卷积神经网络实战(4)代码详解
目录
一、导包
二、数据准备
1.数据集
2. 标准化转换(Normalize)
3.设置dataloader
三、定义模型
四、可视化计算图(不重要)
五、评估函数
六、Tensorboard
一、导包
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
from tqdm.auto import tqdm
import torch
import torch.nn as nn
import torch.nn.functional as Fprint(sys.version_info)
for module in mpl, np, pd, sklearn, torch:print(module.__name__, module.__version__)device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
print(device)seed = 42-
%matplotlib inline:Jupyter Notebook魔法命令,使图表直接显示在单元格下方 -
device配置:优先使用CUDA GPU加速计算,如果没有则使用CPU
二、数据准备
# 导入数据集相关模块
from torchvision import datasets
from torchvision.transforms import ToTensor
from torch.utils.data import random_split# 加载FashionMNIST数据集
# 训练集:自动下载并转换为Tensor格式
train_ds = datasets.FashionMNIST(root="data", # 数据集存储路径train=True, # 加载训练集download=True, # 如果本地不存在则下载transform=ToTensor()# 将PIL图像转换为[0,1]范围的Tensor
)# 测试集:同样进行格式转换
test_ds = datasets.FashionMNIST(root="data",train=False, # 加载测试集download=True,transform=ToTensor()
)# 划分训练集和验证集(原始数据没有提供验证集)
# 使用random_split按55000:5000比例划分
# 设置随机种子保证可重复性
train_ds, val_ds = random_split(train_ds, [55000, 5000],generator=torch.Generator().manual_seed(seed) # 固定随机种子
)#%% 数据预处理模块
from torchvision.transforms import Normalize# 计算数据集的均值和标准差(用于标准化)
def cal_mean_std(ds):mean = 0.std = 0.for img, _ in ds: # 遍历数据集中的每个图像# 计算每个通道的均值和标准差(dim=(1,2)表示在H和W维度上计算)mean += img.mean(dim=(1, 2)) # 形状为 [C]std += img.std(dim=(1, 2)) # C为通道数(这里为1)mean /= len(ds) # 求整个数据集的平均std /= len(ds)return mean, std# 根据计算结果创建标准化转换
# 实际计算值约为 mean=0.2856,std=0.3202
transforms = nn.Sequential(Normalize([0.2856], [0.3202]) # 单通道标准化
)#%% 数据检查
img, label = train_ds[0] # 获取第一个训练样本
img.shape, label # 输出形状(通道×高×宽)和标签#%% 创建数据加载器
from torch.utils.data.dataloader import DataLoaderbatch_size = 32 # 每批加载的样本数# 训练集加载器
train_loader = DataLoader(train_ds,batch_size=batch_size,shuffle=True, # 每个epoch打乱顺序num_workers=4 # 使用4个子进程加载数据
)# 验证集加载器
val_loader = DataLoader(val_ds,batch_size=batch_size,shuffle=False, # 不需要打乱顺序num_workers=4
)# 测试集加载器
test_loader = DataLoader(test_ds,batch_size=batch_size,shuffle=False, # 保持原始顺序num_workers=4
)tips:
1.数据集
datasets.FasionMNIST是pytorch提供的标准数据集类
-
类别:10 类(T恤、裤子、套头衫、连衣裙、外套、凉鞋、衬衫、运动鞋、包、靴子)。
-
图像大小:28×28 像素,单通道灰度图。
-
用途:替代原始 MNIST,作为更复杂的图像分类基准数据集。
2. 标准化转换(Normalize)
在cal_mean_std中,先遍历数据集中的每个图像和标签(忽略),计算每个通道的均值和标准差,然后求整个数据集的平均值和标准差,为后序标准化提供参数。img.mean(dim=(1,2))是在图像的高度和宽度两个维度上求均值,保留通道维度。transforms使用nn.Sequential将多个数据转换操作按顺序组合起来,对图像数据进行标准化,nn.Sequential是pytorch提供的容器,用于按顺序执行多个操作,Normalize是torchvision.transforms中的一个标准化操作,功能是对输入数据的每个通道进行均值平移和标准差缩放,对图片的每个像素值进行以下变换:
