如何查看某个文件中的特殊符号
Q:如何查看某个文件中的特殊符号,比如说是换行符之类的转义字符?
1,法1:使用cat -A
cat -A filename
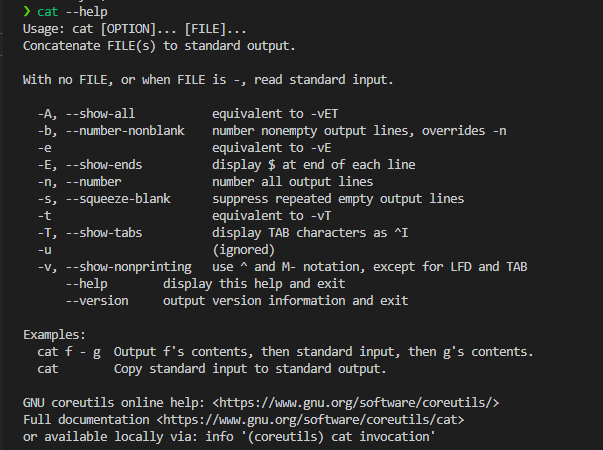
可以看到-A本质上就是-vET,也就是
展示所有的字符,-v是显示非打印字符,这个需要回顾一下ASCII码的知识了,因为有很多字符可以用ASCII码表示,但是没法直接打印显示出来;
