数据结构(1)复杂度
一、数据结构概要
1.数据结构
数据结构是计算机存储、组织数据的方式,是数据相互之间存在一种或者多种特定关系的集合。没有一种单一的数据结构可以解决所有问题,因此要学习多种多样的数据结构。如:线性表、图、树等。
2.算法
算法其实就是解决问题的一系列步骤或者说一个计算过程,可以将现实生活中问题的条件(输入的值)转化为理想的目标(输出值)。
比如最简单的计算两个整型的加法,就是输入两个整型,返回两个整型的和。
学好数据结构在一定程度上就是帮助自己写更好的算法,比如计算一系列的整型值,如果单单用基本数据类型int就会非常麻烦,比如说计算100个,1000个,10000个int的和,你要是一个一个去定义,一个一个去初始化,那就太麻烦了,用上数组和循环,就会非常简单,数组就可以说是一个非常简单的数据结构。
那么如何能判断一个算法的好坏呢?
二、算法效率
算法的效率或者算法的好坏该通过什么样的标准来判断呢?
比如这样一道题:
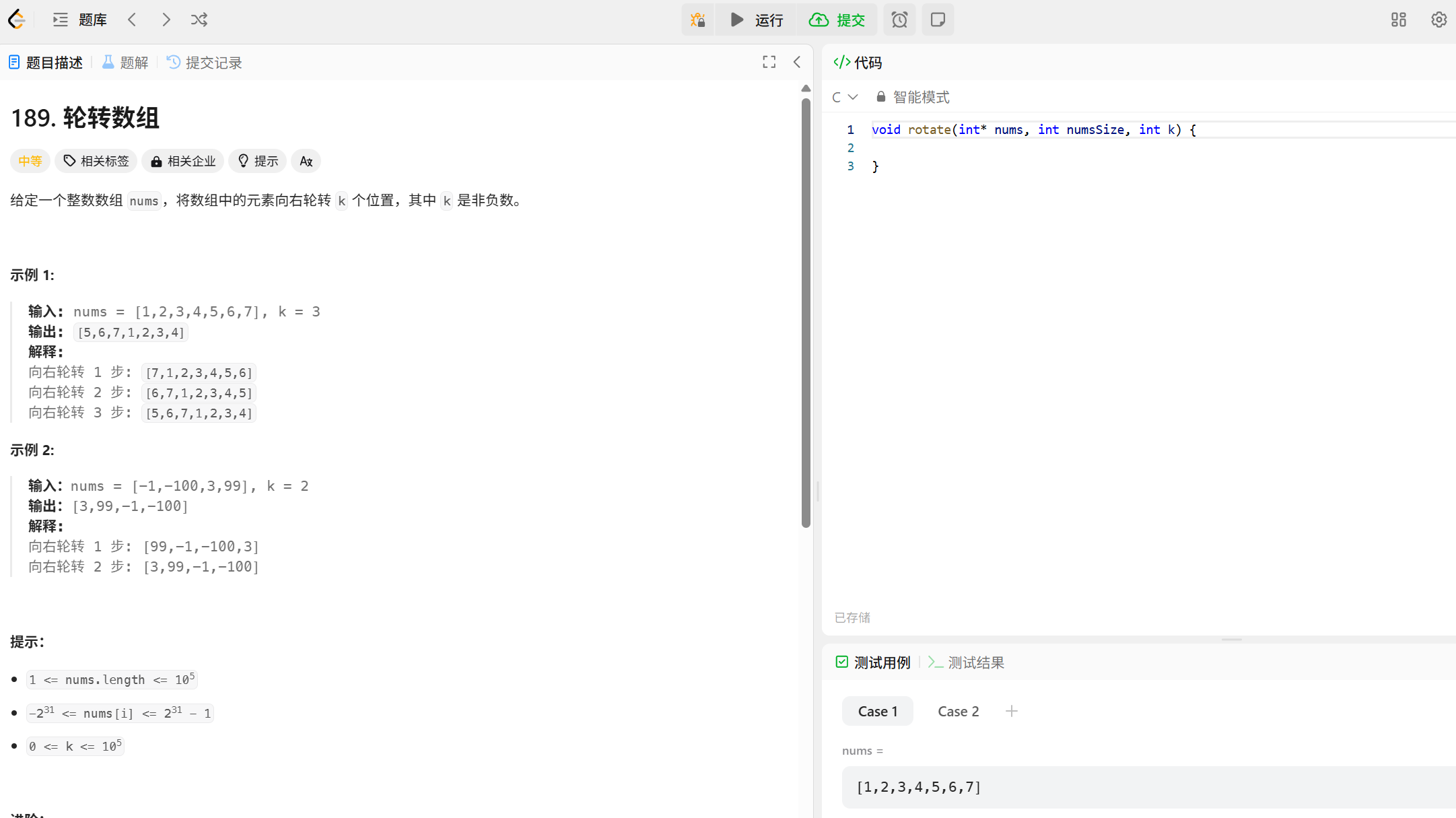
容易想到以这样的方式去解决:
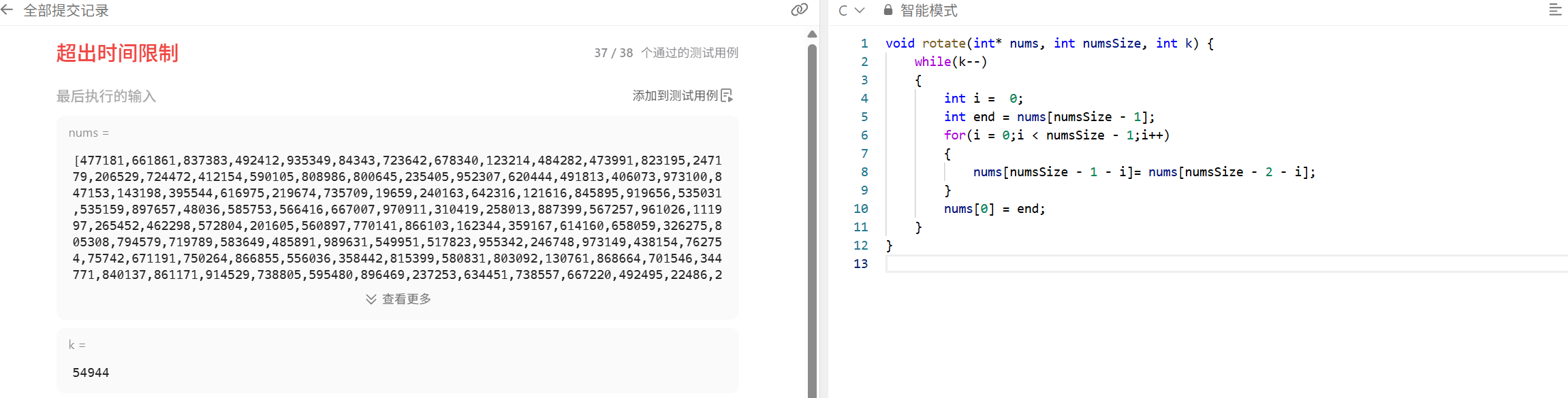
这个思路就是啥吧,你说啥我就干啥,你告诉我说轮转一步是把最后一个数提到最前面,其他的数次序不变依次前移,那我就这么写呗,外层循环是轮转的次数,内层循环想清顺序,数组最后一个数已经保存下来了,接下来就是从最后两个数开始,依次让后面的数等于前面的数,结果,最后弹出来个超出时间限制,这就是算法判断好坏的其中一个标准,时间。
三、复杂度
算法生成可执行程序进而运行的时候是需要向内存申请空间并且耗费一定时间的。因此衡量一个算法的好坏一般从时间和空间两个方面来衡量,即时间复杂度和空间复杂度。
时间复杂度主要就是衡量一个算法运行的快慢,空间复杂度主要衡量一个算法运行时所需要额外申请的内存空间。
1.时间复杂度
详解
在计算机中,时间复杂度并不是具体的几秒了,几分钟了,而是一个函数表达式T(N)。为什么不是具体的时间呢?
原因在于一个算法在不同机器下(想象一下20年前的计算机和现在的计算机运行同一个程序)、不同运行时间、不同编译环境下多可能不同。而且如果要计算时间的话,只能在程序运行后才会出现,但是复杂度在程序写好以后即可算出。
让自己接受了时间快慢就是用时间复杂度来衡量以后就来理解一下函数式T(N)到底是什么:
T(N)这个表达式计算了程序执行的次数,因为我们学习完C语言以后知道了,我们自己编写好的代码在运行前要进行编译和链接,最终转换为二进制指令,每条二进制指令的时间不一定相同,但是也不会相差过大,因此一般情况下我们都看成每条二进制指令所需时间相同,那么一个程序的时间=每条指令执行的时间*执行次数,每条指令执行时间又相同,所以不同算法的区别就在于执行次数的多少。
比如解决同一个问题:
T(N)= N和T(N)= N ^ 2
同样一个N,很明显N^2会耗费更多时间,效率也就更低。
另外,时间复杂度的计算还要进行近似的忽略,比如:
// 请计算⼀下Func1中++count语句总共执行了多少次?
void Func1(int N)
{
int count = 0;
for (int i = 0; i < N; ++i)
{
for (int j = 0; j < N; ++j)
{
++count;
}
}
for (int k = 0; k < 2 * N; ++k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
}
读读代码,for循环嵌套+count的次数就是N^2,后面又来一for循环,易得执行次数为2N,最后还得执行whie循环的10次,因此T(N)= N ^ 2 + 2N + 10
而代入数值去计算:
T(10)=130
T(100)=10210
T(1000)=1002010
其实很明显能感觉出来对结果影响最大的就是N^2了,次数越多,影响力越大,而我们的计算机每秒可以处理成千上万条二进制指令,N^2下比它次数低的可以忽略不计了。
即我们计算时间复杂度的时候也不是非得计算出它真正的执行次数(其实也算不出来,你count++和count*=最终搞出来的二进制指令都不一定一样多),只是大概看一下不同情况下随N增加算法的量级,所以复杂度的表示常用大O的渐进表示法。
大O的渐进表示法
规则:
1. 时间复杂度函数式 T(N) 中,只保留最高阶项,去掉那些低阶项,因为当 N 不断变大时, 低阶项对结果影响越来越小,当 N 无穷大时,就可以忽略不计了。
2. 如果最高阶项存在且不是 1 ,则去除这个项目的常数系数,因为当 N 不断变大,这个系数对结果影响越来越小,当 N 无穷大时,就可以忽略不计了。
3. T(N) 中如果没有 N 相关的项目,只有常数项,用常数 1 取代所有加法常数。
案例
理解了时间复杂度怎么回事,并且大致知道怎么算以后,着手计算几个常见的类:
例1
// 计算Func2的时间复杂度?
