基于SeaFormer的YOLOv8性能提升策略—轻量高效注意力模块Sea_AttentionBlock在语义分割中的应用研究
近年来,随着深度学习在计算机视觉领域的广泛应用,目标检测任务的精度和效率不断被推上新的高度。
YOLO系列作为实时检测算法的代表,在工业界和学术界都具有广泛影响力。而YOLOv8更是在前代基础上进一步优化了模型结构,提升了检测性能。然而,在面对小目标检测任务时,YOLOv8仍然存在一定的局限性。为了解决这一问题,本文引入一种来自ICLR 2023的轻量级语义分割网络SeaFormer中的核心模块 ——Sea_AttentionBlock,并将其与YOLOv8中的C2f模块相结合,提出了一种新的改进方案,显著提升了模型在多个数据集上的检测精度,特别是在小目标场景下效果尤为突出。
1. 背景动机
随着 Vision Transformer(ViT)在计算机视觉领域逐步超越传统 CNN 模型,在图像分类、目标检测、语义分割等任务中展现出卓越性能,其应用前景日益广泛。然而,ViT 类模型通常伴随着高昂的计算成本和内存需求,尤其在处理高分辨率图像的密集预测任务(如语义分割)时,难以满足边缘设备和移动端部署对实时性和能效的要求。为解决这一问题,复旦大学与腾讯联合提出了一种面向移动端优化的新型轻量化语义分割架构 —— SeaFormer(Squeeze-enhanced Axial Transformer) ,旨在实现精度与效率的最佳平衡。
2. SeaFormer介绍
论文地址:https://arxiv.org/pdf/2301.13156
代码地址:https://github.com/fudan-zvg/SeaFormer
2.1 整体网络架构
SeaFormer 采用典型的编码器-解码器结构,但设计为不对称双分支架构,主要包括以下几个模块:
| 模块名称 | 功能说明 |
|---|---|
| STEM | 输入图像的初步特征提取层,进行1/2下采样 |
| Context Branch(红色) | 高层语义提取分支,由 MV2 Block 与 SeaFormer Layer 交替构成 |
| Spatial Branch(蓝色) | 局部细节提取分支,轻量结构设计,注重边缘与纹理 |
| Fusion Module | 融合两个分支输出,通过卷积生成权重图并与空间分支相乘 |
| Light Segmentation Head | 最终输出分割结果,结构简洁,适配移动端部署 |

上图中的MV2表示MobileNetV2 block,MV2 ↓2表示带有下采样的MobileNetV2 block,⊗表示元素相乘。上面这张图是SeaFormer 的网络架构图,可以看到整体上仍然是一个不对称的编码器-解码器结构,网络设计成双分支的结构侧重于捕捉不同的特征信息,如上下文语义信息和空间细节信息。其主要包含以下几个模块:
- 共享的骨干网络层
- 上下文分支
- 空间分支
- 融合模块
- 轻量级的分割头
该网络采用轻量化的双分支结构,分别提取上下文信息(通过MobileNetV2 Block和SeaFormer Layer交替堆叠)和空间细节信息。图像先进行1/2、1/4、1/8三级下采样,随后两个分支在多个层级通过Fusion Block融合,并利用卷积+Sigmoid生成权重图对空间分支特征进行加权增强,整个过程迭代三次以逐步优化特征表示,最终通过轻量分割头输出分割结果,适用于高效准确的语义分割任务。
2.2 挤压增强型轴向Transformer层的详细结构

主要分为以下几个部分:
-
输入与特征分解:
- 输入特征 x x x 被分解为查询(Query, Q Q Q)、键(Key, K K K)和值(Value, V V V),分别具有形状 H × W × C q k H \times W \times C_{qk} H×W×Cqk 和 H × W × C v H \times W \times C_v H×W×Cv。
-
细节增强核(Detail enhancement kernel):
- 将 Q Q Q、 K K K 和 V V V 拼接后,通过一个 3 × 3 3 \times 3 3×3 的深度可分离卷积(dwconv)进行细节增强。
- 接着经过批量归一化(BN)和 ReLU6 激活函数,输出特征维度为 H × W × ( 2 C q k + C v ) H \times W \times (2C_{qk} + C_v) H×W×(2Cqk+Cv)。
-
挤压轴向注意力(Squeeze Axial attention):
- 对输入特征进行水平(Horizontal squeeze)和垂直(Vertical squeeze)方向的挤压操作,分别生成 H × 1 × C q k H \times 1 \times C_{qk} H×1×Cqk 和 1 × W × C q k 1 \times W \times C_{qk} 1×W×Cqk 的特征。
- 这些特征分别用于计算水平和垂直方向的多头注意力(Multi-head attention),并最终通过广播(Broadcast)操作恢复到原始空间维度。
-
挤压增强型轴向注意力(Squeeze-enhanced Axial attention):
- 将细节增强后的特征与挤压轴向注意力的结果相乘(Mul),结合两者的优点。
- 结果进一步通过 1 × 1 1 \times 1 1×1 卷积进行降维或特征融合。
-
前馈网络(FFN):
- 经过挤压增强型轴向注意力处理的特征被送入前馈网络(FFN),进行非线性变换。
- 最终结果与输入特征通过逐元素相加(⊕)的方式进行残差连接,提升模型的表达能力。
图中符号说明:
- Concat:拼接操作。
- Mul:逐元素乘法操作。
- ⊕:逐元素相加操作。
- BN:批量归一化(Batch Normalization)。
- ReLU6:ReLU6 激活函数。
- Horizontal Squeeze 和 Vertical Squeeze:水平和垂直方向的特征挤压操作。
- Multi-head Attention:多头注意力机制。
