RAIL-KD: 随机中间层映射知识蒸馏
RAIL-KD: RAndom Intermediate Layer Mapping for Knowledge Distillation
发表:NAACL 2022
机构:Huawei Noah's Ark Lab
Abstract
中间层知识蒸馏(KD)能够改进标准KD技术(仅针对师生模型的输出层),尤其对于大型预训练语言模型效果显著。然而,中间层蒸馏存在计算负担过重和层映射设置工程复杂的问题。为解决这些难题,我们提出随机中间层知识蒸馏(RAIL-KD)方法,通过随机选取教师模型的中间层蒸馏到学生模型的对应层。这种随机选择机制确保:所有教师层都能参与训练过程,同时降低中间层蒸馏的计算开销。此外,该方法还能作为正则化器提升学生模型的泛化能力。我们在GLUE任务集及域外测试集上进行了大量实验,结果表明:无论是模型性能还是训练效率,我们提出的RAIL-KD方法都显著优于其他最先进的中间层KD方法。
1 Introduction
预训练语言模型(PLMs)——如BERT(Devlin等人,2019)、RoBERTa(Liu等人,2020)和XLNet(Yang等人,2019)——已在众多自然语言理解(NLU)任务(Rajpurkar等人,2018;Wang等人,2018,2019)中展现出媲美甚至超越人类的表现能力。然而,这些模型在实际应用(如边缘设备)中的部署仍面临挑战,主要源于其庞大的模型规模与推理耗时。为此,研究者开发了多种模型压缩技术:包括量化(Shen等人,2019;Zafrir等人,2019)、剪枝(Guo等人,2019;Gordon等人,2020;Michel等人,2019)、Transformer架构优化(Fan等人,2019;Ghaddar和Langlais,2019;Wu等人,2020b;Lu等人,2020)以及知识蒸馏(Sanh等人,2019a;Jiao等人,2019;Sun等人,2020b;Wang等人,2020a;Rashid等人,2021;Passban等人,2021;Jafari等人,2021;Kamalloo等人,2021),旨在保持模型性能的同时降低参数量与延迟。
知识蒸馏(KD)作为本文研究核心,是一种通过大型预训练教师模型指导小型学生模型训练的神经网络压缩方法。传统KD技术(Buciluǎ等人,2006;Hinton等人,2014;Turc等人,2019)利用教师模型的输出预测作为软标签监督学生训练。现有研究尝试通过数据增强(Fu等人,2020;Li等人,2021;Jiao等人,2019)、对抗训练(Zaharia等人,2021;Rashid等人,2020,2021)和中间层蒸馏(ILD)(Wang等人,2020b,a;Ji等人,2021;Passban等人,2021)来缩小师生模型性能差距。
在BERT模型压缩中,ILD通过将师生模型的中间层表征映射至共享空间(Sun等人,2019采用回归损失,Sanh等人,2019a采用余弦相似度损失),实现超越输出层匹配的知识迁移,显著提升性能(Sanh等人,2019a;Jiao等人,2019;Wang等人,2020a)。但ILD存在核心缺陷:缺乏系统性的层匹配策略,导致"跳跃搜索问题"(Passban等人,2021)。现有解决方案多依赖层组合(Wu等人,2020a)、基于注意力的层投影(Passban等人,2021)和对比学习(Sun等人,2020a)。
