3;
第 3 条指令分给服务器 2;
第 4 条指令分给服务器 4;
第 5 条指令分给服务器 6;
第 6 条指令分给服务器 5。
思路
利用全排列方式搜索,
#include<bits/stdc++.h>
using namespace std;
int n,k,a[10],b[10],arr[10];
bool visited[10];
void dfs(int x){if(x==k+1){for(int i=1;i<=n;i++)cout<<arr[i]<<' '; exit(0);}for(int i=1;i<=n;i++){//利用for循环来遍历第i个服务器,让第x个数据扔进去,扔不进去就跳到下一个,//然后搜索,又重新遍历服务器,让之前没用的服务器再次可能被用 if(a[i]-b[x]>=0&&!visited[i]){arr[x]=i,visited[i]=1;dfs(x+1);visited[i]=0;} }return;
}
int main(){cin>>n>>k;for(int i=1;i<=n;i++) cin>>a[i];for(int i=1;i<=k;i++) cin>>b[i];dfs(1);cout<<-1;return 0;
}P9304 「DTOI-5」3-1
题目描述
里克在视线可及的范围内发现了一颗古老的「神树」。
神树是一颗树,树上有 n 个含有魔法装置的位置。经过初步「考察」,有 n−1 条魔法连接,第 i(1≤i≤n−1) 条连接 ui,vi 两个魔法装置,保证 ui=vi 且 1≤ui,vi≤n。这两个装置可以相互双向地在 1 单位时间内通行,保证仅由这 n−1 条连接,每个魔法装置都可以相互到达。
此外,有 n−1 条特殊连接,对于每个魔法装置 i∈[2,n],可以瞬间传送到第 1 个魔法装置,花费 0 单位时间。特殊连接总共只能使用一次。
里克初始在魔法装置 1 处。现在,给出这棵「神树」的结构,里克想要在若干时间内研究尽可能多的魔法装置。我们假定,研究一个魔法装置只需要到达该装置处,并且不需要花费额外时间。
里克想让你尽快计算出,对所有 k∈[1,n],如果要恰好研究 k 个不同的魔法装置,并且随之返回魔法装置 1,最少应花费多少时间。
输入格式
第一行,一个整数 n。
接下来 n−1 行,每行两个整数 ui,vi。
输出格式
共 n 行,第 i 行一个整数表示 k=i 的答案。
输入输出样例
输入 #1复制
5 1 2 1 3 2 4 2 5
输出 #1复制
0 1 2 4 6
输入 #2复制
见下发的 hope/hope2.in
输出 #2复制
见下发的 hope/hope2.ans
说明/提示
【样例解释 1】
- k=1 时,里克只需要呆在装置 1 处。
- k=2 时,里克的路径可以是 1→2⇒1。
- k=3 时,里克的路径可以是 1→2→4⇒1。
- k=4 时,里克的路径可以是 1→2→4⇒1→3→1。
- k=5 时,里克的路径可以是 1→3→1→2→5→2→4⇒1。
【样例解释 2】
这组数据满足测试点编号 13∼20 的性质。
【数据规模与约定】
| 测试点编号 | 特殊限制 |
|---|---|
| 1∼2 | n=3 |
| 3∼4 | n=5 |
| 5∼6 | n=100 |
| 7∼8 | n=1000 |
| 9∼10 | ui=1,vi=i+1 |
| 11∼12 | ui=i,vi=i+1 |
| 13∼20 | 无特殊限制 |
对于所有数据,1≤n≤105,1≤ui,vi≤n。
附件下载
hope.zip790.22KB
思路
就是把他当成树,把节点1当成根然后开始搜索,遍历所有节点,记录他们的深度,并记录最深的深度,但最后我们是要找到这题的那个公式,我们要知道回到节点1,就要走两遍边,然后现在多了个顺义,想要最大程度利用的话,就减去你走的这个分支的最大长度
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+10;
struct edge{int to;int next;
}graph[N*2];
int cnt,head[N],degree[N],depth[N];//degree记录一下每个节点都连了几个节点
//当遇到只连一个的除了根节点,那就是遇到从上往下的节点到底了
void add_edge(int u,int v){cnt++;graph[cnt].to=v;graph[cnt].next=head[u];head[u]=cnt;degree[u]++;
}
int n,max_length;
void dfs(int x,int fa){depth[x]=depth[fa]+1;if(x!=1&°ree[x]==1){max_length=max(max_length,depth[x]);return ;//说明从上往下到达一个个分支的最下面了//然后就更新一下最深度 }for(int i=head[x];i;i=graph[i].next){int to=graph[i].to;if(to!=fa){dfs(to,x);}}
}