- Broadcast:广播操作,将特征扩展回原始空间维度。
3. 核心创新点
SeaFormer 的设计聚焦于构建一种高效、即插即用且适用于移动端部署的注意力机制模块,其主要创新包括:
- Squeeze-enhanced Axial Attention Block
- 结合通道压缩(squeeze)操作与轴向注意力(Axial Attention),降低全局注意力带来的计算负担;
- 引入细节增强(detail enhancement)机制,强化局部特征表达,提升小目标识别能力;
- 可灵活集成至主流网络结构中,作为通用注意力模块使用。
- 双分支结构设计
- 上下文分支(Context Branch):采用 MobileNetV2 Block 和 SeaFormer Layer 交替堆叠,专注于提取高层语义信息;
- 空间分支(Spatial Branch):侧重捕捉局部空间细节,增强边缘与纹理感知能力。
- 轻量级分割头(Light Segmentation Head)
- 简化解码器结构,去除冗余计算模块;
- 提升推理速度,同时保持良好的分割质量。
- Fusion 模块
- 对两个分支的信息进行加权融合;
- 使用卷积+Sigmoid 提取权重图,并与空间分支特征相乘;
- 在多个尺度上重复该融合过程,以增强多尺度表达能力。

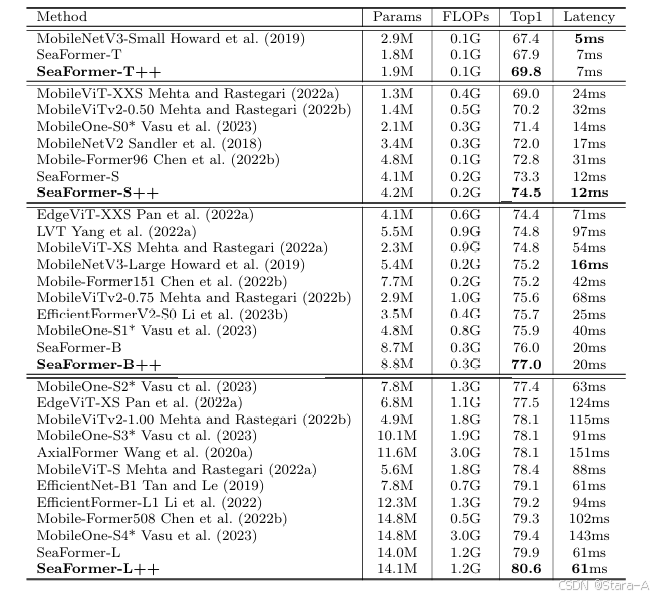
4. 不同模型在 ImageNet-1K 数据集结果
在 ImageNet-1K 验证集上的图像分类结果。FLOPs(浮点运算次数)和延迟(latency)的测量基于输入尺寸 224×224,但 MobileViT 和 MobileViTv2 的测量是根据其原始实现,使用 256×256 的输入尺寸。* 表示重新参数化的变体。延迟是在单个 Qualcomm Snapdragon 865 上测量的,且仅使用一个 ARM CPU 核心进行速度测试。未使用其他加速手段,例如 GPU 或量化。
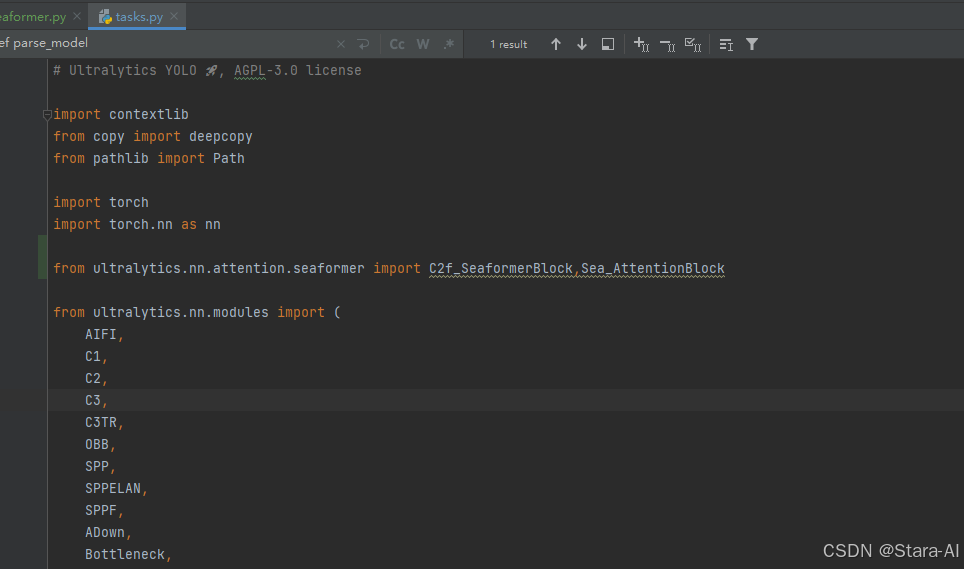
5. YOLOv8—集成 Sea_Attention 和 C2f_Seaformer
- 在
ultralytics/nn新建attention文件包,随后新建seaformer.py,粘贴下面代码
import math
import torch
from torch import nn
import torch.nn.functional as Ffrom mmcv.cnn import ConvModule
from mmcv.cnn import build_norm_layer
from timm.models.registry import register_model__all__ = ["SeaFormer_T", "SeaFormer_S", "SeaFormer_B", "SeaFormer_L"]def autopad(k, p=None, d=1): # kernel, padding, dilation# Pad to 'same' shape outputsif d > 1:k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-sizeif p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)default_act = nn.SiLU() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):return self.act(self.conv(x))def _make_divisible(v, divisor, min_value=None):"""This function is taken from the original tf repo.It ensures that all layers have a channel number that is divisible by 8It can be seen here:https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py:param v::param divisor::param min_value::return:"""if min_value is None:min_value = divisornew_v = max(min_value, int(v + divisor / 2) // divisor * divisor)# Make sure that round down does not go down by more than 10%.if new_v < 0.9 * v:new_v += divisorreturn new_vdef drop_path(x, drop_prob: float = 0., training: bool = False):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted forchanging the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use'survival rate' as the argument."""if drop_prob == 0. or not training:return xkeep_prob = 1 - drop_probshape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNetsrandom_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)random_tensor.floor_() # binarizeoutput = x.div(keep_prob) * random_tensorreturn outputclass DropPath(nn.Module):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""def __init__(self, drop_prob=None):super(DropPath, self).