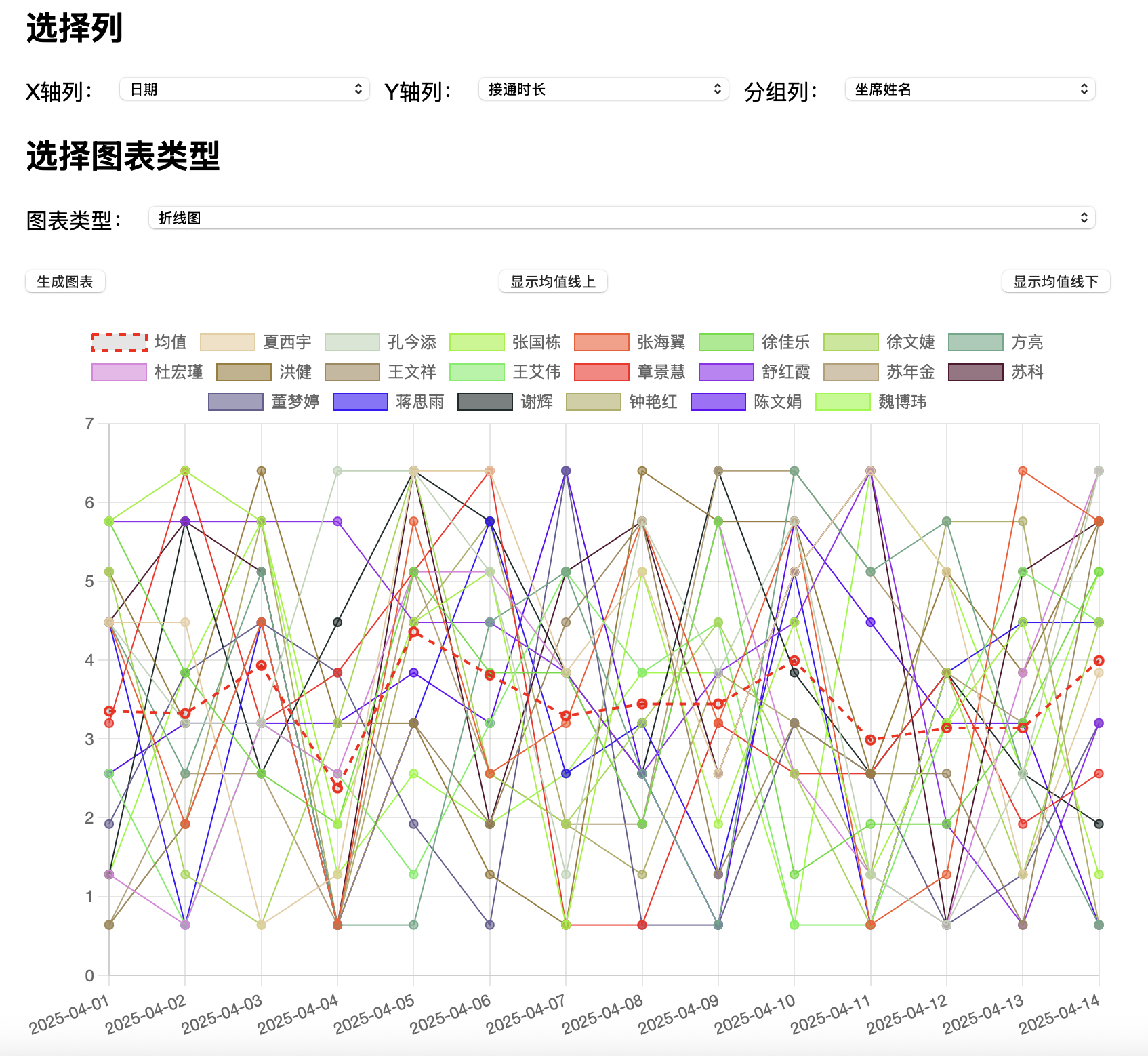
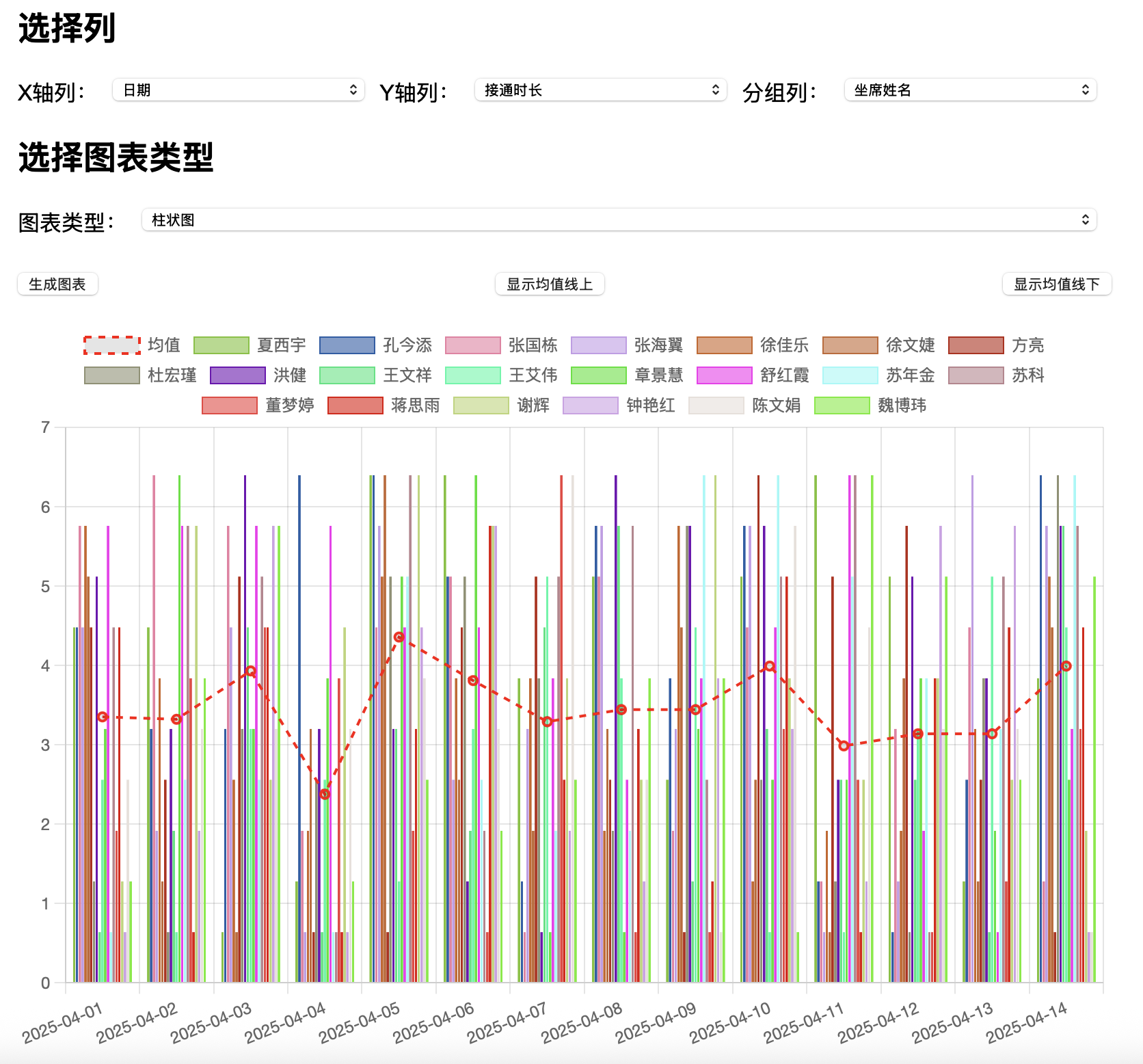
基于flask+pandas+csv的报表实现
基于大模型根据提示词去写SQL执行SQL返回结果输出报表技术上可行的,但为啥还要基于pandas去实现呢?