int main(){cin>>n;for(int i=1;i<n;i++){int u,v;cin>>u>>v;add_edge(u,v);add_edge(v,u);}depth[0]=-1;//这样就能保证深度就是边的长度了dfs(1,0);//从节点1开始搜,节点0是他爹//k个节点就有(k-1)个边,当没有直接传送,那么想要把所有节点走完再回到根节点//那么必须把所有节点走两遍,那么边就走两遍 //现在多了个传送,我们就要最大程度利用传送,也就是当我走的最远那个分支时候我们就传送,这样就能少走最多的路 //但是我们要求的是走所有数量的节点的情况,所以不是所有情况都要走哪个最深的分支 for(int i=1;i<=n;i++){cout<<(i-1)*2-min(i-1,max_length)<<endl; }}P10095 [ROIR 2023] 斐波那契乘积 (Day 1)
题目背景
翻译自 ROIR 2023 D1T2。
斐波那契数指斐波那契数列(f0=1,f1=1,fi=fi−2+fi−1)中出现的数。
题目描述
给定一个自然数 n,求出将其表示为若干个大于 1 的斐波那契数的乘积的方案数。
输入格式
第一行一个数 t,表示数据组数。
接下来 t 行,每行输入一个数 n。
输出格式
对于每组测试数据,输出一个数表示答案。
输入输出样例
输入 #1复制
5 2 7 8 40 64
输出 #1复制
1 0 2 2 3
说明/提示
样例解释:
- 2=2。
- 7 无法被表示为斐波那契乘积。
- 8=8=2×2×2。
- 40=5×8=2×2×2×5。
- 64=8×8=2×2×2×8=2×2×2×2×2×2。
本题使用捆绑测试。
| 子任务编号 | 分值 | 2≤n≤ |
|---|---|---|
| 1 | 15 | 100 |
| 2 | 17 | 105 |
| 3 | 9 | n 是 2 的整数次幂 |
| 4 | 38 | 109 |
| 5 | 21 | 1018 |
对于所有数据,1≤t≤50,2≤n≤1018。
思路
看题目对样例的解析,我们可以知道就是让得到,n如果被分解成只有斐波那契数,那么能被分解的方案有多少个,,,我们可以想象成你在拼拼图,现在有很多拼图(这些拼图都是斐波那契数),找到所有可能的搭配,拼出n,咱们分析一下递归
1,现在当前最大的是斐波那契数是arr[num],如果这个数很大,比你的n还大,那咱就不考虑,直接减小num,然后找到小于等于n的斐波那契数,咱们有两种选择,选或不选这个拼图,如果选,那必须是在这个拼图能被n整除情况下选,剩下情况就是不选,去试试更小的斐波那契数,然后当n等于1也就是拼完了(也就是不用拼了),那就代表咱找到一个方案了,当num=1,说明就剩一个拼图了,这个拼图大小是1(第一个斐波那契数),这时候返回0,因为我们的n不是1,他选这个斐波那契数没用,我们一直能整除他,但永远拼不完图
我用了打表,一班看见斐波那契我就喜欢打表,这个数也不多
#include<bits/stdc++.h>
using namespace std;
#define int long long
vector<int>arr={1,1,2,3,5,8,13,21,34,55,89,144,233,377,610,987,1597,2584,4181,6765,10946,17711,28657,46368,75025,121393,196418,317811,514229,832040,1346269,2178309,3524578,5702887,9227465,14930352,24157817,39088169,63245986,102334155,165580141,267914296,433494437,701408733,1134903170,1836311903};int n;
int dfs(int n,int num){if(n==1) return 1;if(num==1) return 0;while(n<arr[num]){num--;}int ans=0;if(n%arr[num]==0){ans+=dfs(n/arr[num],num);}ans+=dfs(n,num-1);return ans;
}
signed main(){int t;cin>>t;while(t--){cin>>n;cout<<dfs(n,arr.size()-1)<<endl;}}P10386 [蓝桥杯 2024 省 A] 五子棋对弈
题目描述
“在五子棋的对弈中,友谊的小船说翻就翻?” 不!对小蓝和小桥来说,五子棋不仅是棋盘上的较量,更是心与心之间的沟通。这两位挚友秉承着 “友谊第一,比赛第二” 的宗旨,决定在一块 5×5 的棋盘上,用黑白两色的棋子来决出胜负。但他们又都不忍心让对方失落,于是决定用一场和棋(平局) 作为彼此友谊的见证。 比赛遵循以下规则:
- 棋盘规模:比赛在一个 5×5 的方格棋盘上进行,共有 25 个格子供下棋使用。
- 棋子类型:两种棋子,黑棋与白棋,代表双方。小蓝持白棋,小桥持黑棋。
- 先手规则:白棋(小蓝)具有先手优势,即在棋盘空白时率先落子(下棋)。
- 轮流落子:玩家们交替在棋盘上放置各自的棋子,每次仅放置一枚。
- 胜利条件:率先在横线、竖线或斜线上形成连续的五个同色棋子的一方获胜。
- 平局条件:当所有 25 个棋盘格都被下满棋子,而未决出胜负时,游戏以平局告终。
