偏导数和梯度
1. 背景与引入
历史来源与重要性
偏导数和梯度是多元微积分的核心概念,起源于18-19世纪对多变量函数的研究。数学家如欧拉、拉格朗日和哈密顿在研究物理问题(如力学和场论)时发展了相关理论。在现代机器学习中,它们是优化算法的基石,尤其在神经网络训练中,通过反向传播算法高效计算损失函数的梯度,从而调整模型参数。
实际问题与类比
问题场景:假设你在训练一个房价预测模型,模型的误差(损失函数)由多个参数(如房屋面积、地理位置权重)决定。如何快速找到一组参数使误差最小?
类比:想象站在山地的浓雾中,只能看到脚下局部地面的坡度。你需要根据每一步的“下坡方向”(梯度)决定移动方向,最终到达谷底(最小值)。偏导数告诉你每个方向的陡峭程度,梯度则指向下坡最快的综合方向。
学习目标
学完本节后,你将能够:
- 理解偏导数如何描述多变量函数在单一方向的变化率;
- 掌握梯度的定义及其几何意义(最快上升方向);
- 为后续学习梯度下降法、反向传播等机器学习优化技术奠定基础。
2. 核心概念与定义
偏导数(Partial Derivative)
定义:
对于多变量函数 f ( x 1 , x 2 , . . . , x n ) f(x_1, x_2, ..., x_n) f(x1,x2,...,xn),其偏导数 ∂ f ∂ x i \frac{\partial f}{\partial x_i} ∂xi∂f表示固定其他变量,仅让变量 x i x_i xi微小变化时,函数值的变化率。
数学形式:
∂ f ∂ x i = lim h → 0 f ( x 1 , . . . , x i + h , . . . , x n ) − f ( x 1 , . . . , x i , . . . , x n ) h \frac{\partial f}{\partial x_i} = \lim_{h \to 0} \frac{f(x_1, ..., x_i + h, ..., x_n) - f(x_1, ..., x_i, ..., x_n)}{h} ∂xi∂f=h→0limhf(x1,...,xi+h,...,xn)−f(x1,...,xi,...,xn)
核心思想:
偏导数衡量的是单一输入变量对输出的影响,就像调节空调温度时,只关注温度变化对房间舒适度的影响,而忽略湿度等其他因素。
例子:
假设房价预测模型为 f ( 面积 , 距离地铁 ) = 5 × 面积 − 3 × 距离地铁 f(\text{面积}, \text{距离地铁}) = 5 \times \text{面积} - 3 \times \text{距离地铁} f(面积,距离地铁)=5×面积−3×距离地铁。
- 对“面积”的偏导数 ∂ f ∂ 面积 = 5 \frac{\partial f}{\partial \text{面积}} = 5 ∂面积∂f=5,表示每增加1平方米,房价平均上涨5单位。
- 对“距离地铁”的偏导数 ∂ f ∂ 距离地铁 = − 3 \frac{\partial f}{\partial \text{距离地铁}} = -3 ∂距离地铁∂f=−3,表示每远离地铁100米,房价下降3单位。
几何意义:
在三维图像中,偏导数对应曲面在某一坐标轴方向的切线斜率。例如,固定“距离地铁”为100米,函数在“面积”方向的切线斜率为5。
梯度(Gradient)
定义:
梯度是函数的所有偏导数构成的向量,记作 ∇ f \nabla f ∇f,即:
∇ f = ( ∂ f ∂ x 1 , ∂ f ∂ x 2 , . . . , ∂ f ∂ x n ) \nabla f = \left( \frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}, ..., \frac{\partial f}{\partial x_n} \right) ∇f=(∂x1∂f,∂x2∂f,...,∂xn∂f)
它指向函数值增长最快的方向,大小表示增长的速率。
核心思想:
梯度像一个“导航仪”,告诉你在多维空间中往哪个方向走能最快提升函数值(或下降最快,取负方向)。例如,盲人摸象时,梯度会告诉他脚下哪边最陡峭。
例子:
继续房价模型 f ( 面积 , 距离地铁 ) f(\text{面积}, \text{距离地铁}) f(面积,距离地铁),若当前参数为(面积=80㎡,距离地铁=500米),梯度为$\nabla f = (5, -3) $:
- 向量方向表示:增加面积或减少距离地铁(即靠近地铁)会使房价上升。
- 负梯度方向 ( − 5 , 3 ) (-5, 3) (−5,3)表示房价下降最快的方向,即减少面积或靠近地铁。
几何意义:
在三维图像中,梯度是曲面在某点处切平面的倾斜方向。例如,在山丘地形图中,梯度指向最陡峭的上坡方向,负梯度指向最陡峭的下坡方向。
关键联系
- 偏导数是梯度的“零件”:梯度由所有偏导数组成。
- 梯度方向综合了所有变量的变化率,是优化算法(如梯度下降)的核心依据。
3. 拆解与解读
偏导数的拆解与解读
定义拆解
偏导数公式:
∂ f ∂ x i = lim h → 0 f ( x 1 , . . . , x i + h , . . . , x n ) − f ( x 1 , . . . , x i , . . . , x n ) h \frac{\partial f}{\partial x_i} = \lim_{h \to 0} \frac{f(x_1, ..., x_i + h, ..., x_n) - f(x_1, ..., x_i, ..., x_n)}{h} ∂xi∂f=h→0limhf(x1,...,xi+h,...,xn)−f(x1,...,xi,...,xn)
可拆解为以下4个关键部分:
-
多变量函数$f(x_1, …, x_n) $
- 解读:输出值由多个输入变量共同决定。
- 类比:像一个蛋糕的甜度由糖量、烘烤时间、烤箱温度等多个因素决定。
-
固定其他变量
- 解读:研究某一个变量(如$x_i $)对输出的影响时,暂时“冻结”其他变量。
- 类比:调节空调时,只关注温度变化对舒适度的影响,而暂时忽略湿度、风速等因素。
-
变化率: Δ f Δ x i \frac{Δf}{Δx_i} ΔxiΔf
- 解读:输入变量 x i x_i xi微小变化( h h h)引起的函数值变化( Δ f Δf Δf)的比例。
- 类比:类似汽车速度表显示的“瞬时速度”——当前时刻每秒行驶的距离。
-
极限 h → 0 h \to 0 h→0
- 解读:关注“无限小”的变化,排除宏观变化中的非线性干扰。
- 类比:放大镜观察曲线的局部切线,忽略远处的弯曲。
逻辑联系
多变量函数 → 固定其他变量 → 计算单一变量的微小变化率 → 通过极限消除误差 → 得到精确的偏导数值。
梯度的拆解与解读
定义拆解
梯度公式:
∇ f = ( ∂ f ∂ x 1 , ∂ f ∂ x 2 , . . . , ∂ f ∂ x n ) \nabla f = \left( \frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}, ..., \frac{\partial f}{\partial x_n} \right) ∇f=(∂x1∂f,∂x2∂f,...,∂xn∂f)
可拆解为以下3个关键部分:
-
由偏导数组成的向量
- 解读:将每个变量的偏导数按顺序排列成箭头状的向量。
- 类比:像导航仪显示的“方向箭头”,每个偏导数代表一个维度上的“导航力度”。
-
方向:最快上升方向
- 解读:梯度箭头指向函数值增长最快的方向。
- 类比:站在山坡上,梯度箭头指向最陡峭的上坡方向;负梯度箭头指向最陡峭的下坡方向。
-
大小:增长率
- 解读:梯度的长度表示沿该方向的上升速率。
- 类比:箭头越长,表示“爬坡越吃力”;箭头越短,表示“坡度越缓”。
逻辑联系
偏导数 → 每个维度的变化率 → 组合成方向箭头 → 梯度方向 = 所有维度变化率的“合力方向”。
关键联系的深度解读
1. 偏导数与梯度的“零件-成品”关系
- 偏导数是梯度的“零件”:每个偏导数描述单一维度的变化,而梯度是这些变化率的“组装成品”。
- 类比:像自行车的齿轮(偏导数)和整个传动系统(梯度)——齿轮单独工作,但组合后驱动整车前进。
2. 方向选择的数学本质
- 为什么梯度是最快上升方向?
