3、Kafka 核心架构拆解和总结
1. Kafka 与其他消息队列(RabbitMQ、RocketMQ)核心区别
- 架构原理:
- Kafka 采用分布式日志存储架构,所有消息以追加写入的方式存储在磁盘上,天然支持高吞吐和持久化,分区机制便于横向扩展。
- RabbitMQ 基于 AMQP 协议,消息通过 Exchange 路由到 Queue,支持灵活的路由和消息确认机制,适合复杂业务解耦。
- RocketMQ 支持分布式事务、顺序消息、定时/延迟消息,采用长轮询拉取,强调高可用和事务一致性。
- 应用场景:
- Kafka 适合大数据日志采集、实时流处理、事件驱动架构、监控数据汇聚等高吞吐场景。
- RabbitMQ 适合微服务解耦、异步任务、短消息通知等对可靠性和灵活性要求高的场景。
- RocketMQ 适合金融、电商等对事务一致性和高并发有特殊要求的业务。
- 优缺点:
- Kafka 优势在于高吞吐、可扩展性强、生态完善,劣势是消息实时性略低、功能相对聚焦。
- RabbitMQ 优势在于协议标准、路由灵活,劣势是高并发下性能瓶颈明显。
- RocketMQ 优势在于事务、顺序、延迟消息,劣势是生态和社区活跃度略逊。
2. Kafka 日志段(LogSegment)设计
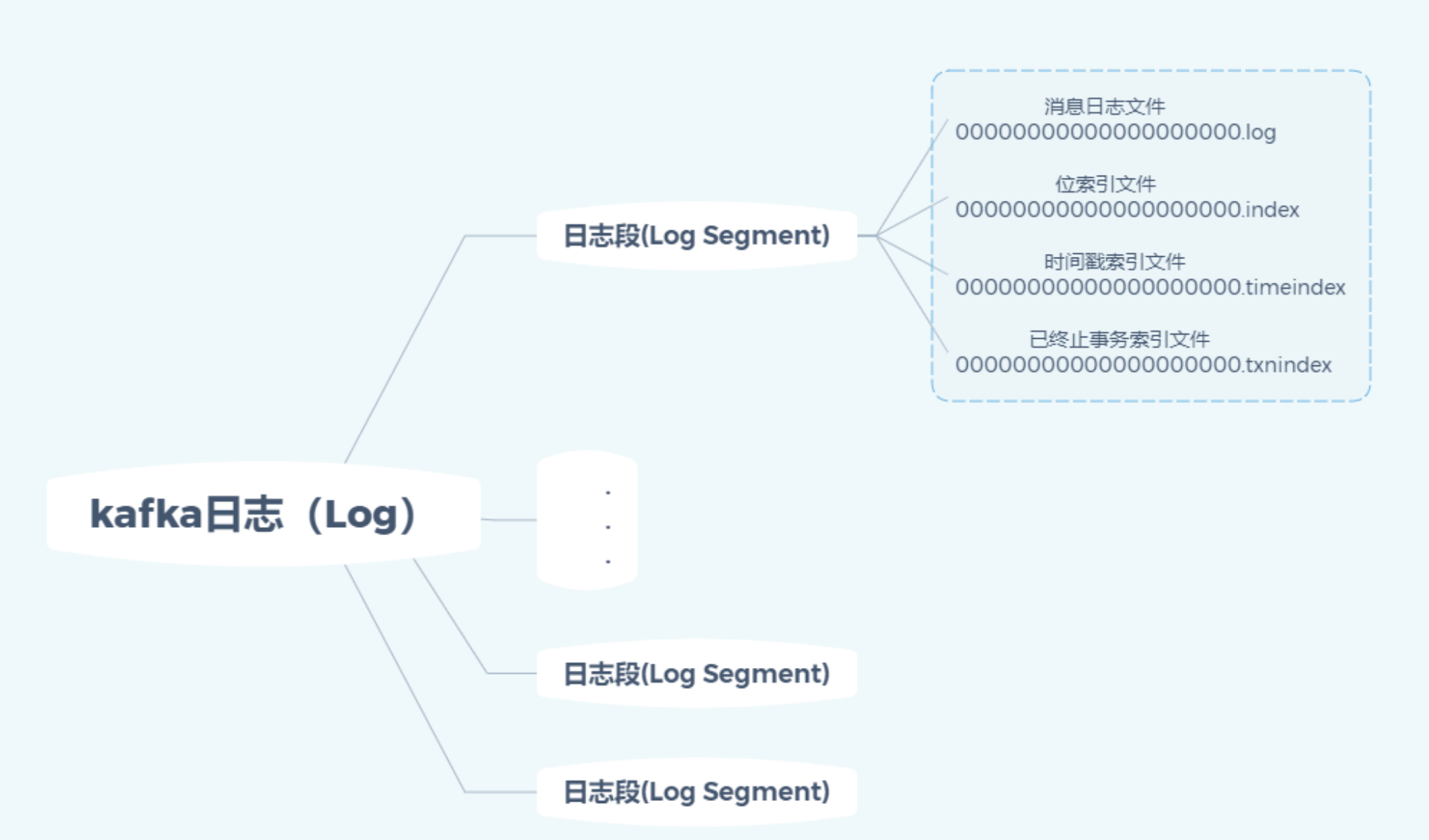
- 结构原理:
- 每个分区由多个 LogSegment 组成,每个 Segment 包含
.log(消息数据)、.index(偏移量索引)、.timeindex(时间戳索引)、.txnindex(事物索引文件)等文件。 .log文件顺序追加写入消息,.index文件加速 offset 定位,.timeindex支持按时间检索。
- 每个分区由多个 LogSegment 组成,每个 Segment 包含
- 机制与优势:
- 分段存储避免单文件过大,便于定期清理和高效查找。
- 旧 Segment 可直接删除或压缩,提升磁盘利用率。
- 配置建议:
- 通过
log.segment.bytes、log.retention.hours等参数灵活控制分段和保留策略。
- 通过
3. 时间轮(TimingWheel)算法
- 原理:
- Kafka 内部采用分层时间轮(TimingWheel)管理延迟任务,如副本同步超时、消息重试等。
- 每层时间轮由若干时间格(slot)组成,任务根据延迟时间被分配到不同层级和 slot。
- 机制与优势:
- 插入/删除任务时间复杂度 O(1),极大提升定时任务调度效率。
- 结合 DelayQueue 只推进非空 slot,减少无效轮询和 CPU 消耗。
- 应用场景:
- 适合毫秒到小时级的延迟任务,如请求超时、重试、定时消息等。
4. 消费者再平衡(Rebalance)机制
- 触发条件:
- 消费者组成员增减(如新消费者加入或退出)、订阅 Topic 变化、心跳超时(
