树上背包学习笔记
树上背包,顾名思义,就是在树上跑背包。每日顾名思义
Q:那么到底为什么要树上跑背包 dp 呢?
A:因为我们到现在学的背包 dp 还是属于较浅的一类,什么 01 背包、完全背包还是多重背包,但是如果这个东西变得较为复杂一些,例如如果存在了依赖关系(即选某个东西才可以选另一个东西),前面的背包就束手无策了。
实际上,树上背包就是把背包 dp 用到了树的上面。
不如先看一个引入题。
P2014 [CTSC1997] 选课
在大学里每个学生,为了达到一定的学分,必须从很多课程里选择一些课程来学习,在课程里有些课程必须在某些课程之前学习,如高等数学总是在其它课程之前学习。现在有 N N N 门功课,每门课有个学分,每门课有一门或没有直接先修课(若课程 a 是课程 b 的先修课即只有学完了课程 a,才能学习课程 b)。一个学生要从这些课程里选择 M M M 门课程学习,问他能获得的最大学分是多少?
N , M ≤ 300 N,M \le300 N,M≤300。
发现每一个东西都可能存在一个依赖关系,果断使用树上背包。
注意到题面中有这样的一句话:
每门课有一门或没有直接先修课
联想到树上面去,发现每门课如果有一门先修课,就类似于每一个儿子都恰好有一个父亲。每门课如果没有先修课,就类似于每一个根结点。
于是考虑根据先修课的关系来建图,最终会形成一个森林的形式,每一棵树之间互不干扰。
但是这样的话,又会产生问题:最终是所有的点中选择 M M M 个,而不是单棵树中选择 M M M 个。
所以要将森林重新变成一颗更大的树。考虑建 0 0 0 号虚点,作为新的树的根结点,并连接原本每一棵树的根结点作为儿子。
但是这时候有一个小细节:因为 0 0 0 是必选的(否则其他东西都选不了),所以直接将 m + 1 → m m+1 \to m m+1→m 即可。
于是我们成功地将问题转化成了:
给定一棵树,点带权,需要你在里面选 M M M 个点,注意如果要选儿子就必须要选父亲。求最终权值。特别地, 0 0 0 的权值为 0 0 0。
考虑 d p dp dp。设 d p u , i dp_{u,i} dpu,i 表示在 u u u 为根的子树内,选 i i i 个可以得到的最大权值是多少。
考虑转移,但是好像遇到了亿点点麻烦。。。显然可以枚举每一个子结点的子树选了多少个,最终合并起来得到答案,但是太慢了。
所以,这样的状态并不能行得通。因此,考虑改变状态。
注意我们讲的是树上背包,但是我们只是在树上跑了 dp,并没有跑背包。所以考虑背包。
显然可以把点权变成价值,而把 1 1 1 作为每一个点的代价,而每一个点可以选择也可以不选择。这样就转换为了一个背包问题。
考虑使用 d p u , i , j dp_{u,i,j} dpu,i,j 表示 u u u 为根的子树内,考虑了前 i i i 个子结点,选了 j j j 个可以得到的最大权值是多少。
转移显然。为了优化转移方程,可以使用滚动数组。因为这是 01 背包所以需要倒序处理。
#include <bits/stdc++.h>
using namespace std;
#define int long long
#define N 310
int n, m, x, y, dp[N][N], val[N];
vector<int> edge[N];void dfs(int u) {dp[u][1] = val[u];for (auto v : edge[u]) {dfs(v);for (int i = m; i >= 1; i--)//转移 u 选了 i 节课的答案for (int j = i - 1; j >= 1; j--)//u 的这个儿子 v 选了 i - j 节课的答案dp[u][i] = max(dp[u][i], dp[u][i - j] + dp[v][j]);//合并两个背包}
}signed main() {ios::sync_with_stdio(0);cin >> n >> m;m++;for (int x = 1; x <= n; ++x) {cin >> y >> val[x];edge[y].push_back(x);}dfs(0);cout << dp[0][m] << endl;return 0;
}
这里的复杂度是 O ( n × m 2 ) O(n \times m^2) O(n×m2) 的,有一些慢,后面我们会讲更加快速的做法。
观察 dfs 里面的转移步骤,可以发现这个东西本身其实上可以说是把子结点的背包合并了。这个观点很好理解。所以,这种求解树上背包的方法也叫做dfs 合并。
所以这个有依赖的背包就这么做完了,但是以后的树上背包大差不差的都是一个样子,所以就可以按照固定的东西想即可。
P2014 更好的写法
实际上这里还有一种实现方法,那就是使用 s u m sum sum 来把转移次数优化一下,尤其是 n , m n,m n,m 同阶的时候。
到底是怎么思考的呢?
