StreamRL:弹性、可扩展、异构的RLHF架构
StreamRL:弹性、可扩展、异构的RLHF架构
大语言模型(LLMs)的强化学习(RL)训练正处于快速发展阶段,但现有架构存在诸多问题。本文介绍的StreamRL框架为解决这些难题而来,它通过独特设计提升了训练效率和资源利用率,在相关实验中表现优异,想知道它是如何做到的吗?快来一探究竟!
文章核心
论文标题:StreamRL: Scalable, Heterogeneous, and Elastic RL for LLMs with Disaggregated Stream Generation
来源:arXiv:2504.15930v1 [cs.LG] + https://arxiv.org/abs/2504.15930
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
研究背景
在大语言模型(LLMs)的发展进程中,强化学习(RL)已成为关键的训练后技术,它有效提升了模型的推理能力,不少前沿模型如 OpenAI 的 o1、o3,Claude 3.7 Sonnet 以及 DeepSeek - R1 等均借助 RL 在多种任务中取得领先表现。
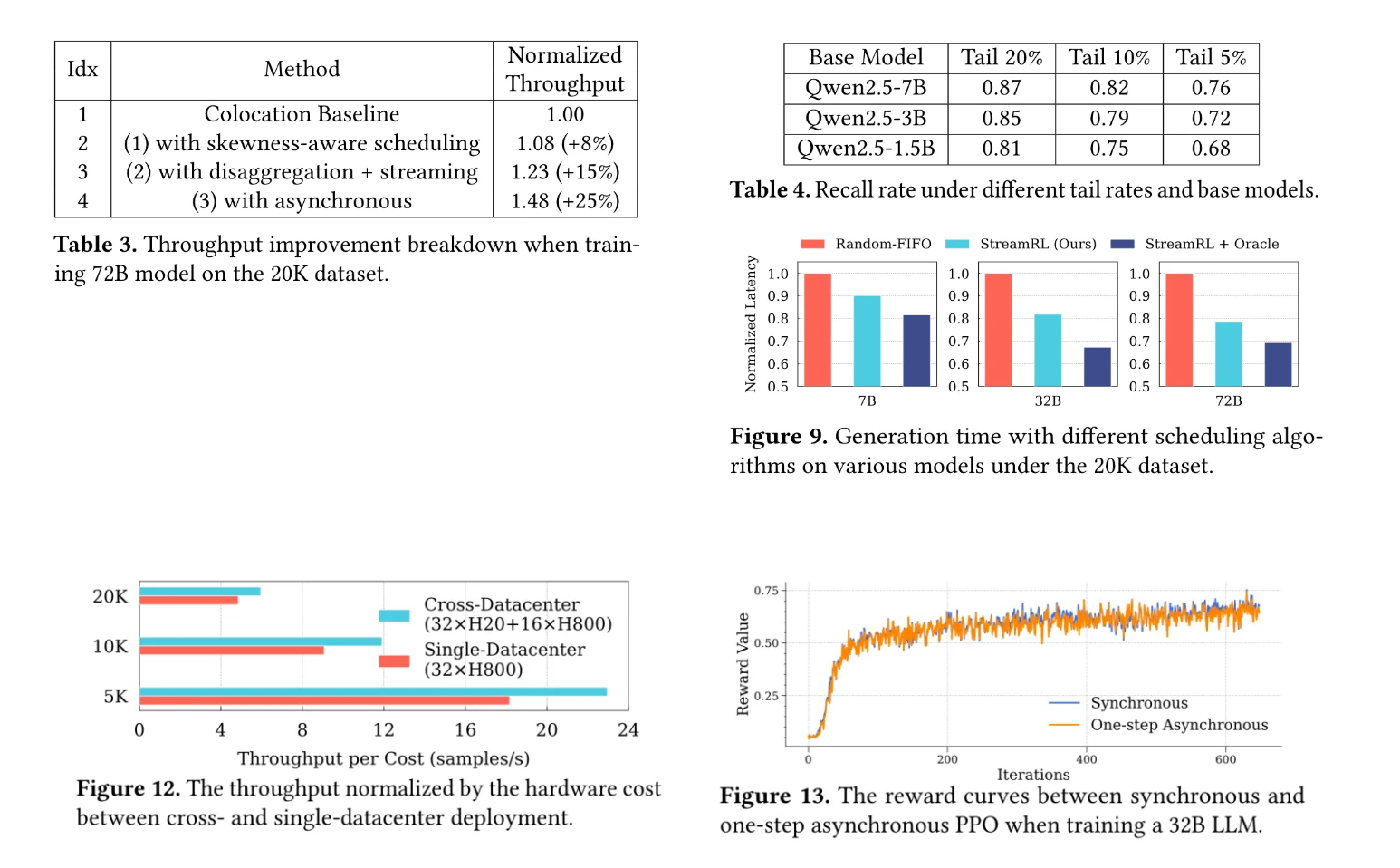