尽管这些方法均有一定效果,但现有研究尚未从效率与性能双维度进行全面评估。尤其当面对超深度网络时,前述层匹配方案均存在可扩展性不足的问题。为此,我们提出RAIL-KD(随机中间层知识蒸馏),通过每训练周期随机选取教师模型中k个中间层与学生层对应蒸馏,实现:1)所有教师层均有机会参与蒸馏;2)零额外计算开销。该方法在GLUE基准测试(Wang等人,2018)中全面超越现有技术,且当蒸馏大型教师模型或在域外数据集评估时优势更显著。我们通过5组随机种子实验验证随机选择机制的有效性,确保与基线方法的公平对比。
本文核心贡献如下:
• 提出RAIL-KD,一种高效可扩展的中间层蒸馏方法
• 首次从效率与性能双维度系统评估中间层蒸馏技术
• 在BERT/RoBERTa蒸馏任务中,基于域外测试集对比当代前沿技术,建立新的性能参照系
2 Related Work
近年来,研究者提出了多种创新方法,旨在拓展基于Transformer架构(Vaswani等人,2017)的NLU模型知识迁移能力,突破传统输出层匹配的局限。DistillBERT(Sanh等人,2019a)引入师生模型嵌入层间的余弦相似度损失;TinyBERT(Jiao等人,2019)、MobileBERT(Sun等人,2020b)和MiniLM(Wang等人,2020b)则通过匹配中间层表征与自注意力分布实现知识迁移。
Sun等人(2019)在PKD中采用确定性映射策略,将12层BERT教师模型蒸馏至6层学生模型:PKD-LAST策略使学生模型第1-5层对应教师第7-11层,PKD-SKIP则采用间隔映射(教师层2/4/6/8/10)。但这些固定层映射方案未能充分考虑层选择对性能的影响。后续研究发现,优化层映射策略可显著提升ILD技术效果(Sun等人,2019),但最优映射的搜索面临重大挑战——此即Passban等人(2021)提出的"层跳跃搜索问题"。
针对该问题,CKD(Wu等人,2020a)在PKD基础上将教师层分组后蒸馏至学生层,但最优分组方案需穷举实验确定。当师生模型层数差异显著(n>>m)时,教师层选择与映射策略(搜索问题)变得尤为复杂。ALP-KD(Passban等人,2021)通过计算师生层间注意力权重生成加权表征,虽在12层BERT压缩中表现优异,但对所有教师层进行注意力计算会带来巨大计算开销,难以扩展至RoBERTa-large(Liu等人,2020)等超大规模模型。CODIR(Sun等人,2020a)采用对比学习实现无确定性映射的层匹配,但其对比损失计算与负样本存储同样导致训练耗时激增。
表1对比了现有主流中间层蒸馏技术与我们提出的RAIL-KD方法。如表所示,PKD、CKD和CoDIR虽与本研究最相关,但前两者将层映射视为需大量实验调优的超参数,后两者则分别依赖注意力机制与对比学习,均存在显著计算缺陷。RAIL-KD在零计算成本增加的条件下,实证性能超越所有基线方法——例如在24层至6层压缩任务中,其训练速度约为CoDIR的两倍,且无需繁琐的映射策略搜索。需说明的是,本研究聚焦解决"跳跃搜索问题",故未与采用自注意力分布匹配等额外损失的TinyBERT、MiniLM等方法直接对比,但这些技术均可受益于RAIL-KD的随机层映射机制。
3 RAIL-KD
