Java—— 集合 Set
Set集合的特点
无序:存取顺序不一致
不重复:可以去除重复
无索引:没有带索引的方法,所以不能使用普通for循环遍历,也不能通过索引来进行操作
Set集合的方法
Set接口中的方法基本上与Collection的API一致。
代码演示
import java.util.HashSet;
import java.util.Set;public class Test1 {public static void main(String[] args) {Set<String> s = new HashSet<>();//Set集合不能重复,添加重复元素时会添加错误,返回falseSystem.out.println(s.add("aaa"));//trueSystem.out.println(s.add("bbb"));//trueSystem.out.println(s.add("ccc"));//trueSystem.out.println(s.add("aaa"));//false//Set集合无序,存入和输出的顺序不一致System.out.println(s);//[aaa, ccc, bbb]}
}Set集合的实现类的特点
HashSet:无序、不重复、无索引
LinkedHashSet:有序、不重复、无索引
TreeSet:可排序、不重复、无索引
引理
哈希表
哈希表是一种对于增删改查数据性能都较好的结构
组成:
JDK8之前:数组+链表
JDK8开始:数组+链表+红黑树
哈希值
根据hashCode方法算出来的int类型的整数
该方法定义在Object类中,所有对象都可以调用,默认使用地址值进行计算
一般情况下,会重写hashCode方法,利用对象内部的属性值计算哈希值
自定义对象的哈希值特点
如果没有重写hashCode方法,不同对象计算出的哈希值是不同的
如果已经重写hashcode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的
HashSet
HashSet底层原理
HashSet集合底层采取哈希表存储数据
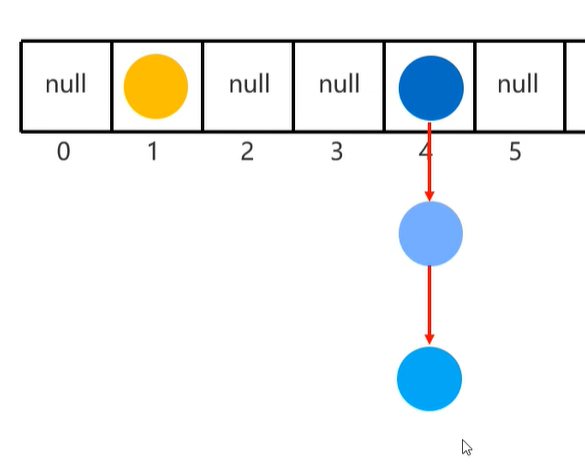
存入元素的底层步骤
1.创建一个默认长度16,默认加载因子0.75的数组,数组名table
2.根据需要存入元素的哈希值跟数组的长度计算出应存入的位置int index = (数组长度-1) & 哈希值;
3.判断当前位置是否为null,如果是null直接存入
4.如果位置不为null,表示有元素,则调用equals方法比较属性值
5.属性值一样:不存,属性值不一样:存入元素,形成链表
JDK8以前:新元素存入数组,老元素挂在新元素下面
JDK8以后:新元素直接挂在老元素下面
注意事项
1.加载因子0.75:当数组中的元素达到数组长度的0.75倍时,数组长度扩容为原先两倍
2.数组某位置形成了链表且还有元素要存入到该位置,需要比较链表上所有元素的属性值,只有都不相同才能存入成功
3.JDK8以后,当链表长度超过8,而且数组长度大于等于64时,自动转换为红黑树
4.如果集合中存储的是自定义对象,必须要重写hashCode和equals方法
底层原理解释HashSet的特点
无序:元素通过哈希值存入,但输出时是从数组0索引开始遍历输出,因此存取顺序不一致
不重复:通过hashCode和equals方法进行约束,元素属性值相同存入失败
无索引:底层采取哈希表存储数据,存在链表
案例练习
利用HashSet集合去除重复元素
需求:创建一个存储学生对象的集合,存储多个学生对象。
要求:学生对象的成员变量值相同,我们就认为是同一个对象,存入失败
Student类
