AAAI-2025 | 视觉定位的深度语义对齐!SSRVG:基于内容与结构信息的视觉定位


-
作者:Shiyi Zheng, Peizhi Zhao, Zhilong Zheng, Peihang He, Haonan Cheng, Yi Cai, Qingbao Huang
-
单位:广西大学电气工程学院,中国传媒大学媒体融合与传播国家重点实验室,华南理工大学大数据与智能机器人教育部重点实验室,广西多媒体通信与网络技术重点实验室
-
论文标题:Look Around Before Locating: Considering Content and Structure Information for Visual Grounding
-
论文链接:https://ojs.aaai.org/index.php/AAAI/article/view/32158/34313
-
代码链接:https://github.com/VILAN-Lab/SSRVG
主要贡献
-
提出了一种半结构化推理框架(SSRVG):用于视觉定位任务,通过逐步理解语言内容和结构,有效弥合视觉和语言模态之间的语义差距。
-
设计了跨模态内容对齐模块(CCA):利用CLIP提供的先验知识,对视觉和语言特征进行细粒度对齐,纠正了以往方法中因语义空间不一致导致的对齐偏差。
-
提出了多分支调制定位模块(MML):通过软拆分机制将表达式分解为主体和上下文两个半结构,利用语言结构信息调制定位过程,解决了传统方法中对主体过度依赖的问题,提升了模型对复杂表达式的理解能力。
-
实验验证了方法的有效性:在五个广泛使用的数据集上,该方法均取得了性能提升,优于现有的单阶段和基于Transformer的先进方法,并且与一些预训练模型和大型模型相当。
研究背景
视觉定位(Visual Grounding)是计算机视觉和自然语言处理领域的一个重要任务,其目标是根据自然语言查询在图像中定位目标对象。这项任务在视觉语言导航、图像描述生成和视觉问答等下游任务中具有重要作用。然而,现有的方法在理解和定位过程中存在一些问题:
-
语义对齐不充分:由于缺乏足够的标注信息,模型难以建立视觉和语言特征之间准确的语义对齐,导致模型只能学习到表面的语义关联,无法深入理解语言表达的真正含义。
-
语言结构未充分利用:语言表达通常包含目标主体和上下文信息,但现有方法大多未能有效利用这些结构信息,而是简单地将语言表达作为一个整体进行处理,容易导致定位偏差。
-
