LLM 论文精读(七)Rethinking Reflection in Pre-Training
这是一篇2025年发表在arxiv中的LLM领域论文,也是之前两篇有关RL和LLM性能关系之间的另一篇论证论文,作者任务模型的反思能力是在预训练阶段就获得的与RL无关;
- 博客一:LLM 论文精读(六)Does Reinforcement Learning Really Incentivize Reasoning Beyond the Base Model
- 博客二:LLM 论文精读(五)Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effec
这三篇文章共同提出了以下观点:
- RL想要学到 “验证”、 “回溯”、“子目标设定”、“后向链接”的能力取决于模型本身是否拥有,而非RL算法;
- RL只能让模型以更高的概率获得更好的答案,但原始模型本身就有得到这个答案的能力,只是概率低了些;
- 推理时加入一些特定的提示词可以让模型表现出反思能力,而不用RL训练;
写在最前面
为了方便你的阅读,以下几点的注意事项请务必了解:
- 该系列文章每个字都是我理解后自行翻译并写上去的,可能会存在笔误与理解错误,如果发现了希望读者能够在评论区指正,我会在第一时间修正错误。
- 阅读这个系列需要你有基本的 LLM、RL相关基础知识,有时候我会直接使用英文名词,因为这些词汇实在不容易找到符合语境的翻译。
- 原文可能因为版面限制存在图像表格与段落不同步的问题,为了更方便阅读,我会在博文中重新对图像表格进行排版,并做到引用图表的文字下方就能看到被引用的图表。因此可能会出现一张图片在博客中多处位置重复出现的情况。
- 对于原文中的图像,我会在必要时对图像描述进行翻译并附上我自己的理解,但如果图像描述不值得翻译我也不会强行写上去。
Basic Information
- 论文标题:Rethinking Reflection in Pre-Training
- 原文链接: https://arxiv.org/abs/2504.04022
- 发表时间:2025年04月05日
- 发表平台:arxiv
- 预印版本号:[v1] Sat, 5 Apr 2025 02:24:07 UTC (5,179 KB)
- 作者团队:Essential AI: Darsh J Shah, Peter Rushton, Somanshu Singla, Mohit Parmar, Kurt Smith, Yash Vanjani, Ashish Vaswani, Adarsh Chaluvaraju, Andrew Hojel, Andrew Ma, Anil Thomas, Anthony Polloreno, Ashish Tanwer, Burhan Drak Sibai, Divya S Mansingka, Divya Shivaprasad, Ishaan Shah, Karl Stratos, Khoi Nguyen, Michael Callahan, Michael Pust, Mrinal Iyer, Philip Monk, Platon Mazarakis, Ritvik Kapila, Saurabh Srivastava, Tim Romanski
- 院校机构:
- Essential AI;
- 项目链接: 【暂无】
