RSS 2025|斯坦福提出「统一视频行动模型UVA」:实现机器人高精度动作推理
导读
在机器人领域,让机器人像人类一样理解视觉信息并做出精准行动,一直是科研人员努力的方向。今天,我们要探讨的统一视频行动模型(Unified Video Action Model,UVA),就像给机器人装上了一个“超级大脑”,为实现这一目标带来了新的突破。
©️【深蓝AI】编译
论文题目:Unified Video Action Model
论文作者:Shuang Li, Yihuai Gao, Dorsa Sadigh, Shuran Song
论文地址:https://arxiv.org/pdf/2503.00200
项目地址:https://unified-video-action-model.github.io/
一、UVA诞生的“前因后果”
以往的机器人研究中,视频生成和行动预测的“配合”总是不太默契。行动建模追求捕捉精细动作的高时间速度,视频生成则侧重于高空间分辨率以输出逼真视觉效果,这导致两者难以平衡,处理速度也受到影响。
传统的策略学习方法往往顾此失彼。只关注行动的方法,像跳过视频生成的那些,虽然计算简单,但错失了视频带来的场景动态信息,容易过度依赖行动历史,在面对视觉干扰时就“露怯”了。而先生成视频再预测行动的方法,速度慢不说,视频生成的误差还会“传染”到行动预测中。
为了解决这些难题,UVA应运而生。它就像一位“协调大师”,致力于同时处理视频和行动信息,精准把握视觉与行动之间的潜在联系,让机器人在理解任务时更加“聪明”,还能在推理时快速做出行动预测。
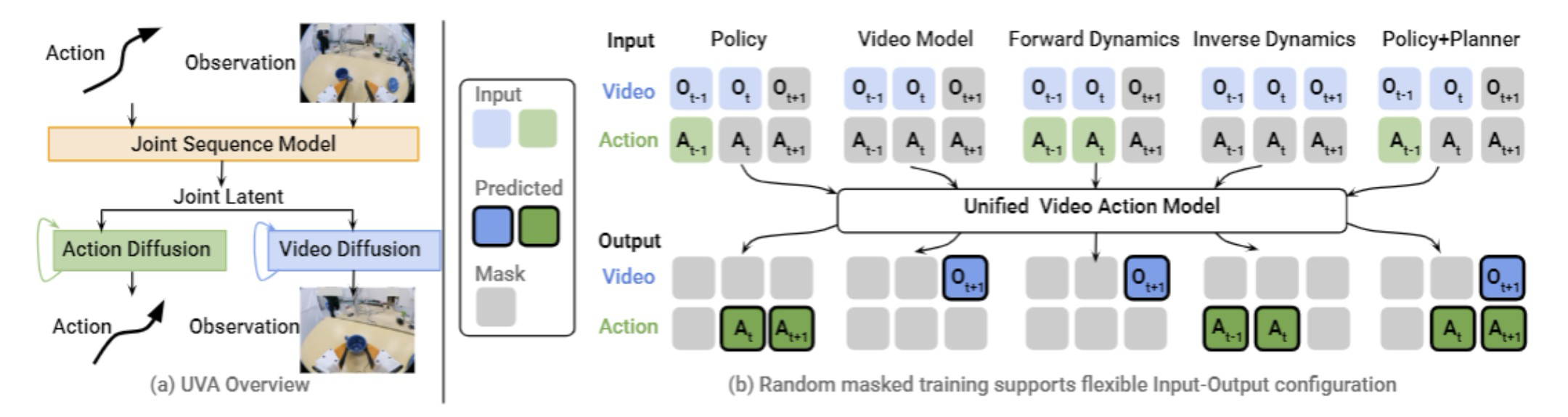
图1 | 统一视频行动模型
二、UVA的“智慧核心”
(一)统一潜在视频 - 行动表示
UVA采用统一的潜在表示,将视觉和行动数据“融合”在一起。和传统分层生成视频和行动的策略方法不同,UVA在训练时同时接受视频和行动数据的监督。这使得它能够以较低的计算成本,捕捉到视觉和行动领域之间复杂的动态关系。通过潜在表示中丰富的场景信息,UVA在理解复杂环境和做出精准行动预测方面表现出色。
(二)解耦视频 - 行动扩散以实现快速推理
为了提升效率,UVA把视频生成和行动预测“分开处理”。训练时,它用两个轻量级扩散头从统一的潜在空间中解码视频观察和行动;推理时,直接利用潜在表示进行快速行动预测,跳过视频生成这一步骤。这样既保留了训练中学习到的丰富信息,又能像只关注行动的方法一样快速推理,实现了实时策略部署。
(三)掩码训练增加灵活性
UVA通过掩码训练解锁了多种功能。它可以根据不同任务的需求,灵活地掩盖输入和输出。比如,在只有图像观察时,它能像逆动力学模型一样从视频中生成行动标签。这种训练方式不仅充分利用了各种数据组合,还能防止模型过度适应特定任务,增强了模型的通用性和鲁棒性。
三、UVA的“多面手”能力
(一)作为策略模型的出色表现
