【目标检测系列】YOLOV1解读
目标检测系列文章
目录
- 目标检测系列文章
- 📄 论文标题
- 🧠 论文逻辑梳理
- 1. 引言部分梳理 (动机与思想)
- 📝 三句话总结
- 🔍 方法逻辑梳理
- 🚀 关键创新点
- 🔗 方法流程图
- 关键疑问解答
- Q1: 关于 YOLOv1 中的 "confidence scores"
- Q2 YOLOv1 如何确定正样本?
📄 论文标题
YOLOV1 You Only Look Once: Unified, Real-Time Object Detection
作者:Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi
团队:University of Washington
🧠 论文逻辑梳理
1. 引言部分梳理 (动机与思想)
| Aspect | Description (Motivation / Core Idea) |
|---|---|
| 问题背景 (Problem) | 传统的优秀目标检测器(如R-CNN系列)虽然精度高,但流程复杂(候选区域生成 + 分类 + 回归),导致速度慢,难以满足实时性要求。 |
| 目标 (Goal) | 对整张图片只进行一次前向传播,直接从完整的图像像素预测边界框坐标和类别概率。 |
| 核心思想 (Core Idea) | 将目标检测视为一个单一的回归问题,而不是一个复杂的、多阶段的流程。 |
📝 三句话总结
| 方面 | 内容 |
|---|---|
| ❓发现的问题 |
|
| 💡提出的方法 (R-CNN) |
|
| ⚡该方案的局限性/可改进的点 |
|
🔍 方法逻辑梳理
-
模型输入 (Input) 是什么?
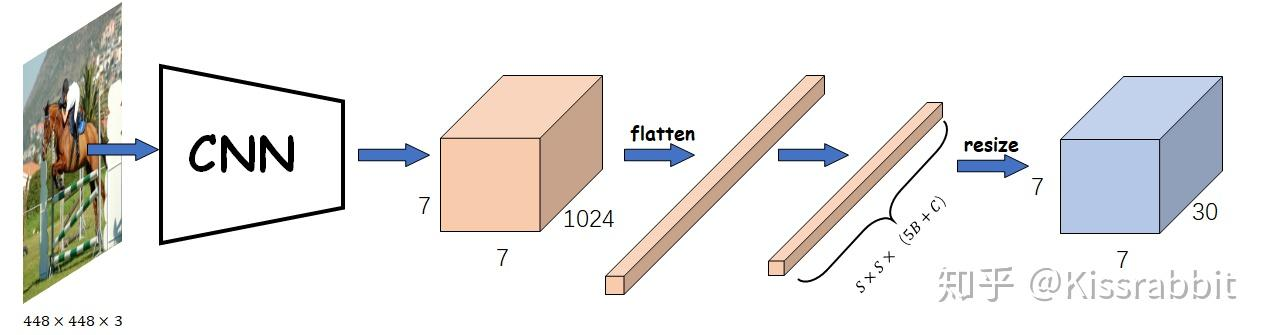
- 一张完整的图像,通常缩放到固定尺寸(例如 448 × 448 × 3 448 \times 448 \times 3 448×448×3 的张量)。
-
处理流程 (Processing Flow)(encoder,decoder,有没有特殊模块?)
