《Python星球日记》 第66天:序列建模与语言模型
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
- 一、传统语言模型
- 1. n-gram 模型基础
- 2. n-gram 模型的局限性
- 二、RNN 在语言建模中的应用
- 1. 语言模型的基本原理
- 2. RNN 构建语言模型的优势
- 3. 实现简单的 RNN 语言模型
- 三、数据准备
- 1. 文本预处理与分词
- 2. 嵌入表示(Word Embedding)
- 四、代码练习:基于 RNN 的简单语言生成任务
- 1. 数据集准备
- 2. 模型构建
- 3. 训练与生成文本
- 4. 效果评估与改进
- 五、总结与展望
- 未来学习方向
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》 第65天:词向量与语言表示
大家好,欢迎来到Python星球的第66天!🪐
今天我们将探索序列建模和语言模型的fascinating世界,这是自然语言处理(NLP)领域的核心技术。从传统的n-gram模型到现代的循环神经网络(RNN)应用,我们将全面了解计算机是如何理解和生成人类语言的。
一、传统语言模型
语言模型是自然语言处理的基础,它能预测词序列的概率分布,为机器翻译、语音识别和文本生成等应用提供支持。
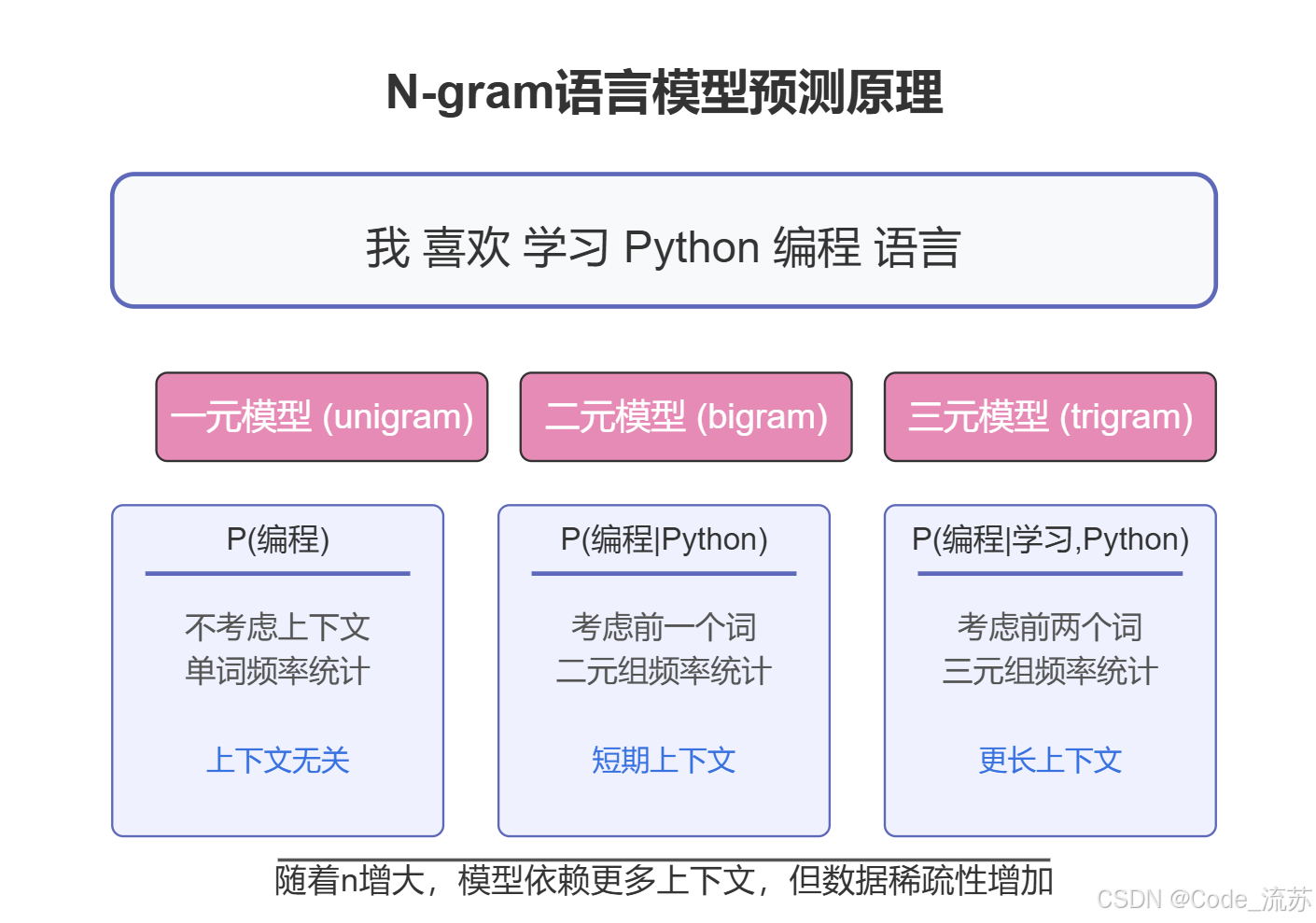
1. n-gram 模型基础
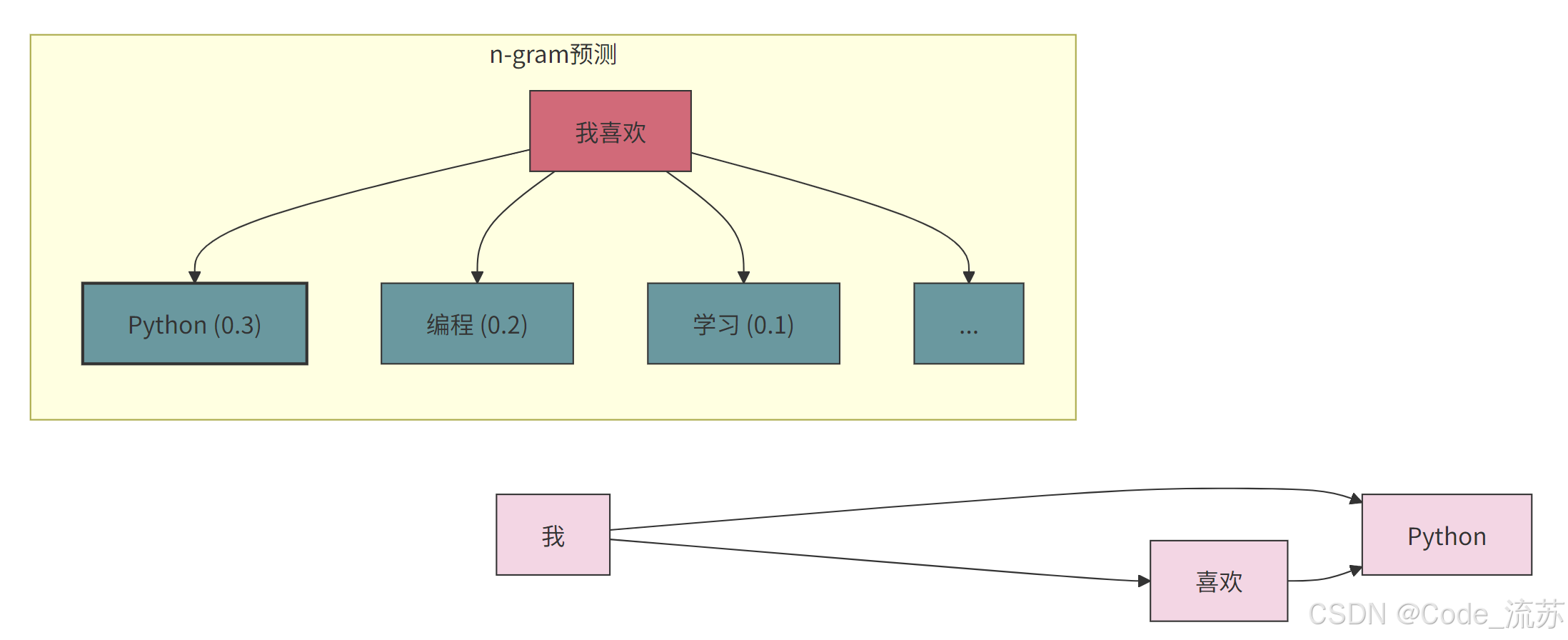
n-gram模型是一种基于统计的语言模型,它通过前n-1个词来预测第n个词出现的概率。具体分类:
- 一元模型(unigram):独立预测每个词,不考虑上下文
- 二元模型(bigram):基于前一个词预测当前词
- 三元模型(trigram):基于前两个词预测当前词
n-gram模型的核心思想可以用条件概率表示:
P(词n | 词1, 词2, ..., 词n-1) =
Count(词1, 词2, ..., 词n) / Count(词1, 词2, ..., 词n-1)