__init__()self.drop_prob = drop_probdef forward(self, x):return drop_path(x, self.drop_prob, self.training)def get_shape(tensor):shape = tensor.shapeif torch.onnx.is_in_onnx_export():shape = [i.cpu().numpy() for i in shape]return shapeclass Conv2d_BN(nn.Sequential):def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,groups=1, bn_weight_init=1, bias=False,norm_cfg=dict(type='BN', requires_grad=True)):super().__init__()self.inp_channel = aself.out_channel = bself.ks = ksself.pad = padself.stride = strideself.dilation = dilationself.groups = groups# self.bias = biasself.add_module('c', nn.Conv2d(a, b, ks, stride, pad, dilation, groups, bias=bias))bn = build_norm_layer(norm_cfg, b)[1]nn.init.constant_(bn.weight, bn_weight_init)nn.init.constant_(bn.bias, 0)self.add_module('bn', bn)class Mlp(nn.Module):def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.ReLU, drop=0.,norm_cfg=dict(type='BN', requires_grad=True)):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = Conv2d_BN(in_features, hidden_features, norm_cfg=norm_cfg)self.dwconv = nn.Conv2d(hidden_features, hidden_features, 3, 1, 1, bias=True, groups=hidden_features)self.act = act_layer()self.fc2 = Conv2d_BN(hidden_features, out_features, norm_cfg=norm_cfg)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.dwconv(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return xclass InvertedResidual(nn.Module):def __init__(self,inp: int,oup: int,ks: int,stride: int,expand_ratio: int,activations=None,norm_cfg=dict(type='BN', requires_grad=True)) -> None:super(InvertedResidual, self).__init__()self.stride = strideself.expand_ratio = expand_ratioassert stride in [1, 2]if activations is None:activations = nn.ReLUhidden_dim = int(round(inp * expand_ratio))self.use_res_connect = self.stride == 1 and inp == ouplayers = []if expand_ratio != 1:# pwlayers.append(Conv2d_BN(inp, hidden_dim, ks=1, norm_cfg=norm_cfg))layers.append(activations())layers.extend([# dwConv2d_BN(hidden_dim, hidden_dim, ks=ks, stride=stride, pad=ks // 2, groups=hidden_dim, norm_cfg=norm_cfg),activations(),# pw-linearConv2d_BN(hidden_dim, oup, ks=1, norm_cfg=norm_cfg)])self.conv = nn.Sequential(*layers)self.out_channels = oupself._is_cn = stride > 1def forward(self, x):if self.use_res_connect:return x + self.conv(x)else:return self.conv(x)class StackedMV2Block(nn.Module):def __init__(self,cfgs,stem,inp_channel=16,activation=nn.ReLU,norm_cfg=dict(type='BN', requires_grad=True),width_mult=1.):super().