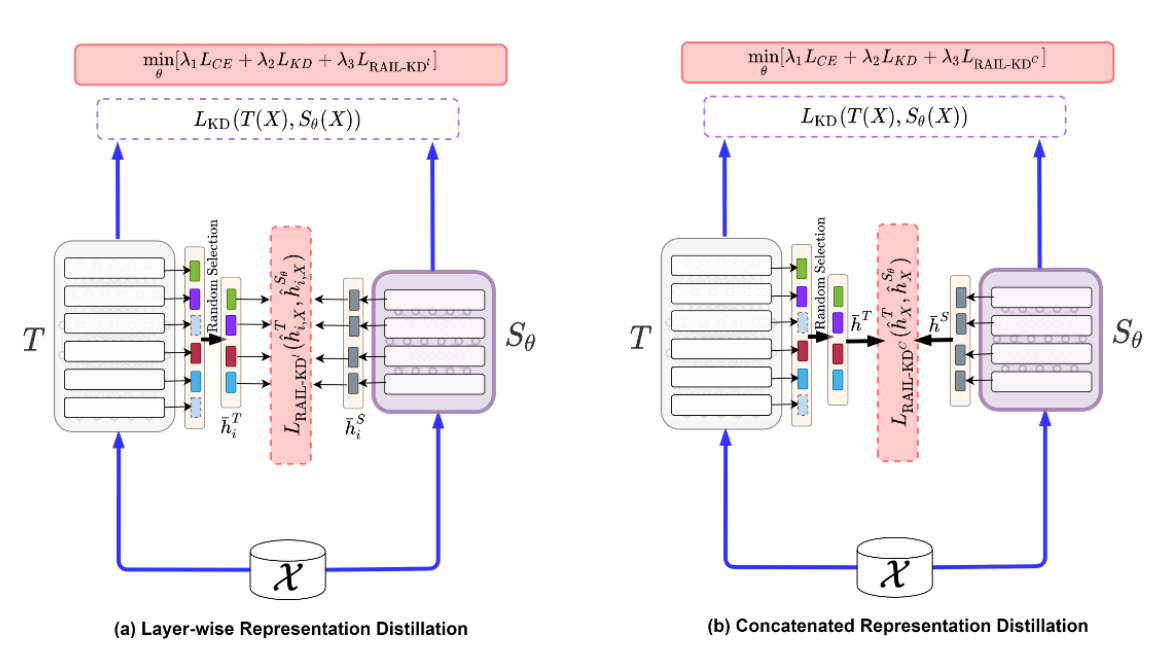

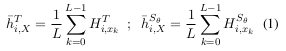
RAIL-KD提出了两种中间层蒸馏的实现形式:分层蒸馏(如图1(a)所示)或层表征拼接蒸馏(如图1(b)所示)。
3.1 Layer-wise RAIL-KD

3.2 Concatenated RAIL-KD

3.3 Training Loss
 4 Experimental Protocol
4 Experimental Protocol
4.1 Datasets and Evaluation
我们在GLUE基准测试(Wang等人,2018)的8个任务上评估RAIL-KD方法,包括:2个单句分类任务(CoLA和SST-2)、5个句对分类任务(MRPC、RTE、QQP、QNLI和MNLI)以及1个回归任务(STS-B)。遵循先前研究(Sun等人,2019;Passban等人,2021;Jiao等人,2019;Sun等人,2020a),我们采用与GLUE基准相同的评估指标。为进一步验证RAIL-KD方法在跨任务域外(OOD)场景下的泛化能力,我们使用Scitail(Khot等人,2018)、PAWS(词语重组生成的复述对抗样本)(Zhang等人,2019)和IMDb(互联网电影数据库)(Maas等人,2011)测试集,分别评估基于MNLI、QQP和SST-2任务微调后的模型表现。
4.2 Implementation Details
我们进行了广泛的实验,使用了三种不同的教师模型,以确保能够与大量已有研究进行公平比较,并验证 RAIL-KD 的有效性。我们采用 BERT-base-uncased(12 层)作为教师模型(BERT₁₂),以及 DistilBERT(6 层)作为学生模型(DistillBERT₆),用于与 PKD(Sun 等人,2019)和 ALP-KD(Passban 等人,2021)方法进行对比。此外,我们还使用 RoBERTa-large(24 层)和 DistilRoBERTa(6 层)分别作为教师模型(RoBERTa₂₄)和学生模型(DistilRoBERTa₆),以便在教师层数远大于学生层数(n >> m)的情况下进行模型比较。进一步地,我们还使用 RoBERTa-base(12 层)作为教师模型,以便能直接与 CoDIR 方法的结果进行对比。
我们根据各自论文中提出的默认设置重新实现了 PKD(Sun 等人,2019)和 ALP-KD(Passban 等人,2021)方法。在训练过程中,我们基于开发集上的表现使用早停机制(early stopping),并确保最终结果与原论文报告的一致。更具体地,对于 PKD,在教师模型 BERT₁₂ 上选择的中间层是 {2, 4, 6, 8, 10},用于蒸馏到学生模型 DistilBERT₆;而在 DistilRoBERTa₆ 上,我们从教师模型 RoBERTa₂₄ 中选择了第 4、8、12、16、20 层进行蒸馏,这些组合在开发集上表现最好。
在 ALP-KD 方法中,我们计算教师模型中间层(BERT₁₂ 的第 1 到 11 层,RoBERTa₂₄ 的第 1 到 23 层)的注意力权重,以得到每个学生模型中间层(第 1 到 5 层)对应的加权表示。由于 RoBERTa₂₄ 和 DistilRoBERTa₆ 的隐藏维度不同,我们将它们通过线性变换映射到同一个低维空间中。我们按照 Sun 等人(2019)和 Passban 等人(2021)中的方法训练 PKD 和 ALP-KD 模型。
