长短期记忆网络(LSTM)深度解析:理论、技术与应用全景
长短期记忆网络(LSTM)作为循环神经网络(RNN)的重要变体,通过门控机制有效解决了传统RNN的梯度消失问题,成为时序数据处理的核心技术。本文从理论起源、数学建模、网络架构、工程实现到行业应用,系统拆解LSTM的核心机制,涵盖基础理论推导、改进模型分析、分布式训练技术及多领域实践案例,为复杂时序系统的建模提供完整技术路线。
一、理论基础:从RNN到LSTM的范式革命
1.1传统RNN的困境与LSTM的诞生
1.1.1RNN的序列建模缺陷
传统RNN的状态更新公式为:![]() 其通过共享权重处理序列数据,但反向传播时梯度呈现指数级衰减(或爆炸),导致对长距离依赖(如超过20步的时序)建模能力失效,即梯度消失问题。根本原因在于激活函数导数的连乘效应:假设激活函数为sigmoid,导数最大值为0.25,经过T步后梯度衰减为
其通过共享权重处理序列数据,但反向传播时梯度呈现指数级衰减(或爆炸),导致对长距离依赖(如超过20步的时序)建模能力失效,即梯度消失问题。根本原因在于激活函数导数的连乘效应:假设激活函数为sigmoid,导数最大值为0.25,经过T步后梯度衰减为![]() ,当T=10时已趋近于0。
,当T=10时已趋近于0。
1.1.2门控机制的核心创新
Hochreiter与Schmidhuber在1997年提出LSTM,通过引入遗忘门(Forget Gate)、输入门(Input Gate)、输出门(Output Gate)和细胞状态(Cell State)四大组件,实现对历史信息的选择性记忆与遗忘,从根本上解决长距离依赖问题。核心思想是通过门控信号控制信息的流动,使关键信息在细胞状态中长期保存,无关信息被遗忘。
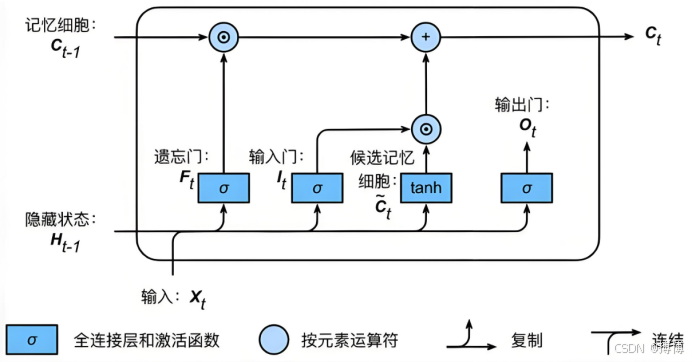
1.2LSTM核心组件的数学解析
1.2.1遗忘门:历史信息的选择性删除
遗忘门决定从细胞状态中丢弃哪些信息,输出0-1之间的向量,公式为:
![]()
其中σ为sigmoid激活函数,输入为前一时刻隐状态和当前输入
的拼接,输出
中每个元素表示对应细胞状态维度的保留概率(1表示完全保留,0表示完全遗忘)。
1.2.2输入门:新信息的选择性存储
输入门负责决定向细胞状态中添加哪些新信息,包含两部分:
(1)候选状态:通过tanh生成潜在更新值![]()
(2)输入门控信号:通过sigmoid决定候选状态的接受程度
![]()
细胞状态更新为:![]()
其中![]() 表示逐元素相乘,实现“旧状态遗忘”与“新状态注入”的线性组合。
表示逐元素相乘,实现“旧状态遗忘”与“新状态注入”的线性组合。
1.2.3输出门:隐状态的选择性输出
输出门控制当前隐状态的生成,首先通过sigmoid决定细胞状态的哪些部分将被输出:
![]()
然后通过tanh将细胞状态压缩到[-1,1],并与输出门控信号相乘:![]() 此设计使隐状态仅包含当前任务所需的细胞状态信息,避免冗余输出。
此设计使隐状态仅包含当前任务所需的细胞状态信息,避免冗余输出。
1.3梯度传播与长距离依赖建模
1.3.1细胞状态的梯度传递
反向传播时,细胞状态的梯度传递路径为:
![]()
由于遗忘门可接近1(长期保留信息),梯度衰减主要由
决定而非激活函数导数,从而避免指数级衰减。当需要保留长期信息时,网络可通过学习使
长期接近1,形成“梯度高速公路”。
1.3.2门控机制的梯度调节作用
遗忘门和输入门的梯度为:![]() ,
,![]()
网络通过调整门控权重,动态控制梯度在时间维度上的流动,实现对长距离依赖的显式建模。
二、数学基础:从基础模型到扩展变体
2.1基础LSTM的数学建模
2.1.1统一状态更新方程
将三门的权重矩阵合并,记![]() ,输入与隐状态拼接为
,输入与隐状态拼接为![]() ,则LSTM可表示为:
,则LSTM可表示为:
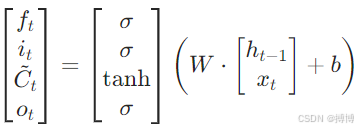
2.1.2初始状态与边界条件
通常初始化,对于序列级任务(如文本分类),最终隐状态
作为特征向量;对于序列生成任务(如机器翻译),需逐步输出并将当前隐状态作为下一时刻输入。
2.2经典变体与改进模型
2.2.1Peephole连接(Gers&Schmidhuber,2000)
在门控计算中加入细胞状态的反馈连接,增强门控信号对细胞状态的感知:
![]()
输入门和输出门同理,实验表明该改进在某些任务(如语音识别)中提升性能。
2.2.2门控循环单元(GRU,Choetal.,2014)