原因有以下几点:
1、大模型无法满足实时性输出报表的需求;
2、使用大模型比较适合数据量比较大的场景,大模型主要辅助写SQL;
3、使用pandas方便快捷,定制好各种模版后,功能也能通用。
代码如下:
from flask import Flask, request, jsonify, render_template_string
import pandas as pd
from io import StringIO
import randomapp = Flask(__name__)# 全局变量,用于保存上传的CSV文件内容和解析后的DataFrame
uploaded_csv_data = None
csv_dataframe = None
@app.route('/')
def index():html_content = '''<!DOCTYPE html><html><head><meta charset="UTF-8"><title>CSV 上传与图表分析</title><script src="https://cdn.jsdelivr.net/npm/chart.js"></script><style>body {font-family: Arial, sans-serif;margin: 20px;}.container {max-width: 800px;margin: 0 auto;}.row {display: flex;flex-wrap: wrap;justify-content: space-between;margin-bottom: 15px;}.row label {margin-right: 10px;white-space: nowrap;}.row select {flex: 1;margin-right: 10px;}.row button {margin-top: 10px;}canvas {margin-top: 20px;}</style></head><body><div class="container"><h2>上传 CSV 文件</h2><div class="row"><input type="file" id="csvFile" accept=".csv"><button onclick="uploadCSV()">上传文件</button></div><p id="uploadStatus"></p><h2>选择列</h2><div class="row"><label for="xAxisColumn">X轴列:</label><select id="xAxisColumn"></select><label for="yAxisColumn">Y轴列:</label><select id="yAxisColumn"></select><label for="groupColumn">分组列:</label><select id="groupColumn"></select></div><h2>选择图表类型</h2><div class="row"><label for="chartType">图表类型:</label><select id="chartType"><option value="bar">柱状图</option><option value="line">折线图</option></select></div><div class="row"><button onclick="analyzeData()">生成图表</button><button onclick="analyzeData('above')">显示均值线上</button><button onclick="analyzeData('below')">显示均值线下</button></div><canvas id="myChart" width="600" height="400"></canvas></div><script>var csvUploaded = false;var columns = [];function uploadCSV() {var fileInput = document.getElementById("csvFile");if (fileInput.files.length === 0) {alert("请选择一个 CSV 文件!");return;}var file = fileInput.files[0];var reader = new FileReader();reader.onload = function(e) {var csvContent = e.target.result;fetch('/upload', {method: 'POST',headers: {'Content-Type': 'text/plain'},body: csvContent}).then(response => response.json()).then(data => {if (data.success) {document.getElementById("uploadStatus").innerText = "CSV 文件上传成功!";csvUploaded = true;columns = data.columns;populateColumns();} else {alert("上传失败:" + data.error);}});};reader.readAsText(file);}function populateColumns() {var xAxisSelect = document.getElementById("xAxisColumn");var yAxisSelect = document.getElementById("yAxisColumn");var groupSelect = document.getElementById("groupColumn");columns.forEach(column => {var option = document.createElement("option");option.value = column;option.text = column;xAxisSelect.appendChild(option.cloneNode(true));yAxisSelect.appendChild(option.cloneNode(true));groupSelect.appendChild(option.cloneNode(true));});}function analyzeData(filter = '') {var xAxisColumn = document.getElementById("xAxisColumn").value;var yAxisColumn = document.getElementById("yAxisColumn").value;var groupColumn = document.getElementById("groupColumn").value;var chartType = document.getElementById("chartType").value;if (!csvUploaded) {alert("请先上传 CSV 文件!");return;}if (!xAxisColumn || !yAxisColumn || !groupColumn) {alert("请选择X轴列、Y轴列和分组列!");return;}fetch(`/analyze?xAxis=${encodeURIComponent(xAxisColumn)}&yAxis=${encodeURIComponent(yAxisColumn)}&group=${encodeURIComponent(groupColumn)}&chartType=${encodeURIComponent(chartType)}&filter=${filter}`).then(response => response.json()).then(data => {renderChart(data, chartType);});}function renderChart(chartData, chartType) {var ctx = document.getElementById('myChart').getContext('2d');if (window.myChartInstance) {window.myChartInstance.destroy();}window.myChartInstance = new Chart(ctx, {type: chartType,data: {labels: chartData.labels,datasets: chartData.datasets},options: {responsive: true,scales: {y: {beginAtZero: true}}}});}</script></body></html>'''return render_template_string(html_content)@app.route('/upload', methods=['POST'])