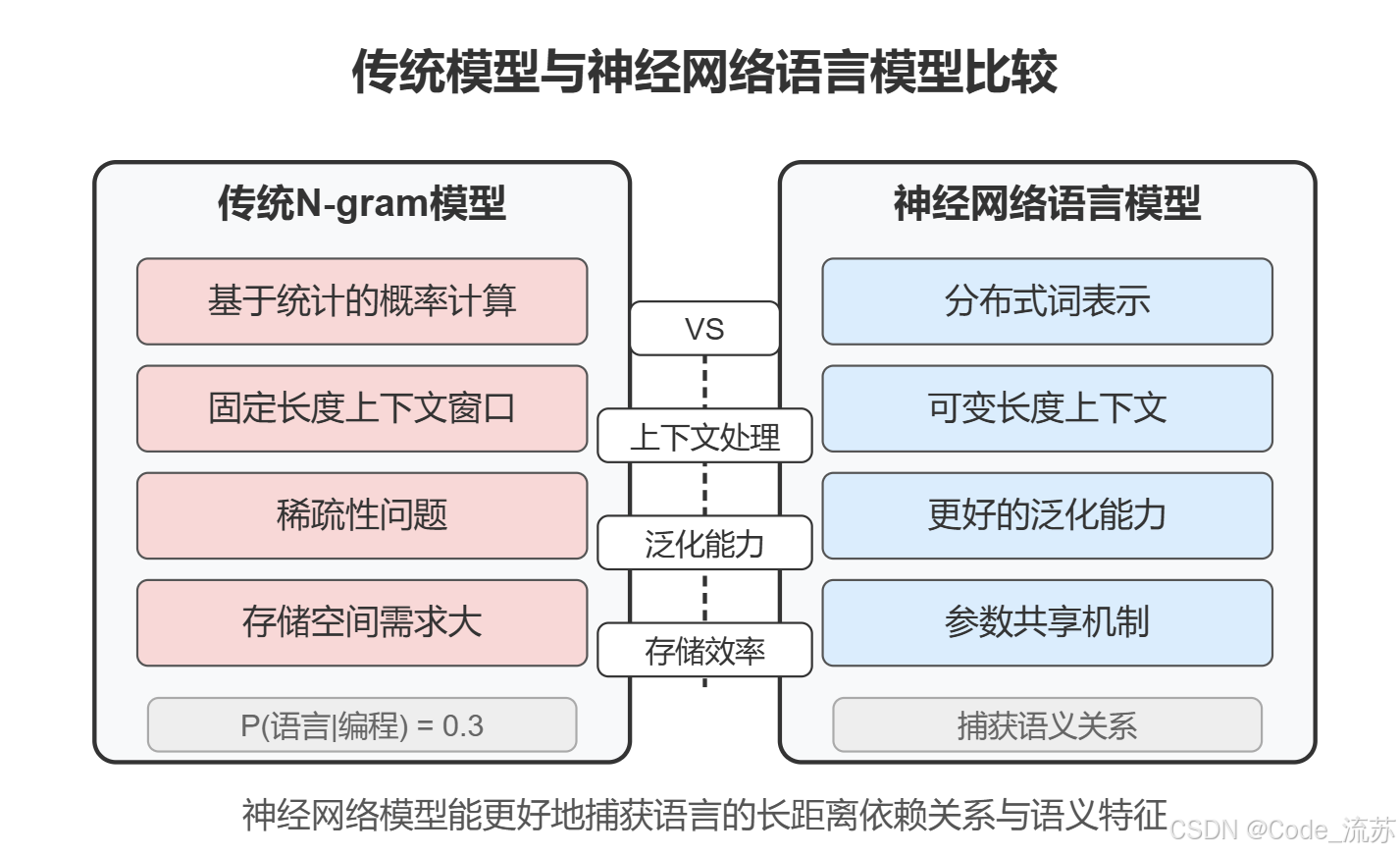
2. n-gram 模型的局限性
尽管简单实用,但n-gram模型存在几个关键限制:
-
稀疏性问题:许多有效的词序列可能在训练数据中从未出现,导致零概率问题。这通常通过平滑技术(如拉普拉斯平滑)来缓解。
-
有限上下文:n-gram模型只考虑固定数量的前序词,无法捕捉长距离依赖关系。例如,"虽然我不喜欢编程,但是我非常喜欢_____"这样的句子,如果n=3,模型就无法利用"虽然"这个重要的上下文信息。
-
内存需求:随着n的增加,可能的n-gram组合数量呈指数级增长,对存储和计算提出了极高要求。
-
缺乏语义理解:这些模型只捕捉词的统计共现关系,而不理解词的实际含义。
二、RNN 在语言建模中的应用
循环神经网络(RNN)通过维护能捕获所有先前单词信息的内部状态,解决了传统n-gram模型的许多限制。
1. 语言模型的基本原理
语言模型本质上是计算一个词序列的概率分布。给定一个词序列w₁, w₂, …, wₙ,语言模型计算:
P(w₁, w₂, ..., wₙ) = P(w₁) × P(w₂|w₁) × P(w₃|w₁,w₂) × ... × P(wₙ|w₁,...,wₙ₋₁)
语言模型训练的目标是最大化训练语料库中观察到的文本概率,从而学习语言的模式和结构。
2. RNN 构建语言模型的优势
RNN相比n-gram模型具有以下几个显著优势:
- 可变长度上下文:理论上RNN可以捕获任意长度的依赖关系,不局限于固定的n。
- 参数共享:在每个时间步应用相同的权重,使模型更高效。
- 分布式表示:RNN使用密集的词向量(嵌入),能捕获词之间的语义关系。
- 更好的泛化能力:神经模型能更有效地泛化到未见过的模式。
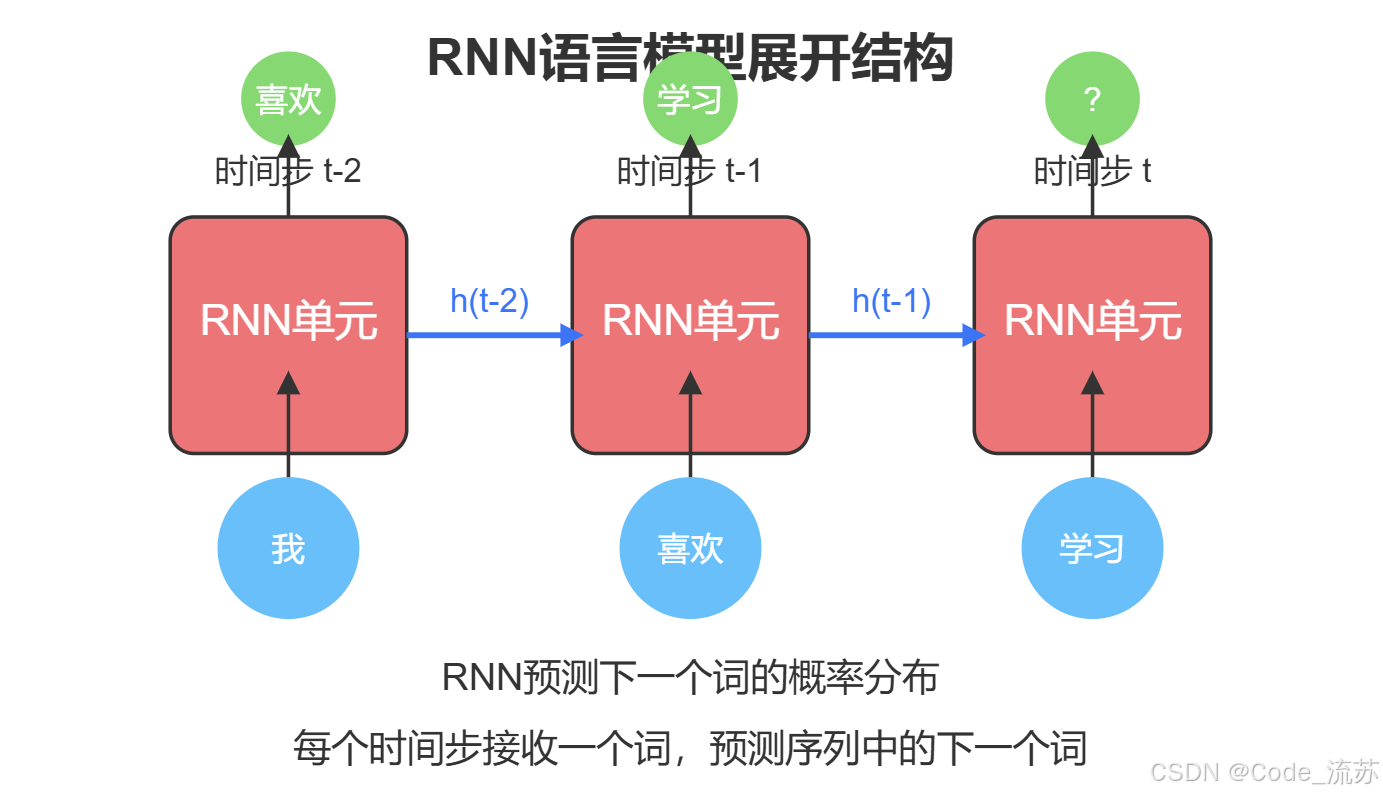
3. 实现简单的 RNN 语言模型
基于RNN的语言模型通常遵循以下工作流程:
- 接收词序列作为输入
- 一个词一个词地处理,不断更新隐藏状态
- 在每一步预测下一个词的概率分布
模型架构通常包括:
- 嵌入层:将词索引转换为向量表示
- 一个或多个RNN层:可以是简单RNN、LSTM或GRU