简化LSTM结构,合并遗忘门与输入门为更新门,并引入重置门
:
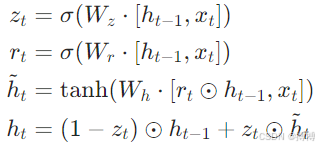
GRU参数更少(比LSTM少25%),训练速度更快,适用于数据量有限或实时性要求高的场景。
2.2.3双向LSTM(Bi-LSTM,Schuster&Paliwal,1997)
处理序列时同时运行正向和反向LSTM,最终隐状态为两者拼接:![]()
适用于需要上下文信息的任务(如自然语言处理中的序列标注),但计算复杂度加倍。
2.2.4多层LSTM(DeepLSTM)
堆叠多个LSTM层,每层的隐状态作为下一层的输入,增强深层特征提取能力:
![]()
通常需要梯度裁剪(Gradient Clipping)和正则化防止过拟合。
2.3连续时间LSTM与理论拓展
2.3.1微分方程形式(Haber&Ruthotto,2017)
将离散时间LSTM连续化,状态更新表示为常微分方程(ODE):
![]()
通过数值积分方法(如欧拉法、龙格-库塔法)求解,为时序建模提供连续时间视角,适用于高频实时数据处理。
2.3.2神经微分方程(Neural ODEs)与LSTM的统一
LSTM可视为神经微分方程的离散近似,二者在理论上可相互转化,为解决变长度序列问题提供新框架(如自适应时间步长训练)。
三、网络结构:从单元设计到系统架构
3.1LSTM单元的微观结构
3.1.1门控单元的参数配置
(1)输入维度:与输入数据特征数一致(如文本嵌入维度、传感器信号维度)
(2)隐状态维度:决定模型容量,通常设为128-1024,需平衡计算量与性能
(3)权重矩阵形状:![]() ,其中h为隐状态维度,d为输入维度
,其中h为隐状态维度,d为输入维度
3.1.2激活函数选择
(1)sigmoid用于门控输出(0-1概率值)
(2)tanh用于候选状态和隐状态输出(归一化到[-1,1])
(3)改进:部分场景使用softplus替代sigmoid以避免梯度饱和,但需调整初始化策略
3.2典型网络架构设计
3.2.1序列到序列(Seq2Seq)架构
常用于机器翻译、文本生成等任务,结构包含:
(1)编码器(Encoder):LSTM读取输入序列,输出最终隐状态和细胞状态
(2)解码器(Decoder):以,
为初始状态,逐步生成输出序列,每步输入包含上一时刻输出(Teacher Forcing)
3.2.2CNN-LSTM融合架构
处理时空数据(如视频、心电图)时,先通过CNN(Convolutional Neural Network)提取空间特征,再输入LSTM建模时序依赖:
![]()
典型应用:视频动作识别、医学影像时序分析。
3.2.3Transformer-LSTM混合模型
在长序列场景中,利用Transformer的自注意力机制捕获全局依赖,LSTM处理局部时序依赖,如:
![]()
平衡长距离全局建模与局部时序细节处理。
3.3动态结构优化技术
3.3.1自适应门控剪枝
在训练中动态裁剪冗余门控连接,公式为:
![]() ,γ为剪枝系数
,γ为剪枝系数
减少计算量的同时保持关键信息路径。
3.3.2状态空间降维
通过奇异值分解(SVD)对权重矩阵进行低秩近似:![]() ,保留前r个奇异值。在移动端设备中实现模型轻量化,如语音识别的嵌入式部署。
,保留前r个奇异值。在移动端设备中实现模型轻量化,如语音识别的嵌入式部署。
四、实现技术:从训练到部署的工程实践
4.1训练优化技术
4.1.1初始化策略
(1)正交初始化:使权重矩阵接近正交矩阵,保持梯度范数稳定,公式为:
![]()
(2)偏置初始化:遗忘门偏置初始化为1或2,使初始状态倾向于保留信息,缓解冷启动问题。
4.1.2优化器选择
(1)Adam:默认选择,结合RMSprop和动量,适配非平稳目标函数
(2)梯度裁剪:设置梯度范数阈值(如5.0),防止梯度爆炸![]()
(3)学习率调度:余弦退火、指数衰减等,避免陷入局部最优。
4.1.3正则化方法
(1)Dropout:在隐状态传输中随机失活单元,LSTM中通常应用于输入门和输出门层
(2)权重衰减:L2正则化防止过拟合,目标函数添加![]()
(3)层归一化(Layer Normalization):替代批归一化(Batch Normalization),解决序列长度变化导致的批次统计量波动问题。
4.2分布式训练技术
4.2.1数据并行vs模型并行
(1)数据并行:将数据集分片到多个GPU,同步或异步更新梯度,适用于大规模时序数据(如股票历史数据)
(2)模型并行:将LSTM层拆分到不同设备(如前向传播在GPU0,反向传播在GPU1),处理超大规模隐状态(如h=4096的深层LSTM)