早期,RL 训练框架多采用分离式架构,虽能复用现有基础设施,但存在资源闲置问题。为解决此问题,共置架构应运而生,它通过时间复用 GPU 资源,提升了训练效率,一度成为主流选择。然而在实际大规模部署时,共置架构暴露出资源耦合的弊端。与此同时,分离式架构的优势重新受到关注,但其在现有框架下存在流水线气泡和偏态气泡等挑战,StreamRL 正是在这样的背景下被提出,旨在解决上述问题,充分释放分离式架构的潜力。
研究问题
-
传统共置(colocated)架构存在资源耦合问题,生成阶段和训练阶段因共享相同资源,无法根据各自特性灵活分配资源,导致资源利用率低,影响大规模训练的可扩展性和成本效益。
-
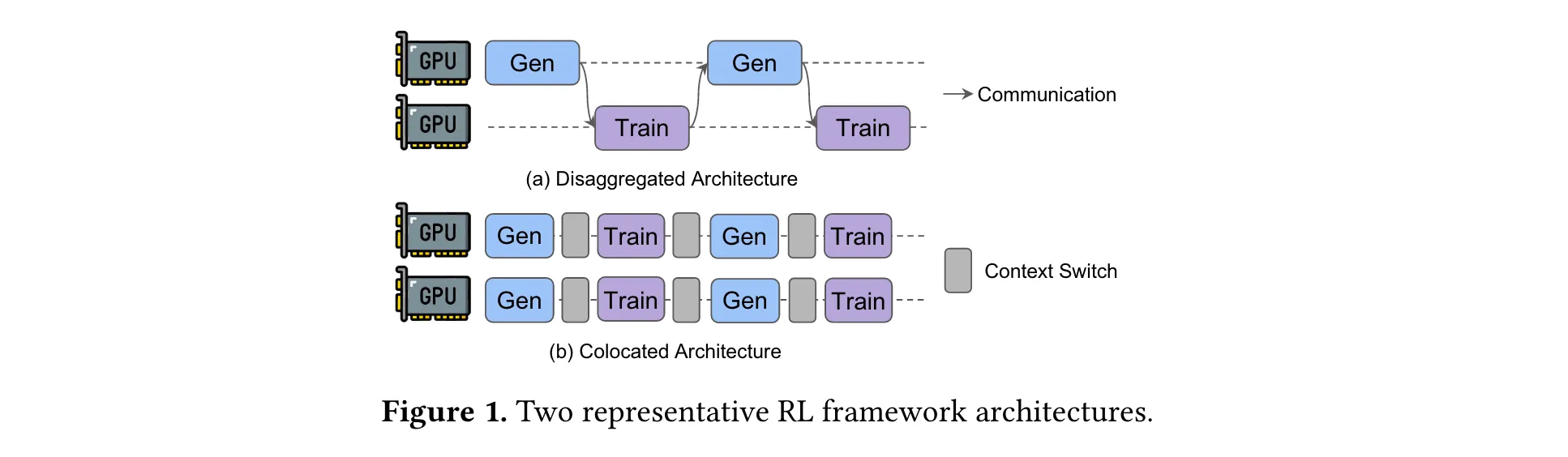
分离式(disaggregated)架构虽理论上有优势,但存在流水线气泡(pipeline bubbles)和偏态气泡(skewness bubbles)问题。流水线气泡源于两阶段串行执行,偏态气泡则因LLM推理工作负载中长尾输出长度分布,这两种气泡都会造成GPU资源闲置。
-
现有框架难以有效应对LLM推理工作负载固有的长尾输出长度分布问题,处理不当会影响模型质量和训练效率。
主要贡献