单阶段方法的局限性:单阶段方法虽然避免了两阶段方法中累积误差的问题,但由于其依赖预定义的密集锚点,预测的灵活性和准确性受到限制。
研究方法
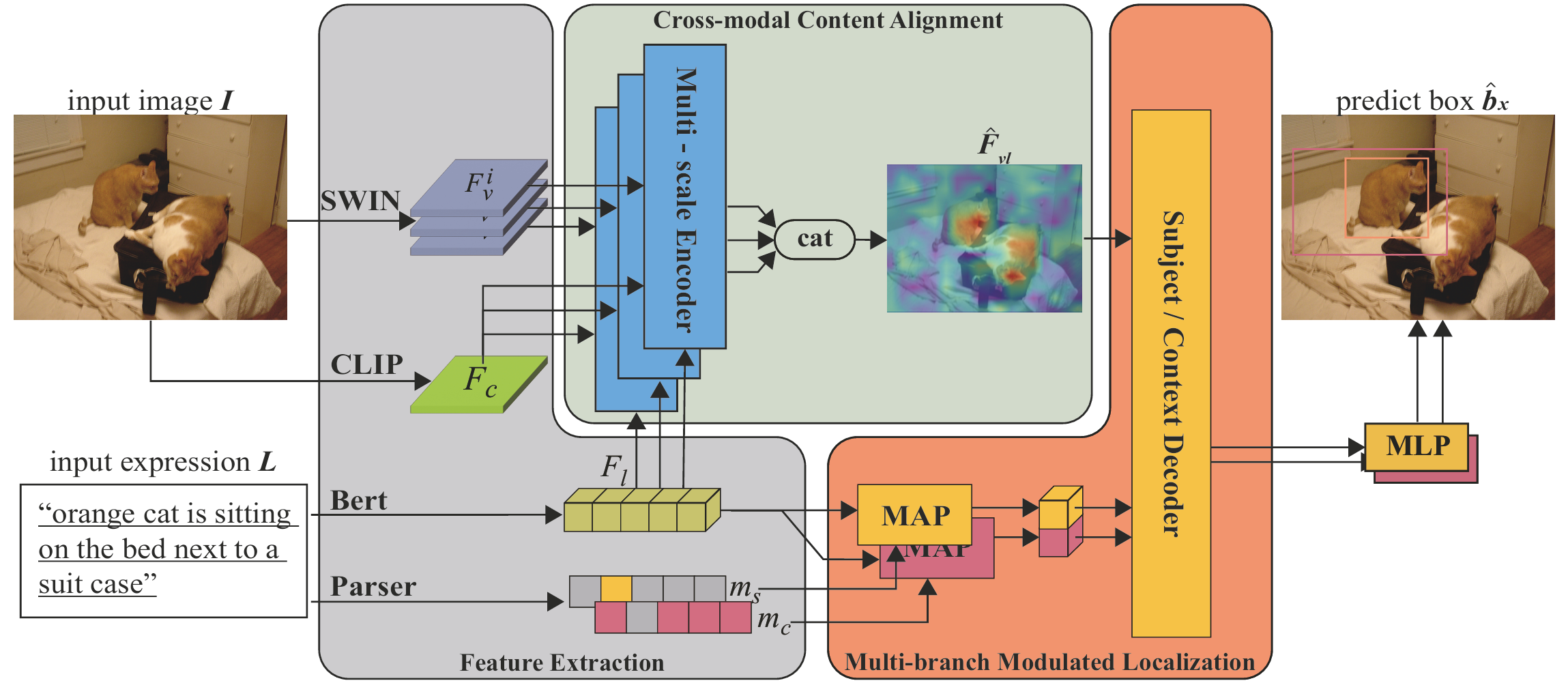
半结构化推理框架
该框架基于Transformer架构,包含三个主要组件:用于特征提取的视觉和语言分支、跨模态内容对齐模块(CCA)和多分支调制定位模块(MML)。
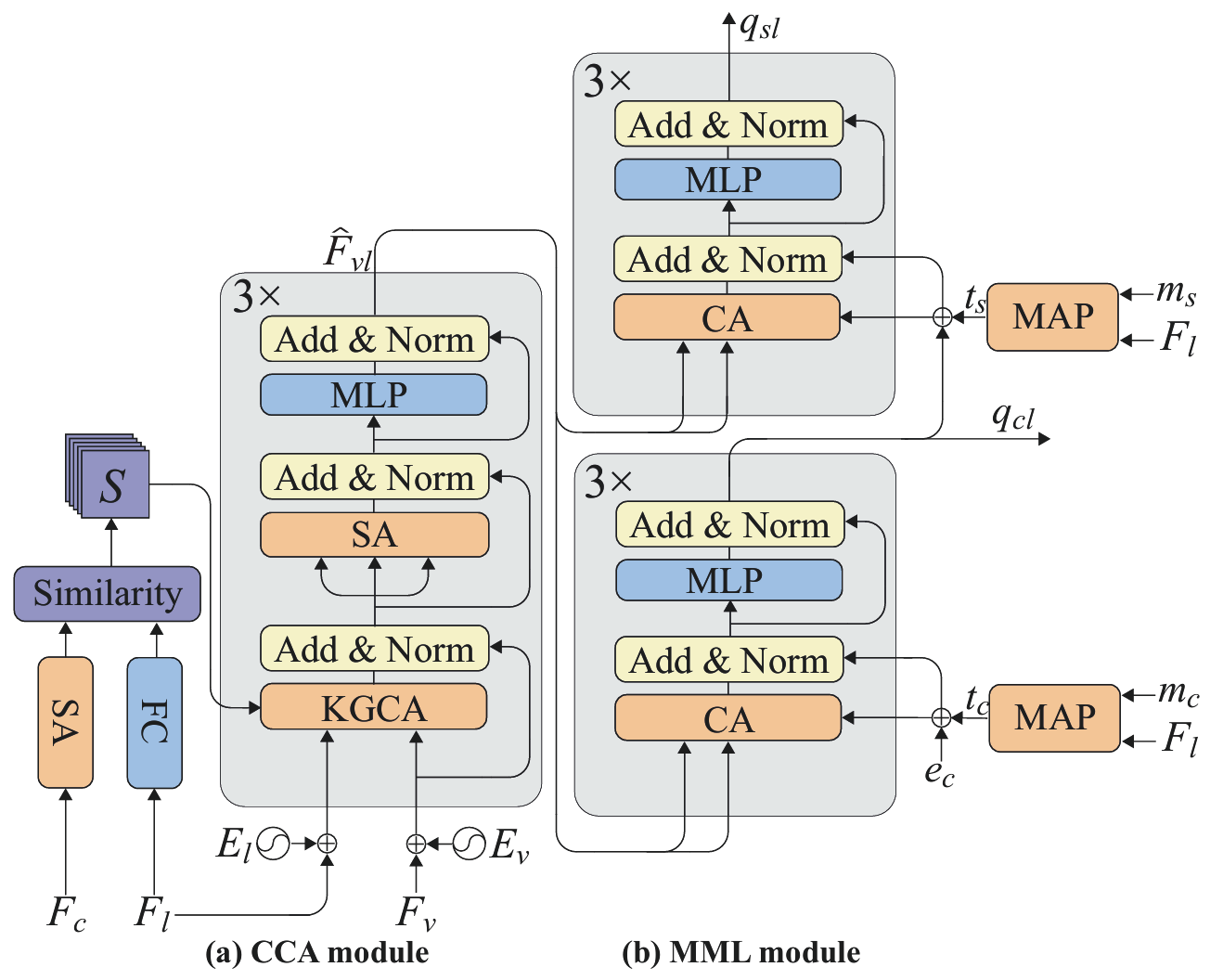
跨模态内容对齐模块(CCA)
-
多尺度特征提取:使用Swin Transformer提取多尺度视觉特征,并通过特征金字塔网络将它们投影到同一维度。
-
知识引导的交叉注意力机制:利用CLIP模型作为外部知识源,计算视觉特征和语言特征之间的亲和矩阵,用于纠正视觉和语言特征之间的对齐偏差。通过这种方式,模型能够更好地理解语言表达中每个单词与图像中相应视觉区域之间的关系。
-
Transformer编码器:在纠正后的语义空间中,使用多层Transformer编码器进一步融合视觉和语言特征,生成多模态表示,为后续的定位任务提供更准确的语义信息。
多分支调制定位模块(MML)
-
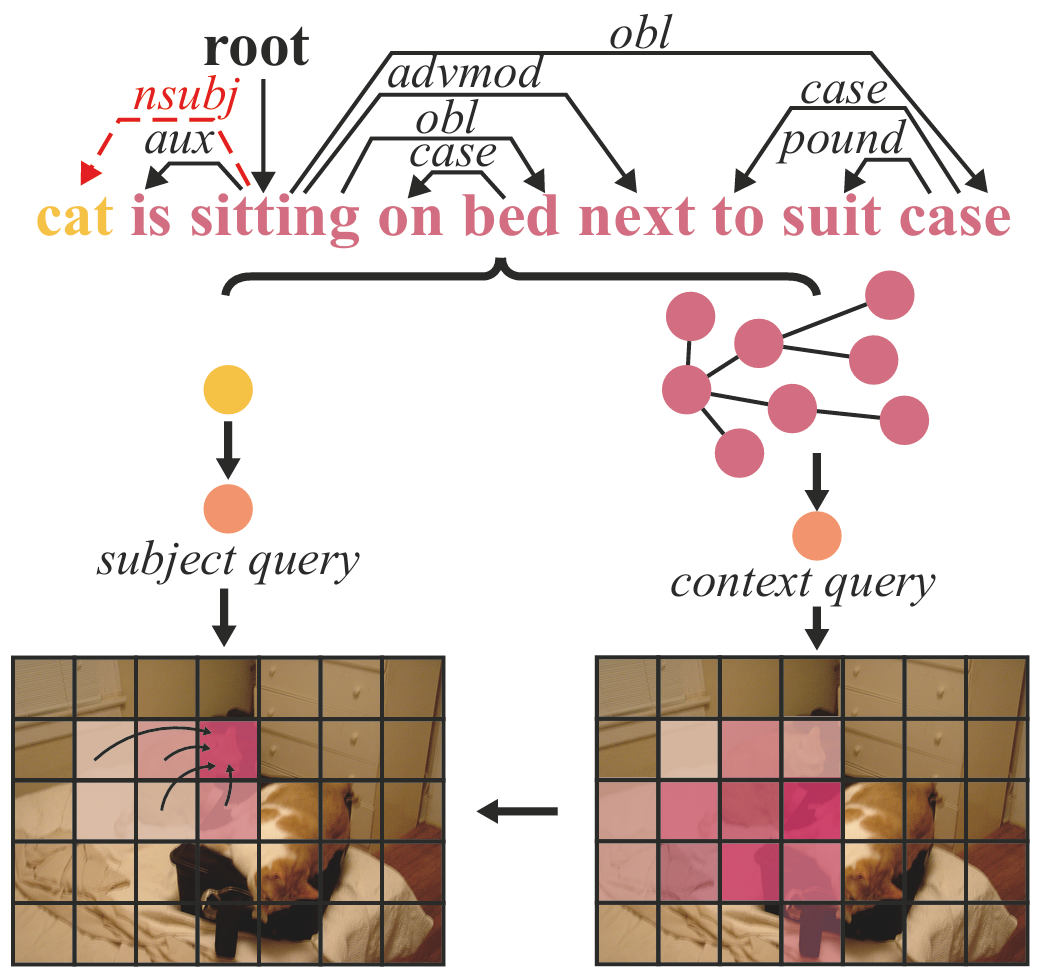
