李沐《动手学深度学习》 | Softmax回归 - 分类问题
文章目录
- 从回归到多类分类
- 交叉熵损失函数
- 图像分类数据集
- 1.读取数据集
- 2.读取小批量
- 3.整合所有组件
- softmaxt回归的从零开始实现
- 1.初始化模型参数
- 初始化模型参数形状分析
- 代码
- 2.定义softmax操作
- 3.定义模型
- 4.定义交叉熵损失函数
- 5.分类精度
- 评估任意模型net上的精度
- 6.训练
- 7.预测
- 代码总结
- softmax的简洁实现
- 初始化模型参数
- 损失函数和优化算法
- CrossEntropyLoss的实现:softmax和交叉熵损失的数值稳定法
从回归到多类分类
回归:估计一个连续值
- 单连续数值输出
- 输出是一个自然区别R
- 损失函数:跟真实值的区别作为损失
分类:预测一个离散类别
- 通常多个输出
- 输出i是预测第i类的置信度
在深度学习中,置信度通常指模型对其预测结果的确信程度
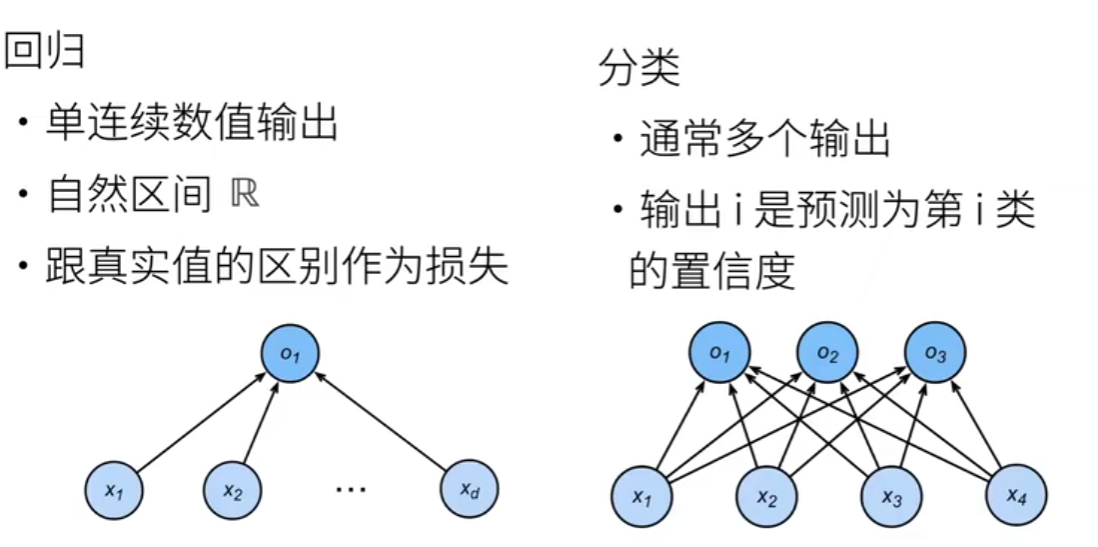
1.对类别进行编码:独热编码
说明
one-hot 独热编码用于将离散的分类标签转换为二进制向量。独热编码是一个向量,它的分量数目=类别,类别对应的分量设置为1,其他所有分量设置为0。
- 离散的分类:类别之间相互独立,不存在谁比谁大、谁比谁先、谁比谁后的关系。
- 二进制向量:每一个分量都是二进制的,只有0、1两种取值。
目的:将独立的标签表示为相互独立的数字,并且数字之间的距离也相等
2.使用均方损失训练
3.选取使得置信度 o i o_i oi最大的i作为预测结果
y ^ = arg max i o i \hat y = \argmax_i o_i y^=argmaxioi
角度1:对分类问题来说,并不关系预测与实际值,关心对正确类别的置信度(可能性)特别大
需要更置信(确信)的识别正确类:
正确类y的置信度 o y o_y oy要远远大于非正确类的置信度 o i o_i oi: o y − o i ≥ Δ ( y , i ) o_y - o_i \geq \Delta(y,i) oy−oi≥Δ(y,i),其中 Δ \Delta Δ表示某个阈值 => 这里我们并不关系 o y o_y oy的具体值,而是关心 o y o_y oy和 o i o_i oi的差距
角度2:我们更希望输出类别的匹配概率(非负,和为1) ,也就是输入一个样本,预测每个输出类型的概率,然后使用预测概率最高的类别作为输出:采用softmax函数。
y ^ = s o f t m a x ( o ) \hat y = softmax(o) y^=softmax(o),具体展开 y ^ i = e x p ( o i ) ∑ k e x p ( o k ) \hat y_i = \frac{exp(o_i)}{\sum_k exp(o_k)} y^i=∑kexp(ok)exp(oi)。其中,指数是不管什么值都可以让其变成非负,这个式子可以保证 y ^ i \hat y_i y^i对所有的i求和值为1。
:::tips
softmax运算将数值映射为一个概率。
:::
交叉熵损失函数
交叉熵常用来衡量两个概率的区别 H ( p , q ) = ∑ i − p i l o g ( q i ) H(p,q)=\sum_i - p_ilog(q_i) H(p,q)=∑i−pilog(qi)
将其作为损失KaTeX parse error: \tag works only in display equations
y y y通常是一个one-hot编码向量,真实类别为1,其余为,其中 y i y_i yi是真实标签的第 i i i个类别的概率; y ^ i \hat y_i y^i是模型预测的第 i i i个类型的概率。
除了 i = k i=k i=k 时 y k = 1 y_k=1 yk=1,其他 y i = 0 y_i=0 yi=0,所以求和式中只有 i = k i=k i=k的项不为零: l ( y , y ^ ) = − ∑ i y i l o g y ^ i = − ( y k l o g y ^ k ) + ∑ i ≠ k y i l o g y ^ i = − l o g y ^ k l(y,\hat y )=-\sum_i y_ilog\hat y_i = -(y_klog\hat y_k) + \sum_{i\neq k} y_ilog \hat y_i = -log\hat y_k l(y,y^)=−∑iyilogy^i=−(yklogy^k)+∑i=kyilogy^i=−logy^k
所以(1)的 y ^ y \hat y_y y^y 表示该样本的真实类别 y y y 对应的预测概率 y ^ k \hat y_k y^k。
为了更明确,交叉熵损失函数可以写成: l ( y , y ^ ) = − l o g y ^ t r u e c l a s s l(y,\hat y)=-log \hat y _{true class} l(y,y^)=−logy^trueclass
交叉熵来衡量概率区别可以发现:我们不关心非正确类的预测值,只关心正确类的预测值。
梯度下降
目标是求损失的梯度,接着朝减少损失的方向更新参数。
损失函数:$l(y,\hat y )=-\sum_i y_ilog\hat y_i $
带入softmax公式: = − ∑ i y i l o g ( e o i ∑ k = 1 q e o k ) =-\sum_i y_ilog(\frac{e^{o_i}}{\sum_{k=1}^q e^{o_k}}) =−∑iyilog(∑k=1qeokeoi)
利用对数性质 l o g ( a b ) = l o g ( a ) − l o g ( b ) log(\frac{a}{b}) = log(a)-log(b) log(ba)=log(a)−log(b):$=-\sum_i y_i [log(e^{o_i}) - log(\sum_{k=1}^q e^{o_k})] $
简化 l o g ( e x ) = x log(e^x)=x log(ex)=x: = ∑ i y i l o g ( ∑ k = 1 q e o k ) − ∑ i y i o i =\sum_i y_i log(\sum_{k=1}^q e^{o_k}) - \sum_i y_i o_i =∑iyilog(∑k=1qeok)−∑iyioi
同理除了 i = k i=k i=k 时 y k = 1 y_k=1 yk=1,其他 y i = 0 y_i=0 yi=0 : = l o g ( ∑ k = 1 q e o k ) − ∑ i y i o i = A + B log(\sum_{k=1}^q e^{o_k}) - \sum_i y_i o_i =A+B log(∑k=1qeok)−∑iyioi=A+B
