pyorch中tensor的理解与操作(一)
tensor 是PyTorch 中一个最基本的数据集合类型, 本文注意针对该结构类型,说明它的存储方式以及主要的操作方法。
tensor其实是一个多维数组(元素的数据类型需一致),类似于 NumPy 的 ndarrays,但可以在 GPU 上运行。张量的维数可以是0,1…,因此这里的张量的意义也包含了数学上的标量(即维度0)、向量(即维度1)、矩阵(即维度2)。
【注】本文示例适用于pytorch2+。
1.内部数据存储理解
在了解tensor的各种方法以前,最好能理解它内部数据的存储方式,这样能更好得理解它的各种行为。
大致上,tensor由meta区和data区两部分构成,meta区保存着tensor的各种信息,如形状(shape)、数据类型(type),底层存储类(Storage)等,底层存储类管理真正的数据存储区。元素有两种存储方式:sparse和dense,sparse用于特殊场景,一般是dense non-overlapping,也就是通常意义下的“逐个元素”存储,存储区是一块内存区域(大小为总元素个数*元素大小)。
数据区保存数据,如何“解释”这些数据,由meta区的信息决定,这是tensor的运作方式。在这种结构下,tensor具有如下性质:
- 如果tensor的shape,stride不同,即使大小相同的存储区域,也可以被“解释”成不同的维度。
- 如果两个tensor的具有相同的数据区,则这两个tensor共享相同的数据,即使它们 “看上去”不同。
- 从时间成本上说,修改或复制meta区的内容比较低,而复制数据区内容则比较高,如果要关注效率,应注意哪些操作复制了数据。
从下面几个方法可以判断两个tensor数据区的“状态”:
- tensor.is_set_to(anothertensor)为true时表明这两个tensor完全一致,共享全部数据
- tensor.data_ptr() 返回底层的存储区指针,此指针相等可以来判断两个tensor数据区相同(反过来不一定成立,即如果一个内存区包含另一个内存区,即使二者不同,数据也是共享的)。
- tensor. untyped_storage()返回底层存储类,通过id操作符来判断两个tensor是否共享底层存储类(如果是则意味着有相同存储区)。
- tensor.equal仅从shape和数据的值来 判断两个tensor是否相等,而不管它们是否是共享数据。
meta区由两个关键属性shape和stride决定存储区数据的“解释”方式。Shape比较好理解,就是各维度大小(各维度下元素的个数,其乘积是总存储区大小)。Stride是各维度下相邻元素的间隔。
例如,假设存储区共24个数,从1到24,shape为(2,3,4),stride为(12,4,1)。从shape角度看(从后到前),每4个元素组成“末级块”,3个“末级块”组成“次末级块”,依次类推;从stride角度看(从后到前),“末级块”中相邻元素的间隔为1,“次末级块”相邻元素的间隔为4,依次类推,如下图所示。
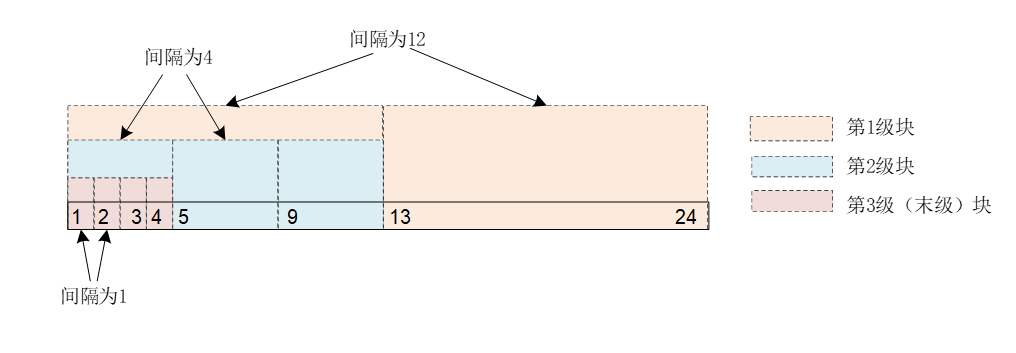
注意,上面示例中,数据是按“行连续”放置(C/C++中数组存放模式,行优先),显而易见,此时shape和stride可以相互推导,且stride呈递减排列,上级是下级的整数倍。然而,某些操作会使数据变得“不连续”,例如transpose(转置),从tensor.is_contiguous()可以返回数据是否按“行连续”放置状态,如果此状态为假,shape和stride变得不能相互推导。
同样对上例,执行
anothertensor=torch.transpose(tensor,1,2)
print(anothertensor.data_ptr(), tensor.data_ptr()
print(anothertensor.shape(), tensor.shape())
print(anothertensor.stride(), tensor.stride())从运行结果,可以看到tensor和anothertensor的数据是共享的,tensor是按“行连续”的,而antothertensor则不是,另外,转置后,shape和stride的第2维与3维交换了,变成shape(2,4,3)和stride(12,1,4),同样可以采用上面的方法进行示意,如下图所示。
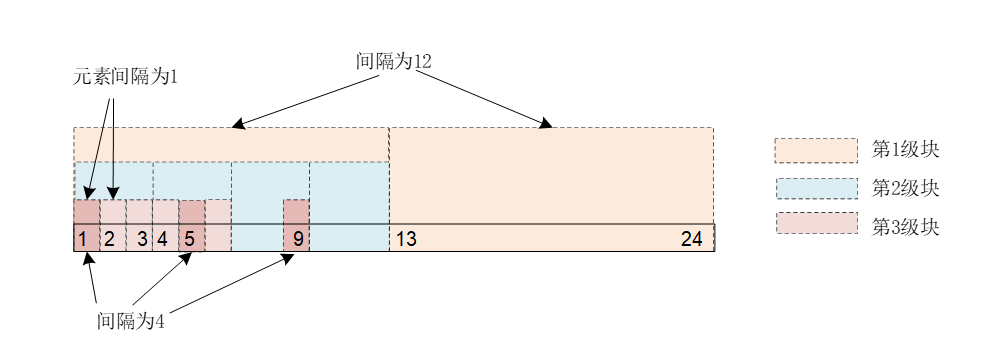
