解锁c++模板:从入门到精通
一、为什么有c++模板?
在编程的时候我们可能会遇到一种情况,那就是编写一个功能相同但处理的数据类型不同的函数。比如实现一个交换函数,交换整型数据时,我们通常这样写:
#include<iostream>
using namespace std;
void swap(int& x, int& y)
{int tmp = x;x = y;y = tmp;
}
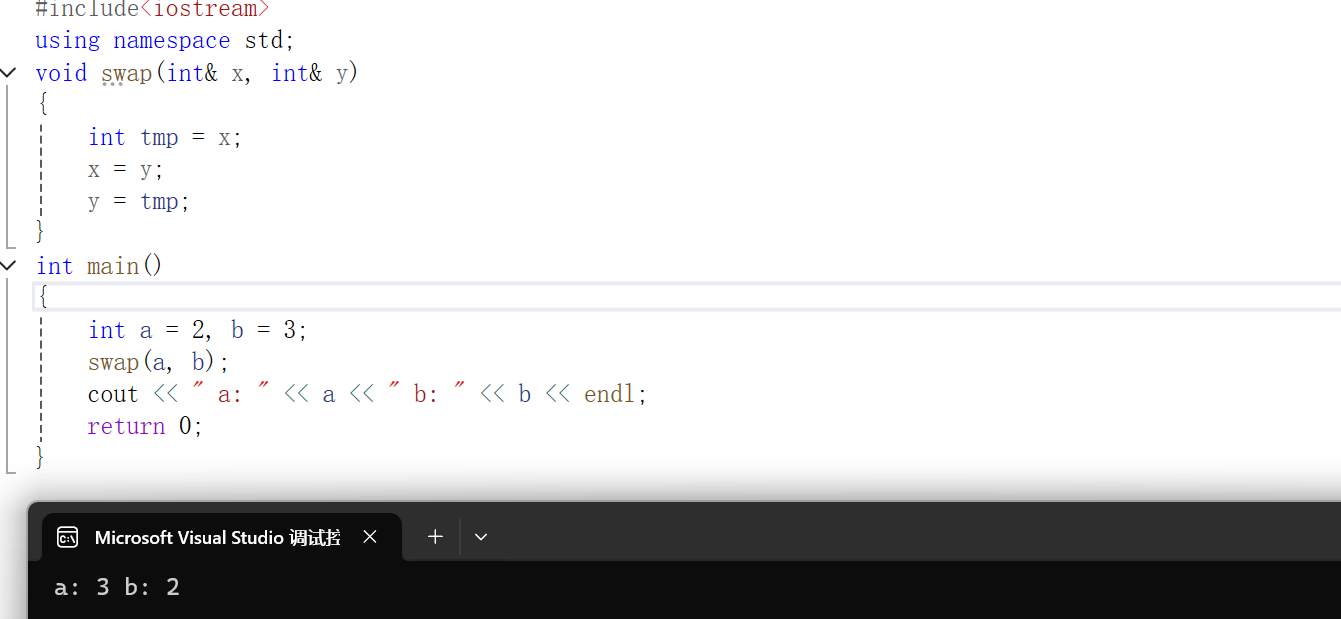
int main()
{int a = 2, b = 3;swap(a, b);cout << " a: " << a << " b: " << b << endl;return 0;
}
但是如果你又要实现一个交换浮点型数据的函数,该怎么办呢,有的人可能会再写一遍函数,如下:
#include<iostream>
using namespace std;
void swap(int& x, int& y)
{int tmp = x;x = y;y = tmp;
}
void swap(float & x, float & y)
{float tmp = x;x = y;y = tmp;
}
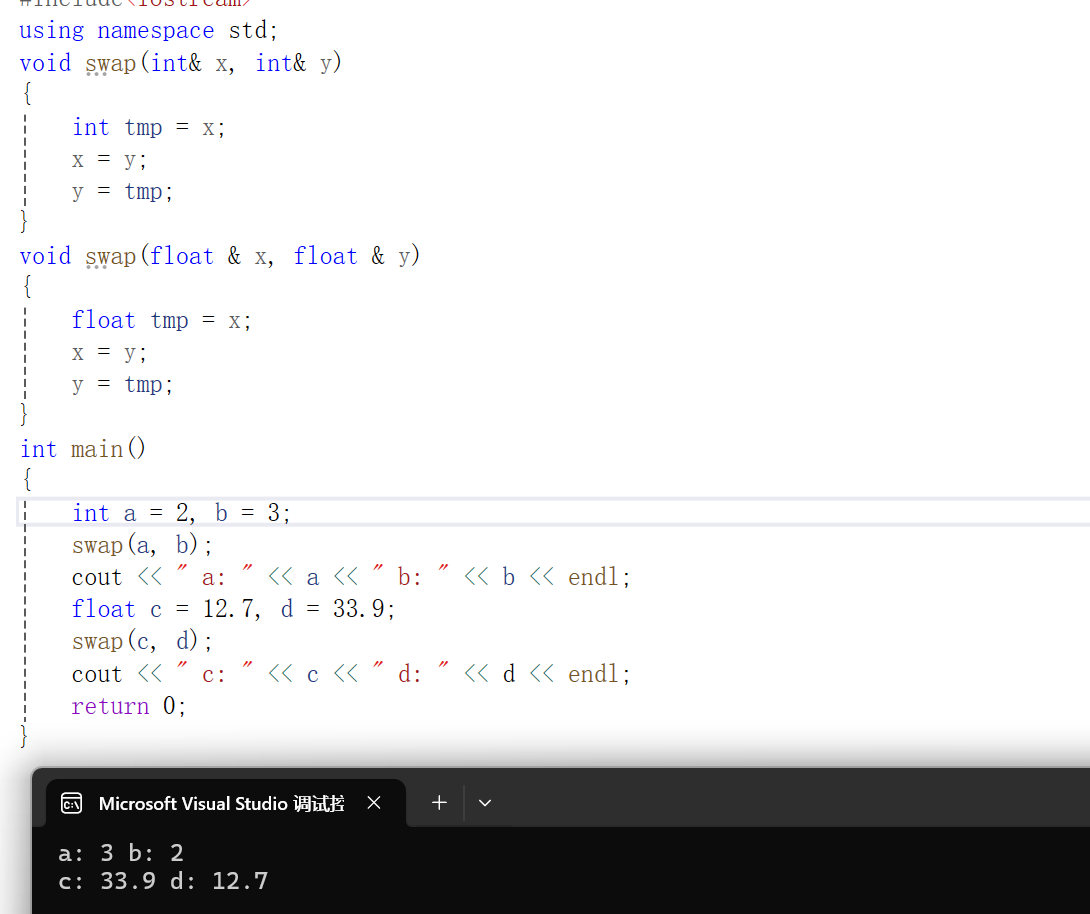
int main()
{int a = 2, b = 3;swap(a, b);cout << " a: " << a << " b: " << b << endl;float c = 12.7, d = 33.9;swap(c, d);cout << " c: " << c << " d: " << d << endl;return 0;
}
这里我们可以发现两个函数除了参数类型不一样,其他逻辑一模一样,因此就有了模板。我们可以用模板来实现一下交换函数:
#include<iostream>
using namespace std;
template<class T>
void myswap(T & x, T& y)
{T tmp = x;x = y;y = tmp;
}
int main()
{int a = 2, b = 3;myswap(a, b);cout << " a: " << a << " b: " << b << endl;float c = 12.7, d = 33.9;myswap(c, d);cout << " c: " << c << " d: " << d << endl;return 0;
}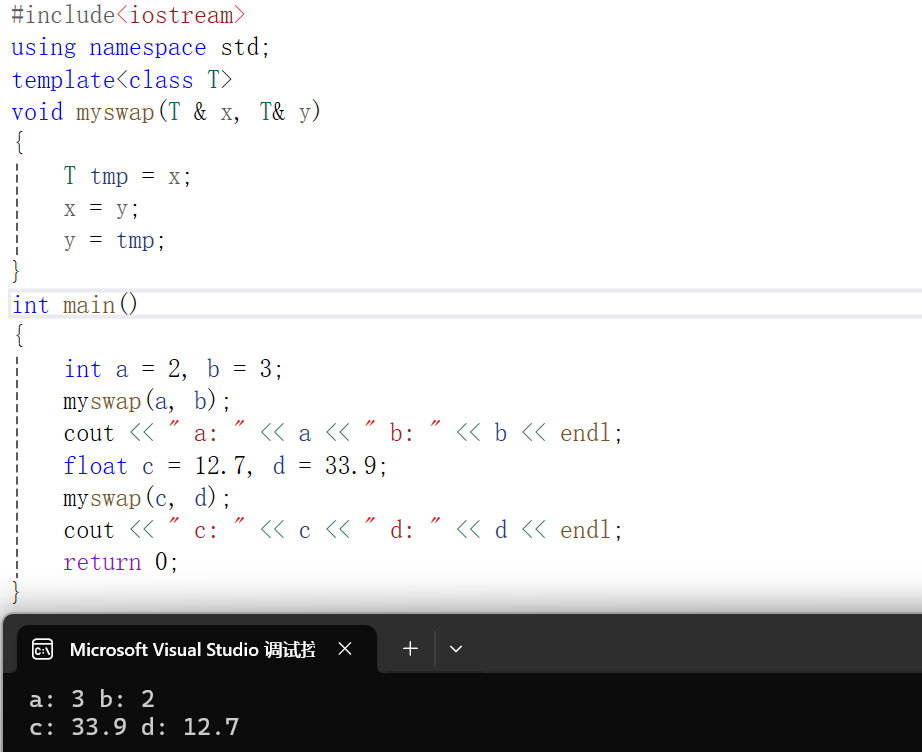
在上面这段代码中template<class T> 表示 T可以代表任意一种数据类型,我们再用T定义一个临时变量,这样就轻松实现了任意相同数据类型的变量的交换函数。调用这个函数只要像调用普通函数一样调用即可,编译器会自动推导变量类型,从而生成相应的函数。
由此可见c++模板的重要性,让我们编写一次代码,便可实现多个函数。
