RAG vs 传统生成模型:核心差异与适用场景
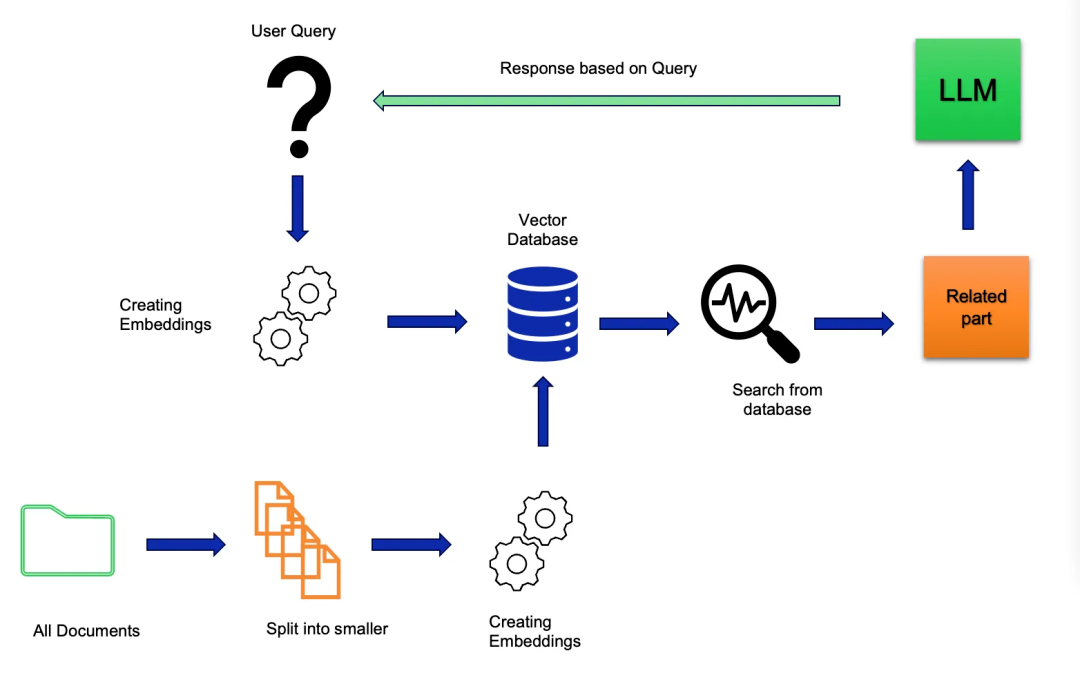
一、核心差异解析
-
知识获取机制的根本变革
传统生成模型(如 GPT-4、Llama 3)依赖静态参数存储知识,训练数据截止后无法更新。例如,若训练数据截止到 2023 年,模型无法回答 2024 年的 GDP 预测问题。而 RAG(检索增强生成)通过向量数据库(如 FAISS、Elasticsearch)实时检索外部知识库,将最新文档片段融入生成过程。阿里巴巴 ViDoRAG 系统在视觉文档处理中,通过多模态检索将准确率提升至 79.4%,较传统 RAG 提升 10% 以上。 -
准确性与幻觉问题的突破
传统模型易产生 "幻觉",如在医疗咨询中虚构药物相互作用。RAG 通过检索真实文献片段,将生成内容锚定在事实基础上。实验表明,RAG 在开放领域问答任务中准确率比 BART 基线提升 20% 以上,且生成内容更具体、事实性更强。校正型 RAG 进一步引入评估机制,通过自我反思将错误率降低 25%。 -
上下文处理的范式转换
传统模型受限于固定上下文窗口(如 4K token),难以处理长文档。RAG 采用分块检索策略,将文档切分为 200-500 字的片段,通过混合检索(向量 + 关键词)提升相关性。Block-Attention 技术更将长文本处理效率提升 98.7%,实现与非 RAG 模型相当的响应速度。 -
领域适应性的显著差异
传统模型通用性强但垂直领域表现不足。RAG 通过定制知识库实现专业场景突破:
- 医疗领域:整合最新临床指南,生成诊断建议的准确率提升 40%
- 法律领域:检索案例法和法规,法律意见书的事实错误率降低 30%
- 教育领域:解析教材生成个性化习题,知识点掌握率提升 40%
- 可解释性与可信度的提升
RAG 生成的答案可追溯至具体文档片段,如在企业知识库中,每条回答都标注来源文档的章节和段落。这种可追溯性使 RAG 在金融审计、合规审查等场景中更具优势,而传统模型的黑箱特性难以满足此类需求。
二、典型适用场景对比
| 场景类型 | 传统生成模型 | RAG 模型 |
|---|---|---|
| 开放域问答 | 适合娱乐性问题(如 "如何制作披萨"),但对时效性问题(如 "2025 年诺贝尔奖得主")可能错误 | 实时检索权威数据源,如维基百科、新闻库,准确率提升 30% 以上 |
| 专业领域咨询 | 缺乏领域知识,如医疗咨询可能给出过时疗法 | 整合行业数据库,如 UpToDate 医学指南,生成建议的准确率达 79.4% |
| 多模态内容生成 | 仅支持文本生成,无法处理图像、表格等数据 | 多模态 RAG 可检索图片、PDF 表格,如 ViDoRAG 在合同分析中提取关键条款的准确率达 85% |
| 复杂逻辑推理 | 难以处理多步骤推理(如数学证明) | 自我反思型 RAG 通过动态迭代推理,在 GSM8K 数学数据集上超越专家设计提示链 54% |
| 企业知识管理 | 无法实时更新内部知识库,导致信息滞后 | 结合企业文档库,如 Haystack 在客服场景中实现 90% 问题自动解答,响应速度提升 5 倍 |