对损失函数求导: ∂ o i l ( y , y ^ ) = ∂ o i A + ∂ o i B \partial_{o_i}l(y,\hat y)= \partial_{o_i}A + \partial_{o_i}B ∂oil(y,y^)=∂oiA+∂oiB
1. A = l o g S A=logS A=logS,那么 ∂ o i A = 1 s ∂ S ∂ o i = 1 s e o i \partial_{o_i}A = \frac{1}{s}\frac{\partial S}{\partial o_i} =\frac{1}{s}e^{o_i} ∂oiA=s1∂oi∂S=s1eoi
2. B = y 1 o 1 + y 2 o 2 + . . . . B=y_1o_1+y_2o_2+.... B=y1o1+y2o2+....,那么 ∂ o i B = y i \partial_{o_i}B =y_i ∂oiB=yi
=> ∂ o i l ( y , y ^ ) = ∂ o i A + ∂ o i B = 1 s e o i + y i \partial_{o_i}l(y,\hat y)= \partial_{o_i}A + \partial_{o_i}B=\frac{1}{s}e^{o_i} +y_i ∂oil(y,y^)=∂oiA+∂oiB=s1eoi+yi
展开后 = s o f t m a x ( o ) i − y i =softmax(o)_i-y_i =softmax(o)i−yi
说明
- 这里的参数是 o i o_i oi,通常表示模型对第 i i i个类型的原始输出分数(第 i i i个类别的“置信度”或“证据强度”)。
我们的目标是选取使得置信度 o i o_i oi最大的i作为预测结果。softmax只不过将数值映射为概率而已,但参数还是 o i o_i oi
- 梯度可以表示为估计值 y ^ = s o f t m a x ( o ) \hat y = softmax(o) y^=softmax(o)和真实值 y y y之间的差距
- 整理一下
+ o = [ o 1 , o 2 , … , o q ] T o=[o_1,o_2,…,o_q]^T o=[o1,o2,…,oq]T 是模型的原始(Logits)输出向量,
+ y ^ = s o f t m a x ( o ) = [ p 1 , p 2 , … , p q ] T \hat y=softmax(o)=[p_1,p_2,…,p_q]^T y^=softmax(o)=[p1,p2,…,pq]T 是预测概率分布,
+ y = [ y 1 , y 2 , … , y q ] T y=[y_1,y_2,…,y_q]^T y=[y1,y2,…,yq]T是真实标签的 one-hot 编码(仅一个 y k = 1 y_k=1 yk=1,其余为 0)
| Logits | 概率(Probabilities) |
|---|---|
| 未归一化的原始值(可为正或负) | 通过 Softmax 归一化到 [0, 1] 区间 |
| 直接来自全连接层或其他输出层的输出 | 由 Logits 经过 Softmax 转换得到 |
图像分类数据集
MNIST数据集是图像分类中广泛使用的数据集之一,但作为基准数据集过于简单。我们将使用类似但更复杂的Fashion-MNIST数据集。
**d2l**是《动手学深度学习》(Dive into Deep Learning,简称D2L)这本书官方配套的 Python工具库。它的设计目的是简化深度学习代码的实现,提供常用函数(如数据加载、模型训练、可视化等)。
# 导入PyTorch核心库
import torch
# pytorch对计算机视觉扩展库,包含常用数据集、预训练模型和图像处理工具
import torchvision
# 导入数据加载工具,提供Dataset和DataLoader
from torch.utils import data
# 导入图像预处理工具,例如调整大小、转为张量、标准化等
from torchvision import transforms
from d2l import torch as d2l
# 设置使用SVG格式显示图表(相比位图更清晰,适合书籍和文档)
d2l.use_svg_display()
1.读取数据集
通过框架中的内置函数将Fashion-MNIST数据集下载(第一次执行会下载)并读取到内存中。
transforms.ToTensor():将PIL.Image或numpy.ndarray图像转换为torch.Tensor,并执行以下操作。
操作1:维度变换,将H x W x C高度x宽度x通道转化为C x H x W符合PyTorch张量格式
PyTorch的约定:图像张量的默认格式为 通道优先(Channels First)
操作2:数据类型转化,将像素值从uint8(0-255)转换为float32(0.0-1.0)
torchvision.datasets.FashionMNIST将数据集读取到内存
root: 将数据集加载后的存储路径(如./data表示上级目录下的data文件夹)。train:True加载训练集,False加载测试集。transform: 预处理流水线(可组合多个转换,如调整大小、标准化等)。
对数据集中的每个样本(如图像)应用指定的预处理操作,本案例中是我们指定的trans操作
download: 若本地不存在数据,自动从互联网下载。
# 定义数据预处理转换:将PIL图像转换为32位浮点数张量,并自动归一化像素值到[0,1]范围
trans = transforms.ToTensor()mnist_train = torchvision.datasets.FashionMNIST(root="./data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="./data", train=False, transform=trans, download=True)Fashion-MNIST由10个类别的图像组成, 每个类别由训练数据集(train dataset)中的6000张图像 和测试数据集(test dataset)中的1000张图像组成。 因此,训练集和测试集分别包含60000和10000张图像。 测试数据集不会用于训练,只用于评估模型性能。
print(mnist_train,mnist_test)