二、模板基础
1.函数模板
在 C++ 中,函数模板就像是一个函数的 “蓝图”,它允许我们编写一个通用的函数,这个函数可以处理多种不同的数据类型,而不需要为每种数据类型都编写一个单独的函数。这样可以大大提高代码的复用性和可维护性。格式如下:
template <typename T>
返回类型 函数名(参数列表) {// 函数体
}其中template <typename T>是模板声明,typename 关键字用于声明模板参数T,这里typename也可以用class 替代,作用都是一样的,看个人习惯。然后我们在函数体内用T定义变量,参数,返回值等。如下面的代码:
#include<iostream>
using namespace std;
template<class T>
void myswap(T & x, T& y)
{T tmp = x;x = y;y = tmp;
}
int main()
{int a = 2, b = 3;myswap(a, b);cout << " a: " << a << " b: " << b << endl;float c = 12.7, d = 33.9;myswap(c, d);cout << " c: " << c << " d: " << d << endl;return 0;
}在这里编译器会根据传入参数的类型来推导T,如第一次调用是传入的a,b 都是int 类型,则推导T为int ,第二次调用时由于c,d 均是float类型,则推导T为float。从而分别实例化各自的函数。
2.类模板
类模板是C++模板编程里另一个重要部分,它允许我们定义一个通用的类操作多种数据类型的类,这样就不用为每个数据类型单独定义一个类。格式如下:
template<class T1,class T2,...>
class mymap {};这里template<class T1,class T2,...>就是模板参数,和函数模板一样,这里T1,T2可以代表任意一种数据类型,并且你也可以定义多个模板参数,就是可以有T3,T4等,需要几个写几个。下面我们简单定义一个栈类:
template<class T>
class mystack
{mystack(int capacity=10):_arr(new T[capacity]),_capacity(capacity),_size(0)~mystack(){delete[] _arr;}void push(const T& val){if (_size == _capacity){_capacity *= 2;_arr = new T[_capacity];}_arr[_size++] = val;}void pop() {if (_size == 0)return;else_size--;}T top() {if (_size >= 0){return _arr[_size-1];}return T();}bool empty(){return _size == 0;}size_t size() {return _size;}private:T* _arr;int _capacity;int _size;
