推测式思维树:让大模型快速完成复杂推理
论文标题
Accelerating Large Language Model Reasoning via Speculative Search
论文地址
https://www.arxiv.org/pdf/2505.02865
作者背景
中科大,华为诺亚方舟实验室,天津大学
ICML 2025接收
动机
之前介绍过多篇投机解码(推测式解码)的相关工作
大模型推理加速:EAGLE-3介绍
大模型推理加速:自适应早退与动态投机长度
大模型推理加速: 使用多个异构的小模型加快投机解码
而本文试图将“小模型草稿-大模型验证”的思路应用到长思考推理中
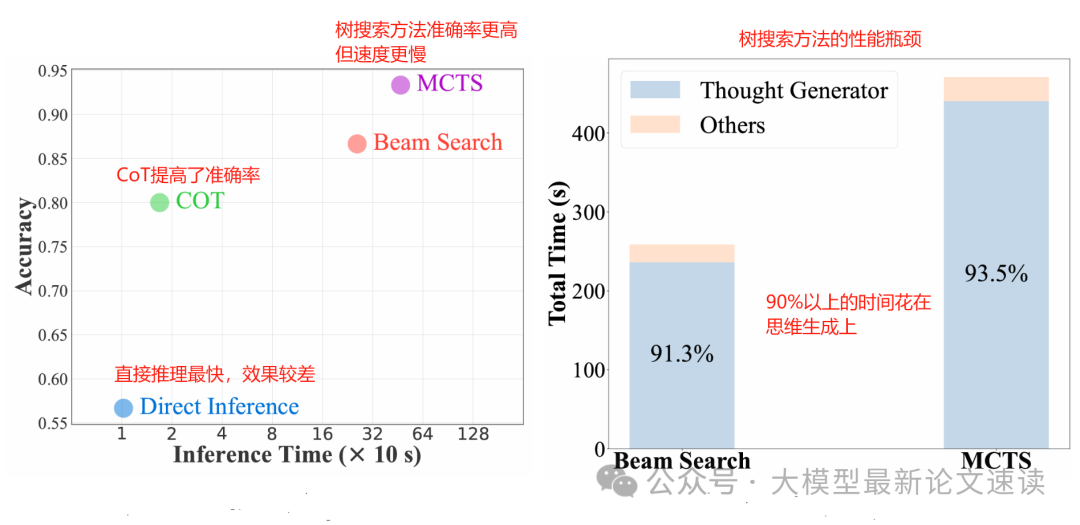