# Dataset FashionMNIST
# Number of datapoints: 60000
# Root location: ./data
# Split: Train
# StandardTransform
#Transform: ToTensor() Dataset FashionMNIST
# Number of datapoints: 10000
# Root location: ./data
# Split: Test
# StandardTransform
#Transform: ToTensor()print(len(mnist_train),len(mnist_test))
# 60000 10000
每个输入图像的高度和宽度均为28像素。 数据集由灰度图像组成,其通道数为1。
mnist_train是一个PyTorch的Dataset对象,前面我们已经打印查看了。
训练集由60000个样本组成,每个样本是一个元组(image,label)
image:经过预处理后的图像张量(通道数,高度,宽度)。label:对应的类别标签(整数0-9)。
mnist_train[0][0]第一个维度表示获取第1个样本,第二个维度选择获取图片。torch.Size([1, 28, 28])表示一个三维张量。
print(mnist_train[0][0].shape)
# torch.Size([1, 28, 28]) 表示获取第1个渠道第几个高度第几宽度像素的值
# 假设形状为[1,3,3] 1个通道,每个通道是3*3的矩阵
#tensor = [# 通道0(唯一通道)
# [
# [0.1, 0.2, 0.3],
# [0.4, 0.5, 0.6],
# [0.7, 0.8, 0.9]
# ]
# ]Fashion-MNIST中包含的10个类别,分别为t-shirt(T恤)、trouser(裤子)、pullover(套衫)、dress(连衣裙)、coat(外套)、sandal(凉鞋)、shirt(衬衫)、sneaker(运动鞋)、bag(包)和ankle boot(短靴)。 以下函数用于在数字标签索引(数据集中采用整数作为label)及其文本名称之间进行转换。
def get_fashion_mnist_labels(labels): #@save"""返回Fashion-MNIST数据集的文本标签"""text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat','sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']# i是整数,循环labels里的每一个标签i,找到对应的文字标签,return [text_labels[int(i)] for i in labels]
可以创建一个函数来可视化样本。
2l.plt.subplots(num_rows, num_cols, figsize=figsize)创建一个子图网格。
- 若
num_rows=2,num_cols=3,则axes初始形状为(2, 3)。axes.flatten()后得到一维数组[ax1, ax2, ax3, ax4, ax5, ax6]
zip(axes, imgs):将 axes 和 imgs 按顺序配对,生成 (ax, img) 元组。
这里配对的逻辑是
- 第 1 个轴
ax1对应第 1 张图像img1。 - 第 2 个轴
ax2对应第 2 张图像img2。
enumerate():为每个元组添加索引 i,形成 (i, (ax, img))
# imgs: 图像列表,支持 PyTorch 张量或 PIL 图像。
# 输入的图像形状为 [样本数, 高度, 宽度] :移除通道维度后,可以直接兼容 Matplotlib 的 imshow 方法
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5): #@save# 设置图像显示尺寸,宽度=列数*缩放比例,高=列数*缩放比例figsize = (num_cols * scale, num_rows * scale)# 创建子图网格,返回所有子图的轴对象(axes是二维数组)_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize)# 将二维轴数组展平为一维,便于遍历axes = axes.flatten()# 遍历每个子图轴和对应的图像 i表示迭代次数# 每一个轴数组的位置显示一张图片for i, (ax, img) in enumerate(zip(axes, imgs)):# 处理PyTorch张量:转换为NumPy数组if torch.is_tensor(img):ax.imshow(img.numpy())else:# PIL图片ax.imshow(img)# 隐藏坐标轴ax.axes.get_xaxis().set_visible(False)ax.axes.get_yaxis().set_visible(False)# 添加标题(如果提供)if titles:ax.set_title(titles[i])# 显式显式图片 d2l.plt.show() # 返回所有子图轴对象 return axes
现在尝试获取训练数据集中前几个样本的图像及其相应的标签。
data.DataLoader方法返回一个可迭代对象,使用iter函数获取可迭代对象的迭代器,使用next函数从迭代器中获得下一个值。
这里获取到的X是从训练集中获取每个样本的第一个参数图像张量(通道数,高度,宽度)组成的数据[18,1,28,28],y是每个样本的第二个参数label组成的张量[18]
我们的数据X是PyTorch张量形式,调整图像张量为 [18, 28, 28],去除通道维度(单通道灰度图可省略通道维度)。
X, y = next(iter(data.DataLoader(mnist_train, batch_size=18)))
print(X.shape ,y.shape)
# torch.Size([18, 1, 28, 28]) torch.Size([18])# 显示2行,每行9列,将数字标签转换维文字标签
show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y));

2.读取小批量
使用DataLoader来读取数据,开启四个进程来读取数据。
batch_size = 256def get_dataloader_workers(): #@save"""使用4个进程来读取数据"""return 4train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=get_dataloader_workers())# 速度测试代码