import java.util.Objects;public class Student {private String name;private int age;public Student() {}public Student(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}//重写equals,hashCode方法@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return age == student.age && Objects.equals(name, student.name);}@Overridepublic int hashCode() {return Objects.hash(name, age);}@Overridepublic String toString() {return "Student{" + name + '\'' +", " + age +'}';}
}实现类
import java.util.HashSet;public class Test2 {public static void main(String[] args) {HashSet s = new HashSet<>();Student s1 = new Student("zhangsan", 23);Student s2 = new Student("lisi", 24);Student s3 = new Student("wangwu", 25);Student s4 = new Student("zhangsan", 23);System.out.println(s.add(s1));//trueSystem.out.println(s.add(s2));//trueSystem.out.println(s.add(s3));//trueSystem.out.println(s.add(s4));//falseSystem.out.println(s);//[Student{wangwu', 25}, Student{lisi', 24}, Student{zhangsan', 23}]}
}LinkedHashSet
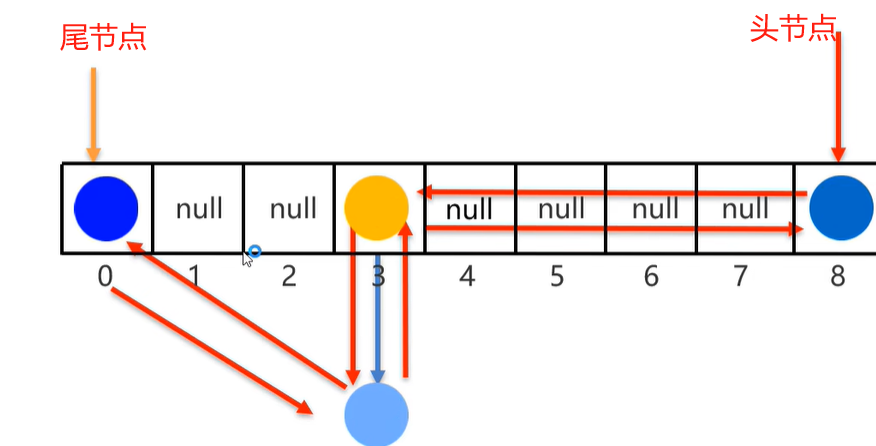
LinkedHashSet底层原理
底层数据结构依然是哈希表,但每个元素又额外多了一个双链表的机制记录存储的顺序。
底层原理解释LinkedHashSet的特点
有序:保证存取元素顺序一致,因为有双链表机制可以从头节点按存入的顺序一直到尾节点
TreeSet
TreeSet底层原理
TreeSet集合底层是基于红黑树的数据结构实现排序的,增删改查性能都较好。
所以在自定义对象的类中不用重写equals和hashCode方法
存入TreeSet集合的数据会进行排序
什么是红黑树
1.每一个节点或是红色的,或者是黑色的
2.根节点必须是黑色
3.如果一个节点没有子节点或者父节点,则该节点相应的指针属性值为Nil,这些Nil视为叶节点,每个叶节点(Nil)是黑色的
4.如果某一个节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连的情况)
5.对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点
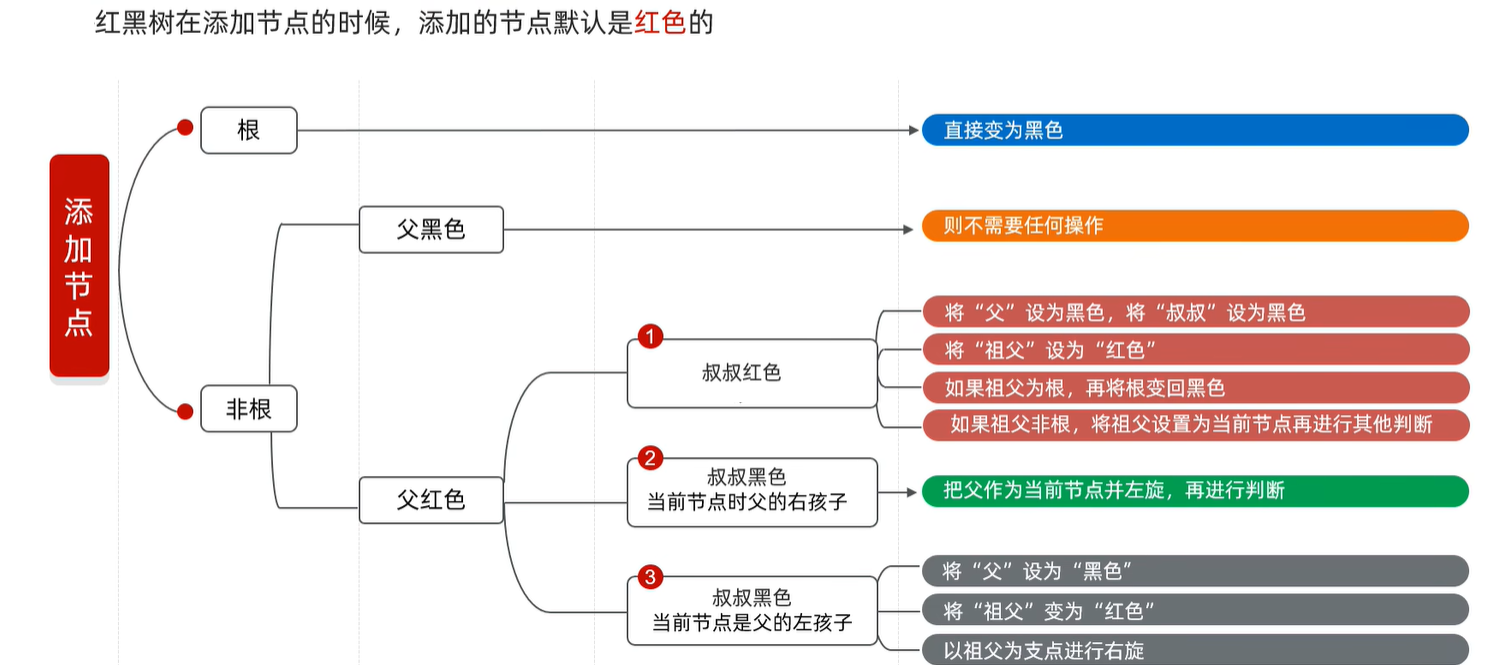
红黑树节点添加规则
TreeSet默认排序规则
String、Integer等类在代码底层已经实现了Comparable接口写好了排序规则
对于数值类型:Integer,Double,默认按照从小到大的顺序进行排序。
对于字符、字符串类型:按照字符在ASCII码表中的数字升序进行排序。
TreeSet自定义排序规则的两种方式
默认排序/自然排序
javabean类实现Comparable接口指定排序规则
自定义对象类在实现Comparable接口后要自定义排序规则
(String、Integer等类在代码底层已经写好了排序规则,也就是默认排序规则)
案例演示
自定义Student类,按照学生年龄升序排序
