强化学习之基于无模型的算法之演员-评论家算法
5、演员-评论家算法
演员-评论家(Actor-Critic, AC)算法是强化学习中的一类混合方法,结合了 策略梯度(Policy Gradient)和 值函数(Value Function)的优势:
- 演员(Actor):负责生成动作(策略网络πθ(a∣s)),通过梯度上升优化策略,使智能体选择高回报的动作。
- 评论家(Critic):评估当前策略的好坏(价值网络Vω(s)或Qω(s,a)),通过最小化误差(如TD误差)优化价值估计。
核心目标:通过 策略梯度和 值函数估计的协同优化,解决传统策略梯度方法方差大、收敛慢的问题,同时避免纯值函数方法的高偏差。
1)优势演员-评论家算法(A2C)
核心思想
A2C 结合了策略梯度算法(演员部分)和价值函数估计(评论家部分)。演员网络负责学习策略 π θ( a∣ s) ,用于选择动作;评论家网络负责学习状态价值函数V ϕ(s) ,用于评估状态的好坏。优势函数 A(s,a) 衡量了在状态 s 下采取动作 a 相对于平均动作的优势,通过引入优势函数可以降低策略梯度估计的方差。
公式

A2C中引入了泛化优势估计和熵正则化方法,通过引入泛化优势估计,A2C 算法能够更稳定、更准确地估计优势函数,减少了方差;而熵正则化则鼓励策略保持一定的随机性,增强了智能体的探索能力。结合这两种方法后,A2C 算法在很多强化学习任务中都能取得更好的性能。
泛化优势估计(GAE)
(1) 原始优势函数的问题
- 单步TD误差:
- 缺点:方差高(仅用一步信息),对环境噪声敏感。
- 蒙特卡洛回报:
- 缺点:偏差高(依赖完整轨迹),不适用于在线学习。
(2) GAE的核心思想
- 指数加权平均:通过λ参数平衡多步TD误差的偏差与方差,公式为:
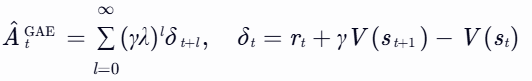
- λ的作用:
- λ=0:退化为单步TD误差(高方差,低偏差)。
- λ=1:退化为蒙特卡洛回报(低方差,高偏差)。
- 0<λ<1:结合两者优势,兼顾稳定性与效率。
(3) 直观理解
- GAE vs. 传统优势函数:想象你预测一家公司的未来利润(A(s,a)):
- 单步TD误差:仅用下一季度财报(高波动,易受短期因素干扰)。
- 蒙特卡洛回报:等公司破产或上市后再评估(结果准确,但耗时过长)。
- GAE:结合未来3-5年的财务预测,并根据预测可靠性加权(更高效且稳定)。
熵正则化
(1) 熵的作用
- 定义:策略的熵为
- 目标:最大化熵,鼓励策略保持多样性(避免过早收敛到局部最优)。
(2) 策略梯度公式调整
- 原始策略梯度:
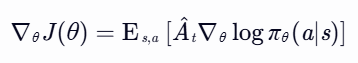
- 含熵正则化的策略梯度:
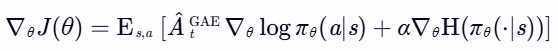
- α:控制熵项权重的超参数(α越大,探索越积极)。
(3) 直观理解
- 熵正则化类比:将智能体比作一名“运动员”:
- 无熵正则化:运动员只重复练习已知的最优动作(易陷入“过拟合”)。
- 有熵正则化:教练要求运动员在保证成绩的同时,尝试不同动作(提升泛化能力)。
特点:
- 优势函数:直接利用Q(s,a)与V(s)的差值,避免独立估计两者的误差累积。
- 单线程同步更新:所有智能体同步收集数据并更新网络,适用于离散动作空间任务。
基于离散动作空间的实现代码
#! /usr/bin/env pythonimport gym
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.distributions import Categorical
import random
from PIL import Image
from collections import deque
import numpy as np
import matplotlib.pyplot as pltclass ActorNet(nn.Module):def __init__(self, img_size, num_actions):super().__init__()# 输入图像的形状(c, h, w)self.img_size = img_sizeself.num_actions = num_actions# 对于Atari环境,输入为(4, 84, 84)self.featnet = nn.Sequential(nn.Conv2d(img_size[0], 32, kernel_size=8, stride=4),nn.ReLU(),nn.Conv2d(32, 64, kernel_size=4, stride=2),nn.ReLU(),nn.Conv2d(64, 64, kernel_size=3, stride=1),nn.ReLU(),nn.Flatten(),)gain = nn.init.calculate_gain('relu')self.pnet1 = nn.Sequential(nn.Linear(self._feat_size(), 512),nn.ReLU(),)self._init(self.featnet, gain)self._init(self.pnet1, gain)# 策略网络,计算每个动作的概率gain = 1.0self.pnet2 = nn.Linear(512, self.num_actions)self._init(self.pnet2, gain)def _feat_size(self):with torch.no_grad():x = torch.randn(1, *self.img_size)x = self.featnet(x).view(1, -1)return x.size(1)def _init(self, mod, gain):for m in mod.modules():if isinstance(m, (nn.Linear, nn.Conv2d)):nn.init.orthogonal_(m.weight, gain=gain)nn.init.zeros_(m.bias)def forward(self, x):feat = self.featnet(x)feat = self.pnet1(feat)return self.pnet2(feat)def act(self, x):with torch.no_grad():logits = self(x)m = Categorical(logits=logits).sample().squeeze()return m.cpu().item()class CriticNet(nn.Module):def __init__(self, img_size):super().__init__()# 输入图像的形状(c, h, w)self.img_size = img_size# 对于Atari环境,输入为(4, 84, 84)self.featnet = nn.Sequential(nn.Conv2d(img_size[0], 32, kernel_size=8, stride=4),nn.ReLU(),nn.Conv2d(32, 64, kernel_size=4, stride=2),nn.ReLU(),nn.Conv2d(64, 64, kernel_size=3, stride=1),nn.ReLU(),nn.Flatten())#nn.init 是 PyTorch 中用于初始化张量(Tensor)权重和偏置的模块;calculate_gain 是 nn.init 中的一个函数,用于根据激活函数的类型计算一个 增益值。gain = nn.init.calculate_gain('relu')self.vnet1 = nn.Sequential(nn.Linear(self._feat_size(), 512),nn.ReLU())self._init(self.featnet, gain)self._init(self.vnet1, gain)# 价值网络,根据特征输出每个动作的价值gain = 1.0self.vnet2 = nn.Linear(512, 1)self._init(self.vnet2, gain)def _feat_size(self):with torch.no_grad():x = torch.randn(1, *self.img_size)x = self.featnet(x).view(1, -1)return x.size(1)def _init(self, mod, gain):for m in mod.modules():if isinstance(m, (nn.Linear, nn.Conv2d)):nn.init.orthogonal_(m.weight, gain=gain)nn.init.zeros_(m.bias)def forward(self, x):feat = self.featnet(x)feat = self.vnet1(feat)return self.vnet2(feat).squeeze(-1)def val(self, x):with torch.no_grad():val = self(x).squeeze() #调用模型的 forward 方法,获取模型的输出,移除张量中维度为 1 的维度return val.cpu().item()#.item() 是 PyTorch 张量的方法,用于从 单个元素的张量(标量张量)中提取值,并返回 Python 的原生数据类型(如 int、float)class ActionBuffer(object):def __init__(self, buffer_size):super().__init__()self.buffer = deque(maxlen=buffer_size)def reset(self):self.buffer.clear()def push(self, state, action, value, reward, done):self.buffer.append((state, action, value, reward, done))def sample(self, next_value):state, action, value, reward, done = \zip(*self.buffer)value = np.array(value + (next_value, ))done = np.array(done).astype(np.float32)reward = np.array(reward).astype(np.float32)delta = reward + GAMMA*(1-done)*value[1:] - value[:-1]rtn = np.zeros_like(delta).astype(np.float32)adv = np.zeros_like(delta).astype(np.float32)reward_t = next_valuedelta_t = 0.0for i in reversed(range(len(reward))):reward_t = reward[i] + GAMMA*(1.0 - done[i])*reward_tdelta_t = delta[i] + (GAMMA*LAMBDA)*(1.0 - done[i])*delta_trtn[i] = reward_tadv[i] = delta_treturn np.stack(state, 0), np.stack(action, 0), rtn, advdef __len__(self):return len(self.buffer)class EnvWrapper(object):def __init__(self, env, num_frames):super().