timer = d2l.Timer()
for X, y in train_iter:continue
print(f'{timer.stop():.2f} sec') # 5.58 sec
3.整合所有组件
定义load_data_fashion_mnist函数,用于获取和读取Fashion-MNIST数据集,这个函数返回训练集和验证集的数据迭代器。
此这个函数还接受一个可选参数resize,用来将图像大小调整到指定的尺寸。
- 输入是整数(如
resize=32,表示将图像调整为32x32像素)。 - 输入是元组(如
resize=(32, 32),明确指定高度和宽度)。
def load_data_fashion_mnist(batch_size, resize=None): #@save"""下载Fashion-MNIST数据集,然后将其加载到内存中"""trans = [transforms.ToTensor()]if resize:# 如果需要调整大小,在转换列表开头插入Resize操作trans.insert(0, transforms.Resize(resize)) # 先调整大小,再转张量trans = transforms.Compose(trans) # 组合预处理步骤# 加载训练集和测试集mnist_train = torchvision.datasets.FashionMNIST(root="./data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST(root="./data", train=False, transform=trans, download=True)return (data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=get_dataloader_workers()),data.DataLoader(mnist_test, batch_size, shuffle=False,num_workers=get_dataloader_workers()))
代码总结
其余函数比如显示图片之类可以在调试阶段使用。
# 导入PyTorch核心库
import torch
# pytorch对计算机视觉扩展库,包含常用数据集、预训练模型和图像处理工具
import torchvision
# 导入数据加载工具,提供Dataset和DataLoader
from torch.utils import data
# 导入图像预处理工具,例如调整大小、转为张量、标准化等
from torchvision import transforms
from d2l import torch as d2lbatch_size = 256def get_dataloader_workers(): #@save"""使用4个进程来读取数据"""return 4# 加载数据
def load_data_fashion_mnist(batch_size, resize=None): #@save"""下载Fashion-MNIST数据集,然后将其加载到内存中"""trans = [transforms.ToTensor()]if resize:# 如果需要调整大小,在转换列表开头插入Resize操作trans.insert(0, transforms.Resize(resize)) # 先调整大小,再转张量trans = transforms.Compose(trans) # 组合预处理步骤# 加载训练集和测试集mnist_train = torchvision.datasets.FashionMNIST(root="./data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST(root="./data", train=False, transform=trans, download=True)return (data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=get_dataloader_workers()),data.DataLoader(mnist_test, batch_size, shuffle=False,num_workers=get_dataloader_workers()))
softmaxt回归的从零开始实现
之前已经介绍了如何获取数据集,这里加载数据的逻辑已经封装在d2l中,我们直接使用d2l包中的对应函数。
import torch
from IPython import display
from d2l import torch as d2lbatch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
1.初始化模型参数
原始数据集中的每个样本都是2828的图像。在之后的章节中,会讨论如何利用图像空间结构的特征,但现在暂时将每个像素位置看成一个特征。也就是说每个样本有2828=784个特征,我们将每个图片展开,看作长度为784的向量。
初始化模型参数形状分析
全连接层(Linear Layer)的作用是将输入特征 线性映射 到输出空间,全连接层的计算公式为 输出 = 输入 ⋅ W + b 输出=输入⋅W+b 输出=输入⋅W+b。
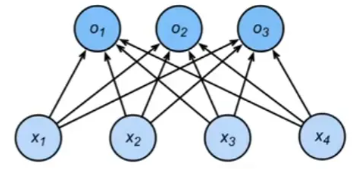
- 输入矩阵X形状是
[batch_size,输入特征维度28*28=784],一共batch_size个行,每一个行表示一个样本,一共784列,每一列表示一个特征 - 输出肯定是一个
[batch_size,输出类别数X],一共X列,每一列表示其中一个类别的概率;一共batch_size个行,每一行表示一个样本。 - 偏置 b j b_j bj 表示第 j j j个类别的独立偏移量,所以偏置向量b的形状为
[输出类别数] - 在全连接中,每一个特征需要乘一个独立的权重_w_,权重矩阵要和输入矩阵X相乘,那么权重矩阵的形状肯定是
[输入特征维度,D],这里的D从权重的物理意义可以的D=输出类别数- 每一列对应一个输出类别:权重矩阵的每一列表示输入特征到某一类别的映射权重。
- 每个权重元素: W i , j Wi,j Wi,j 表示第 i i i 个输入特征对第 j j j 个输出类别的贡献。
:::tips
权重矩阵W的形状为[输入特征维度,输出类别数]
偏置向量b的形状为[输出类别数]
:::
