Kubernetes 集群优化实战手册:从零到生产级性能调优
一、硬件资源优化策略
1. 节点选型黄金法则
# 生产环境常见节点规格(AWS示例)
- 常规计算型:m5.xlarge (4vCPU 16GB)
- 内存优化型:r5.2xlarge (8vCPU 64GB)
- GPU加速型:p3.2xlarge (8vCPU + V100 GPU)
2. 自动扩缩容实战
# Cluster Autoscaler 配置示例(AWS EKS)
apiVersion: apps/v1
kind: Deployment
metadata:name: cluster-autoscaler
spec:template:spec:containers:- name: cluster-autoscalercommand:- ./cluster-autoscaler- --cloud-provider=aws- --node-group-auto-discovery=asg:tag=k8s.io/cluster-autoscaler/enabled,true- --scale-down-unneeded-time=10m # 缩容冷却时间
3. 存储选型对照表
| 场景 | 存储类型 | 延迟 | 适用工作负载 |
|---|---|---|---|
| 高频交易日志 | NVMe SSD | <1ms | Redis、Kafka |
| 大数据分析 | HDD 云存储 | 5-10ms | Spark、Hadoop |
| 容器临时存储 | 本地临时卷 | 极低 | CI/CD 构建任务 |
二、应用层优化技巧
1. 资源配额精准控制
# 生产级资源配额配置
apiVersion: v1
kind: ResourceQuota
metadata:name: prod-quota
spec:hard:requests.cpu: "20" # 总CPU请求不超过20核limits.memory: 100Gi # 总内存限制不超过100GBpods: "50" # 命名空间最多50个Pod
2. 智能扩缩容方案组合
以下是 HPA(Horizontal Pod Autoscaler)与 VPA(Vertical Pod Autoscaler)联动架构 的核心组件与工作流程的解析,结合两者的协同机制,构建一个完整的弹性伸缩体系:
1)架构图核心组件与流程
监控数据源
-
Metrics Server:收集集群中 Pod 的 CPU、内存等基础资源使用数据,供 HPA 和 VPA 使用。
-
Prometheus:通过自定义指标(如 QPS、请求延迟)扩展 HPA 的弹性策略,需搭配 Prometheus Adapter 将指标转换为 Kubernetes 可识别的格式。
-
VPA Recommender:分析历史资源使用数据,生成 Pod 的 CPU/内存推荐值,例如基于 TP90 分位数计算资源需求。
HPA 控制器
-
水平伸缩决策:根据实时指标(如 CPU 利用率、QPS)动态调整 Pod 副本数,计算公式为:
期望副本数 = ceil(当前副本数 × (当前指标值 / 目标指标值))。 -
多指标支持:可同时配置资源指标(CPU/内存)、自定义指标(如每秒请求数)和外部指标(如消息队列长度)。
VPA 控制器
-
Recommender:生成资源推荐值(如 CPU 和内存的请求与限制)。
-
Updater:驱逐需要调整资源的 Pod,触发 Pod 重建。
-
Admission Controller:在 Pod 重建时注入新的资源请求和限制到 Pod 配置中。
工作负载联动
-
Deployment/StatefulSet:受 HPA 和 VPA 共同管理的目标工作负载。
-
Pod 生命周期:VPA 调整资源需通过重建 Pod 实现(Kubernetes 不支持动态修改运行中的 Pod 资源)。
2)联动工作流程示例
+-------------------+ +---------------------+ +-------------------+ | 监控数据源 | | 控制器决策 | | 工作负载 | | - Metrics Server |<---->| - HPA: 调整副本数 |<---->| - Deployment | | - Prometheus | | - VPA: 调整资源请求 | | - StatefulSet | +-------------------+ +---------------------+ +-------------------+| ^v |+-----------------------+| Pod 重建与资源注入 || - VPA Updater 驱逐 Pod|| - Admission Controller|+-----------------------+
(图示说明:Horizontal Pod Autoscaler 负责横向扩展Pod数量,Vertical Pod Autoscaler 自动调整单个Pod资源)