__init__()self.stem = stemif stem:self.stem_block = nn.Sequential(Conv2d_BN(3, inp_channel, 3, 2, 1, norm_cfg=norm_cfg),activation())self.cfgs = cfgsself.layers = []for i, (k, t, c, s) in enumerate(cfgs):output_channel = _make_divisible(c * width_mult, 8)exp_size = t * inp_channelexp_size = _make_divisible(exp_size * width_mult, 8)layer_name = 'layer{}'.format(i + 1)layer = InvertedResidual(inp_channel, output_channel, ks=k, stride=s, expand_ratio=t, norm_cfg=norm_cfg,activations=activation)self.add_module(layer_name, layer)inp_channel = output_channelself.layers.append(layer_name)def forward(self, x):if self.stem:x = self.stem_block(x)for i, layer_name in enumerate(self.layers):layer = getattr(self, layer_name)x = layer(x)return xclass SqueezeAxialPositionalEmbedding(nn.Module):def __init__(self, dim, shape):super().__init__()self.pos_embed = nn.Parameter(torch.randn([1, dim, shape]))def forward(self, x):B, C, N = x.shapex = x + F.interpolate(self.pos_embed, size=(N), mode='linear', align_corners=False)return xclass Sea_Attention(torch.nn.Module):def __init__(self, dim, key_dim=16, num_heads=4,attn_ratio=2,activation=None,norm_cfg=dict(type='BN', requires_grad=True), ):super().__init__()self.num_heads = num_headsself.scale = key_dim ** -0.5self.key_dim = key_dimself.nh_kd = nh_kd = key_dim * num_heads # num_head key_dimself.d = int(attn_ratio * key_dim)self.dh = int(attn_ratio * key_dim) * num_headsself.attn_ratio = attn_ratioself.to_q = Conv2d_BN(dim, nh_kd, 1, norm_cfg=norm_cfg)self.to_k = Conv2d_BN(dim, nh_kd, 1, norm_cfg=norm_cfg)self.to_v = Conv2d_BN(dim, self.dh, 1, norm_cfg=norm_cfg)self.proj = torch.nn.Sequential(activation(), Conv2d_BN(self.dh, dim, bn_weight_init=0, norm_cfg=norm_cfg))self.proj_encode_row = torch.nn.Sequential(activation(), Conv2d_BN(self.dh, self.dh, bn_weight_init=0, norm_cfg=norm_cfg))self.pos_emb_rowq = SqueezeAxialPositionalEmbedding(nh_kd, 16)self.pos_emb_rowk = SqueezeAxialPositionalEmbedding(nh_kd, 16)self.proj_encode_column = torch.nn.Sequential(activation(), Conv2d_BN(self.dh, self.dh, bn_weight_init=0, norm_cfg=norm_cfg))self.pos_emb_columnq = SqueezeAxialPositionalEmbedding(nh_kd, 16)self.pos_emb_columnk = SqueezeAxialPositionalEmbedding(nh_kd, 16)self.dwconv = Conv2d_BN(self.dh + 2 * self.nh_kd, 2 * self.nh_kd + self.dh, ks=3, stride=1, pad=1, dilation=1,groups=2 * self.nh_kd + self.dh, norm_cfg=norm_cfg)self.act = activation()self.pwconv = Conv2d_BN(2 * self.nh_kd + self.dh, dim, ks=1, norm_cfg=norm_cfg)self.sigmoid = h_sigmoid()def forward(self, x):B, C, H, W = x.shapeq = self.to_q(x)k = self.to_k(x)v = self.to_v(x)# detail enhanceqkv = torch.cat([q, k, v], dim=1)qkv = self.act(self.dwconv(qkv))qkv = self.pwconv(qkv)# squeeze axial attention## squeeze rowqrow = self.pos_emb_rowq(q.mean(-1)).reshape(B, self.num_heads, -1, H).permute(0, 1, 3, 2)krow = self.pos_emb_rowk(k.mean(-1)).reshape(B, self.num_heads, -1, H)vrow = v.mean(-1).reshape(B, self.num_heads, -1, H).permute(0, 1, 3, 2)attn_row = torch.matmul(qrow, krow) * self.scaleattn_row = attn_row.softmax(dim=-1)xx_row = torch.matmul(attn_row, vrow) # B nH H Cxx_row = self.proj_encode_row(xx_row.permute(0, 1, 3, 2).reshape(B, self.dh, H, 1))## squeeze columnqcolumn = self.pos_emb_columnq(q.mean(-2)).reshape(B, self.num_heads, -1, W).permute(0, 1, 3, 2)kcolumn = self.pos_emb_columnk(k.mean(-2)).reshape(B, self.num_heads, -1, W)vcolumn = v.mean(-2).reshape(B, self.num_heads, -1, W).permute(0, 1, 3, 2)attn_column = torch.matmul(qcolumn, kcolumn) * self.scaleattn_column = attn_column.softmax(dim=-1)xx_column = torch.matmul(attn_column, vcolumn) # B nH W Cxx_column = self.proj_encode_column(xx_column.permute(0, 1, 3, 2).reshape(B, self.dh, 1, W))xx = xx_row.add(xx_column)xx = v.add(xx)xx = self.proj(xx)xx = self.sigmoid(xx) * qkvreturn xxclass Sea_AttentionBlock(nn.Module):def __init__(self, dim, key_dim=64, num_heads=4, mlp_ratio=2., attn_ratio=2., drop=0.,drop_path=0.1, act_layer=nn.ReLU, norm_cfg=dict(type='BN2d', requires_grad=True)):super().__init__()self.dim = dimself.num_heads = num_headsself.mlp_ratio = mlp_ratioself.attn = Sea_Attention(dim, key_dim=key_dim, num_heads=num_heads, attn_ratio=attn_ratio,activation=act_layer, norm_cfg=norm_cfg)# NOTE: drop path for stochastic depth, we shall see if this is better than dropout hereself.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop,norm_cfg=norm_cfg)def forward(self, x1):x1 = x1 + self.drop_path(self.attn(x1))x1 = x1 + self.drop_path(self.mlp(x1))return x1class C2f_SeaformerBlock(nn.Module):# CSP Bottleneck with 2 convolutionsdef __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()self.c = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, 2 * self.c, 1, 1)self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)self.m = nn.ModuleList(Sea_AttentionBlock(self.c) for _ in range(n))def forward(self, x):y = list(self.cv1(x).chunk(2, 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))def forward_split(self, x):y = list(self.cv1(x).split((self.c, self.c), 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))class SeaformerBasicLayer(nn.Module):def __init__(self, block_num, embedding_dim, key_dim, num_heads,mlp_ratio=4., attn_ratio=2., drop=0., attn_drop=0., drop_path=0.,norm_cfg=dict(type='BN2d', requires_grad=True),act_layer=None):super().