问题1:[C]、[C,1]、 形状(C,) 的区别
| 表示方法 | 维度数 | 物理意义 | 示例(C=3) |
|---|---|---|---|
**[C]**或 (C,) | 一维 在内存中按顺序存储 C 个元素 | 长度为 C的向量 无行或列的概念 | [0.1, 0.2, 0.3] |
**[C, 1]** | 二维 | C行 1 列的矩阵(列向量) 有行和列的区分 | [[0.1], [0.2], [0.3]] |
**问题2:**输入矩阵X形状是[batch_size,输入特征维度28*28=784],权重矩阵W形状是[输入特征维度,输出类别数],XW的形状是batch_size,输出类别数是一个二维,为什么偏置b是一个一维,这样怎么相加?
在深度学习的框架中,有广播机制可以自动处理。根据广播规则(Broadcasting Rules),b 会自动扩展为 [batch_size, 输出类别数] 的矩阵(所有行复制相同的偏置量)。
设计成一维的原因:偏置表示每个类别的独立偏移量,与样本无关。所有样本共享同一组偏置更合理,并保持了参数的最简性。
代码
权重是一个784x10的矩阵,偏置的形状是[10]的一维数组
num_inputs = 784
num_outputs = 10W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)
print(b) # tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], requires_grad=True)
2.定义softmax操作
- 对于单个样本的输出向量 o = [ o 1 , o 2 , . . . , o c ] o=[o_1,o_2,...,o_c] o=[o1,o2,...,oc](其中 c c c 是类别数)
softmax操作的公式是 s o f t m a x ( o ) i = e x p ( o i ) ∑ k = 1 c e x p ( o k ) softmax(o)_i = \frac{exp(o_i)}{\sum_{k=1}^c exp(o_k)} softmax(o)i=∑k=1cexp(ok)exp(oi), o i o_i oi通常表示模型对第 i i i个类型的原始输出分数,分母是每个类别原始输出分数的和
- 当处理批量数据时,输入是一个矩阵X,矩阵X的形状为 N × C N\times C N×C。需要注意Softmax的输入X是模型输出层的结果,并不是原始数据的X。
s o f t m a x ( X ) i j = e x p ( X i j ) ∑ k e x p ( X i k ) softmax(X)_{ij} = \frac{exp(X_{ij})}{\sum_k exp(X_{ik})} softmax(X)ij=∑kexp(Xik)exp(Xij),这里 s o f t m a x ( X ) i j softmax(X)_{ij} softmax(X)ij第 i i i 个样本的第 j j j 个特征的概率值,分母对每个样本(每行)的原始输出结果(logits)求和
实现softmax的三个步骤
输入矩阵 X e x p ∈ R N × C X_{exp}∈R^{N×C} Xexp∈RN×C,其中 N N N 是批量大小, C C C 是类别数
- 对每个元素 x i j x_{ij} xij 计算指数 e x i j e^{x_{ij}} exij,输出矩阵 X e x p ∈ R N × C X_{exp}∈R^{N×C} Xexp∈RN×C,所有值为正数。
- 每个样本的logits求和,也就是输入矩阵X的每一行求和,输出
partition形状 N × 1 N\times 1 N×1 - 将每个样本的指数值除以其规范化常数,这里 x e x p x_{exp} xexp的形状为 N × C N\times C N×C 与
partition形状 N × 1 N\times 1 N×1
广播机制自动将partiton的每行值,赋值到所有列扩展成 N × C N\times C N×C的
def softmax(X):X_exp = torch.exp(X)# axis=0 沿列方向求和 axis=1 沿行方向求和 keepdims=true保持输出的维度与原数组一致partition = X_exp.sum(1, keepdims=True)return X_exp / partition # 这里应用了广播机制
矩阵中的非常大或非常小的元素可能造成数值上溢或下溢,但这里没有采取措施来防止这点。
通过上述操作,对于任何随机输入,我们将每个元素转变为一个非负数。依据概率论原理,每行总和为1。
X = np.random.normal(0, 1, (2, 5))
X_prob = softmax(X)
print(X_prob, X_prob.sum(1))
# [[0.10085486 0.32451584 0.2029946 0.24126379 0.13037092]
# [0.48606599 0.20100612 0.09976437 0.17589873 0.03726479]] [1. 1.]
3.定义模型
softmax回归模型虽然解决分类问题,但其仍然是一个线性模型 y = X W + b y=XW+b y=XW+b。
下面的代码定义了输入如何通过网络映射到输出。
权重矩阵W形状是[输入特征维度,输出类别数],那么代码中的W.shape[0]=784。reshape第一个参数为-1,表示自动计算该维度的大小,确保总数量不变。那么在本案例中是256。
这里具体怎么拉平,怎么操作其实是和传入X的形状有关,但是作者这本书并没有讲清楚这里的输入X的形状是什么?只要记住这一步的目的是将输入转化为形状为[batch_size,输入特征维度28*28=784]的矩阵。
def net(X):# w矩阵的形状为(784,10)return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
4.定义交叉熵损失函数
交叉熵损失函数: l ( y , y ^ ) = − l o g y ^ t r u e c l a s s l(y,\hat y)=-log \hat y _{true class} l(y,y^)=−logy^trueclass ,这里的代码不使用Python的for循环迭代,因为效率往往很低,这里采用一个运算符。
使用一个案例来理解一下。
- 创建变量y表示真实标签,在下面的案例中,第一个样本的标签是0,第二个标签的类别是2。
y的形状是(2,) y_hat表示模型的预测结果,y_hat的形状是(2,3)y_hat[[0, 1], [0,2]]表示取第0行的第0个元素0.1和第1行的第2个元素0.5
# 创建一个一维张量 y,值为 [0, 2]。
y = torch.tensor([0, 2])
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
print(y_hat[[0, 1], y]) # tensor([0.1000, 0.5000])
由上述的案例可以写出交叉熵损失函数的代码
y_hat表示模型的预测结果,y_hat的形状是(256,10),每一行表示一个样本中每一类的概率值。**y**是真实标签,形状为(batch_size,),下标表示样本,数值表示真实类别。len返回张量第一个维度的大小,所以range生成的数组为[0,1,...255]
def cross_entropy(y_hat, y):return - torch.log(y_hat[range(len(y_hat)), y])cross_entropy(y_hat, y)
5.分类精度
将预测类别与真实y元素进行比较,来权衡预测的准确度。预测正确输出1,错误输出0。
检查 y ^ \hat y y^的维度
- 分类问题的模型预测输出,可以是以下两种形式
- 概率矩阵-多分类任务:形状为
(batch_size,num_classes),每行表示样本的各类别概率。这种情况,我们选择每行概率最大的下标作为该样本的类。 - 类别标签-直接预测类别:形状为
(batch_size,),下标表示样本,数值表示真实类别。
- 概率矩阵-多分类任务:形状为
- 由于等式运算符“
==”对数据类型很敏感, 因此我们将y_hat的数据类型转换为与y的数据类型一致。 - 比较得到的结果
cmp是布尔值数组转换为y的数据类型(数值数组),True转换为1、False转换为0,最后结果返回float便于后续计算准确度。