三、技术实现与选型建议
- 核心技术栈对比
- 传统模型:依赖预训练模型 + 微调,如 GPT-4 API 调用成本约 $0.06/1K token
- RAG 架构:需构建 "分块 - 向量化 - 检索 - 融合" 流水线,典型框架包括:
- LangChain:适合快速原型开发,支持 700 + 工具集成,适合电商客服等复杂场景
- Haystack:企业级首选,支持 K8s 部署和混合检索,在医疗领域错误率降低 25%
- DSPy:声明式编程降低门槛,利用小模型实现与 GPT-3.5 相当性能,成本减少 60%
- 性能优化策略
- 检索效率:采用 HNSW 索引实现十亿级数据毫秒级检索,Block-Attention 技术将首字延时降低 98.7%
- 成本控制:DSPy 的 MIPROv2 优化器减少 30% LLM 调用次数,Haystack 的缓存机制降低 50% 重复查询成本
- 多模态处理:ViDoRAG 通过 GMM 混合检索实现图像 - 文本联合推理,准确率提升 10%
- 落地挑战与应对
- 数据质量:需建立数据清洗流程,如医疗场景中结构化病历的准确率需达 95% 以上
- 冷启动问题:采用 Bootstrapping 方法,先通过专家标注构建初始知识库
- 合规要求:金融场景需实现数据加密和访问审计,Haystack 的权限管理模块可满足 PCI-DSS 标准
四、未来发展趋势
- 智能检索升级
- 自我反思型 RAG 引入 "三位一体" 架构(检索器 + 评审器 + 生成器),在开放域问答中准确率提升至 62.3%
- Fast GraphRAG 结合知识图谱和 PageRank 算法,处理超大数据集的效率提升 6 倍
- 多模态融合深化
- 支持图像、音频、视频混合检索,如教育场景中结合实验视频生成操作指南
- 阿里巴巴 ViDoRAG 已实现 PDF 表格、流程图的智能解析,在合同审查中关键条款提取准确率达 85%
- 小模型增强方案
- DSPy 通过提示工程优化,使 T5-base 模型在数学推理任务中性能接近 GPT-3.5,成本降低 70%
- 缓存增强生成(CAG)预加载高频数据,减少实时检索需求,响应速度提升 3 倍
五、总结
RAG 通过 "检索 - 生成" 双引擎架构,在知识获取、准确性、领域适应性等维度实现了对传统生成模型的超越。其核心价值在于:
- 事实锚定:将生成内容与真实数据绑定,解决幻觉问题
- 动态进化:实时更新知识库,适应快速变化的应用场景
- 深度定制:通过领域知识库构建专业级 AI 应用
对于开发者,建议根据场景需求选择技术路径:
- 原型开发:LangChain 快速搭建 MVP
- 生产部署:Haystack 实现企业级落地
- 复杂任务:DSPy 的自动化优化提升效率
- 多模态场景:ViDoRAG 或 GraphRAG 实现深度内容理解
随着 Block-Attention、自我反思等技术的成熟,RAG 正从辅助工具进化为 AI 应用的核心架构,推动生成式 AI 从 "创意助手" 向 "决策引擎" 跨越。