- Encoder (编码器/特征提取器):
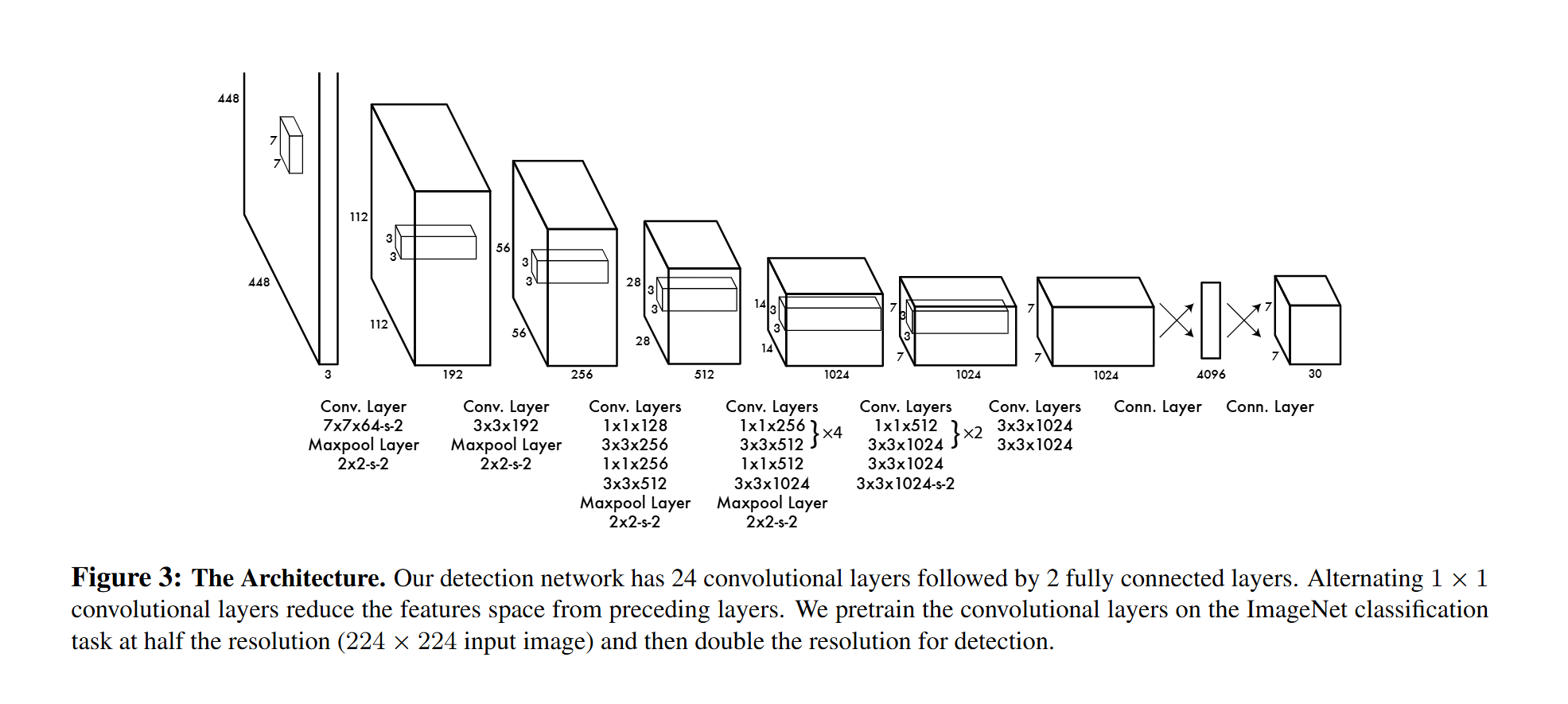
- YOLOv1使用一个单一的卷积神经网络作为其骨干网络(Encoder)。这个网络基于GoogLeNet(包含24个卷积层)或作者后来提出的Darknet(包含19个卷积层)进行修改。
- 它的作用是从输入图像中提取丰富的特征。通过一系列卷积层和池化层,图像的空间维度逐渐减小,而特征维度(通道数)逐渐增加。
- Decoder (解码器/预测头) - 概念上的:
- 严格来说,YOLOv1不像现代的Encoder-Decoder架构(如U-Net或Transformer)那样有一个明确的、复杂的Decoder结构。
- 可以认为其网络的最后几层(通常是全连接层,或者在全卷积版本中是卷积层)充当了“解码”或“预测”的角色。这些层接收来自Encoder的高层特征图,并将其转换为最终的预测张量。
- 特殊模块/概念:
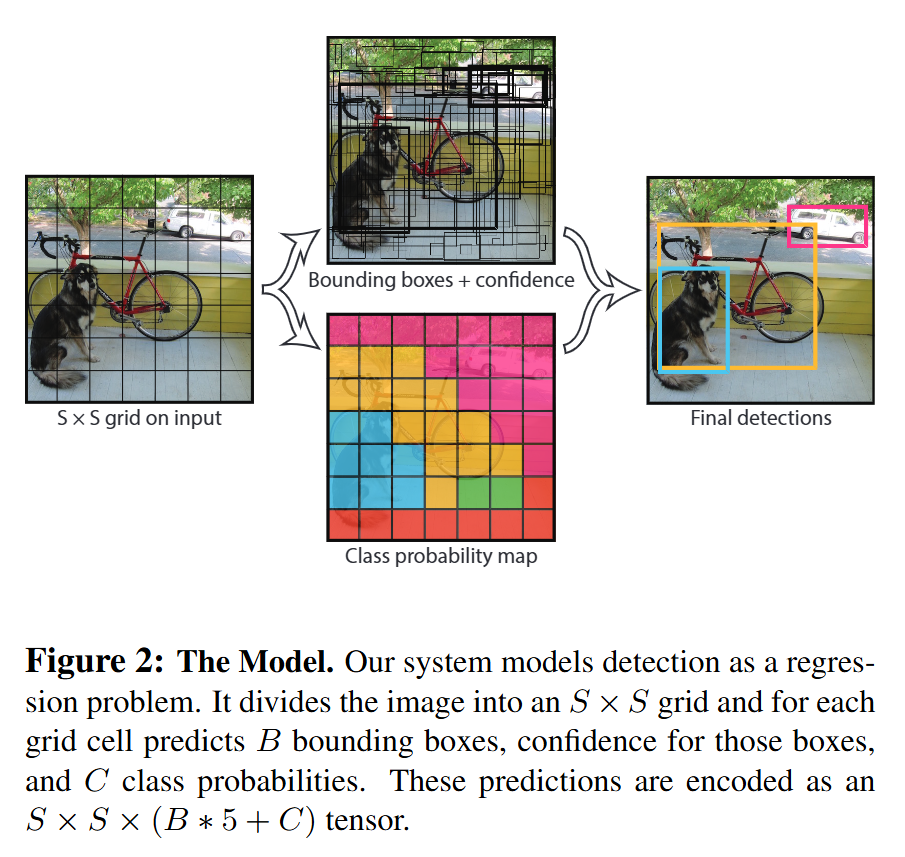
- 网格划分 (Grid Cell):这不是一个网络层,而是一个核心概念。网络输出的张量在空间上对应于输入图像的 S × S S \times S S×S 网格。
- 全连接层 (Fully Connected Layers):在原始YOLOv1论文中,骨干CNN的输出特征图会先被展平,然后通过两个全连接层来最终预测边界框坐标、置信度和类别概率。这意味着网络的输出具有固定的空间维度( S × S S \times S S×S),对于不同尺寸的输入图像,需要先将其缩放到固定大小。
