强化学习系列:深度强化学习和DQN
1. 往期回顾
-
介绍了强化学习的基本概念和基本原理
-
介绍了基于动态规划的传统强化学习——价值迭代、策略迭代
-
介绍了在无模型的环境下,基于时序差分的表格型强化学习——Q-learning、SARSA
这些传统的方法都有各自的局限性,能适用的范围有限,无法应对许多复杂的实际场景。比如在上期介绍的Q-learning算法中,我们构造了一个多维数组存储每一个状态下的动作Q值,使用时直接索引即可,但在实际中几乎很少有这么小而简单的状态空间。
这种用表格存储动作价值的做法只在环境的状态和动作都是离散的,并且空间都比较小的情况下适用,我们之前进行代码实战的几个环境都是如此(如悬崖漫步)。当状态或者动作数量非常大的时候,这种做法就不适用了。例如,当状态是一张 RGB 图像时,如果图像大小是210*160*3,此时一共有种状态256^(210*160*3)种状态,在计算机中存储这个数量级的表格是不现实的。更重要的是,当状态或者动作连续的时候,就有无限个状态动作对,我们更加无法使用这种表格形式来记录各个状态动作的值。
传统的方法已经无法解决这些问题,从本期开始我们正式进入深度强化学习(DRL)的大门,由于深度学习使用数据来学习的方式与无模型强化学习通过采样数据来学习的方式不谋而合,所以我们将深度神经网络与强化学习结合,解决更复杂场景下的决策问题。
我们从深度强化学习最基本的DQN算法开始。
《深度强化学习》和人工智能入门学习zi料包
【1.超详细的人工智能学习大纲】:一个月精心整理,快速理清学习思路!
【2.基础知识】:Python基础+高数基础
【3.机器学习入门】:机器学习经典算法详解
【4.深度学习入门】:神经网络基础(CNN+RNN+GAN)
扫马获取:

2. DQN——Deep Q-learning Network
2.1 简介
DQN顾名思义就是用深度神经网络实现的Q-learning,为什么要用深度神经网络来实现Q-learning?
对于上面的情形,表格方法不再适用,但是考虑到表格也是一种映射或者说一个函数,它将每个可枚举的状态的索引和Q值一一对应。面对不可枚举的状态,我们考虑用函数拟合的方法来估计Q值,把这个无法离散表示出来的”Q表格“用一个参数化的Q_{\theta}函数来表示,我们通过拟合这个函数来代替精确的表格计算,从而得到Q值的估计。
这种函数拟合的方法存在一定的精度损失,因此被称为近似方法。我们今天要介绍的DQN 算法便可以用来解决连续状态下离散动作的问题。
2.2 DQN

2.2 Q网络的训练
熟悉深度学习的人都知道,神经网络的训练或者说参数更新,是由梯度的反向传播(BP)来实现的,而梯度又由这个神经网络的输出与实际值之间的误差——损失函数来产生的。所以,我们在深度学习视角下将上面的问题描述为:如何为Q网络构造一个损失函数,使得由这个损失函数产生的梯度反向传播参数更新等价于时序差分更新规则。

有了预测值和目标值,就可以定义损失函数了。由于这两项都是连续的标量值,它们之间的差距就可以用均方误差(MSE)来刻画,这样我们就可以正式导出DQN的Q网络损失函数了:

2.3 目标网络和经验回放池
经过前面的分析和推导,我们找到了用神经网络来实现时序差分的方法,这时已经可以开始训练Q网络来实现DQN算法了,但是由于神经网络本身的一些性质,我们还需要解决两个问题——训练稳定性和收敛性和数据分布,才能保证DQN算法本身足够稳定。
2.3.1 目标网络

那么问题又来了,新构造的这个目标Q网络又如何更新呢?如果两套网络的参数随时保持一致,则仍为原先不够稳定的算法。

2.3.2 经验回放池
在一般的有监督学习中,假设训练数据是独立同分布的,我们每次训练神经网络的时候从训练数据中随机采样一个或若干个数据来进行梯度下降。
在原来的 Q-learning 算法中,每一个数据只会用来更新一次值。为了更好地将 Q-learning 和深度神经网络结合,DQN 算法采用了经验回放(experience replay)方法,具体做法为维护一个回放缓冲区,将每次从环境中采样得到的四元组数据(状态、动作、奖励、下一状态)存储到回放缓冲区中,训练 Q 网络的时候再从回放缓冲区中随机采样若干数据来进行训练。这么做可以起到以下两个作用。
-
使样本满足独立假设。在 MDP 中交互采样得到的数据本身不满足独立假设,因为这一时刻的状态和上一时刻的状态有关。非独立同分布的数据对训练神经网络有很大的影响,会使神经网络拟合到最近训练的数据上。采用经验回放可以打破样本之间的相关性,让其满足独立假设。
-
提高样本效率,每一个样本可以被使用多次,十分适合深度神经网络的梯度学习。
2.4 DQN算法
解决所有问题之后,我们就得到一个完整的强化学习DQN算法了。DQN只负责估计Q值,在具体行动策略上依然采用 epsilon-greedy贪婪算法,这一点与传统的Q-learning一样。综合上面所有分析,DQN的算法流程如下:

3. DQN实践
3.1 环境介绍——LunarLander
LunarLander——月球登陆器,这是一个平面二维游戏,经典的轨迹优化问题。登陆器有3个引擎(左、右、主引擎,主引擎)。假设燃料无限,游戏的任务是需要控制引擎将登陆器着陆在月球表面(指定的登陆点:下图下方中央两个旗子中间的区域),允许在登陆点外区域着陆。游戏有离散和连续动作两个版本,为了方便演示DQN,这里使用离散动作版本。
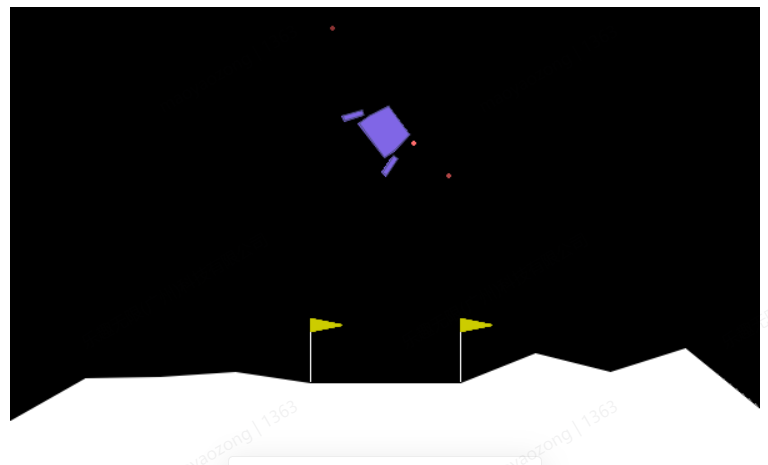
| 动作空间 | 0,1,2,3 |
| 状态空间 | [-1.5 -1.5-5.-5.-3.1415927-5.-0.-0.] ~ [1.51.55.5.3.14159275.1.1. ],(8,) |
动作空间
离散版本的动作空间有4种动作:
-
0:不做任何事情,即登陆器按月球重力加速度下降
-
1:左引擎点火,即向右
-
2:主引擎点火,即向上
-
3:右引擎点火,即向左
状态空间
状态空间是一个8维向量,包括:
-
登陆器在画面中的坐标(x, y),登陆区中心坐标为(0, 0)
-
登陆器水平和垂直方向的速度 (vx, vy)
-
登陆器水平角度和角速度 (\theta,\omega)
-
登陆器的左右支撑脚是否触达月球表面的两个布尔型状态(L, R)
初始状态,登陆器总是出现在画面中央上方,并被施加一个随机的外力(随机的初速度、角度等)
奖励函数
环境对每一步动作进行奖励:
-
当登陆器靠近/远离登陆点,奖励增加/减少
-
当登陆器速度增加/减少,奖励减少/增加
-
当登陆器倾斜过大(水平角度过大),奖励减少
-
每有一个支撑脚触达月面,奖励+10
-
每一步,每有一个侧翼引擎开火,奖励-0.03
-
每一步,主引擎开火,奖励-0.3
-
当登陆器在登陆点安全着陆/坠毁、飞出画面,获得额外+100/-100奖励
终止条件
-
坠毁,登陆器除了支撑脚之外的其他部位接触月球表面
-
安全着陆(包括在着陆点外着陆)
-
登陆器飞出画面范围
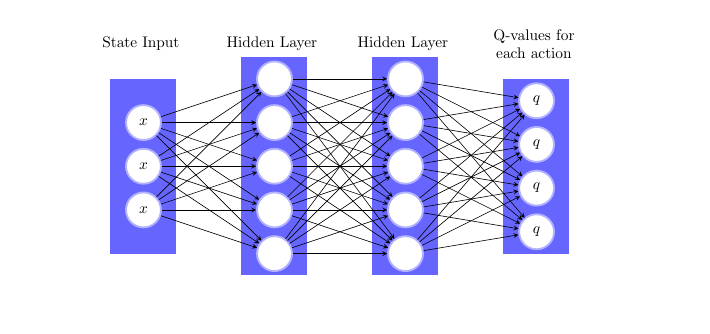
Q网络
Q网络结构,一个典型的MLP结构,输入状态向量,输出所有4个动作的Q值。
4. 结语
本期是深度强化学习的第一章,介绍了DRL中最基础的DQN算法,在深度神经网络的加持下强化学习,保证了算法的收敛性的同时又突破了传统方法的限制。学习了DQN之后,我们理论上可以处理任何类型的状态空间,但是,动作空间仍然是离散的。我们今后将继续介绍更多的DRL算法,进一步扩宽强化学习的适用范围,应对更加复杂的环境。
《深度强化学习》和人工智能入门学习zi料包
【1.超详细的人工智能学习大纲】:一个月精心整理,快速理清学习思路!
【2.基础知识】:Python基础+高数基础
【3.机器学习入门】:机器学习经典算法详解
【4.深度学习入门】:神经网络基础(CNN+RNN+GAN)
扫马获取: