[特殊字符]【深度解析】Transformer革命:《Attention Is All You Need》完全解读
🔍 传统模型的局限:RNN时代的困境
在Transformer出现之前,机器翻译等序列任务主要依赖编码器-解码器架构的循环神经网络(RNN):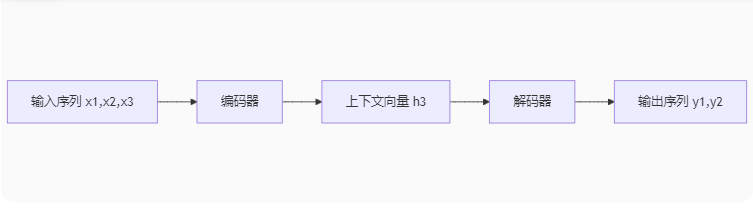
输入序列 x1,x2,x3编码器上下文向量 h3解码器输出序列 y1,y2
❌ 传统方法的三大痛点:
-
顺序计算的枷锁:必须逐个处理序列元素,无法并行
-
历史记忆的缺失:长距离依赖关系难以捕捉
-
资源的黑洞:训练耗时且计算成本高昂
💡 Transformer的破局之道:注意力机制革命
"Attention is all you need" - 这篇2017年的论文彻底改变了NLP领域
🌟 核心创新点对比表
| 特性 | 传统RNN | Transformer |
|---|---|---|
| 并行计算 | ❌ 顺序处理 | ✅ 全并行 |
| 长程依赖 | ❌ 梯度消失 | ✅ 全局注意力 |
| 计算效率 | ❌ O(n)复杂度 | ✅ O(1)路径长度 |
| 信息保留 | ❌ 信息衰减 | ✅ 直接连接 |
🧩 Transformer架构全景解析
1. 输入处理:词嵌入 + 位置编码
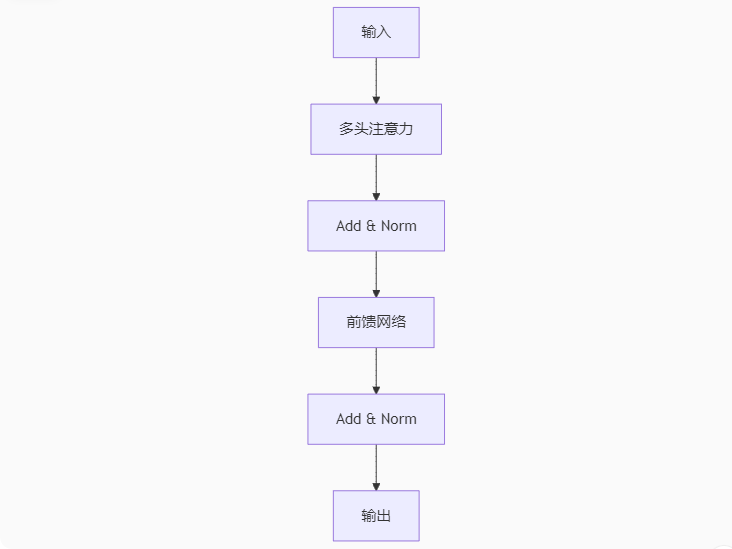
# 伪代码示例 input_embedding = Embedding(vocab_size, d_model)(tokens) position_encoding = sin/cos(position) # 独特的位置编码方式 final_input = input_embedding + position_encoding
2. 编码器堆叠结构(N×重复)
3. 解码器双重注意力机制
-
掩码自注意力:防止"偷看"未来信息
-
编码器-解码器注意力:桥接两个模块的关键
💻 核心代码逐行解读
🔥 ScaledDotProductAttention(缩放点积注意力)
class ScaledDotProductAttention(nn.Module):def forward(self, query, key, value, mask=None):d_k = query.size(-1)# 1. 计算相似度得分scores = torch.matmul(query, key.transpose(-2, -1)) / √d_k# 2. 可选掩码操作(解码器使用)if mask is not None:scores = scores.masked_fill(mask == 0, -1e9)# 3. 转化为概率分布attn_weights = F.softmax(scores, dim=-1)# 4. 加权求和return torch.matmul(attn_weights, value), attn_weights
🧠 MultiHeadAttention(多头注意力)
class MultiHeadAttention(nn.Module):def __init__(self, num_heads, d_model):super().__init__()assert d_model % num_heads == 0 # 确保可均分self.d_k = d_model // num_headsself.W_q = nn.Linear(d_model, d_model) # 查询变换self.W_k = nn.Linear(d_model, d_model) # 键变换self.W_v = nn.Linear(d_model, d_model) # 值变换self.W_o = nn.Linear(d_model, d_model) # 输出变换 def forward(self, query, key, value, mask=None):# 分头处理 → 独立计算 → 合并结果Q = self._split_heads(self.W_q(query))K = self._split_heads(self.W_k(key))V = self._split_heads(self.W_v(value))attn_output, _ = ScaledDotProductAttention()(Q, K, V, mask)return self.W_o(self._combine_heads(attn_output))
🎯 Transformer的五大突破性优势
-
并行计算的狂欢:告别序列处理的等待
-
全局视野的胜利:任意位置直接交互
-
长程依赖的克星:彻底解决梯度消失
-
模块化的优雅:编码器-解码器灵活组合
-
性能的飞跃:在WMT2014英德翻译任务上BLEU值提升28.4→41.8
📚 学习资源宝库
- [论文原文] https://arxiv.org/abs/1706.03762 - [视频解析] 知乎专栏《图解Transformer》 - [代码实战] HuggingFace Transformer库 - [延伸阅读] 《The Illustrated Transformer》博客