很容易发现,上面的代码有一行是 for (int i = m; i >= 1; i--),但是实际上我们并不需要枚举那么多次,实际上只需要枚举 s u m sum sum 次就可以了。(当然如果 min ( m , s u m ) \min(m,sum) min(m,sum) 还可以更快)
所以把 for (int i = m; i >= 1; i--) 更改成 for(int i = min(m, sum[u]);i >= 0;i--) 即可。
考虑同样把这个东西用到 for (int j = i - 1; j >= 1; j--) 上面去。但是这样子是做差的,所以考虑枚举 v 选了多少课,以代替以前的枚举。
于是:
for (int j = i - 1; j >= 1; j--)dp[u][i] = max(dp[u][i], dp[u][i - j] + dp[v][j]);
变成了:
for(int j = min(m, sum[v]);j >= 0;--j)dp[u][i + j] = max(dp[u][i + j], dp[u][i] + dp[v][j]);//把减变成了加
最终得出来这样的代码:
void dfs(int u,int pre)
{/* DP初始化 */ sum[u] = 1;for(auto v : edge[u]) if(v != pre) {dfs(v,u);for(int i = min(m, sum[u]);i >= 0;--i)//枚举 u 选了 i 节课for(int j = min(m, sum[v]);j >= 0;--j) //枚举 v 选了 j 节课dp[u][i + j] = max(dp[u][i + j], dp[u][i] + dp[v][j]);sum[u] += sum[v];}
}
略加数学分析可得这样的代码复杂度是 O ( n 2 ) O(n^2) O(n2)。
是这样分析的:对于每一个 u u u 都最多要转移 s u m u × n sum_u \times n sumu×n 次,而把所有结点加起来就是 ∑ ( s u m u × n ) = ∑ s u m u × n = n × n \sum (sum_u \times n) = \sum sum_u \times n = n \times n ∑(sumu×n)=∑sumu×n=n×n,是不是很奇妙!
当然,如果 m m m 远小于 n n n,则使用 O ( n × m 2 ) O(n \times m^2) O(n×m2) 会优秀一点,否则使用 O ( n 2 ) O(n^2) O(n2) 优秀一点,这两个东西都不可以抛弃掉。
U53204 【数据加强版】选课
这道题是 P2014 [CTSC1997] 选课 的一个超级数据加强版,原本 O ( n 2 ) O(n^2) O(n2) 地算法只能拿到 50 分。
这道题,如果使用上面给出的代码并略加修改,只能得到 50pts 的好成绩。所以上面的方法在这道题是行不通的。
所以,在这道题里面我将介绍一种新的树形背包方法,也就是在 dfs 序上面进行的奇妙 dp。
这样复杂度是 O ( n m ) O(nm) O(nm) 的,也是非常优秀的了。而且题目保证了 n m ≤ 1 0 8 nm \le 10^8 nm≤108,使用这种方法恰好可以卡过。
接下来开始讲解思路。
考虑先看一棵树,作为例子:
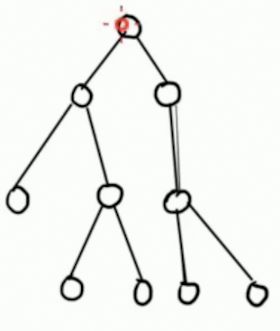
显然我们可以发现,如果最上面的点被选了,那么就可以考虑它最左边的一个儿子。
如果这个儿子被选了,那么就可以继续考虑它最左边的一个儿子。
如果它的左边的儿子已经考虑完了,那么就可以开始考虑右边的儿子。
如果这个儿子没有被选,则显然不能考虑任何一个儿子。
……
最终,考虑的顺序是这样子的:
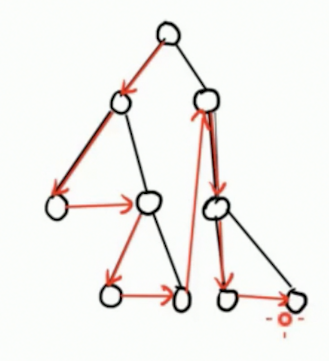
那么,看到这个东西,你的脑子里面还没有一点点灵感吗?
这不就是 dfs 序嘛!