参考:https://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html

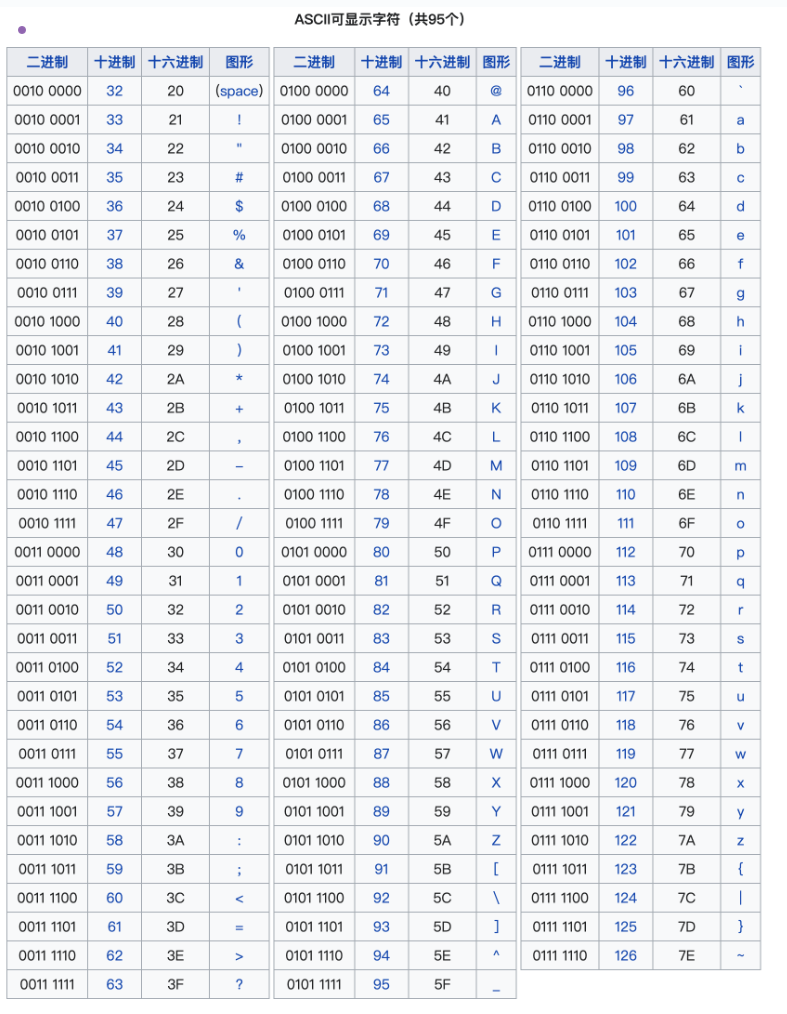
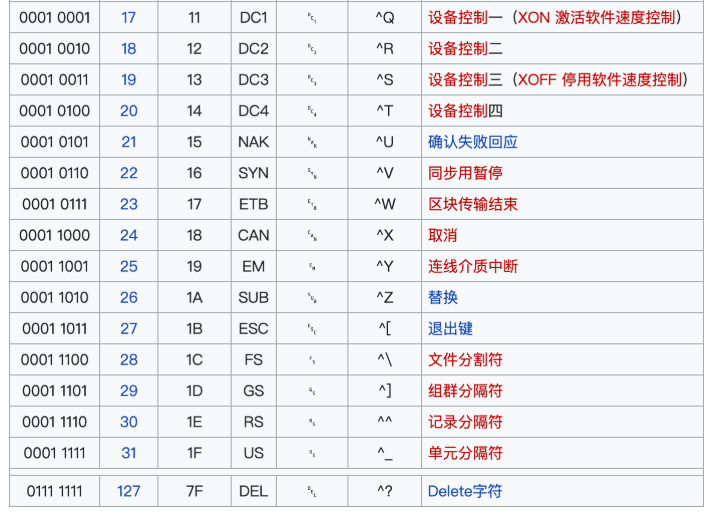
可显示字符编号范围是32-126(0x20-0x7E),共95个字符:
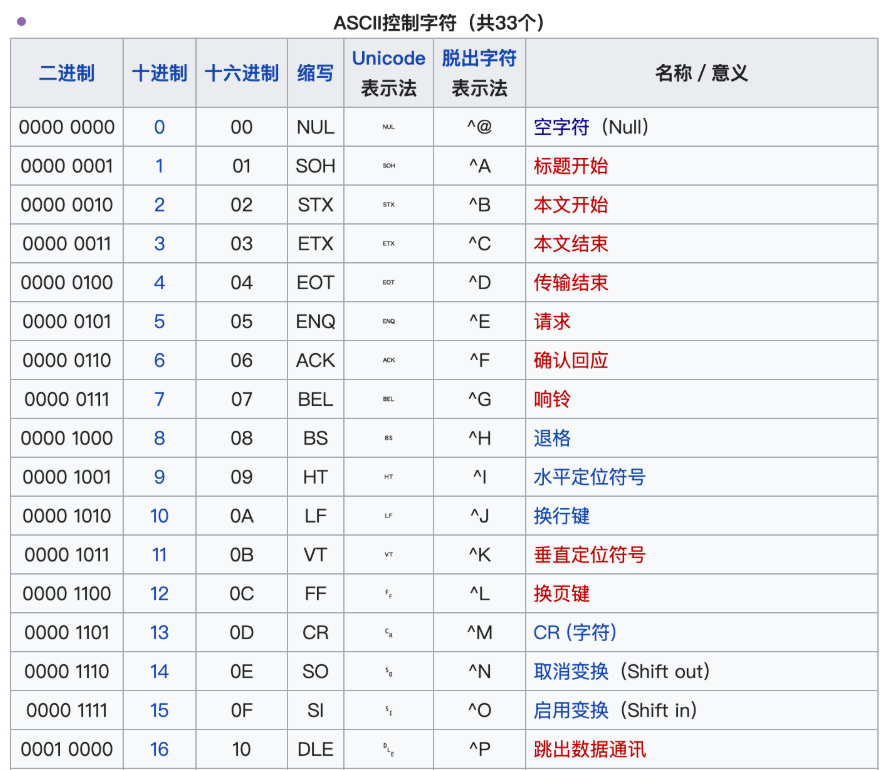
ASCII控制字符的编号范围是0-31和127(0x00-0x1F和0x7F),共33个字符:

