【论文阅读】DETR+Deformable DETR
可变形注意力是目前transformer结构中经常使用的一种注意力机制,最近补了一下这类注意力的论文,提出可变形注意力的论文叫Deformable DETR,是在DETR的基础上进行的改进,所以顺带着把原本的DETR也看了一下。
一、DETR
DETR本身是一个使用transformer结构进行目标检测的模型,在相关工作这一节作者提到使用了一种叫做集合预测的方法,集合预测不同于传统的目标检测方法,这类方法是直接输出固定大小的包围框的集合,而传统的方法是不固定的包围框再使用极大值抑制进行后处理。使用这一结构之后,设计DETR需要解决两个关键问题,如何建立一个基于集合的损失函数以及集合内部的对应关系应该如何构建。
匹配关系的建立
DETR首先约定了自己能够检测到的目标的数量的最大值N,如果图像中的物体超过了这个数量也没用,只能检测出N个物体。对于检测出的N个物体,如何与groundtruth建立联系是DETR需要解决的第一个问题,这里作者使用了匈牙利算法进行解决。简单来说,匈牙利算法就是从全局角度找出一个让整体效果最优的一对一匹配关系。传统的目标检测构建的实际上是一个多对多的关系,利用正负样本来指导模型预测的包围框应该属于哪个真值。使用匈牙利算法,我们需要构建一个真值与预测之间的一对一关系,让这个关系组的误差最小化。对于预测的N个物体,我们一般假设N要大于实际存在的物体数量,超过的部分将包围框的类别标记为空,即无物体。之后利用下面的式子进行优化:
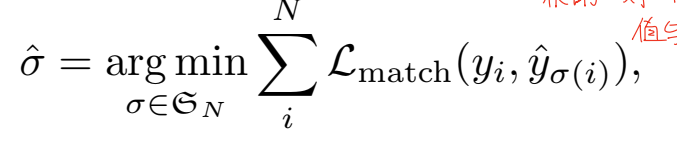
其中Lmatch可以理解为一个损失值,用于描述当我们将第i个物体与第б(i)个物体匹配时错误带来的影响。这个误差包括两部分:类别的差异和包围框的差异。类别的差异直接使用最简单粗暴的负对数似然损失,我们希望预测的类别的可信度尽可能接近当前匹配的真值中的类别。而包围框差异的部分,我们同时考虑交并比差异和包围框边界差异。交并比差异采用的是GIOU进行计算,它在原始 IoU 基础上,再减去预测框与真实框在最小闭包矩形中未覆盖区域的比重。而包围框边界差异指的则是包围框的四个端点与真实值之间的差异。最终包围框差异的计算公式为:
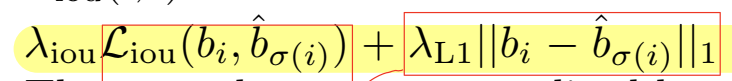
在此基础上得到的匈牙利算法的计算公式为:
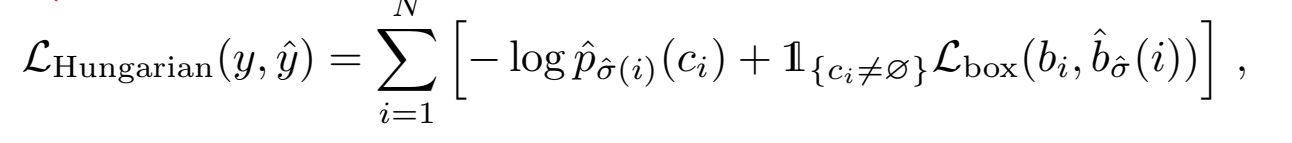
DETR模型设计
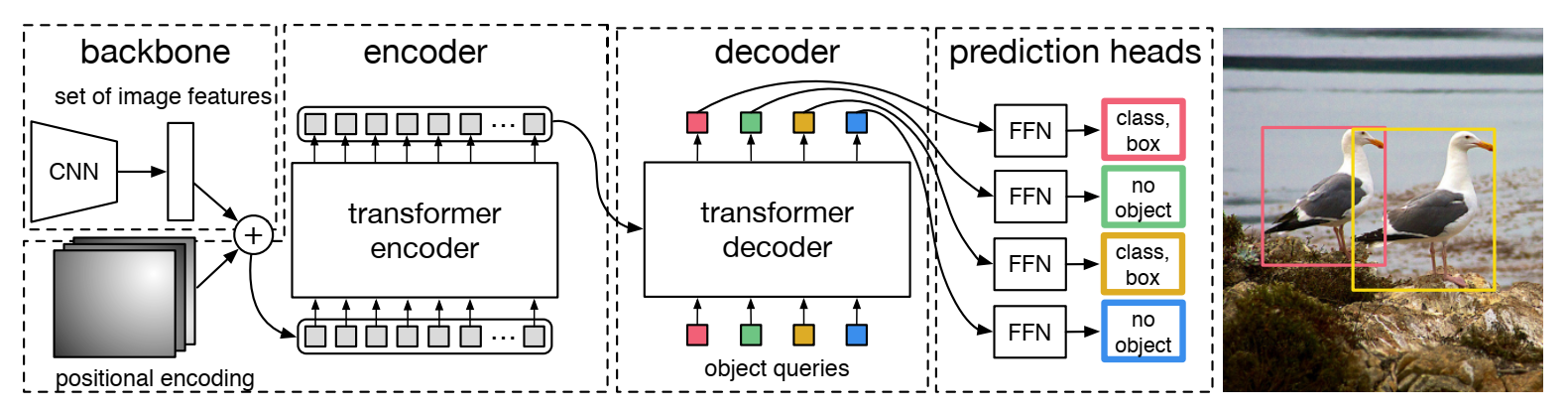
模型设计的部分,DETR首先采用一个CNN进行特征提取,提取好的特征图送入transformer的编码器部分进行处理,送入编码器之前首先使用1×1卷积进行维度调整,假设原来的特征图维度是C×H×W,调整的过程使用1×1卷积进行,从而将新的特征图维度调整为d×H×W,之后这d张特征图被调整为HW个d维的向量,这些向量会被作为token再加入2d位置编码后送入编码器。encoder的部分首先是这d个token自己之间计算自注意力,在多个编码器块之后得到提取结果。
解码器的部分则是使用N个可学习query进行提取,这里的N对应的就是前面的N个物体。这N个查询首先进行自注意力产生相互关系,之后再与encoder的输出计算交叉注意力进行提取,这N个查询的结果最终经过一个前馈神经网络调整为N个预测结果。
二、Deformable DETR
Deformable DETR是对DETR的改进,针对收敛慢、小物体识别不好的问题,但是从结果来看,其提出的可变形注意力貌似比本身模型更出名。简单来说,可变形注意力是借鉴了CNN中可变形卷积的思想,让transformer不是平等地关注所有像素,有些像素更加重要那我就只关注那一部分就完事了。
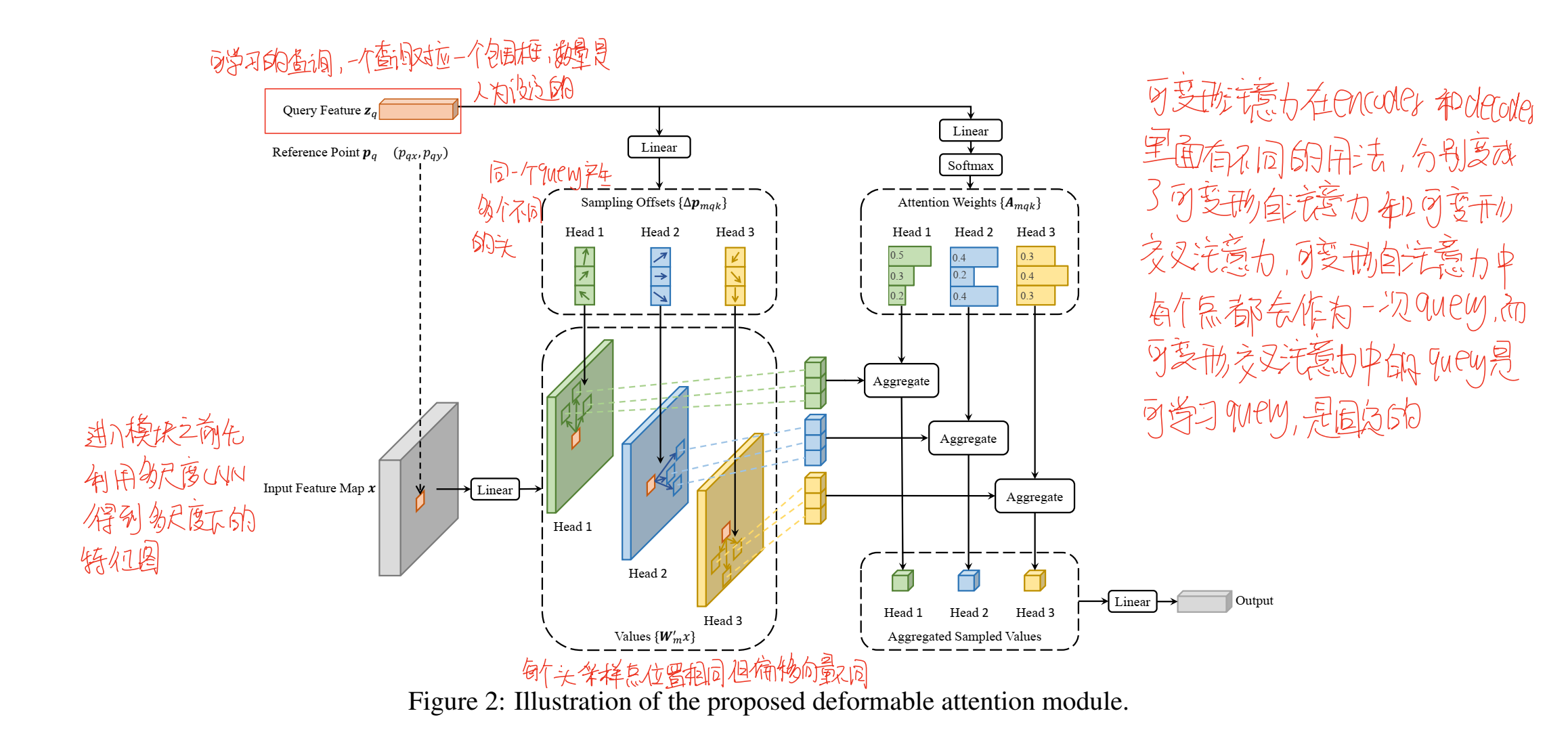
可变形注意力机制