1. 重新审视架构优势:分析现有共置RL框架的关键问题,提出重新采用分离式架构进行RL训练。该架构可实现灵活资源分配、支持异构硬件选择以及跨数据中心训练,克服了共置架构的局限性。
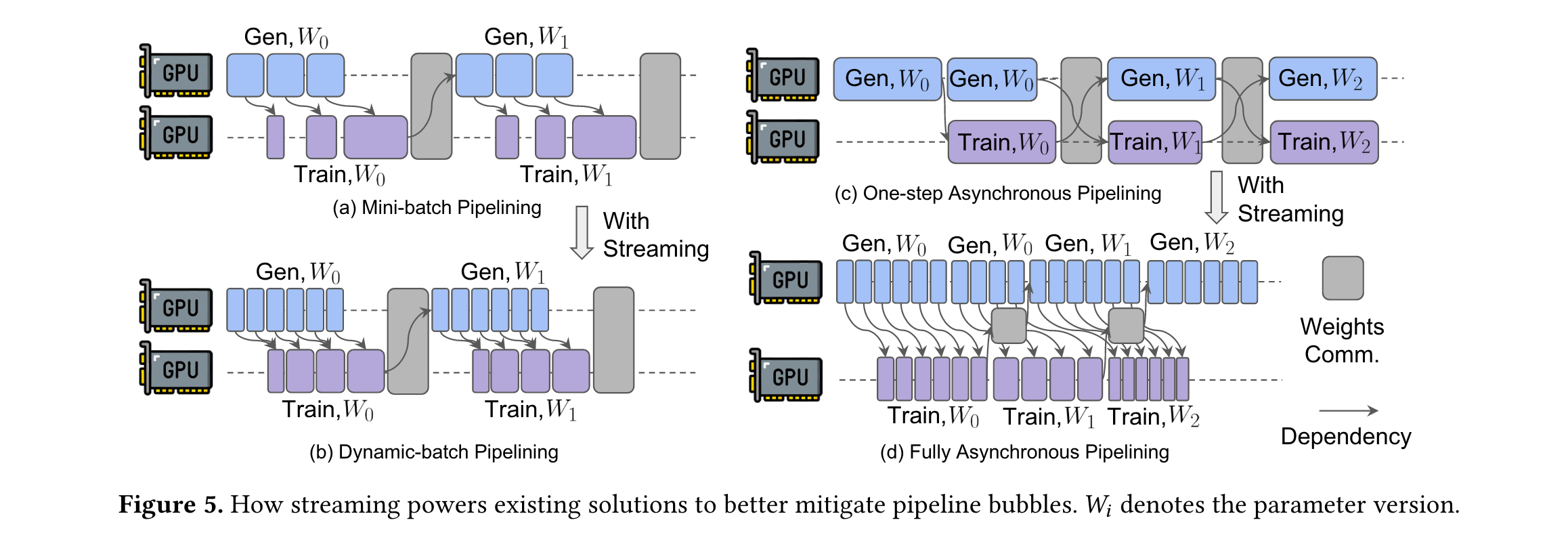
2. 提出StreamRL框架:设计StreamRL框架,通过解决流水线气泡和长尾问题,充分释放分离式架构的潜力。如采用动态批处理流水线(Dynamic-batch pipelining)和完全异步流水线(Fully asynchronous pipelining)解决流水线气泡;利用输出长度排序器模型(Output Length Ranker)和偏态感知调度(Skewness-aware scheduling)处理长尾问题。
3. 实验验证性能优越:通过在多种LLMs和真实数据集上实验,证明StreamRL相比现有最先进系统,吞吐量最高提升2.66倍,在异构、跨数据中心设置下成本效益最高提升1.33倍,展现出良好的性能和可扩展性。
方法论精要
StreamRL是专为分离式架构设计的高效强化学习框架,其技术路线围绕解决分离式架构存在的问题展开,主要包含以下关键步骤:
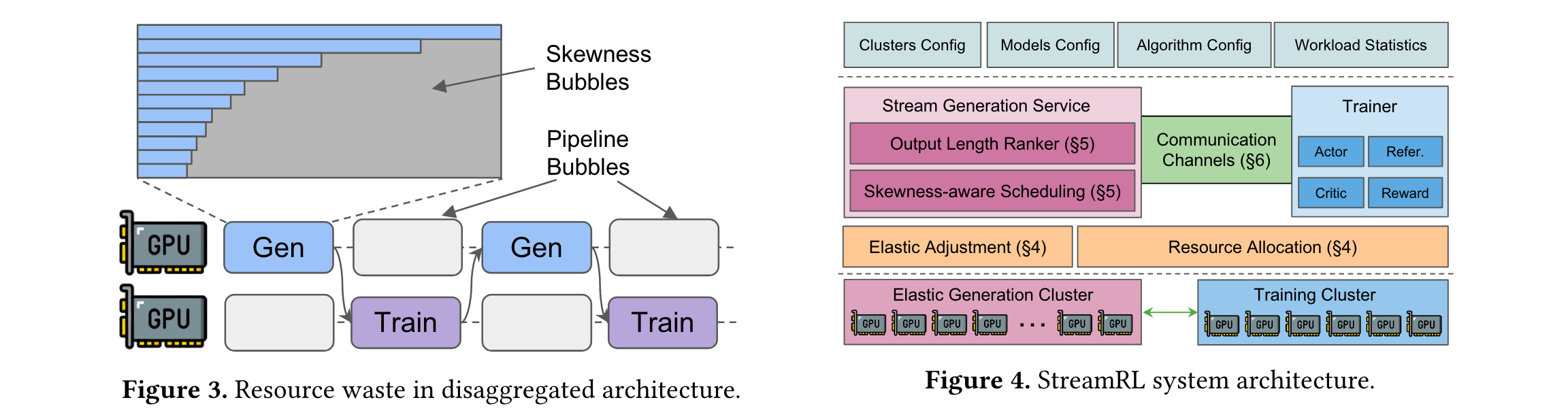