- GitHub仓库: https://github.com/Essential-AI/reflection
Abstract
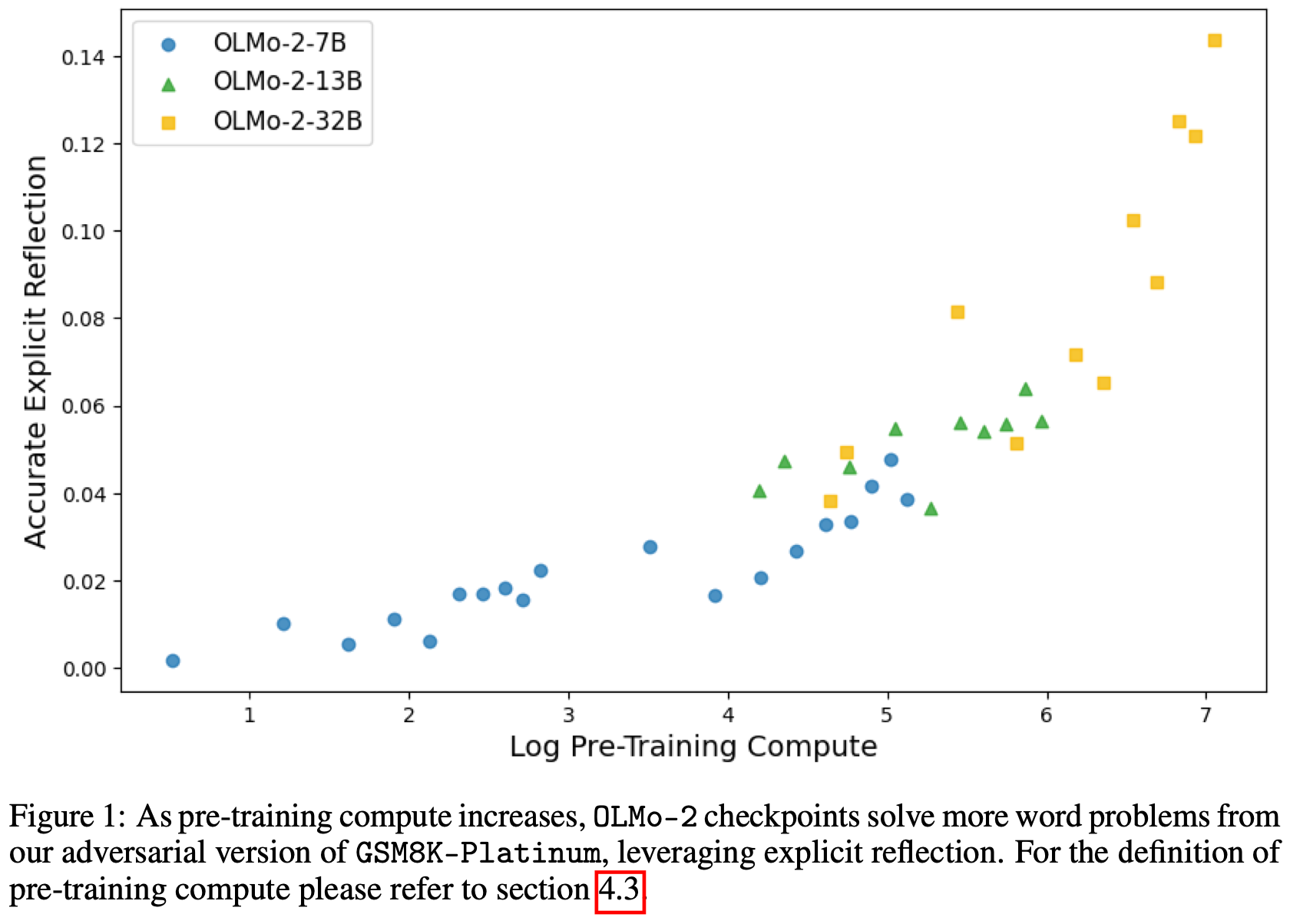
语言模型反思自身推理的能力是解决复杂问题的关键优势。虽然最近的研究主要关注这种能力在强化学习过程中是如何发展的,但本文研究表明,它实际上在更早的时候就开始显现:在模型的预训练阶段。为了研究这一点,在思维链中故意引入错误,并测试模型是否能够通过识别和纠正这些错误来得出正确答案。通过追踪模型在预训练不同阶段的表现,观察到这种自我纠正能力很早就显现出来,并且随着时间的推移稳步提升。例如,一个在 4 万亿个词条上进行预训练的 OLMo-2-7B 模型,在六项自我反思任务中展现出了自我纠正的能力。
1. Introduction
Reflection 增强了模型根据先前推理调整响应的能力,从而提高其输出的准确性。最近的研究报告指出,“诸如反思之类的行为……是模型与强化学习环境交互的结果”。要验证此类说法归因于能力的发展,需要在整个训练阶段进行全面的评估。本研提出了一个详尽的框架来测量反思,并在预训练期间持续观察这一现象。
使用现有的推理数据集对反思进行基准测试一直很有挑战性。在这样的任务中反思通常很少,每个模型都表现出不同的错误模式,从而产生独特的反思行为表现 。作者通过区分情境反思和自我反思来应对这一挑战。在情境设置中,模型会检查由其他来源(例如不同的前沿模型)创建的推理链。在自我反思中,模型会考虑自己的推理过程。当提供一些导致错误答案的混杂推理时,会校准模型解决任务的能力,从而在整个预训练过程中衡量反思能力。
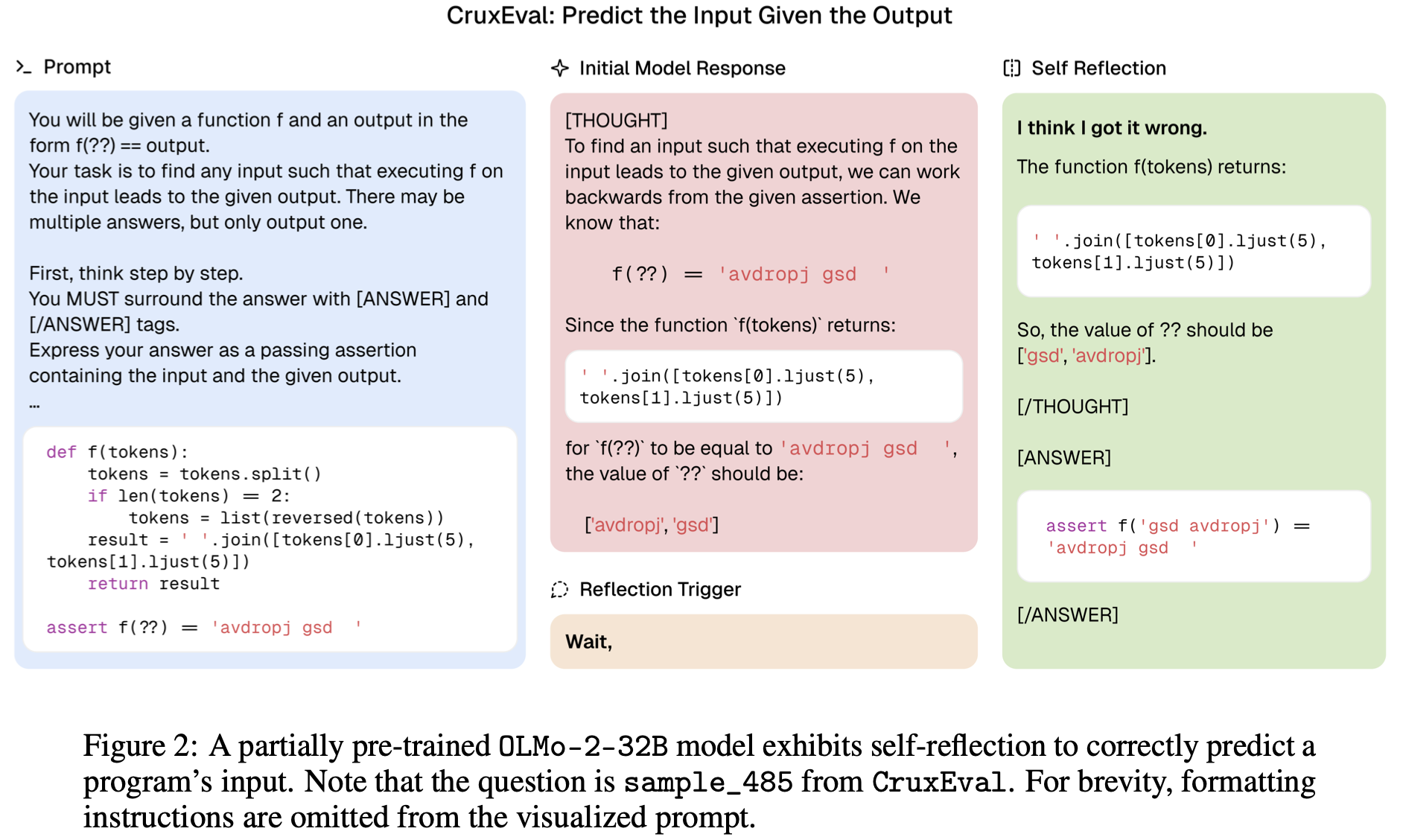
Fig.2 展示了部分预训练的 OLMo-2 检查点尝试解决编码任务。在本例中,模型被提出一个问题,即确定 Python 函数 f 的输入,该输入最终导致输出“avdropj gsd”。在第一次尝试中,该模型(拥有 320 亿个参数,并在 4.8 万亿个标记上进行预训练)将输出重复为答案“advdropj gsd”。在用其错误的想法加上“等待”后缀提示它之后,该模型能够成功地自我反思并生成“我想我错了……?? 的值应该是 [‘gsd’, ‘avdropj’]”。
通过以编程方式引入错误思维链 (CoT),例如算术扰动和逻辑不一致等元素,可以控制和扩展正确完成这些任务所需的反思程度。这也保留了既定的 CoT 格式。此外,作者的算法方法允许通过调整既定的推理基准,以相对快速且经济的方式创建这些数据集,从而可以全面研究模型在不同领域的反思能力。六个数据集涵盖数学、编码、逻辑推理、知识获取等领域,旨在评估情境反思和自我反思能力。
作者在六个不同的数据集上评估了 OLMo-2 系列模型(这些模型具有不同的计算能力)的预训练checkpoint,结果表明,反思在各个领域都普遍存在。即使是像“Wait”这样的简单触发短语,也能使部分预训练的模型能够一致地识别引入的错误及其自身产生的错误。具体而言,在 240 个数据集-检查点对中,有 231 个至少展示了一次情境反思,240 个对中,有 154 个至少展示了一次自我反思。随着预训练的深入,模型能够纠正更多对抗性样本,导致准确率与对数(预训练计算能力)之间的平均皮尔逊相关系数在各个任务中达到 0.76。此外,随着预训练的进展,模型能够逐渐从错误的先验推理中恢复,模型生成过程中显式反思的速率不断提高,并且显式反思对从令人困惑的“待解决的问题”(CoT)中恢复的贡献也越来越大。