在策略学习方面,UVA在多种任务场景中都展现出了强大的实力。在模拟环境的单任务评估中,它能与最先进的Diffusion Policy(DP - C)模型媲美,在多任务评估中更是表现卓越。以PushT - M任务为例,UVA的成功率比最好的基线方法高出20%,在Libero10基准测试中也高出5%。
在真实世界的任务中,UVA同样表现出色。虽然在单任务设置下,它的表现与针对特定数据集优化的DP - UMI相近,但在多任务设置下,UVA的优势就凸显出来了。在杯子排列、毛巾折叠和鼠标排列等任务中,UVA的成功率比DP - UMI更高。而且,UVA在处理视觉干扰、适应不同历史长度输入方面也有很好的表现,充分证明了联合视频 - 行动建模的重要性。
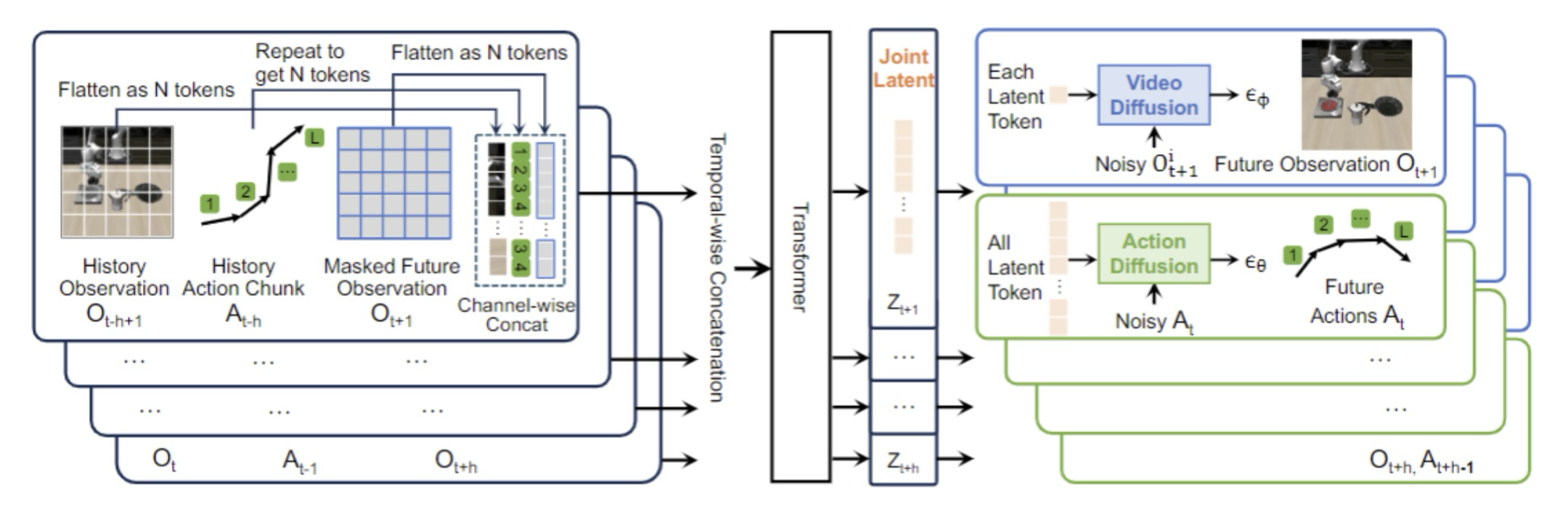
图2 | 网络架构
(二)作为视频生成器的优秀成果
UVA在视频生成方面也毫不逊色。通过掩码自动编码器训练,它能够以自回归的方式生成视频。与UniPi相比,UVA生成的视频质量更高。在Libero10和杯子排列数据集上,UVA生成视频的Fréchet Video Distance(FVD)得分更低,这意味着它生成的视频在视觉保真度和时间连贯性上表现更好。即使只进行一步自回归生成,UVA在杯子排列任务上的表现也优于UniPi,增加生成步数后效果更优。
(三)作为前向动力学模型的显著成效
UVA还能作为前向动力学模型,指导预训练策略模型的行为。在块推动任务中,UVA可以根据历史观察和采样的行动预测未来观察,帮助策略模型选择更好的行动轨迹。实验表明,借助UVA的指导,预训练策略模型DP - C的成功率从38% 提升到了60%,虽然比不上使用真实模拟器,但也极大地提高了任务完成的成功率。
图3 | 模拟环境
(四)作为逆动力学模型的可靠性能
在逆动力学方面,UVA同样表现出了良好的性能。以UMI杯子排列数据为例,UVA预测的行动与真实行动的误差较小。与UniPi的逆动力学模型相比,UVA预测的行动更加连贯;与视觉惯性SLAM系统相比,虽然UVA的误差略高,但仍在可接受范围内,并且具有更好的泛化能力,有望成为难以校准且失败率高的SLAM的替代方案。
四、UVA的“现在”与“未来”
UVA的出现,为机器人领域带来了新的希望。它能够充分利用视频数据进行监督,在推理时快速预测行动,还具备多种功能,在多任务学习等方面表现出色。不过,UVA也并非完美无缺。目前,它还没有充分利用大量无行动视频数据,这使得它在一些真实世界任务中的表现与DP - UMI相当。
展望未来,研究人员计划在大规模网络视频数据集上对UVA进行预训练,以增强其泛化能力。此外,通过添加更多的扩散头,UVA有望预测声音、力等更多模态,成为一个更全面、更通用的框架。
统一视频行动模型UVA为机器人的发展开辟了新的道路。随着技术的不断进步,相信UVA将不断完善,让机器人在更多领域发挥重要作用,为我们的生活带来更多便利和惊喜。让我们一起期待UVA在未来创造更多的可能!