分布式id的两大门派!时钟回拨问题的解决方案!
2.1 两大门派
目前业界的分布式ID实现路径归结起来有两派:一派以雪花算法为代表,不强依赖DB能力,只使用分布式节点自身信息(时间戳+节点ID+序列号)的编码生成唯一序列,好处是去中心化、无单点风险;另一派的思路是基于中心DB进行全局号段协调,具体做法是使用一个号段表给不同的节点分配号段从而实现分布式ID,二者的详细介绍如下。
*雪花算法*
生成的是Long类型的ID,一个Long类型占8个字节,每个字节占8比特,总共占64个比特,组成结构包括符号位(占1比特)+ 时间戳(占41比特)+ 节点ID(占10比特)+ 序列号(占12比特)。
符号位(1bit):Long的最高位是符号位代表正负,正数是0,负数是1,一般生成ID都为正数,所以默认为0。
时间戳(41bit):毫秒级的时间,一般不使用墙上时钟,而是用相对时间戳(当前时间戳 - 固定开始时间戳),可以使产生的ID从更小的值开始;例如41位的相对时间戳可以使用(1L << 41) / (1000606024365) = 69年。
节点ID(10bit):也被叫做WorkerId,可以灵活配置,机房或者机器ip组合都可以,是保证分布式ID在节点间唯一的关键因素。
序列号(12bit):自增值支持单位时间内同一个节点可以生成4096个ID。
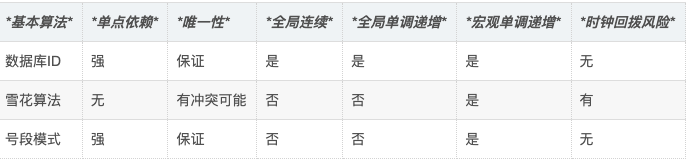
*优点:实现简单轻量,**不强依赖任何DB****,无单点风险***
*缺点:**节点ID只依赖于机器ip的话存在冲突****的****可能,且存在时钟回拨的问题。***
*号段模式*
号段模式每次从数据库取出一个号段范围,加载到服务内存中。业务获取时ID直接在这个范围递增取值即可。
等这批号段ID用完,再次向数据库申请新号段,对max_id字段做一次update操作,新的号段范围是(max_id ,max_id +step]。
由于多业务端可能同时操作,所以采用版本号version乐观锁方式更新。
*优点:产生的分布式ID全局唯一,宏观单调递增,无时钟回拨问题**;***
*缺点:**运行时依赖DB存在单点风险****,****并且每次取号段时存在抖动,****节点重启会造成号段空洞,另外主从切换有延迟时可能导致号段重复。***
两种基本路径的对比如下:
2.2 业界方案
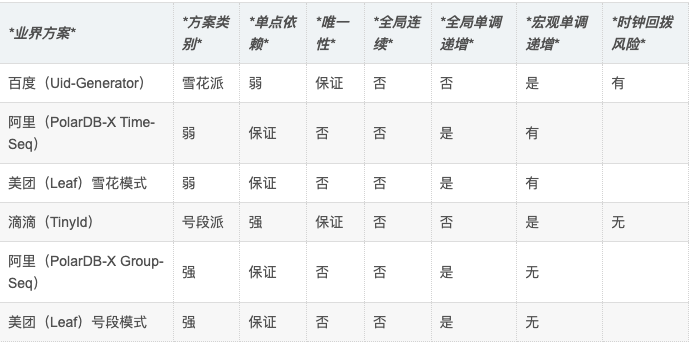
业界比较有名的解决方案如下表所示,本文将选择两个典型的代表进行比较:百度的Uid-Generator以及美团的Left-号段模式,前者基于雪花算法,后者是典型的号段模式。
*百度(Uid-Generator)*
uid-generator是基于雪花算法实现的,64个比特位分配如下。
不同之处有以下:
uid-generator支持自定义时间戳、节点ID和序列号等各部分的位数。
uid-generator中不是使用节点IP而是使用了自定义节点ID的生成策略。具体来说依赖于worker_node表,当应用启动时会向数据库表中去插入一条数据,插入成功后返回的自增ID就是该机器的workerId。
位分配:节点ID占了22位,时间占了28位,序列号占了13位,需要注意的是,和原始的雪花算法不一样,时间的单位是秒,而不是毫秒,节点ID也不一样,而且同一节点每次重启就会消费一个节点ID。
*优点:实现简单轻量,对DB是弱依赖(只在启动时访问一次),能够保证节点ID无冲突可能,从而实现严格的全局唯一性**;***
*缺点:**节点ID****不可回收,有耗尽风险。***
*美团(Leaf-号段模式)
*优点:产生的分布式ID全局唯一,宏观单调递增,通过双buffer解决号段更新时的抖动问题**;***
*缺点:**运行时强依赖DB存在单点风险。***
*2.3* *方案选择*
雪花算法:通过赋予64个比特位不同的含义来实现全局唯一ID的生成,但没有考虑单元信息,同时需要重点解决节点ID的冲突和耗尽问题;
号段模式:通过在DB上记录区间段然后给不同节点分配区间来产生ID,在单元化的场景下使用这种思路则需要再引入一个中心化DB,与单元化本身相斥。
雪花PLUS:最终本文选择在雪花算法的基础上,采用类似百度Uid-Generator的思路,同时在64比特位中增加单元ID的信息,以实现跨单元全局唯一ID的生成。
3.3.2 时间回拨解决方案
实际应用中,机器时间可能会不可靠,比如NTP校准使得当前时间戳小于上一次生成ID时的时间戳,这种系统时钟向后跳变的现象被称作时间回拨,如果不加处理有可能会造成ID冲突,解决思路有如下:
等待策略:当检测到时钟回拨时,服务可以暂时拒绝生成新的ID,等待系统时钟恢复到正常状态(至少大于或等于上次生成ID时的时间戳)。这种策略可以确保ID的严格递增性,但会在时钟调整期间暂停ID服务,对系统性能造成一定的影响,该思路适合回拨时间比较小的场景。
回拨位:从64比特位中再分出2位留给回拨使用,当发现时钟回拨时对回拨进行加1,优点是对ID服务无影响,但支持的回拨次数也只有4次,且消耗了本就紧缺的比特位。
借号:当检测到系统时间回拨时,不使用当前回拨后的时间戳,而是继续使用上一次生成ID时的时间戳。
方案选择:结合等待策略和借号,当回拨时间小于1s时进行等待,否则使用借号,借号如果未成功则进行等待,同时检测到时钟回拨后将会上报到监控进行告警。
不妨看一下本方案是如何解决前文提到的几个挑战的:
全局唯一:通过在雪花算法中引入单元ID来标识单元信息,同时单元内通过节点ID编码分布式节点的信息,而这两个ID的有效性是由SDK内的一个后台续约线程来保证,这些机制综合起来可以保证跨单元全局唯一ID的实现。
高性能:运行时所有的唯一ID获取都是内存操作,只需要对原子变量自增即可获取新的ID,同时通过多任务共享同一套续约机制提高了系统的并发性,默认配置下单机单任务ID生成的QPS能达到理论值8000。
高可用:本方案对DB的依赖只在节点启动时生效,后续每隔一段时间后台会续约一次元数据,即使DB出现故障也有一定的缓冲时间保证系统能继续正常运行,而如果是号段模式在主从发生切换时存在可用性风险(主要是发号可能重复)。
易用性:本方案对用户提供的接口只有一个SDK内的抽象RedSequence以及其核心方法 nextVal(String seqKey),节点分配表提前通过DMS平台进行申请创建,用户基本无负担,实现了拿来即用的目标。