浙大与哈佛联合开源图像编辑模型IC-Edit,实现高效、精准、快速的指令编辑~
项目背景
研究动机与目标
ICEdit(In-Context Edit)由浙江大学团队开发,旨在通过自然语言指令实现高效、精准的图像编辑,降低对大规模训练数据和计算资源的需求。传统图像编辑方法(如基于微调的扩散模型或无训练技术)面临以下问题:
-
微调方法:需要大量数据(数百万张图像)和计算资源(高性能 GPU),成本高且耗时。
-
无训练技术:指令理解能力有限,编辑质量不稳定,尤其在复杂任务中。
ICEdit 提出了一种新的范式,通过结合上下文生成和高效参数适配,实现在极少数据(50K 张图像,0.1%)和参数(200M,1%)的情况下达到 state-of-the-art(SOTA)性能。其目标是提供一个开源、低成本、高效的图像编辑工具,适用于学术研究和非商业应用。

技术背景
ICEdit 基于扩散变换器(Diffusion Transformer, DiT),这是近年来生成模型领域的重要进展。DiT 相较传统 U-Net 架构具有更强的生成能力和上下文感知能力,特别适合处理复杂指令。项目还受到 Flux.1 模型的启发,Flux.1 是一个高性能的开源扩散模型,广泛用于图像生成和编辑。ICEdit 在此基础上引入上下文生成(in-context generation),通过提示驱动模型理解和执行编辑任务,无需修改底层架构。
模型结构
基础模型:Flux.1
ICEdit 基于 Flux.1 系列模型(具体为 Flux.1-fill-dev),这是一个开源的高性能扩散模型,结合了扩散过程和变换器架构。Flux.1 的优势在于:
-
生成能力: 支持高分辨率图像生成,细节保留良好。
-
上下文感知: 变换器架构增强了模型对复杂指令的理解。
-
灵活性: 可通过 LoRA 等技术进行轻量级微调,适配特定任务。
ICEdit 在 Flux.1 的基础上进行了优化,引入了上下文生成和高效适配策略,以支持指令-based图像编辑。
三大技术创新
ICEdit 的模型结构围绕以下三大创新构建,详细描述如下:
上下文编辑框架(In-Context Editing Framework)

-
核心思想: 利用上下文提示(in-context prompting)实现零样本指令遵循。模型通过输入图像和文本指令,在不修改底层架构的情况下理解编辑需求。
-
实现方式: 在推理时,模型接收图像和指令(如“Change her hair to dark green”),通过上下文生成机制直接生成编辑后的图像。这种方法避免了传统方法中对模型结构的重训练或大规模微调。
-
优势: 增强了模型对多样化指令的适应性,特别适合处理复杂或非标准编辑任务。
-
论文引用: “An in-context editing framework for zero-shot instruction compliance using in-context prompting, avoiding structural changes” [arXiv:2504.20690].
LoRA-MoE 混合调优策略(LoRA with Mixture-of-Experts)

-
核心思想: 结合低秩适配(LoRA)和专家混合(MoE)路由机制,通过动态激活任务特定专家实现高效适配。
-
LoRA 部分: LoRA 通过在预训练模型中添加低秩矩阵(占参数量约 1%),实现轻量级微调,降低计算和存储需求。ICEdit 使用 LoRA 适配 Flux.1 模型,仅需 200M 可训练参数。
-
MoE 部分: MoE 路由机制根据任务类型动态选择专家模块(如人物编辑专家、背景替换专家),提高模型在多样化任务中的性能。
-
实现细节: LoRA-MoE 混合策略在训练时仅更新少量参数(约 1%),并通过专家路由优化推理效率。训练数据仅 50K 张图像,远低于传统方法的数百万张。
-
优势: 高效适配、多任务支持、低资源需求。
-
论文引用: “A LoRA-MoE hybrid tuning strategy that enhances flexibility with efficient adaptation and dynamic expert routing, without extensive retraining” [arXiv:2504.20690].
早期过滤推理时缩放(Early Filter Inference-Time Scaling)
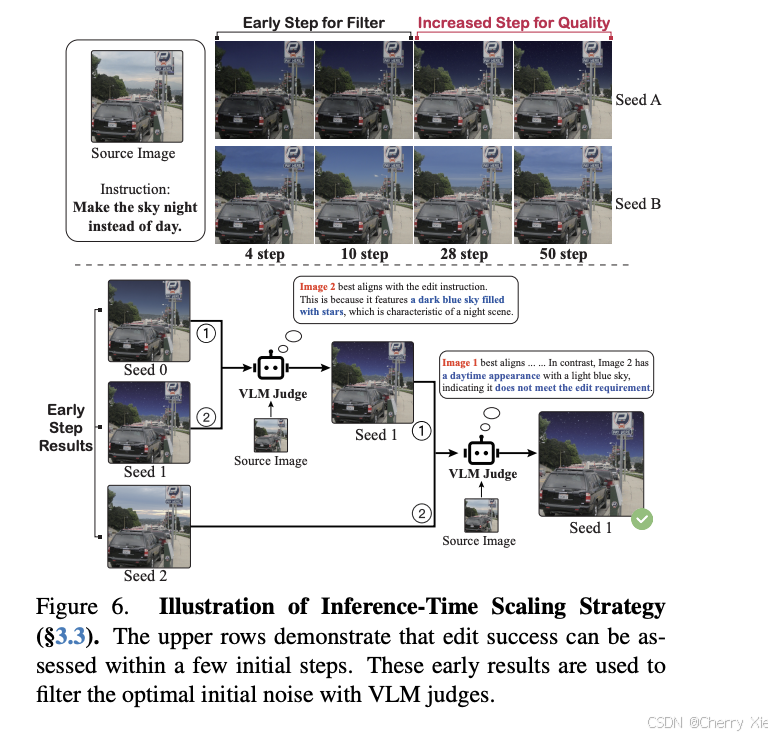
-
核心思想: 在推理初期使用视觉-语言模型(VLMs)选择更优的初始噪声,提升编辑质量和一致性。
-
实现方式: 扩散模型的推理过程从随机噪声开始,ICEdit 在早期阶段引入 VLM(如 CLIP 或类似模型)评估噪声质量,选择更接近目标编辑的初始噪声。这种方法提高了生成图像与指令的一致性。
-
优势: 显著改善编辑质量,尤其在细节保留(如人物 ID)和指令遵循方面。
-
论文引用: “An early filter inference-time scaling method using vision-language models (VLMs) to select better initial noise early, improving edit quality” [arXiv:2504.20690].
性能对比
详见技术报告