采用与DETR相同的结构,图像的输入首先会经过CNN进行特征的提取,在得到的特征图的基础上,可变形注意力会选取一部分点,这部分点的坐标是query自己学习得来的,在推理过程是固定的,除此之外,query还会提供一个偏移值,基于选择的点的坐标,加上这个偏移值,就可以计算出采样点周围的几个点,特征图中这几个点的特征向量被提取出来进行加权求和,从而得到可变形注意力的输出。

这一可变形注意力机制可以很好地与多尺度卷积结合起来,多尺度卷积中特征图的大小是不同的,所以我们不能采用固定的坐标大小来表示采样点的位置,这里作者设计了一个归一化机制,通过归一化让位置和偏移量转换为0-1的一个比例,这样再在每一层根据大小得到一个可能是浮点数的坐标,这个坐标可能没有直接对应的点,需要利用临近点插值得到这个坐标对应的值,这样将尺度引入,我们就得到了多尺度的可变形注意力。
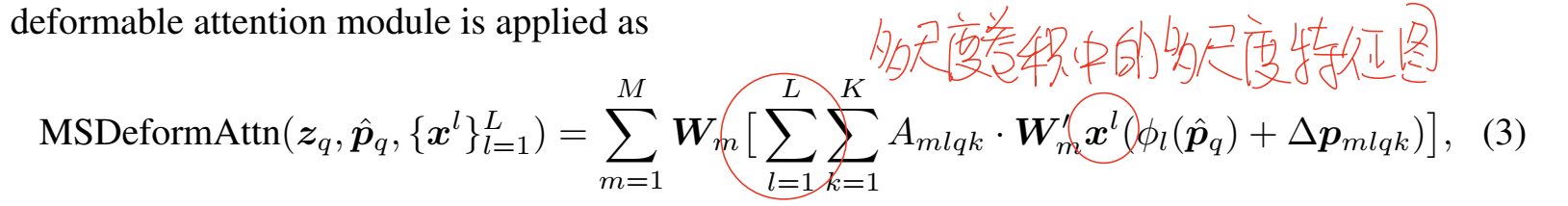
Deformable transformer 结构
使用了可变形注意力机制之后,DETR的整个输入输出都变了,变成了多尺度卷积产生的多尺度特征图。在encoder的部分,编码器的输入和输出都是多尺度的特征图,并且编码器输出的大小和编码器输入的大小是一样的,这部分使用可变形自注意力机制每个像素都会作为一个query参与到计算中,在添加尺度编码之后参与可变形注意力的计算,也就是说这部分是对特征图中的每个点,都计算一遍多尺度可变形注意力,最后叠加出来一个等大小的特征图。在decoder的部分,作者使用了可变形自注意力和可变形交叉注意力。对于N个query,首先使用可变形自注意力机制进行交互,这个交互也是可变形的,主要体现在交互的过程不是一一对应的,每个query只和一部分query进行交互。虽然都叫做可变形自注意力,但是decoder部分使用的和encoder部分使用的还不一样,decoder的部分的Deformable Self-Attention并不能很好地体现出采样点这一概念,只保留了非全部交互这一概念。
