LGDRL:基于大型语言模型的深度强化学习在自动驾驶决策中的应用
《Large Language Model guided Deep Reinforcement Learning for Decision Making in Autonomous Driving》2024年12月发表,来自北理工的论文。
深度强化学习(DRL)在自动驾驶决策方面显示出巨大的潜力。然而,由于DRL的学习效率低,它需要大量的计算资源来在复杂的驾驶场景中实现合格的策略。此外,利用人类的专家指导来提高日间行车灯的性能会导致过高的劳动力成本,这限制了其实际应用。在这项研究中,我们提出了一种新的大型语言模型(LLM)引导的深度强化学习(LGDRL)框架,用于解决自动驾驶汽车的决策问题。在此框架内,一位基于LLM的驾驶专家被整合到DRL中,为DRL的学习过程提供智能指导。随后,为了有效地利用LLM专家的指导来提高DRL决策政策的性能,通过创新的专家政策约束算法和新颖的LLM干预交互机制来增强DRL的学习和交互过程。实验结果表明,与最先进的基线算法相比,我们的方法不仅实现了90%任务成功率的卓越驾驶性能,而且显著提高了学习效率和专家指导利用效率。此外,所提出的方法使DRL代理能够在没有LLM专家指导的情况下保持一致和可靠的性能。
研究背景与问题
自动驾驶决策系统需在复杂动态交通场景中生成安全、合理的驾驶行为。传统基于规则的方法适应性不足,而深度强化学习(DRL)虽在决策任务中表现优异,但存在学习效率低和依赖人类专家指导成本高的问题。
-
DRL的局限性:需通过大量环境交互优化策略,在复杂场景中难以积累有效轨迹,导致策略优化缓慢。
-
现有专家指导的不足:依赖人类专家实时干预或演示数据,成本高昂且效率低下。
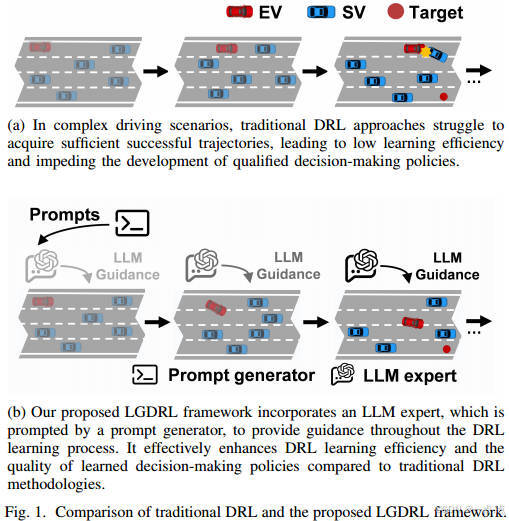
核心贡献
作者提出LLM引导的深度强化学习框架(LGDRL),通过以下创新点解决问题:
-
LLM驾驶专家:替代人类专家,提供低成本、高质量的决策指导。
-
专家策略约束算法:基于Jensen-Shannon(JS)散度的策略约束,限制DRL策略与LLM专家策略的差异,提升知识吸收效率。
-
LLM干预互动机制:允许LLM在训练阶段间歇性干预DRL代理的动作,避免灾难性行为,同时保留自主探索能力。
方法细节
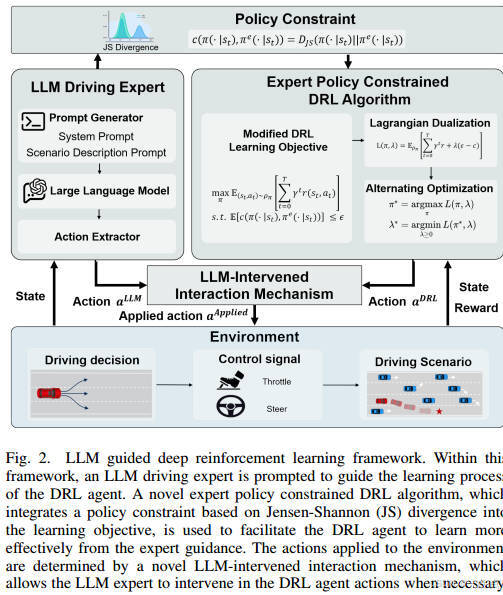