__init__()self.block_num = block_numself.transformer_blocks = nn.ModuleList()for i in range(self.block_num):self.transformer_blocks.append(Sea_AttentionBlock(embedding_dim, key_dim=key_dim, num_heads=num_heads,mlp_ratio=mlp_ratio, attn_ratio=attn_ratio,drop=drop, drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,norm_cfg=norm_cfg,act_layer=act_layer))def forward(self, x):# token * Nfor i in range(self.block_num):x = self.transformer_blocks[i](x)return xclass h_sigmoid(nn.Module):def __init__(self, inplace=True):super(h_sigmoid, self).__init__()self.relu = nn.ReLU6(inplace=inplace)def forward(self, x):return self.relu(x + 3) / 6class SeaFormer(nn.Module):def __init__(self, cfgs,channels,emb_dims,key_dims,depths=[2, 2],num_heads=4,attn_ratios=2,mlp_ratios=[2, 4],drop_path_rate=0.,norm_cfg=dict(type='BN', requires_grad=True),act_layer=nn.ReLU6,init_cfg=None,num_classes=1000):super().__init__()self.num_classes = num_classesself.channels = channelsself.depths = depthsself.cfgs = cfgsself.norm_cfg = norm_cfgself.init_cfg = init_cfgif self.init_cfg is not None:self.pretrained = self.init_cfg['checkpoint']for i in range(len(cfgs)):smb = StackedMV2Block(cfgs=cfgs[i], stem=True if i == 0 else False, inp_channel=channels[i],norm_cfg=norm_cfg)setattr(self, f"smb{i + 1}", smb)for i in range(len(depths)):dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depths[i])] # stochastic depth decay ruletrans = SeaformerBasicLayer(block_num=depths[i],embedding_dim=emb_dims[i],key_dim=key_dims[i],num_heads=num_heads,mlp_ratio=mlp_ratios[i],attn_ratio=attn_ratios,drop=0, attn_drop=0,drop_path=dpr,norm_cfg=norm_cfg,act_layer=act_layer)setattr(self, f"trans{i + 1}", trans)self.linear = nn.Linear(channels[-1], 1000)self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.apply(self.init_weights)self.channel = [i.size(0) for i in self.forward(torch.randn(1, 3, 224, 224))]def init_weights(self, m):for m in self.modules():if isinstance(m, nn.Conv2d):n = m.kernel_size[0] * m.kernel_size[1] * m.out_channelsn //= m.groupsm.weight.data.normal_(0, math.sqrt(2. / n))if m.bias is not None:m.bias.data.zero_()elif isinstance(m, nn.BatchNorm2d):m.weight.data.fill_(1)m.bias.data.zero_()elif isinstance(m, nn.Linear):m.weight.data.normal_(0, 0.01)if m.bias is not None:m.bias.data.zero_()def forward(self, x):num_smb_stage = len(self.cfgs)num_trans_stage = len(self.depths)for i in range(num_smb_stage):smb = getattr(self, f"smb{i + 1}")x = smb(x)if num_trans_stage + i >= num_smb_stage:trans = getattr(self, f"trans{i + num_trans_stage - num_smb_stage + 1}")x = trans(x)out = self.avgpool(x).view(-1, x.shape[1])out = self.linear(out)return out@register_model