最内层的数据之间间隔为4,由3个数组成,即为[1,5,9],次内层的第2个元素与上个元素的间隔是1,即将第1个元素[1,4,9]中每个整体后移1个间隔,即为[2,6,10],次内层第2个元素为[3,7,11],其余类推。如果按“行连续”,与shape(2,4,3)对应的stride为(12,3,1),显然,按“行连续”与“非行连续”展示存储区的数据,结果是不一样的。
因此,如果数据按“行连续”,根据shape或stride都可以展示数据,如果“不连续”,则要根据shape和stride展示数据。
最后,稍微说一下memory_format,它是tensor.is_contiguous的参数,实际上,tensor.is_contiguous是检查tensor的数据放置模式是否与memory_format一致,缺省时memory_format=torch.contiguous_format,也就是检查是否按行连续。memory_format有4个选项值:
- torch.contiguous_format:也就是通常的按行连续(C语言数组存放模式)
- torch.channels_last: 专门针对“2d图像”数据(4个维度),stride按NHWC顺序。
- torch.channels_last_3d: 专门针对“视频图像”数据(5个维度)stride按NDHWC顺序。
- torch.preserve_format:如果torch.contiguous_format,则不发生变化,否则遵循torch.contiguous_format方式。
其中N:batch,D:Time,H:height,W:width,C:channel
一般情况下,pytorch中图像的存储方式是CHW,其stride为(H*W,W,1),HWC方式与bmp文件格式类似,CHW与HWC如下图所示,HWC的stride为(1,3*W,3),以上假设C=3。
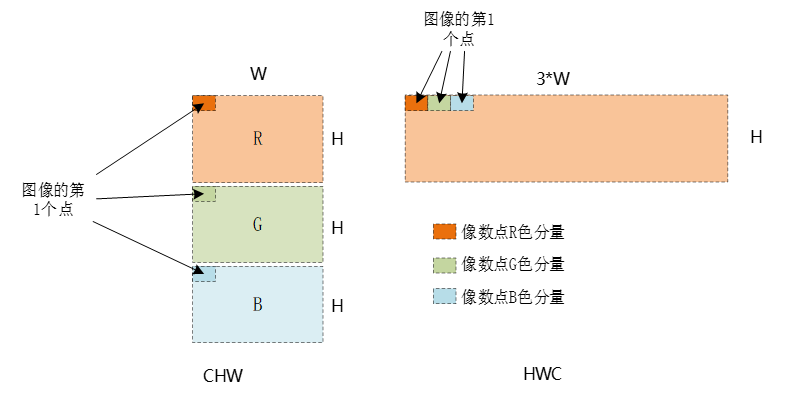
channels_last与channels_last_3d都是针对图像训练数据的,目的是提高运行速度(pytorch,tensorflow都引用了XNNPACK,一个开源的高效的神经网络库,而XNNPACK采用channels_last格式数据)。关于channel_last存储模式,可参考https://pytorch.org/blog/tensor-memory-format-matters/,以及内存模式中数据的表达,可参考https://oneapi-src.github.io/oneDNN/dev_guide_understanding_memory_formats.html
2.tensor的创建
tensor有很多种创建方式,包括创建+不初始元素,创建+按特定方式初始化化元素,从python的list或numpy的narray转换创建等。以下是一些示例。
tensor1 = torch.tensor([[[0,1,2,3,4],[0,1,2,3,4],[0,1,2,3,4]]]) #接受从list或tuple的内容创建,1*3*5
tensor2 = torch.Tensor([[[0,1,2,3,4],[0,1,2,3,4],[0,1,2,3,4]]]) #接受从list或tuple的内容创建,1*3*5
tensor3 = torch.Tensor(1,3,5) #也接受维度信息,元素随机值,1*3*5,tensor不行
tensor4=torch.tensor(2) #其实是一个标量,0维,值为2,shape为torch.Size([])
tensor5=torch.FloatTensor(2) #1维向量,2个(随机)值tensor6 =torch.empty ((2,3)) # 2*3的矩阵,第1个参数为*size,因而也可写[2,3],或2,3,下同
tensor7 = torch.full((2,3),2) #2*3矩阵,元素都填充为2
tensor8 = torch.ones((2,3)) #相当于full((2,3),1)
tensor9 = torch.zeros ((2,3)) #相当于full((2,3],0)
tensor10= torch.eye(3,2) #创建3*2矩阵,其中包含的2*2方阵为单位阵,不支持3维及以上
tensor11 =torch.rand/randn (2,3) #2*3矩阵,从[0-1]平均/标准正态分布中随机选取数据填充元素tensor12 =torch.as_tensor(anothorarray)