- 数学证明:方向导数的最大值出现在梯度方向,因为梯度综合了所有偏导数的“贡献”。
- 直觉理解:想象在山坡上,若向东偏北方向走,既利用东侧的陡峭,又结合北侧的坡度,总上升速度最快。
3. 负梯度与优化的关联
- 机器学习的目标是最小化损失函数,因此需沿负梯度方向更新参数。
- 类比:下山时,盲人摸象者会沿最陡的下坡方向(负梯度)移动,以最快到达谷底。
总结:从局部到全局的逻辑链条
- 单变量导数(一维变化率)
→ 偏导数(多维中单变量变化率)
→ 梯度(多维变化率的综合方向) - 局部信息(偏导数)
→ 全局决策(梯度方向)
→ 优化路径(负梯度下降)
通过这种拆解,读者能清晰理解:偏导数是梯度的“基石”,梯度是优化的“指南针”。
4. 几何意义与图形化展示
1. 偏导数的几何意义
核心思想:
偏导数是函数曲面在某一坐标轴方向的切线斜率。
示例函数:
f ( x , y ) = − x 2 − 0.5 y 2 + 4 f(x, y) = -x^2 - 0.5y^2 + 4 f(x,y)=−x2−0.5y2+4
(一个开口向下的抛物面,顶点在原点)
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D# 定义函数
def f(x, y):return -x**2 - 0.5*y**2 + 4# 生成网格数据
x = np.linspace(-2, 2, 100)
y = np.linspace(-2, 2, 100)
X, Y = np.meshgrid(x, y)
Z = f(X, Y)# 创建3D图形
fig = plt.figure(figsize=(12, 6))# 子图1:三维曲面与偏导数切线
ax1 = fig.add_subplot(121, projection='3d')
ax1.plot_surface(X, Y, Z, cmap='viridis', alpha=0.7)
ax1.set_title("Figure-1: 偏导数的几何意义")
ax1.set_xlabel("x")
ax1.set_ylabel("y")
ax1.set_zlabel("f(x, y)")# 在点 (1, 0) 处绘制偏导数切线
x0, y0 = 1, 0
z0 = f(x0, y0)# 计算偏导数 ∂f/∂x = -2x → -2*1 = -2
h = 0.1
x_line = np.array([x0 - h, x0 + h])
y_line = np.array([y0, y0])
z_line = f(x_line, y_line)ax1.plot(x_line, y_line, z_line, color='red', linewidth=3, label="∂f/∂x 切线")
ax1.legend()# 子图2:等高线图与梯度方向
ax2 = fig.add_subplot(122)
contour = ax2.contour(X, Y, Z, levels=10, cmap='viridis')
ax2.clabel(contour, inline=True, fontsize=8)
ax2.set_title("Figure-2: 梯度的几何意义")
ax2.set_xlabel("x")
ax2.set_ylabel("y")# 计算梯度 ∇f = (-2x, -y) → 在点 (1, 1) 处为 (-2, -1)
x_grad = -2 * X
y_grad = -Y# 在点 (1, 1) 绘制梯度箭头
ax2.quiver(1, 1, -2, -1, color='red', scale=10, label="梯度方向")
ax2.legend()
plt.show()
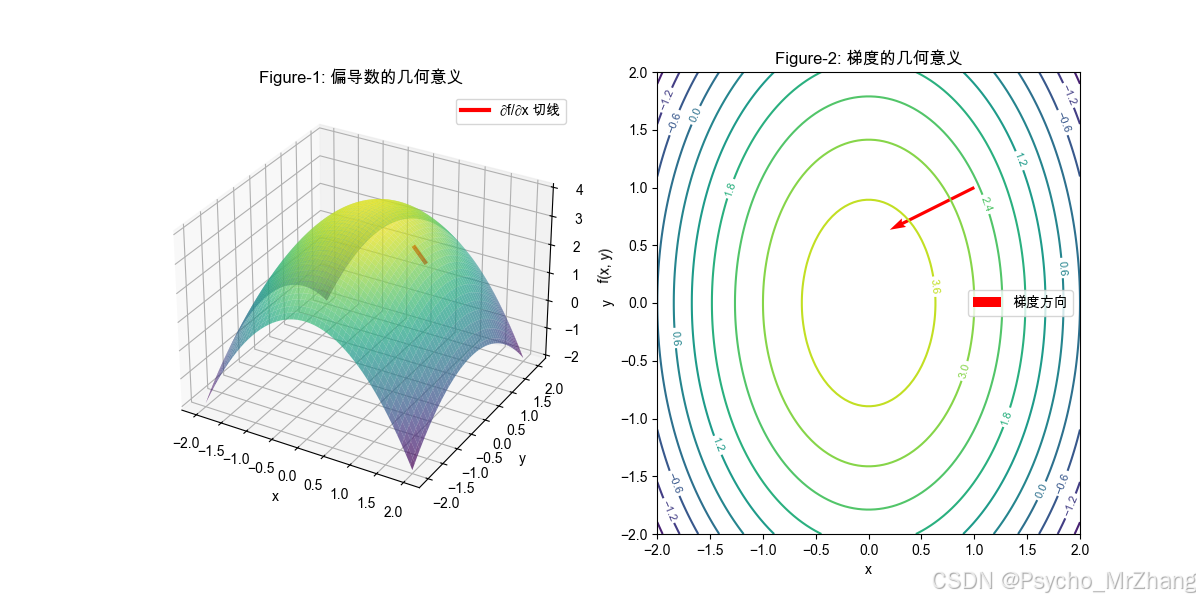
2. 图形解读
Figure-1(三维曲面):
- 曲面形状:类似倒置的碗,顶点在原点(最大值)。
- 红色切线:在点 ( 1 , 0 ) (1, 0) (1,0)处,固定 y = 0 y=0 y=0,沿 x x x方向的切线斜率为 ∂ f ∂ x = − 2 x = − 2 \frac{\partial f}{\partial x} = -2x = -2 ∂x∂f=−2x=−2。
- 切线向右($ x$增加方向)时,函数值下降,符合负斜率特性。
Figure-2(等高线图):
- 等高线:椭圆形闭合曲线,越靠近中心函数值越大(颜色越深)。
- 红色箭头:梯度向量 ∇ f = ( − 2 x , − y ) \nabla f = (-2x, -y) ∇f=(−2x,−y)在点 ( 1 , 1 ) (1, 1) (1,1)处指向 ( − 2 , − 1 ) (-2, -1) (−2,−1),即左下方。
- 方向意义:梯度方向是函数值上升最快的方向,但此处箭头指向低值区域,说明梯度实际指向“最快上升”,负梯度才是“最快下降”。
- 垂直性:梯度箭头与等高线垂直,验证了“梯度方向与等高线切线正交”的数学性质。
3. 关键几何性质总结
| 概念 | 几何意义 | 图形表现 |
|---|---|---|
| 偏导数 | 固定其他变量时,函数在单一方向的切线斜率 | 三维图中红色切线的陡峭程度 |
| 梯度 | 所有偏导数组成的向量,指向函数值上升最快方向 | 等高线图中垂直于等高线的箭头方向 |
4. 与优化的联系
- 梯度下降法:在机器学习中,损失函数的优化目标是最小值。
- 几何操作:从初始点出发,沿负梯度方向(与红色箭头相反)逐步移动,最终到达谷底(最小值)。
- 类比:盲人沿最陡峭的下坡方向下山(负梯度),避免绕路或爬坡。
5. 总结
通过三维曲面和二维等高线图的结合:
- 偏导数对应局部切线的陡峭程度;
- 梯度方向综合所有偏导数,指向最快上升方向;
- 等高线图直观展示了梯度与函数变化率的关系。
这些图形化工具帮助将抽象的数学概念转化为可操作的几何直觉,为后续优化算法奠定基础。
5. 常见形式与变换
1. 偏导数的不同表达形式
偏导数的核心思想是“固定其他变量,仅研究单一变量对函数值的影响”,但其表达形式可能因场景不同而有所变化。以下是三种常见形式:
(1) 标准偏导数符号
形式:
∂ f ∂ x i \frac{\partial f}{\partial x_i} ∂xi∂f
含义:
直接对函数 f ( x 1 , x 2 , . . . , x n ) f(x_1, x_2, ..., x_n) f(x1,x2,...,xn)中的第 i i i个变量求导,其他变量视为常数。
适用场景:
- 多变量函数的局部变化率分析(如经济学中的边际成本)。
- 机器学习中反向传播算法的链式法则计算。
示例:
函数 f ( x , y ) = x 2 + x y + y 3 f(x, y) = x^2 + xy + y^3 f(x,y)=x2+xy+y3的偏导数:
∂ f ∂ x = 2 x + y , ∂ f ∂ y = x + 3 y 2 \frac{\partial f}{\partial x} = 2x + y, \quad \frac{\partial f}{\partial y} = x + 3y^2 ∂x∂f=2x+y,∂y∂f=x+3y2
(2) 向量微分算子(梯度)
形式:
∇ f = ( ∂ f ∂ x 1 , ∂ f ∂ x 2 , . . . , ∂ f ∂ x n ) \nabla f = \left( \frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}, ..., \frac{\partial f}{\partial x_n} \right) ∇f=(∂x1∂f,∂x2∂f,...,∂xn∂f)
含义:
将所有偏导数按顺序排列成向量,表示函数值上升最快的方向。
适用场景:
- 优化算法(如梯度下降法)。
- 物理场论中的势能梯度(如电场强度是电势的负梯度)。
示例:
函数 f ( x , y ) = x 2 + y 2 f(x, y) = x^2 + y^2 f(x,y)=x2+y2的梯度:
∇ f = ( 2 x , 2 y ) \nabla f = (2x, 2y) ∇f=(2x,2y)
在点 ( 1 , 1 ) (1, 1) (1,1)处,梯度为 ( 2 , 2 ) (2, 2) (2,2),指向右上方。
(3) 极坐标下的梯度表达
形式:
在二维极坐标 ( r , θ ) (r, \theta) (r,θ)下:
∇ f = ∂ f ∂ r e r + 1 r ∂ f ∂ θ e θ \nabla f = \frac{\partial f}{\partial r} \mathbf{e}_r + \frac{1}{r} \frac{\partial f}{\partial \theta} \mathbf{e}_\theta ∇f=∂r∂fer+r1∂θ∂feθ
含义:
-$\frac{\partial f}{\partial r} :沿径向的变化率。 − :沿径向的变化率。 - :沿径向的变化率。−\frac{1}{r} \frac{\partial f}{\partial \theta} :沿切向的变化率(需归一化半径 :沿切向的变化率(需归一化半径 :沿切向的变化率(需归一化半径r $)。
适用场景:
- 圆形或旋转对称问题(如流体力学中的涡旋场)。
- 图像处理中的极坐标滤波器设计。
示例:
函数 f ( r , θ ) = r 2 f(r, \theta) = r^2 f(r,θ)=r2的梯度:
∇ f = 2 r e r + 0 ⋅ e θ \nabla f = 2r \mathbf{e}_r + 0 \cdot \mathbf{e}_\theta ∇f=2rer+0⋅eθ
表示梯度仅沿径向方向,与直角坐标系结果一致。
2. 形式之间的联系
| 形式 | 数学本质 | 适用场景 | 转换关系 |
|---|---|---|---|
| 标准偏导数 | 单变量变化率 | 局部分析 | 梯度的“零件” |
| 向量微分算子 | 多变量变化率的综合方向 | 优化与物理场论 | 所有偏导数组成向量 |
| 极坐标梯度 | 曲线坐标系下的梯度表达 | 旋转对称问题 | 通过坐标变换与直角坐标关联 |
核心一致性:
所有形式均描述“函数值的变化率”,仅因坐标系或应用场景不同而采用不同表达方式。
3. 图形化对比
以下代码绘制同一函数在直角坐标系和极坐标系下的梯度方向,验证形式一致性。
import numpy as np
import matplotlib.pyplot as plt# 定义函数 f(x, y) = x² + y²
def f(x, y):return x**2 + y**2# 直角坐标系梯度
def grad_cartesian(x, y):return 2*x, 2*y# 极坐标系梯度
def grad_polar(r, theta):df_dr = 2*rdf_dtheta = 0return df_dr, df_dtheta# 生成网格数据
x = np.linspace(-2, 2, 20)
y = np.linspace(-2, 2, 20)
X, Y = np.meshgrid(x, y)# 计算直角坐标梯度
U_cart, V_cart = grad_cartesian(X, Y)# 转换为极坐标
R = np.sqrt(X**2 + Y**2)
Theta = np.arctan2(Y, X)# 计算极坐标梯度
df_dr, df_dtheta = grad_polar(R, Theta)
# 转换回直角坐标系以绘制箭头
U_polar = df_dr * np.cos(Theta) - df_dtheta * np.sin(Theta)
V_polar = df_dr * np.sin(Theta) + df_dtheta * np.cos(Theta)# 绘制图形
plt.figure(figsize=(12, 6))# 子图1:直角坐标梯度
plt.subplot(121)
plt.quiver(X, Y, U_cart, V_cart, color='blue')
plt.title("Figure-1: 直角坐标梯度")
plt.xlabel("x")
plt.ylabel("y")
plt.axis('equal')# 子图2:极坐标梯度
plt.subplot(122)
plt.quiver(X, Y, U_polar, V_polar, color='red')
plt.title("Figure-2: 极坐标梯度")
plt.xlabel("x")
plt.ylabel("y")
