Informer 预测模型合集:新增特征重要性分析!

往期精彩内容:
单步预测-风速预测模型代码全家桶-CSDN博客
半天入门!锂电池剩余寿命预测(Python)-CSDN博客
超强预测模型:二次分解-组合预测-CSDN博客
VMD + CEEMDAN 二次分解,BiLSTM-Attention预测模型-CSDN博客
超强预测算法:XGBoost预测模型-CSDN博客
基于麻雀优化算法SSA的预测模型——代码全家桶-CSDN博客
VMD + CEEMDAN 二次分解,CNN-Transformer预测模型-CSDN博客
独家原创 | SCI 1区 高创新预测模型!-CSDN博客
风速预测(八)VMD-CNN-Transformer预测模型-CSDN博客
高创新 | CEEMDAN + SSA-TCN-BiLSTM-Attention预测模型-CSDN博客
VMD + CEEMDAN 二次分解,Transformer-BiGRU预测模型-CSDN博客
独家原创 | 基于TCN-SENet +BiGRU-GlobalAttention并行预测模型-CSDN博客
VMD + CEEMDAN 二次分解——创新预测模型合集-CSDN博客
独家原创 | BiTCN-BiGRU-CrossAttention融合时空特征的高创新预测模型-CSDN博客
CEEMDAN +组合预测模型(CNN-Transfromer + XGBoost)-CSDN博客
时空特征融合的BiTCN-Transformer并行预测模型-CSDN博客
独家首发 | 基于多级注意力机制的并行预测模型-CSDN博客
独家原创 | CEEMDAN-CNN-GRU-GlobalAttention + XGBoost组合预测-CSDN博客
多步预测系列 | LSTM、CNN、Transformer、TCN、串行、并行模型集合-CSDN博客
独家原创 | CEEMDAN-Transformer-BiLSTM并行 + XGBoost组合预测-CSDN博客