相较于CoT,树形搜索(如BeamSearch、MCTS)可以更加充分地考虑多种可能的情况,从而提供更加深思熟虑后的回答,但它们需要大量的中间推理步骤,时间开销、token消耗极大
实际上在复杂问题的多步推理中,不同步骤的难度差异明显:部分步骤相对简单,小模型也能给出高质量结果;而另一些步骤复杂,需要强大的模型才能正确解决。
例如,计算“99²+99+1”包含99²(较难)和99+1(较易)两个子步骤
于是我们完全可以借助投机解码的思想,先使用小模型快速输出各种思路的草稿,然后再利用大模型并行地验证,从而降低时间与计算资源的消耗
面临挑战
原始的投机解码方法难以直接用于复杂推理,主要是由于以下两方面的局限性:
- 它只是token级加速方案,无法同时探索多条推理路径,无法减少多分支推理的总体步骤数
- 它只关注局部token的一致性,并不能确保全局逻辑正确。小模型可能提出在语义上看似合理但逻辑上错误的步骤,即使大模型概率上接受了这些token,最后推理结果可能偏离正确答案
本文方法
本文提出Speculative Search(投机搜索,or推测式搜索),让小模型和大模型在思路级(粗粒度)和token级(细粒度)两个层面协作,采用“起草-评估-拒绝-纠正”的推理生成步骤,在保证质量的前提下显著提升了推理速度
SpecSearch的核心思想是:由小模型快速起草多个中间推理步骤候选,利用验证模型评估筛选其质量,仅当小模型候选不达标时才调用大模型纠正,并动态调整策略以保持与大模型单独推理的质量一致
1.草稿阶段: 先由一个较小且快速的模型 Gq 根据当前已有的思路序列,批量快速生成N个下一步思路候选
