Transformer架构:基于自注意力机制推动NLP革命性突破
Transformer架构自2017年提出以来,彻底改变了自然语言处理领域的发展轨迹,成为当前大语言模型(如BERT、GPT系列)的核心基础。
这一架构通过自注意力机制取代传统RNN/CNN的序列处理方式,解决了长距离依赖建模困难和并行计算效率低下的问题,同时通过位置编码显式引入序列位置信息,弥补了注意力机制对顺序的天然不敏感性。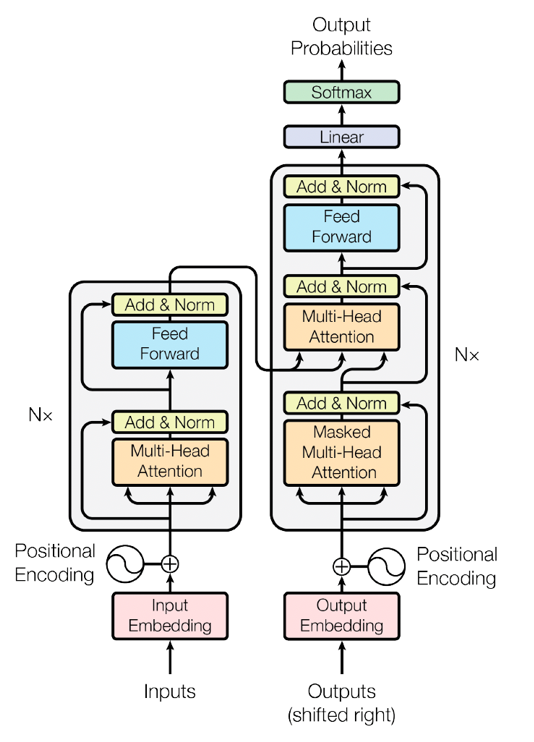
基于Transformer的预训练模型(如BERT、GPT)通过大规模无监督学习获取通用语言表示,再通过微调或提示工程灵活适配各种下游任务,实现了NLP领域的一系列突破性进展。
一、Transformer架构的历史背景与核心思想
Transformer架构由Google Brain团队的八位研究人员于2017年12月在论文《Attention Is All You Need》中首次提出。该架构的初衷是改进机器翻译,摆脱传统循环神经网络(RNN)和卷积神经网络(CNN)在序列处理上的局限性。
在提出Transformer之前,NLP领域的主流模型主要依赖RNN和LSTM来处理文本序列,这些模型虽然能捕捉长期依赖,但存在计算效率低下(无法并行处理)、梯度消失等严重问题。同时,基于CNN的模型虽能部分解决并行计算问题,但其固定感受野难以捕捉长距离语义关联。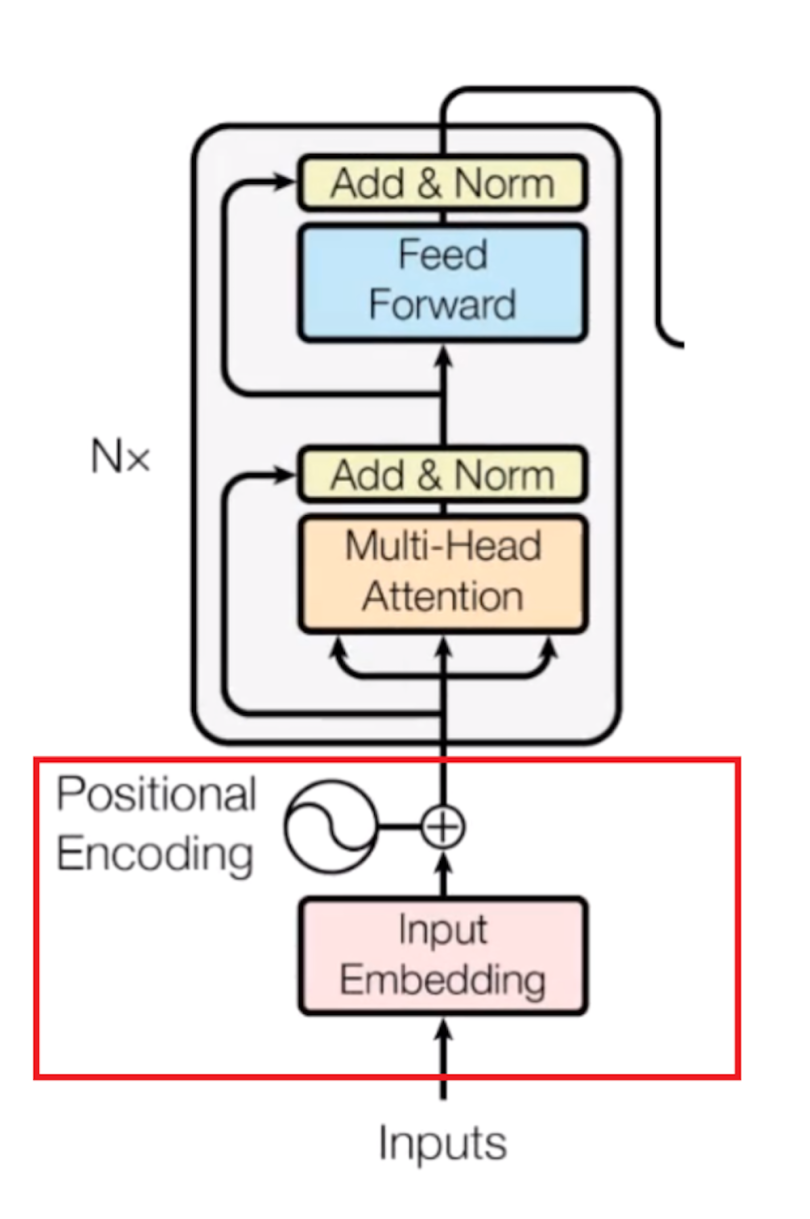
Transformer架构的核心思想是完全基于自注意力机制,无需任何循环或卷积操作即可处理序列数据,从而实现更高的计算效率和更强的长距离依赖建模能力。
Transformer架构的主要创新点体现在三个方面:
- 首先,它首次将自注意力机制作为核心组件,替代传统RNN/CNN的序列处理方式;
- 其次,通过位置编码显式引入序列位置信息,解决了注意力机制对顺序的不敏感问题;
- 最后,采用模块化设计,包括编码器-解码器结构、多头注意力机制、前馈神经网络等组件,增强了模型的灵活性和表达能力。
这些创新使得Transformer在机器翻译任务上首次实现了比RNN更优的性能,同时训练速度提升了5-10倍。
二、自注意力机制的工作流程及其优势
自注意力机制是Transformer架构的核心组件,其工作流程主要包括以下几个步骤:
首先,输入序列通过线性变换生成查询(Query)、键(Key)和值(Value)向量,分别表示当前元素的关注需求、特征标识和实际内容。
例如,输入序列中的每个元素xi通过权重矩阵WQ、WK、WV生成qi=xiWQ、ki=xiWK、vi=xiWV。