涨点创新 | 基于 Informer-LSTM的并行预测模型-CSDN博客
独家原创 | 基于 Informer + TCN-SENet的并行预测模型-CSDN博客
即插即用 | 时间编码+LSTM+全局注意力-CSDN博客
粉丝福利 | 再添 Seq2Seq 多步预测模型-CSDN博客
暴力涨点! | 基于 Informer+BiGRU-GlobalAttention的并行预测模型-CSDN博客
热点创新 | 基于 KANConv-GRU并行的多步预测模型-CSDN博客
重大更新!锂电池剩余寿命预测新增 CALCE 数据集_calce数据集-CSDN博客
基于 VMD滚动分解+Transformer-GRU并行的锂电池剩余寿命预测模型
前言
本期我们更新 Informer 相关预测模型合集,增添关于特征重要性的分析:
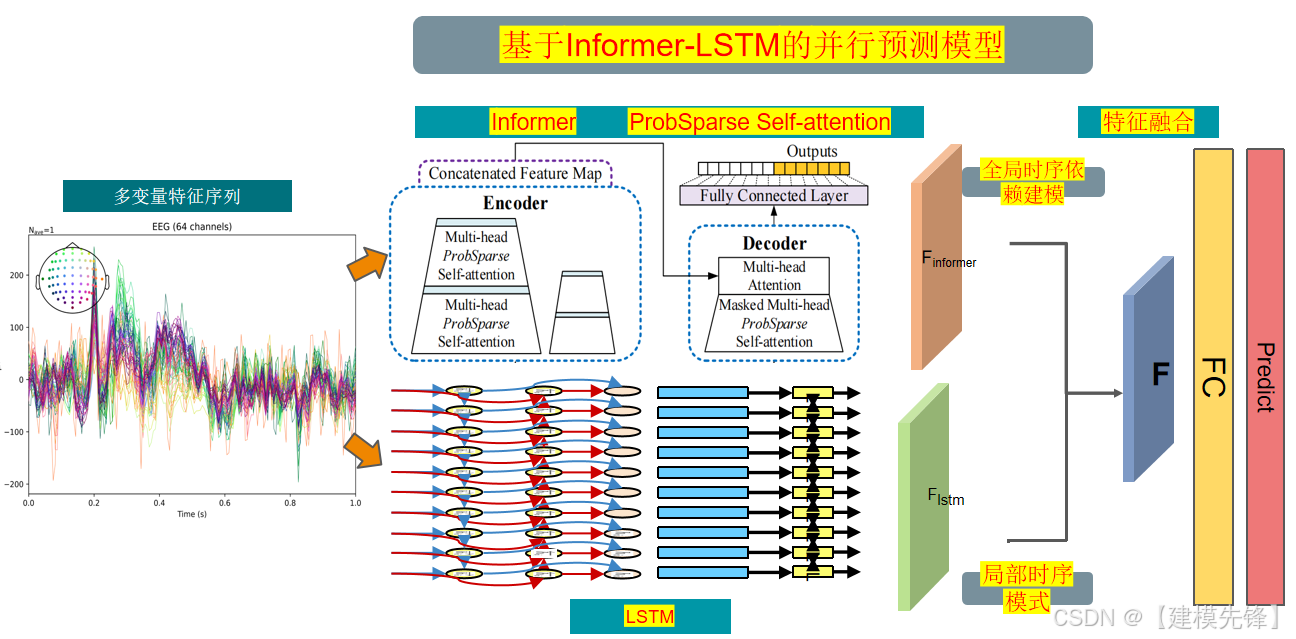