};在这个栈类模板中,T 是模板参数,代表栈中存储的数据类型。通过这个类模板,我们可以创建出存储不同类型数据的栈,如 mystack<int> 用于存储整数,mystack<double> 用于存储浮点数等。
三、模板进阶用法
1.非类型模板参数
c++编程中,除了模板参数,还有非类型模板参数,就是用一个常量作为参数,在模板中把他当作一个常量来使用。类如:
namespace my_namespace {template <typename T, size_t N = 10>class StaticArray {public:StaticArray() : _size(0) {}void PushBack(const T& value) {if (_size < N) {_array[_size++] = value;}}T& operator[](size_t index) {return _array[index];}const T& operator[](size_t index) const {return _array[index];}size_t Size() const {return _size;}private:T _array[N];size_t _size;};
}在这个 StaticArray 类模板中,T 是类型模板参数,表示数组中元素的类型,N 是非类型模板参数,表示数组的大小,并且它有一个默认值 10。因此我们在初始化时也可以指定数组的大小。
2.模板的特化
在 C++ 模板编程中,模板特化是一个非常重要的概念。它允许我们在原模板的基础上,针对特殊类型进行特殊化的实现,以满足不同场景下的需求。模板特化的概念源于这样一种情况:通常情况下,使用模板可以实现一些与类型无关的代码,但对于一些特殊类型,可能会得到一些错误的结果,需要特殊处理 。例如,我们有一个简单的比较函数模板。
template <typename T>
bool Compare(T left, T right) {return left < right;
}这个函数模板在大多数情况下都能用,比如比较整型和浮点型数据。
#include<iostream>
using namespace std;
template <typename T>
bool Compare(T left, T right) {return left < right;
}int main() {int a = 10, b = 20;std::cout << Compare(a, b) << std::endl; // 输出1,结果正确double c = 3.14, d = 2.718;std::cout << Compare(c, d) << std::endl; // 输出0,结果正确return 0;