监控与数据收集
-
Metrics Server 和 Prometheus 分别提供基础资源指标和业务指标。
-
VPA Recommender 分析历史资源使用模式,生成推荐值。
水平伸缩(HPA)
-
当流量激增时,HPA 根据指标(如 CPU 使用率超过阈值)触发扩容,增加 Pod 副本数。
垂直伸缩(VPA)
-
VPA 检测到单个 Pod 资源不足(如内存接近 Limit),Recommender 生成新资源值。
-
Updater 驱逐旧 Pod,触发控制器重建 Pod。
-
Admission Controller 在 Pod 创建时注入新的资源请求和限制。
联动策略与冲突管理
-
优先级:通常优先执行 HPA 扩容以快速应对流量,再通过 VPA 优化资源分配。
-
资源边界:为 VPA 设置
minAllowed和maxAllowed,避免资源调整过度影响 HPA 决策。
3)配置示例与注意事项
HPA 配置(支持多指标)
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
spec:metrics:- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 60- type: Podspods:metric:name: requests_per_secondtarget:type: AverageValueaverageValue: 100VPA 配置(限制资源范围)
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
spec:resourcePolicy:containerPolicies:- minAllowed:cpu: "100m"memory: "512Mi"maxAllowed:cpu: "2"memory: "8Gi"注意事项
稳定性风险:VPA 的
Auto模式可能导致 Pod 频繁重启,生产环境建议结合UpdateMode: Off手动审核推荐值。指标冲突:避免 HPA 和 VPA 同时依赖同一资源指标(如 CPU),可能引发决策冲突。
适用场景
-
突发流量场景:HPA 快速扩容应对流量高峰,VPA 优化每个 Pod 的资源分配。
-
资源敏感型应用:如数据库服务,VPA 动态调整内存限制防止 OOM,HPA 确保服务可用性。
通过联动 HPA 和 VPA,可实现 资源利用率最大化 与 服务稳定性 的平衡,但需谨慎设计策略以避免副作用。具体实现可参考 Kubernetes 官方文档及社区最佳实践。
3. 镜像优化三板斧
# 高效Dockerfile示例
FROM alpine:3.15 as builder
RUN build-your-app-hereFROM gcr.io/distroless/static:nonroot # 使用极简运行时镜像
COPY --from=builder /app/bin /app
USER 65534:65534 # 非root用户运行
三、架构设计进阶
1. 服务网格性能优化
# Istio 性能调参示例(values.yaml)
global:proxy:resources:requests:cpu: 100mmemory: 128Miconcurrency: 2 # 调整Sidecar线程数meshConfig:defaultConfig:holdApplicationUntilProxyStarts: true # 确保代理就绪
2. 存储架构设计模式
# 高性能本地存储方案(OpenEBS示例)
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: openebs-device
provisioner: openebs.io/local
parameters:storageType: "device"fstype: "xfs"
3. 网络拓扑优化方案
# Calico 网络策略优化
apiVersion: projectcalico.org/v3
kind: BGPConfiguration
metadata:name: default
spec:logSeverityScreen: InfonodeToNodeMeshEnabled: true # 启用全节点互联asNumber: 64512
四、生产环境硬核调优
1. etcd 性能调优指南
# etcd 关键参数配置
ETCD_HEARTBEAT_INTERVAL=500 # 心跳间隔(ms)
ETCD_ELECTION_TIMEOUT=5000 # 选举超时(ms)
ETCD_SNAPSHOT_COUNT=10000 # 快照阈值
ETCD_MAX_REQUEST_BYTES=1572864 # 最大请求大小(1.5MB)
2. Kubelet 参数黄金配置