对于 RAIL-KDl,在每个训练周期中我们从教师模型的中间层中随机选取 5 层(例如 BERT₁₂ 的第 1 到 11 层,RoBERTa₂₄ 的第 1 到 23 层),然后对所选层的索引进行排序,并对这些层执行逐层蒸馏(如图 1(a) 所示)。对于 RAIL-KD c,我们将这些排序后的中间层表示进行拼接,并进行拼接表示的蒸馏(如图 1(b) 所示)。我们使用一个线性变换将中间表示(逐层或拼接后的表示)映射到 128 维的空间,并在计算损失函数 L RAIL-KD l/c 前对其进行归一化处理。在我们提出的方法中,我们固定 α i = 1,λ₁, λ₂, λ₃ = 1/3。我们搜索的学习率范围为 {1e-5, 2e-5, 5e-5, 4e-6},批大小范围为 {8, 16, 32},所有实验均固定训练轮数为 40 轮。为了验证结果的可信度,我们每组实验重复运行 5 次并报告平均得分。所有实验均在单块 NVIDIA V100 GPU 上使用混合精度训练(Micikevicius 等人,2018)和 PyTorch(Paszke 等人,2019)框架完成。
我们的实验结果表明,随机层映射不仅比确定性的层映射技术(如 PKD)在各种任务上表现更优,而且在训练过程中具有更低的计算开销,同时避免了寻找最优层映射所需的大量搜索实验。另一方面,使用注意力机制进行层选择(ALP-KD)或使用对比学习(CoDIR)的方法,其效果略逊于我们的随机选择策略。
5 Results
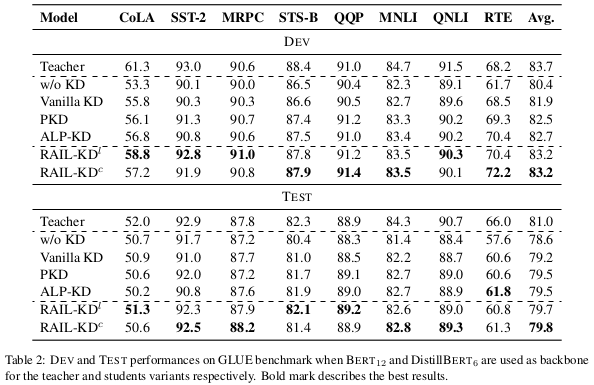
表 2 展示了在 GLUE 任务上训练并分别在 DEV 和 TEST 集上评估的模型表现,实验设置为从 12 层教师模型蒸馏到 6 层学生模型。教师和学生模型分别使用 BERT₁₂ 和 DistilBERT₆。基线包括不进行知识蒸馏(w/o KD)和标准知识蒸馏(Vanilla KD)。此外,我们还将 RAIL-KDlc 的结果与 PKD 和 ALP-KD 等更具代表性的竞争方法直接进行了比较。
首先,我们可以观察到,在从 12 层到 6 层的蒸馏中,中间层蒸馏(ILD)方法与 Vanilla-KD 之间的性能差距较小(DEV 集上为 0.8%,TEST 集上为 0.3%)。此外,正如我们所预期的那样,ALP-KD 相比 PKD 在 DEV 集上的表现更好,在 TEST 集上相似,DEV 结果提升了 0.2%。
其次,结果显示,RAIL-KD 在平均 DEV 和 TEST 集上分别以 0.5% 和 0.3% 的优势超过了最好的 ILD 方法。我们注意到,除了 RTE 数据集的 TEST 集外,RAIL-KDl/c 在各个任务上都取得了最高的性能。
第三,我们发现 RAIL-KDl 和 RAIL-KDc 的表现非常接近,这表明我们的方法在层间逐层蒸馏和拼接表示蒸馏中都同样有效。
