自监督学习(Self-supervised Learning)李宏毅
目录
Self-supervised Learning简介:
BERT :
How to use BERT
case1:sequence to class 语言积极性OR消极性判断
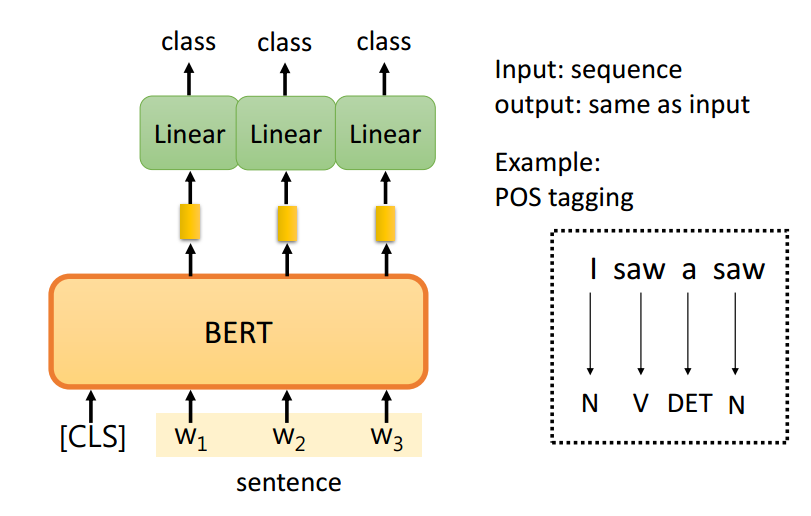
case2:sequence to sequence句子中的词语词性标注
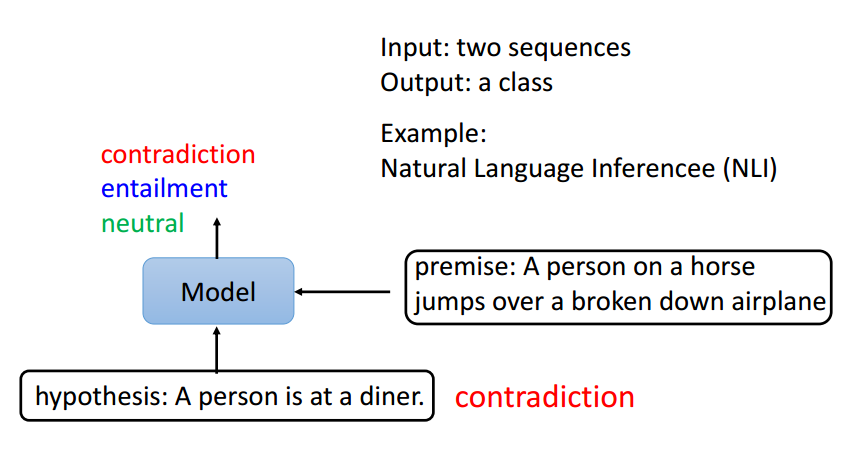
case3:sequence×2 to class两个句子是不是一个为前提一个为假设
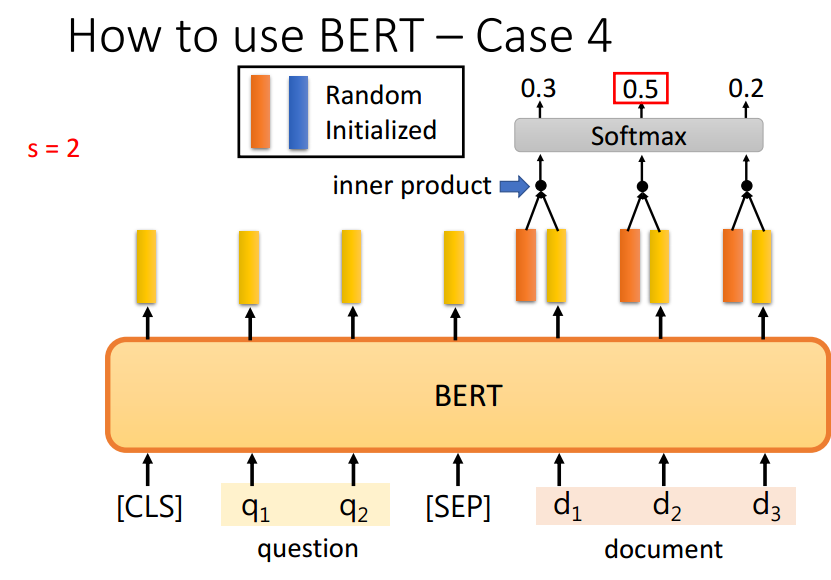
case4:QA问题(要求答案一定会出现在原文里)输出的数字是答案在原文的起始和结尾位置
Why does BERT work?
GPT
Self-supervised Learning简介:
supervised Learning为输入一个x经过Model之后输出成一个y,然后根据label里的正确y进行比较,但是如果没有label怎么办?
Self-supervised Learning可以把输入文件中的x转换为x1x2,用x1作为输入用x2作为label。所以Self-supervised Learning中没有label,可以看成Unsupervised Learning。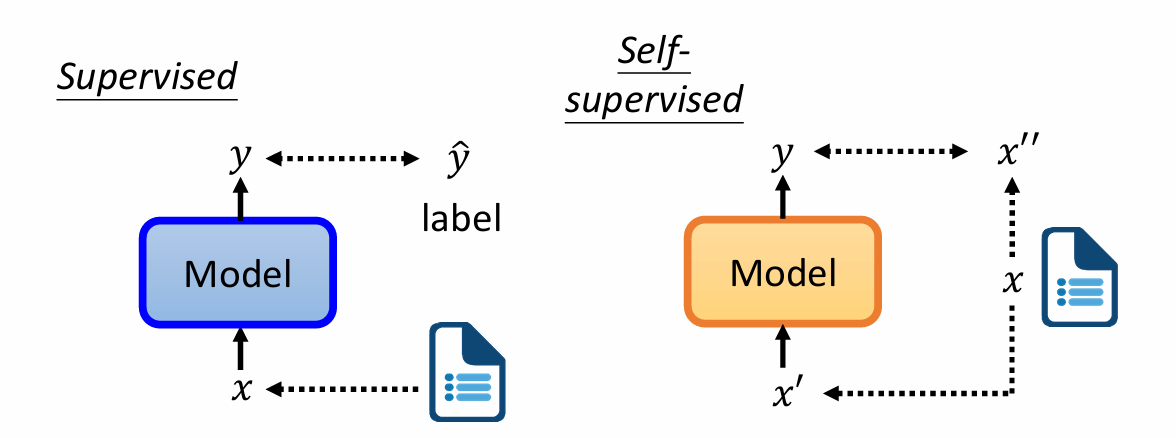
BERT :
BERT是一个Transformer Encoder 输入输出是一个等长的向量。训练的时候是在做填空题的时候,随机盖住一个字softmax之后的输出来判别这个盖住的字是所有汉字中的哪一个(把所有的每一个汉字看成一个class)?然后和truth进行比较。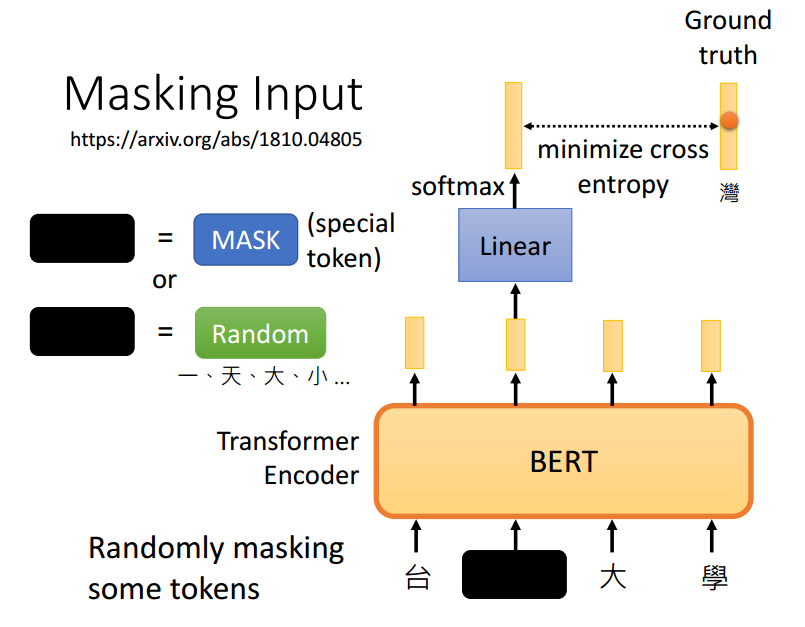
训练的时候也做了接收一对句子,并判断第二个句子是否是第一个句子的自然延续。
这个任务有助于模型理解句子之间的关系。
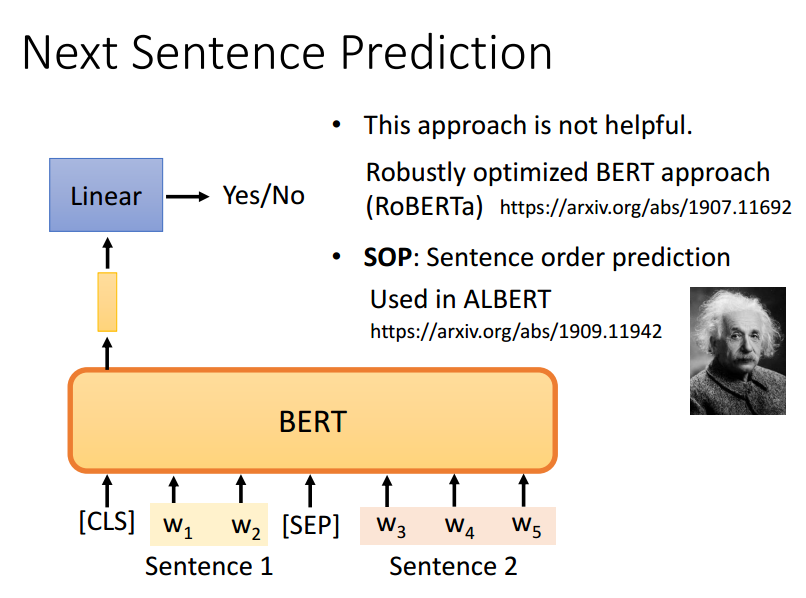