本文的贡献有三方面:
- 引入了一种系统方法来创建跨代码、知识获取、逻辑推理、数学的六个数据集来研究模型的反映能力;
- 证明了不同参数量和训练计算的预训练模型都可以引发反思,以纠正各种领域中使用简单插入语的不准确的先前推理;
- 观察到不断改进预训练可以带来更好的反思,需要更少的测试时间标记来解决相同数量的任务;
2. Related Work
Evaluating Reasoning in LLMs
自然语言系统在现实世界中的适用性取决于推理能力。LLM 与诸如思路链、思路树、自洽性等提示技巧相结合,已成功用于解决各种推理任务。推理能力通常通过观察模型结果、生成轨迹、交互参与来衡量。先前的研究还通过研究注意力模式、激活流、各个层对模型内部网络进行参数归因,以识别推理特征。这些方法主要用于评估训练后的模型,这里感兴趣的是在整个训练阶段引入推理的诊断技术,其核心类似于通过参数和训练数据缩放来研究模型性能。本文中,通过评估对抗数据集中反思的出现来研究推理。这些数据集要求模型通过包含微小误差的多步提示进行推理,才能成功完成任务。
Adversarial Attacks on LLMs
对抗性输入早已被用来暴露神经网络的漏洞。最近,类似的技术已被应用于LLM,证明了它们易受精心设计的提示的影响。这些攻击成功地针对了模型的策略一致性、安全性和鲁棒性,凸显了巨大的漏洞。已有多种方法提出采用对抗性训练来提升模型对此类攻击的防御能力。然而,本文研究的主要目标并非展示模型在对抗面前的脆弱性,而是强调如何利用此类数据集持续且全面地评估其推理能力。通过引入思维链来实现这一点,其中的步骤大部分是正确的,但也包含需要反思的错误。
Train Time vs Test Time Tradeoff
高级推理模型(例如 Open AI 的 o1 和 DeepSeek-R1 )对测试时计算的依赖日益加深,这再次引发了关于计算优化分配的讨论。先前的研究探讨了训练时间和测试时间计算之间的权衡,以及监督微调和强化学习等训练后技术对推理性能的影响。推理时范式——例如树搜索、思路链提示、预算强制,与模型的预训练表征相互作用。然而本研究贡献了一个互补的视角,证明即使没有微调、强化学习或专门的测试时推理技术,某些推理能力也可以在预训练过程中逐渐显现。研究结果表明,推理的关键方面可以仅通过预训练来灌输,这可能会改变在训练和推理过程中计算资源最佳利用的计算方式。
3. Approach
本文的目标是全面、大规模地测量反思。提出了反思 3.1 的定义,以编程方式创建任务来引出反思 3.2,并严格测量了反思 3.3 的存在。
3.1 Defining Reflection
Reflection 反思是一种元认知形式,它涉及审视信息、评估其背后的推理,并根据评估结果调整未来行为。在语言模型的语境中,这一过程可以应用于从外部来源引入的信息,也可以应用于模型自身生成的信息。在本研究中,创建了两种场景来引出和测量反思:
- Situational-reflection:一个模型反思由另一个来源(例如不同的模型)创建的信息;
- Self-reflection:是当模型反思其自身生成的输出时;
还通过两种形式全面描述反思:
- Explicit reflection:当模型生成的tokens能够根据其含义识别并解决对抗性语境中的错误时,就会发生显式反思。显式反思可能出现在正确的模型输出(换句话说,构成对抗性任务正确答案的输出)或错误的模型输出中;