1 基于Informer-LSTM的并行预测模型
原文介绍:
涨点创新 | 基于 Informer-LSTM的并行预测模型_基于informer成熟的 功率预测的开源模型有那些, 可以直接传气象数据就可以用的-CSDN博客
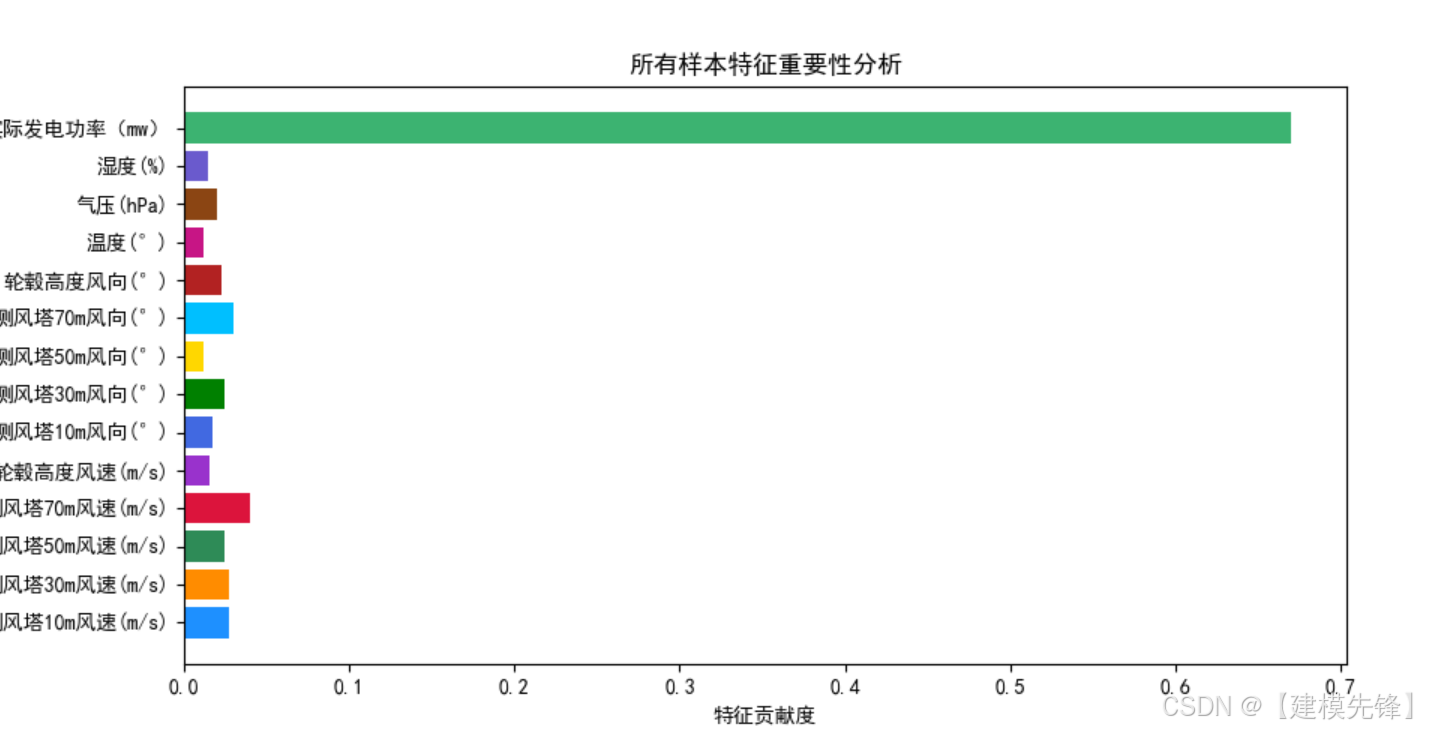
风电功率数据集特征分析—可视化:
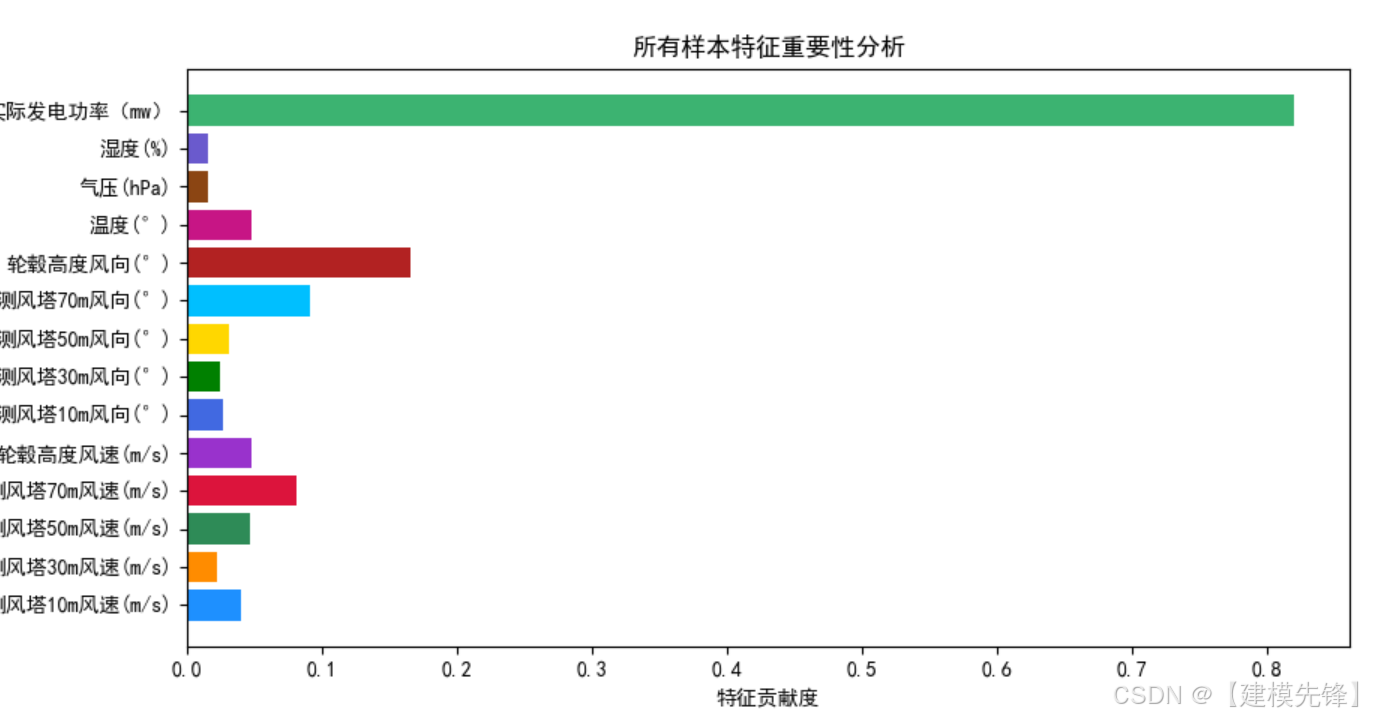
2 基于Informer + TCN-SENet的并行预测模型
原文介绍:
独家原创 | 基于 Informer + TCN-SENet的并行预测模型-CSDN博客
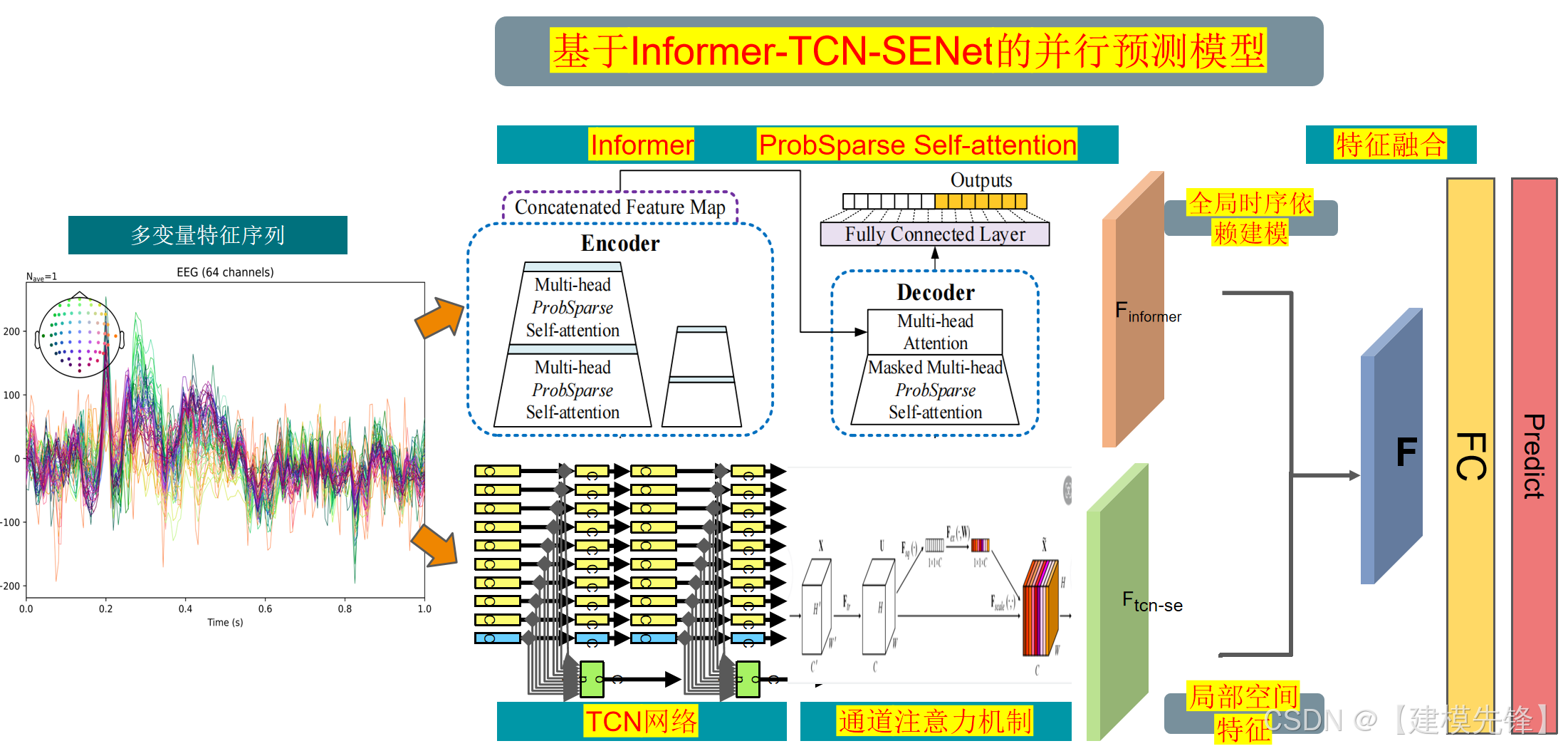
风电功率数据集特征分析—可视化:
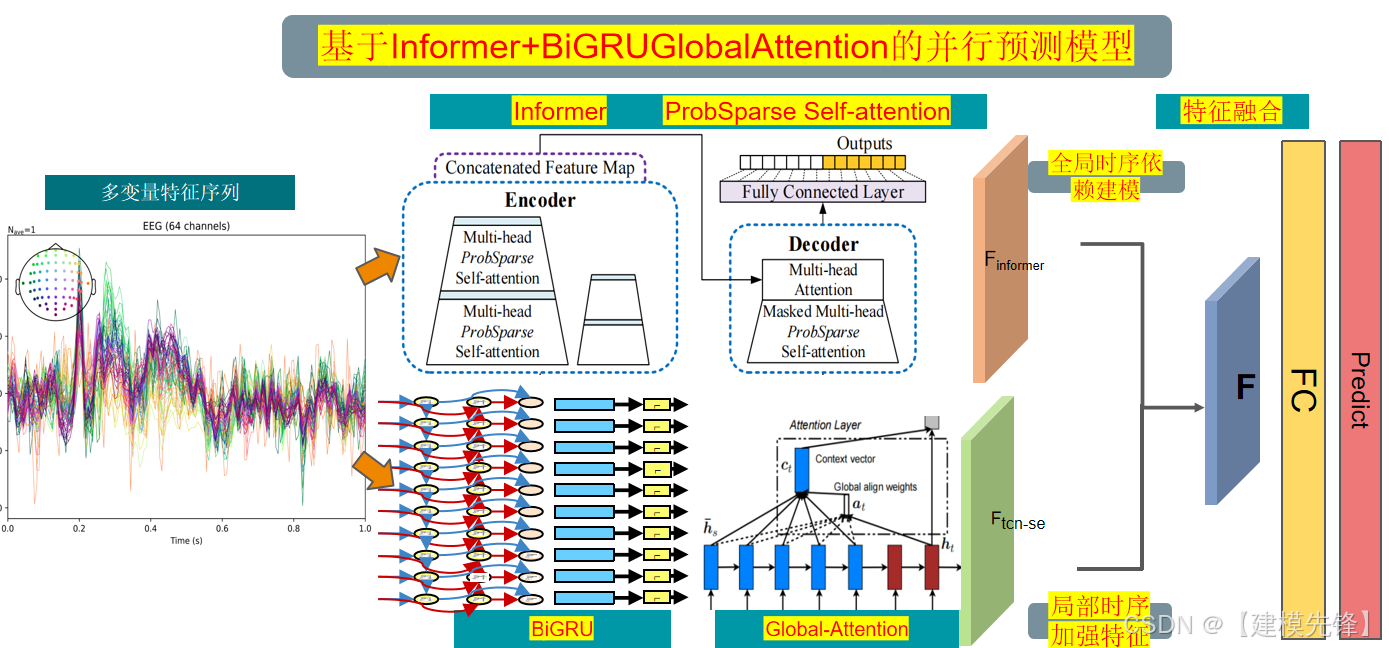
3 基于Informer+BiGRU-GAtt的并行预测模型
原文介绍:
暴力涨点! | 基于 Informer+BiGRU-GlobalAttention的并行预测模型_+informer++视觉架构图-CSDN博客
电力变压器数据集特征分析—可视化:
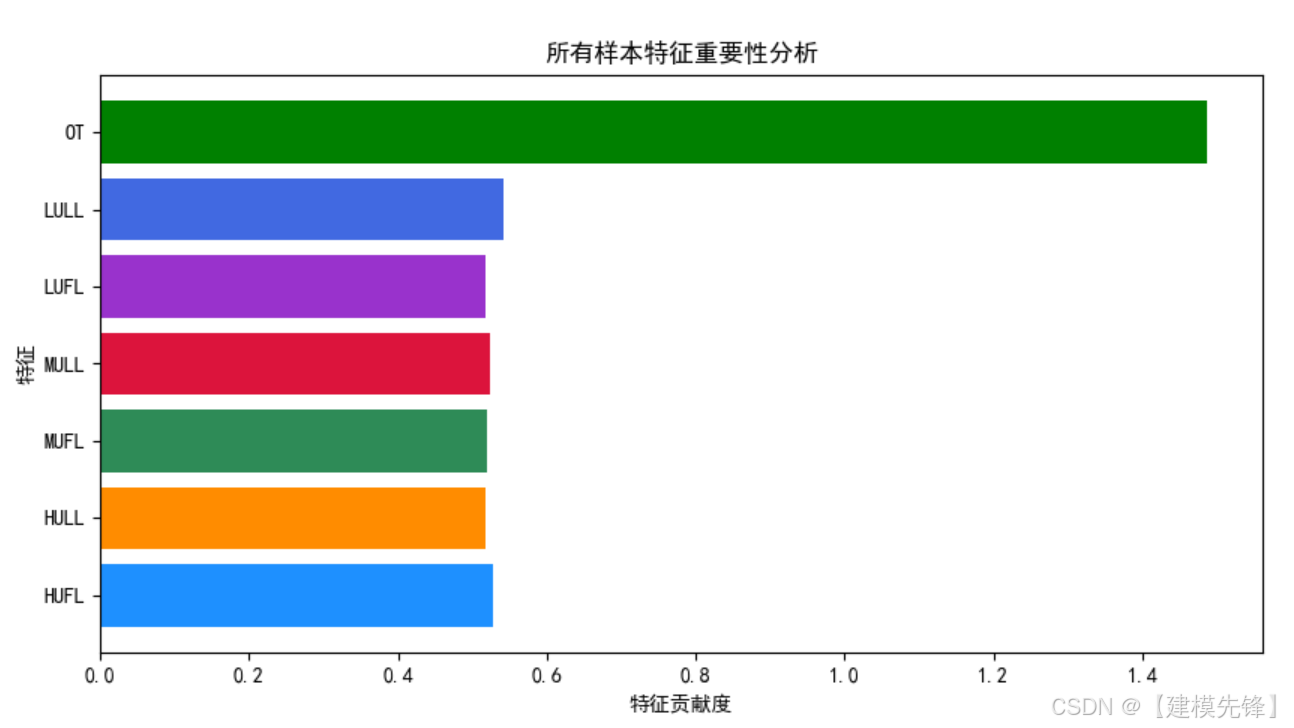
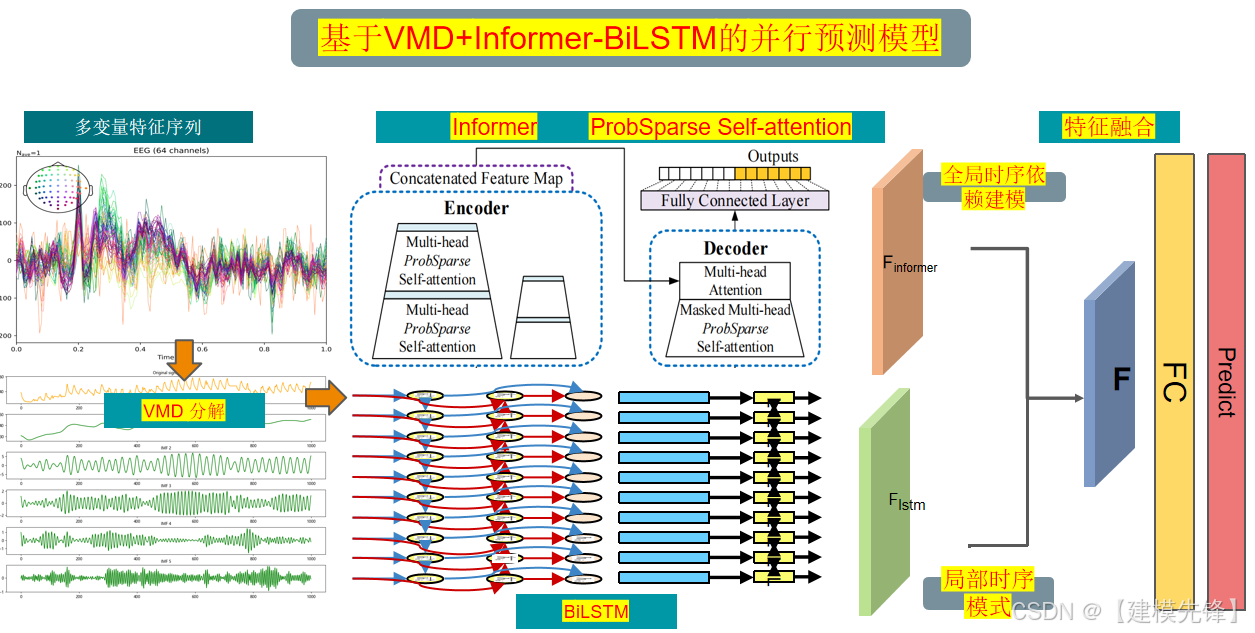
4 基于VMD滚动分解 + Informer-BiLSTM的预测模型
原文介绍:
拒绝信息泄露!VMD滚动分解 + Informer-BiLSTM并行预测模型_vmd加lstm会造成数据泄露吗-CSDN博客
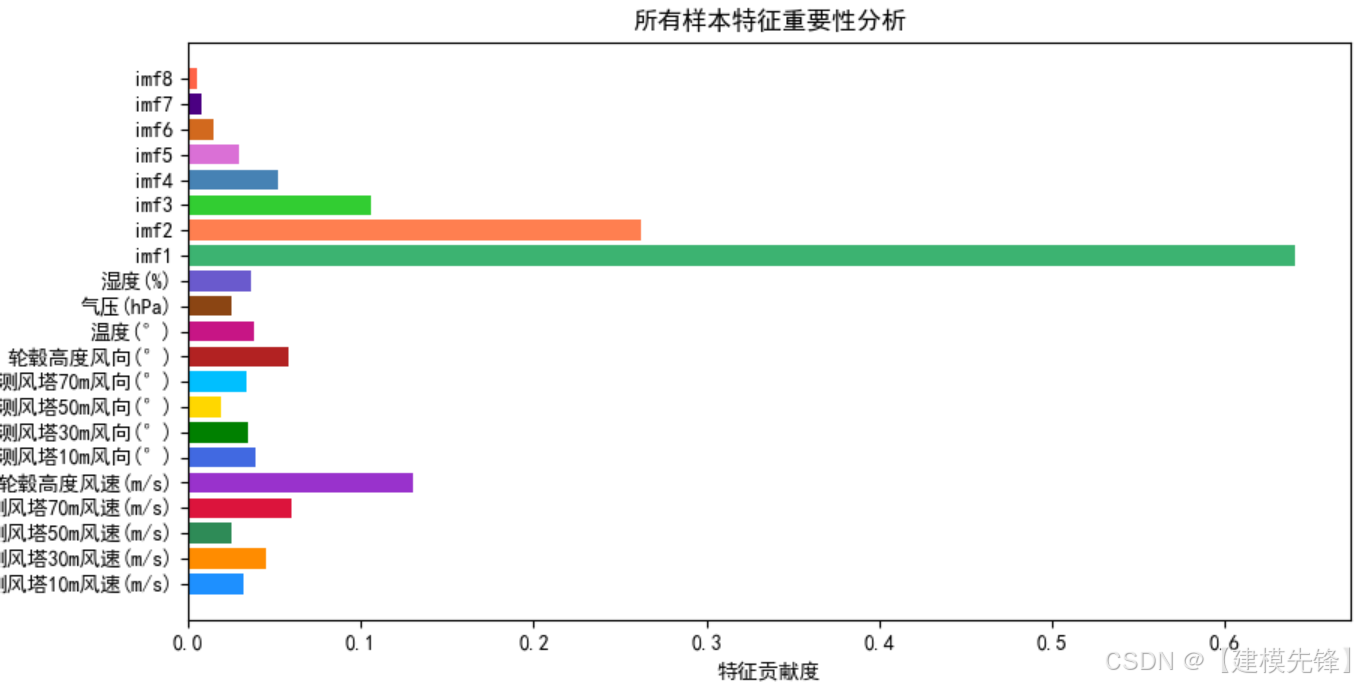
风电功率数据集+VMD分解特征分析—可视化:
5 Informer 详解,三大创新点
5.1 概率稀疏注意力机制(ProbSparse Self-attention)