1. 核心框架设计:StreamRL将生成和训练阶段分别抽象为流生成服务(SGS)和训练器(Trainer),二者部署在物理上分离的资源上,甚至可位于不同数据中心,通过点到点链路连接。这种设计能实现灵活的资源分配、异构硬件选择和跨数据中心训练。
2. 解决流水线气泡问题:针对流水线气泡,StreamRL在不同RL算法场景下采用不同策略。在同步RL中,提出动态批处理流水线,摒弃传统的批量生成方式,样本一完成就立即发送给训练阶段,训练阶段根据生成速度进行动态批处理,减少训练阶段空闲时间,消除大部分流水线气泡。在异步RL中,采用完全异步流水线,使权重传输与训练、生成过程并行,去除权重传输对关键路径的影响,即便迭代间生成和训练时间有波动,只要平均速度匹配且波动有限,就不会产生新的气泡。
3. 处理偏态气泡问题:为解决偏态气泡,StreamRL利用输出长度排序器模型来识别长尾样本。该模型通过对收集的(prompt, length)对进行监督微调训练得到,可对输入提示的输出长度进行估计和排序。基于此,SGS采用偏态感知调度机制,将提示按估计输出长度排序,标记出长尾样本,为其分配专门的计算资源和较小的批量大小,同时将常规样本组成大批次,充分利用GPU资源。在调度顺序上,采用最长处理时间优先(LPT)的贪心算法,优先处理长样本,以减少整体生成延迟。
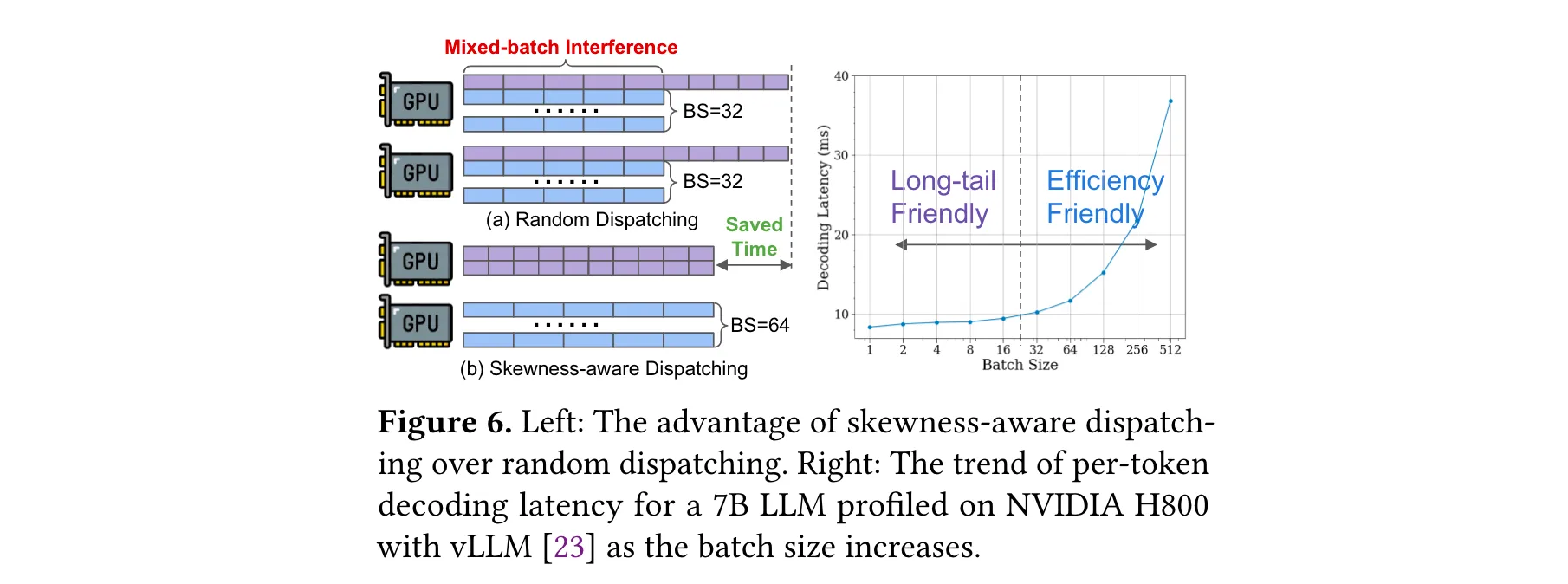