plt.axis('equal')plt.tight_layout()
plt.show()
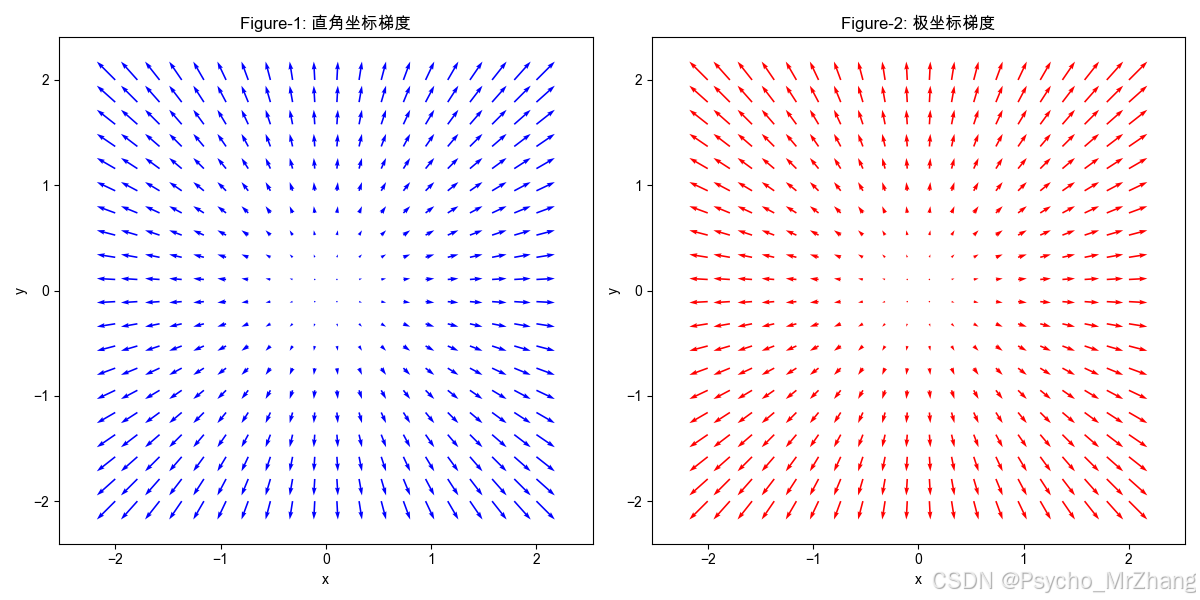
4. 图形解读
-
Figure-1(直角坐标梯度):
箭头指向径向方向(远离原点),长度随距离增加而增大,符合梯度 ∇ f = ( 2 x , 2 y ) \nabla f = (2x, 2y) ∇f=(2x,2y)的特性。 -
Figure-2(极坐标梯度):
箭头同样指向径向方向,与直角坐标结果一致,验证了不同坐标系下梯度方向的一致性。
关键结论:
- 尽管表达形式不同,但梯度方向始终保持一致(径向)。
- 极坐标形式通过坐标变换保留了直角坐标的几何意义。
5. 应用场景与选择建议
-
标准偏导数:
- 适用:单变量敏感性分析(如金融模型中利率对收益的影响)。
- 优势:直观且易于计算。
-
向量微分算子:
- 适用:机器学习优化(如神经网络参数更新)。
- 优势:统一多变量方向信息,便于编程实现。
-
极坐标梯度:
- 适用:旋转对称系统(如天体轨道力学、电磁场分析)。
- 优势:简化复杂对称问题的数学表达。
6. 总结
- 本质一致性:所有形式均描述函数值的变化率,仅因坐标系或需求不同而采用不同表达。
- 形式多样性:从单变量偏导数到向量梯度,再到极坐标梯度,覆盖了从基础分析到高级应用的广泛场景。
- 实践选择:根据问题对称性(如旋转对称)或计算需求(如优化方向)选择合适形式。
6. 实际应用场景
1. 机器学习:梯度下降法优化神经网络参数
问题描述:
在训练神经网络时,需要最小化损失函数$L(\mathbf{w}) (如均方误差),其中 (如均方误差),其中 (如均方误差),其中\mathbf{w}$是模型参数。如何高效调整参数以降低损失?
解决步骤:
- 定义损失函数:
假设损失函数为 L ( w 1 , w 2 ) = ( w 1 2 + w 2 2 − 4 ) 2 L(w_1, w_2) = (w_1^2 + w_2^2 - 4)^2 L(w1,w2)=(w12+w22−4)2,其最小值在 w 1 2 + w 2 2 = 4 w_1^2 + w_2^2 = 4 w12+w22=4的圆环上。 - 计算梯度:
梯度为 ∇ L = ( ∂ L ∂ w 1 , ∂ L ∂ w 2 ) = ( 4 w 1 ( w 1 2 + w 2 2 − 4 ) , 4 w 2 ( w 1 2 + w 2 2 − 4 ) ) \nabla L = \left( \frac{\partial L}{\partial w_1}, \frac{\partial L}{\partial w_2} \right) = \left( 4w_1(w_1^2 + w_2^2 - 4), 4w_2(w_1^2 + w_2^2 - 4) \right) ∇L=(∂w1∂L,∂w2∂L)=(4w1(w12+w22−4),4w2(w12+w22−4))。 - 梯度下降更新规则:
参数更新公式:
w t + 1 = w t − η ⋅ ∇ L ( w t ) \mathbf{w}_{t+1} = \mathbf{w}_t - \eta \cdot \nabla L(\mathbf{w}_t) wt+1=wt−η⋅∇L(wt)
其中 η \eta η是学习率(如$\eta = 0.01 $)。 - 迭代优化:
从初始点 w 0 = ( 3 , 3 ) \mathbf{w}_0 = (3, 3) w0=(3,3)开始,沿负梯度方向逐步逼近最小值。
图形化展示:
import numpy as np
import matplotlib.pyplot as plt# 定义损失函数
def loss(w1, w2):return (w1**2 + w2**2 - 4)**2# 梯度计算
def gradient(w1, w2):dL_dw1 = 4 * w1 * (w1**2 + w2**2 - 4)dL_dw2 = 4 * w2 * (w1**2 + w2**2 - 4)return np.array([dL_dw1, dL_dw2])# 梯度下降
def gradient_descent(eta=0.01, steps=50):path = []w = np.array([3.0, 3.0]) # 初始点for _ in range(steps):path.append(w.copy())grad = gradient(w[0], w[1])w -= eta * gradreturn np.array(path)# 可视化
w1 = np.linspace(-4, 4, 100)
w2 = np.linspace(-4, 4, 100)
W1, W2 = np.meshgrid(w1, w2)
L = loss(W1, W2)path = gradient_descent()
plt.figure(figsize=(8, 6))
contour = plt.contour(W1, W2, L, levels=20, cmap='viridis')
plt.clabel(contour, inline=True, fontsize=8)
plt.plot(path[:, 0], path[:, 1], 'r.-', label="优化路径")
plt.scatter(3, 3, color='black', label="起点")
plt.title("Figure-1: 梯度下降优化路径")
plt.xlabel("w1")
plt.ylabel("w2")
plt.legend()
plt.grid(True)
plt.show()
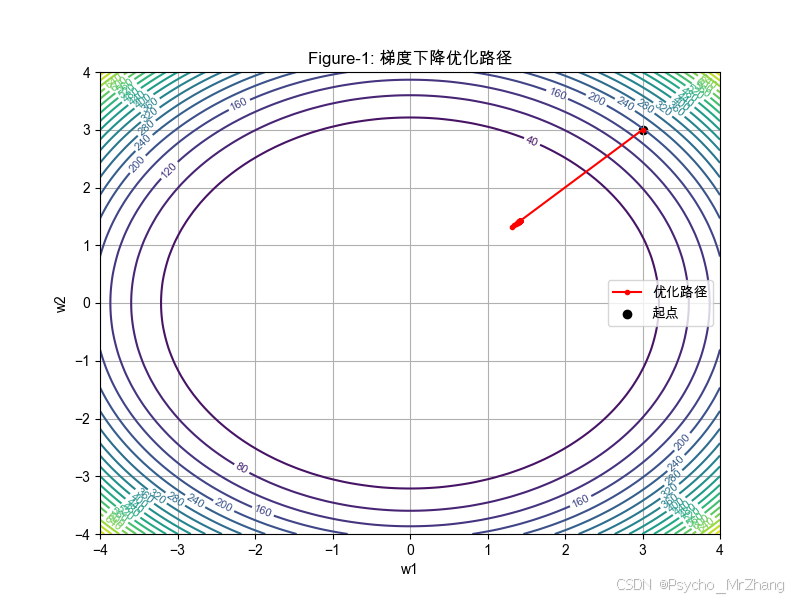
图形解读:
- 等高线表示损失函数的值,越靠近中心(圆环)损失越小。
- 红色路径表示参数沿负梯度方向逐步收敛到目标区域。
- 关键性质:梯度方向垂直于等高线,负梯度方向指向损失减小最快的方向。
2. 图像处理:基于梯度的边缘检测
问题描述:
如何自动识别图像中的物体边界(如人脸轮廓)?边缘通常是图像亮度变化最剧烈的区域,而梯度可以量化这种变化。
解决步骤:
- 图像灰度化:将彩色图像转换为灰度图像 I ( x , y ) I(x, y) I(x,y),其中 x , y x, y x,y是像素坐标。