当然这里扯到了字符编码的计算机的一些基本常识,ASCII编码肯定是不够的,我们还有unicode编码,顾名思义uniform也就是统一的、unique唯一的,基本上是百科全书式的,

当然编码只是第1个问题,我们有了世界上任意国家任意语言任意字符的1个统一标准的编码,那么我们人是能够识别的,但是计算机呢?
所以第2个问题就是如何在计算机上存储的问题,也就是计算机识别的问题?
相当于我们有了字典,但是我们需要在计算机上去实现这个字典。

所以我们经常提到的UTF-8编码方式,本质上是对Unicode编码格式的一种计算机实现;

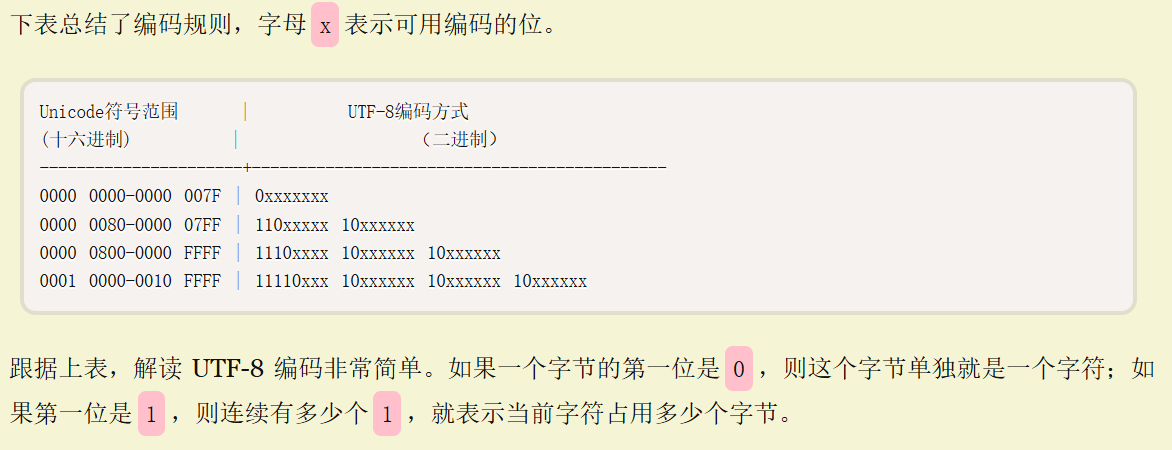

“-v, --show-nonprinting”是一个命令行选项,用于显示非打印字符。具体解释如下:
- -v:这是该选项的短格式,用于在命令行中快速指定该功能。
- –show-nonprinting:这是该选项的长格式,提供了更清晰的描述,表明其功能是显示非打印字符。
- use ^ and M- notation:表示非打印字符的符号,如“^A”表示ASCII码为1的字符;“M-”通常用来表示带有Meta键修饰的字符,比如“M-a”可能表示某个特定的控制字符。
- except for LFD and TAB:表示除了换行符(LFD,Line Feed)和制表符(TAB)之外。也就是说,换行符和制表符不会使用上述的“^”和“M-”符号来表示,而是会以它们原本的显示方式呈现。
回过来,-E类似于换行符的提醒功能,但是不换行,只是展示EOF类似,end of line,EOL之类;

然后就是制表符的打印

比如说我通过使vim新建了1个文本字符文件,
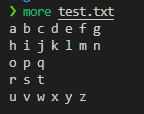
然后使用
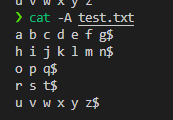
事实上我只能看到每行在哪里结束,这其实和直接打印出内容没有区别,都是一目了然的效果;
2,法2:使用od(八进制/十六进制查看)

本质上是一个读取文件内容,再以八进制格式输出的命令



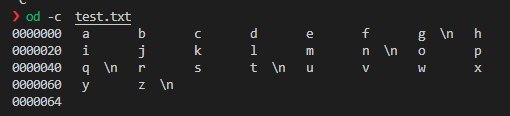
od -c filename
现在我们能够看到换行符
参考:https://www.runoob.com/linux/linux-comm-od.html
3,使用 hexdump
因为字符编码是本质,所以查看任意文件内容,花样或者说核心就在于查看文件的字符格式,
比如说用多进制格式来查看

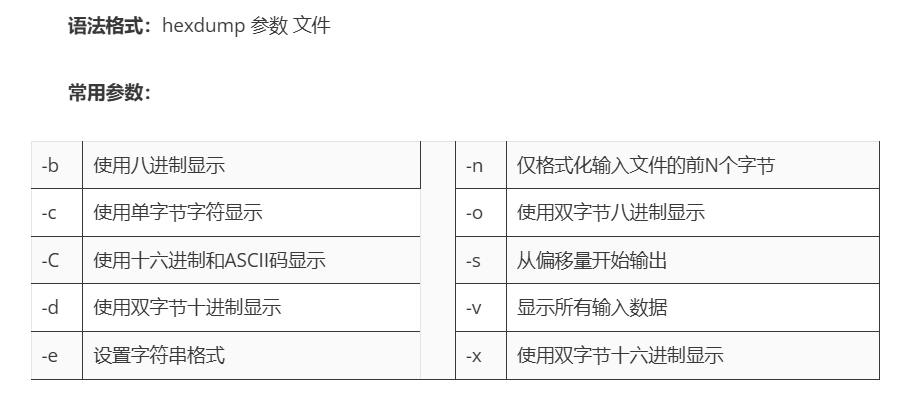
hexdump -C filename
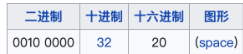
我们能够查看十六进制以及相应地ASCII码,

事实上我们可以看到ASCII码中:
以最后一行为例:
79是y,20是空格space,7a是z,0a是换行符



参考:https://www.linuxcool.com/hexdump
4,使用vi或vim+特殊模式(mode)
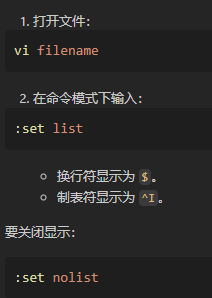

可以看到换行符的展示:
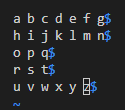
只是符号形式的展示,不是编码本质的展示
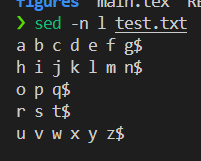
5,使用sed或者awk文本处理命令:
sed -n l filename
l 命令会将不可见字符显示为可见形式

如果是使用awk的话,可以取出每一行,然后定义1个ord函数,用于读取每一个字符的unicode字符(基础python中的ord以及chr字符函数等),这样我就可以查看每一行具体的字符形式,包括其中的特殊字符。
当然,如果使用ord的话,需要自己自己能够识别unicode字符编码中哪些码值对应特殊的字符。
awk '{for(i=1;i<=length($0);i++) printf "%d ", ord(substr($0,i,1)); print ""}' filename# 上面的ord函数只是1个idea,需要自己定义,可以使用python等