【并发编程】MySQL锁及单机锁实现
目录
一、MySQL锁机制
1.1 按锁粒度划分
1.2 按锁功能划分
1.3 InnoDB锁实现机制
(1)记录锁(Record Lock)
(2) 间隙锁(Gap Lock)
(3) 临键锁(Next-Key Lock)
(4) 插入意向锁(Insert Intention Lock)
二、基于 JVM 本地锁实现,保证线程安全
2.1 线程不安全的分析
2.1.1 多线程并发访问(未加锁)
2.2 基于 synchronized 加锁访问
2.3 基于 synchronized 加锁访问
2.4 JVM 本地锁的缺陷
三、基于 MySQL 锁实现,保证线程安全问题
3.1 基于原子 SQL 实现
3.2 基于悲观锁实现(灵活多 SQL )
3.2.1 原生 SQL 实现
3.2.2 Java 代码实现
3.2.3 悲观锁优缺点
3.2.4 死锁演示
3.3 基于乐观锁实现(CAS)
3.3.1 原生SQL实现
3.3.2 Java 代码实现
3.3.3 乐观锁存在的问题
四、本地不同类型锁的总结
一、MySQL锁机制
1.1 按锁粒度划分
-
表级锁:锁定整张表
- 优点:开销小,加锁快
- 缺点:并发度低
- 实现:
LOCK TABLES语句或存储引擎自动加锁
-
行级锁:锁定单行记录
- 优点:并发度高
- 缺点:开销大,加锁慢
- 实现:InnoDB通过索引实现
-
页级锁:锁定一页(16KB)
- 折中方案,BDB引擎使用
1.2 按锁功能划分
-
共享锁(S锁):
- 语法:
SELECT ... LOCK IN SHARE MODE - 特性:多个事务可同时获取,但不能与排他锁共存
- 语法:
-
排他锁(X锁):
- 语法:
SELECT ... FOR UPDATE - 特性:独占锁,其他事务不能获取任何锁
- 语法:
-
意向锁(Intention Lock):
- 表级锁,表示事务将要获取行锁
- IS锁(意向共享锁):事务准备给行加S锁
- IX锁(意向排他锁):事务准备给行加X锁