它可以解决SOP问题,即判断两句话的语序是否为颠倒。

BERT功能强大,在进行pre训练之后,进行微调就可以用到多种场景
GLUE(General Language Understanding Evaluation)一般语言理解评估,评估一般模型的能力。包括九个任务。BERT在NLP领域比较适用。
How to use BERT
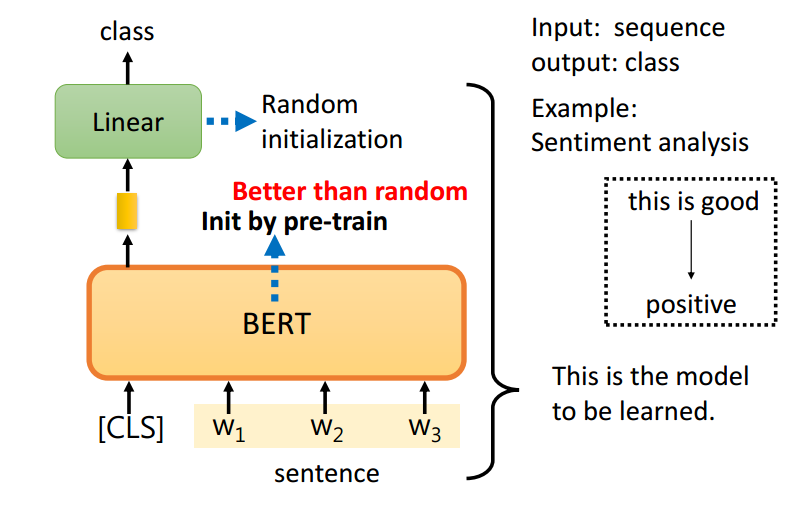
case1:sequence to class 语言积极性OR消极性判断
在Linear的时候,采用随机初始化的参数,在BERT的仍要提供一些标注的资料,利用填空训练出来的模型比随机初始化参数的模型LOSS下降的更快,且最后的LOSS数值更小。
case2:sequence to sequence句子中的词语词性标注
BERT的参数不是随机初始化的
case3:sequence×2 to class两个句子是不是一个为前提一个为假设
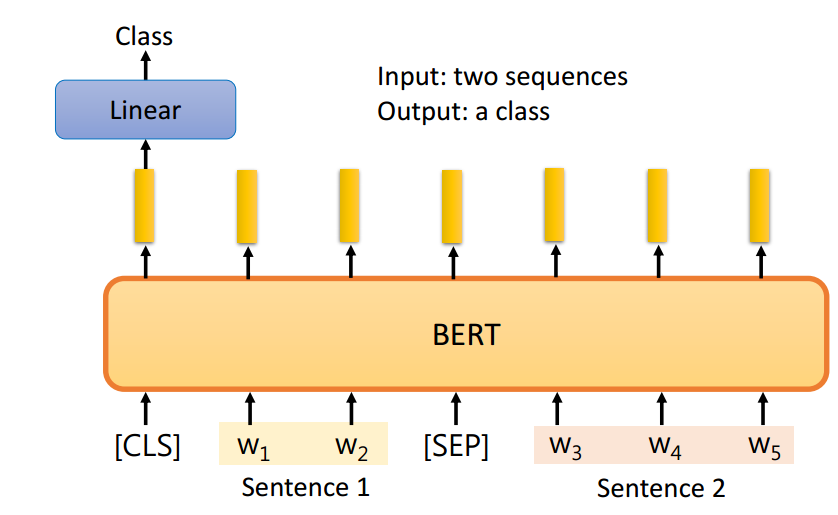
case4:QA问题(要求答案一定会出现在原文里)输出的数字是答案在原文的起始和结尾位置

Why does BERT work?
“苹果手机”和“喝苹果汁”的两个果是不是相似的呢?(黄色越深代表相似度越高)
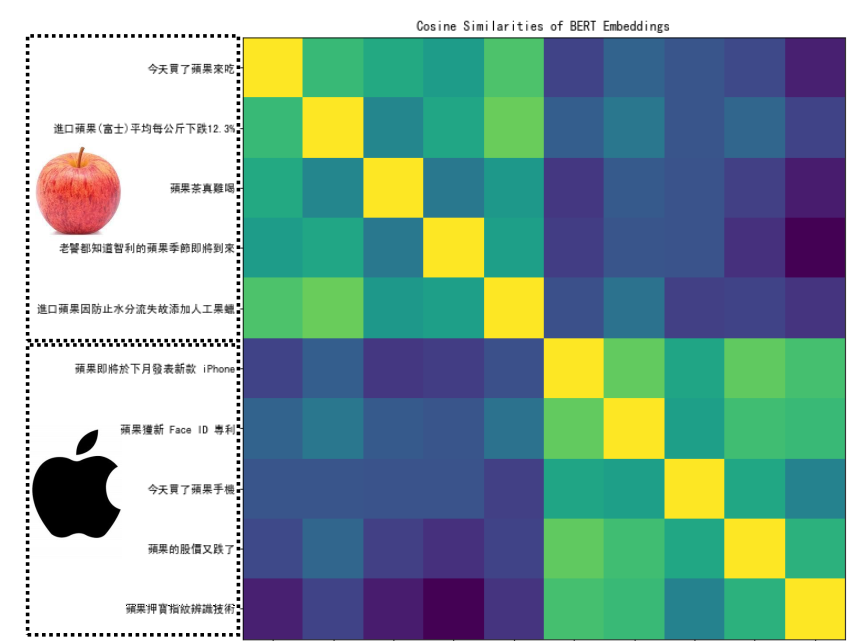
答案是不相似的
Multi-lingual BERT
发现训练完一个语言的BERT之后他就自动的具备了另一个语言的功能,
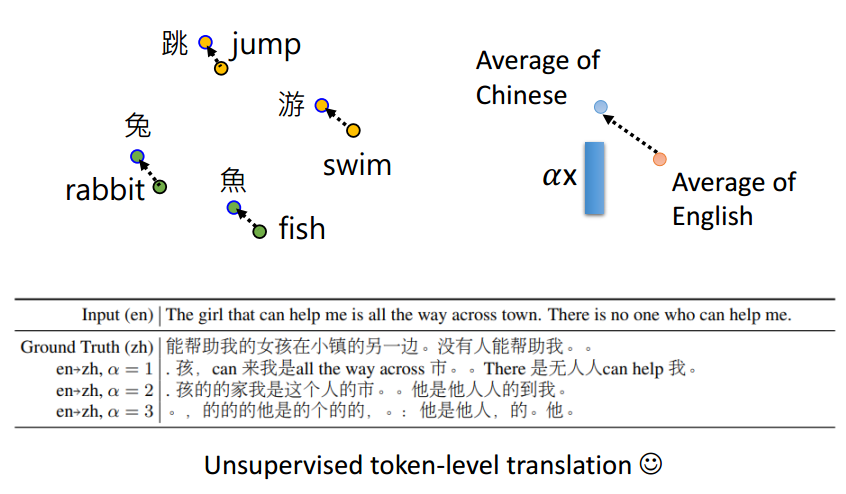
认为是不同的语言意思差不多的词在几乎相近的向量空间上
GPT
训练方式自回归语言建模(Autoregressive Language Modeling):
在训练时,GPT的任务是给定一段文本的前面部分,预测接下来的一个词或标记。
换句话说,GPT会根据上下文信息逐步生成文本,每次生成一个单词(或更精确的标记),然后使用这个生成的标记作为下一个预测的输入。
举个例子,如果给定文本是:“The cat is on the”,GPT的任务是预测下一个词是“mat”或其他合理的词。