- Implicit reflection:当模型能够驾驭对抗性语境正确解决任务,而无需输出明确指出先前推理中错误的tokens时,就会发生这种情况。这意味着隐式反思不会导致对抗性任务给出错误答案。这能够区分两种情况:一种是没有显式反思但可以推断出发生了隐式反思的情况;另一种是根本没有发生反思的情况;
3.2 Eliciting Reflection with Adversarial Reflection Datasets
作者提出了一种算法来生成对抗性数据集,以引出语言模型的反思行为。该算法会创建CoT,从而得出错误的解决方案。与自我反思不同,可以从模型自身的错误中汲取经验,而情境反思则需要设计人工CoT。从高层次上讲,这些 CoT 是通过破坏正确 CoT 来创建的,其方式类似于人类的推理错误,例如逻辑错误和算术错误。在这两种情况下,当上下文中提 CoT 时,模型必须反思并修复错误,最终得出正确的解决方案。作者认为,这些设定对于全面研究反思至关重要。
任务设计包括附加触发标记,例如“Wait”,以促进整个任务解决过程中的持续推理;
该算法有两种变体。Algorithm.1和Algorithm.2 分别创建情境反思和自我反思数据集。

3.3 Measuring Reflection
根据之前对反思的分类(见 3.1)提出了一种自动化方法来使用对抗数据集来测量模型的反思能力:
- Measuring explicit reflection:为了识别显式反射的实例,作者开发了一个基于提示的 LLM 分类器,它可以检测模型的输出是否在给定的对抗语境中明确地承认并解决了错误,无论模型是否得出了正确答案。该分类器将在下文 4.3 中描述。
- Measuring implicit reflection:规定所有在对抗性语境下得出正确答案的模型生成都归因于反思,即使没有输出与反思相关的tokens。作者认为这符合“反思”在描述人类元认知方面的日常理解。该方法的一个含义是,根据构造,那些产生正确答案但未被显式分类器识别的生成被归类为隐式反思的实例;
有关使用的具体反思指标的更多详细信息,请参阅第 4.3 节。
4. Experimental Setup
为了全面研究反思,作者评估了跨越不同计算预算的部分预训练模型,参数数量和训练tokens数量都有变化。
研究包括两种类型的对抗性任务:(1)Situational-Reflection:其中对抗性思维链是使用前沿模型从现有数据集系统地生成的;(2)Self-Reflection:其中对抗性思维链源自模型自身对原始任务实例的先前错误反应。
评估还检查模型输出是否表现出明确的反思推理。第 4.4 节详细介绍了基础设施设置。
4.1 Model Families
- OLMo-2:
OLMo-2是一个完全开源、开放权重的 LLM 项目,提供适用于 7B、13B 和 32B 参数变体的训练检查点。总共评估了 40 个检查点(详情请参阅附录 B),力求检查点间距相等,并在无法获取等间距检查点的情况下使用最接近的备选方案。 - Qwen2.5:评估了
Qwen2.5的 0.5B、3B、7B、14B、32B 和 72B 参数变体。详情请参阅附录 B。
4.2 Datasets
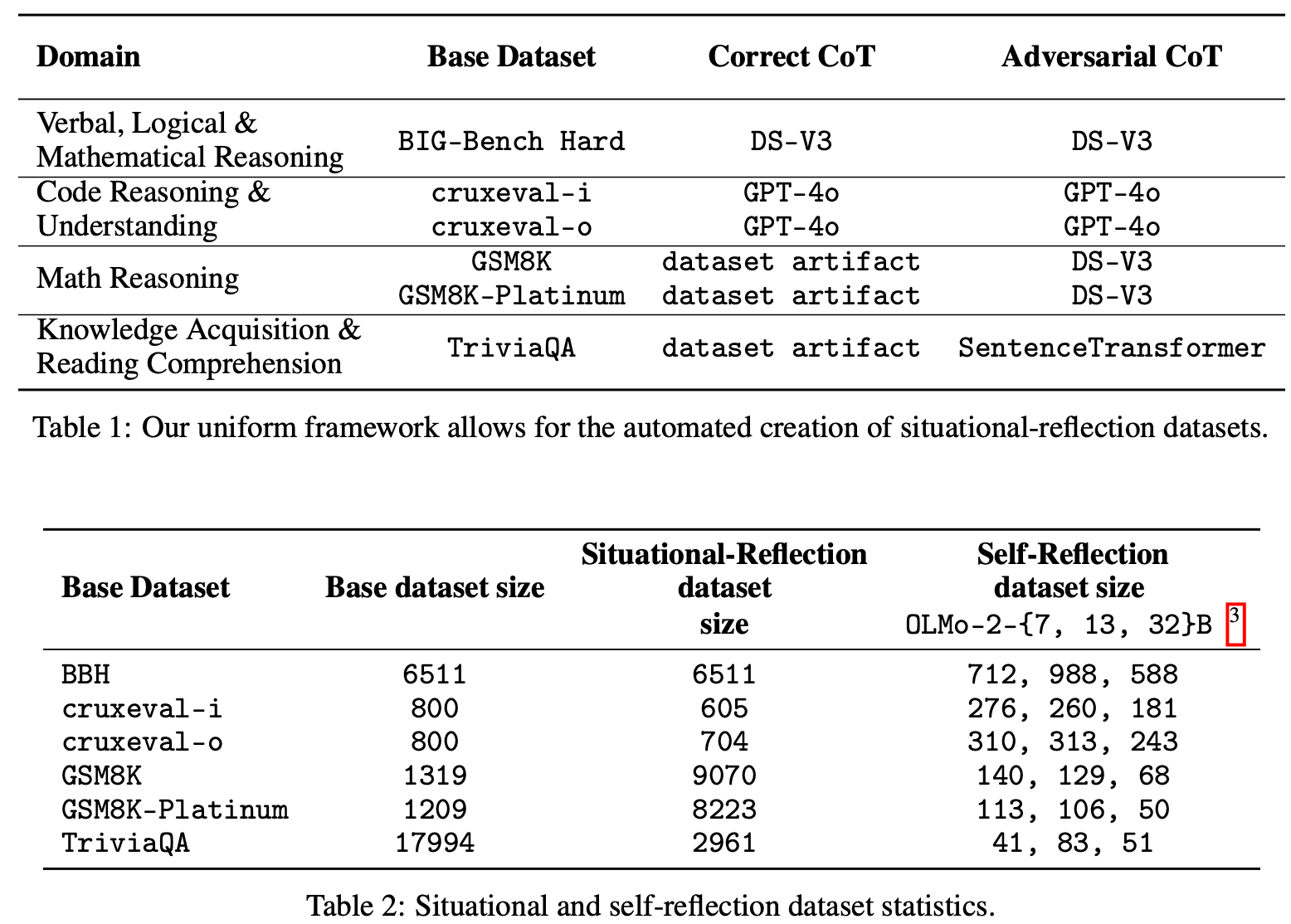