- 计算梯度幅值与方向:
- 水平偏导数(Sobel核):
G x = [ − 1 0 1 − 2 0 2 − 1 0 1 ] G_x = \begin{bmatrix} -1 & 0 & 1 \\ -2 & 0 & 2 \\ -1 & 0 & 1 \end{bmatrix} Gx= −1−2−1000121 - 垂直偏导数(Sobel核):
G y = [ − 1 − 2 − 1 0 0 0 1 2 1 ] G_y = \begin{bmatrix} -1 & -2 & -1 \\ 0 & 0 & 0 \\ 1 & 2 & 1 \end{bmatrix} Gy= −101−202−101 - 梯度幅值:$ G = \sqrt{G_x^2 + G_y^2}$
- 梯度方向:$ \theta = \arctan\left(\frac{G_y}{G_x}\right)$
- 水平偏导数(Sobel核):
- 非极大值抑制:保留梯度方向上局部最大值,抑制其他像素。
- 双阈值检测:区分强边缘、弱边缘和非边缘。
图形化展示:
import cv2
import matplotlib.pyplot as plt# 读取图像并灰度化
image = cv2.imread('face.jpg', 0)# Sobel算子计算梯度
grad_x = cv2.Sobel(image, cv2.CV_64F, 1, 0, ksize=3)
grad_y = cv2.Sobel(image, cv2.CV_64F, 0, 1, ksize=3)# 梯度幅值与方向
gradient_magnitude = np.sqrt(grad_x**2 + grad_y**2)
gradient_direction = np.arctan2(grad_y, grad_x)# 非极大值抑制(简化版)
edge_image = np.zeros_like(gradient_magnitude)
for i in range(1, image.shape[0]-1):for j in range(1, image.shape[1]-1):angle = gradient_direction[i, j] * 180 / np.piif (angle < 22.5 or angle > 157.5):neighbor1 = gradient_magnitude[i, j+1]neighbor2 = gradient_magnitude[i, j-1]elif (22.5 <= angle < 67.5):neighbor1 = gradient_magnitude[i-1, j+1]neighbor2 = gradient_magnitude[i+1, j-1]elif (67.5 <= angle < 112.5):neighbor1 = gradient_magnitude[i-1, j]neighbor2 = gradient_magnitude[i+1, j]else:neighbor1 = gradient_magnitude[i-1, j-1]neighbor2 = gradient_magnitude[i+1, j+1]if gradient_magnitude[i, j] >= neighbor1 and gradient_magnitude[i, j] >= neighbor2:edge_image[i, j] = gradient_magnitude[i, j]# 可视化
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.imshow(image, cmap='gray')
plt.title("Figure-2a: 原始图像")
plt.axis('off')plt.subplot(122)
plt.imshow(edge_image, cmap='viridis')
plt.title("Figure-2b: 边缘检测结果")
plt.axis('off')
plt.show()
图形解读:
- Figure-2a:原始灰度图像,包含人脸和背景。
- Figure-2b:边缘检测结果中,人脸轮廓、眼睛和嘴巴的边界被清晰提取。
- 梯度方向:边缘处的梯度方向垂直于边界,幅值越大表示边界越明显。
3. 关键应用场景总结
| 应用领域 | 核心思想 | 数学工具 | 优势与局限性 |
|---|---|---|---|
| 机器学习 | 沿负梯度方向更新参数 | 梯度下降法 | 收敛快,但可能陷入局部最优 |
| 图像处理 | 梯度幅值检测边缘强度 | Sobel算子、梯度方向 | 实时性强,但对噪声敏感 |
4. 总结
- 梯度下降法:通过负梯度方向逐步逼近损失函数最小值,是神经网络训练的核心算法。
- 边缘检测:梯度幅值反映图像亮度变化强度,方向指示边缘走向,广泛应用于计算机视觉。
- 通用性:偏导数和梯度不仅是数学工具,更是连接理论与实际应用的桥梁,适用于优化、信号处理、物理建模等多个领域。
7. Python 代码实现
1. 计算偏导数与梯度
目标:
- 计算多变量函数的偏导数和梯度向量。
- 可视化梯度场(Gradient Field),展示不同位置的梯度方向与大小。
import numpy as np
import matplotlib.pyplot as plt# Step 1: 定义多变量函数
def f(x, y):return x**2 + y**2 # 示例函数:f(x, y) = x² + y²# Step 2: 计算偏导数(数值方法)
def partial_derivative(func, var, point, h=1e-5):"""计算偏导数(中心差分法):param func: 函数 f(x, y):param var: 求导变量索引 (0=x, 1=y):param point: 点 (x, y):param h: 微小步长:return: 偏导数值"""if var == 0:return (func(point[0] + h, point[1]) - func(point[0] - h, point[1])) / (2*h)else:return (func(point[0], point[1] + h) - func(point[0], point[1] - h)) / (2*h)# Step 3: 计算梯度向量