__init__()self.env_ = envself.num_frames = num_framesself.frame = deque(maxlen=num_frames)def _preprocess(self, img):# 预处理数据img = Image.fromarray(img)img = img.convert("L")img = img.crop((0, 30, 160, 200)) #截取图像的中央部分img = img.resize((84, 84))img = np.array(img)/256.0return img - np.mean(img)def reset(self):obs = self.env_.reset()if isinstance(obs, tuple):obs = obs[0]for _ in range(self.num_frames):self.frame.append(self._preprocess(obs))return np.stack(self.frame, 0)def step(self, action):obs, reward, done, _, _ = self.env_.step(action)self.frame.append(self._preprocess(obs))return np.stack(self.frame, 0), np.sign(reward), done, {}@propertydef env(self):return self.env_def train(buffer, next_value, pnet, vnet, optimizer, use_gae=False):state, action, rtn, adv = buffer.sample(next_value)state = torch.tensor(state, dtype=torch.float32)action = torch.tensor(action, dtype=torch.long)rtn = torch.tensor(rtn, dtype=torch.float32)adv = torch.tensor(adv, dtype=torch.float32)logits = pnet(state)values = vnet(state)dist = Categorical(logits=logits)if not use_gae:adv = (rtn - values).detach()lossp = -(adv*dist.log_prob(action)).mean() - REG*dist.entropy().mean()lossv = 0.5*F.mse_loss(rtn, values)optimizer.zero_grad()lossp.backward()lossv.backward()torch.nn.utils.clip_grad_norm_(pnet.parameters(), 0.5)torch.nn.utils.clip_grad_norm_(vnet.parameters(), 0.5)optimizer.step()return lossp.item()GAMMA = 0.99
LAMBDA = 0.95
NFRAMES = 4
BATCH_SIZE = 32
NSTEPS = 100000
REG = 0.01
env = gym.make('PongDeterministic-v4', render_mode='human')
env = EnvWrapper(env, NFRAMES)state = env.reset()
buffer = ActionBuffer(BATCH_SIZE)
pnet = ActorNet((4, 84, 84), env.env.action_space.n)
vnet = CriticNet((4, 84, 84))
# pnet.cuda()
# vnet.cuda()
optimizer = torch.optim.Adam([{'params': pnet.parameters(), 'lr': 1e-4},{'params': vnet.parameters(), 'lr': 1e-4},
])all_rewards = []
all_losses = []
all_values = []
episode_reward = 0
loss = 0.0state = env.reset()for nstep in range(NSTEPS):print("step-------",nstep)state_t = torch.tensor(state, dtype=torch.float32).unsqueeze(0)action = pnet.act(state_t)value = vnet.val(state_t)next_state, reward, done, _ = env.step(action)buffer.push(state, action, value, reward, done)state = next_stateepisode_reward += rewardif done:state = env.reset()all_rewards.append(episode_reward)state_t = torch.tensor(next_state, dtype=torch.float32).unsqueeze(0)all_values.append(vnet.val(state_t))episode_reward = 0if done or len(buffer) == BATCH_SIZE:with torch.no_grad():state_t = torch.tensor(next_state, dtype=torch.float32).unsqueeze(0)next_value = vnet.val(state_t)loss = train(buffer, next_value, pnet, vnet, optimizer)all_losses.append(loss)buffer.reset()epochs = range(1, len(all_losses) + 1)# 创建折线图
plt.figure(figsize=(10, 6))
plt.plot(epochs, all_losses, marker='o', linestyle='-', color='b', label='Training Loss')# 添加标题和标签
plt.title('Training Loss Over Epochs')
plt.xlabel('Epochs')
plt.ylabel('Loss')# 显示图例
plt.legend()# 显示网格
plt.grid(True)# 显示图形
plt.show()基于连续动作空间的实现代码
#! /usr/bin/env pythonimport gym
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.distributions import Normal
import random
from PIL import Image
from collections import deque
import numpy as npclass PolicyNet(nn.Module):def __init__(self, state_dim, act_dim, act_min, act_max):super().__init__()self.state_dim = state_dimself.act_dim = act_dimself.feat_net = nn.Sequential(nn.Linear(state_dim, 256),nn.ReLU(),nn.Linear(256, 256),nn.ReLU())self.pnet_mu = nn.Linear(256, act_dim)self.pnet_logs = nn.Parameter(torch.zeros(act_dim))self.act_min = act_minself.act_max = act_maxdef forward(self, x):feat = self.feat_net(x)mu = 2.0*self.pnet_mu(feat).tanh()sigma = (F.softplus(self.pnet_logs) + 1e-4).sqrt()return mu, sigmadef act(self, x):with torch.no_grad():mu, sigma = self(x)dist = Normal(mu, sigma)return dist.sample()\.clamp(self.act_min, self.act_max)\.squeeze().cpu().item()class ValueNet(nn.Module):def __init__(self, state_dim, act_dim):super().__init__()# 特征提取网络self.feat_net = nn.Sequential(nn.Linear(state_dim, 256),nn.ReLU(),nn.Linear(256, 256),nn.ReLU())# 价值网络self.vnet = nn.Linear(256, 1)def forward(self, x):feat = self.feat_net(x)value = self.vnet(feat)return valuedef val(self, x):with torch.no_grad():value = self(x)return value.squeeze().cpu().item()class ActionBuffer(object):def __init__(self, buffer_size):super().