ReSearch:强化学习赋能大模型,推理与搜索的创新融合
ReSearch:强化学习赋能大模型,推理与搜索的创新融合
大语言模型(LLMs)的推理能力不断提升,却在与外部搜索结合处理复杂问题时遇阻。本文提出的ReSearch框架,借助强化学习让LLMs学会将搜索融入推理,无需推理步骤的监督数据。实验效果惊艳,快来一探究竟它如何突破困境、提升性能!
论文标题
ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning
来源
arXiv:2503.19470v2 [cs.AI] + https://arxiv.org/abs/2503.19470
代码
https://github.com/Agent-RL/ReCall
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
研究背景
在当今人工智能领域,大语言模型(LLMs)取得了显著进展,它不仅能依靠自身内部知识,还能借助外部搜索工具检索信息,检索增强生成(RAG)技术也因此备受关注。然而,LLMs在实际应用中仍面临挑战。一方面,许多现实问题复杂,需要多步推理,可设计有效的多步RAG策略却很困难。另一方面,现有多步RAG方法依赖手动提示或启发式规则,扩展性差,且标注推理步骤成本高。此外,强化学习虽能提升推理能力,但在结合推理与外部知识检索方面探索不足。
研究问题
-
训练LLMs在信息检索时进行交互式推理是研究难题,现有多步RAG方法多依赖手动设计提示或启发式规则,不仅费力,对更复杂问题还缺乏扩展性。
-
在多步RAG框架中标注推理步骤,成本高且耗时,实际操作困难。