软拆分机制:通过依赖解析器将语言表达分解为主体和上下文两个部分,分别对应目标对象的描述和与目标相关的背景信息。这种软拆分方式既保留了语言表达的完整性,又为模型提供了明确的语言结构信息。
-
级联查询机制:采用级联形式的查询机制,首先利用上下文信息进行粗略的定位推断,然后基于主体信息进行更精确的定位。这种机制能够充分利用上下文信息来修正定位过程,避免模型仅依赖主体信息而导致的定位错误。
-
解码器设计:使用DETR解码器对多模态特征进行查询,建立文本节点与图像区域之间的一一映射关系,确保定位过程的稀疏性。通过这种方式,模型能够更准确地将语言表达对应的目标定位到图像中的特定区域。
实验
数据集和评估指标
-
数据集:实验使用了RefCOCO、RefCOCO+、RefCOCOg、ReferItGame和Flickr30K Entities这五个广泛使用的视觉定位数据集。
-
评估指标:采用准确率作为评估指标,当预测边界框与真实边界框的交并比(IoU)大于0.5时,认为预测是正确的。
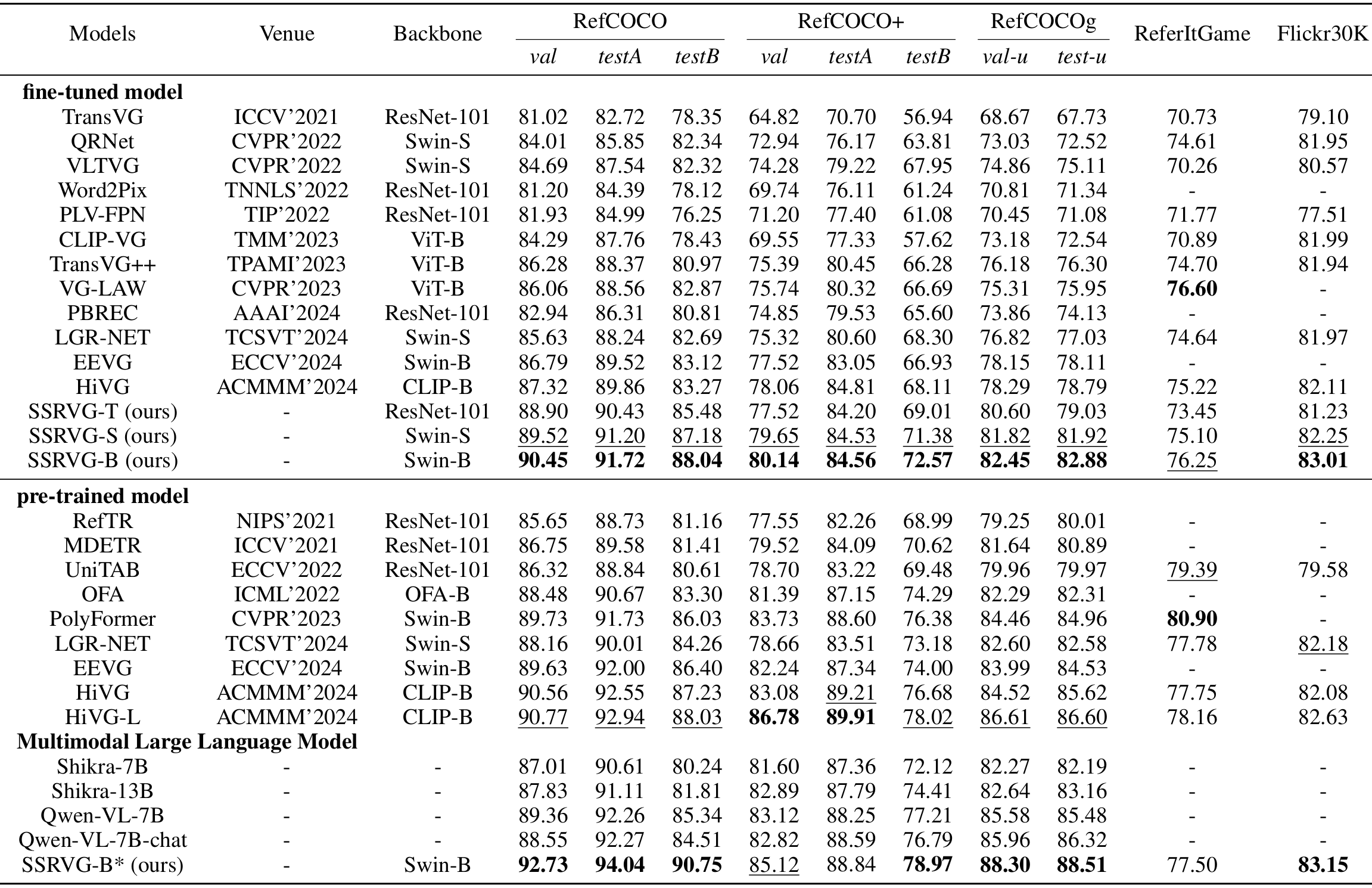
实验结果
-