def SeaFormer_T(pretrained=False, **kwargs):model_cfgs = dict(cfg1=[# k, t, c, s[3, 1, 16, 1],[3, 4, 16, 2],[3, 3, 16, 1]],cfg2=[[5, 3, 32, 2],[5, 3, 32, 1]],cfg3=[[3, 3, 64, 2],[3, 3, 64, 1]],cfg4=[[5, 3, 128, 2]],cfg5=[[3, 6, 160, 2]],channels=[16, 16, 32, 64, 128, 160],num_heads=4,depths=[2, 2],emb_dims=[128, 160],key_dims=[16, 24],drop_path_rate=0.1,attn_ratios=2,mlp_ratios=[2, 4])return SeaFormer(cfgs=[model_cfgs['cfg1'], model_cfgs['cfg2'], model_cfgs['cfg3'], model_cfgs['cfg4'], model_cfgs['cfg5']],channels=model_cfgs['channels'],emb_dims=model_cfgs['emb_dims'],key_dims=model_cfgs['key_dims'],depths=model_cfgs['depths'],attn_ratios=model_cfgs['attn_ratios'],mlp_ratios=model_cfgs['mlp_ratios'],num_heads=model_cfgs['num_heads'],drop_path_rate=model_cfgs['drop_path_rate'])@register_model
def SeaFormer_S(pretrained=False, **kwargs):model_cfgs = dict(cfg1=[# k, t, c, s[3, 1, 16, 1],[3, 4, 24, 2],[3, 3, 24, 1]],cfg2=[[5, 3, 48, 2],[5, 3, 48, 1]],cfg3=[[3, 3, 96, 2],[3, 3, 96, 1]],cfg4=[[5, 4, 160, 2]],cfg5=[[3, 6, 192, 2]],channels=[16, 24, 48, 96, 160, 192],num_heads=6,depths=[3, 3],key_dims=[16, 24],emb_dims=[160, 192],drop_path_rate=0.1,attn_ratios=2,mlp_ratios=[2, 4])return SeaFormer(cfgs=[model_cfgs['cfg1'], model_cfgs['cfg2'], model_cfgs['cfg3'], model_cfgs['cfg4'], model_cfgs['cfg5']],channels=model_cfgs['channels'],emb_dims=model_cfgs['emb_dims'],key_dims=model_cfgs['key_dims'],depths=model_cfgs['depths'],attn_ratios=model_cfgs['attn_ratios'],mlp_ratios=model_cfgs['mlp_ratios'],num_heads=model_cfgs['num_heads'],drop_path_rate=model_cfgs['drop_path_rate'])@register_model
def SeaFormer_B(pretrained=False, **kwargs):model_cfgs = dict(cfg1=[# k, t, c, s[3, 1, 16, 1],[3, 4, 32, 2],[3, 3, 32, 1]],cfg2=[[5, 3, 64, 2],[5, 3, 64, 1]],cfg3=[[3, 3, 128, 2],[3, 3, 128, 1]],cfg4=[[5, 4, 192, 2]],cfg5=[[3, 6, 256, 2]],channels=[16, 32, 64, 128, 192, 256],num_heads=8,depths=[4, 4],key_dims=[16, 24],emb_dims=[192, 256],drop_path_rate=0.1,attn_ratios=2,mlp_ratios=[2, 4])return SeaFormer(cfgs=[model_cfgs['cfg1'], model_cfgs['cfg2'], model_cfgs['cfg3'], model_cfgs['cfg4'], model_cfgs['cfg5']],channels=model_cfgs['channels'],emb_dims=model_cfgs['emb_dims'],key_dims=model_cfgs['key_dims'],depths=model_cfgs['depths'],attn_ratios=model_cfgs['attn_ratios'],mlp_ratios=model_cfgs['mlp_ratios'],num_heads=model_cfgs['num_heads'],drop_path_rate=model_cfgs['drop_path_rate'])@register_model