- 线性层:将输出投影到词汇表大小
- Softmax函数:将输出转换为概率
三、数据准备
准备高质量的数据是训练有效语言模型的关键环节。
1. 文本预处理与分词
文本预处理通常包括以下步骤:
- 清洗文本:移除特殊字符、处理大小写、标准化格式等
- 分词(tokenization):将文本分割成词或子词单元
- 构建词汇表:为每个标记分配唯一索引
- 转换为索引序列:将文本转换为数字序列
对于语言建模任务,输入和目标序列是通过移位创建的:如果输入是[w₁, w₂, …, wₙ₋₁],那么目标就是[w₂, w₃, …, wₙ]。这样模型就能学习预测序列中的下一个词。
2. 嵌入表示(Word Embedding)
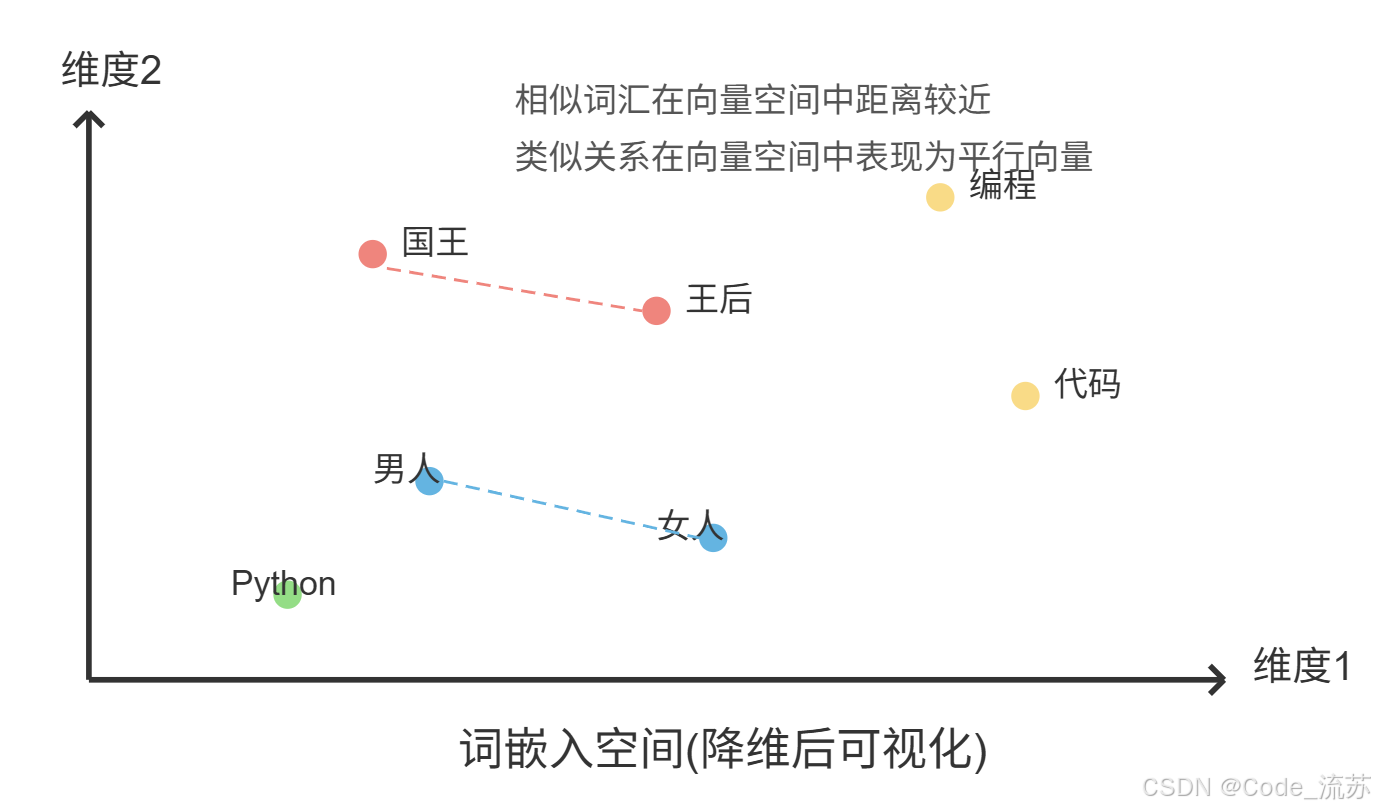
词嵌入是将离散的词转换为连续向量表示的过程,这些向量能捕获词之间的语义关系。常见的嵌入方法包括:
- 独热编码(One-hot encoding):简单但缺乏语义信息,每个词是一个只有一个1,其余都是0的稀疏向量
- Word2Vec:基于词共现创建的嵌入,包括Skip-gram和CBOW两种模型
- GloVe:结合全局矩阵分解与局部上下文的嵌入方法
- FastText:融合了子词信息的嵌入
- 上下文嵌入:来自BERT、GPT等模型的动态词表示
词嵌入帮助语言模型理解词之间的关系,例如"王"与"王后"的关系类似于"男人"与"女人"的关系,这大大提升了模型的泛化能力。
四、代码练习:基于 RNN 的简单语言生成任务
下面我们来实现一个基于字符级别的RNN语言模型,并使用它生成文本。我们将使用PyTorch框架完成这个任务。
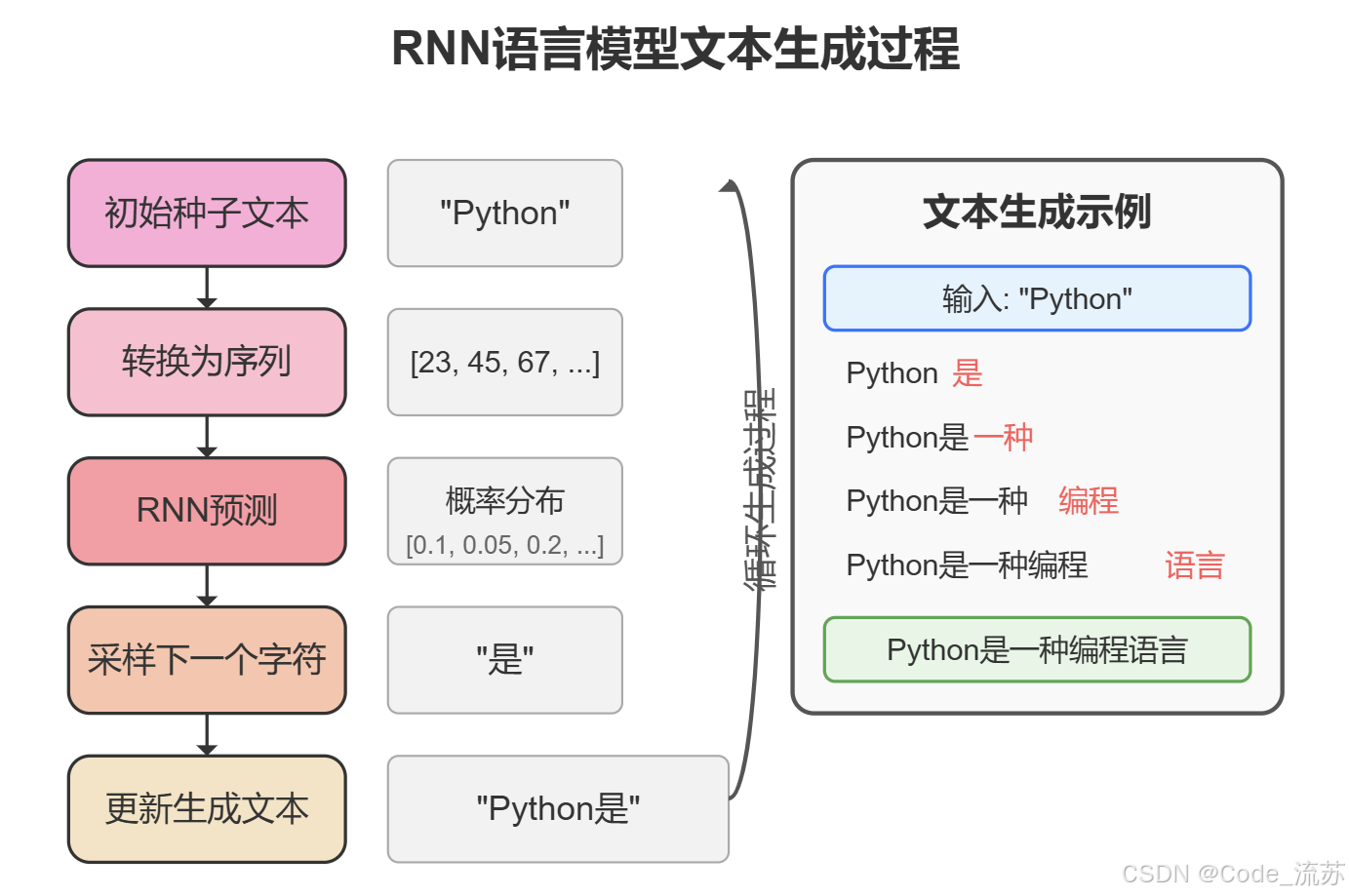
1. 数据集准备
首先,我们需要准备数据:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np# 示例文本(实际应用中可以使用更大的语料库)
text = """
Python是一种编程语言,让你能够快速工作并更有效地集成系统。
Python功能强大且快速,与其他语言配合良好,可在各处运行,并且使用友好。