session.timeout.ms)等。
- 消费者组成员增减(如新消费者加入或退出)、订阅 Topic 变化、心跳超时(
- 机制:
- Kafka 通过协调者(Coordinator)分配分区给各消费者,确保同一分区同一时刻只被一个消费者消费。
- 再平衡期间,所有消费者会暂停拉取,重新分配分区。
- 优化建议:
- 调整
max.poll.interval.ms、session.timeout.ms,避免因消费慢或心跳超时频繁触发 Rebalance。 - 使用静态分区分配(Static Membership)减少分区漂移。
- 调整
- 优缺点:
- 优点:保证分区消费唯一性,便于扩缩容。
- 缺点:频繁 Rebalance 会导致消费暂停,影响实时性。
5. 数据保留策略
- 原理:
- Kafka 支持按时间(
log.retention.hours)、大小(log.retention.bytes)、日志段(log.segment.bytes)等多种方式保留消息。
- Kafka 支持按时间(
- 机制与配置:
- 超过保留时间或空间的 Segment 会被自动删除或压缩(compact)。
- 日志类数据建议短保留,审计/合规类数据可设置长保留。
- 优缺点:
- 灵活应对不同业务需求,兼顾存储成本和数据可用性。
- 保留时间过长会占用大量磁盘,需结合磁盘容量合理配置。
6. 副本同步机制
- 原理:
- Kafka 采用 Leader-Follower 架构,Leader 负责所有读写,Follower 通过
fetch请求批量拉取 Leader 数据。 - Leader 维护 ISR(In-Sync Replicas)集合,只有 ISR 内副本同步后消息才算提交。
- Kafka 采用 Leader-Follower 架构,Leader 负责所有读写,Follower 通过
- 机制与优势:
- 零拷贝(sendfile)技术减少数据传输开销。
- Follower 落后过多会被移出 ISR,保证数据一致性。
- 配置建议:
replica.lag.time.max.ms控制最大同步延迟,min.insync.replicas保证高可用。
7. 消息压缩算法
- 支持算法:GZIP(高压缩率)、Snappy(低延迟)、LZ4(平衡压缩率与速度)。
- 原理与机制:
- Producer 端可通过
compression.type参数选择压缩算法,Broker 和 Consumer 自动解压。
- Producer 端可通过
- 选择建议:
- 网络带宽紧张优先高压缩率(GZIP),对延迟敏感优先低延迟(Snappy/LZ4)。
- 需权衡 CPU 占用和网络传输效率。
8. Producer异步/同步发送
- 异步发送:
- Producer 调用
send()方法异步提交消息,主线程不阻塞,适合高吞吐场景。 - 需通过回调函数处理发送异常。
- Producer 调用