-
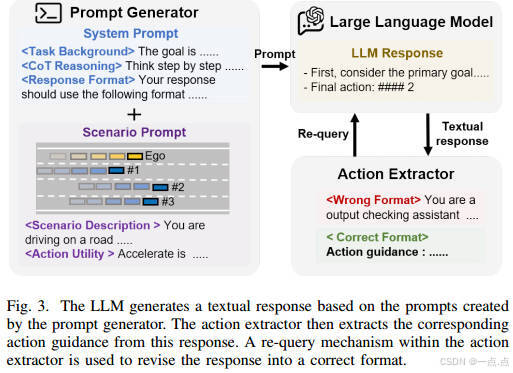
LLM专家构建
-
基于ChatGPT-4o构建,通过提示生成文本响应,提取动作指导。
-
包含重查询机制,确保动作格式正确性。
-
-
专家策略约束算法
-
优化目标:最大化累积奖励,同时约束DRL策略与专家策略的JS散度(公式11-15)。
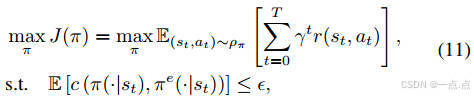
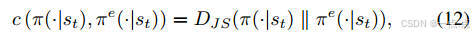
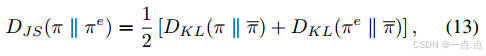
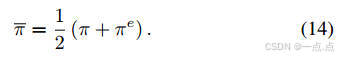
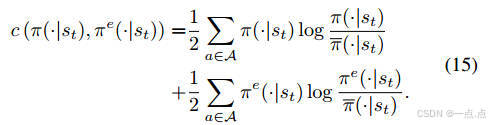
-
实现:结合拉格朗日对偶理论,通过交替优化策略和拉格朗日乘子(公式16-18)。
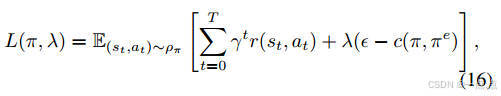
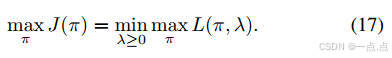
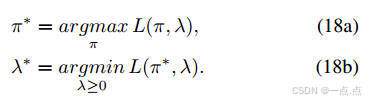
-
策略更新:Actor-Critic框架中,Critic网络评估动作值函数,Actor网络优化策略(公式19-25)。
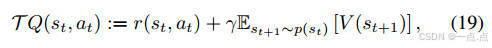
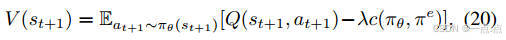
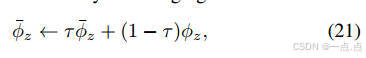
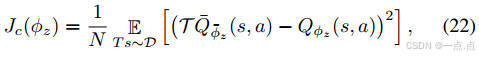
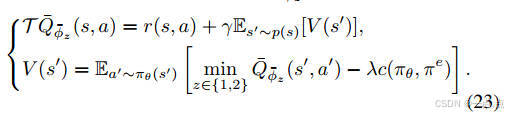
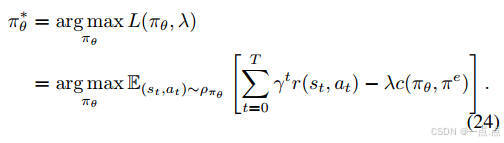
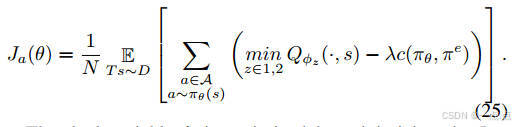
-
-
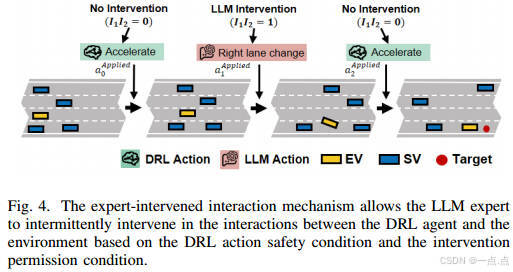
LLM干预机制
-
动作替换条件:基于时间到碰撞(TTC)的安全评估和间歇性干预权限(公式29)。

-
间歇模式:仅在部分训练回合允许干预,平衡专家指导与自主探索。
-
实验与结果
-