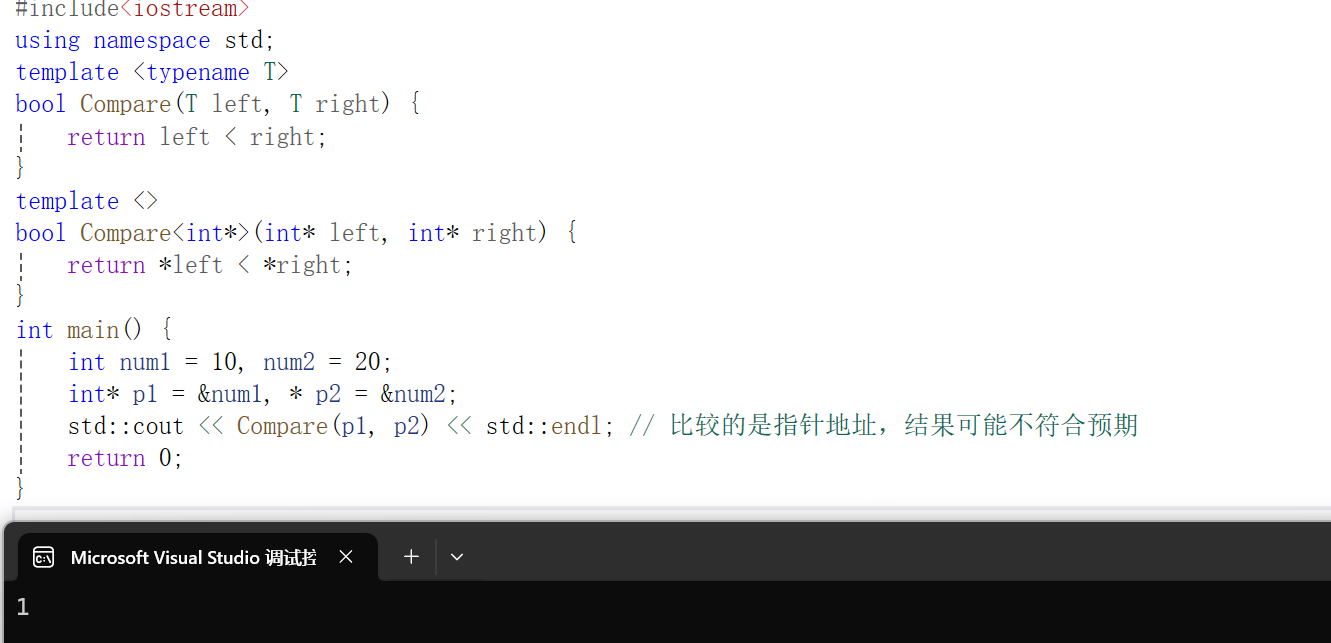
}但是当我们尝试比较指针时就会出现问题:
#include<iostream>
using namespace std;
template <typename T>
bool Compare(T left, T right) {return left < right;
}
int main() {int num1 = 10, num2 = 20;int* p1 = &num1, *p2 = &num2;std::cout << Compare(p1, p2) << std::endl; // 比较的是指针地址,结果可能不符合预期return 0;
}在这种情况下,我们期望比较的是指针所指向的内容,而不是指针的地址。这时候,就需要对模板进行特化。
函数模板特化的步骤如下:首先,必须要先有一个基础的函数模板,这是特化的基础。然后,关键字 template 后面接一对空的尖括号 <>,表示这是一个特化版本。接着,函数名后跟一对尖括号,尖括号中指定需要特化的类型。函数形参表必须要和模板函数的基础参数类型完全相同,如果不同编译器可能会报一些奇怪的错误 。
下面是对 Compare 函数模板进行特化的示例:
#include<iostream>
using namespace std;
template <typename T>
bool Compare(T left, T right) {return left < right;
}
template <>
bool Compare<int*>(int* left, int* right) {return *left < *right;
}
int main() {int num1 = 10, num2 = 20;int* p1 = &num1, *p2 = &num2;std::cout << Compare(p1, p2) << std::endl; // 比较的是指针地址,结果可能不符合预期return 0;
}
要注意,一般来说呢,如果函数模板碰到它搞不定或者处理出错的类型,为了图个简单,通常都是直接把函数写出来,而不是去做函数模板特化。为啥呢?因为有些参数类型特别复杂的函数模板,在特化的时候直接给出函数,代码读起来更清楚,写起来也更轻松。比如说,我们可以直接定义一个比较int*类型的函数:
bool Compare(int* left, int* right) {return *left < *right;
}这样的实现方式简单明了,与函数模板特化相比,可能更易于理解和维护。
类模板特化又分为全特化和偏特化。全特化即是将模板参数列表中所有的参数都确定化 。例如,我们有一个通用的类模板 Data:
template <class T1, class T2>
class Data {
public:Data() {std::cout << "Data<T1, T2>" << std::endl;}