__init__()self.buffer = deque(maxlen=buffer_size)def reset(self):self.buffer.clear()def push(self, state, action, value, reward, done):self.buffer.append((state, action, value, reward, done))def sample(self, next_value):state, action, value, reward, done = \zip(*self.buffer)value = np.array(value + (next_value, ))done = np.array(done).astype(np.float32)reward = np.array(reward).astype(np.float32)delta = reward + GAMMA*(1-done)*value[1:] - value[:-1]rtn = np.zeros_like(delta).astype(np.float32)rtn = reward + GAMMA*(1-done)*value[1:]adv = deltareturn np.stack(state, 0), np.stack(action, 0), rtn, advdef __len__(self):return len(self.buffer)def train(buffer, next_value, pnet, vnet, optimizer, use_gae=True):state, action, rtn, adv = buffer.sample(next_value)state = torch.tensor(state, dtype=torch.float32)action = torch.tensor(action, dtype=torch.float32)rtn = torch.tensor(rtn, dtype=torch.float32)adv = torch.tensor(adv, dtype=torch.float32)values = vnet(state).squeeze()# 计算损失函数mu, sigma = pnet(state)dist = Normal(mu, sigma)if not use_gae:adv = (rtn - values).detach()lossp = -(adv*dist.log_prob(action)).mean() - REG*dist.entropy().mean()lossv = 0.5*F.mse_loss(rtn, values)optimizer.zero_grad()lossp.backward()lossv.backward()torch.nn.utils.clip_grad_norm_(pnet.parameters(), 50.0)torch.nn.utils.clip_grad_norm_(vnet.parameters(), 50.0)optimizer.step()return lossp.item()BATCH_SIZE = 16
NSTEPS = 1000000
GAMMA = 0.90
REG = 0.01
env = gym.make("Pendulum-v1", render_mode="human")
buffer = ActionBuffer(BATCH_SIZE)
pnet = PolicyNet(env.observation_space.shape[0], env.action_space.shape[0], env.action_space.low[0], env.action_space.high[0])
vnet = ValueNet(env.observation_space.shape[0], env.action_space.shape[0])
# pnet.cuda()
# vnet.cuda()
optimizer = torch.optim.Adam([{'params': pnet.parameters(), 'lr': 1e-4},{'params': vnet.parameters(), 'lr': 1e-3},
])loss = 0.0
episode_reward = 0.0state = env.reset()
for nstep in range(NSTEPS):if isinstance(state,tuple):state=state[0]state_t = torch.tensor(state, dtype=torch.float32).unsqueeze(0)action = pnet.act(state_t)value = vnet.val(state_t)next_state, reward, done, _, _ = env.step((action,))buffer.push(state, action, value, 0.1*reward, done)state = next_stateepisode_reward += rewardif done:state = env.reset()episode_reward = 0if done or len(buffer) == BATCH_SIZE:with torch.no_grad():state_t = torch.tensor(next_state, dtype=torch.float32).unsqueeze(0)next_value = vnet.val(state_t)loss = train(buffer, next_value, pnet, vnet, optimizer)buffer.reset()2)异步优势演员-评论家算法(A3C)
核心思想
A3C 是 A2C 的异步版本,它通过多个并行的智能体在不同的环境副本中进行交互,异步地更新全局网络的参数。其根本思想是利用多个共享策略网络模型和价值网络模型的智能体同时对强化学习环境进行采样,计算对应的梯度,同时收集所有智能体的梯度,并且每隔一定的步数利用收集的梯度对策略网络和价值网络进行更新,从而达到优化策略网络和价值网络的目的。这种并行化的方法可以加速训练过程,并且在一定程度上增加了训练数据的多样性。
公式
A3C 的更新公式与 A2C 基本相同,但由于是异步更新,每个智能体在本地计算梯度,然后将梯度发送到全局网络进行更新。

特点:
- 异步并行:多线程独立探索环境,加速收敛。
- 全局网络共享:线程定期同步全局网络参数,保持训练稳定性。
- 适用场景:高维连续动作空间任务(如机器人控制)。
实现代码
#! /usr/bin/env pythonimport gym
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.distributions import Categorical
import torch.multiprocessing as mp
import random
from PIL import Image
from collections import deque
import numpy as npGAMMA = 0.99
LAMBDA = 0.95
NFRAMES = 4
BATCH_SIZE = 32
NSTEPS = 100000
NWORKERS = 10
REG = 0.01class ActorNet(nn.Module):def __init__(self, img_size, num_actions):super().__init__()# 输入图像的形状(c, h, w)self.img_size = img_sizeself.num_actions = num_actions# 对于Atari环境,输入为(4, 84, 84)self.featnet = nn.Sequential(nn.Conv2d(img_size[0], 32, kernel_size=8, stride=4),nn.ReLU(),nn.Conv2d(32, 64, kernel_size=4, stride=2),nn.ReLU(),nn.Conv2d(64, 64, kernel_size=3, stride=1),nn.ReLU(),nn.Flatten(),)gain = nn.init.calculate_gain('relu')self.pnet1 = nn.Sequential(nn.Linear(self._feat_size(), 512),nn.ReLU(),)self._init(self.featnet, gain)self._init(self.pnet1, gain)# 策略网络,计算每个动作的概率gain = 1.0self.pnet2 = nn.Linear(512, self.num_actions)self._init(self.pnet2, gain)def _feat_size(self):with torch.no_grad():x = torch.randn(1, *self.img_size)x = self.featnet(x).view(1, -1)return x.size(1)def _init(self, mod, gain):for m in mod.modules():if isinstance(m, (nn.Linear, nn.Conv2d)):nn.init.orthogonal_(m.weight, gain=gain)nn.init.zeros_(m.bias)def forward(self, x):feat = self.featnet(x)feat = self.pnet1(feat)return self.pnet2(feat)def act(self, x):with torch.no_grad():logits = self(x)m = Categorical(logits=logits).sample().squeeze()return m.cpu().item()class CriticNet(nn.Module):def __init__(self, img_size):super().__init__()# 输入图像的形状(c, h, w)self.img_size = img_size# 对于Atari环境,输入为(4, 84, 84)self.featnet = nn.Sequential(nn.Conv2d(img_size[0], 32, kernel_size=8, stride=4),nn.ReLU(),nn.Conv2d(32, 64, kernel_size=4, stride=2),nn.ReLU(),nn.Conv2d(64, 64, kernel_size=3, stride=1),nn.ReLU(),nn.Flatten())gain = nn.init.calculate_gain('relu') #根据激活函数类型计算“合适的缩放比例”self.vnet1 = nn.Sequential(nn.Linear(self._feat_size(), 512),nn.ReLU())self._init(self.featnet, gain)self._init(self.vnet1, gain)# 价值网络,根据特征输出每个动作的价值gain = 1.0self.vnet2 = nn.Linear(512, 1)self._init(self.vnet2, gain)def _feat_size(self):with torch.no_grad():x = torch.randn(1, *self.img_size)x = self.featnet(x).view(1, -1)return x.size(1)def _init(self, mod, gain):for m in mod.modules():if isinstance(m, (nn.Linear, nn.Conv2d)):nn.init.orthogonal_(m.weight, gain=gain) #正交初始化nn.init.zeros_(m.bias) #将偏置量初始化为0def forward(self, x):feat = self.featnet(x)feat = self.vnet1(feat)return self.vnet2(feat).squeeze(-1)def val(self, x):with torch.no_grad():val = self(x).squeeze()return val.cpu().item()class ActionBuffer(object):def __init__(self, buffer_size):super().