-
目前基于强化学习提升LLMs推理能力的方法,大多聚焦内部推理,对推理与外部知识检索的有效结合探索不足。
主要贡献
1. 创新框架设计:提出ReSearch框架,将搜索操作视为推理链的一部分,通过强化学习训练LLMs基于文本思考决定何时及如何搜索,且无需推理步骤的监督数据,这与以往方法显著不同。
2. 模型训练与效果验证:在不同规模的Qwen模型上训练ReSearch,在多跳问答基准测试中,相比基线模型有显著性能提升,且仅在一个数据集上训练就能在多个基准测试中表现良好,展现出强大的泛化能力。
3. 推理能力激发:分析训练过程发现,ReSearch能自然激发LLMs的反思和自我纠正等高级推理能力,且不依赖预定义的启发式规则。
方法论精要
在探索大语言模型(LLMs)与外部搜索高效协同的道路上,ReSearch提出了一套别具一格的方法体系,核心在于将搜索操作巧妙融入推理过程,借助强化学习让LLMs自主学会合理运用搜索进行推理。
1. 核心算法/框架: 采用 Group Relative Policy Optimization(GRPO)算法训练 LLMs。在这个框架中,推理链由文本思考(<think></think>)、搜索查询(<search></search>)和检索结果(<result></result>)组成,搜索操作与文本思考相互作用。
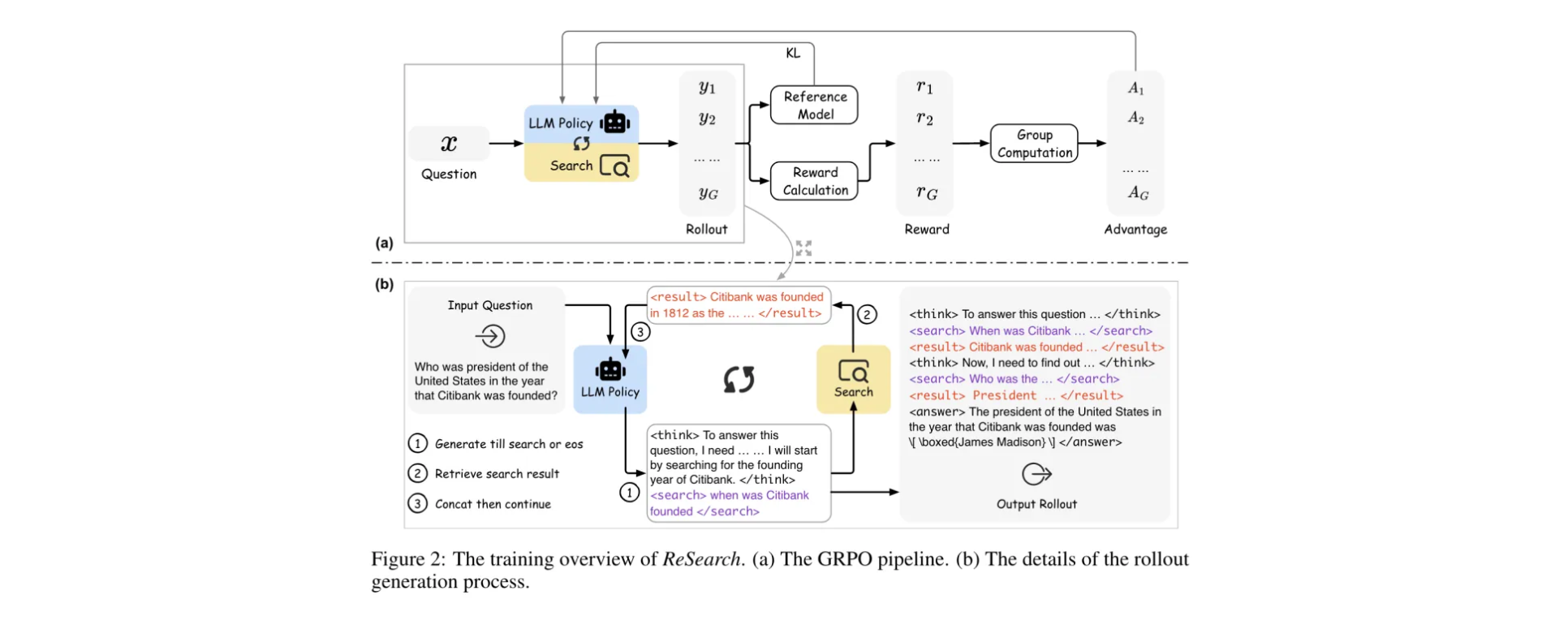
2. 关键参数: GRPO算法中有几个关键参数起着至关重要的作用。裁剪比率(ϵ)防止模型在训练过程中“跑偏”,确保训练的稳定性;KL散度系数(β)避免模型策略偏离参考策略太远,保证模型在优化过程中始终保持一定的“稳健性”。这些参数相互配合,共同引导LLMs在训练中不断优化推理与搜索的协同策略。
