R1-Omni
一、Omni概述

Omni = 文本+视频+音频,全模态。
R1+Omni = 强化学习+全模态。
二、Omni举例-humanOmni
humanOmni:以人体姿态和人物交互为中心的全模态模型。
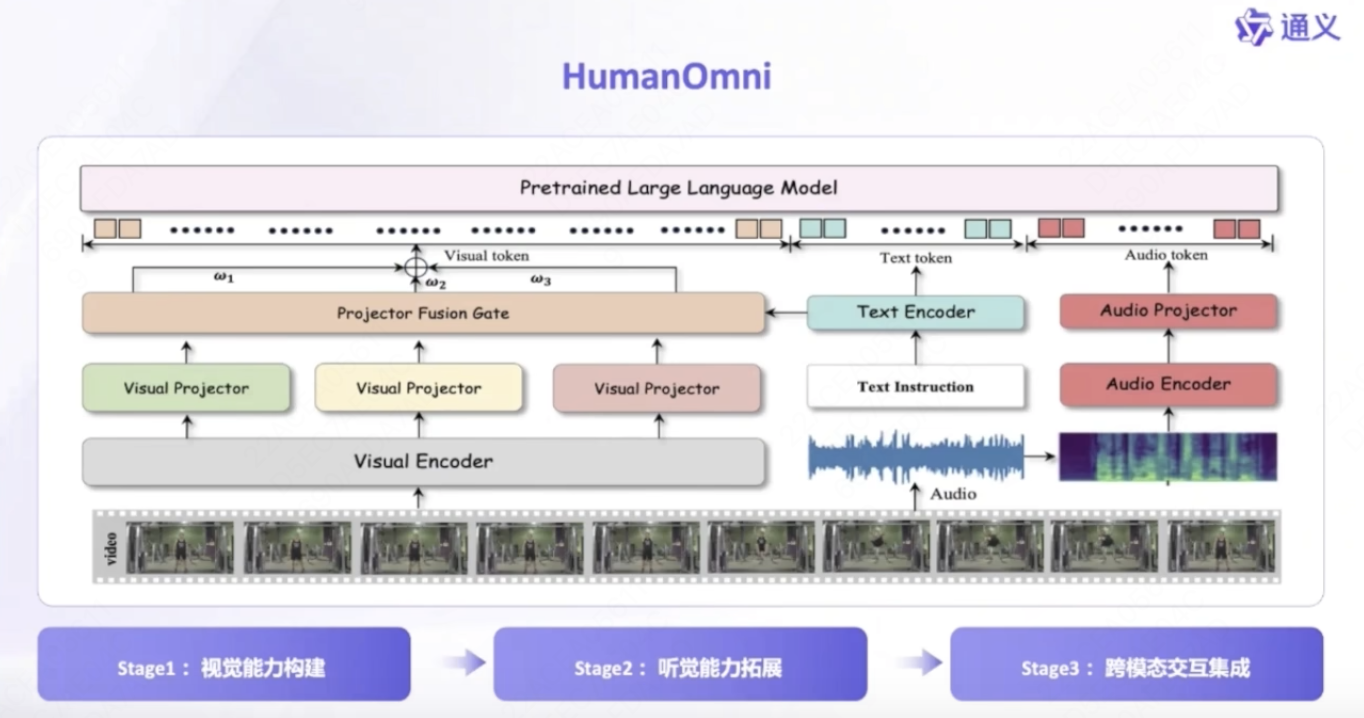
- visual projector有3个,分别负责人脸标签、姿态检测、人和物交互。有点像moe。
- text encoder 对visual projector进行fusion加权,通过文本区分不同的任务,对不同的视觉组件进行激活。
三、训练流程
冷启动 + Reinforcement Learning with Verifiable Reward (RLVR)
- 冷启动:少量(带COT)样本的sft。为了确保强化学习训练(RLVR)的稳定性,R1-Omni采用了一种冷启动(Cold Start)策略,旨在通过少量标注数据为模型赋予初步的推理能力。
- 可验证奖励的强化学习RLVR+组相对策略优化GRPO:与传统的基于人类反馈的强化学习(RLHF)不同,RLVR通过直接利用验证函数来评估输出,从而消除了中间奖励建模的需求。RLVR的核心在于简化奖励机制,同时确保与任务的内在正确性标准保持一致。
- reward 函数:格式+正确性,总奖励公式为:R=Racc+Rformat

- 准确率奖励(RaccRacc:若情感标签与真实值一致,奖励为1,否则为0。
- 格式奖励(RformatRformat:若输出严格符合
<think>和<answer>标签格式,奖励为1,否则为0。
- 组相对策略优化(GRPO)
与传统方法如近端策略优化(PPO)不同。GRPO通过直接比较生成的响应组来评估候选策略的相对质量,从而简化了训练过程。
具体来说,GRPO首先为给定输入问题q生成G个不同的响应{o1,o2,…,oG},然后根据预定义的奖励函数评估这些响应的奖励{r1,r2,…,rG}。为了确定每个响应的相对质量,GRPO通过计算均值和标准差来归一化奖励。
四、其它
1.如何理解训练中仅对answer进行reward,大模型可以学习调整think内容?
①在sft冷启动时,我们让大模型监督学习的内容包含<think>和<answer>,可以让大模型迅速的get到我们想要表达的业务逻辑。
②在强化学习过程中,仅对answer进行reward,此时需要发挥语言大模型自身的逻辑能力,对answer调整的同时match到相应的think。