tensor13 =torch.from_numpy(ndarray)
tensor14 = torch.linspace(1,16,16).view(2,4,2) #创建一个数值线性增长(1-16)的2*4*2的Tensor
tensor15 =torch.empty_like /rand_like(anothertensor) / # 与anothertensor的维度相同
tensor16= torch.zeros([2,3],dtype=torch.float64,device=torch.device('cuda:0')) #指定类型和设备在创建过程中,如果tensor的数据来自其它数据源,则应注意tensor数据与这个“数据源”的关系,即这两者的数据是共享还是各自独立。例如,
- tensor1的传入参数是数组,tensor会以“copy”方式创建,二者独立; 注:以torch.tensor()方式创建的tensor总是以“copy”方式创建。
- 采用as_tensor方法,情况比较复杂,首先尝试采用共享,不行的话采用”copy”。
- from_numpy创建的tensor与numpy共享数据。
从已有Tensor创建相同的Tensor有几个方法:
tensor =torch.clone(anothertensor) 或 tensor =anothertensor.clone()
tensor.copy_(anothertensor) 或 tensor = torch.empty_like(anothertensor).copy_( anothertensor)
tensor = anothertensor.detach()clone创建的tensor与源tensor不共享data数据,需要注意,clone被当作一种“运算”(就如同Atensor=Btensor+Ctensor中“+”一样),因而clone的tensor与源tensor通过“计算图”关联(clone的tensor是源tensor某种运算的结果),在反向传播计算时,clone的tensor结果会累积到是源tensor。简单说,就是clone的tensor与源tensor数据独立,反向梯度计算有联系。(关于计算图,参阅下面内容)
copy_在使用之前,tensor需要先创建(第1个示例表示前面已创建,第2个示例中采用了torch.empty_like),然后从anothertensor中“copy”数据,tensor与anothertensor的总数据个数必须一致,但各维度可以不同,它们在操作完成后不再有任何关系。
detach的功能与clone正好相对,detach的tensor与源tensor共享数据,但detach不是一种“运算”,因而二者在反向梯度计算中没有关系,并且detach的tensor会设置其requires_grad为False。
2.tensor信息
创建tensor后或在尤其在调试中,经常需要查看tensor的结构信息,以下是一个查看tenso的信息的方法:
def tensor_info(t):if not isinstance(t,torch.Tensor):return f"not a tensor object:{type(t)}"device=t.device # cpudtype =t.dtypeshape =t.shape # 尺寸ndim =t.ndim #维度nbytes= t.nbytes if hasattr(t,"nbytes") else None # this attribute doesnot exist in low versions itemsize=t.element_size()itemcount=t.nelement() #element count totallyreturn f"device={device}, dtype={dtype}, shape={shape}, ndim={ndim}, nbytes={nbytes}, itemsize={itemsize}, count={itemcount}";特别说明的是tensor的维度信息,有下面两个方法:tensor.size()和tensor.shape,它们返回的是同一个类型torch.Size,注意前者是类的函数,后者是类的属性,如果需要某一维度的大小(示例是第2个维度),调用方法如下:
tensor.size()[1]
tensor.shape[1]