__init__()self.buffer = deque(maxlen=buffer_size)def reset(self):self.buffer.clear()def push(self, state, action, value, reward, done):self.buffer.append((state, action, value, reward, done))def sample(self, next_value):state, action, value, reward, done = \zip(*self.buffer)value = np.array(value + (next_value, ))done = np.array(done).astype(np.float32)reward = np.array(reward).astype(np.float32)delta = reward + GAMMA*(1-done)*value[1:] - value[:-1]rtn = np.zeros_like(delta).astype(np.float32)adv = np.zeros_like(delta).astype(np.float32)reward_t = next_valuedelta_t = 0.0for i in reversed(range(len(reward))):reward_t = reward[i] + GAMMA*(1.0 - done[i])*reward_tdelta_t = delta[i] + (GAMMA*LAMBDA)*(1.0 - done[i])*delta_trtn[i] = reward_tadv[i] = delta_treturn np.stack(state, 0), np.stack(action, 0), rtn, advdef __len__(self):return len(self.buffer)class EnvWrapper(object):def __init__(self, env, num_frames):super().__init__()self.env_ = envself.num_frames = num_framesself.frame = deque(maxlen=num_frames)def _preprocess(self, img):# 预处理数据img = Image.fromarray(img)img = img.convert("L")img = img.crop((0, 30, 160, 200))img = img.resize((84, 84))img = np.array(img)/256.0return img - np.mean(img)def reset(self):obs = self.env_.reset()if isinstance(obs, tuple):obs = obs[0]for _ in range(self.num_frames):self.frame.append(self._preprocess(obs))return np.stack(self.frame, 0)def step(self, action):obs, reward, done, _, _ = self.env_.step(action)self.frame.append(self._preprocess(obs))return np.stack(self.frame, 0), np.sign(reward), done, {}@propertydef env(self):return self.env_def train(buffer, next_value, pnet, vnet, optimizer, lock, use_gae=False):state, action, rtn, adv = buffer.sample(next_value)state = torch.tensor(state, dtype=torch.float32)action = torch.tensor(action, dtype=torch.long)rtn = torch.tensor(rtn, dtype=torch.float32)adv = torch.tensor(adv, dtype=torch.float32)logits = pnet(state)values = vnet(state)dist = Categorical(logits=logits)if not use_gae:adv = (rtn - values).detach()lossp = -(adv*dist.log_prob(action)).mean() - REG*dist.entropy().mean()lossv = 0.5*F.mse_loss(rtn, values)lock.acquire() # 加锁optimizer.zero_grad()lossp.backward()lossv.backward()torch.nn.utils.clip_grad_norm_(pnet.parameters(), 0.5)torch.nn.utils.clip_grad_norm_(vnet.parameters(), 0.5)optimizer.step()lock.release() # 释放锁return lossp.cpu().item()def train_worker(idx, pnet, vnet, optimizer, lock):# 构造强化学习环境env = gym.make('PongDeterministic-v4')env.seed(idx)env = EnvWrapper(env, NFRAMES)buffer = ActionBuffer(BATCH_SIZE)state = env.reset()episode_reward = 0# 强化学习环境的采样和训练for nstep in range(NSTEPS):state_t = torch.tensor(state, dtype=torch.float32).unsqueeze(0)action = pnet.act(state_t)value = vnet.val(state_t)next_state, reward, done, _ = env.step(action)buffer.push(state, action, value, reward, done)state = next_stateepisode_reward += rewardif done:state = env.reset()state_t = torch.tensor(next_state, dtype=torch.float32).unsqueeze(0)print(f"Process {idx:4d}, reward {episode_reward:6.4f}")episode_reward = 0if done or len(buffer) == BATCH_SIZE:with torch.no_grad():state_t = torch.tensor(next_state, dtype=torch.float32).unsqueeze(0)next_value = vnet.val(state_t)loss = train(buffer, next_value, pnet, vnet, optimizer, lock)buffer.reset()class SharedAdam(torch.optim.Adam):def __init__(self, params, lr=1e-3, betas=(0.9, 0.99), eps=1e-8, weight_decay=0):super(SharedAdam, self).__init__(params, \lr=lr, betas=betas, eps=eps, weight_decay=weight_decay)# 初始化Adam优化器的状态for group in self.param_groups:for p in group['params']:state = self.state[p]state['step'] = 0state['exp_avg'] = torch.zeros_like(p.data)state['exp_avg_sq'] = torch.zeros_like(p.data)# 优化器状态共享state['exp_avg'].share_memory_()state['exp_avg_sq'].share_memory_()if __name__ == "__main__":torch.multiprocessing.set_start_method('spawn')env = gym.make('PongDeterministic-v4', render_mode='human')pnet = ActorNet((4, 84, 84), env.env.action_space.n)vnet = CriticNet((4, 84, 84))# pnet.cuda()# vnet.cuda()# 进程之间共享模型pnet.share_memory()vnet.share_memory()workers = []optimizer = SharedAdam([{'params': pnet.parameters(), 'lr': 1e-4},{'params': vnet.parameters(), 'lr': 1e-4},])lock = mp.Lock()for idx in range(NWORKERS):worker = mp.Process(target=train_worker, args=(idx, pnet, vnet, optimizer, lock), daemon=True)worker.start()workers.append(worker)for work in workers:worker.join()3)软演员-评论家算法(SAC)
核心思想