def gradient(func, point):"""计算梯度向量 ∇f = (∂f/∂x, ∂f/∂y)"""df_dx = partial_derivative(func, 0, point)df_dy = partial_derivative(func, 1, point)return np.array([df_dx, df_dy])# Step 4: 生成网格数据并计算梯度场
x = np.linspace(-2, 2, 20)
y = np.linspace(-2, 2, 20)
X, Y = np.meshgrid(x, y)
U, V = np.zeros_like(X), np.zeros_like(Y)for i in range(X.shape[0]):for j in range(X.shape[1]):point = (X[i, j], Y[i, j])grad = gradient(f, point)U[i, j] = grad[0] # ∂f/∂xV[i, j] = grad[1] # ∂f/∂y# Step 5: 可视化梯度场
plt.figure(figsize=(8, 6))
plt.quiver(X, Y, U, V, color='blue')
plt.title("Figure-1: 梯度场 ∇f = (2x, 2y)")
plt.xlabel("x")
plt.ylabel("y")
plt.grid(True)
plt.axis('equal')
plt.show()
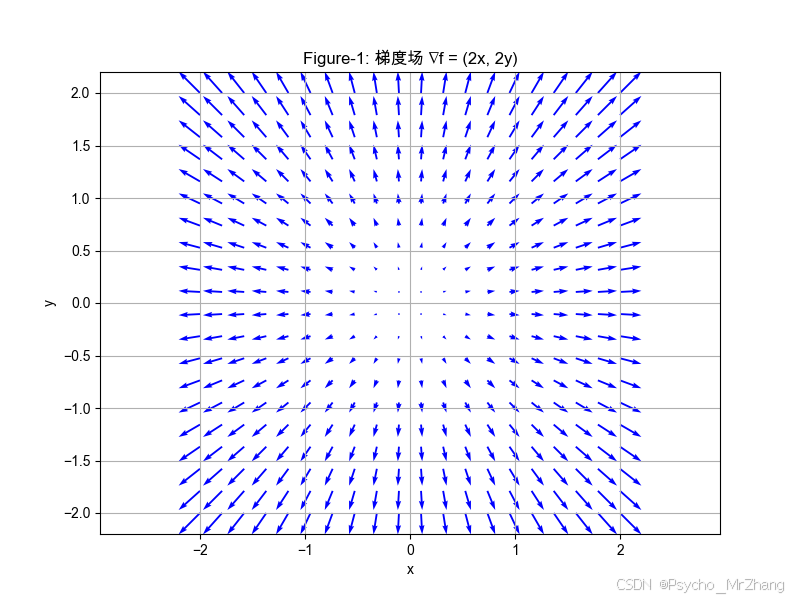
代码解读:
partial_derivative:使用中心差分法(精度更高)计算偏导数。gradient:将两个偏导数组合成梯度向量。quiver:绘制箭头图,箭头方向表示梯度方向,长度表示变化率大小。
图形解读:
- 箭头指向函数值上升最快的方向(径向远离原点)。
- 箭头长度随距离原点增加而变长,符合梯度 ∇ f = ( 2 x , 2 y ) \nabla f = (2x, 2y) ∇f=(2x,2y)的特性。
2. 梯度下降法优化路径可视化
目标:
- 实现梯度下降算法,展示参数更新路径。
- 对比不同学习率对收敛速度的影响。
# Step 1: 定义损失函数和梯度
def loss(x, y):return x**2 + y**2 # 目标函数def gradient(x, y):return np.array([2*x, 2*y]) # 梯度 ∇f = (2x, 2y)# Step 2: 梯度下降算法
def gradient_descent(start_point, learning_rate=0.1, steps=50):path = [start_point.copy()]for _ in range(steps):grad = gradient(path[-1][0], path[-1][1])new_point = path[-1] - learning_rate * gradpath.append(new_point)return np.array(path)# Step 3: 设置初始点和学习率
start_point = np.array([2.0, 2.0]) # 初始点 (2, 2)
learning_rates = [0.01, 0.1, 0.5] # 不同学习率对比# Step 4: 生成等高线图
x = np.linspace(-3, 3, 100)
y = np.linspace(-3, 3, 100)
X, Y = np.meshgrid(x, y)
Z = loss(X, Y)# Step 5: 绘制不同学习率的优化路径
plt.figure(figsize=(12, 8))
for i, lr in enumerate(learning_rates):path = gradient_descent(start_point, learning_rate=lr)plt.subplot(1, len(learning_rates), i+1)contour = plt.contour(X, Y, Z, levels=20, cmap='viridis')plt.clabel(contour, inline=True, fontsize=8)plt.plot(path[:, 0], path[:, 1], 'r.-', label=f"学习率={lr}")plt.scatter(start_point[0], start_point[1], color='black', label="起点")plt.scatter(0, 0, color='gold', label="最小值")plt.title(f"Figure-2a-c: 学习率={lr}")plt.xlabel("x")plt.ylabel("y")plt.legend()plt.grid(True)
plt.tight_layout()
plt.show()
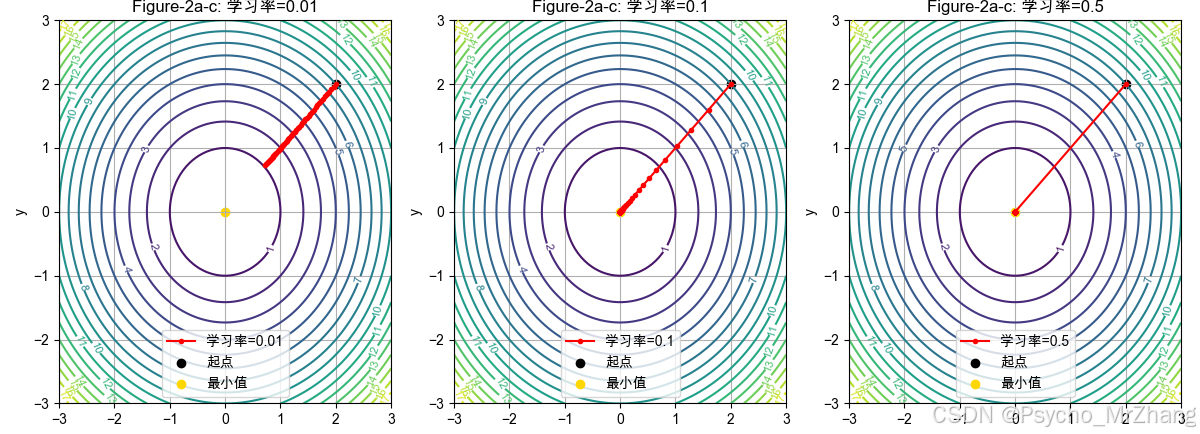
代码解读:
gradient_descent:从初始点出发,沿负梯度方向更新参数。- 学习率对比:
- 过小(0.01):收敛慢,路径密集。
- 适中(0.1):稳定收敛到最小值。
- 过大(0.5):震荡甚至发散,无法收敛。
图形解读:
- 红色路径表示参数沿负梯度方向移动。
- 金点(0,0)为函数最小值点,黑点为初始位置。
3. 关键应用场景总结
| 代码模块 | 功能 | 数学工具 | 适用场景 |
|---|---|---|---|
| 偏导数与梯度计算 | 数值计算梯度向量 | 中心差分法 | 任意可微函数的梯度分析 |
| 梯度场可视化 | 展示梯度方向与大小 | matplotlib.quiver | 多变量函数几何分析 |
| 梯度下降路径可视化 | 优化算法路径模拟 | 迭代更新规则 | 机器学习参数优化 |
4. 扩展建议
- 符号计算:使用
SymPy库自动求偏导数(无需手动推导)。 - 高维扩展:将代码推广到三维以上,结合
TensorFlow或PyTorch自动微分。 - 动态演示:使用