def upload():global uploaded_csv_data, csv_dataframecontent = request.data.decode('utf-8')try:# 将上传的 CSV 文件内容解析为 DataFramedf = pd.read_csv(StringIO(content))uploaded_csv_data = content # 存储原始数据(可选)csv_dataframe = df # 保存解析后的DataFrame供后续分析使用columns = df.columns.tolist() # 获取列名return jsonify({'success': True, 'columns': columns})except Exception as e:return jsonify({'success': False, 'error': str(e)})@app.route('/get_unique_values')
def get_unique_values():global csv_dataframecolumn = request.args.get('column', '')if csv_dataframe is None or column not in csv_dataframe.columns:return jsonify({'uniqueValues': []})unique_values = csv_dataframe[column].dropna().unique().tolist()return jsonify({'uniqueValues': unique_values})@app.route('/analyze')
def analyze():global csv_dataframexAxis = request.args.get('xAxis', '')yAxis = request.args.get('yAxis', '')group = request.args.get('group', '')chartType = request.args.get('chartType', 'bar') # 获取图表类型filter_type = request.args.get('filter', '') # 获取过滤类型# 若未上传文件,则返回空数据if csv_dataframe is None:return jsonify({'labels': [], 'datasets': []})df = csv_dataframe.copy()# 如果 X 轴是日期类型,确保其为日期格式if pd.api.types.is_string_dtype(df[xAxis]):df[xAxis] = pd.to_datetime(df[xAxis])# 按 X 轴列和分组列分组,并对 Y 轴列进行求和grouped = df.groupby([xAxis, group])[yAxis].sum().reset_index()# 按 X 轴列排序grouped = grouped.sort_values(by=xAxis)# 获取所有唯一的 X 轴值(日期)labels = grouped[xAxis].dt.strftime('%Y-%m-%d').unique().tolist() # 转换为字符串格式datasets = []# 计算每个 X 轴值对应的 Y 轴均值mean_values = grouped.groupby(xAxis)[yAxis].mean().reset_index()mean_values_dict = mean_values.set_index(xAxis)[yAxis].to_dict()# 添加均值线mean_data = [mean_values_dict.get(pd.to_datetime(label), 0) for label in labels]datasets.append({'label': '均值','data': mean_data,'borderColor': 'rgba(255, 0, 0, 1)','borderWidth': 2,'borderDash': [5, 5], # 虚线'fill': False,'type': 'line'})# 根据均值线过滤数据if filter_type == 'above':filtered_df = df[df.apply(lambda row: row[yAxis] > mean_values_dict.get(row[xAxis], 0), axis=1)]elif filter_type == 'below':filtered_df = df[df.apply(lambda row: row[yAxis] < mean_values_dict.get(row[xAxis], 0), axis=1)]else:filtered_df = df# 重新分组并计算filtered_grouped = filtered_df.groupby([xAxis, group])[yAxis].sum().reset_index()# 确保每个日期都有数据all_dates = pd.date_range(start=grouped[xAxis].min(), end=grouped[xAxis].max(), freq='D')all_dates_str = all_dates.strftime('%Y-%m-%d').tolist()for obj in filtered_grouped[group].unique():data = []for date in all_dates:value = filtered_grouped[(filtered_grouped[xAxis] == date) & (filtered_grouped[group] == obj)][yAxis].sum()if value > 0: # 只包括值大于0的点data.append(value)else:data.append(None) # 使用 None 来表示没有数据的点color = f"rgba({random.randint(0, 255)}, {random.randint(0, 255)}, {random.randint(0, 255)}, 0.6)"datasets.append({'label': obj,'data': data,'backgroundColor': color,'borderColor': color.replace("0.6", "1"),'borderWidth': 1,'type': chartType # 使用用户选择的图表类型})return jsonify({'labels': all_dates_str, 'datasets': datasets})if __name__ == '__main__':app.run(debug=True)