- 最大熵强化学习:传统的强化学习算法通常只关注最大化累积奖励,而 SAC 引入了最大熵原理,即在追求高奖励的同时,鼓励智能体采取更加随机和多样化的行动策略。该原理通过在目标函数中引入熵项来实现,熵是对随机变量不确定性的度量,在强化学习中,它表示智能体策略的随机性。最大化熵可以使智能体在学习过程中探索更多的状态 - 动作空间,从而避免过早地陷入局部最优解,提高学习的稳定性和鲁棒性。
- 演员 - 评论家架构:SAC 采用了演员 - 评论家架构,包含两个主要部分,即演员网络(Actor)和评论家网络(Critic)。演员网络负责生成动作,根据当前的状态输出一个动作分布,例如在连续动作空间中,可能输出一个均值和方差,以表示正态分布的参数,智能体根据这个分布来采样实际执行的动作。评论家网络则负责评估演员网络生成的动作的价值,它接收状态和动作作为输入,输出一个价值估计,表示在该状态下执行该动作的长期累积奖励的预期值。通过这种方式,演员网络根据评论家网络的反馈来调整自己的策略,以生成更优的动作。
- 软更新机制:在 SAC 中,使用了软更新机制来更新网络参数。与传统的硬更新(直接将目标网络的参数替换为当前网络的参数)不同,软更新是通过将目标网络的参数朝着当前网络的参数进行缓慢的插值来实现的。具体来说,对于每个参数,会按照一定的比例将目标网络参数更新为当前网络参数和目标网络参数的加权平均值。这种软更新方式可以使目标网络的参数变化更加平滑,避免了因参数更新过快而导致的学习不稳定问题,有助于提高算法的收敛性和性能。
- 双评论家网络:为了更准确地估计动作价值,SAC 使用了两个评论家网络,它们具有相同的结构,但参数不同。在训练过程中,同时使用这两个评论家网络来估计同一个状态 - 动作对的价值,然后取两者中的最小值作为最终的价值估计。这种双评论家网络的结构可以有效地减少价值估计的偏差,提高价值函数的估计精度,从而使演员网络能够学习到更优的策略。同时,在更新评论家网络参数时,利用两个评论家网络的估计值来计算损失函数,通过最小化损失函数来调整网络参数,使得评论家网络能够更好地拟合真实的价值函数。
公式



特点:
- 最大熵机制:避免策略陷入局部最优,提升探索效率。
- 双Q网络:缓解过估计问题,提高策略稳定性。
- 适用场景:复杂连续控制任务(如机器人运动)。
实现代码
#! /usr/bin/env pythonimport torch
import torch.nn as nn
import torch.nn.functional as F
from torch.distributions import Normal, Independent
from collections import deque
import random
import numpy as np
import gymclass PolicyNet(nn.Module):def __init__(self, state_dim, act_dim):super().__init__()self.state_dim = state_dimself.act_dim = act_dim# 特征提取网络self.featnet = nn.Sequential(nn.Linear(state_dim, 256),nn.ReLU(),nn.Linear(256, 256),nn.ReLU(),)# 连续分布期望和对数标准差网络self.pnet_mu = nn.Linear(256, act_dim)self.pnet_logs = nn.Linear(256, act_dim)def forward(self, x):feat = self.featnet(x)mu = self.pnet_mu(feat)sigma = self.pnet_logs(feat).clamp(-20, 2).exp()# 根据期望和标准差得到正态分布return Independent(Normal(loc=mu, scale=sigma), reinterpreted_batch_ndims=1)#使用 PyTorch 的 Normal 类定义一个正态分布,均值为 mu,标准差为 sigmadef action_logp(self, x, reparam=False):dist = self(x)u = dist.rsample() if reparam else dist.sample()a = torch.tanh(u)# 概率密度变换# logp = dist.log_prob(u) - torch.log(1 - a.pow(2) + 1e-6).squeeze()logp = dist.log_prob(u) - (2*(np.log(2) - u - F.softplus(-2 * u))).squeeze()return a, logp,logp.sum().item()def act(self, x):# 计算具体的动作with torch.no_grad():a, _ ,_= self.action_logp(x)return a.cpu().item()class DQN(nn.Module):def __init__(self, state_dim, act_dim):super().__init__()# 特征提取网络self.featnet = nn.Sequential(nn.Linear(state_dim+act_dim, 256),nn.ReLU(),nn.Linear(256, 256),nn.ReLU(),)# 价值网络self.vnet = nn.Linear(256, 1)def forward(self, state, action):x = torch.cat([state, action], dim=-1)feat = self.featnet(x)value = self.vnet(feat)return valuedef val(self, state, action):with torch.no_grad():value = self(state, action)return value.squeeze().cpu().item()# 使用双网络方法来进行价值函数的预测
class TwinDQN(nn.Module):def __init__(self, state_dim, act_dim):super().__init__()self.dqn1 = DQN(state_dim, act_dim)self.dqn2 = DQN(state_dim, act_dim)def update(self, other, polyak=0.995):with torch.no_grad():for param1, param2 in zip(self.parameters(), other.parameters()):param1.data.copy_(polyak*param1.data+(1.0-polyak)*param2.data)class NormalizedActions(gym.ActionWrapper):def action(self, action):low = self.action_space.lowhigh = self.action_space.highaction = low + (action + 1.0) * 0.5 * (high - low)action = np.clip(action, low, high)return actiondef reverse_action(self, action):low = self.action_space.lowhigh = self.action_space.highaction = 2 * (action - low) / (high - low) - 1action = np.clip(action, low, high)return actionclass ExpReplayBuffer(object):def __init__(self, buffer_size):super().__init__()self.buffer = deque(maxlen=buffer_size)def push(self, state, action, reward, next_state, done):self.buffer.append((state, action, reward, next_state, done))def sample(self, bs):state, action, reward, next_state, done = \zip(*random.sample(self.buffer, bs))return np.stack(state, 0), np.stack(action, 0), \np.stack(reward, 0), np.stack(next_state, 0), \np.stack(done, 0).astype(np.float32)def __len__(self):return len(self.buffer)def train(buffer, pnet, vnet, vnet_target, optim_p, optim_v):# 对经验进行采样state, action, reward, next_state, done = buffer.sample(BATCH_SIZE)state = torch.tensor(state, dtype=torch.float32)reward = torch.tensor(reward, dtype=torch.float32).unsqueeze(-1)action = torch.tensor(action, dtype=torch.float32).unsqueeze(-1)next_state = torch.tensor(next_state, dtype=torch.float32)done = torch.tensor(done, dtype=torch.float32).unsqueeze(-1)# 估算目标价值函数with torch.no_grad():next_action, logp,sum = pnet.action_logp(next_state)next_qval1 = vnet_target.dqn1(next_state, next_action)next_qval2 = vnet_target.dqn2(next_state, next_action)next_qval = torch.min(next_qval1, next_qval2)target = reward + GAMMA * (1 - done) * (next_qval - REG * logp)# 计算价值网络损失函数value1 = vnet.dqn1(state, action)value2 = vnet.dqn2(state, action)lossv = 0.5*(value1 - target).pow(2).mean() + 0.5*(value2 - target).pow(2).mean()optim_v.zero_grad()lossv.backward()torch.nn.utils.clip_grad_value_(vnet.parameters(), 1.0) #将 vnet(值函数网络)的参数梯度值裁剪到最大绝对值 1.0optim_v.step() #参数更新# 计算策略网络损失函数,注意关闭价值网络参数梯度for param in vnet.parameters():param.requires_grad = False #冻结 vnet 网络的所有参数,即让 vnet 的参数在训练过程中不参与梯度更新action, logp,sum = pnet.action_logp(state, True)qval = torch.min(vnet.dqn1(state, action), vnet.dqn2(state, action))lossp = -torch.mean(qval - REG * logp)optim_p.zero_grad()lossp.backward()torch.nn.utils.clip_grad_value_(pnet.parameters(), 1.0)optim_p.step()for param in vnet.parameters():param.requires_grad = Truevnet_target.update(vnet)return logp.mean().item(),sumBATCH_SIZE = 64