def SeaFormer_L(pretrained=False, **kwargs):model_cfgs = dict(cfg1=[# k, t, c, s[3, 3, 32, 1],[3, 4, 64, 2],[3, 4, 64, 1]],cfg2=[[5, 4, 128, 2],[5, 4, 128, 1]],cfg3=[[3, 4, 192, 2],[3, 4, 192, 1]],cfg4=[[5, 4, 256, 2]],cfg5=[[3, 6, 320, 2]],channels=[32, 64, 128, 192, 256, 320],num_heads=8,depths=[3, 3, 3],key_dims=[16, 20, 24],emb_dims=[192, 256, 320],drop_path_rate=0.1,attn_ratios=2,mlp_ratios=[2, 4, 6])return SeaFormer(cfgs=[model_cfgs['cfg1'], model_cfgs['cfg2'], model_cfgs['cfg3'], model_cfgs['cfg4'], model_cfgs['cfg5']],channels=model_cfgs['channels'],emb_dims=model_cfgs['emb_dims'],key_dims=model_cfgs['key_dims'],depths=model_cfgs['depths'],attn_ratios=model_cfgs['attn_ratios'],mlp_ratios=model_cfgs['mlp_ratios'],num_heads=model_cfgs['num_heads'],drop_path_rate=model_cfgs['drop_path_rate'])if __name__ == '__main__':model = SeaFormer_L()# ck = torch.load('model.pth.tar', map_location='cpu')# model.load_state_dict(ck['state_dict_ema'])input = torch.rand((1, 3, 224, 224))print(model)from fvcore.nn import FlopCountAnalysis, flop_count_tablemodel.eval()flops = FlopCountAnalysis(model, input)print(flop_count_table(flops))
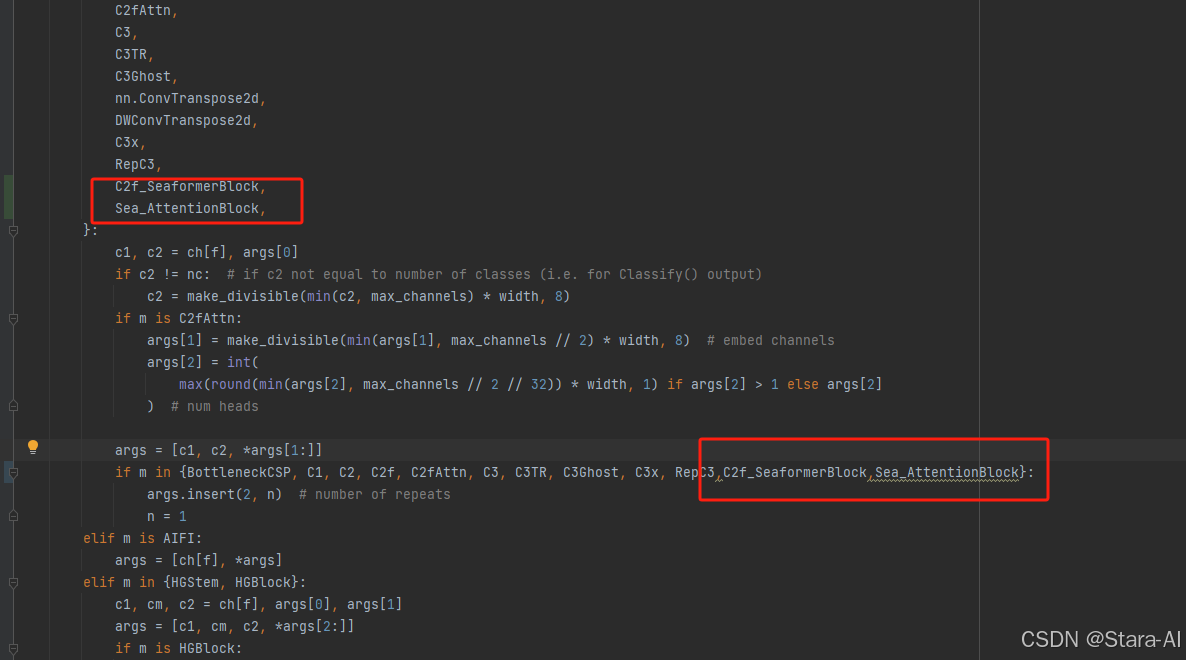
- 在
tasks.py注册
from ultralytics.nn.attention.seaformer import C2f_SeaformerBlock,Sea_AttentionBlock
修改def parse_model(d, ch, verbose=Ture):
if m in {Classify,Conv,ConvTranspose,GhostConv,Bottleneck,GhostBottleneck,SPP,SPPF,DWConv,Focus,BottleneckCSP,C1,C2,C2f,RepNCSPELAN4,ADown,SPPELAN,C2fAttn,C3,C3TR,C3Ghost,nn.ConvTranspose2d,DWConvTranspose2d,C3x,RepC3,C2f_SeaformerBlock,Sea_AttentionBlock,}:c1, c2 = ch[f], args[0]if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)c2 = make_divisible(min(c2, max_channels) * width, 8)if m is C2fAttn:args[1] = make_divisible(min(args[1], max_channels // 2) * width, 8) # embed channelsargs[2] = int(max(round(min(args[2], max_channels // 2 // 32)) * width, 1) if args[2] > 1 else args[2]) # num headsargs = [c1, c2, *args[1:]]if m in {BottleneckCSP, C1, C2, C2f, C2fAttn, C3, C3TR, C3Ghost, C3x, RepC3,C2f_SeaformerBlock,Sea_AttentionBlock}:args.insert(2, n) # number of repeatsn = 1
yolov8_Sea_Attention.yaml
# Ultralytics YOLO 🚀, GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, Sea_AttentionBlock, [512]] # 13 (P5/32-large)- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Sea_AttentionBlock, [256]] # 17 (P5/32-large)- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Sea_AttentionBlock, [512]] # 21 (P5/32-large)- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [-1, 1, Sea_AttentionBlock, [1024]] # 25 (P5/32-large)- [[17, 21, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)
6. 总结
SeaFormer 通过引入 Squeeze-enhanced Axial Attention 模块,结合双分支结构与轻量分割头,成功实现了在移动设备上的高性能语义分割方案。其实验结果表明,该模型在多个数据集上均取得了精度与速度的良好平衡,是当前轻量化 Transformer 架构中的代表性工作之一。未来可进一步探索其模块在目标检测、视频分析、遥感图像处理等领域的扩展应用。