4. 系统实现优化:SGS使用内部优化的C++推理引擎和CUDA内核,支持连续批处理和前缀共享技术,提高生成效率;Trainer实现3D并行,通过开发动态CPU卸载技术解决GPU内存限制问题。此外,专门开发的RL - RPC通信框架用于SGS和Trainer间的数据传输,利用GPU - Direct RDMA实现零拷贝张量传输,减少通信开销,并具备TCP fallback机制确保兼容性。在权重传输方面,根据不同部署场景采用不同策略,单数据中心通过多树负载均衡,跨数据中心则由特定节点发送权重并结合本地广播,以优化传输效率。
实验洞察
为全面评估StreamRL的性能,研究人员进行了一系列实验,从多个维度深入探究其特性,具体实验结果如下:
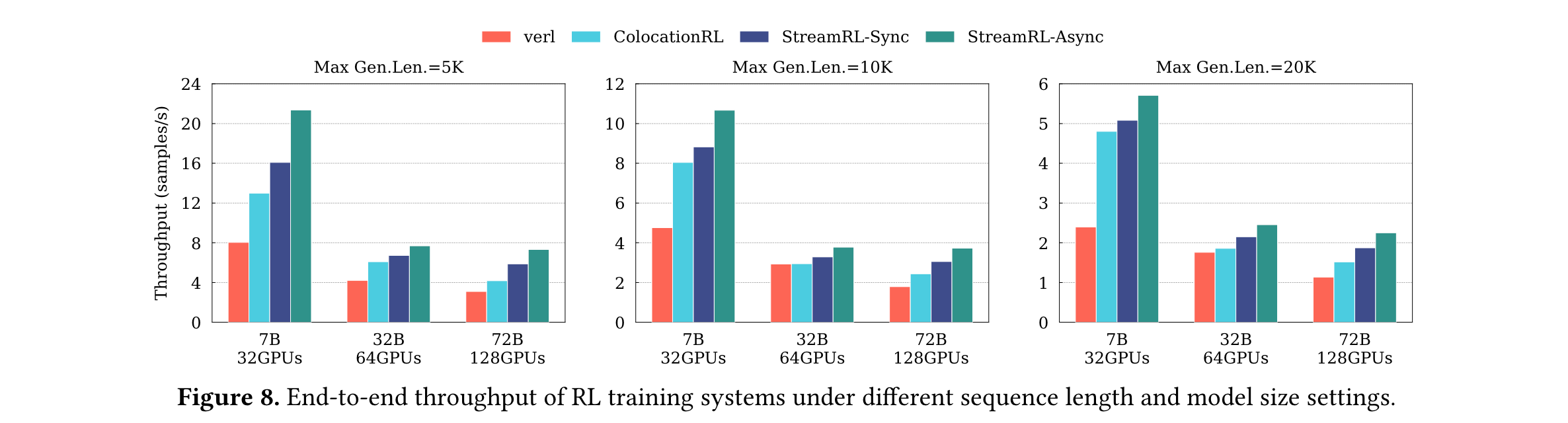
1. 性能优势显著:研究人员在包含16个节点、128个GPU的H800集群上,选用Qwen2.5系列模型(7B - 72B),以内部CodeMath prompts数据集开展实验,并以verl和ColocationRL为基线对比。结果显示,StreamRL - Sync相较于verl,吞吐量提升1.12 - 2.12倍;相较于ColocationRL,提升1.06 - 1.41倍。而StreamRL - Async借助一步异步训练,充分重叠流水线气泡,吞吐量提升幅度更大,达1.30 - 2.66倍。