void Func2(int N)
{
int count = 0;
for (int k = 0; k < 2 * N; ++k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}
第一个for循环2N次,第二个while循环10次。
因此T(N)= 2N+10
根据规则一,只包含最高次幂的2N,根据规则二,去掉系数。
故最后得到O(N)。
例2
// 计算Func3的时间复杂度?
void Func3(int N, int M)
{
int count = 0;
for (int k = 0; k < M; ++k)
{
++count;
}
for (int k = 0; k < N; ++
k)
{
++count;
}
printf("%d\n", count);
}
不多bb了,T(N)= M + N
同级加减,光管量级的话就是一次的O(N)
例3
// 计算Func4的时间复杂度?
void Func4(int N)
{
int count = 0;
for (int k = 0; k < 100; ++k)
{
++count;
}
printf("%d\n", count);
}
T(N) = 100
规则三,常数就是O(1)(跟上面说的,计算机一秒处理成千上万个代码,你就几百几千条,一次执行的事)
例4
const char* strchr(const char* str, char character)
{
const char* p_begin = str;
while (*p_begin != character)
{
if (*p_begin == '\0')
return NULL;
p_begin++;
}
return p_begin;
}
这个查找其实就有点说头了,最好的情况,字符串第一个字符就是要找的,那不就是O(1)嘛,最差的就是刚好这个字符在字符串的末尾str有多长就得找多长,假如说为N的话,岂不成O(N)了嘛。
这点就说一下,O(N)一般关注的就是最坏的情况。(后面也有几个经典的算法,根据输入数据的不同,存在最好和最坏情况)
例5
void Bubble_sort(int* arr, size_t sz)
{asserrt(arr);
int i = 0;
int flag = 0;
for (i = 0; i < sz - 1; i++)
{
int j = 0;
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = arr[j];
flag = 1;
}
}
if (flag == 0)
{
break;
}
}
}
根据数据的不同,肯定排序的次数也就不同,咱直接算最坏的,也就是完全倒序的一个序列,肯定两层循环都得走完了,假设sz是N,第一次内层for循环执行N - 1次,第二次N - 2次知道最后一次,执行1次,即1+2+……+N-1,也不用细算,肯定最后O(N^2)。
例6
void func5(int n)
{
int cnt = 1;
while (cnt < n)
{
cnt *= 2;
}
}
这玩意一下还看不出来到底执行多少次,必须计算设执行次数为x那么cnt每次都*2,也就是2^x次方,最终循环出来跟n比,相等或者大于就跳出循环了,2^x>=n那么 x>= logn。
一般有好几种表示:
![]()
O渐进表示法写的是第一个,计算机上,书籍上,资料上这几个都有,归根结底是指数函数对数函数底数和指数,底数和真数不好写出来,人手写当然就没啥问题,知道就行了。
例7
long long Fac(size_t N)
{
if (0 == N)
return 1;
return Fac(N - 1) * N;
}
其实还是看执行了几句,很显然肯定执行次数是一次,最后肯定O(N)。
2.空间复杂度
详解
有了时间复杂度的经验,类比着学。
空间复杂度也是一个数学表达式,是一个算法在运行过程中需要额外临时开辟的空间。不是算程序有多大,一般都是算变量个数(因为函数运行时所需要的栈空间(存储参数、局部变量、⼀些寄存器信息等)在编译期间已经确定好了)。
比如我们的冒泡排序,函数大小不用管,函数内就创建了个flag变量和temp变量还有i变量最后一加,再估算,用O渐进表示法也就是个O(1)
对于上面例7,函数递归,就是说调用函数空间本来准备好了,结果你是递归,不停的申请函数栈帧,也不去具体算了,反正基本就是N次,最后归结成O也就是O(N)。
但是随着我们科技的发展,反正内存不那么关心了相对于时间,一般提复杂度就是说的时间复杂度。但是也不能不管,你别说为了达成O(1)时间复杂度,不用循环,去计算500个数的值,你不嫌累,框框打了500个变量下去,自己手打了那么多个加法语句,你可是给计算机省时间去了,最后给内存干的快枯竭了。
四、常见复杂度对比
O(1)<O(logn)<O(n)<O(nlogn)<O(n^2)<O(2^n)<O(n!)<O(n^n)
大概就是这样了,其实类似于高数里面的那个无穷大的比较。