NSTEPS = 100000
NBUFFER = 100000
GAMMA = 0.99
REG = 0.1
env = NormalizedActions(gym.make("Pendulum-v1", render_mode="human"))
buffer = ExpReplayBuffer(NBUFFER)
pnet = PolicyNet(env.observation_space.shape[0], env.action_space.shape[0])
vnet = TwinDQN(env.observation_space.shape[0], env.action_space.shape[0])
vnet_target = TwinDQN(env.observation_space.shape[0], env.action_space.shape[0])
# pnet.cuda()
# vnet.cuda()
# vnet_target.cuda()
vnet_target.load_state_dict(vnet.state_dict())
optim_p = torch.optim.Adam(pnet.parameters(), lr=1e-3) #使用 optim_p 更新策略网络 pnet 的参数, lr是学习率
optim_v = torch.optim.Adam(vnet.parameters(), lr=1e-3)all_rewards = []
all_losses = []
episode_reward = 0
loss = 0.0
log_pi_sum=[]state = env.reset()
for nstep in range(NSTEPS):if(isinstance(state, tuple)):state=state[0]state_t = torch.tensor(state, dtype=torch.float32).unsqueeze(0)action = pnet.act(state_t)next_state, reward, done, _, _ = env.step(action)buffer.push(state, action, reward, next_state, done)state = next_stateepisode_reward += rewardif done:state = env.reset()all_rewards.append(episode_reward)episode_reward = 0if len(buffer) >= BATCH_SIZE:sum=0loss,sum = train(buffer, pnet, vnet, vnet_target, optim_p, optim_v)log_pi_sum.append(sum)
for _ in range (100000):env.render()state_t=torch.tensor(state,dtype=torch.float32)action=pnet.act(state_t)next_state, reward, done, _ = env.step(action)if done:breakstate=next_state
env.close()4)深度确定性策略梯度( DDPG)
核心思想
DDPG 是一种适用于连续动作空间的无模型强化学习算法,它结合了深度 Q 网络(DQN)和确定性策略梯度(DPG)的思想。DDPG 同时使用演员网络和评论家网络,演员网络输出确定性的动作,评论家网络评估动作的价值。
- 借鉴深度 Q 网络(DQN)的核心机制
- 经验回放(Experience Replay):DDPG 继承了 DQN 的经验回放机制,智能体在与环境交互过程中,将每个时间步的状态、采取的动作、获得的奖励 以及下一时刻的状态存储到经验回放缓冲区(Replay Buffer)。在训练时,从缓冲区中随机采样一批经验数据进行学习。这种方式打破了数据之间的时间相关性,避免了连续数据样本的高度关联性对学习过程的干扰,同时使得同一批数据可以被多次利用,提高了样本效率和训练的稳定性。例如在机器人控制任务中,机器人不同时刻的动作和状态往往存在时间上的联系,经验回放能有效处理这种关联性带来的问题。
- 目标网络(Target Network):DDPG 引入了与 DQN 类似的目标网络结构。算法分别为演员网络和评论家网络设置目标网络,即目标演员网络和目标评论家网络。目标网络的结构与对应的主网络相同,但参数更新较为缓慢。在训练过程中,主网络用于生成动作和评估当前状态 - 动作对的价值,而目标网络则用于计算目标价值,以减少训练过程中的波动。例如,在计算评论家网络的目标值时,利用目标评论家网络和目标演员网络来计算下一状态的价值,为学习过程提供一个相对稳定的目标,帮助算法更好地收敛。
- 融合确定性策略梯度(DPG)的核心思想
- 确定性策略(Deterministic Policy):DPG 的核心在于使用确定性策略,即策略函μ(s|θ) 直接根据当前状态 s 和策略参数θ输出一个确定的动作,而不是像随机策略那样输出动作的概率分布。在连续动作空间中,确定性策略能够更高效地探索和利用环境。例如,在自动驾驶场景下,需要精确控制车辆的方向盘转角、油门和刹车力度等连续动作,确定性策略可以直接输出具体的数值,相较于随机策略更具实用性和效率。
- 策略梯度(Policy Gradient):DDPG 基于策略梯度方法更新演员网络的参数。策略梯度的核心是计算策略参数对目标函数(通常是期望累计奖励)的梯度,通过沿着梯度方向更新参数,逐步改进策略。在 DDPG 中,通过计算价值函数关于动作的梯度,再结合策略函数关于参数的梯度,来得到策略网络参数的更新方向,从而使得演员网络能够根据评论家网络的反馈不断优化输出的动作,以最大化长期累计奖励。
公式

特点:
- 确定性策略:直接输出动作,无需采样。
- 经验回放与目标网络:打破数据相关性,稳定训练过程。
- 适用场景:连续动作控制任务(如自动驾驶)。
实现代码
#! /usr/bin/env pythonimport gym
import torch
import torch.nn as nn
import random
import numpy as np
from collections import dequeclass PolicyNet(nn.Module):def __init__(self, state_dim, act_dim):super().__init__()self.state_dim = state_dimself.act_dim = act_dimself.featnet = nn.Sequential(nn.Linear(state_dim, 256),nn.ReLU(),nn.Linear(256, 256),nn.ReLU(),)self.pnet = nn.Linear(256, act_dim)def forward(self, x):feat = self.featnet(x)return self.pnet(feat).tanh()def act(self, x):with torch.no_grad():action = self(x)action += 0.1*torch.randn_like(action)return action.clamp(-1, 1).cpu().item()def update(self, other, polyak=0.995):with torch.no_grad():for param1, param2 in zip(self.parameters(), other.parameters()):param1.data.copy_(polyak*param1.data+(1-polyak)*param2.data)class DQN(nn.Module):def __init__(self, state_dim, act_dim):super().__init__()self.featnet = nn.Sequential(nn.Linear(state_dim+act_dim, 256),nn.ReLU(),nn.Linear(256, 256),nn.ReLU(),)self.vnet = nn.Linear(256, 1)def forward(self, state, action):x = torch.cat([state, action], dim=-1)feat = self.featnet(x)value = self.vnet(feat)return valuedef val(self, state, action):with torch.no_grad():value = self(state, action)return value.squeeze().cpu().item()def update(self, other, polyak=0.995):with torch.no_grad():for param1, param2 in zip(self.parameters(), other.parameters()):param1.data.copy_(polyak*param1.data+(1-polyak)*param2.data)class NormalizedActions(gym.ActionWrapper):def action(self, action):low = self.action_space.lowhigh = self.action_space.highaction = low + (action + 1.0) * 0.5 * (high - low)action = np.clip(action, low, high)return actiondef reverse_action(self, action):low = self.action_space.lowhigh = self.action_space.highaction = 2 * (action - low) / (high - low) - 1action = np.clip(action, low, high)return actionclass ExpReplayBuffer(object):def __init__(self, buffer_size):super().