在这一设定下,小蓝和小桥想知道,有多少种不同的棋局情况(终局不同看成不同情况,终局相同而落子顺序不同看成同一种情况),既确保棋盘下满又保证比赛结果为平局。
输入格式
这是一道结果填空题,你只需要算出结果后提交即可。本题的结果为一个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分。
输出格式
这是一道结果填空题,你只需要算出结果后提交即可。本题的结果为一个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分。
输入输出样例
无
思路
这题嘛,明显的回溯,和那个数独,八皇后是一样的,我们只要一行一行下,然后每下一次棋就回溯一次,犹豫这词是两个不同的棋所以要回溯两次,对于之前的数独和八皇后都是一类棋,他们只用回溯一次,然后我们再对每次下棋check一下,算一下总共有多少种方案就行了,这题我就不写了,我看题解都挺好
P10490 Missile Defence System
题目描述
为了对抗附近恶意国家的威胁,R 国更新了他们的导弹防御系统。
一套防御系统的导弹拦截高度要么一直严格单调上升要么一直严格单调下降。
例如,一套系统先后拦截了高度为 3 和高度为 4 的两发导弹,那么接下来该系统就只能拦截高度大于 4 的导弹。
给定即将袭来的一系列导弹的高度,请你求出至少需要多少套防御系统,就可以将它们全部击落。
输入格式
输入包含多组测试用例。
对于每个测试用例,第一行包含整数 n,表示来袭导弹数量。
第二行包含 n 个不同的整数,表示每个导弹的高度。
当输入测试用例 n=0 时,表示输入终止,且该用例无需处理。
输出格式
对于每个测试用例,输出一行,一个整数,表示所需的防御系统数量。
显示翻译
题意翻译
输入输出样例
输入 #1复制
5 3 5 2 4 1 0
输出 #1复制
2
说明/提示
样例解释
对于样例,需要两套系统。一套击落 3,4 号导弹,另一套击落 5,2,1 号导弹。
数据规模与约定
1≤n≤50。
思路
这题我不会哈,我看题解写的,就是构建两个导弹拦截系统,一个up代表上升的系统,记录上升的一串数那个最大的数,一个down代表下降的系统,记录的是下降到一串数最小的那个数,,,,然后dfs搜索就是先一直构建嘛,当然是要判断的,如果比如这个数比当前up拦截系统最大的这个数
#include<bits/stdc++.h>
using namespace std;
#define int long long
const int N=60;
vector<int> up,down;
int arr[N];
int n,ans;
void dfs(int now){int x=up.size(),y=down.size();//两个拦截系统有多少if(x+y>=ans) return;//如果拦截系统比已经记录到的多直接返回就好 if(now>n) {ans=min(x+y,ans);return;}for(int i=0;i<x;i++){if(up[i]<arr[now]){int tmp=up[i];up[i]=arr[now];dfs(now+1);up[i]=tmp;break;}}//构造一个新的拦截系统 if(x==0||up[x-1]>=arr[now]){up.push_back(arr[now]);dfs(now+1);up.pop_back();}//不构造up新的的话,那就开始看看能不能扔进down系统for(int i=0;i<y;i++){if(down[i]>arr[now]){int tmp=down[i];down[i]=arr[now];dfs(now+1);down[i]=tmp;break;}} if(y==0||down[y-1]<=arr[now]){down.push_back(arr[now]);dfs(now+1);down.pop_back();}}
signed main(){while(cin>>n){if(n==0) break;for(int i=1;i<=n;i++){cin>>arr[i];}ans=0x7fffffff;up.clear();down.clear();//多测清空 dfs(1);cout<<ans<<endl; }
}P10477 Subway tree systems
题目描述
一些主要城市的地铁系统采用树状结构,即在任何两个车站之间,只有一条且仅有一条地铁线路。此外,大多数这些城市都有一个独特的中央车站。想象一下,你是这些城市中的一名游客,你想要探索整个地铁系统。你从中央车站出发,随机选择一条地铁线路,跳上地铁列车。每当你到达一个车站,你就会选择一条你尚未乘坐过的地铁线路。如果在当前车站没有其他要探索的地铁线路了,你就会乘坐第一次到达该车站的地铁线路返回,直到最终你沿着所有的线路都行驶了两次,即每个方向都行驶了一次。在那时,你回到了中央车站。之后,你所记得的探索顺序只是在任何给定时间是否向中央车站更远或更近,也就是说,你可以将你的旅程编码为一个二进制字符串,其中 0 表示乘坐一条地铁线路使你离中央车站更远一站,而 1 表示使你离中央车站更近一站。
输入格式
输入的第一行是一个正整数 n,表示接下来要跟随的测试方案的数量。每个测试方案包括两行,每行包含一个长度最多为 3000 的由字符 '0' 和 '1' 组成的字符串,描述了地铁树系统的正确探索旅程。