private:T1 _d1;T2 _d2;
};对其进行全特化:
template <>
class Data<int, char> {
public:Data() {std::cout << "Data<int, char>" << std::endl;}
private:int _d1;char _d2;
};在这个全特化版本中,T1 被确定为 int,T2 被确定为 char。当我们实例化 Data<int, char> 时,就会使用这个全特化版本:
int main() {Data<int, char> d; // 调用全特化版本,输出Data<int, char>return 0;
}偏特化则是任何针对模版参数进一步进行条件限制设计的特化版本 。它有两种表现方式,一种是部分特化,即将模板参数类表中的一部分参数特化。例如,将 Data 类模板的第二个参数特化为 int:
template <class T1>
class Data<T1, int> {
public:Data() {std::cout << "Data<T1, int>" << std::endl;}
private:T1 _d1;int _d2;
};另一种是参数更进一步的限制,比如将两个参数偏特化为指针类型或引用类型:
template <typename T1, typename T2>
class Data<T1*, T2*> {
public:Data() {std::cout << "Data<T1*, T2*>" << std::endl;}
private:T1* _d1;T2* _d2;
};
template <typename T1, typename T2>
class Data<T1&, T2&> {
public:Data(const T1& d1, const T2& d2) : _d1(d1), _d2(d2) {std::cout << "Data<T1&, T2&>" << std::endl;}
private:const T1& _d1;const T2& _d2;
};通过这些偏特化的方式,我们可以根据不同的需求对类模板进行更细致的定制。例如,在某些情况下,我们可能需要对指针类型的数据进行特殊处理,就可以使用指针类型的偏特化版本;而对于引用类型的数据,也可以通过引用类型的偏特化来实现特定的功能。
三、模板编译分离
在 C++ 编程中,分离编译是一种常见的编程模式。一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链接起来形成单一的可执行文件的过程称为分离编译模式 。这种模式有助于提高代码的可维护性和可读性,使得项目的结构更加清晰。
然而,当涉及到模板时,分离编译却会遇到一些问题。假设我们有一个模板函数的声明在头文件 a.h 中,定义在源文件 a.cpp 中,如下所示:// a.h
template <typename T>