def accuracy(y_hat, y): if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:# 眼行方向取概率最大的类别索引 输出的形状是(batch_size,)y_hat = y_hat.argmax(axis=1)# dtype返回张量的数据类型# type(转换类型):返回新数据类型的张量cmp = y_hat.type(y.dtype) == y #将类型转换为一致再比较return float(cmp.type(y.dtype).sum())
评估任意模型net上的精度
Accumulator()是一个初始化累加器,用于存储两个值。metric[0]累计正确预测的样本数,metric[1]累计总样本数。
核心代码是便利数据集每个批次,累加每个批次的正确数可以得到所有样本的正确数,并累加每个批次的样本数等到总的样本数。最后返回这个数据集的准确率。
def evaluate_accuracy(net, data_iter): #@save"""计算在指定数据集上模型的精度"""# 步骤1:如果模型是PyTorch模块,设置为评估模式(关闭dropout等)if isinstance(net, torch.nn.Module):net.eval() # 步骤2:初始化累加器(正确预测数,总样本数)metric = Accumulator(2) # 步骤3:禁用梯度计算以加速推理with torch.no_grad():for X, y in data_iter: # 遍历数据集的每个批次# 步骤4:计算本批次正确数,并累加 y.numel返回y的总样本数metric.add(accuracy(net(X), y), y.numel()) # 步骤5:返回准确率(正确数 / 总数)return metric[0] / metric[1]
这里定义一个实用程序类Accumulator,用于对多个变量进行累加。
zip函数将当前累加值列表和输入的args参数进行配对,第一个参数与累加值列表的第一个元素组成元组,第二个参数与累加值列表的第二个元素组成元组,以此类推。add操作可以计算每个位置的累加值。
class Accumulator: #@save"""在n个变量上累加"""def __init__(self, n):# 初始化存储n个累加值的列表,初始为0.0self.data = [0.0] * n # 将输入的多个值(*args)逐个累加到对应的存储位置def add(self, *args):self.data = [a + float(b) for a, b in zip(self.data, args)]# 重置所有累加值为0.0def reset(self):self.data = [0.0] * len(self.data)# 通过索引访问累加值(例如metric[0]获取第一个累加值)def __getitem__(self, idx):return self.data[idx]
6.训练
定义一个训练函数
num_epochs参数控制训练的总轮数,每轮会遍历整个数据集一次。
updater函数指定优化函数,这里我们还是采用自定义优化算法小批量随机梯度下降法,设置学习率为0.1。
d2l中的小批量随机梯度下降法定义我们在线性回归中实现过,这里直接用就行了。这里需要注意之前求损失函数的时候没有取均值,所以我们在这里取均值运算也就是除以batch_size。
def train(net, train_iter, test_iter, loss, num_epochs, updater): #@savefor epoch in range(num_epochs):# 计算每个周期的平均损失和训练的准确度train_metrics = train_epoch(net, train_iter, loss, updater)# 评估模型在测试集上的分类准确率,返回准确度test_acc = evaluate_accuracy(net, test_iter)# 循环结束后,train_metrics 和 test_acc 仅保留最后一个 epoch 的值# train_loss平均损失 train_acc训练的准确度train_loss, train_acc = train_metrics# 断言最后一个 epoch 的结果assert train_loss < 0.5, train_lossassert train_acc <= 1 and train_acc > 0.7, train_accassert test_acc <= 1 and test_acc > 0.7, test_acclr=0.1
def updater(batch_size):return d2l.sgd([W,b],lr,batch_size)#def sgd(params, lr, batch_size): #@save
# """小批量随机梯度下降"""
# with torch.no_grad():
# for param in params: #一次更新参数w和b
# param -= lr * param.grad / batch_size
# param.grad.zero_()
train_epoch函数定义训练模型的一个epoch,如果扫一遍所有数据。返回平均训练损失和训练准确率。
根据优化器类型选择不同的梯度计算和更新策略
- 自定义优化器,我们自定义优化在计算损失时,只需要计算总损失的梯度。在优化器函数中,会除以
batch_size来计算平均梯度。 - PyTorch内置优化器,需要计算平均损失梯度,在优化器里不会除以
batch_size
def train_epoch(net, train_iter, loss, updater): #@save"""训练模型一个迭代周期(定义见第3章)"""# 步骤1:设置模型为训练模式(启用Dropout/BatchNorm等训练专用层)if isinstance(net, torch.nn.Module):net.train()# 步骤2:初始化累加器(总损失、总正确数、总样本数)metric = Accumulator(3)for X, y in train_iter: # 遍历训练数据的每个批次# 步骤3:前向传播计算预测值和损失y_hat = net(X)l = loss(y_hat, y) # 计算损失# 步骤4:反向传播并更新参数(分PyTorch优化器和自定义优化器)if isinstance(updater, torch.optim.Optimizer):# 情况1:使用PyTorch内置优化器updater.zero_grad() # 清空梯度l.mean().backward() # 计算平均损失的梯度 l.mean()将损失取平均,得到一个标量updater.step() # 根据当前梯度更新参数else:# 情况2:使用自定义优化器l.sum().backward() # 计算总损失的梯度updater(X.shape[0]) # 传入批次大小以更新参数# 步骤5:累加本批次的损失、正确数和样本数metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())# 步骤6:返回平均训练损失和训练准确率return metric[0] / metric[2], metric[1] / metric[2]
在这个过程中,可以定义一个在动画中绘制数据的实用程序类Animator,来可视化训练进度。
这个部分的代码我没有看,感觉不是重点。而且代码适用于Jupyter,如果在PyCharm上运行还需要修改。
7.预测
模型训练完后,就需要对图像进行分类预测。给定一系列图像,我们将比较它们的实际标签(文本输出的第一行)和模型预测(文本输出的第二行)。
输入样本矩阵X的形状为(batch_size,1,28,28),模型的输出为 (batch_size, 10) 的预测概率矩阵,所以这里保留每行数据中概率最大的下标索引作为该样本的分类值。
def predict(net, test_iter, n=6): #@save# 步骤1:从测试数据迭代器中获取一个批次的数据(X:图像,y:真实标签)for X, y in test_iter: # 仅取第一个批次break# 获取实际标签的文本trues = d2l.get_fashion_mnist_labels(y)# 获取预测标签的文本preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))titles = [true +'\n' + pred for true, pred in zip(trues, preds)] # 步骤5:显示前n个样本的图像及标题d2l.show_images(# 重塑去掉channelX[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])d2l.plt.show()代码总结
- 获取到的数据集是可迭代的数据装载器(DataLoader)对象,其中输入数据X的形状是(256,1,28,28),标签Y的形状是(256)。