Python可以用于Web开发、数据分析、人工智能和科学计算等多个领域。
"""# 创建字符到索引的映射和索引到字符的映射
chars = sorted(list(set(text)))
char_to_idx = {ch: i for i, ch in enumerate(chars)}
idx_to_char = {i: ch for i, ch in enumerate(chars)}
vocab_size = len(chars)print(f"词汇表大小: {vocab_size}")
print(f"前10个字符: {chars[:10]}")# 准备序列
seq_length = 20 # 序列长度
x_data = [] # 输入序列
y_data = [] # 目标(下一个字符)for i in range(0, len(text) - seq_length):# 输入是长度为seq_length的序列x_data.append([char_to_idx[c] for c in text[i:i+seq_length]])# 目标是序列后面的下一个字符y_data.append(char_to_idx[text[i+seq_length]])# 转换为PyTorch张量
x_tensor = torch.tensor(x_data, dtype=torch.long)
y_tensor = torch.tensor(y_data, dtype=torch.long)# 创建DataLoader
from torch.utils.data import TensorDataset, DataLoader
dataset = TensorDataset(x_tensor, y_tensor)
loader = DataLoader(dataset, batch_size=32, shuffle=True)
这段代码首先定义了一个小型文本语料库,然后创建了字符和索引之间的映射。接着,我们将文本划分为多个输入序列和对应的目标(每个序列后面的下一个字符)。最后,我们创建了PyTorch的DataLoader用于批量训练。