2.评估阶段: 使用一个验证模型 Verifier 对每个候选思路进行质量评分(类似于过程奖励模型),预测该中间步骤的“有用性”或正确性分数。同时,根据大模型的历史表现设定一个动态阈值 β,如果候选评分高于β,则认为这个思路质量达标,可以接受;反之则拒绝
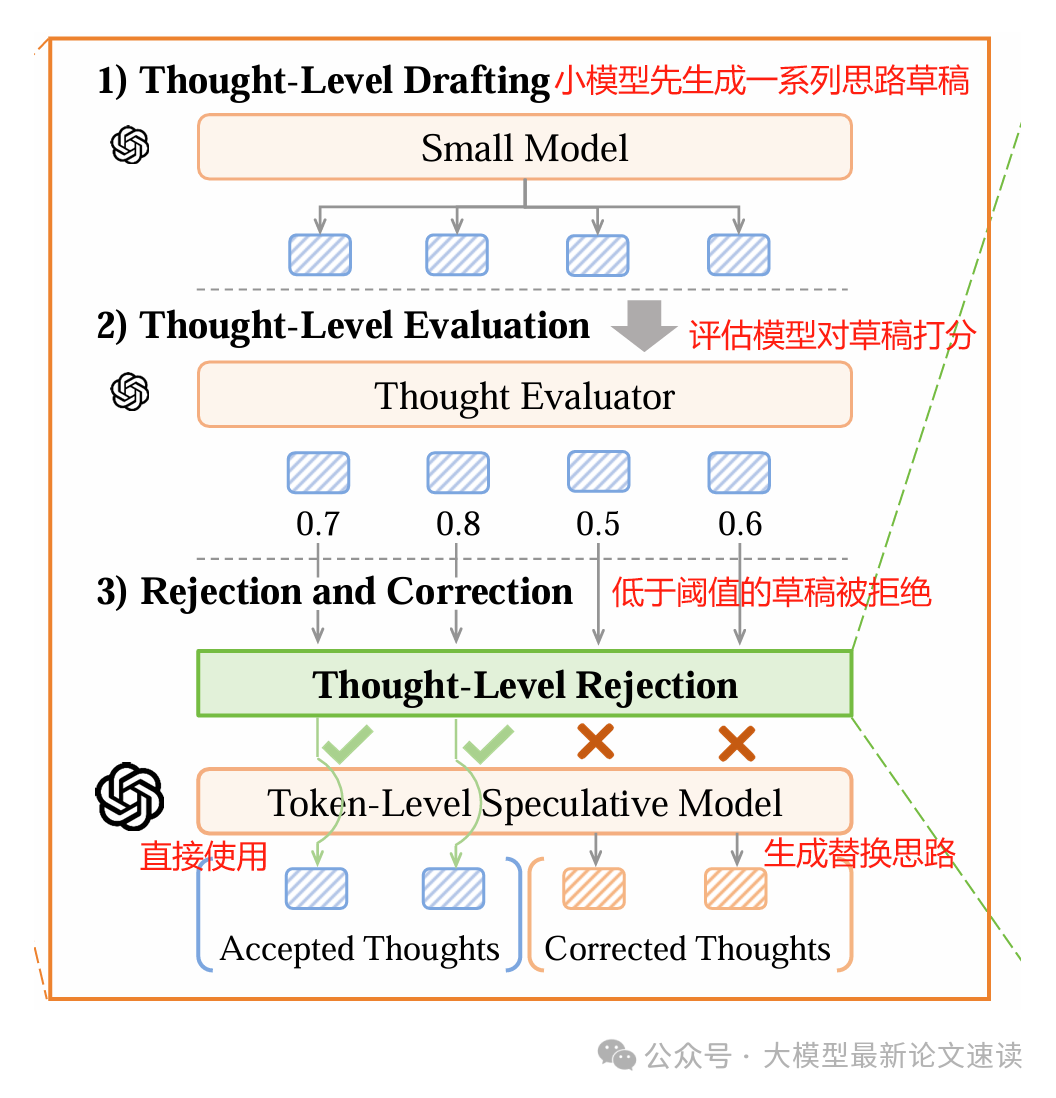
3.纠正阶段: 对于被筛掉的候选思路,SpecSearch采用大模型 Gp来生成该步骤的替代思路。为避免大模型逐字慢速输出,这里同时应用了投机解码来加速,即由小模型Gq 打草稿,大模型Gp 来验证,从而快速得到替代结果
4.动态更新阈值: 由于推理步骤的难度存在变化,SpecSearch会动态调整接受阈值 β。具体地,利用刚才那些由大模型产生的“纠正思路”的评分数据,采用统计方法(如指数移动平均)估计大模型在当前阶段的输出质量。比如随着推理深入,大模型的思路质量可能会下降,此时阈值也应下调