matplotlib.animation动态展示梯度下降过程。
通过以上代码,读者可以直观理解偏导数和梯度的计算方法,并掌握其在优化问题中的实际应用。
8. 总结与拓展
1. 核心知识点回顾
-
偏导数:
- 定义:固定其他变量,仅研究单一变量对函数值的影响。
- 作用:量化多变量函数在单个维度上的局部变化率。
- 示例:房价模型中“面积”对价格的敏感度(如$\frac{\partial f}{\partial \text{面积}} = 5 $)。
-
梯度:
- 定义:所有偏导数构成的向量,指向函数值上升最快的方向。
- 作用:综合多变量变化率,指导优化方向(如梯度下降法)。
- 几何意义:垂直于等高线,长度表示变化速率(如 ∇ f = ( 2 x , 2 y ) \nabla f = (2x, 2y) ∇f=(2x,2y)的径向箭头)。
-
形式与变换:
- 直角坐标梯度、极坐标梯度等形式一致,仅因坐标系不同而表达方式变化。
- 应用场景:机器学习(参数优化)、图像处理(边缘检测)、物理场论(电场方向)。
-
代码实现:
- 数值计算偏导数、梯度场可视化、梯度下降路径模拟,验证理论与实践的统一性。
2. 关键结论
-
数学本质:
- 偏导数是梯度的“零件”,梯度是偏导数的“组装成品”。
- 梯度方向是函数值变化最快的路径,负梯度方向用于最小化问题。
-
应用场景:
- 机器学习:梯度下降法优化神经网络参数(如更新公式$\mathbf{w}_{t+1} = \mathbf{w}_t - \eta \nabla L $)。
- 图像处理:Sobel算子基于梯度幅值提取边缘。
-
几何直觉:
- 三维曲面的切线斜率(偏导数)与二维等高线的垂直箭头(梯度)共同构建直观理解。
3. 进一步学习方向
以下方向为后续深入学习提供路径:
| 领域 | 进阶主题 |
|---|---|
| 数学基础 | - 高阶导数(Hessian矩阵): 描述函数曲率,用于牛顿法优化。 - 方向导数: 研究任意方向的变化率(梯度是其最大值方向)。 |
| 机器学习 | - 自动微分(AutoDiff): PyTorch/TensorFlow中的反向传播实现。 - 优化算法: Adam、RMSProp等自适应学习率方法。 |
| 图像处理 | - Canny边缘检测: 结合梯度幅值与非极大值抑制的工业标准算法。 - 卷积神经网络(CNN): 卷积核本质是图像梯度的加权组合。 |
| 物理与工程 | - 场论(如电场、引力场): 梯度描述势能变化方向(如$\mathbf{E} = -\nabla V $)。 - 流体动力学: 速度场的梯度分析。 |
| 高级数学工具 | - 拉格朗日乘数法: 带约束优化问题中梯度的平衡条件。 - 微分流形上的梯度: 非欧几何中的梯度定义(如球面梯度)。 |
4. 深层次问题思考
鼓励读者探索以下开放性问题:
-
梯度下降的局限性:
- 在非凸函数中容易陷入局部最优,如何改进?
- 学习率过大或过小会导致什么后果?能否动态调整?
-
梯度的几何扩展:
- 如何在球面、圆柱面等非欧空间中定义梯度?
- 梯度方向与曲面曲率的关系(如Hessian矩阵的特征值)。
-
高维空间的挑战:
- 在百万维参数空间中,梯度计算的效率瓶颈是什么?
- 如何处理梯度消失/爆炸问题(如ReLU激活函数的设计原理)?
-
物理与机器学习的交叉:
- 物理模拟中的梯度场如何启发神经网络设计?
- 基于能量函数的模型(如玻尔兹曼机)如何利用梯度优化?
5. 学习路径建议
- 数学强化:
- 学习《多元微积分》《优化理论》,掌握Hessian矩阵、方向导数等工具。
- 编程实践:
- 使用PyTorch/TensorFlow实现自动微分,对比数值梯度与符号梯度的差异。
- 应用拓展:
- 尝试图像边缘检测、神经网络训练等项目,结合理论与代码验证。
- 前沿探索:
- 阅读论文《深度学习中的优化方法》(如Adam算法)、《流形优化》等。
6. 总结
偏导数与梯度不仅是数学工具,更是连接理论与实际应用的桥梁:
- 从局部到全局:偏导数描述局部变化,梯度指引全局方向。
- 从理论到实践:梯度下降优化模型参数,图像梯度提取视觉特征。
- 从基础到前沿:掌握梯度本质后,可进一步探索高阶优化、物理建模、非欧几何等方向。
通过本节系统化学习,读者已具备扎实的梯度分析能力,可自信应对机器学习、图像处理、物理模拟等领域的核心挑战。
9. 练习与反馈
1. 基础题:偏导数与梯度计算
题目:
计算以下函数的偏导数和梯度向量:
f ( x , y ) = 3 x 2 y + sin ( x ) − e y f(x, y) = 3x^2y + \sin(x) - e^{y} f(x,y)=3x2y+sin(x)−ey
- (1) 求 ∂ f ∂ x \frac{\partial f}{\partial x} ∂x∂f和 ∂ f ∂ y \frac{\partial f}{\partial y} ∂y∂f。
- (2) 在点 ( 0 , 0 ) (0, 0) (0,0)处计算梯度 ∇ f \nabla f ∇f。
答案与提示:
- (1)
∂ f ∂ x = 6 x y + cos ( x ) , ∂ f ∂ y = 3 x 2 − e y \frac{\partial f}{\partial x} = 6xy + \cos(x), \quad \frac{\partial f}{\partial y} = 3x^2 - e^{y} ∂x∂f=6xy+cos(x),∂y∂f=3x2−ey - (2)
∇ f ( 0 , 0 ) = ( cos ( 0 ) , 3 ⋅ 0 2 − e 0 ) = ( 1 , − 1 ) \nabla f(0, 0) = \left( \cos(0), 3 \cdot 0^2 - e^{0} \right) = (1, -1) ∇f(0,0)=(cos(0),3⋅02−e0)=(1,−1)
提示:
- 对 x x x求偏导时,将 y y y视为常数;反之亦然。
- 三角函数和指数函数的导数规则需单独应用。
2. 提高题:梯度方向与等高线
题目:
已知函数 f ( x , y ) = x 2 + 2 y 2 f(x, y) = x^2 + 2y^2 f(x,y)=x2+2y2,其等高线图为椭圆。
- (1) 在点 ( 1 , 1 ) (1, 1) (1,1)处,梯度方向是否垂直于等高线?