3. 创新性技术组合: ReSearch的创新之处在于,将搜索操作深度嵌入推理链中。在这个推理链里,不仅有文本思考(用标记),还有搜索查询(<search></search>)和检索结果(<result></result>)。模型会根据前面文本思考的内容,决定何时进行搜索以及搜索什么内容,而搜索结果又会反过来影响后续的文本思考。在计算损失时,ReSearch会对检索结果进行mask处理,避免训练策略偏向检索结果。

4. 实验验证: 使用四个多跳问答基准测试数据集:HotpotQA、2WikiMultiHopQA、MuSiQue 和 Bamboogle。选取两个简单基线(No RAG 和 Naive RAG)以及两个改进多步 RAG 的方法(Iter - RetGen 和 IRCoT)进行对比。这样选取是因为涵盖了直接生成答案、简单检索生成和先进多步 RAG 策略等不同类型,能全面评估 ReSearch 的性能。
实验洞察
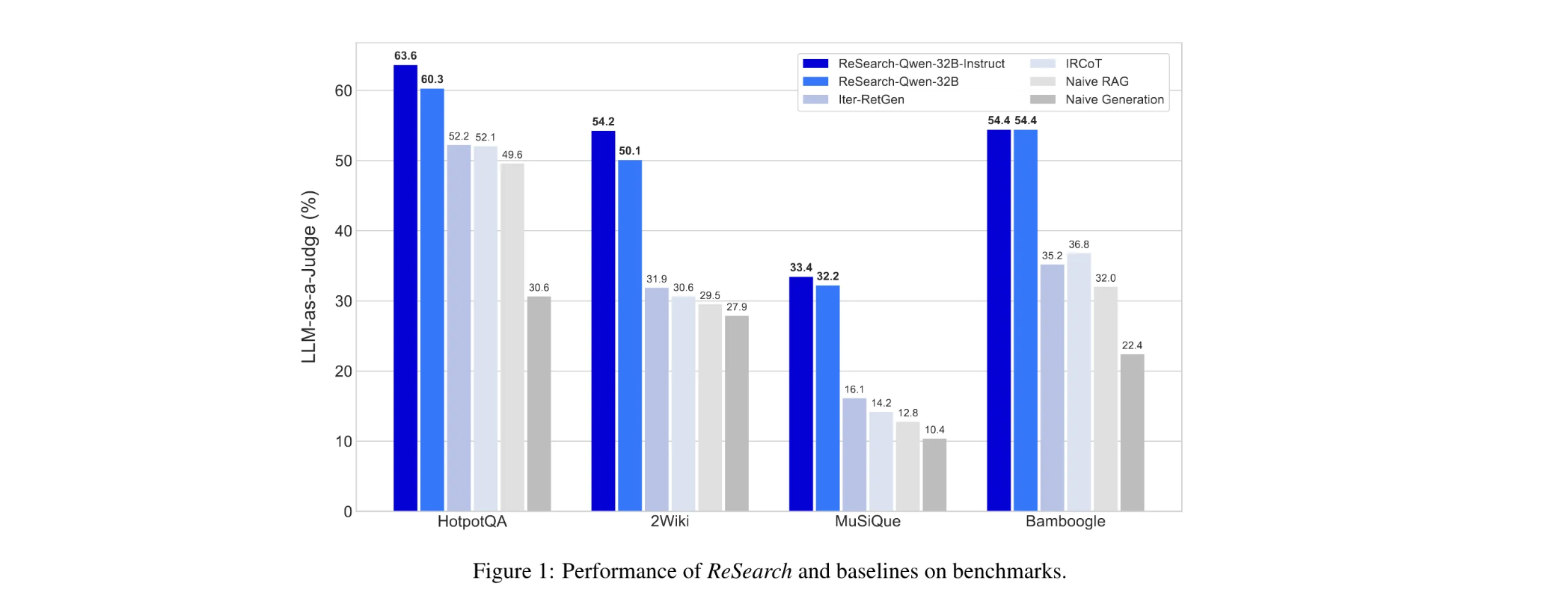
性能优势: 在多个多跳问答基准测试中,ReSearch的表现远超各类基线模型。具体数据如下:
- 对于Qwen2.5-7B模型,在衡量回答与正确答案完全匹配程度的Exact Match指标上,相比表现最佳的基线模型,平均提升幅度高达15.81%。在使用LLM-as-a-Judge这种借助其他大语言模型来评判答案正确性的指标中,其平均提升更是达到17.56%。