考虑转移。
如果一个点被选了,它就会转移到下一个 dfs 序代表的位置。
而且,如果一个点没有被选,则其子树所有的点都不能被选!!!完美符合 dfs 序的优秀传统:只需要跳到子树区间右端点 + 1 +1 +1 的位置即可。
所以,这个时候我们就已经把它转换为了一个序列式的 dp,且转移也已经明确,直接跑背包即可。复杂度显然就是 O ( n m ) O(nm) O(nm) 的。
**但是因为这不是相邻进行转移,而是会带有一些跳跃性地转移,所以不能使用滚动数组。空间复杂度也是 O ( n m ) O(nm) O(nm) 的。**但是空间有 500 500 500 MB,所以直接开 int 数组也可以开的下。
个人感觉这种方法非常的优美。
关于实现的一些注意事项:
-
因为数据范围只给了 n m nm nm 的取值,并没有特别地约束 n , m n,m n,m 分别的值,如果开数组的话就会开不下,应该在主函数里面开 vector 二维数组。
-
一开始要让 v a l 0 = 1 val_0 = 1 val0=1,不然后面就无法转移,最后直接把答案减一即可。
其他的看代码就可以了。
#include <bits/stdc++.h>
using namespace std;
const int N = 100010;
int n, m, x, y;
int val[N], l[N], r[N];
int id[N], dfn;
vector<int> v[N];void dfs(int u) {l[u] = ++dfn, id[dfn] = u;for (auto i : v[u])dfs(i);r[u] = dfn;
}int main() {cin >> n >> m;m++;for (int x = 1; x <= n; x++) {cin >> y >> val[x];v[y].push_back(x);}dfs(0);val[0] = 1;vector<vector<int> > dp(n + 10, vector<int>(m + 10));//二维数组for (int i = 1; i <= n + 1; i++) {int x = id[i];for (int j = 0; j <= m; j++)if (dp[i][j] > 0 || i == 1) {//要判断这是否是合法状态dp[i + 1][j + 1] = max(dp[i + 1][j + 1], dp[i][j] + val[x]);dp[r[x] + 1][j] = max(dp[r[x] + 1][j], dp[i][j]);}}cout << dp[n + 2][m] - 1;return 0;
}
CF815C Karen and Supermarket
仿照日常的树上背包,不难设计出 d p u , n u m , 0 / 1 dp_{u,num,0/1} dpu,num,0/1 表示 u u u 的子树里面选了 n u m num num 个物品, u u u 不使用 / 使用优惠券的最小花费。
考虑如何写出转移。
首先,我们可以不用 u u u,所以子树内也就没有点会被使用:
d p u , i + j , 0 = min ( d p u , i + j , 0 , d p u , i , 0 + d p v , j , 0 ) dp_{u,i+j,0} = \min(dp_{u,i+j,0},dp_{u,i,0}+dp_{v,j,0}) dpu,i+j,0=min(dpu,i+j,0,dpu,i,0+dpv,j,0)
其次,我们可以使用 u u u,且对于 v v v,这个 u u u 的子结点也使用:
d p u , i + j , 1 = min ( d p u , i + j , 1 , d p u , i , 1 + d p v , j , 1 ) dp_{u,i+j,1} = \min(dp_{u,i+j,1},dp_{u,i,1}+dp_{v,j,1}) dpu,i+j,1=min(dpu,i+j,1,dpu,i,1+dpv,j,1)
最后,我们可以使用 u u u,但是对于 v v v 不使用优惠券:
d p u , i + j , 1 = min ( d p u , i + j , 1 , d p u , i , 1 + d p v , j , 0 ) dp_{u,i+j,1} = \min(dp_{u,i+j,1},dp_{u,i,1}+dp_{v,j,0}) dpu,i+j,1=min(dpu,i+j,1,dpu,i,1+dpv,j,0)
考虑初始状态,显然 n u m = 0 num=0 num=0 和 n u m = 1 num=1 num=1 的情况我们会选择特殊考虑。
{ d p u , 0 , 0 = 0 d p u , 1 , 0 = a u d p u , 1 , 1 = a u − b u \begin{cases} dp_{u,0,0} = 0\\ dp_{u,1,0} = a_u \\ dp_{u,1,1} = a_u - b_u \end{cases} ⎩ ⎨ ⎧dpu,0,0=0dpu,1,0=audpu,1,1=au−bu
其他的东西都可以根据这几个初始状态算出来。
答案显然就是找最大的 i i i 来满足 min ( d p 1 , i , 0 , d p 1 , i , 1 ) ≤ m o n e y \min(dp_{1,i,0},dp_{1,i,1}) \le money min(dp1,i,0,dp1,i,1)≤money,其中 m o n e y money money 是她的预算。
#include <bits/stdc++.h>
#define int long long
using namespace std;
const int N = 5010;
int n, m, a[N], b[N];
int dp[N][N][2], siz[N];
vector<int> v[N];void dfs(int u) {dp[u][0][0] = 0;dp[u][1][0] = a[u];dp[u][1][1] = a[u] - b[u];siz[u] = 1;for (int x : v[u]) {dfs(x);for (int i = siz[u]; i >= 0; i--)for (int j = 0; j <= siz[x]; j++)dp[u][i + j][0] = min(dp[u][i + j][0], dp[u][i][0] + dp[x][j][0]),dp[u][i + j][1] = min(dp[u][i + j][1], dp[u][i][1] + min(dp[x][j][0], dp[x][j][1]));siz[u] += siz[x];}
}signed main() {cin >> n >> m >> a[1] >> b[1];memset(dp, 0x3f, sizeof dp);for (int i = 2, x; i <= n; i++)cin >> a[i] >> b[i] >> x, v[x].push_back(i);dfs(1);for (int i = n; i >= 0; i--)if (min(dp[1][i][0], dp[1][i][1]) <= m) {cout << i;return 0;}return 0;
}