与先进方法的比较:在所有五个数据集上,SSRVG方法均取得了优于或可比于现有单阶段和基于Transformer的先进方法的性能。例如,在RefCOCOg数据集上,SSRVG-B版本的准确率达到了88.04%,比之前的最佳方法HiVG-L高出2.03个百分点。
-
预训练模型的比较:虽然SSRVG在某些数据集上与大型预训练模型(如Shikra-7B、Qwen-VL-7B等)相比仍有差距,但在RefCOCO数据集上能够取得与这些模型相当的性能。这表明SSRVG在处理复杂语言表达和定位任务时具有较强的竞争力。
-
消融实验:通过一系列消融实验验证了CCA模块、MML模块以及多尺度特征等关键组件的有效性。例如,加入知识引导的交叉注意力机制(KGCA)后,模型性能提升了1.29个百分点;引入多尺度特征和半结构化推理分别带来了0.74和1.05个百分点的提升。

结论与未来工作
-
结论:SSRVG通过建立细粒度的视觉和语言内容对齐以及利用语言结构信息调制定位过程,有效解决了现有方法中存在的语义对齐不充分和语言结构未充分利用的问题。实验结果表明,该方法在多个数据集上取得了显著的性能提升,证明了其在视觉定位任务中的有效性。
-
未来工作:论文计划进一步研究如何在开放域中实现单阶段结构化推理,以提高模型的泛化能力。这可能涉及到探索更复杂的语言结构建模方法,以及如何更好地利用大规模无监督数据来增强模型的语义理解能力。
