【面试真题】王者荣耀亿级排行榜,如何设计?
目录
一、数据库 order by
二、Redis 的zset
三、抗亿级数据存在的问题
3.1 热点 key 问题
3.1.1 多级缓存(Redis+JVM本地缓存)
3.1.2 读写分离 + 从库负载均衡
3.1.3 分片Key设计
3.2 内存爆炸
3.2.1 缩短键名
3.2.2 分片存储
3.3 数据持久化风险
3.3.1 异步双写
3.3.2 混合持久化
一、数据库 order by
1. 在表数据较少的情况下,推荐使用该做法
2. 如果在数据量比较多的情况下(亿级用户+高并发实时更新):磁盘扛不住、排序算不动、并发撑不起
select * from user_info order by step desc 二、Redis 的zset
当数据量较大且需要实时更新并频繁查询时,使用 Redis 的zset有序集合更为适合。zset是 Redis 提供的一种数据结构,它类似于集合(set),但每个成员都关联着一个分数(score),Redis 使用这个分数来对集合中的成员进行排序。
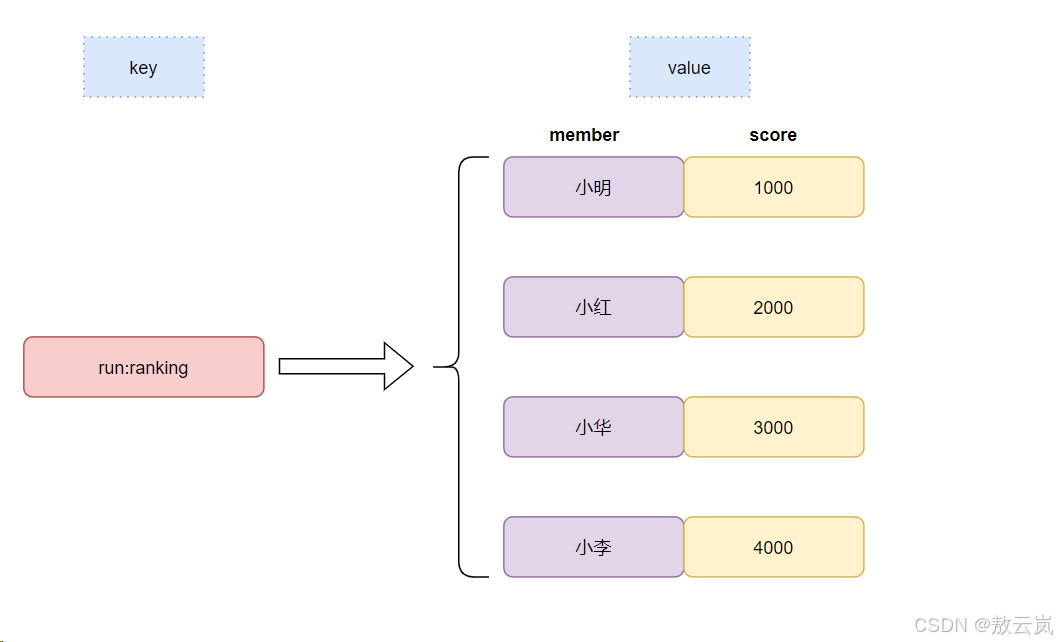 不仅仅是redis的zset支持排序,API简单易用,还因为redis的排序快(基于内存存储)、可扩展性强(通过分片存储可以将数据拆分到多个实例)、能轻松应对高并发(单线程+IO多路复用+内存操作)。
不仅仅是redis的zset支持排序,API简单易用,还因为redis的排序快(基于内存存储)、可扩展性强(通过分片存储可以将数据拆分到多个实例)、能轻松应对高并发(单线程+IO多路复用+内存操作)。
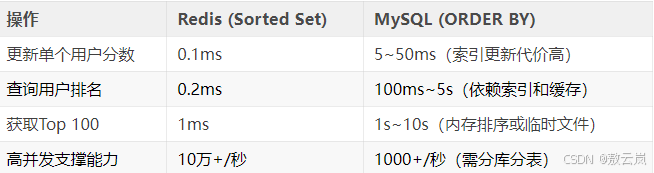
性能对比:
三、抗亿级数据存在的问题
3.1 热点 key 问题
全服玩家频繁查询 ZREVRANGE leaderboard 0 99(获取Top 100),导致所有请求集中访问 同一个Key(leaderboard)。容易导致单分片CPU和带宽被打满(假设数据分片不均匀)。极端情况下Redis实例崩溃,全服排行榜瘫痪
3.1.1 多级缓存(Redis+JVM本地缓存)
-
请求优先读本地内存缓存
-
缓存未命中时读Redis集群
-
Redis集群内部缓存Top 100(设置更短TTL)
3.1.2 读写分离 + 从库负载均衡
主库处理写请求(更新分数)。多个从库轮询处理读请求(查Top 100)
3.1.3 分片Key设计
操作:将排行榜按分数区间拆分成多个Key,例如:
-
leaderboard:top1(前100名)
-
leaderboard:top2(101~1000名)
-
leaderboard:rest(其他用户)
查询逻辑:查Top 100时,只需访问 leaderboard:top1。
3.2 内存爆炸
存储1亿用户,若每个键占32字节(如 user:123),仅键就需约3.2GB,加上分数和指针,内存压力巨大。
3.2.1 缩短键名
缩短键名:将 user:123 转换为整数(如123),利用 Redis 的 int 编码优化内存。
3.2.2 分片存储
分片存储:按用户ID哈希分片到多个 Redis 实例,分散压力。
3.3 数据持久化风险
Redis 宕机可能导致最新数据丢失(即使开启AOF,默认每秒同步一次)。
3.3.1 异步双写
异步双写:更新分数时,同步写入 Kafka,由消费者异步落库 MySQL,用于故障恢复。
3.3.2 混合持久化
混合持久化:开启 RDB + AOF,平衡恢复速度与数据完整性。