- 边界框参数化:预测的 ( x , y ) (x,y) (x,y) 是相对于网格单元的偏移, ( w , h ) (w,h) (w,h) 是相对于整个图像的比例。这种相对坐标的预测方式使得学习更容易。
- 置信度计算: P ( Object ) × I O U pred truth P(\text{Object}) \times IOU_{\text{pred}}^{\text{truth}} P(Object)×IOUpredtruth 的定义是一个关键。
- Encoder (编码器/特征提取器):
-
输出 (Output) 是什么?
- 一个三维张量,形状为 S × S × ( B × 5 + C ) S \times S \times (B \times 5 + C) S×S×(B×5+C)。
- S × S S \times S S×S: 代表网格的数量。
- 对于每个网格单元 ( S × S S \times S S×S 中的一个):
- B × 5 B \times 5 B×5: 包含 B B B 个边界框的预测信息。每个边界框有5个值: ( x , y , w , h , confidence ) (x, y, w, h, \text{confidence}) (x,y,w,h,confidence)。
- C C C: 包含 C C C 个类别的条件概率 P ( Class i ∥ Object ) P(\text{Class}_i \| \text{Object}) P(Classi∥Object)。
- 一个三维张量,形状为 S × S × ( B × 5 + C ) S \times S \times (B \times 5 + C) S×S×(B×5+C)。
-
怎么训练 (Training)?