2. 模型构建
现在,我们构建RNN语言模型:
class CharRNN(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim, n_layers=1):super(CharRNN, self).__init__()# 定义网络层self.embedding = nn.Embedding(vocab_size, embedding_dim) # 嵌入层self.rnn = nn.LSTM(embedding_dim, hidden_dim, n_layers, batch_first=True) # LSTM层self.fc = nn.Linear(hidden_dim, vocab_size) # 全连接层def forward(self, x):# x的形状: (batch_size, seq_length)embeds = self.embedding(x) # (batch_size, seq_length, embedding_dim)rnn_out, _ = self.rnn(embeds) # (batch_size, seq_length, hidden_dim)# 我们只需要最后一个时间步的输出来预测下一个字符output = self.fc(rnn_out[:, -1, :]) # (batch_size, vocab_size)return output# 初始化模型
embedding_dim = 64 # 嵌入维度
hidden_dim = 128 # 隐藏层维度
model = CharRNN(vocab_size, embedding_dim, hidden_dim, n_layers=1)# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
我们的模型包含三个主要部分:
- 嵌入层:将字符索引转换为密集向量
- LSTM层:处理序列并捕获上下文依赖关系
- 全连接层:将LSTM的输出映射到词汇表大小,预测下一个字符的概率
3. 训练与生成文本
接下来,我们训练模型并使用它生成文本:
# 训练模型
epochs = 100
for epoch in range(epochs):total_loss = 0for x_batch, y_batch in loader:# 前向传播output = model(x_batch)loss = criterion(output, y_batch)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()total_loss += loss.item()if (epoch+1) % 10 == 0:print(f'Epoch {epoch+1}, Loss: {total_loss/len(loader):.4f}')# 文本生成函数
def generate_text(model, start_string, length=100):# 将起始字符串转换为索引chars_idx = [char_to_idx[c] for c in start_string]# 生成文本generated_text = start_stringmodel.eval() # 设置为评估模式with torch.no_grad():for _ in range(length):# 准备输入# 如果序列不够长,就用当前所有的字符if len(chars_idx) < seq_length:x = torch.tensor([chars_idx + [0] * (seq_length - len(chars_idx))])else:# 否则就取最后seq_length个字符x = torch.tensor([chars_idx[-seq_length:]])# 前向传播output = model(x)# 获取预测的字符(采用贪婪解码策略)_, predicted = torch.max(output, 1)predicted_idx = predicted.item()# 添加到生成文本generated_text += idx_to_char[predicted_idx]chars_idx.append(predicted_idx)return generated_text# 从"Python"开始生成文本
generated = generate_text(model, "Python")
print(generated)
这段代码完成了两个主要任务:
- 模型训练:在准备好的数据上迭代学习,通过最小化交叉熵损失来优化模型参数
- 文本生成:从给定的起始字符串开始,逐步预测下一个字符,生成连贯的文本
4. 效果评估与改进
我们的简单模型可能存在一些局限性。以下是几种改进方法:
-
使用更多数据:更大、更多样化的语料库能产生更好的语言模型。小规模语料库往往导致模型过拟合,生成的文本缺乏多样性。
-
更复杂的架构:
- 使用LSTM或GRU替代简单RNN,以解决梯度消失问题,捕获更长的依赖关系
- 增加更多层以进行层次化特征提取
- 实现注意力机制,让模型更好地关注相关上下文
-
超参数调优:
- 尝试不同的嵌入维度
- 调整隐藏层大小
- 尝试不同学习率和批量大小
- 加入正则化手段,如Dropout
-
评估指标:
- 困惑度(Perplexity):语言模型的标准评估指标,计算公式为2的交叉熵损失次方
- BLEU分数:用于比较生成文本与参考文本的相似度
- 人工评估:对生成文本的质量、连贯性和多样性进行主观评价
实际生产环境中,还可以考虑使用更高级的技术:
# 使用温度采样提高生成文本的多样性
def generate_with_temperature(model, start_string, length=100, temperature=0.8):chars_idx = [char_to_idx[c] for c in start_string]generated_text = start_stringmodel.eval()with torch.no_grad():for _ in range(length):if len(chars_idx) < seq_length:x = torch.tensor([chars_idx + [0] * (seq_length - len(chars_idx))])else:x = torch.tensor([chars_idx[-seq_length:]])# 