实验场景
-
使用
highway-env模拟四车道高速公路,目标为右车道500米处,周围车辆随机生成。 -
对比基线包括Vanilla-SAC、SAC+RP、SAC+BC、SAC+Demo。
-
-
训练性能
-
回报与成功率:LGDRL在218回合内达到基线最大回报,成功率82%,显著优于其他方法(图7)。
-
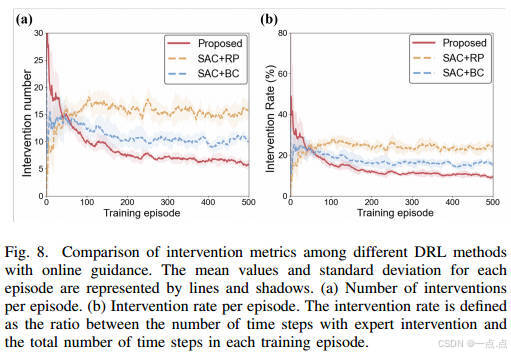
专家指导利用率:干预次数和率最低(图8),表明高效吸收专家知识。
-
-
测试性能
-
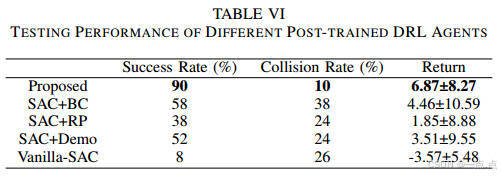
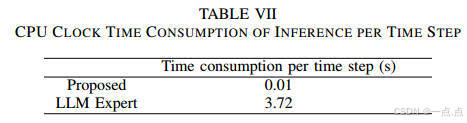
任务成功率90%,碰撞率10%,推理时间仅0.01秒/步,优于LLM专家的3.72秒(表VI-VII)。
-
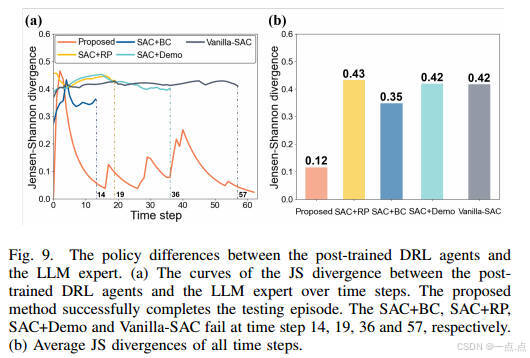
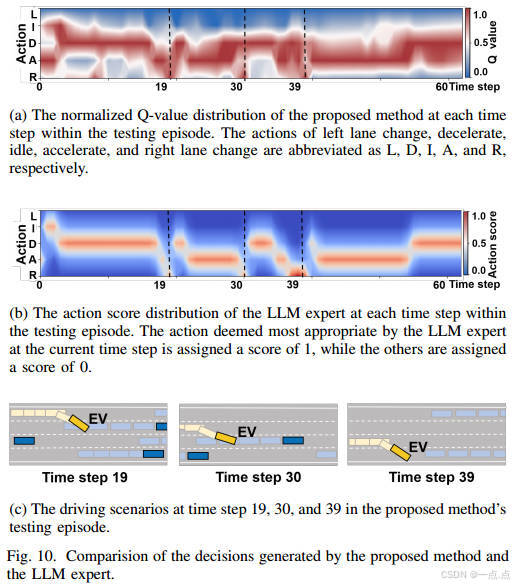
策略一致性:与LLM专家的JS散度最低(0.12),动作选择高度一致(图9-10)。
-
-
干预模式与消融实验
-
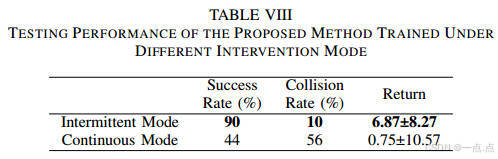
间歇干预优于持续干预,避免过度依赖专家,保持自主探索能力(表VIII)。
-
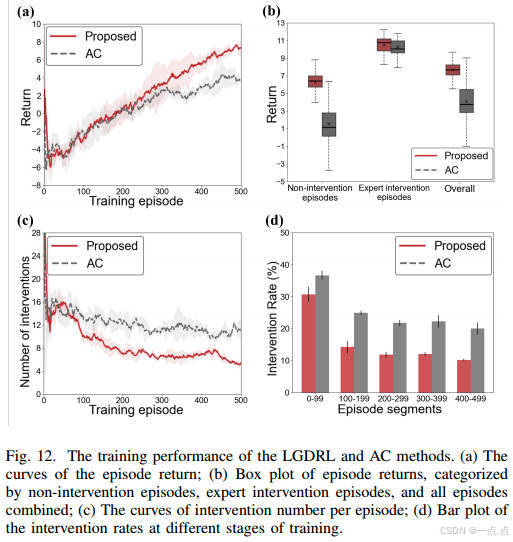
策略约束组件显著提升训练性能,干预需求减少(图12)。
-
创新与不足
创新点:
-
首次将LLM作为专家融入DRL训练闭环,降低对人类专家的依赖。
-
通过策略约束和间歇干预机制,平衡学习效率与自主探索。
潜在不足:
-
LLM专家的安全性与泛化能力需进一步验证,尤其在极端场景(如紧急避障)。
-
实验环境较理想化,未涉及城市道路、行人交互等复杂场景。
-
LLM的实时推理依赖预训练DRL代理,可能限制其动态适应性。
结论与展望
LGDRL框架通过LLM引导DRL,显著提升自动驾驶决策的效率和安全性,任务成功率达90%,且具备实时推理能力。未来可扩展至多车协同、复杂城市道路等场景,并探索LLM与DRL的更深度融合(如多模态输入)。该研究为自动驾驶决策系统提供了一种高效、低成本的新范式。
如果此文章对您有所帮助,那就请点个赞吧,收藏+关注 那就更棒啦,十分感谢!!!