- 数据准备:将真实标注(物体类别和边界框坐标)通过
YoloMatcher(或类似逻辑)转换为基于网格的目标张量(gt_objectness,gt_classes,gt_bboxes)。 - 损失函数:如前所述,使用一个多部分组成的损失函数,优化定位、置信度和分类。
- 定位损失:只对正样本(负责检测物体的预测框)计算 ( x , y , w , h ) (x,y,w,h) (x,y,w,h) 的均方误差( w , h w,h w,h 取平方根)。乘以权重 λ coord \lambda_{\text{coord}} λcoord。
- 置信度损失:
- 对正样本:目标是其与真实框的IoU,计算均方误差。
- 对负样本:目标是0,计算均方误差。乘以权重 λ noobj \lambda_{\text{noobj}} λnoobj。
- 分类损失:只对包含物体的网格单元(正样本单元)计算类别概率的均方误差。
- 优化器:使用标准的随机梯度下降(SGD)及其变种进行优化。
- 预训练:骨干网络通常在ImageNet等大规模图像分类数据集上进行预训练,以学习通用的图像特征,然后进行微调。
- 数据准备:将真实标注(物体类别和边界框坐标)通过
🚀 关键创新点
-
创新点1:统一的检测框架 (Unified Detection as Regression)
- 为什么要这样做? 为了解决传统多阶段检测方法(如R-CNN系列)速度慢、流程复杂的问题。将检测视为单一的回归任务可以大大简化流程并提高效率。
- 如果不用它,会出什么问题? 检测速度会很慢,难以满足实时应用的需求。系统集成和优化也会更加复杂。
-
创新点2:全局上下文信息利用 (Global Context)
- 为什么要这样做? 传统方法中,分类器通常只看到局部候选区域,缺乏全局信息,容易将背景误识别为物体。
- 如果不用它,会出什么问题? 背景误检(False Positives)的概率会更高。YOLO在预测时能看到整张图片,因此对物体及其周围环境有更全面的理解,能更好地区分物体和背景。
-
创新点3:网格单元划分与责任分配 (Grid Cell System)
- 为什么要这样做? 提供了一种简单有效的方式来将物体的空间定位问题离散化,并为不同的预测器分配明确的职责。每个单元格只负责预测其中心点落入的物体,并预测少量的边界框。
- 如果不用它,会出什么问题? 如果没有这种空间约束,直接从全局特征回归所有物体的位置和类别会非常困难,模型可能难以收敛,或者需要更复杂的机制来处理多个物体的输出。网格系统简化了输出结构和学习目标。
🔗 方法流程图
关键疑问解答
知乎:YOLOV1详解
Q1: 关于 YOLOv1 中的 “confidence scores”
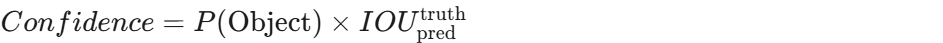
置信度分数是 YOLO 中衡量每个预测边界框“质量”的关键指标。它巧妙地结合了 框内是否有物体 和 框的位置准不准 这两个因素。
Q2 YOLOv1 如何确定正样本?
对于一个真实物体(Ground Truth Object):
其正样本是 -> 位于包含该物体中心点的那个网格单元内 -> 预测出的边界框与该物体真实边界框 IOU 最高的那个边界框预测器。
训练中的意义:
正样本:在计算损失函数时,这个预测器需要:
1、学习预测正确的物体类别(Class Probability Loss)。
2、学习预测更接近真实边界框的坐标 ( x , y , w , h ) (x,y,w,h) (x,y,w,h) (Coordinate Loss)。
3、学习预测一个高的置信度分数(Confidence Loss,目标通常是 1 或等于其预测框与真实框的 IOU)。
负样本 (Negative Samples):
所有不包含任何物体中心点的网格单元中的所有预测器。
包含物体中心点的网格单元中,除了那个被选为正样本(IOU最高)之外的其他 B−1 个预测器。
对于这些负样本,主要计算置信度损失 (Confidence Loss),目标是让它们的置信度分数趋近于 0(表示它们不包含物体)。它们的坐标损失和类别损失通常不计算或权重为零。
其实就是让负样本预测背景,正样本预测前景,这个Objectness(框的置信度)把前景和背景解耦开了,一生二的思想