获取原始logitslogits = model(x)# 应用温度logits = logits / temperature# 转换为概率分布probs = torch.softmax(logits, dim=1)# 从概率分布中采样predicted_idx = torch.multinomial(probs, 1).item()generated_text += idx_to_char[predicted_idx]chars_idx.append(predicted_idx)return generated_text
通过调整温度参数,我们可以控制生成文本的随机性:温度越低,生成的文本越确定性;温度越高,生成的文本则越多样化但可能变得不连贯。
五、总结与展望
在本文中,我们深入探讨了序列建模和语言模型:
- 我们从传统的n-gram模型出发,了解了它们的工作原理和局限性。
- 我们学习了RNN如何解决这些局限性,构建更强大的语言模型。
- 我们探讨了数据准备,包括分词和词嵌入的重要性。
- 我们实现了一个简单的字符级RNN语言模型,并用它生成文本。
语言建模技术在不断快速发展。现代方法如基于Transformer的模型(如GPT、BERT)已经在很大程度上取代了基于RNN的方法,提供更好的性能和捕获长距离依赖关系的能力。随着您继续Python和机器学习之旅,探索这些高级模型将是自然的下一步。
未来学习方向
- Transformer架构:深入了解自注意力机制和Transformer架构
- 预训练语言模型:研究如何使用和微调GPT、BERT等模型
- 多模态模型:探索文本与图像、音频等其他模态结合的模型
- 强化学习:学习如何通过人类反馈训练语言模型(RLHF)
语言模型的应用几乎无处不在——从智能助手到内容生成,从代码补全到语言翻译。掌握这些技术将使您在AI时代拥有宝贵的技能!
希望这篇文章对您理解序列建模和语言模型有所帮助。明天,我们将继续我们的Python星球之旅,探索更多令人兴奋的领域!
祝你学习愉快,Python星球的探索者!👨🚀🌠
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!