__init__()self.buffer = deque(maxlen=buffer_size)def push(self, state, action, reward, next_state, done):self.buffer.append((state, action, reward, next_state, done))def sample(self, bs):state, action, reward, next_state, done = \zip(*random.sample(self.buffer, bs))return np.stack(state, 0), np.stack(action, 0), \np.stack(reward, 0), np.stack(next_state, 0), \np.stack(done, 0).astype(np.float32)def __len__(self):return len(self.buffer)def train(buffer, pnet, pnet_target, vnet, vnet_target, optim_p, optim_v):state, action, reward, next_state, done = buffer.sample(BATCH_SIZE)state = torch.tensor(state, dtype=torch.float32)reward = torch.tensor(reward, dtype=torch.float32).unsqueeze(-1)action = torch.tensor(action, dtype=torch.float32).unsqueeze(-1)next_state = torch.tensor(next_state, dtype=torch.float32)done = torch.tensor(done, dtype=torch.float32).unsqueeze(-1)with torch.no_grad(): #临时禁用梯度计算next_action = pnet_target(next_state) # 计算动作,不记录梯度next_qval = vnet_target(next_state, next_action)target = reward + GAMMA * (1 - done) * next_qvalvalue = vnet(state, action)lossv = 0.5*(value - target).pow(2).mean()optim_v.zero_grad()lossv.backward()torch.nn.utils.clip_grad_value_(vnet.parameters(), 1.0)optim_v.step()for param in vnet.parameters():param.requires_grad = Falseqval = vnet(state, pnet(state))lossp = -torch.mean(qval)optim_p.zero_grad()lossp.backward()torch.nn.utils.clip_grad_value_(pnet.parameters(), 1.0)optim_p.step()for param in vnet.parameters():param.requires_grad = Truevnet_target.update(vnet)pnet_target.update(pnet)return losspBATCH_SIZE = 64
NSTEPS = 1000000
NBUFFER = 100000
GAMMA = 0.99
REG = 0.1
env = NormalizedActions(gym.make("Pendulum-v1", render_mode="human"))
buffer = ExpReplayBuffer(NBUFFER)pnet = PolicyNet(env.observation_space.shape[0], env.action_space.shape[0])
pnet_target = PolicyNet(env.observation_space.shape[0], env.action_space.shape[0])
vnet = DQN(env.observation_space.shape[0], env.action_space.shape[0])
vnet_target = DQN(env.observation_space.shape[0], env.action_space.shape[0])
# pnet.cuda()
# pnet_target.cuda()
pnet_target.load_state_dict(pnet.state_dict())
# vnet.cuda()
# vnet_target.cuda()
vnet_target.load_state_dict(vnet.state_dict())optim_p = torch.optim.Adam(pnet.parameters(), lr=1e-3)
optim_v = torch.optim.Adam(vnet.parameters(), lr=1e-3)all_rewards = []
all_losses = []
episode_reward = 0
loss = 0.0state = env.reset()
for nstep in range(NSTEPS):if isinstance(state, tuple):state = state[0]state_t = torch.tensor(state, dtype=torch.float32).unsqueeze(0)action = pnet.act(state_t)next_state, reward, done, _, _ = env.step(action)buffer.push(state, action, reward, next_state, done)state = next_stateepisode_reward += rewardif done:state = env.reset()all_rewards.append(episode_reward)episode_reward = 0if len(buffer) >= BATCH_SIZE:loss = train(buffer, pnet, pnet_target, vnet, vnet_target, optim_p, optim_v)5)双延迟深度确定性策略梯度算法(TD3)
核心思想
TD3 是 DDPG 的改进算法,主要解决了 DDPG 中高估 Q 值的问题。TD3 使用两个评论家网络,取两个网络输出的最小值作为目标 Q 值,从而减少了高估的可能性。此外,TD3 还引入了延迟更新和目标策略平滑的技术。
通过三个关键技术提升算法性能:
- 双评论家网络(Twin Critic Networks)
- 解决 Q 值高估问题:在 DDPG 中,价值网络(评论家)对 Q 值的高估会导致策略学习出现偏差,使得智能体学习到的策略并非最优。TD3 采用两个结构相同但参数不同的评论家网络Q1和Q2,它们同时对状态 - 动作对(s,a)进行价值评估,输出两个不同的 Q 值估计。在计算目标 Q 值时,取两个网络输出的最小值,即min(Q1(s,a), Q2(s,a)) 。这种做法基于 “保守估计” 的原则,避免了因单个网络的高估倾向导致的策略优化偏差。例如,在复杂的机器人控制任务中,某一状态下动作价值的高估可能会使机器人执行错误的动作,而 TD3 的双网络机制降低了这种风险。
- 增强稳定性:两个评论家网络相互制约,减少了价值估计的方差。由于不同网络在训练过程中会捕捉到状态 - 动作价值的不同方面,取最小值的操作使得价值估计更加稳健,让算法在训练过程中更加稳定,不易出现剧烈波动。
- 延迟更新(Delayed Updates)
- 平衡训练速度与稳定性:TD3 对演员网络(策略网络)和评论家网络的更新频率进行差异化处理。在训练过程中,评论家网络以较高的频率更新参数,而演员网络则以较低的频率更新参数,即每经过一定次数的评论家网络更新后,才进行一次演员网络的更新。这种延迟更新机制避免了演员网络的快速变化导致评论家网络难以准确评估,防止因策略变化过快而引发的训练不稳定问题。例如,在训练初期,如果演员网络频繁更新,评论家网络可能无法及时适应新策略,导致价值估计混乱,延迟更新可以有效缓解这一问题。
- 防止过拟合:减少演员网络的更新频率,在一定程度上降低了网络对当前训练数据的过拟合风险。因为演员网络不会过度依赖某一阶段的训练样本进行更新,有助于学习到更具泛化能力的策略。
- 目标策略平滑(Target Policy Smoothing)
- 减少策略变化敏感性:TD3 在计算目标 Q 值时,对目标演员网络输出的动作进行平滑处理。具体做法是在目标动作中加入一个服从正态分布的噪声ε,并通过超参数 clip 对噪声进行裁剪,得到 a = u'(s') + clip(ε, -c, c),其中 u'(s') 是目标演员网络在状态 s' 下输出的动作,c 是裁剪边界。这样做使得目标 Q 值的计算更加鲁棒,减少了因动作微小变化导致的价值估计剧烈波动,尤其是在动作空间较为敏感的任务中,例如精细的机械臂操作,能够让算法对环境中的小扰动不那么敏感。
- 增强泛化能力:平滑操作有助于智能体学习到更稳定的策略,避免陷入局部最优。通过在目标动作中引入噪声,强制算法考虑动作的邻域情况,从而学习到在一定范围内都能表现良好的策略,提高了策略的泛化能力。
公式

特点:
- 双Q网络:减少过估计偏差。
- 目标策略平滑:防止策略对极端动作过拟合。
- 延迟更新:提升策略稳定性。
- 适用场景:高维连续控制任务(如复杂机器人操作)。
实现代码
#! /usr/bin/env pythonimport gym
import torch
import torch.nn as nn
import random
import numpy as np