- Qwen2.5-32B模型同样表现出色,在Exact Match指标上平均提升14.82%,在LLM-as-a-Judge指标上平均提升15.46% 。这表明ReSearch能让模型在不同规模下,都更精准地应对复杂问题,给出高质量答案。
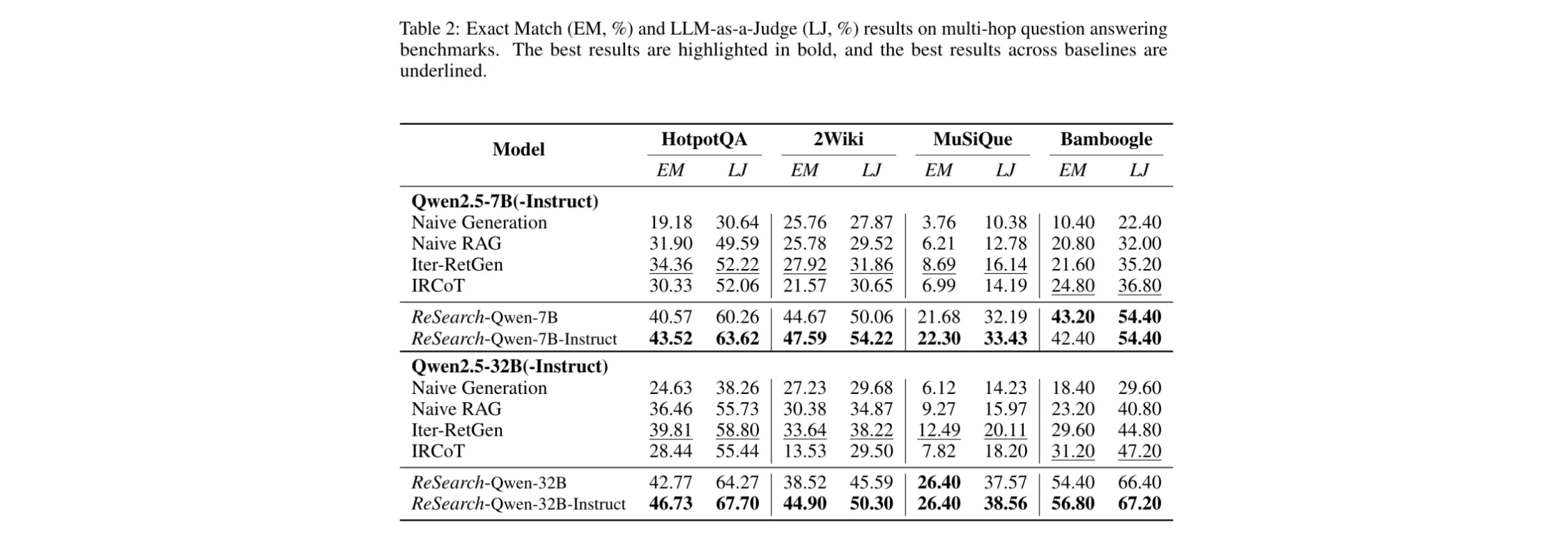
动态性分析: 在训练ReSearch模型的过程中,能观察到模型在推理和搜索策略上的有趣变化:
- 响应长度变化:整体而言,模型的响应长度呈增长态势。以32B模型为例,训练初期因其内部储备知识丰富,倾向于依赖自身生成知识来作答,使得响应较长。随着训练推进,在奖励信号的指引下,模型更多地借助搜索获取信息,响应长度先有所缩短,随后又因对搜索和推理配合的熟练运用而再次变长。
- 搜索操作次数增加:训练期间,模型的搜索操作次数不断增多。这意味着模型逐渐掌握了通过多次迭代搜索来收集信息的技巧,以应对复杂多跳问题,提升问题解决效率。
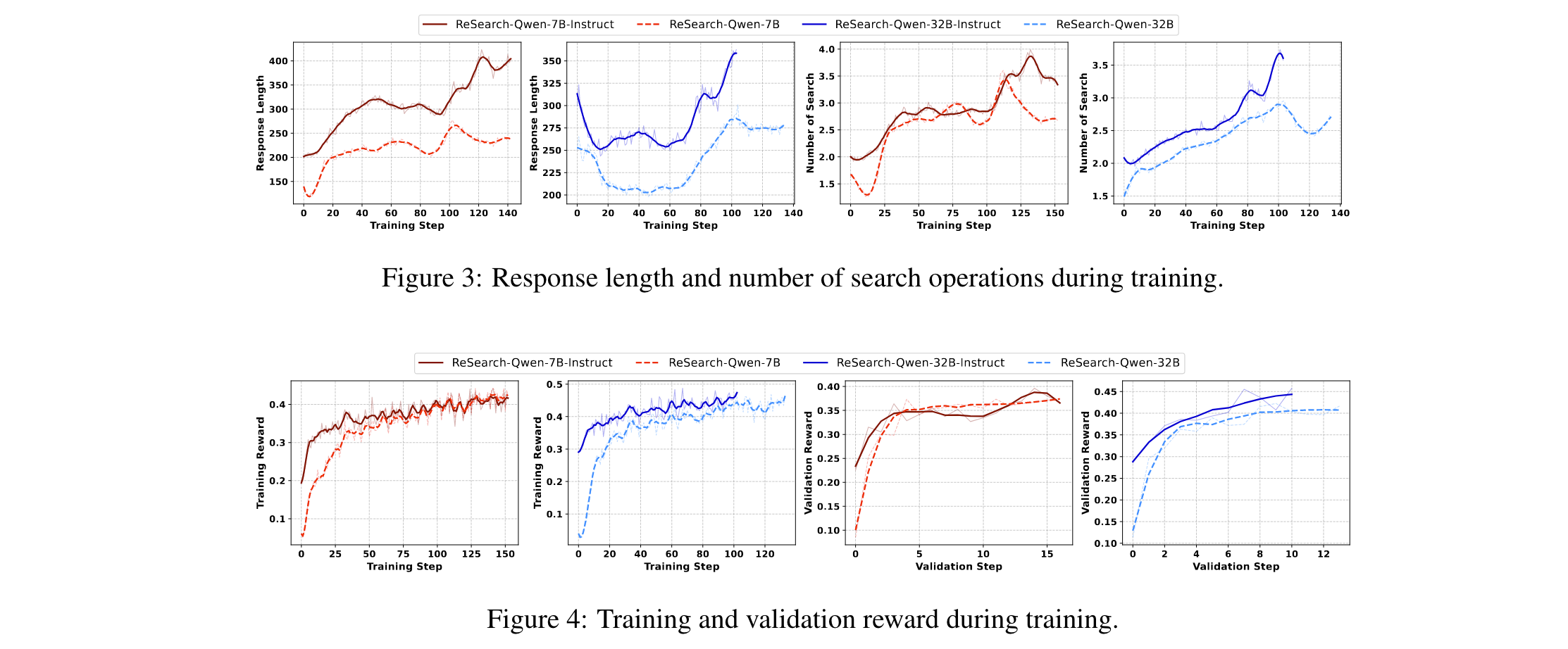
消融研究: 为探究ReSearch框架各组件的作用,研究人员开展了消融实验,从多个关键指标进行分析:
- 模型行为调整:实验发现模型能够依据奖励信号灵活调整推理和搜索行为。当得到积极奖励时,会强化当前策略;反之,则尝试改变策略,证明奖励机制能有效引导模型优化。
- 指令调整的优势:对比不同模型,经过指令调整的模型在训练初期就能获得更高奖励,后续性能提升也更为显著,体现了指令调整对模型训练的积极作用。
- 综合指标验证:通过对响应长度、搜索操作次数、训练和验证奖励等指标的综合分析,充分验证了ReSearch框架中各组件在提升模型性能方面的有效性,它们相互协作,共同促进模型能力的提升。