1.3 InnoDB锁实现机制
(1)记录锁(Record Lock)
- 锁定索引中的单条记录
- 实现方式:通过索引项加锁
(2) 间隙锁(Gap Lock)
- 锁定索引记录间的间隙
- 防止幻读问题
- 示例:
SELECT * FROM t WHERE id > 10 AND id < 20 FOR UPDATE
(3) 临键锁(Next-Key Lock)
- 记录锁+间隙锁的组合
- 锁定记录及记录前的间隙
- InnoDB默认行锁算法
(4) 插入意向锁(Insert Intention Lock)
- 特殊的间隙锁
- 多个事务在相同间隙插入不同记录时不冲突
二、基于 JVM 本地锁实现,保证线程安全
2.1 线程不安全的分析
多线程环境下多个线程(并发用户访问)访问同一个共享资源,并对资源进行修改(触发了线程安全问题)。
接下来只关注 Service 层的逻辑实现
2.1.1 多线程并发访问(未加锁)
1. 创建多线程环境下生产级减库存案例
@Service
public class StockService {private Stock stock = new Stock();public void deduct(){stock.setStock(stock.getStock()-1);System.out.println("扣减成功,剩余库存:"+stock.getStock());}
}2. 运行项目,通过 JMeter 进行并发测试:
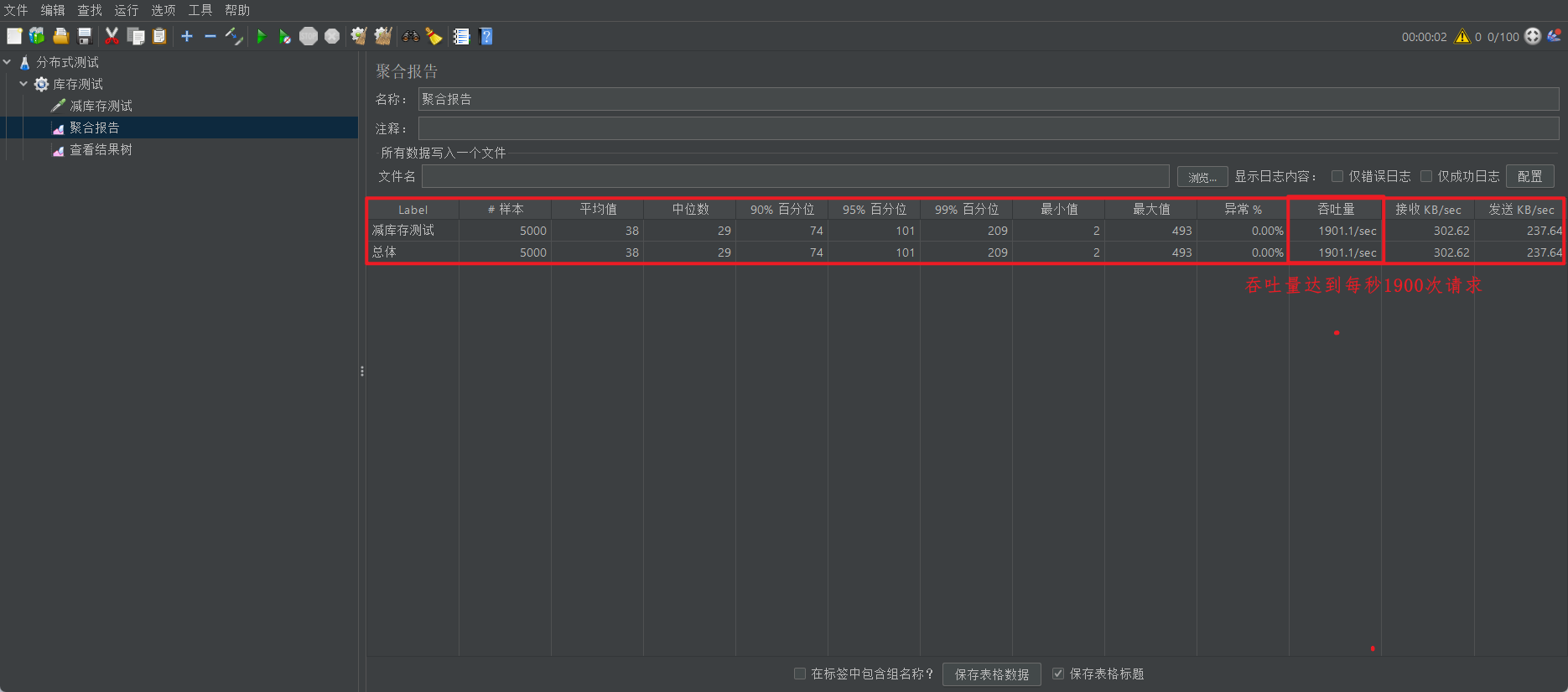
查看聚合报告,样本数量为 5000 次,吞吐量为 1900个事务/秒 左右。
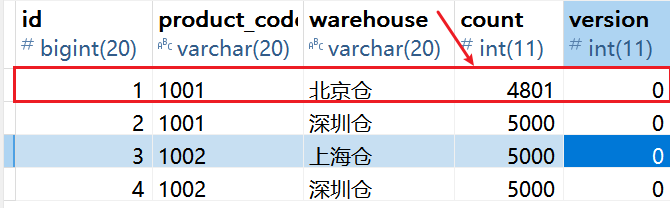
3. 查看项目日志:发生超卖现象。
此时查看 MySQL 表中的 1001 商品编号的第一条记录,校验库存数量是否为0:
2.2 基于 synchronized 加锁访问
1. 修改减库存的方法,进行加锁操作:synchronized 直接修改方法(底层是基于 Monitor 实现)