# /var/lib/kubelet/config.yaml 关键配置
cpuManagerPolicy: static # 启用CPU绑核
topologyManagerPolicy: best-effort
evictionHard:memory.available: "500Mi"nodefs.available: "10%"
kubeReserved:cpu: "500m"memory: "1Gi"
3. 内核参数调优清单
# /etc/sysctl.conf 生产建议值
net.core.somaxconn=32768
net.ipv4.tcp_tw_reuse=1
fs.file-max=2097152
vm.swappiness=10
五、成本控制实战技巧
1. 资源利用率分析工具链
# 使用kube-cost进行成本分析
kubectl port-forward -n kubecost deployment/kubecost-cost-analyzer 9090
# 访问 http://localhost:9090 查看成本分布
2. 实例类型优化策略
| 负载特征 | 推荐实例类型 | 成本节约比例 |
|---|---|---|
| 定时批处理任务 | 竞价实例 | 最高70% |
| 长期稳定负载 | 预留实例 | 40-60% |
| 突发流量 | 自动扩缩容+按需 | 20-30% |
3. 闲置资源回收方案
# 自动清理失败Job的CronJob
apiVersion: batch/v1beta1
kind: CronJob
metadata:name: clean-failed-jobs
spec:schedule: "0 3 * * *"jobTemplate:spec:template:spec:containers:- name: cleanerimage: bitnami/kubectlcommand: ["sh", "-c", "kubectl delete jobs --field-selector status.successful=0"]
六、安全加固必做清单
1. 零信任网络架构
# 全拒绝默认策略
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:name: default-deny-all
spec:podSelector: {}policyTypes:- Ingress- Egress
2. 运行时安全监控
# 使用Falco检测异常行为
falcoctl install --set driver.kind=ebpf # 无内核模块安装
kubectl logs -f daemonset/falco -n falco
3. 密钥管理最佳实践
# 使用External Secrets Operator
apiVersion: external-secrets.io/v1beta1
kind: ExternalSecret
metadata:name: db-credentials
spec:refreshInterval: 1hsecretStoreRef:name: aws-secret-managerkind: SecretStoretarget:name: production-db-secretdata:- secretKey: passwordremoteRef:key: /prod/databaseproperty: password
七、可视化监控体系搭建
1. 核心监控指标看板
包含:
- 节点资源利用率
- Pod重启次数
- API延迟百分位
- 存储IOPS等关键指标
2. 告警规则示例
# Prometheus 关键告警规则
- alert: HighPodRestartRateexpr: rate(kube_pod_container_status_restarts_total[5m]) > 0.5for: 10mlabels:severity: criticalannotations:summary: "Pod频繁重启 ({{ $labels.pod }})"
3. 日志收集架构
# EFK 日志方案组件
Fluentd(收集) -> Kafka(缓冲) -> Elasticsearch(存储) -> Kibana(展示)
总结建议
1)性能调优优先级
网络优化 > 存储IO优化 > 资源利用率提升 > 成本优化
2)必装工具清单
- 监控:Prometheus + Grafana
- 日志:Loki + Grafana
- 安全:Falco + Trivy
- 成本:kube-cost + Kubecost
3)优化迭代流程
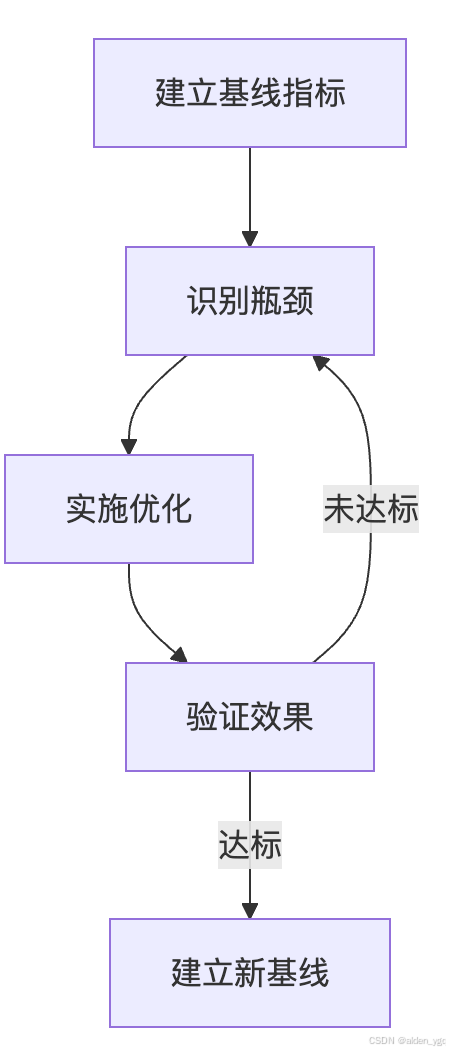
通过系统化的优化策略,结合持续监控和迭代改进,可使Kubernetes集群在生产环境中实现最佳的性能、安全性和成本效益平衡。