from collections import dequeclass PolicyNet(nn.Module):def __init__(self, state_dim, act_dim):super().__init__()self.state_dim = state_dimself.act_dim = act_dimself.featnet = nn.Sequential(nn.Linear(state_dim, 256),nn.ReLU(),nn.Linear(256, 256),nn.ReLU(),)self.pnet = nn.Linear(256, act_dim)def forward(self, x):feat = self.featnet(x)return self.pnet(feat).tanh()def act(self, x):with torch.no_grad():action = self(x)action += 0.1*torch.randn_like(action)return action.clamp(-1, 1).cpu().item()def update(self, other, polyak=0.995):with torch.no_grad():for param1, param2 in zip(self.parameters(), other.parameters()):param1.data.copy_(polyak*param1.data+(1-polyak)*param2.data)class DQN(nn.Module):def __init__(self, state_dim, act_dim):super().__init__()self.featnet = nn.Sequential(nn.Linear(state_dim+act_dim, 256),nn.ReLU(),nn.Linear(256, 256),nn.ReLU(),)self.vnet = nn.Linear(256, 1)def forward(self, state, action):x = torch.cat([state, action], dim=-1)feat = self.featnet(x)value = self.vnet(feat)return valuedef val(self, state, action):with torch.no_grad():value = self(state, action)return value.squeeze().cpu().item()class TwinDQN(nn.Module):def __init__(self, state_dim, act_dim):super().__init__()self.dqn1 = DQN(state_dim, act_dim)self.dqn2 = DQN(state_dim, act_dim)def update(self, other, polyak=0.995):with torch.no_grad():for param1, param2 in \zip(self.parameters(), other.parameters()):param1.data.copy_(polyak*param1.data+(1.0-polyak)*param2.data)class NormalizedActions(gym.ActionWrapper):def action(self, action):low = self.action_space.lowhigh = self.action_space.highaction = low + (action + 1.0) * 0.5 * (high - low)action = np.clip(action, low, high)return actiondef reverse_action(self, action):low = self.action_space.lowhigh = self.action_space.highaction = 2 * (action - low) / (high - low) - 1action = np.clip(action, low, high)return actionclass ExpReplayBuffer(object):def __init__(self, buffer_size):super().__init__()self.buffer = deque(maxlen=buffer_size)def push(self, state, action, reward, next_state, done):self.buffer.append((state, action, reward, next_state, done))def sample(self, bs):state, action, reward, next_state, done = \zip(*random.sample(self.buffer, bs))return np.stack(state, 0), np.stack(action, 0), \np.stack(reward, 0), np.stack(next_state, 0), \np.stack(done, 0).astype(np.float32)def __len__(self):return len(self.buffer)def train(buffer, pnet, pnet_target, vnet, vnet_target, optim_p, optim_v, train_p = False):state, action, reward, next_state, done = buffer.sample(BATCH_SIZE)state = torch.tensor(state, dtype=torch.float32)reward = torch.tensor(reward, dtype=torch.float32).unsqueeze(-1)action = torch.tensor(action, dtype=torch.float32).unsqueeze(-1)next_state = torch.tensor(next_state, dtype=torch.float32)done = torch.tensor(done, dtype=torch.float32).unsqueeze(-1)with torch.no_grad():next_action = pnet_target(next_state)next_action += 0.1*torch.randn_like(next_action)next_action = next_action.clamp(-1, 1)next_qval1 = vnet_target.dqn1(next_state, next_action)next_qval2 = vnet_target.dqn2(next_state, next_action)target = reward + GAMMA * (1 - done) * torch.min(next_qval1, next_qval2)value1 = vnet.dqn1(state, action)value2 = vnet.dqn2(state, action)lossv = 0.5*(value1 - target).pow(2).mean() + 0.5*(value2 - target).pow(2).mean()optim_v.zero_grad()lossv.backward()torch.nn.utils.clip_grad_value_(vnet.parameters(), 1.0)optim_v.step()vnet_target.update(vnet)if not train_p: return Nonefor param in vnet.parameters():param.requires_grad = Falseqval = vnet.dqn1(state, pnet(state))lossp = -torch.mean(qval)optim_p.zero_grad()lossp.backward()torch.nn.utils.clip_grad_value_(pnet.parameters(), 1.0)optim_p.step()for param in vnet.parameters():param.requires_grad = Truepnet_target.update(pnet)return losspBATCH_SIZE = 64
NSTEPS = 1000000
NBUFFER = 100000
GAMMA = 0.99
REG = 0.1
NTRAIN = 2
env = NormalizedActions(gym.make("Pendulum-v1", render_mode='human'))
buffer = ExpReplayBuffer(NBUFFER)pnet = PolicyNet(env.observation_space.shape[0], env.action_space.shape[0])
pnet_target = PolicyNet(env.observation_space.shape[0], env.action_space.shape[0])
vnet = TwinDQN(env.observation_space.shape[0], env.action_space.shape[0])
vnet_target = TwinDQN(env.observation_space.shape[0], env.action_space.shape[0])
# pnet.cuda()
# pnet_target.cuda()
pnet_target.load_state_dict(pnet.state_dict())
# vnet.cuda()
# vnet_target.cuda()
vnet_target.load_state_dict(vnet.state_dict())optim_p = torch.optim.Adam(pnet.parameters(), lr=1e-3)
optim_v = torch.optim.Adam(vnet.parameters(), lr=1e-3)all_rewards = []
all_losses = []
episode_reward = 0
loss = 0.0state = env.reset()
for nstep in range(NSTEPS):if isinstance(state, tuple):state = state[0]state_t = torch.tensor(state, dtype=torch.float32).unsqueeze(0)action = pnet.act(state_t)next_state, reward, done, _, _ = env.step(action)buffer.push(state, action, reward, next_state, done)state = next_stateepisode_reward += rewardif done:state = env.reset()all_rewards.append(episode_reward)episode_reward = 0if len(buffer) >= BATCH_SIZE:loss = train(buffer, pnet, pnet_target, vnet, vnet_target, optim_p, optim_v, (nstep+1)%NTRAIN == 0)