输出格式
对于每个测试方案,如果两个字符串可以表示相同地铁树系统的探索旅程,则输出 "same";如果两个字符串不能表示相同地铁树系统的探索旅程,则输出 "different"。
翻译来自于:ChatGPT。
显示翻译
题意翻译
输入输出样例
输入 #1复制
2 0010011101001011 0100011011001011 0100101100100111 0011000111010101
输出 #1复制
same different
思路
这个题搞了好久,才算是明白怎么回事,就是现在给你两棵树,用字符串标示量,可能这两棵树的子树们顺序不一样,但整体结构是一样的,这就算是相同的树,那我们现在就需要把他们的子树顺序搞的一样,我们怎么办呢,我们利用树这个结构,他们是天生的递归圣体,我们通过在开头末尾分别加0和1,代表给这个子树加一个根形成新的树,然后存进数组里,然后排序形成新的顺序,当然最开始是先去掉0 1,然后相当于把这个子树的根去掉,然后开始进行操作,最后加01构成新树
字符串操作的意义
-
去掉首尾
0和1:剥离当前根节点A,仅处理其子节点B和C。 -
排序子树:对子节点
B和C的字符串进行排序,消除顺序差异。 -
重组字符串:将排序后的子树重新包裹在
0和1中,形成新的根节点表示。
我这个是看题解,看了好久才懂的(我太笨蛋了哈哈),我之前把题解扔上去了,因为我也对题解做不出什么改变了。
#include<bits/stdc++.h>
using namespace std;
string s1,s2;
void stl(string &s)
{if(s=="01") return;s=s.substr(1,s.size()-2);int st=0,cnt=0;vector<string>vs;vs.clear(); for(int i=0;i<s.size();++i){cnt+=(s[i]=='0'?1:-1);if(!cnt){string ss=s.substr(st,i-st+1);stl(ss);vs.push_back(ss);st=i+1;}}sort(vs.begin(),vs.end());s='0';for(int j=0;j<vs.size();++j) s+=vs[j];s+='1';return;
}
int main()
{int t;scanf("%d",&t);while(t--){cin>>s1;cin>>s2;s1='0'+s1+'1';s2='0'+s2+'1';//方便后面递归stl(s1);stl(s2);if(s1==s2) printf("same\n");else printf("different\n");}return 0;
}P12317 [蓝桥杯 2024 国 C] 树的结点值
题目描述
给定一棵包含 n 个结点的树,其树根编号为 1。我们规定其第 i 个结点的值为其对应的子树内所有与 i 奇偶性相同的结点数量。请按编号从小到大的顺序输出其每个结点的值。
输入格式
输入的第一行包含一个整数 n。
接下来 n−1 行描述每个结点的父结点,其中第 i 行包含一个整数 Fi+1,表示第 i+1 个结点的父结点。
输出格式
输出 n 行,每行包含一个整数表示编号为 i 的结点的值。
输入输出样例
输入 #1复制
5 1 2 1 2
输出 #1复制
3 1 1 1 1
说明/提示
评测用例规模与约定
对于 40% 的评测用例,1≤n≤5000;
对于所有评测用例,1≤n≤2×105,1≤Fi<i。
思路
就是从根节点开始搜,然记录每个节点下面的子树所含有的和自己父节点的奇偶性相同的子树数量,这么长一串可能看不懂哈,就是正常我们记录的是一棵数下面包括自己有多少个节点,但是这里我们记录的是下面与自己节点奇偶性相同的节点有多少个,包括自己也算上,我们用一个二维数组记录,0 1 代表偶和奇
#include<bits/stdc++.h>
using namespace std;
const int N=2e5+10;
struct edge{int to;int next;
}graph[N*2];
int cnt,head[N];
void add_edge(int u,int v){cnt++;graph[cnt].to=v;graph[cnt].next=head[u];head[u]=cnt;
}
int n,arr[N][2];//记录第i个节点下面包括自己的奇数偶数节点有多少个
void dfs(int x,int fa){arr[x][x%2]=1;//for(int i=head[x];i;i=graph[i].next){int to=graph[i].to;if(to==fa) continue;dfs(to,x);arr[x][0]+=arr[to][0];arr[x][1]+=arr[to][1];}
}
int main(){cin>>n;
//读好题,建图别建错for(int i=2;i<=n;i++){int v;cin>>v;add_edge(v,i);add_edge(i,v);}dfs(1,0);for(int i=1;i<=n;i++){cout<<arr[i][i%2]<<endl;}
}