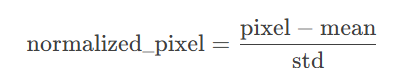
代码中的图片没有使用这个标准化,所以想使用的话可以
transforms = Compose([ToTensor(), # 1. 转Tensor并缩放到[0,1]Normalize([0.2856], [0.3202]) # 2. 标准化
])然后在加载数据那里把transform=后面改成transforms。
修改前:
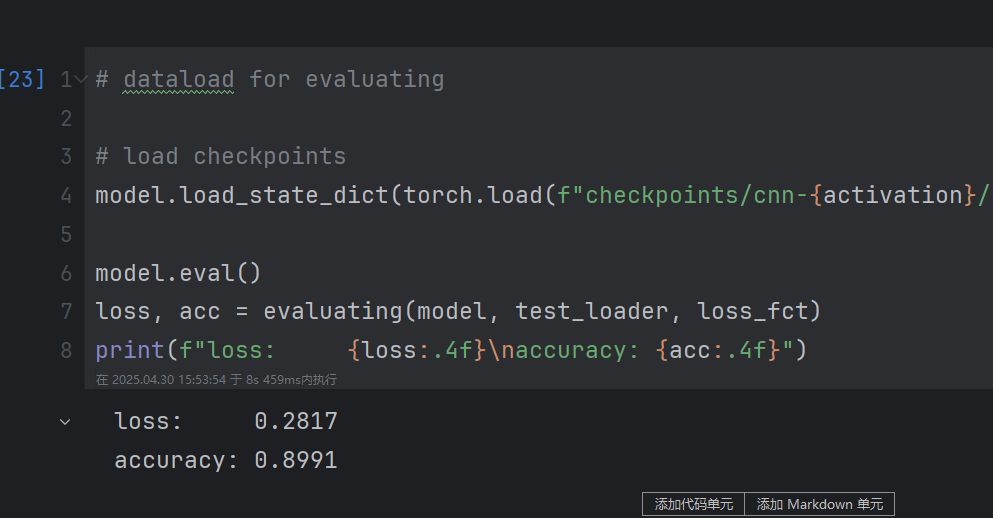
修改后:
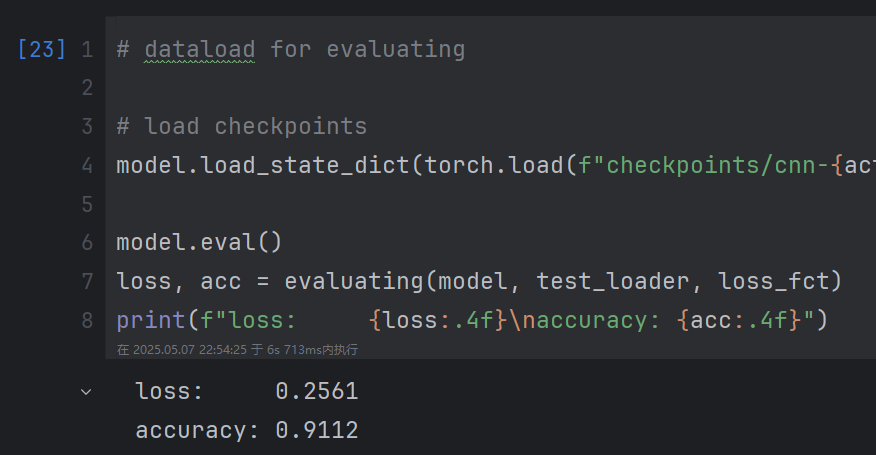
图像数据标准化后结果更优秀。
3.设置dataloader
将batch_size设置为32,只打乱训练集,验证集和测试集不需要打乱,num_workers=4使用4个子进程并行加载数据(和CPU核心数相关)。
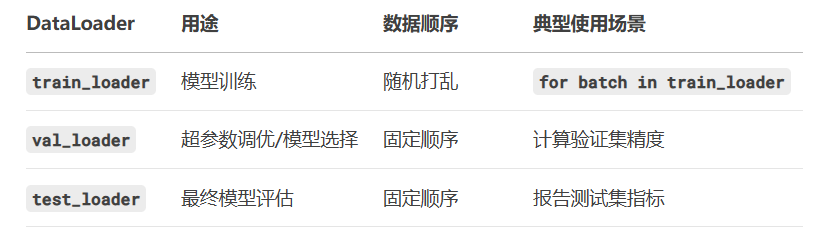
Dataloader可以自动将数据集分成多个批次,打乱数据,设置多进程加速,提供标准化接口,都可以for batch in dataloader: 。
三、定义模型
import torch.nn as nn
import torch.nn.functional as F
import numpy as npclass CNN(nn.Module):"""一个用于图像分类的卷积神经网络(CNN)模型"""def __init__(self, activation="relu"):"""初始化CNN模型结构Args:activation: 激活函数类型,可选"relu"或"selu""""super(CNN, self).__init__()# 设置激活函数self.activation = F.relu if activation == "relu" else F.selu# 卷积层定义# 输入形状: (batch_size, 1, 28, 28)self.conv1 = nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, padding=1) # 保持空间维度不变self.conv2 = nn.Conv2d(32, 32, kernel_size=3, padding=1) # 双卷积结构增强特征提取# 最大池化层(下采样)self.pool = nn.MaxPool2d(2, 2) # 将特征图尺寸减半# 后续卷积层(逐步增加通道数)self.conv3 = nn.Conv2d(32, 64, kernel_size=3, padding=1)self.conv4 = nn.Conv2d(64, 64, kernel_size=3, padding=1)self.conv5 = nn.Conv2d(64, 128, kernel_size=3, padding=1)self.conv6 = nn.Conv2d(128, 128, kernel_size=3, padding=1)# 展平层(将多维特征图转换为一维向量)self.flatten = nn.Flatten()# 全连接层# 输入尺寸计算:经过3次池化后是3x3,通道数128 → 128*3*3=1152self.fc1 = nn.Linear(128 * 3 * 3, 128) # 特征压缩self.fc2 = nn.Linear(128, 10) # 输出10类(FashionMNIST有10个类别)# 初始化权重self.init_weights()def init_weights(self):"""使用Xavier均匀分布初始化权重,偏置初始化为0"""for m in self.modules():if isinstance(m, (nn.Linear, nn.Conv2d)): nn.init.xavier_uniform_(m.weight) # 保持前向/反向传播的方差稳定nn.init.zeros_(m.bias) # 偏置初始为0def forward(self, x):"""前向传播过程"""act = self.activation# 第一个卷积块(两次卷积+激活+池化)x = self.pool(act(self.conv2(act(self.conv1(x))))) # [32,1,28,28]→[32,32,14,14]# 第二个卷积块x = self.pool(act(self.conv4(act(self.conv3(x))))) # [32,32,14,14]→[32,64,7,7]# 第三个卷积块x = self.pool(act(self.conv6(act(self.conv5(x))))) # [32,64,7,7]→[32,128,3,3]# 分类头x = self.flatten(x) # [32,128,3,3]→[32,1152]x = act(self.fc1(x)) # [32,1152]→[32,128]x = self.fc2(x) # [32,128]→[32,10]return x # 输出10个类别的logits# 打印模型各层参数量
for idx, (key, value) in enumerate(CNN().named_parameters()):print(f"{key:<30} paramerters num: {np.prod(value.shape)}")定义模型在前几篇文章已有详细描述,这里补充一些内容。