在异构、跨数据中心场景下,将SGS部署于H20集群,Trainer部署于H800集群,StreamRL经硬件成本归一化后的吞吐量,相比单数据中心场景提高了1.23 - 1.31倍,展现出强大的性能优势。
2. 效率大幅提升:在训练效率方面,StreamRL成果斐然。通过异步训练和优化资源分配,实现了阶段延迟的有效平衡,在异步训练中迭代时间由较慢阶段决定,平衡的阶段延迟直接带来1.25倍的加速。并且,动态调整算法能实时监测生成和训练时间差,当生成时间超训练时间一定阈值时,自动为SGS增加数据并行单元,恢复阶段平衡。如在训练7B模型时,随着数据集输出长度增加,StreamRL能及时检测到不平衡并自动调整资源,确保训练高效进行。
3. 核心模块效果显著:通过消融研究,验证了StreamRL核心模块的有效性。以72B模型在20K最大长度数据集上的实验为例,偏态感知调度技术可使吞吐量提升8%,主要是因为其利用输出长度排序器模型精准识别长尾样本,为其分配专属资源和合适批量,加速了长尾样本生成。在此基础上,分离式流生成技术进一步将吞吐量提升15%,异步训练则额外提升25%。输出长度排序器模型对最长20%样本的召回率高达87%,能有效识别长尾样本,大幅提升生成效率,为整体性能提升奠定坚实基础。