Redis 主从同步与对象模型(四)
目录
1.淘汰策略
1.1 expire/pexpire(设置键的过期时间)
1.2 配置
1.maxmemory
2.maxmemory-policy
3.maxmemory-samples
2.持久化
2.1背景
2.2 fork 的写时复制机制
2.3 大 key
3.持久化方式
3.1 aof(Apped Only File)
3.2 aof-rewrite
3.3 rdb(Redis DataBase)
3.4 rdb-aof 混用
3.5 大 key 对持久化影响
4.高可用
4.1 redis 主从复制
4.2 哨兵模式
4.3Redis cluster集群
1.淘汰策略
redis 是内存数据库
1.1 expire/pexpire(设置键的过期时间)
| 命令 | 说明 |
| EXPIRE key seconds | 设置 key 在 seconds 秒后过期 |
| PEXPIRE key milliseconds | 设置 key 在 milliseconds 毫秒后过期 |
| TTL key / PTTL key | 查看 key 剩余过期时间 |
| PERSIST key | 移除 key 的过期时间,使其永久存在 |
1.2 配置
1.maxmemory
- 设置 Redis 最大可用内存限制
- 单位支持 : bytes,kb,mb,gb
- 例如: maxmemory 4gb
2.maxmemory-policy
| 策略 | 含义 |
| noeviction | 不删除任何数据,写操作会报错 |
| allkeys-lru | 所有 key 中,淘汰最近最少使用的 key |
| volatile-lru | 仅在设置了过期时间的 key 中,淘汰最近最少使用的 |
| allkeys-random | 所有 key 中,随机选择 key 进行淘汰 |
| volatile-random | 仅在设置了过期时间的 key 中,随机淘汰 |
| allkeys-lfu | 所有 key 中,淘汰使用频率最低的 key |
| volatile-lfu | 仅在设置了过期时间的 key 中,淘汰使用频率最低的 |
| volatile-ttl | 仅在设置了过期时间的 key 中,淘汰即将过期的 key |
注:volatile 策略只作用于设置了过期时间的键
allkeys 策略作用于所有的键
3.maxmemory-samples
在执行策略时,从样本中采样,然后从中选出最符合淘汰机制的key
例如: 设置allkeys-lru,并设定 maxmemory-samples 10
Redis 会从所有 key 中随机采样 10 个,然后选出最近最少访问的那个key来淘汰
2.持久化
2.1背景
redis是内存数据库,重启需要加载回来原来的数据
2.2 fork 的写时复制机制
为了提高效率而采用的一种延迟复制优化策略
父子进程最初共享同一块物理内存,只有当任一方尝试修改内存时,才会复制对应页到新的物理内存,从而实现真正的“独立”
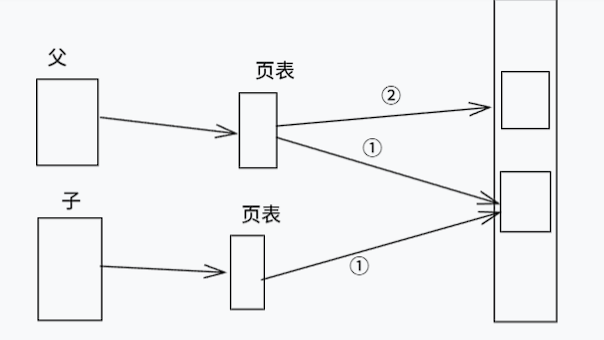
父进程对数据修改,触发写保护中断,从而进行物理内存的复制,父进程的页表指向新的物理内存(谁修改谁指向新的物理内存)
发生写操作时候才会去复制物理内存
避免物理内存复制时间过长导致父进程长时间阻塞
2.3 大 key
占用内存较大或成员数量非常多的 Key,比如 v 中存储的时 hash 或者 zset 这种数量比较多的类型
3.持久化方式
3.1 aof(Apped Only File)
AOF持久化通过记录服务器所执行的所有写操作命令来记录数据库状态。这些命令会被追加到AOF文件的末尾,支持:
- always:每次写命令都会同步(sync)写入到磁盘
- everysec:每秒将aof缓冲区内容同步到磁盘中(由后台线程执行,是默认的方式)
- no:Redis 只负责写入 aof 缓存,不主动同步到磁盘,由系统决定同步或手动同步
优点:
- 数据更安全
- 命令可读,易于恢复/调试
缺点:
- 文件体积大,性能开销高于 rdb
- 数据存在一定冗余
3.2 aof-rewrite
处理 aof 文件过大,减少 aof 数据恢复速度过慢
工作原理:
fork进程,根据内存数据生成 aof 文件,避免同一个 key 历史冗余,在重写 aof 期间,对 redis 的写操作记录到重写缓存区,当重写 aof 结束后,附加到 aof 文件末尾
3.3 rdb(Redis DataBase)
- 周期性将内存数据写入磁盘(.rdb文件)
- 通过 fork 子进程来执行,不影响主线程
- rdb 存储的是经过压缩的二进制数据
优点:
文件小,恢复速度块
缺点:
有数据丢失的风险(最近一次快照之后的修改会丢失)
3.4 rdb-aof 混用
通过 fork 子进程,根据内存数据生成 rdb 文件,在rdb持久化期间,对redis 的写操作记录到重写缓冲区,当rdb 持久化结束后,附加到 aof 文件末尾