概率稀疏自注意力是Informer模型中引入的一种稀疏自注意力机制。其核心思想是通过概率方法选择最重要的一部分注意力权重进行计算,而忽略那些对结果影响较小的权重。这种方法能够显著降低计算复杂度,同时保持较高的模型性能。
-
稀疏自注意力:不同于标准 Transformer 的密集自注意力机制,Informer 引入了 ProbSparse Self-attention,通过概率抽样机制选择重要的 Q-K 对进行计算,减少了计算复杂度。
-
效率提升:稀疏注意力机制显著降低了计算复杂度,从 O(L2⋅d) 降低到 O(L⋅log(L)⋅d),其中 L 是序列长度,d 是每个时间步的特征维度。
5.2 多尺度特征提取-信息蒸馏
Informer的架构图并没有像Transformer一样在Encoder的左边标注来表示N个Encoder的堆叠,而是一大一小两个梯形。横向看完单个Encoder(也就是架构图中左边的大梯形,是整个输入序列的主堆栈)。
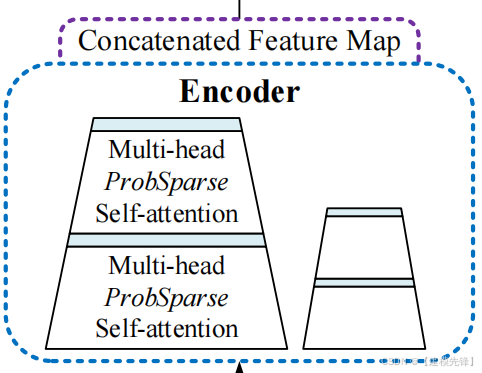
Encoder的作用是Self-attention Distilling,由于ProbSparse自相关机制有很多都是用V的mean填充的,所以天然就存在冗余的attention sorce ,因此在相邻的Attention Block之间应用卷积与池化来对特征进行下采样,所以作者在设计Encoder时,采用蒸馏的操作不断抽取重点特征,从而得到值得重点关注的特征图。
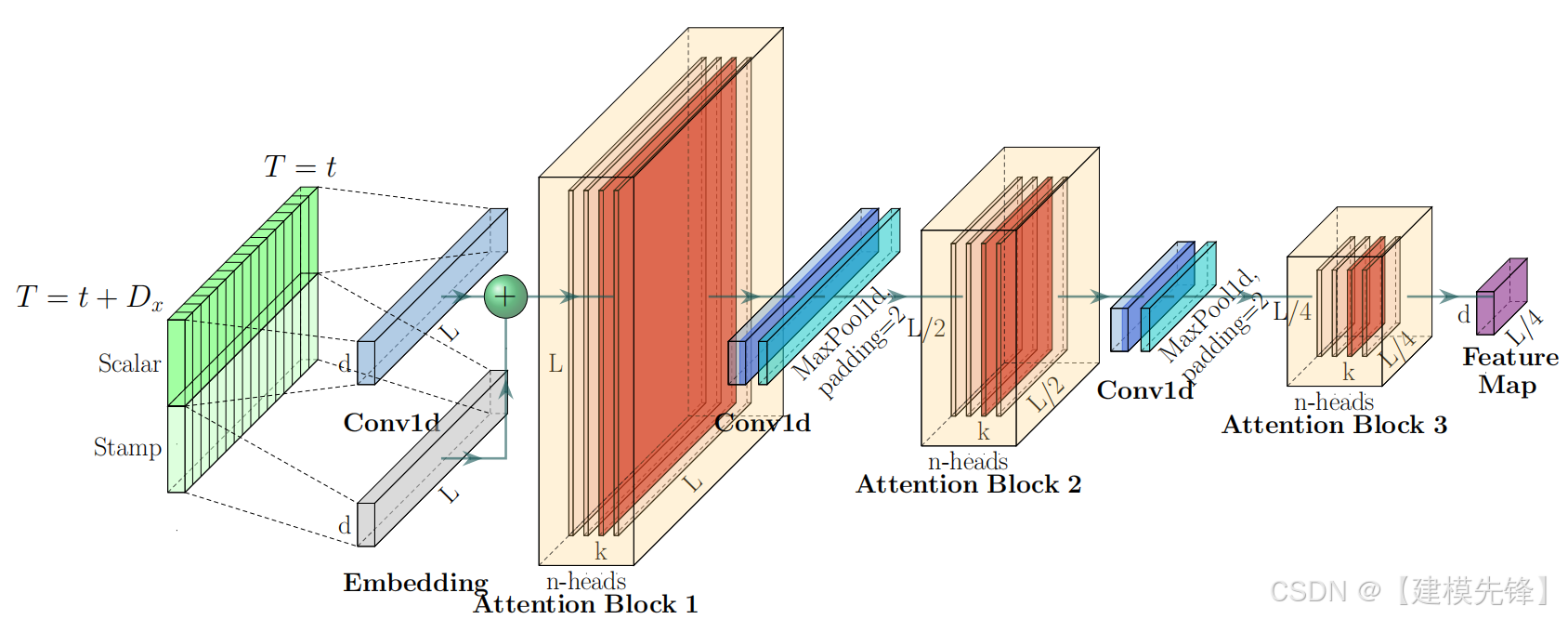
-
多尺度时间序列特征提取:Informer 通过多尺度的方式对不同时间粒度的特征进行建模,可以更好地捕捉时间序列中的多尺度依赖关系。
-
信息蒸馏:引入了信息蒸馏机制,通过层次化的时间卷积池化层逐步缩减时间步长,提取不同尺度的特征,实现长时间依赖的高效建模。
-
卷积降维:在编码器中使用1D卷积池化层进行降维,步长为2,使得序列长度减半,进一步减少计算复杂度。
-
信息压缩:通过卷积池化层进行信息压缩,将长序列信息浓缩到较短的时间步长中,从而更高效地进行时序建模。
5.3 时间编码
Informer在原始向量上不止增加了Transformer架构必备的PositionEmbedding(位置编码)还增加了与时间相关的各种编码:
-
日周期编码:表示一天中的时间点。
-
周周期编码:表示一周中的时间点。
-
月周期编码:表示一个月中的时间点。
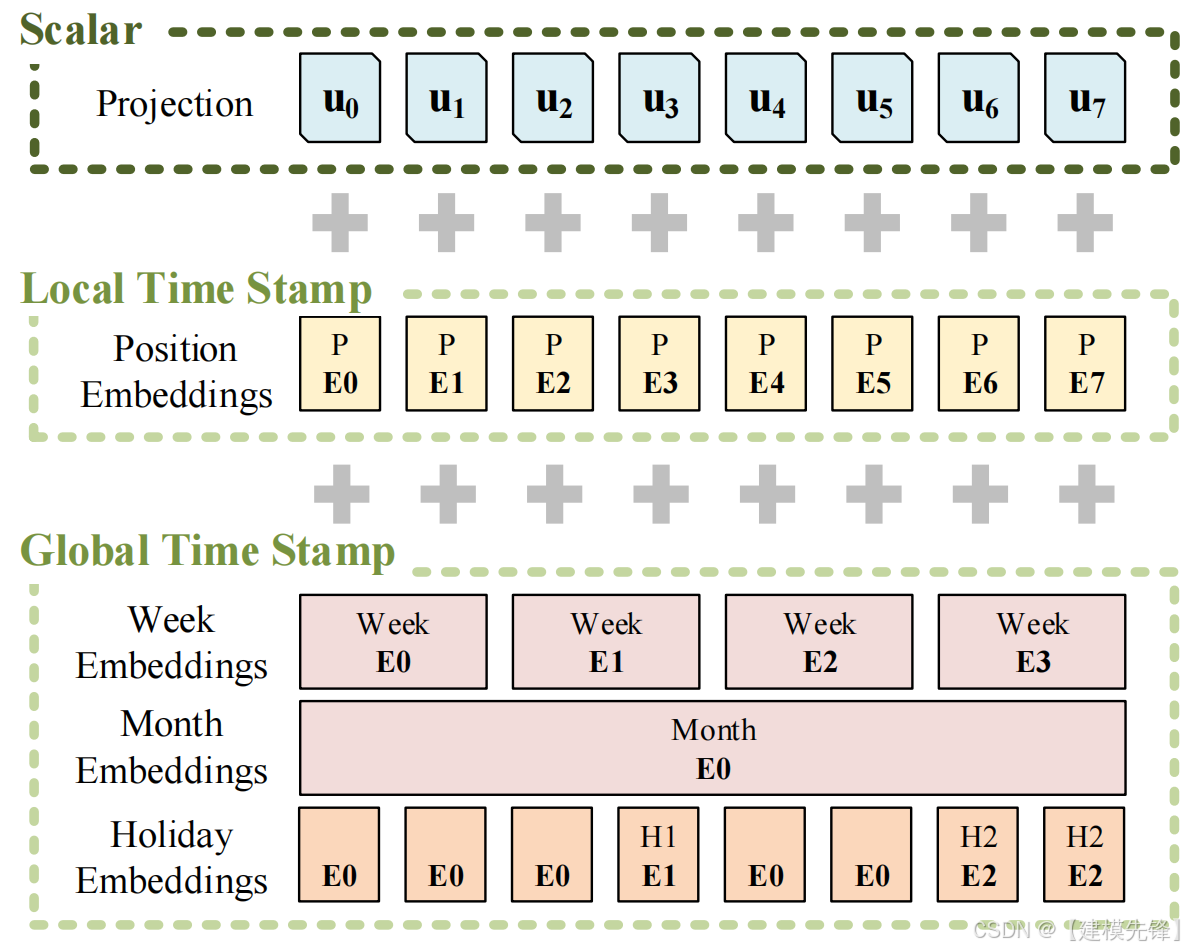
在 LSTF 问题中,捕获远程独立性的能力需要全局信息,例如分层时间戳(周、月和年)和不可知时间戳(假期、事件)。
具体在这里增加什么样的GlobalTimeStamp还需要根据实际问题来确认,如果计算高铁动车车站的人流量,显然“假期”的时间差就是十分重要的。如果计算公交地铁等通勤交通工具的人流量,显然“星期”可以更多的揭示是否为工作日。
6 代码、数据整理如下:
点击下方卡片获取代码!