此文的模型结构包含3个卷积块,每个卷积块包含两个卷积层,3个最大池化层,2个全连接层。
这里详细介绍一下pytorch构建新模型的步骤:
1.继承nn.Module类,所有pytorch模型都必须继承torch.nn.Module类
基础代码:
import torch.nn as nnclass MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()# 定义模型组件调用父类的构造函数,确保底层机制正确初始化。
2.在__init__方法中定义所有层和组件、实现forward方法,和此实战代码类似。
这里介绍一下常用的网络层类型:
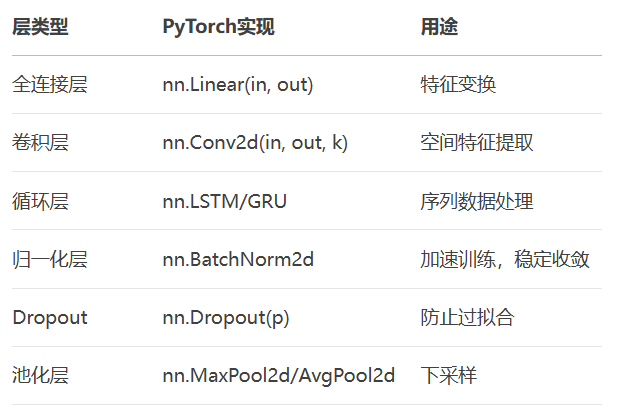
四、可视化计算图(不重要)
需要下载包,如果遇到下载困难也许可以看这篇文章:关于安装graphviz库遇到ExecutableNotFound: failed to execute WindowsPath(‘dot‘)……解决方案-CSDN博客
from torchviz import make_dot# Assuming your model is already defined and named 'model'
# Construct a dummy input
dummy_input = torch.randn(1, 1, 28, 28) # Replace with your input shape# Forward pass to generate the computation graph
output = model(dummy_input)# Visualize the model architecture
dot = make_dot(output, params=dict(model.named_parameters()))
dot.render("model_CNN", format="png")使用之后的效果像这样
五、评估函数
接下来就是训练的部分了,第一个是构造评估函数:
from sklearn.metrics import accuracy_score # 导入准确率计算函数@torch.no_grad() # 禁用梯度计算装饰器,减少内存消耗并加速计算
def evaluating(model, dataloader, loss_fct):"""模型评估函数参数:model: 待评估的PyTorch模型dataloader: 数据加载器,提供验证/测试数据集loss_fct: 损失函数返回:tuple: (平均损失, 准确率)"""# 初始化存储列表loss_list = [] # 存储每个batch的损失值pred_list = [] # 存储所有预测结果label_list = [] # 存储所有真实标签# 遍历数据加载器中的每个batchfor datas, labels in dataloader:# 将数据转移到指定设备(如GPU)datas = datas.to(device)labels = labels.to(device)# 前向计算(预测)logits = model(datas) # 模型输出原始预测值(未归一化)loss = loss_fct(logits, labels) # 计算当前batch的损失值loss_list.append(loss.item()) # 将损失值(标量)添加到列表# 获取预测类别(将logits转换为类别索引)preds = logits.argmax(axis=-1) # 取每行最大值的索引作为预测类别# 将结果转移到CPU并转换为Python列表pred_list.extend(preds.cpu().numpy().tolist()) # 添加当前batch的预测结果label_list.extend(labels.cpu().numpy().tolist()) # 添加当前batch的真实标签# 计算整体准确率(所有batch的预测与真实标签比较)acc = accuracy_score(label_list, pred_list) # 返回平均损失和准确率return np.mean(loss_list), acc 这里@torch.no_grad()是pytorch中的一个关键机制,用于在模型推理(评估)阶段关闭自动梯度计算功能,因为梯度自动计算只需要在模型训练里存在。
六、Tensorboard
```shell
tensorboard \--logdir=runs \ # log 存放路径--host 0.0.0.0 \ # ip--port 8848 # 端口from torch.utils.tensorboard import SummaryWriterclass TensorBoardCallback:def __init__(self, log_dir, flush_secs=10):"""Args:log_dir (str): dir to write log.flush_secs (int, optional): write to dsk each flush_secs seconds. Defaults to 10."""self.writer = SummaryWriter(log_dir=log_dir, flush_secs=flush_secs)def draw_model(self, model, input_shape):self.writer.add_graph(model, input_to_model=torch.randn(input_shape))def