| 对比项 | RDB(快照) | AOF(追加日志) |
| 方式 | 定时保存内存数据的快照 | 每次写操作记录命令到日志文件 |
| 触发时机 | 定时或手动触发 | 每次写命令(可配置是否每次/fsync) |
| 启动恢复时间 | 快(直接加载快照) | 慢(需要回放全部命令) |
| 数据完整性 | 可能丢失几分钟数据 | 最多丢失1秒(默认 everysec) |
| 文件大小 | 紧凑、体积小 | 文件可能较大,命令多会膨胀 |
| 性能影响 | 运行中 fork 子进程保存快照,影响小 | 持续写磁盘,影响相对大 |
| 可读性 | 二进制文件,不可读 | 文本命令,可直接读懂、重放 |
| 使用场景 | 数据量大,恢复速度优先 | 数据安全要求高的业务 |
3.5 大 key 对持久化影响
- 对 RDB:fork 期间,写时复制(COW)会导致 内存急剧增长
- 对 AOF:每次修改都写入完整命令,大 key 会让文件迅速膨胀,AOF 重写成本高
- 会导致重启时间变长,甚至服务阻塞
4.高可用
4.1 redis 主从复制
- 异步复制:主节点将写操作同步到从节点,但不是实时同步(存在数据延迟)。
- 环形缓冲区:主节点维护一个固定大小的缓冲区保存最近的写命令,用于断线后快速增量同步。
- 复制偏移量:主从节点维护一个偏移量,表示同步的数据位置,用于比对是否需要全量(主从节点之间的数据全部重新同步的过程)或增量复制(主从节点之间同步断开期间 丢失的数据部分补充同步,无需全量)。
- runid:每个 Redis 实例有唯一运行 ID,复制过程中标识主节点身份。
作用:
- 解决了单点故障
- 高可用性的基础
4.2 哨兵模式
目的:实现 Redis 故障自动转移。仅仅保障了单节点的高可用(主节点宕机可自动切换,从节点提升为主)
流程:
- 主观下线:
- 客观下线
- 烧饼选举
- 从库选主
- 故障转移
如何使用
一个 Redis 哨兵(Sentinel)模式的配置与使用示例,包含:
- 1 个主节点(master)
- 2 个从节点(slave)
- 3 个哨兵(sentinel)
- 1 个客户端访问配置方式
1.主从配置
#主节点 redis-master.conf(6379)
port 6379
dir /data/redis/master
appendonly yes#从节点 redis-slave1.conf(6380)
port 6380
dir /data/redis/slave1
replicaof 127.0.0.1 6379
appendonly yes#从节点 redis-slave2.conf(6381)
port 6381
dir /data/redis/slave2
replicaof 127.0.0.1 6379
appendonly yes
2.哨兵配置(sentinel.conf)
每个哨兵配置几乎一样,只需修改端口和自身 IP
#哨兵1 sentinel1.conf(26379)
port 26379
dir /data/redis/sentinel1
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 10000
sentinel parallel-syncs mymaster 1
#其他两个哨兵只改端口和目录,比如:
sentinel2.conf: 端口 26380,目录 /data/redis/sentinel2
sentinel3.conf: 端口 26381,目录 /data/redis/sentinel3
3.启动
放到一个文件比如start下面,然后chmod +x,最后./start
# 启动主从
redis-server redis-master.conf
redis-server redis-slave1.conf
redis-server redis-slave2.conf# 启动哨兵
redis-sentinel sentinel1.conf
redis-sentinel sentinel2.conf
redis-sentinel sentinel3.conf缺点:
- 主观宕机存在误判风险
- 部署麻烦
- 没有避免数据丢失问题
- 没有数据扩展
4.3Redis cluster集群
去中心化结构,每个节点互相通信,无集中式主控节点,解决了数据扩展
特征:
- 客户端与服务端缓存槽位信息,以服务器为主,客户节点缓存主要为了避免连接切换
- 自动分片,16384(2^14)个哈希槽分配给不同节点
- 每个主节点可挂载一个或多个从节点实现高可用
流程:
- 客户端根据 key 计算哈希槽值。
- 连接对应槽所属的主节点。
- 若节点不对,返回 MOVED 重定向信息,客户端重新连接目标节点
缺点:
- 不支持多 key 操作跨槽执行(除非通过 hash tags)。
- 集群节点间通讯复杂,部署维护成本高。
- 客户端需支持 Redis Cluster 协议