- 同步发送:
- 调用
get()方法阻塞等待 Broker 确认,适合对可靠性要求极高的场景。
- 调用
- 可靠性保障:
- 设置
acks=all,确保所有 ISR 副本确认。 - 启用重试(
retries参数),防止网络抖动导致消息丢失。
- 设置
- 优缺点:
- 异步吞吐高但可靠性略低,需配合回调和幂等性。
- 同步可靠性高但吞吐低,适合关键业务。
9. Controller作用与选举
- 职责:
- 管理分区 Leader 选举、Broker 上下线、副本同步状态、元数据更新。
- 选举机制:
- 旧版依赖 ZooKeeper 临时节点,最先注册的 Broker 成为 Controller。
- 新版(KRaft 模式)采用内置 Raft 协议实现分布式共识,无需 ZooKeeper。
- 高可用保障:
- Controller 故障时自动重新选举,保证集群元数据一致性和高可用。
10. Kafka Streams API
- 核心思想:
- 以 Topic 为输入/输出流,支持有状态流处理(State Store)、窗口操作、Exactly-Once 语义。
- 机制与优势:
- 轻量级库,直接嵌入应用,无需独立集群。
- 支持流批一体、端到端一致性。
- 与 Flink/Spark Streaming 区别:
- Kafka Streams 适合轻量级 ETL、实时聚合,Flink/Spark 适合复杂流批处理和大规模数据分析。
Kafka 延迟消息能力补充
- Kafka 3.5+:原生支持延迟消息,最大延迟由
log.retention.ms决定,默认 7 天,可配置更长。 - 时间戳过滤:Producer 设置未来时间戳,Consumer 过滤未到期消息,理论无上限,受 Topic 保留策略影响。
- 时间轮算法:适合小时级以内短延迟,精度高,常用于内部定时任务、重试等。
- 外部工具:如 Flink、Kafka Connect 可实现更长延迟,理论无限制,适合复杂调度。
- 配置建议:根据业务需求权衡存储成本与延迟精度,合理设置
log.retention.ms和相关参数。
低延迟优化要点
- 生产者端:
- 合理设置
batch.size、linger.ms,批量发送提升吞吐同时兼顾延迟。 - 选择高效压缩算法(lz4/snappy),减少网络传输时间。
acks=1可降低延迟但牺牲可靠性,acks=all更安全但延迟略高。
- 合理设置
- 消费者端:
- 利用零拷贝拉取(sendfile),减少数据拷贝。
- 设置合适的
fetch.min.bytes、max.poll.records,减少网络往返。 - 优化心跳间隔(
session.timeout.ms、max.poll.interval.ms),避免频繁 Rebalance。
- 系统层面:
- 充分利用操作系统页缓存,保证顺序写入,提升磁盘和内存利用率。
- 合理规划分区数,提升并发处理能力。