在一系列广泛的任务中评估了反射现象,并基于 BIG-Bench Hard (BBH)、CruxEval、GSM8K、GSM8K-Platinum 和 TriviaQA 创建了六个对抗数据集。对抗数据集概览见Table.1 和Table.2。
利用 DeepSeek-V3(简称 DS-V3)、GPT-4o2 和 SentenceTransformers模型,以及流程中的多项自动检查和手动检查,以确保数据集的质量和稳健性。
Situational-Reflection Datasets
这些数据集的创建涉及一个多步骤的流水线,实验时会提示LLM创建对抗性计算任务CoT(Algorithm.1)。对于推理任务,原始任务可能包含 CoT 作为数据集构件;如果没有,则使用前沿模型(例如 GPT-4o 或 DS-V3)创建。随后,使用正确的 CoT,通过故意引入导致错误答案的错误来开发对抗性计算任务。此外还会进行检查,以确保 CoT 不会泄露其误导性意图。这些流水线和提示都经过精心设计,旨在最大限度地减少错误,并且特定于特定数据集,但整体框架可以推广到任何领域和数据集。
Self-Reflection Datasets
这些数据集是通过在基础任务上执行我们想要评估的 LLM 并收集与模型未通过的问题对应的 CoT(Algorithm.2)而创建的。由于关注的是模型在预训练过程中的反思能力,因此仅将每个参数尺度上所有检查点都错误回答的问题保留在自反思数据集中,以确保跨预训练检查点的一致性比较。
有关数据集特定的管道、检查和过滤器的详细信息,请参阅附录 F。
4.3 Evaluation
Metrics
如Table.3 所示,无论是情境反思还是自我反思,准确率都是指模型正确解决的任务实例的比例。利用显式反思分类器来测量显式反思率,即模型输出中展现出显式反思的任务实例的比例,无论这些实例是否正确。此外,还统计了显式反思准确率,即模型既正确解决又展现出显式反思的任务实例的比例。最后,隐式反思准确率是指模型输出正确但未展现出显式反思的任务实例的比例。每个数据集的准确率指标详情,请参阅附录 H。

对于每个数据点,将预训练计算量设置为 6 n t 6nt 6nt,其中 n n n 和 t t t 分别是参数的数量和训练 token 的数量。有关训练时间和测试时间计算公式的更多详细信息,请参阅第 5.4 节。
Explicit Reflection Classifier
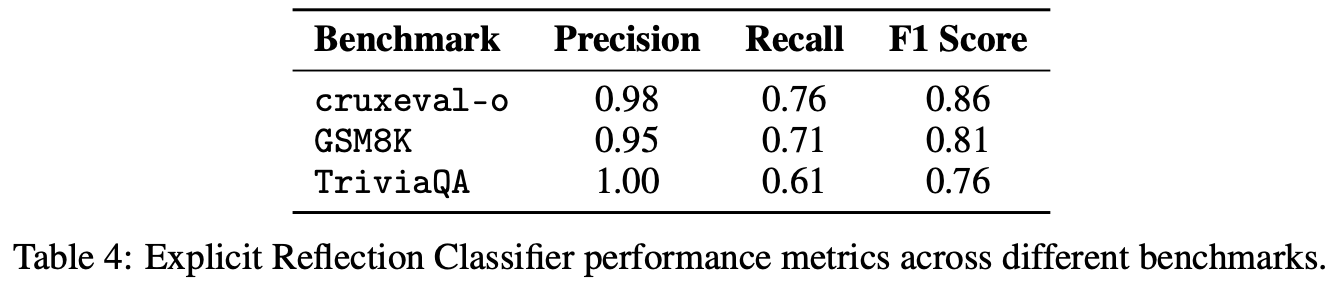
作者开发了一个基于提示的分类器,用于判断模型输出是否表现出显式反射。DeepSeek-V3会以“反思”含义的描述以及两到四个显式反射示例作为提示。Table.5 展示了该分类器旨在检测的一些显式反射短语示例。在 GSM8K、cruxeval-o 和 TriviaQA 上针对人工标注的标签验证了该分类器(每个基准测试 120 个问题;有关标注过程的详细信息,请参阅附录 G)。虽然分类器召回的反思实例较少Table.4,但其准确率足以验证其有效性,在最坏的情况下会漏报反思行为。

4.4 Infrastructure
实验设置使用 vLLM 推理框架来托管 OLMo-2 和 Qwen 模型。使用 SGLang 来托管 DeepSeek-V3。使用 AMD MI300x 加速器和 Kubernetes 集群来调度作业。
5. Results