Student类
public class Student implements Comparable<Student> {private String name;private int age;public Student() {}public Student(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic String toString() {return "Student{" + name + '\'' +", " + age +'}';}//自定义排序规则@Overridepublic int compareTo(Student o) {return this.getAge() - o.getAge();}
}测试类
import java.util.TreeSet;public class Test {public static void main(String[] args) {Student s1 = new Student("zhangsan", 23);Student s2 = new Student("lisi", 24);Student s3 = new Student("wangwu", 25);TreeSet<Student> ts = new TreeSet<>();ts.add(s3);ts.add(s2);ts.add(s1);for (Student s : ts) {System.out.println(s);}//Student{zhangsan', 23}//Student{lisi', 24}//Student{wangwu', 25}}
}this:表示当前要添加的元素
o:表示已经在红黑树中存在的元素
返回值:
负数:认为要添加的元素是小的,存左边
正数:认为要添加的元素是大的,存右边
0:认为要添加的元素已经存在,舍弃
比较器排序
创建TreeSet对象时候,传递比较器Comparator指定规则
案例演示
存入四个字符串,“c”,“ab”,“df”,“qwer”,按照长度排序,如果一样长则按照首字母排序
public class Test3 {public static void main(String[] args) {//存入四个字符串,“c”,“ab”,“df”,“qwer”//按照长度排序,如果一样长则按照首字母排序TreeSet<String> ts = new TreeSet<>(new Comparator<String>() {@Overridepublic int compare(String o1, String o2) {int i = o1.length() - o2.length();i = i == 0 ? o1.compareTo(o2) : i;return i;}});ts.add("c");ts.add("ab");ts.add("df");ts.add("qwer");System.out.println(ts);//[c, ab, df, qwer]}
}o1:表示当前要添加的元素
o2:表示已经在红黑数中存在的元素
返回值规则与默认排序/自然排序相同
注意事项
使用原则:默认使用第一种,如果第一种不能满足当前需求,就使用第二种
如果两种方式都存在,以第二种指定的排序规则排序
各种单列集合的使用场景
1. 如果想要集合中的元素可重复
用ArrayList集合,基于数组的。(用的最多)
2.如果想要集合中的元素可重复,而且当前的增删操作明显多于查询
用LinkedList集合,基于链表的。
3.如果想对集合中的元素去重
用HashSet集合,基于哈希表的。(用的最多)
4.如果想对集合中的元素去重,而且保证存取顺序
用LinkedHashSet集合,基于哈希表和双链表,效率低于HashSet。
5.如果想对集合中的元素进行排序
用TreeSet集合,基于红黑树。后续也可以用List集合实现排序。