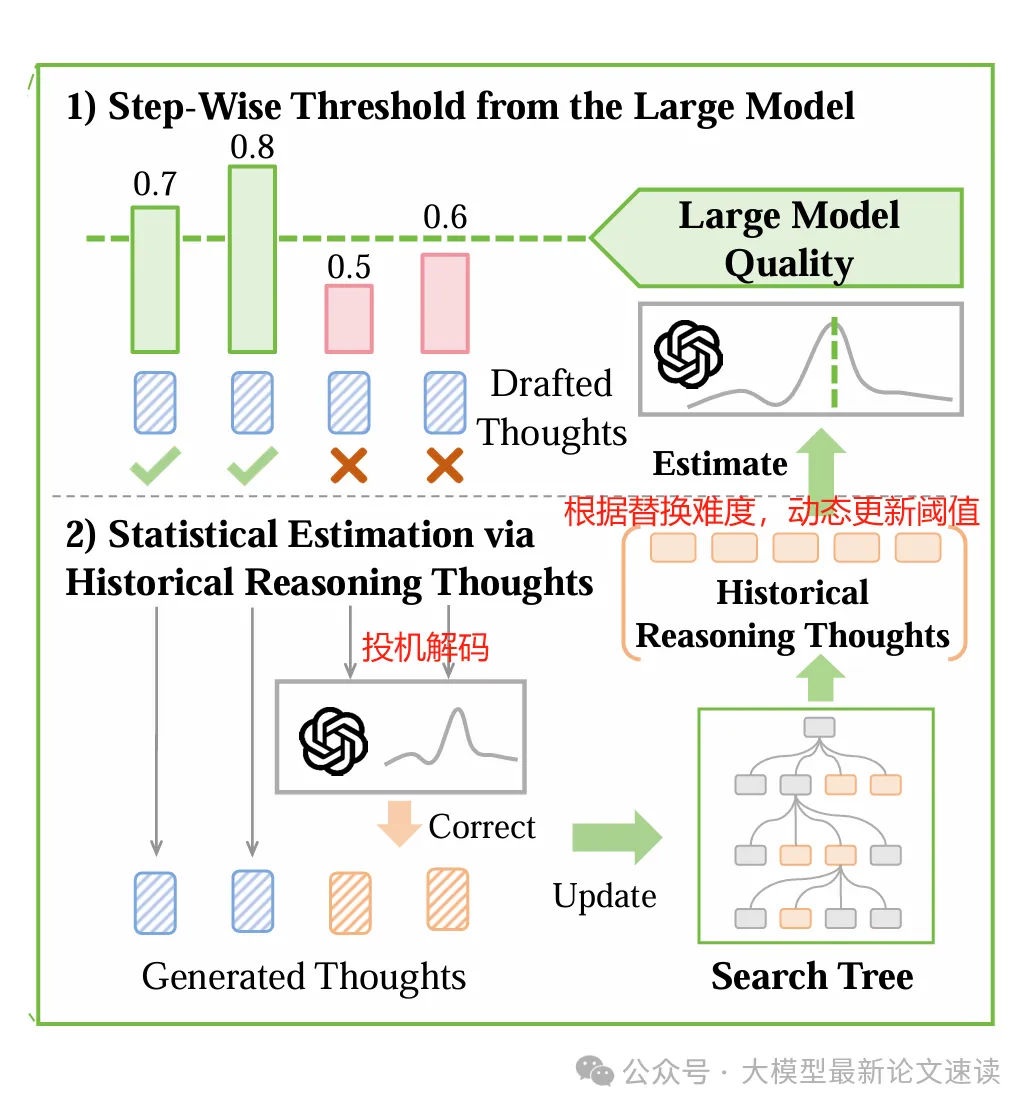
5.循环搜索: 以上过程在每个推理步骤重复进行。被接受和纠正的思路一起组成当前步骤可能的扩展节点,然后使用常规的搜索算法(如Beam Search或MCTS)决定下一步要扩展哪些节点,继续让小模型起草候选…如此迭代,直到找到完整的解答路径或达到终止条件
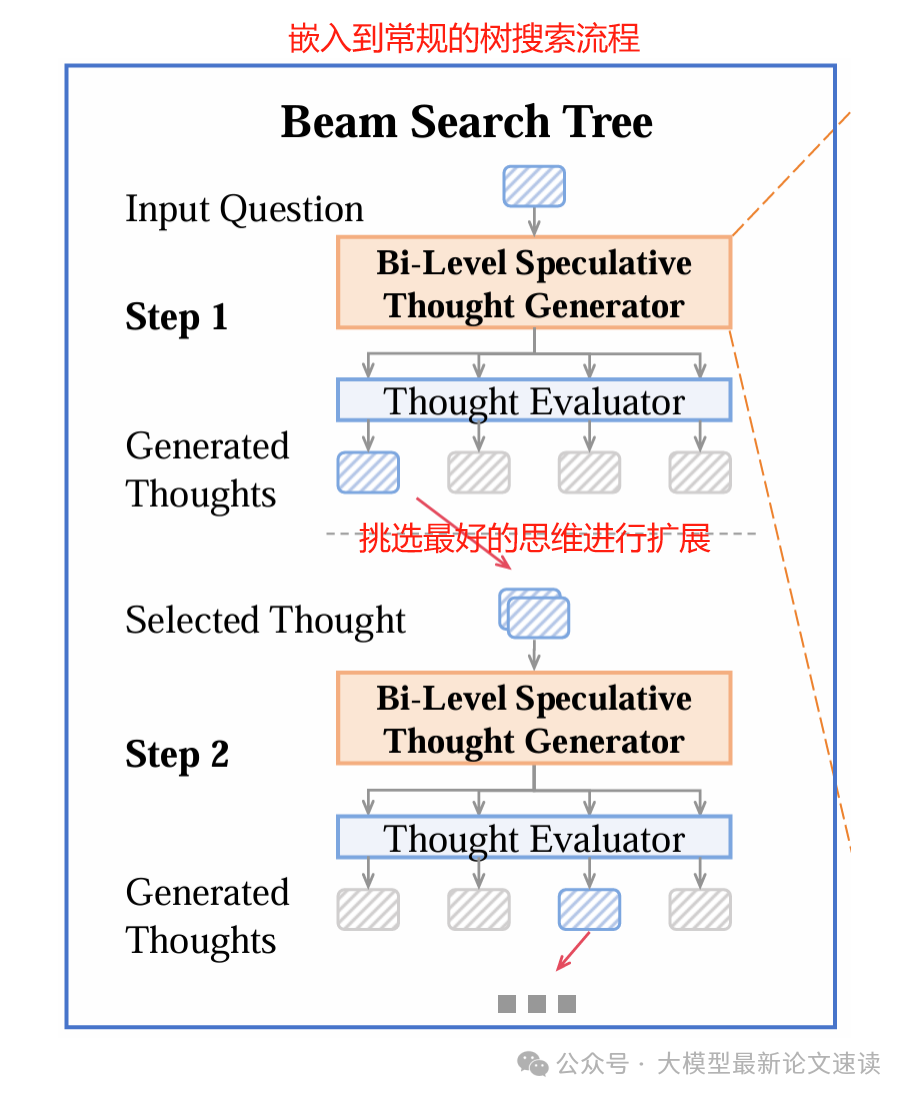
可见SpecSearch作为搜索树的节点扩展模块,能够无缝嵌入各种推理算法,并且保证了质量无损:每一步进入搜索树的思路,要么来自小模型且通过了质量门槛,要么干脆由大模型产生,因而不会比大模型原本输出的质量更差。如果阈值设置准确,最终的解答路径质量将与纯大模型搜索相当(论文对此进行了理论证明)