为了全面衡量跨领域的反思性推理能力,分类器分别在 BBH、cruxeval-i、cruxeval-o、GSM8K、GSM8K-Platinum 和 TriviaQA 中,针对情境反思 5.1 和自我反思 5.3 设置,区分了显式反思和隐式反思。作者发现反思能力的显著提升,并且随着训练计算量的增加而增强。此外,随着预训练的进行,模型逐渐从混杂因素中恢复,显式反思的速率不断提高,并且显式反思对从混杂因素中恢复的贡献也越来越大Table.5。这些结果凸显了预训练在培养反思能力方面的作用。
5.1 Explicit Situational-Reflection is Prominent in all Models
Table.6 中除cruxeval-i任务外的所有任务,每个OLMo-2预训练检查点都显示出从情境混杂因素中恢复的迹象,无论是隐性还是显性。这导致240个数据集-检查点对中有231个至少展示了一次情境反思的实例。然而,为了证实关于模型逐步发展并使用显性反思的假设,大多数恢复应该归因于显性情境反思。作者所期望的是,随着预训练计算量的增加,(a) 从情境混杂因素中恢复;(b) 显性反思情境混杂因素; © 通过显性反思从情境混杂因素中恢复的频率不断提高。
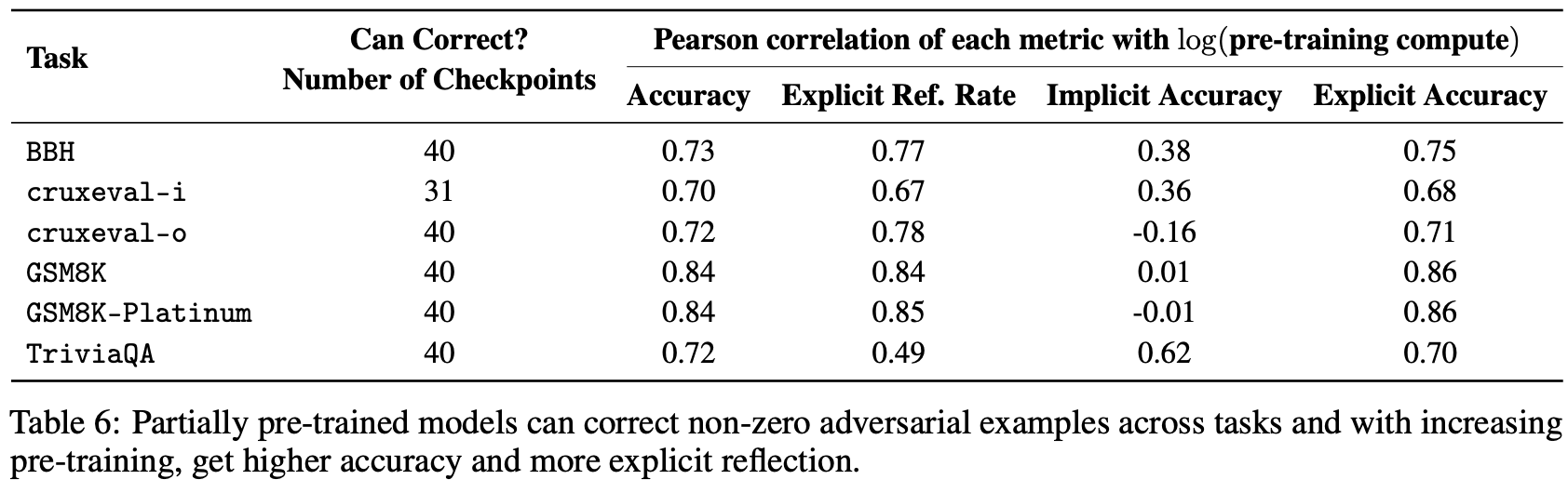
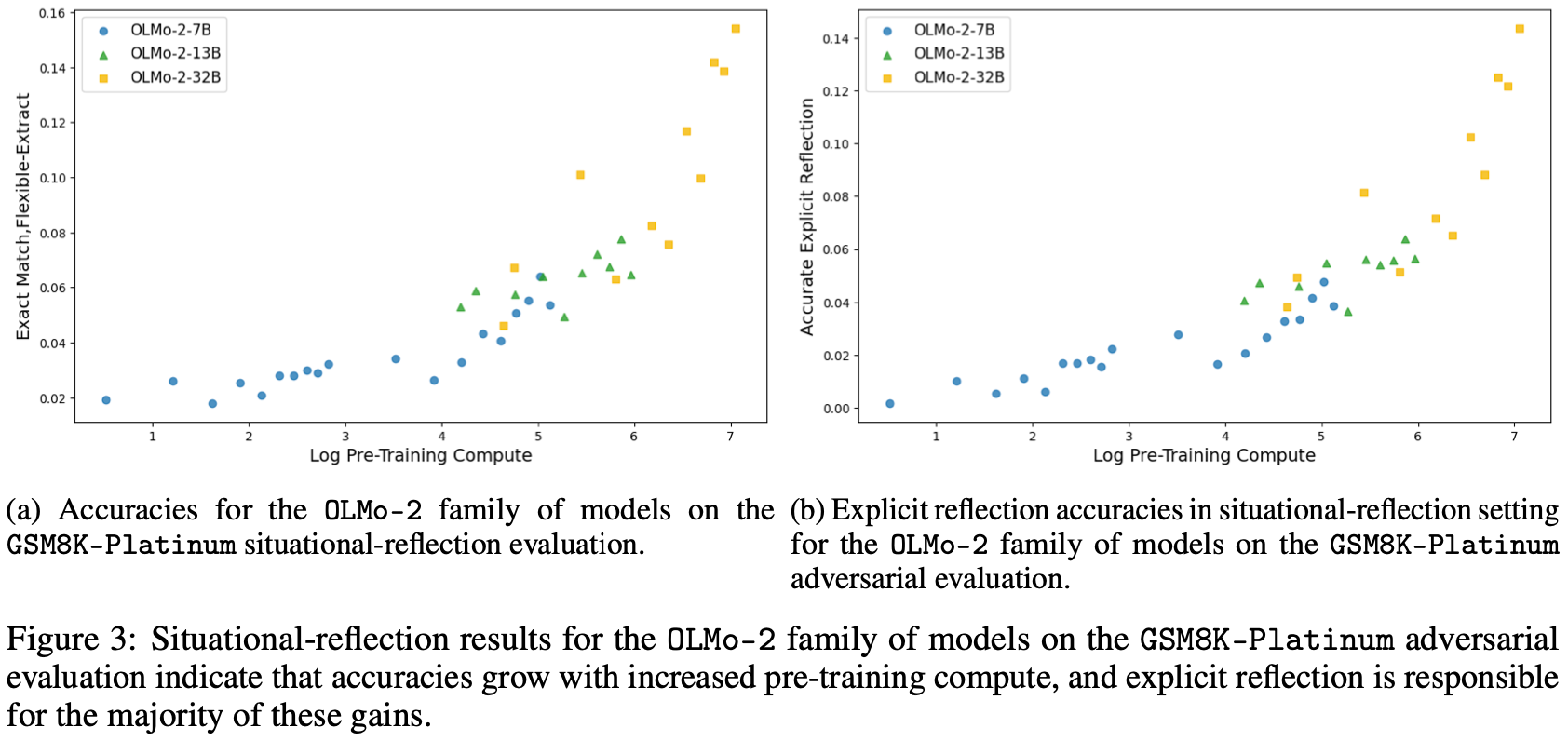
每个指标与 log(pre-training compute) 的高正 Pearson 相关性意味着 (a)、(b) 和 ©。作者还发现隐式反射准确率与 log(pre-training compute) 的相关性普遍较低。总之,这些结果强调了随着预训练的深入,模型往往能够成功解决更多对抗性实例,并且在执行此操作时越来越倾向于使用显式反射。例如,GSM8K-Platinum 在Fig.3 中显示,随着预训练的增加,不同参数数量的模型通过显式反射错误来解决大多数任务实例。TriviaQA 是一个例外,其显著的改进可以归因于隐式反射,这是该任务主要衡量知识获取的结果,其中一些实例无需显式推理即可解决。所有六项任务的详细结果可在附录 C 中找到。
5.2 Models Reflect Even Without Triggers; ‘Wait,’ Enhances Explicitness and Accuracy
为了理解“Wait”触发器的因果作用,作者研究了在 GSM8K-Platinum 上使用两个极端触发器的模型性能。具体来说,研究了没有触发器(A)和带有触发器(B)的模型性能,触发器包含明确的“等一下,我犯了一个错误”。A 模式以尽量减少对CoT中错误的关注;B 模式以强调CoT中存在的错误。Fig.4绘制了这些结果。
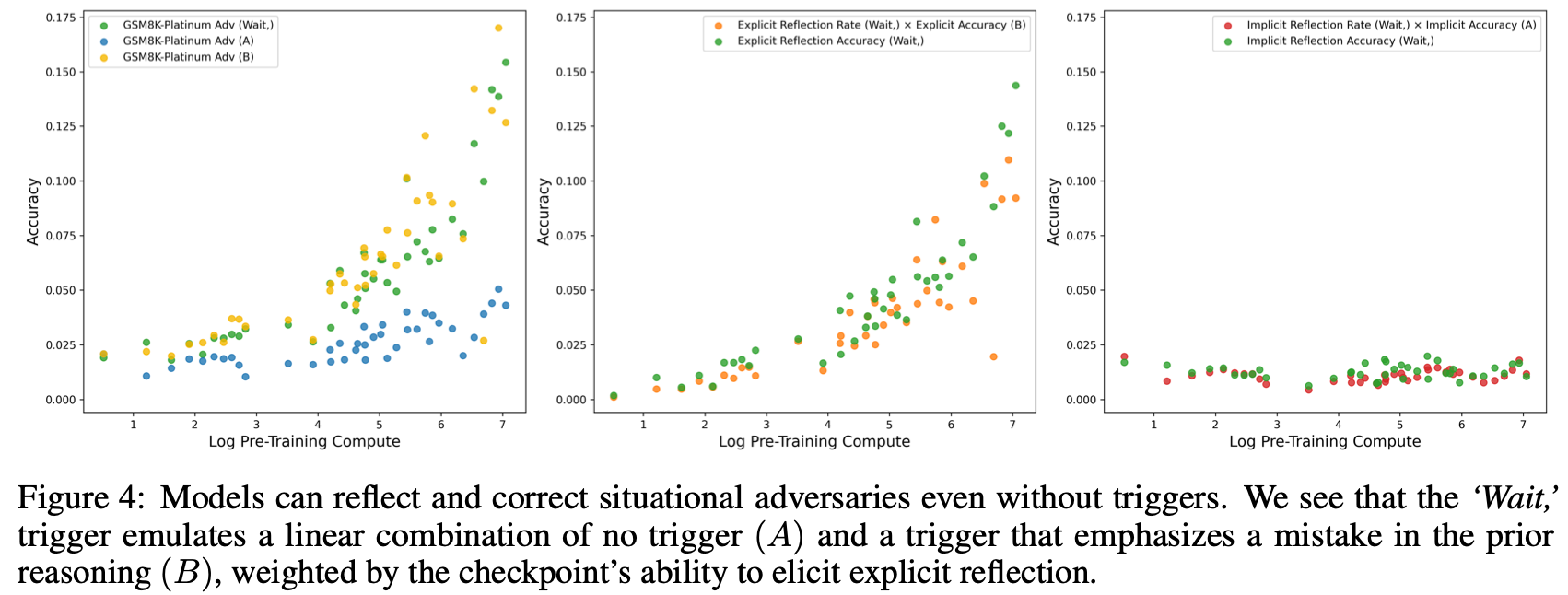
结果首先证实了以下假设:即使没有触发因素,随着预训练的进展,模型也能越来越成功地应对情境混杂因素。上文第 5.1 节结果中“等待”的作用在此得到进一步阐明。模型在此任务上的表现受 A 和 B 两个极端的限制。在场景 A 中,模型通过隐式反思来提高准确率,而在场景 B 中,模型通过构造来显式反思从而大大提高性能。‘Wait’设置在隐式反思时表现得像 A,在显式反思时表现得像 B。如Fig.4 所示,它的性能可以分解为 a c c W a i t = e W a t i ∗ a c c B + ( 1 − e W a i t ) ∗ i _ a c c A acc_{Wait}=e_{Wati}*acc_{B}+(1-e_{Wait})*i\_acc_{A} accWait=eWati∗accB+(1−eWait)∗i_accA,其中 e W a i t e_{Wait} eWait 是显式反思比例, i _ a c c i\_acc i_acc 是隐式反思准确率。