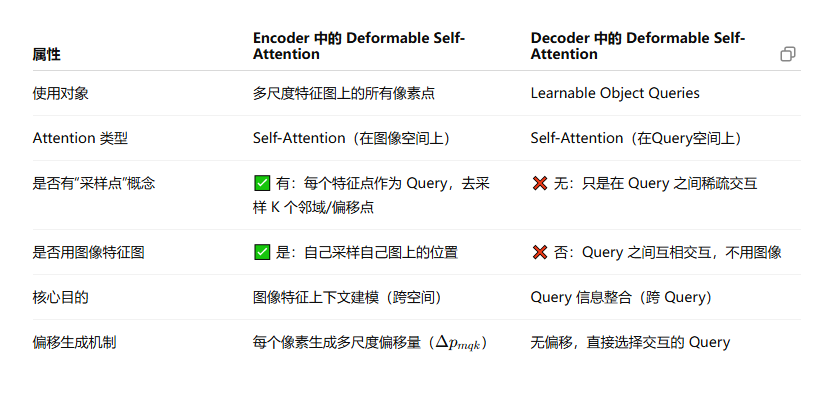
而可变形交叉注意力则是将每个query与encoder的输出进行交互,得到交叉注意力结果,最终得到N个query查询的结果。
整体理顺一下可变形注意力在DETR中的机制。首先模型利用多尺度卷积得到不同尺度下的特征图P3P4P5,之后这些特征图会被先送入encoder的部分,编码器中使用多尺度可变形自注意力机制,对于每一个尺度,每个点都是一个query与周围的小部分点进行加权求和,同时不同尺度之间也会相互参与计算,比如说P3尺度下,同尺度采样点直接参与计算,不同尺度的采样点则是使用归一化进行处理然后参与计算,由于加权求和并不改变向量长度,所以自注意力计算过程完全不改变输入输出的大小。经过处理,encoder部分使用多尺度可变形自注意力机制将特征图进行了处理,输出的是一个等大小但是特征更加丰富的特征图。之后decoder的部分输入是N个可学习的object query,这部分query首先进行可变形自注意力机制,每个query和小部分query进行加权求和,之后所有的object query都作为query与encoder输出的多尺度特征图进行可变形多尺度交叉注意力计算,每个query会得到一个向量,这个向量的长度等于特征图的深度,最后所有的query都扫一遍,就可以拼成一个二维矩阵,这个二维矩阵再经过后续计算送入不同的head完成不同的下游任务。
可以看到,虽然打着可变形注意力的幌子,但是扣细节的话可以发现,可变形注意力几乎是重写了传统transformer中qkv的结构,我们很难找到真正意义上的qkv三个内容,可变形这个词,主要针对的就是让点不是和全部剩余点进行交互,而是让点和小部分点进行交互,图像中并不是所有的内容都是完全有意义的,我只需要关注真正有价值的东西即可,剩余的是在徒增开销。