- 模型
net传入的参数是数据集X,W的形状为[输入特征维度,输出类别数]。我们需要改变X的形状为和W矩阵做乘法,所以X的形状需要拉平为[256,784]。对模型的原本输出进行softmax操作转换为每个分量表示该类别的概率。 - 开始训练模型,训练模型迭代
num_epochs个周期,在每个周期里都需要扫一遍数据- 损失函数使用交叉熵损失
cross_entropy - 根据损失函数计算参数的梯度
- 沿着梯度的负方向调用
updater优化器更新参数
- 损失函数使用交叉熵损失
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2l
d2l.use_svg_display()# 使用4个进程来读取数据
def get_dataloader_workers(): #@savereturn 4
# 下载Fashion-MNIST数据集,然后将其加载到内存中
# 获取数据集与测试集:可迭代的数据装载器(DataLoader)对象
def load_data_fashion_mnist(batch_size, resize=None): #@save""""""trans = [transforms.ToTensor()]if resize:trans.insert(0, transforms.Resize(resize))trans = transforms.Compose(trans)# 加载训练集和测试集mnist_train = torchvision.datasets.FashionMNIST(root="./data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST(root="./data", train=False, transform=trans, download=True)return (data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=get_dataloader_workers()),data.DataLoader(mnist_test, batch_size, shuffle=False,num_workers=get_dataloader_workers()))# 定义softmax操作
def softmax(X):X_exp = torch.exp(X)# axis=0 沿列方向求和 axis=1 沿行方向求和 keepdims=true保持输出的维度与原数组一致partition = X_exp.sum(1, keepdims=True)return X_exp / partition # 这里应用了广播机制# 定义模型
def net(X):# torch.matmul 计算两个张量的矩阵乘积return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
# 定义损失函数
def cross_entropy(y_hat, y):return - torch.log(y_hat[range(len(y_hat)), y])# 返回预测结果数组[0,1,...],0表示预测正确,1表示预测错误
def accuracy(y_hat, y):if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:# 眼行方向取概率最大的类别索引 输出的形状是(batch_size,)y_hat = y_hat.argmax(axis=1)# dtype返回张量的数据类型# type(转换类型):返回新数据类型的张量cmp = y_hat.type(y.dtype) == y #将类型转换为一致再比较return float(cmp.type(y.dtype).sum())# 常用的累计值类
class Accumulator: #@save"""在n个变量上累加"""def __init__(self, n):# 初始化存储n个累加值的列表,初始为0.0self.data = [0.0] * n# 将输入的多个值(*args)逐个累加到对应的存储位置def add(self, *args):self.data = [a + float(b) for a, b in zip(self.data, args)]# 重置所有累加值为0.0def reset(self):self.data = [0.0] * len(self.data)# 通过索引访问累加值(例如metric[0]获取第一个累加值)def __getitem__(self, idx):return self.data[idx]
# 计算在指定模型上的精准度,返回准确率
def evaluate_accuracy(net, data_iter): # @save"""计算在指定数据集上模型的精度"""# 步骤1:如果模型是PyTorch模块,设置为评估模式(关闭dropout等)if isinstance(net, torch.nn.Module):net.eval()# 步骤2:初始化累加器(正确预测数,总样本数)metric = Accumulator(2)# 步骤3:禁用梯度计算以加速推理with torch.no_grad():for X, y in data_iter: # 遍历数据集的每个批次# 步骤4:计算本批次正确数,并累加 y.numel返回y的总样本数metric.add(accuracy(net(X), y), y.numel())# 步骤5:返回准确率(正确数 / 总数)return metric[0] / metric[1]# 返回Fashion-MNIST数据集的文本标签
def get_fashion_mnist_labels(labels): # @savetext_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat','sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']# i是整数,循环labels里的每一个标签i,找到对应的文字标签,return [text_labels[int(i)] for i in labels]
# 定义优化器
def updater(batch_size):return d2l.sgd([W,b],lr,batch_size)def accuracy(y_hat, y):if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:# 眼行方向取概率最大的类别索引 输出的形状是(batch_size,)y_hat = y_hat.argmax(axis=1)cmp = y_hat.type(y.dtype) == y #将类型转换为一致再比较return float(cmp.type(y.dtype).sum())# 定义训练函数
def train(net, train_iter, test_iter, loss, num_epochs, updater): # @savefor epoch in range(num_epochs):# 计算每个周期的平均损失和训练的准确度train_metrics = train_epoch(net, train_iter, loss, updater)# 评估模型在测试集上的分类准确率,返回准确度test_acc = evaluate_accuracy(net, test_iter)print('周期',epoch,train_metrics,test_acc)#周期 1 (0.5702844327926636, 0.8132833333333334) 0.8065#周期 2 (0.52667691599528, 0.8266666666666667) 0.8171#周期 3 (0.5005770920435587, 0.8323666666666667) 0.8022#周期 4 (0.4853064177831014, 0.8371833333333333) 0.822#周期 5 (0.47540995241800943, 0.8408833333333333) 0.8296#周期 6 (0.4646201767603556, 0.8434166666666667) 0.8295#周期 7 (0.4580004734039307, 0.8455833333333334) 0.827#周期 8 (0.4527769360860189, 0.8470833333333333) 0.8336#周期 9 (0.4474859270731608, 0.84775) 0.833# 训练模型一个迭代周期