在从 24 层教师模型到 6 层学生模型的压缩实验中也观察到了类似的趋势,见表 3。在该实验中,我们分别使用 RoBERTa₂₄ 和 DistillRoBERTa₆ 作为教师和学生模型。总体来看,RAIL-KD 分别在 DEV 和 TEST 集上比最佳基线方法高出 1.2% 和 0.3%。有趣的是,相比 BERT₁₂ 实验,RAIL-KD 与 PKD、ALP-KD 在 DEV 集上的差距更大,并且 PKD 的 TEST 表现明显低于 ALP-KD 和 RAIL-KD。这可能是因为 PKD 在 RoBERTa₂₄ 上跳过了大量中间层,而 ALP-KD 在大量教师层上计算注意力权重时可能会导致权重分配较弱,从而影响了其表现。
此外,为了进一步验证 RAIL-KD 的有效性,我们将它与当前最先进的 ILD 方法 CoDIR(Sun 等人,2020a)进行了直接比较。CoDIR 使用对比学习目标以及一个记忆库来提取大量负样本用于对比损失的计算。
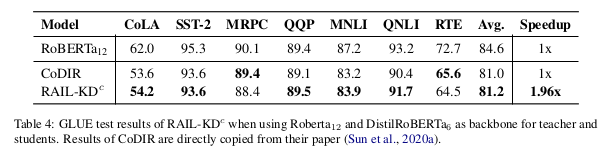
表 4 展示了在将 RoBERTa₁₂ 蒸馏到 DistillRoBERTa₆ 任务中两种方法在 GLUE TEST 集上的结果。CoDIR 的结果来自其论文,我们遵循其实验协议,未报告 STS-B 的得分。另外,我们还报告了不同方法相对于教师模型的整体训练加速情况。
平均而言,RAIL-KD 的训练速度几乎比 CoDIR 快了一倍,同时性能与其相当(+0.2%)。更重要的是,RAIL-KD 在 8 个数据集中有 5 个超越了 CoDIR。
5.1 Impact of Random Layer Selection
为了评估与其它基线方法相比,随机层选择对 RAIL-KD 性能的影响,我们在三个最小的 GLUE 任务上报告了 DistilBERT₆ 学生模型的标准差(这些任务已知具有最高的方差),结果见表 5。
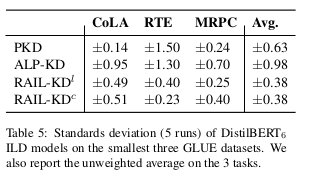
图中显示,在 CoLA 和 MRPC 任务上,RAIL-KD 的方差与 PKD 和 ALP-KD 相当;而在 RTE 任务上,其方差甚至更低。这强烈表明,RAIL-KD 所带来的性能提升并不是单纯由于随机层选择所带来的偶然性。
5.2 Out-of-Distribution Test
我们进一步通过测量学生模型在领域内(in-domain)和领域外(out-of-domain)评估任务上的鲁棒性,来验证其泛化能力。具体来说,我们在 MLI、QQP 和 SST-2 数据集上对模型进行微调,并分别在 SciTail、PAWS 和 IMDB 数据集上进行评估。这些数据集包含了针对训练数据中存在偏见的反例(counterexamples),用于测试模型是否真正理解了任务内容而非依赖表面特征(McCoy 等人,2019;Schuster 等人,2019;Clark 等人,2019)。
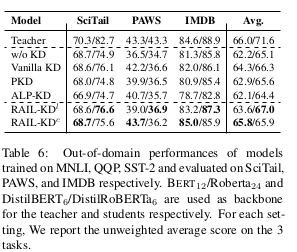
表 6 中报告了 BERT₁₂ / RoBERTa₂₄ 教师模型与 DistilBERT₆ / DistilRoBERTa₆ 学生模型变体的表现。此外,我们还计算了三个任务的未加权平均得分。
首先,我们注意到模型在不同任务中的排名存在较大差异,并且与领域内结果相比,性能表现也存在一些不一致现象。这种现象在之前关于领域外训练与评估的研究中也有报道(Clark 等人,2019;Mahabadi 等人,2020;Utama 等人,2020;Sanh 等人,2020)。