- (2) 若沿梯度方向移动,函数值如何变化?
答案与提示:
- (1) 是垂直的。
- 梯度 ∇ f = ( 2 x , 4 y ) \nabla f = (2x, 4y) ∇f=(2x,4y),在 ( 1 , 1 ) (1, 1) (1,1)处为 ( 2 , 4 ) (2, 4) (2,4)。
- 等高线切线方向与梯度正交(可通过隐函数求导验证)。
- (2) 函数值会增加最快,因为梯度方向是上升最快的方向。
提示:
- 等高线方程为 x 2 + 2 y 2 = C x^2 + 2y^2 = C x2+2y2=C,对两边求导可得切线斜率。
- 梯度与切线方向向量的点积为零,说明垂直。
3. 挑战题:梯度下降路径分析
题目:
考虑函数 f ( x , y ) = ( x − 2 ) 2 + ( y − 3 ) 2 f(x, y) = (x - 2)^2 + (y - 3)^2 f(x,y)=(x−2)2+(y−3)2,使用梯度下降法从初始点 ( 0 , 0 ) (0, 0) (0,0)开始优化:
- (1) 写出梯度下降的更新公式(学习率为$\eta $)。
- (2) 分析参数路径是否会收敛到最小值点 ( 2 , 3 ) (2, 3) (2,3)。
答案与提示:
- (1)
∇ f = ( 2 ( x − 2 ) , 2 ( y − 3 ) ) , { x t + 1 = x t − 2 η ( x t − 2 ) y t + 1 = y t − 2 η ( y t − 3 ) \nabla f = \big(2(x - 2), 2(y - 3)\big), \quad \begin{cases} x_{t+1} = x_t - 2\eta(x_t - 2) \\ y_{t+1} = y_t - 2\eta(y_t - 3) \end{cases} ∇f=(2(x−2),2(y−3)),{xt+1=xt−2η(xt−2)yt+1=yt−2η(yt−3) - (2) 会收敛。
- 这是一个凸函数,梯度下降在适当学习率下可收敛到全局最小值。
- 若 η < 0.5 \eta < 0.5 η<0.5,参数会逐步逼近 ( 2 , 3 ) (2, 3) (2,3)。
提示:
- 将更新公式改写为线性系统,分析迭代矩阵的收敛性。
- 学习率过大可能导致震荡或发散。
4. 编程实践题:数值梯度与可视化
题目:
使用 Python 完成以下任务:
- (1) 定义函数 f ( x , y ) = sin ( x ) ⋅ cos ( y ) f(x, y) = \sin(x) \cdot \cos(y) f(x,y)=sin(x)⋅cos(y)。
- (2) 计算其数值梯度(使用
np.gradient)。 - (3) 可视化梯度场(箭头图)和函数曲面(三维图)。
答案与提示:
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D# Step 1: 定义函数
def f(x, y):return np.sin(x) * np.cos(y)# Step 2: 生成网格数据
x = np.linspace(-np.pi, np.pi, 50)
y = np.linspace(-np.pi, np.pi, 50)
X, Y = np.meshgrid(x, y)
Z = f(X, Y)# Step 3: 计算数值梯度
grad_y, grad_x = np.gradient(Z) # 注意np.gradient的输出顺序# Step 4: 可视化梯度场
plt.figure(figsize=(8, 6))
plt.quiver(X, Y, grad_x, grad_y, color='blue')
plt.title("Figure-1: 梯度场 ∇f = (cos(x)cos(y), -sin(x)sin(y))")
plt.xlabel("x")
plt.ylabel("y")
plt.grid(True)
plt.axis('equal')
plt.show()# Step 5: 可视化三维曲面
fig = plt.figure(figsize=(10, 7))
ax = fig.add_subplot(111, projection='3d')
ax.plot_surface(X, Y, Z, cmap='viridis')
ax.set_title("Figure-2: f(x, y) = sin(x)cos(y)")
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_zlabel("f(x, y)")
plt.show()
提示:
np.gradient返回顺序是先 y 后 x(与np.meshgrid的indexing参数有关)。- 符号梯度为 ∇ f = ( cos ( x ) cos ( y ) , − sin ( x ) sin ( y ) ) \nabla f = (\cos(x)\cos(y), -\sin(x)\sin(y)) ∇f=(cos(x)cos(y),−sin(x)sin(y)),可对比数值结果。
5. 开放思考题:梯度的局限性
题目:
在机器学习中,梯度下降法可能面临哪些问题?如何改进?
提示方向:
- 局部最优与鞍点问题(如非凸损失函数)。
- 学习率选择困难(太大导致震荡,太小收敛慢)。
- 高维空间中的梯度消失/爆炸(如深度神经网络)。
- 改进方法:动量法、Adam优化器、二阶优化(如牛顿法)。
反馈与答疑
-
常见问题:
- 问:偏导数计算时如何处理复合函数?
答:使用链式法则,如 ∂ ∂ x sin ( x y ) = y cos ( x y ) \frac{\partial}{\partial x} \sin(xy) = y\cos(xy) ∂x∂sin(xy)=ycos(xy)。 - 问:梯度下降为何可能陷入局部最优?
答:若损失函数非凸,梯度方向仅保证局部下降,无法跳出局部极小值。 - 问:如何验证数值梯度是否正确?
答:与符号梯度对比,或使用中心差分法计算误差(如误差应随 h h h减小而二次下降)。
- 问:偏导数计算时如何处理复合函数?
-
鼓励提问:
- 如果对梯度在非欧空间的定义有疑问,可进一步探讨流形上的梯度。
- 对优化算法感兴趣的同学,可研究自适应学习率方法(如 Adam)。
总结
通过以上练习,读者应掌握:
- 偏导数与梯度的数学计算;
- 梯度方向与几何意义的关联;
- 梯度下降法的实现与分析;
- 数值梯度的编程实践。
建议动手完成所有题目,尤其是编程题,以巩固理论与实践的结合。