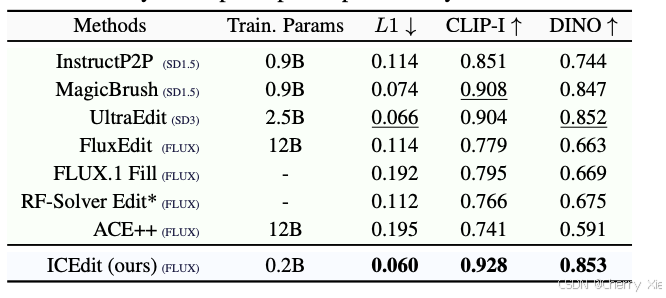
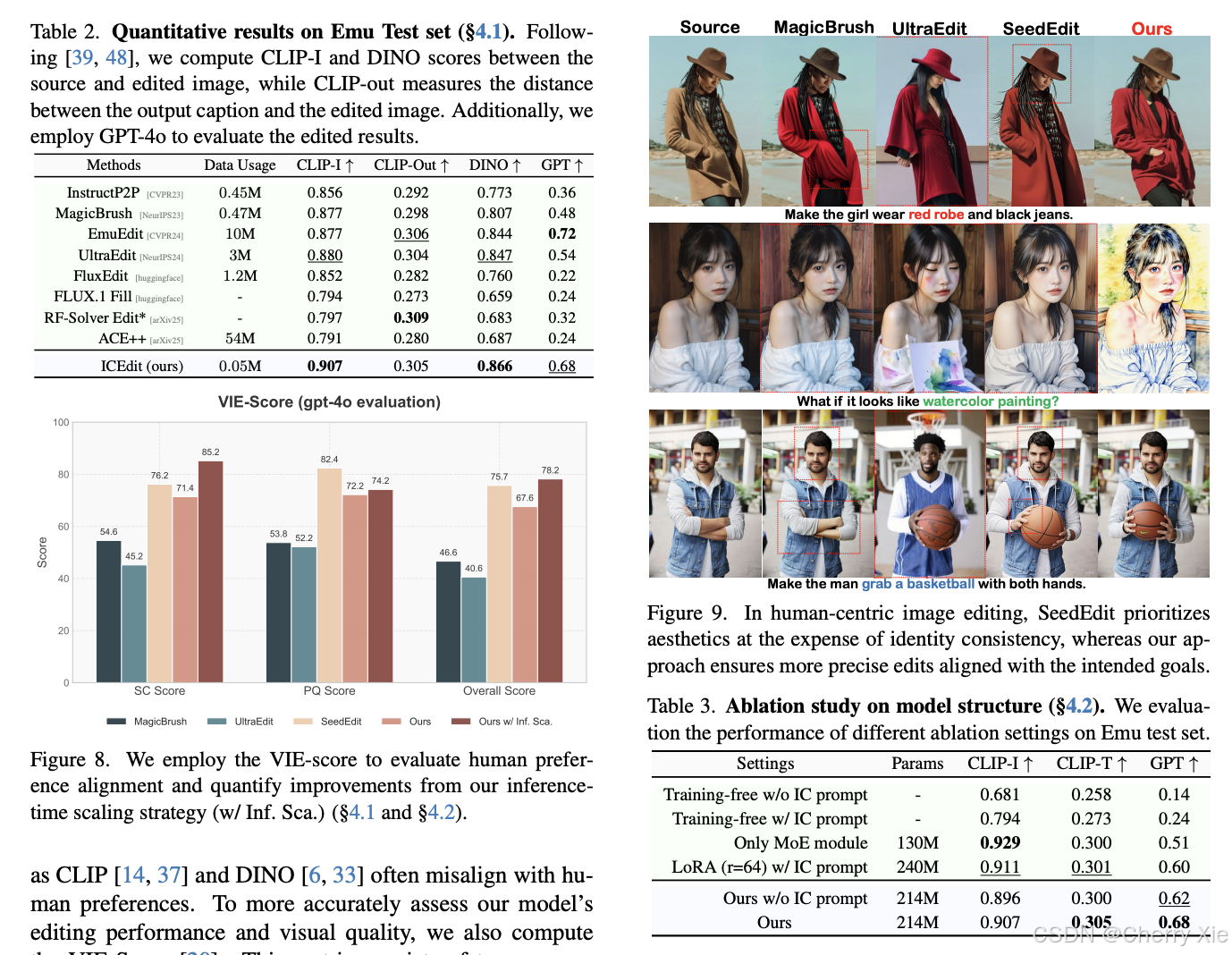
看看效果

相关文献
github地址:https://arxiv.org/pdf/2504.20690
模型下载:https://huggingface.co/RiverZ/normal-lora/tree/main
官方地址:https://river-zhang.github.io/ICEdit-gh-pages/
在线体验地址:https://huggingface.co/spaces/RiverZ/ICEdit