T Add(const T& left, const T& right);
// a.cpp
template <typename T>
T Add(const T& left, const T& right) {
return left + right;
}
在 main.cpp 中,我们包含了 a.h 并调用 Add 函数:
// main.cpp
#include "a.h"
int main() {
Add(1, 2);
Add(1.0, 2.0);
return 0;
}
当我们尝试编译这个项目时,会发现链接阶段报错,提示找不到 Add 函数的定义。这是因为模板函数只有在被调用时才会进行实例化 ,而在分离编译的情况下,编译器在编译 main.cpp 时,虽然知道 Add 函数的声明,但由于定义在 a.cpp 中,编译器无法在此时实例化出具体的函数版本。在编译 a.cpp 时,又没有实际的调用,所以也不会实例化。这样一来,在链接阶段,链接器就找不到对应的函数定义,从而导致链接错误。
为了解决模板分离编译的问题,有以下两种常见的方法。一种方法是将声明和定义放到一个文件 “xxx.hpp” 里面,或者使用 .h 文件也是可以的 。这种方法是比较推荐的,因为它简单直接,能够确保编译器在实例化模板时可以找到完整的定义。例如,我们可以将 a.h 和 a.cpp 的内容合并到 a.hpp 中:
// a.hpp
template <typename T>
T Add(const T& left, const T& right) {return left + right;
}在 main.cpp 中,只需包含 a.hpp 即可正常调用 Add 函数:
// main.cpp
#include "a.hpp"int main() {Add(1, 2);Add(1.0, 2.0);return 0;
}另一种方法是在模板定义的位置显式实例化,但这种方法不实用,不推荐使用 。显式实例化需要在代码中明确指定模板参数的类型,让编译器提前生成对应的实例。例如,在 a.cpp 中显式实例化 Add 函数:
// a.cpp
template <typename T>
T Add(const T& left, const T& right) {return left + right;
}// 显式实例化
template int Add<int>(const int& left, const int& right);
template double Add<double>(const double& left, const double& right);这种方法的缺点是,如果需要支持多种类型,就需要手动显式实例化每一种类型,代码量会大幅增加,而且不够灵活。一旦有新的类型需要支持,就需要修改代码并重新编译。所以,在实际应用中,除非有特殊需求,否则不建议使用这种方法来解决模板分离编译的问题。
好了,今天的分享就到这里了,下次我会讲解map 和set。