第20节:深度学习基础-反向传播算法详解
一、引言
反向传播算法(Backpropagation,简称BP算法)是深度学习领域最为核心的算法之一,它为神经网络提供了一种高效计算梯度的方法,使得基于梯度的优化成为可能。自20世纪80年代被重新发现并广泛应用以来,反向传播算法已经成为训练多层神经网络的标准方法,推动了深度学习革命的发展。
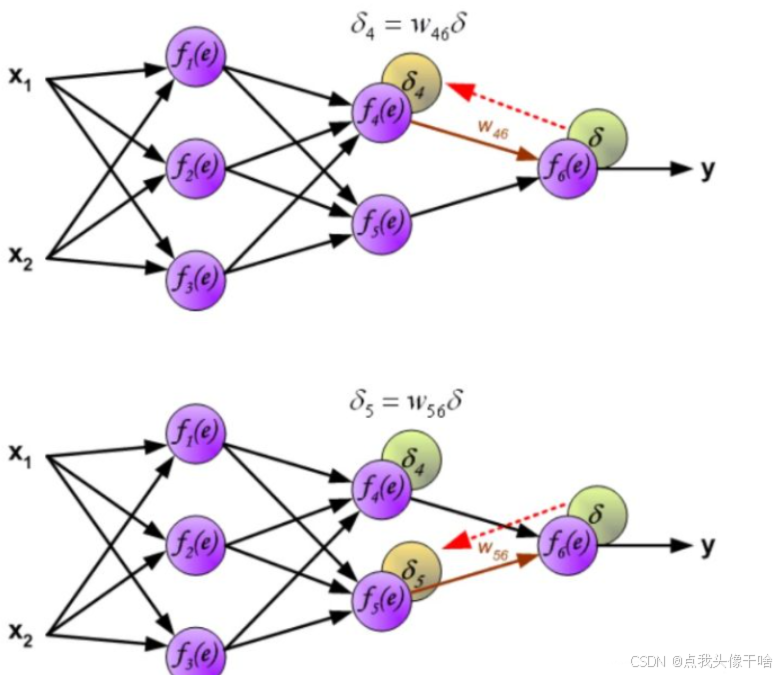
反向传播算法的本质是链式法则(Chain Rule)在神经网络中的巧妙应用,它通过从输出层向输入层反向传播误差信号,计算网络中每个参数相对于损失函数的梯度。这些梯度随后被用于优化算法(如随机梯度下降)来更新网络参数,从而最小化损失函数。
二、前向传播与计算图
2.1 神经网络的前向传播
在理解反向传播之前,首先需要了解前向传播(Forward Propagation)的过程。
前向传播是指输入数据通过神经网络的各层变换,最终得到输出的过程。
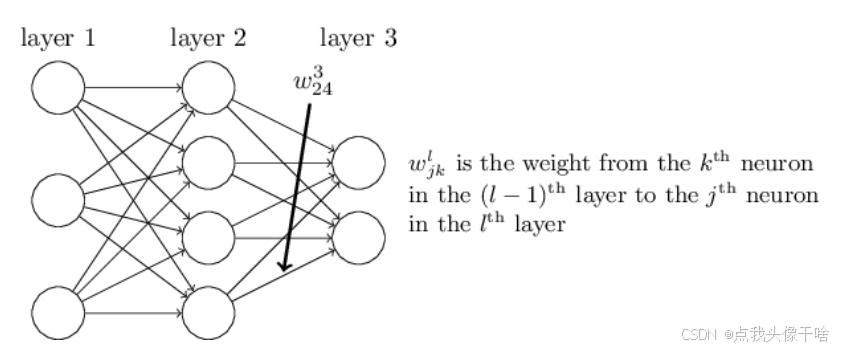
对于一个简单的全连接神经网络,前向传播可以表示为:
输入层:接收输入向量x
隐藏层:h = σ(W₁x + b₁),其中W₁是权重矩阵,b₁是偏置向量,σ是激活函数
输出层:ŷ = W₂h + b₂
计算损失:L = ½(y - ŷ)²(以均方误差为例)
2.2 计算图表示
反向传播算法可以很自然地用计算图(Computational Graph)来表示。
计算图是将数学表达式表示为有向无环图(DAG),其中节点表示变量(输入、输出、参数)或操作(如矩阵乘法、激活函数),边表示数据流向。
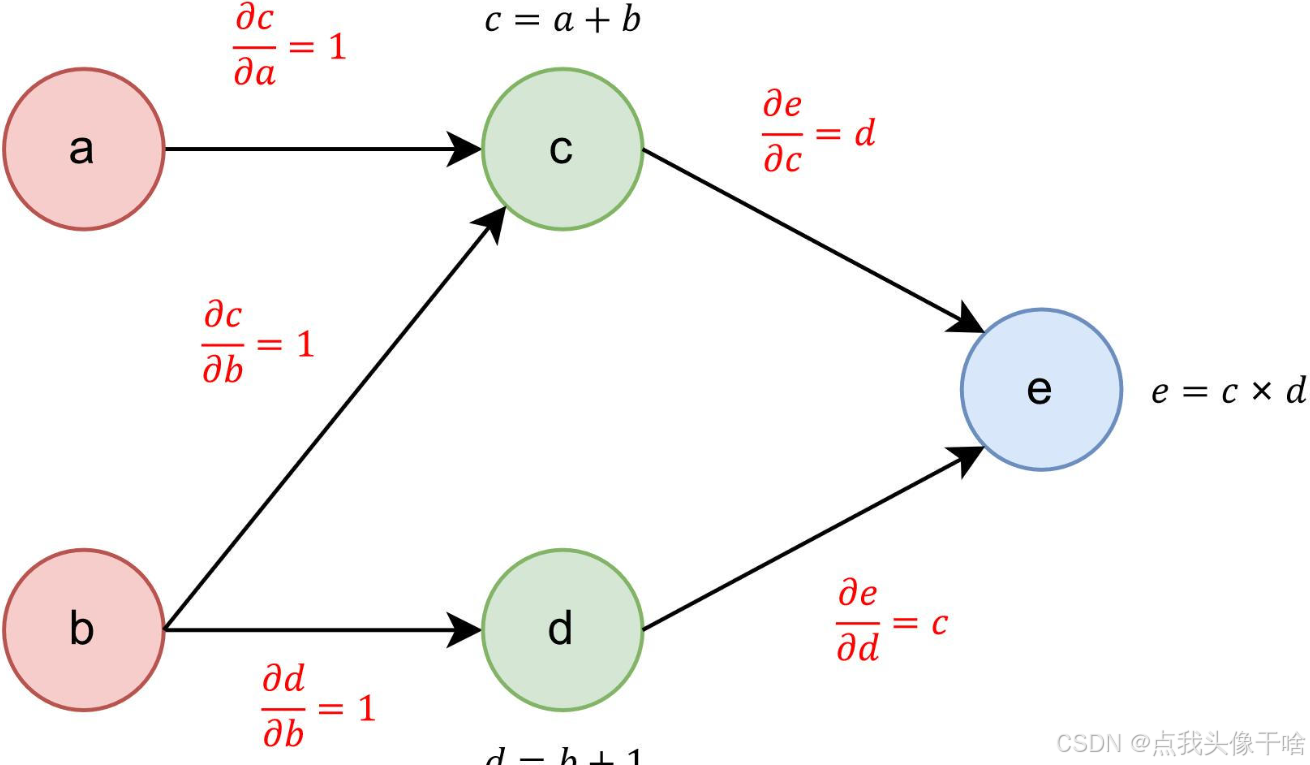
以简单的两层神经网络为例,其计算图可以表示为:
输入x → 矩阵乘法(W₁) → 加偏置(b₁) → 激活函数(σ) → 矩阵乘法(W₂) → 加偏置(b₂) → 输出ŷ → 计算损失L
这种图形化表示使得我们可以清晰地追踪数据的流动和变换过程,为反向传播提供了直观的基础。
三、反向传播的数学原理
3.1 链式法则
反向传播算法的核心数学工具是微积分中的链式法则。
链式法则指出,对于复合函数y = f(g(x)),y关于x的导数可以表示为:
dy/dx = (dy/dg) * (dg/dx)
在神经网络中,损失函数L是网络参数θ的复合函数,因此计算∂L/∂θ需要沿着计算路径将局部导数相乘。
3.2 反向传播的四个基本方程