add_loss_scalars(self, step, loss, val_loss):self.writer.add_scalars(main_tag="training/loss", tag_scalar_dict={"loss": loss, "val_loss": val_loss},global_step=step,)def add_acc_scalars(self, step, acc, val_acc):self.writer.add_scalars(main_tag="training/accuracy",tag_scalar_dict={"accuracy": acc, "val_accuracy": val_acc},global_step=step,)def add_lr_scalars(self, step, learning_rate):self.writer.add_scalars(main_tag="training/learning_rate",tag_scalar_dict={"learning_rate": learning_rate},global_step=step,)def __call__(self, step, **kwargs):# add lossloss = kwargs.pop("loss", None)val_loss = kwargs.pop("val_loss", None)if loss is not None and val_loss is not None:self.add_loss_scalars(step, loss, val_loss)# add accacc = kwargs.pop("acc", None)val_acc = kwargs.pop("val_acc", None)if acc is not None and val_acc is not None:self.add_acc_scalars(step, acc, val_acc)# add lrlearning_rate = kwargs.pop("lr", None)if learning_rate is not None:self.add_lr_scalars(step, learning_rate)from torch.utils.tensorboard import SummaryWriterclass TensorBoardCallback:def __init__(self, log_dir, flush_secs=10):"""Args:log_dir (str): dir to write log.flush_secs (int, optional): write to dsk each flush_secs seconds. Defaults to 10."""self.writer = SummaryWriter(log_dir=log_dir, flush_secs=flush_secs)def draw_model(self, model, input_shape):self.writer.add_graph(model, input_to_model=torch.randn(input_shape))def add_loss_scalars(self, step, loss, val_loss):self.writer.add_scalars(main_tag="training/loss", tag_scalar_dict={"loss": loss, "val_loss": val_loss},global_step=step,)def add_acc_scalars(self, step, acc, val_acc):self.writer.add_scalars(main_tag="training/accuracy",tag_scalar_dict={"accuracy": acc, "val_accuracy": val_acc},global_step=step,)def add_lr_scalars(self, step, learning_rate):self.writer.add_scalars(main_tag="training/learning_rate",tag_scalar_dict={"learning_rate": learning_rate},global_step=step,)def __call__(self, step, **kwargs):# add lossloss = kwargs.pop("loss", None)val_loss = kwargs.pop("val_loss", None)if loss is not None and val_loss is not None:self.add_loss_scalars(step, loss, val_loss)# add accacc = kwargs.pop("acc", None)val_acc = kwargs.pop("val_acc", None)if acc is not None and val_acc is not None:self.add_acc_scalars(step, acc, val_acc)# add lrlearning_rate = kwargs.pop("lr", None)if learning_rate is not None:self.add_lr_scalars(step, learning_rate)后续代码与前几篇文章代码差不多,不过多赘述。