尽管如此,RAIL-KDl/c 在所有任务中都明显优于所有基线方法。令人惊讶的是,我们发现 PKD 和 ALP-KD 的表现远不如 Vanilla KD 基线方法(在所有三项任务中均表现较差)。
有趣的是,我们观察到在 RoBERTa₂₄ 的模型压缩中,RAIL-KDl(逐层蒸馏)的表现始终优于 RAIL-KDc(拼接蒸馏),平均高出 1.1%;而在 BERT₁₂ 的任务中,RAIL-KDc 的表现更好,平均也高出 1.1%。这些结果表明,当教师模型与学生模型之间的容量差距(层数差异)较大时,逐层蒸馏方法更有效;而当容量差距较小时,拼接蒸馏则更具优势。
6 Analysis
我们进行了广泛的分析,以更好地理解为什么 RAIL-KD 的表现优于其他基线方法。我们可视化了教师模型和学生模型中间层表示之间的逐层余弦相似度。
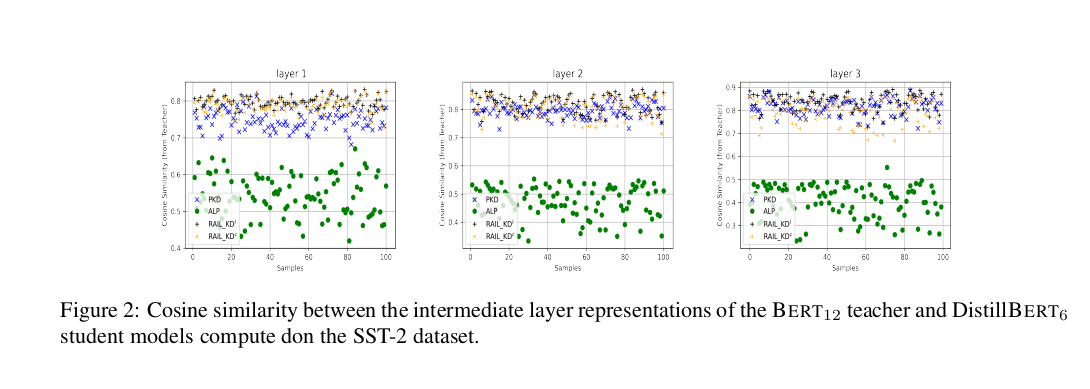
图 2 展示了 BERT₁₂ 教师模型的三个中间层(即第 2、4 和 6 层)与学生模型前三个中间层在 SST-2 数据集中随机选取的 100 个样本上的相似度得分,比较的方法包括 PKD、ALP-KD 和 RAIL-KDl/c。由于篇幅限制,我们仅展示了学生模型前三层的结果,其他层也呈现出类似的趋势。
我们发现,尽管 RAIL-KD 的层映射策略在每个训练周期中是动态变化的,但它仍能使学生模型很好地模仿教师模型的表示,其效果与 PKD 相当,且明显优于 ALP-KD。此外,我们观察到:
- ALP-KD 方法在上层中间层的相似度得分较低;
- PKD 方法在下层中间层得分较低,但在上层有所提升;
- 而我们的 RAIL-KD 方法在所有层上都表现出更稳定的相似度,并且在上层更接近教师模型的表示。
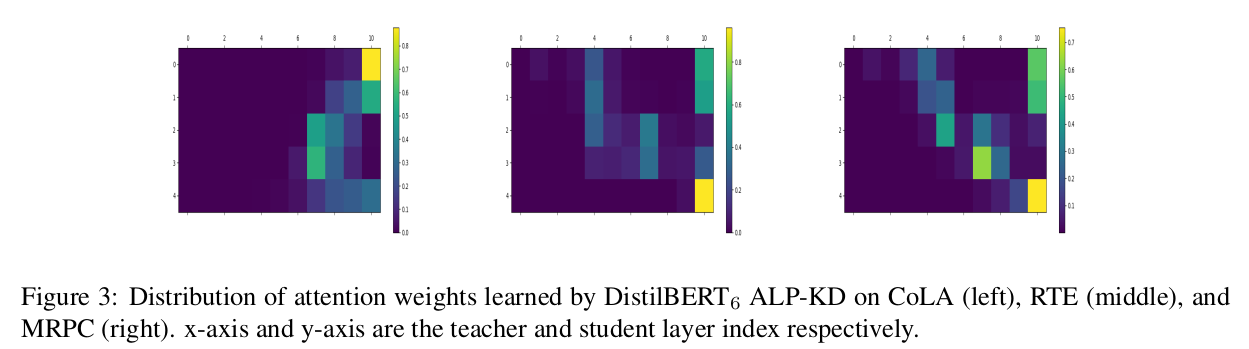
我们进一步分析了 ALP-KD 所学习到的注意力权重,发现它们主要集中在少数几层(呈现稀疏注意力)。图 3 展示了 DistilBERT₆ 上 ALP-KD 学生模型在 CoLA(左)、RTE(中)和 MRPC(右)任务上所有训练样本的平均权重分布。图中清楚地显示(颜色较浅),ALP-KD 的大部分权重集中在教师模型的顶层。例如,这三个学生的第 1、2、5 层主要关注的是 BERT₁₂ 的最后一层输出。
这可能表明 ALP-KD 过度依赖于教师模型最后几层的信息,存在一定的过拟合现象。相比之下,RAIL-KD 中的随机层选择机制确保了对学生模型对教师各层知识的均匀关注,这也许可以解释为何 RAIL-KD 在领域外评估任务中的表现优于 ALP-KD。
7 Conclusion and Future Work
我们提出了一种新颖、简单且高效的中间层知识蒸馏方法,在性能提升和训练效率方面均优于传统方法。RAIL-KD 从教师模型中随机选择与学生模型中间层数量相等的层,然后对这些选中的中间层进行排序,并将其表示蒸馏到学生模型中。
RAIL-KD 提供了更好的正则化效果,从而有助于提升模型性能。此外,我们的方法在更大模型的蒸馏任务中表现出更优的性能,同时训练速度更快。这为未来研究在超大规模模型(如 GPT-2(Radford 等人,2019))上的中间层蒸馏提供了新的方向,也有望在更广泛的自然语言理解任务(NLU)上提升模型的鲁棒性和泛化能力(Ghaddar 等人,2021a,b)。