对于具有L层的神经网络,反向传播可以通过四个基本方程来描述。设第l层的加权输入为z^l = W^l a^{l-1} + b^l,激活值为a^l = σ(z^l),输出层的激活值为a^L。
定义第l层的误差δ^l为∂L/∂z^l,则反向传播方程如下:
-
输出层误差:
δ^L = ∇_a L ⊙ σ'(z^L) -
误差反向传播:
δ^l = ((W^{l+1})^T δ^{l+1}) ⊙ σ'(z^l) -
损失函数对偏置的梯度:
∂L/∂b^l = δ^l -
损失函数对权重的梯度:
∂L/∂W^l = δ^l (a^{l-1})^T
其中⊙表示逐元素乘积(Hadamard积),σ'表示激活函数的导数。
3.3 反向传播的推导
让我们详细推导这些方程的来源。以简单的两层网络为例:
-
计算输出层误差δ^L:
δ^L = ∂L/∂z^L = (∂L/∂a^L) * (∂a^L/∂z^L) = ∇_a L ⊙ σ'(z^L) -
对于隐藏层误差δ^l:
δ^l = ∂L/∂z^l = (∂L/∂z^{l+1}) * (∂z^{l+1}/∂a^l) * (∂a^l/∂z^l) = (W^{l+1})^T δ^{l+1} ⊙ σ'(z^l) -
对于偏置的梯度:
∂L/∂b^l = (∂L/∂z^l) * (∂z^l/∂b^l) = δ^l * 1 = δ^l -
对于权重的梯度:
∂L/∂W^l = (∂L/∂z^l) * (∂z^l/∂W^l) = δ^l (a^{l-1})^T
这些推导展示了反向传播如何系统地应用链式法则来计算网络中所有参数的梯度。
四、反向传播算法的实现
4.1 算法步骤
反向传播算法的具体实现步骤如下:
-
前向传播:
-
输入训练样本x,计算各层的激活值a^l和加权输入z^l,直到输出层
-
-
计算输出误差:
-
计算输出层的误差δ^L = ∇_a L ⊙ σ'(z^L)
-
-
反向传播误差:
-
对于每一层l = L-1, L-2, ..., 2:
-
计算δ^l = ((W^{l+1})^T δ^{l+1}) ⊙ σ'(z^l)
-
-
-
计算梯度:
-
对于每一层l = L, L-1, ..., 1:
-
计算权重梯度∂L/∂W^l = δ^l (a^{l-1})^T
-
计算偏置梯度∂L/∂b^l = δ^l
-
-
-
参数更新:
-
使用计算得到的梯度更新参数(通常结合优化算法如SGD、Adam等)
-
4.2 向量化实现
在实际实现中,为了高效处理批量数据,反向传播通常采用向量化形式:
-
前向传播:
Z^l = W^l A^{l-1} + b^l (广播)
A^l = σ(Z^l) -
输出误差:
δ^L = ∇_A L ⊙ σ'(Z^L) -
反向传播:
δ^l = ((W^{l+1})^T δ^{l+1}) ⊙ σ'(Z^l) -
梯度计算:
∂L/∂W^l = δ^l (A^{l-1})^T / m
∂L/∂b^l = sum(δ^l, axis=1) / m
其中m是批量大小,除法用于计算平均梯度。
4.3 自动微分与现代框架
现代深度学习框架(如TensorFlow、PyTorch)实现了自动微分(Automatic Differentiation),可以自动计算反向传播所需的梯度。这些框架构建计算图并跟踪所有操作,使得用户只需定义前向传播,框架会自动处理反向传播。
例如,在PyTorch中:
# 定义模型
model = nn.Sequential(nn.Linear(784, 256),nn.ReLU(),nn.Linear(256, 10)
)# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)# 反向传播
loss.backward()# 参数更新
optimizer.step()自动微分极大地简化了反向传播的实现,使研究人员可以专注于模型架构的设计而非梯度计算。
五、反向传播的优化与挑战
5.1 梯度消失与爆炸问题
反向传播面临的主要挑战之一是梯度消失(Vanishing Gradients)和梯度爆炸(Exploding Gradients)问题:
-
梯度消失:在深层网络中,梯度在反向传播过程中可能变得极小,导致底层参数几乎不更新
-
梯度爆炸:相反,梯度也可能指数级增长,导致参数更新过大,模型无法收敛
解决方案包括:
-
使用ReLU等改进的激活函数
-
恰当的权重初始化(如Xavier、He初始化)
-
批量归一化(Batch Normalization)
-
残差连接(ResNet)
5.2 正则化技术
为了防止过拟合,反向传播中常结合各种正则化技术:
-
L2正则化(权重衰减):
在损失函数中加入权重平方和项,修改梯度计算 -
Dropout:
在前向传播中随机丢弃部分神经元,反向传播时只更新活跃神经元 -
早停(Early Stopping):
根据验证集性能提前终止训练
5.3 优化算法选择
基本的反向传播使用随机梯度下降(SGD),但有许多改进的优化算法:
-
带动量的SGD:
v = γv + η∇J(θ)
θ = θ - v -
AdaGrad:
自适应学习率,对频繁参数使用较小学习率 -
RMSProp:
改进的AdaGrad,使用指数移动平均 -
Adam:
结合动量和自适应学习率,是目前最常用的优化器
六、反向传播的扩展与变体
6.1 不同网络结构的反向传播
反向传播可以适应各种网络架构:
-
卷积神经网络(CNN):
-
通过卷积核的局部连接和参数共享
-
反向传播需要计算卷积操作的梯度
-
-
循环神经网络(RNN):
-
通过时间展开处理序列数据
-
使用反向传播通过时间(BPTT)算法
-
-
图神经网络(GNN):
-
处理图结构数据
-
消息传递机制的反向传播
-
6.2 二阶优化方法
传统反向传播使用一阶梯度信息,二阶方法利用Hessian矩阵或其近似:
-
牛顿法:
使用精确Hessian矩阵,计算成本高 -
拟牛顿法(如L-BFGS):
近似Hessian矩阵,适合小批量数据 -
自然梯度:
考虑参数空间的几何结构
6.3 生物学启发算法
标准反向传播被认为在生物学上不太合理,研究者提出了替代方案:
-
反馈对齐(Feedback Alignment):
使用随机固定矩阵反向传播误差 -
目标传播(Target Propagation):
每层学习自己的目标而非传播梯度 -
预测编码(Predictive Coding):
基于大脑信息处理的框架
七、反向传播的实际应用
7.1 超参数调优
反向传播训练中需要调整的重要超参数:
-
学习率:
-
最重要的超参数之一
-
可以使用学习率调度器动态调整
-
-
批量大小:
-
影响梯度估计的准确性和计算效率
-
通常选择32-256之间
-
-
网络架构:
-
层数、每层神经元数量
-
激活函数选择
-
7.2 调试技巧
调试反向传播实现的常用方法:
-
梯度检查(Gradient Checking):
比较解析梯度和数值梯度,验证实现正确性 -
监控激活值和梯度:
-
检查激活值是否饱和
-
观察梯度大小和分布
-
-
可视化工具:
-
TensorBoard等工具跟踪训练过程
-
可视化网络结构和数据流
-
7.3 实际案例
反向传播在各类任务中的应用:
-
计算机视觉:
-
图像分类、目标检测、分割
-
CNN架构如ResNet、EfficientNet
-
-
自然语言处理:
-
机器翻译、文本生成
-
Transformer架构
-
-
强化学习:
-
策略梯度方法
-
深度Q网络(DQN)
-