此外,性能的显著提升归因于“Wait”触发器。这是因为触发器引发显式反思的频率会随着预训练的进行而增加,并且它也能达到相应 B 触发模型所达到的性能。如上所述,选择该模式是为了强调CoT 中存在的错误。换句话说,当以带有“Wait”的CoT为条件的模型表现出显式反思时,其性能与明确告知模型对CoT包含错误时的性能相当。相反,当模型以带有“Wait”的CoT为条件,但不表现出显式反思时,其性能与仅以对CoT为条件的模型性能一致。这建立了通过“Wait”进行显式反思以提高准确率的因果关系。
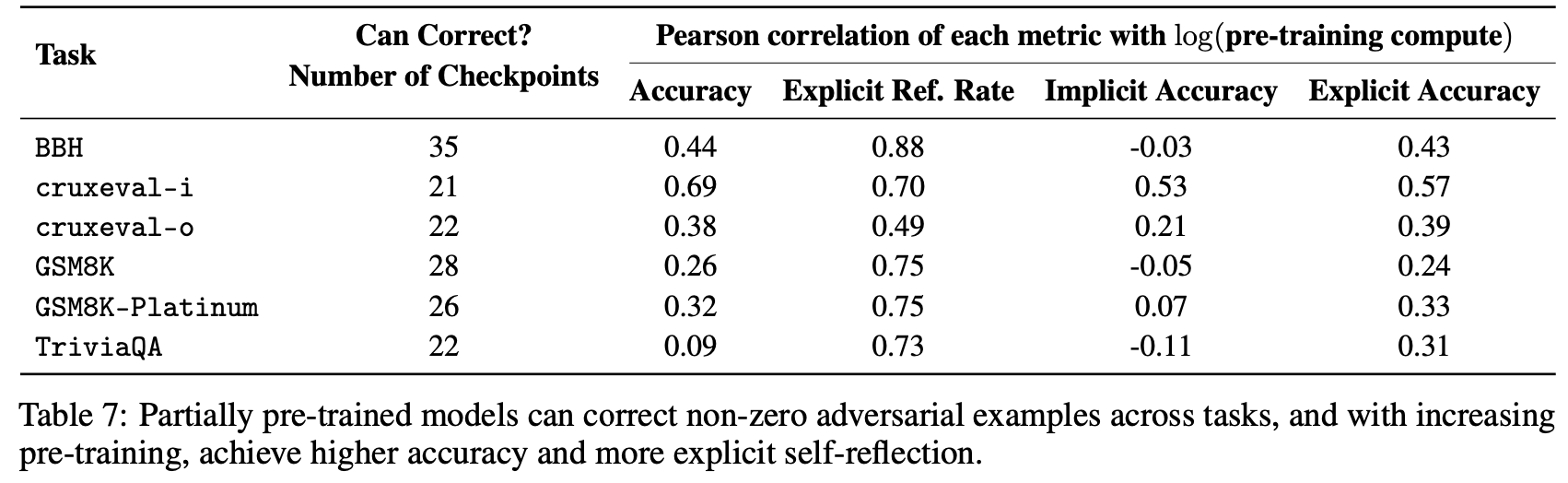
5.3 Explicit Self-Reflection is Harder but Advances With More Compute
Table.7中自我反思的稀缺性可能被视为负面结果。然而这可以解释为:在这种情况下,模型的评估是基于它们回答错误的任务实例,因此从设计上来说自我反思特别困难。尽管如此,在大约64.2%的任务尝试中,模型确实展现出至少一定的自我纠正能力。
为了区分自我反思和自我纠正,Fig.5 中绘制了模型产生的反思率与任务是否已解决无关。这些结果表明,随着预训练的进行,模型越来越善于明确地指出自身的错误。对于 cruxeval-i 随着预训练的增加,模型倾向于学会自我纠正,并且能够更早地进行自我反思。这表明,自我反思技能的自然发展先于自我纠正。
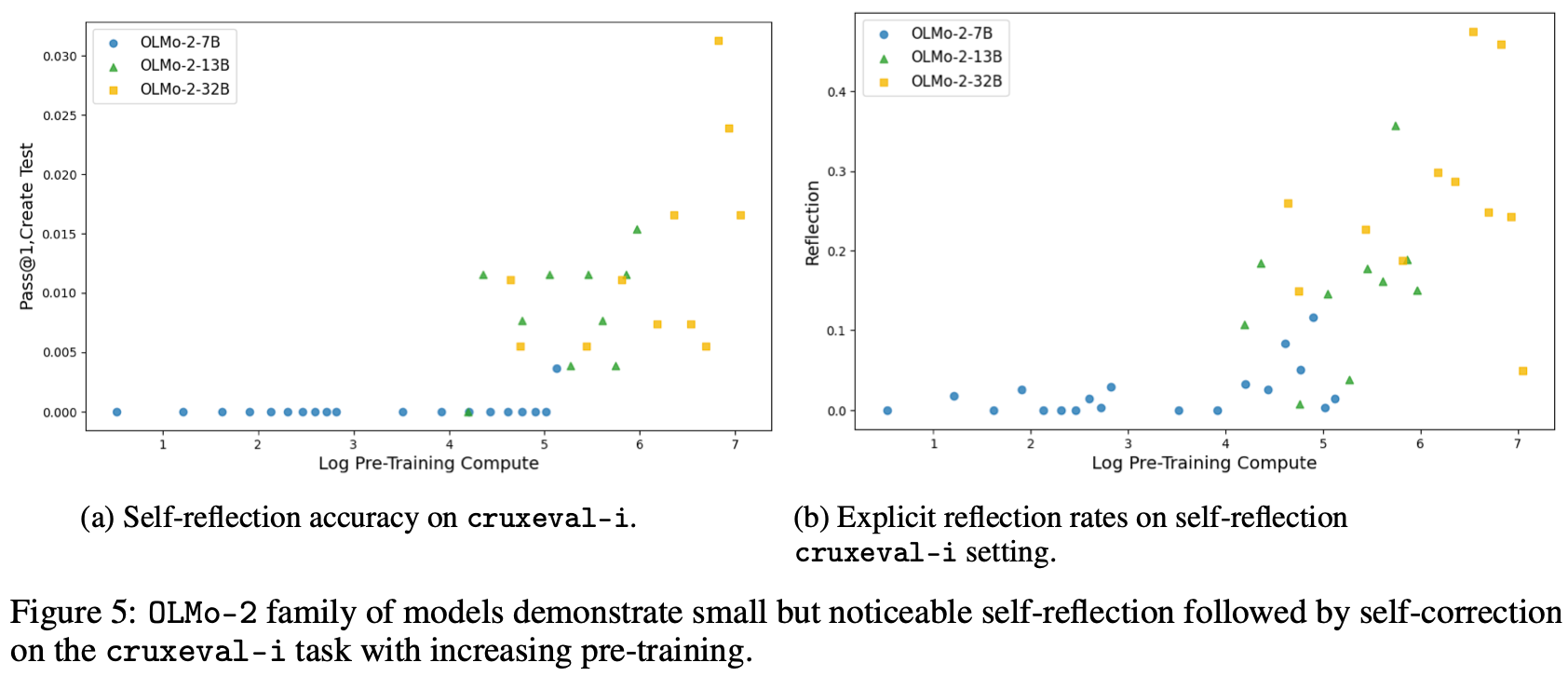
这些自我反思的萌芽如何在训练后演变成复杂的自主推理能力,这是一个悬而未决的问题,留待未来研究。作者猜测,预训练的自我反思能力必然存在一个临界阈值,超过这个阈值,模型就很有可能发展成为测试时推理器。在从有机网络数据集学习时,发现了上图中表现出来的显式自我反思。在预训练阶段,精准定位能够促进显式自我反思的数据分布是我们工作的下一个自然步骤。所有六项任务的详细结果可在附录 D 中找到。
5.4 One Can Trade Training for Test-time Compute
作者研究了在增加训练时间计算投入与测试时间相应成本之间的权衡,以便在下游任务上实现相当的准确率。估算训练时间计算量为 6 n t 6nt 6nt,其中 n n n 和 t t t 分别是参数和训练 token 的数量;测试时间计算量为 2 n w 2nw 2nw,其中 w w w 表示为解决一定数量的对抗性问题而生成的单词数量。
首先设定一组需要正确回答的对抗性问题的目标数量。然后为每个目标绘制一条曲线。针对之前介绍的 GSM8K-Platinum 对抗性数据集进行了研究。遵循一种顺序测试时间扩展方法,在模型生成过程中附加触发器“Wait”。引入了两个“Wait”触发器,以使较弱的模型能够达到与较强的模型相同的指标水平。
如Fig.6 所示,随着训练时间计算量的增加,OLMo-2-32B 检查点的测试时间计算量需求有所下降。这一结果进一步佐证了先前的假设:随着预训练的进行,模型的反思性能会不断提升,这意味着在给定准确率的情况下,测试时间计算量会减少。

5.5 Do we see similar results in stronger model families?
为了研究不同模型系列的这些现象,Fig.7 报告了 Qwen2.5 在对抗任务上的结果。与 OLMo-2 的结果一致,随着预训练计算量的增加(在本例中是参数数量的增加),模型在对抗任务上的性能持续提升。这再次证明,即使先前的推理存在错误,仅凭预训练计算,模型也能越来越有效地解决任务。
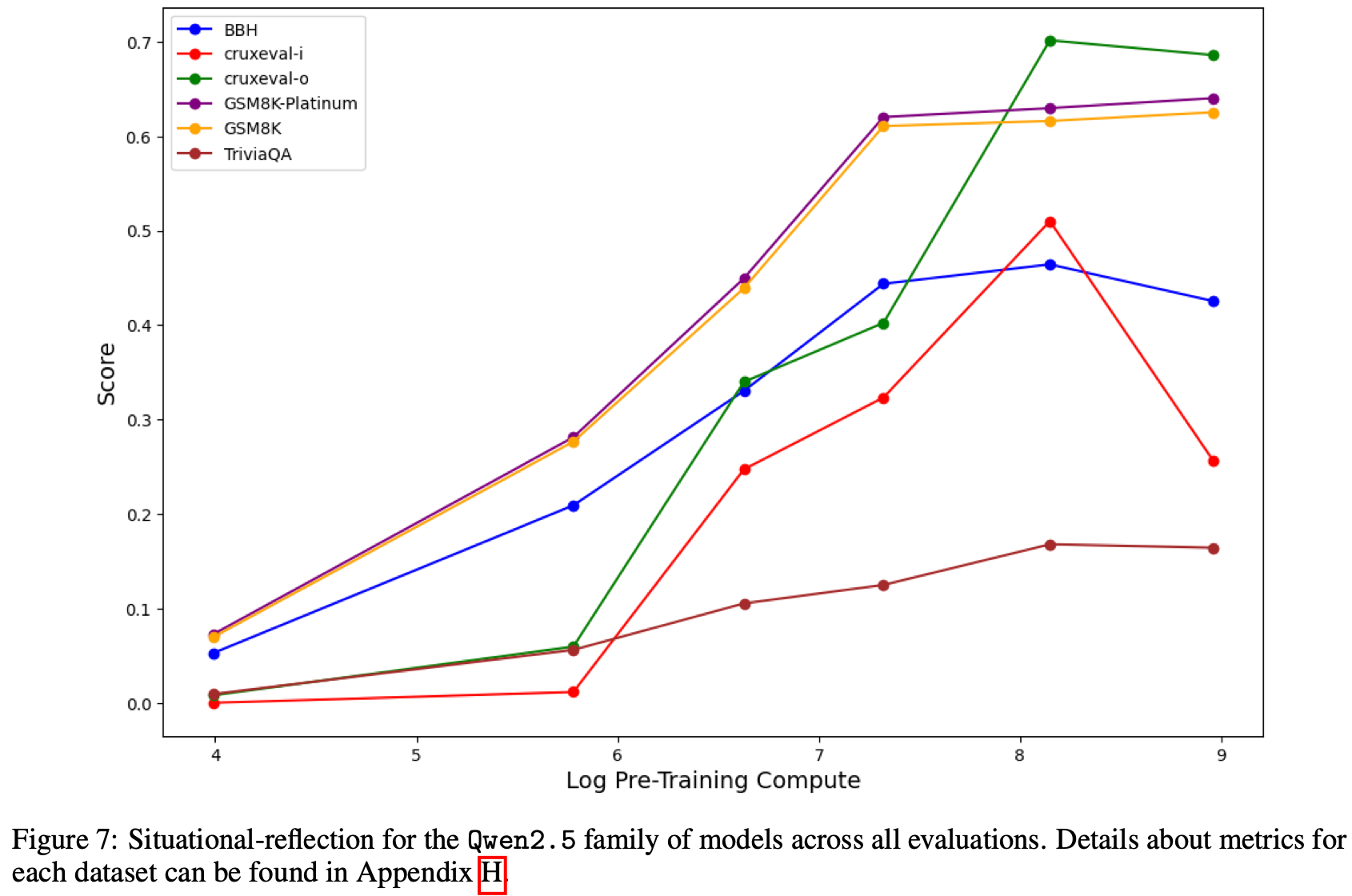
6. Conclusion
这项工作的目标是回答“反思推理如何在预训练期间进步?”这个问题,这与普遍持有的观点相反,即反思是在训练后通过强化学习出现的。作者提出并实施了一个全面的框架来衡量整个预训练过程中的反思能力。通过对抗数据集,无论是情境反思还是自我反思设置,都能够广泛地校准这些能力。实验发现,用很少的训练失败训练的模型,比如用 1980 亿个标记训练的 OLMo-2-7B,在数学、代码、语言、逻辑推理方面表现出反思能力。此外,随着在预训练上花费更多的计算力,这些能力将进一步增强。