def train_epoch(net, train_iter, loss, updater): # @save# 步骤1:设置模型为训练模式(启用Dropout/BatchNorm等训练专用层)if isinstance(net, torch.nn.Module):net.train()# 步骤2:初始化累加器(总损失、总正确数、总样本数)metric = Accumulator(3)for X, y in train_iter: # 遍历训练数据的每个批次# 步骤3:前向传播计算预测值和损失y_hat = net(X)l = loss(y_hat, y) # 计算损失# 步骤4:反向传播并更新参数(分PyTorch优化器和自定义优化器)if isinstance(updater, torch.optim.Optimizer):# 情况1:使用PyTorch内置优化器updater.zero_grad() # 清空梯度l.mean().backward() # 计算平均损失的梯度 l.mean()将损失取平均,得到一个标量updater.step() # 根据当前梯度更新参数else:# 情况2:使用自定义优化器l.sum().backward() # 计算总损失的梯度updater(X.shape[0]) # 传入批次大小以更新参数# 步骤5:累加本批次的损失、正确数和样本数metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())# 步骤6:返回平均训练损失和训练准确率return metric[0] / metric[2], metric[1] / metric[2]# 预测函数
def predict(net, test_iter, n=6): #@save# 步骤1:从测试数据迭代器中获取一个批次的数据(X:图像,y:真实标签)for X, y in test_iter: # 仅取第一个批次break# 获取实际标签的文本trues = d2l.get_fashion_mnist_labels(y)# 获取预测标签的文本preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))titles = [true +'\n' + pred for true, pred in zip(trues, preds)]# 步骤5:显示前n个样本的图像及标题d2l.show_images(# 重塑去掉channelX[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])d2l.plt.show()
# 步骤1:初始化权重
num_inputs = 784
num_outputs = 10
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)# 步骤2:获取数据集:可迭代的数据装载器(DataLoader)对象
batch_size = 256
train_iter,test_iter = load_data_fashion_mnist(batch_size)# 步骤3:开始训练模型
num_epochs=10
lr=0.1
train(net, train_iter, test_iter, cross_entropy, num_epochs, updater)
softmax的简洁实现
这里只介绍了Pytorch中可以简洁实现的部分
调用d2l实现的部分和之前自定义部分一样,只不过封装了一层。
初始化模型参数
线性回归使用的是线性层(全连接层),全连接层在Linear类中定义。
全连接层 nn.Linear 要求输入为一维特征向量,因此需要展平操作。PyTotch不会隐式调整输入的形状,因此定义展平层在线性层前调整网络输入的形状。
nn.Linear(784, 10)执行线性变换,将784维输入映射到10维输出。
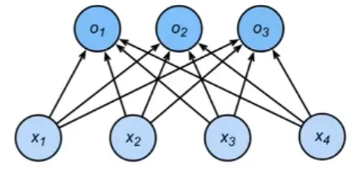
# PyTorch不会隐式地调整输入的形状。因此,net = nn.Sequential(nn.Flatten(), # 展平层:将多维输入压缩为一维向量nn.Linear(784, 10)# 全连接层:输入784维,输出10维
)
PyTorch自动将偏置项初始化为零,适合多数情况,因此代码未显式处理。
net.apply(函数)对net的每个子模块调用参数的函数,
def init_weights(m):# 如果是线性层if type(m) == nn.Linear:# 正态分布初始化权重nn.init.normal_(m.weight, std=0.01)net.apply(init_weights); # 递归应用初始化函数到所有子模块
损失函数和优化算法
loss = nn.CrossEntropyLoss(reduction='none')
我们使用学习率为0.1的小批量随机梯度下降作为优化算法。 这与我们在线性回归例子中的相同,这说明了优化器的普适性。
trainer = torch.optim.SGD(net.parameters(), lr=0.1)
CrossEntropyLoss的实现:softmax和交叉熵损失的数值稳定法
y ^ = s o f t m a x ( o ) \hat y = softmax(o) y^=softmax(o),具体展开 y ^ i = e x p ( o i ) ∑ k e x p ( o k ) \hat y_i = \frac{exp(o_i)}{\sum_k exp(o_k)} y^i=∑kexp(ok)exp(oi)。
在深度学习中,处理分类任务时,softmax函数和交叉熵损失的结合计算容易出现数值不稳定问题,尤其是当输入的未归一化预测值(logits)过大或过小时。
如果 o k o_k ok中的一些数值非常大, 那么 e x p ( o k ) exp(o_k) exp(ok)可能大于数据类型容许的最大数字,发生overflow上溢。 使分母或分子变为inf(无穷大), 最后得到的是0、inf或nan(不是数字)的 y ^ j \hat y_j y^j。
解决办法
- 调整logits以稳定softmax
通过从所有logits中减去最大值 M = m a x ( o k ) M=max(o_k) M=max(ok),确保调整后的输入满足 o j − M ≤ 0 o_j−M≤0 oj−M≤0,从而 e x p ( o j − M ) ≤ 1 exp(o_j−M)≤1 exp(oj−M)≤1,避免上溢。
调整后的公式与原式等价,因为分子和分母同时乘以了 e x p ( M ) exp(M) exp(M): y ^ i = e x p ( o i − M ) ∑ k e x p ( o k − M ) = e x p ( o i − M ) e x p ( M ) ∑ k e x p ( o k − M ) e x p ( M ) = e x p ( o i ) ∑ k e x p ( o k ) \hat y_i = \frac{exp(o_i-M)}{\sum_k exp(o_k-M)} = \frac{exp(o_i-M)exp(M)}{\sum_k exp(o_k-M)exp(M)} = \frac{exp(o_i)}{\sum_k exp(o_k)} y^i=∑kexp(ok−M)exp(oi−M)=∑kexp(ok−M)exp(M)exp(oi−M)exp(M)=∑kexp(ok)exp(oi)
- 结合softmax与交叉熵损失
原来的交叉熵损失函数: l ( y , y ^ ) = − l o g y ^ t r u e c l a s s l(y,\hat y)=-log \hat y _{true class} l(y,y^)=−logy^trueclass,仅需计算正确类别的预测概率的对数。
通过数学变形,将交叉熵损失直接表示为 Logits 的稳定形式,避免显式计算 Softmax 概率。
带入调整后的Logits: l ( y , y ^ ) = − l o g y ^ i = − l o g e x p ( o j − M ) ∑ k e x p ( o k − M ) = − ( o j − m a x ( o k ) − l o g ∑ k e x p ( o k − M ) ) = l o g ∑ k e x p ( o k − M ) ) − ( o t r u e − M ) l(y,\hat y)=-log \hat y _i = -log \frac{exp(o_j-M)}{\sum_k exp(o_k-M)}=-(o_j-max(o_k)-log\sum_k exp(o_k-M)) = log\sum_k exp(o_k-M))-(o_{true}-M) l(y,y^)=−logy^i=−log∑kexp(ok−M)exp(oj−M)=−(oj−max(ok)−log∑kexp(ok−M))=log∑kexp(ok−M))−(otrue−M)