实验结果
作者主要在数学问题集MATH和小学数学词题集GSM8K上验证了Speculative Search的效果,主要结论如下:
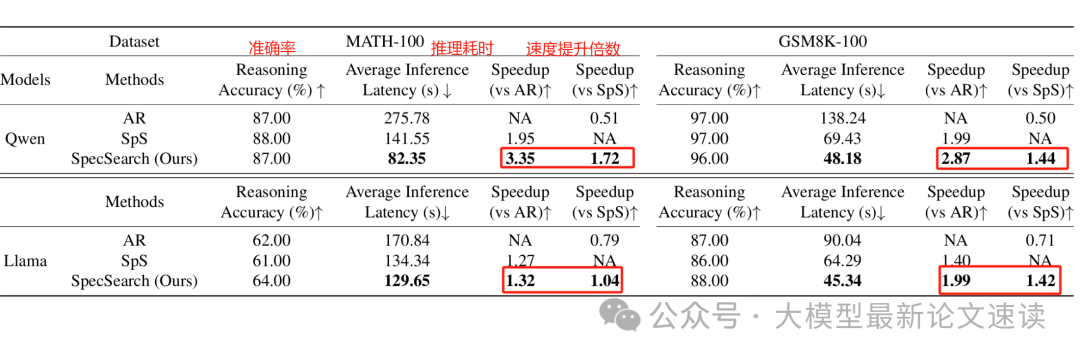
可见此方法能在保证任务效果不下降的前提下,大幅提高推理速度
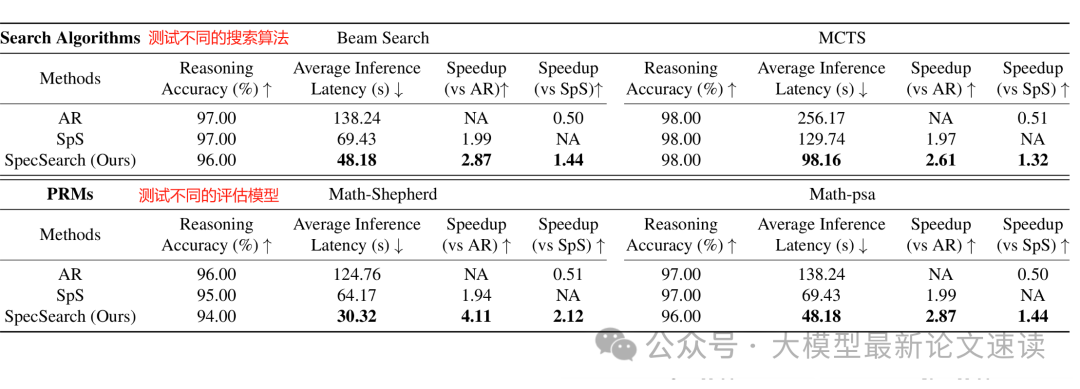
SpecSearch还具有良好的鲁棒性,在更换不同的搜索方法、评估模型时,均是在保持准确性的前提下大幅提高推理速度
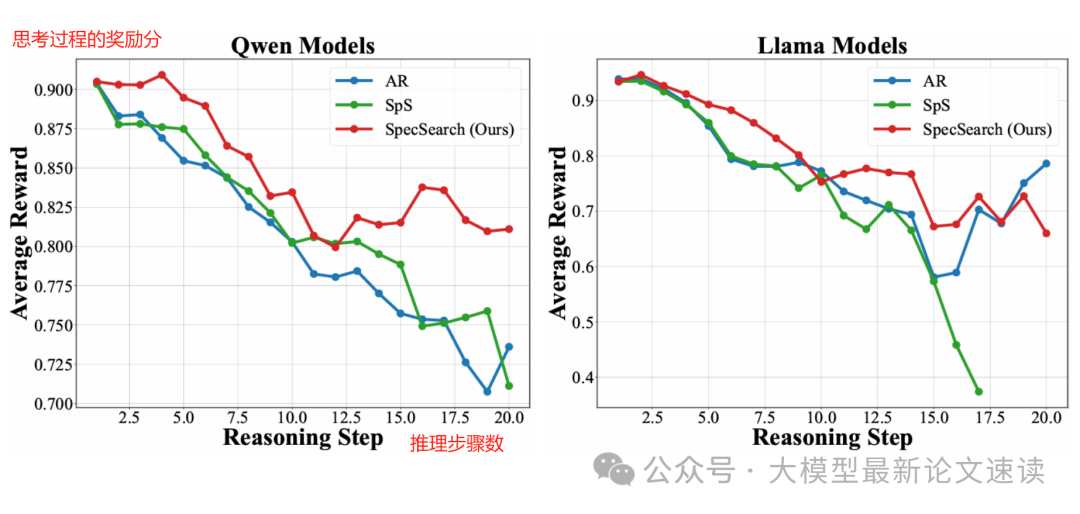
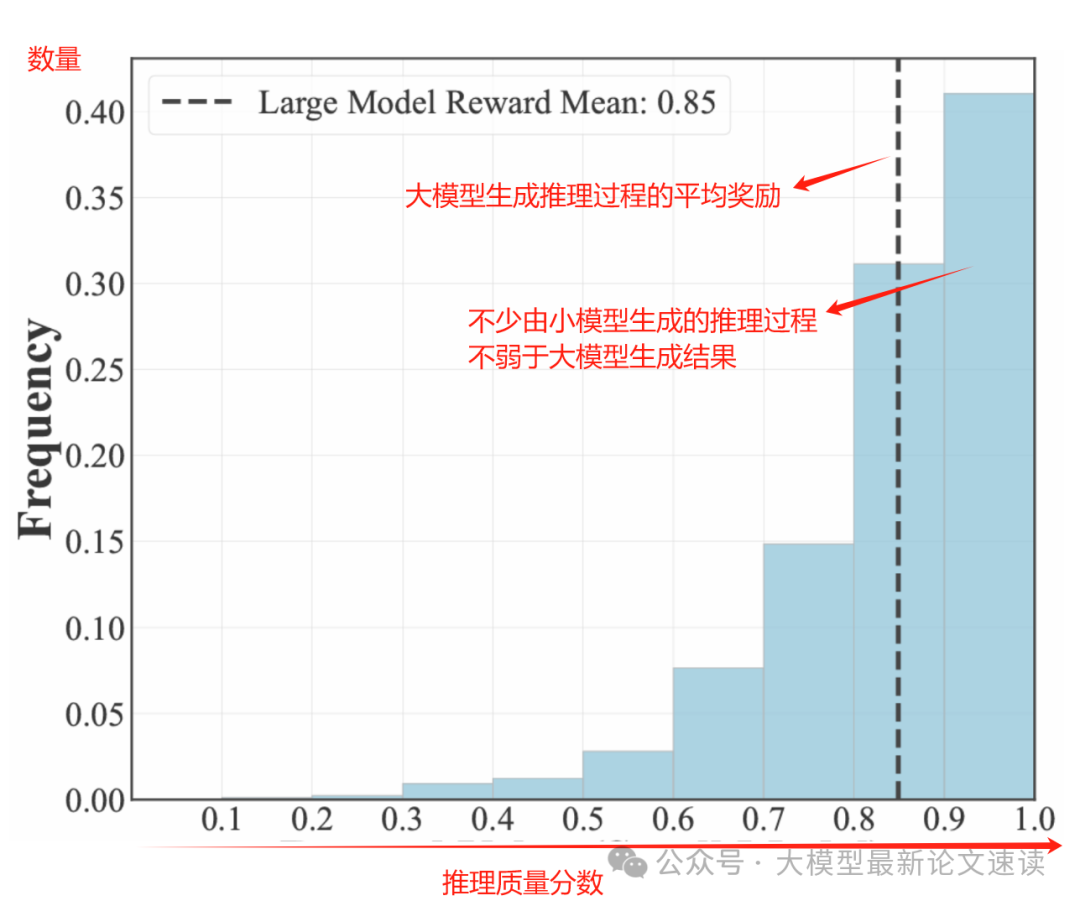
除了结果的准确性,从推理过程的奖励变化可见,SpecSearch的推理过程明显更加准确合理