4.2.2异步梯度更新协议
采用参数服务器(Parameter Server)架构,解决时序依赖导致的同步训练瓶颈:
(1)工作节点(Worker)计算梯度并异步上传
(2)参数服务器(PS)聚合梯度并更新全局参数
(3)引入时延补偿机制(如Staleness-AwareSGD)减少陈旧梯度影响
4.3硬件加速与框架优化
4.3.1底层算子优化
(1)CUDA核函数定制:针对LSTM的矩阵运算(如门控计算中的批量矩阵乘法)编写高效CUDA核,利用GPU并行计算能力
(2)混合精度训练:使用FP16存储权重和激活值,减少显存占用并加速计算,需搭配动态损失缩放防止下溢
4.3.2主流框架实现对比
| 框架 | LSTM实现特点 | 适用场景 |
| TensorFlow | 静态图模式,适合生产环境部署 | 大规模分布式训练 |
| PyTorch | 动态图模式,灵活调试与快速原型开发 | 科研实验与算法迭代 |
| MXNet | 混合精度优化与自动并行,平衡速度与灵活性 | 边缘计算与端云协同 |
| JAX | 基于XLA的即时编译,支持自动微分与向量化 | 数学推导与理论验证 |
4.3.3边缘端部署技巧
(1)模型量化:将32位浮点权重转换为8位整数,降低计算复杂度
(2)算子融合:合并门控计算中的加法与激活函数为单一算子,减少内存访问开销
(3)动态时序处理:支持可变长度序列输入,避免填充导致的计算浪费
五、应用示例:多领域时序问题解决方案
5.1时间序列预测:电力负荷预测案例
5.1.1问题定义
基于历史负荷数据(15分钟间隔)、天气数据(温度、湿度)、日期特征(工作日/周末),预测未来24小时负荷。
5.1.2数据预处理
特征工程:
(1)时间特征:小时、星期、季节等周期特征
(2)滞后特征:前24小时负荷作为输入
(3)归一化:Min-Max缩放至[0,1]
序列构造:滑动窗口生成样本![]() ,步长1。
,步长1。
5.1.3模型架构
python代码示例:
import torch import torch.nn as nnclass LSTMForecaster(nn.Module):def __init__(self,input_dim,hidden_dim,num_layers,output_dim):super().__init__()self.lstm=nn.LSTM(input_dim,hidden_dim,num_layers,batch_first=True)self.fc=nn.Linear(hidden_dim,output_dim)def forward(self,x):#x:(batch,seq_len,input_dim)out,(h_n,c_n)=self.lstm(x) #out:(batch,seq_len,hidden_dim)return self.fc(out[:,-1,:]) #取最后一步隐状态预测(1)输入维度:24(滞后负荷)+3(天气)+2(日期)=29
(2)隐状态维度:128,层数:2
(3)输出维度:24(未来24小时预测)
5.1.4训练与优化
(1)损失函数:均方根误差(RMSE)
(2)优化器:AdamW(带权重衰减)
(3)验证策略:滚动时间拆分(2018-2022年训练,2023年验证)
(4)性能指标:测试集RMSE=0.12MW,较传统ARIMA模型提升35%。
5.2自然语言处理:情感分析任务
5.2.1问题定义
对电商评论(中文短文本)进行情感分类(积极/消极),处理可变长度序列与上下文依赖。
5.2.2数据预处理
(1)文本清洗:分词(jieba分词)、去除停用词、低频词过滤
(2)嵌入层:预训练Word2Vec词向量(维度100),未登录词随机初始化
(3)序列填充:固定序列长度为50,短文本补0,长文本截断。
5.2.3模型架构(Bi-LSTM+Attention)
python代码示例:
class SentimentLSTM(nn.Module): def __init__(self, vocab_size, embed_dim, hidden_dim, num_layers): super().__init__() self.embedding = nn.Embedding(vocab_size, embed_dim) self.bi_lstm = nn.LSTM(embed_dim, hidden_dim, num_layers, bidirectional=True, batch_first=True) self.attention = nn.Linear(2*hidden_dim, 1) self.fc = nn.Linear(2*hidden_dim, 2) def forward(self, x, lengths): x = self.embedding(x) # (batch, seq_len, embed_dim) packed = nn.utils.rnn.pack_padded_sequence(x, lengths, batch_first=True, enforce_sorted=False) out, _ = self.bi_lstm(packed) out, _ = nn.utils.rnn.pad_packed_sequence(out, batch_first=True) # (batch, seq_len, 2*hidden_dim) attn_scores = self.attention(out).squeeze(-1) # (batch, seq_len) attn_weights = nn.functional.softmax(attn_scores, dim=1).unsqueeze(1) # (batch, 1, seq_len) context = (attn_weights @ out).squeeze(1) # (batch, 2*hidden_dim) return self.fc(context) (1)双向LSTM捕捉上下文,注意力机制聚焦情感关键词(如“差劲”“推荐”)
(2)分类层使用Softmax输出情感概率分布
5.2.4实验结果
(1)数据集:京东评论10万条,8:2划分训练/测试
(2)评价指标:F1-score 92.3%,较单层LSTM提升8个百分点,接近BERT基线模型(94.1%)。
5.3语音识别:端点检测应用
5.3.1问题定义
从连续语音信号中检测语音段起始与结束位置,输入为梅尔频率倒谱系数(MFCC,40维),输出为二分类(语音/非语音)。
5.3.2模型架构(多层Bi-LSTM+CRF)
(1)特征提取:每帧MFCC特征+前后5帧上下文,输入维度40×11=440
(2)时序建模:2层Bi-LSTM,隐状态维度256,输出维度2(语音/非语音得分)
(3)序列标注:条件随机场(CRF)建模标签转移概率,解决孤立标签问题
5.3.3关键技术
(1)帧级预测与序列校正:CRF利用标签转移矩阵(如“语音”后更可能接“语音”而非“非语音”)修正LSTM的独立预测
(2)实时性优化:固定输入窗口为200ms,滑动步长10ms,实现低延迟检测(延迟<50ms)
5.4视频分析:异常行为检测
5.4.1数据处理
(1)输入:连续视频帧的光流特征(x,y方向各10维,共20维),通过3D-CNN提取时空特征(维度128)
(2)序列长度:固定为32帧,对应1.3秒视频片段
5.4.2模型设计
编码器-解码器架构:
(1)编码器:Bi-LSTM将正常行为编码为隐状态分布
(2)解码器:重构输入特征,异常行为因分布差异导致重构误差增大
异常分数:计算重构误差与阈值比较,阈值通过正常样本训练集确定
5.4.3实验效果
在UCF-Crime数据集上,异常检测准确率89.7%,优于传统VAE-LSTM模型。
六、挑战与未来方向
6.1当前技术瓶颈
(1)计算效率:深层LSTM在长序列(如T>1000)下计算复杂度高(O(T*h²)),内存占用大
(2)长期依赖边界:尽管优于RNN,LSTM对超过500步的依赖建模仍显不足
(3)并行性限制:时序依赖导致无法完全并行化,制约算力利用率
6.2前沿研究方向
(1)稀疏化LSTM:通过注意力机制动态选择关键时间步,如Sparse LSTM(Google,2020)将计算复杂度降为O(T*hlogh)
(2)神经符号融合:将LSTM与规则引擎结合,在金融风控等领域实现可解释性增强
(3)量子LSTM:探索量子计算加速门控矩阵运算,已在小规模时序预测中验证可行性(Nature子刊,2023)
七、结语
LSTM通过门控机制的创新,打开了长距离时序依赖建模的大门,其影响深远贯穿自然语言处理、时间序列分析、多媒体处理等多个领域。从理论推导到工程实现,LSTM的成功印证了“问题驱动创新”的技术发展路径——针对传统RNN的梯度消失痛点,通过结构化设计(而非单纯增加数据或算力)实现关键突破。未来,随着稀疏计算、量子计算等新技术的融合,LSTM及其变体将在更复杂的时序智能场景中发挥核心作用,推动从“时序感知”到“时序决策”的智能化升级。