#Paper Reading# DeepSeek Math
论文题目: DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
论文地址: https://arxiv.org/pdf/2402.03300
论文发表于: arXiv 2024年4月
论文所属单位: DeepSeek
论文大体内容
本文基于公开的数据集Common Crawl,采用了一种方法抽取出高质量的120B数学数据集,并基于这个数据集训练了一个数学推理模型DeepSeek Math。该模型借助本文提出的GRPO(Group Relative Policy Optimization)方法,增强了其数学推理能力。最终在数学推理上取得了对标GPT-4的效果。
Motivation
数学能力是大模型的重要能力之一,本文专注于探索并提升大模型的数学推理能力。
Contribution
①本文提出了一种方法从Common Crawl的数据中提取出120B的数学数据集。基于这个高质量的数学数据集,小模型上也能取得了跟大模型相当的效果。
②本文提出了GRPO(Group Relative Policy Optimization),它是PPO的优化,用于强化学习。
1. 数学能力是评价大模型能力很重要的一个指标,本文目标是提出模型达到开源大模型数学能力的SOTA,以及达到闭源模型的效果。
2. 120B的数学数据集构建方法如下图,使用的是半监督学习方法:
①使用OpenWebMath数据集作为seed,训练一个fasttext模型。
②fasttext模型预估Common Crawl数据集,选择Top 40B的作为第一轮选择的数据。
③选择出的数据用于扩充seed。除此之外,将超过10%被选择出来的「域」进行人工review,然后扩充了这部分被人工判定为数学域的所有数据。这样可以扩充seed的多样性。
④重复了4轮,最后得到120B的数学数据集。
⑤为了避免评测集数据泄露,这里去掉了与评测集匹配10-gram的数据。

3. 数学数据集质量验证
①对比MathPile、OpenWebMath、Proof-Pile-2共3个数学数据集,直接进行pre-train模型,发现本文抽取的120B数据集效果最好。
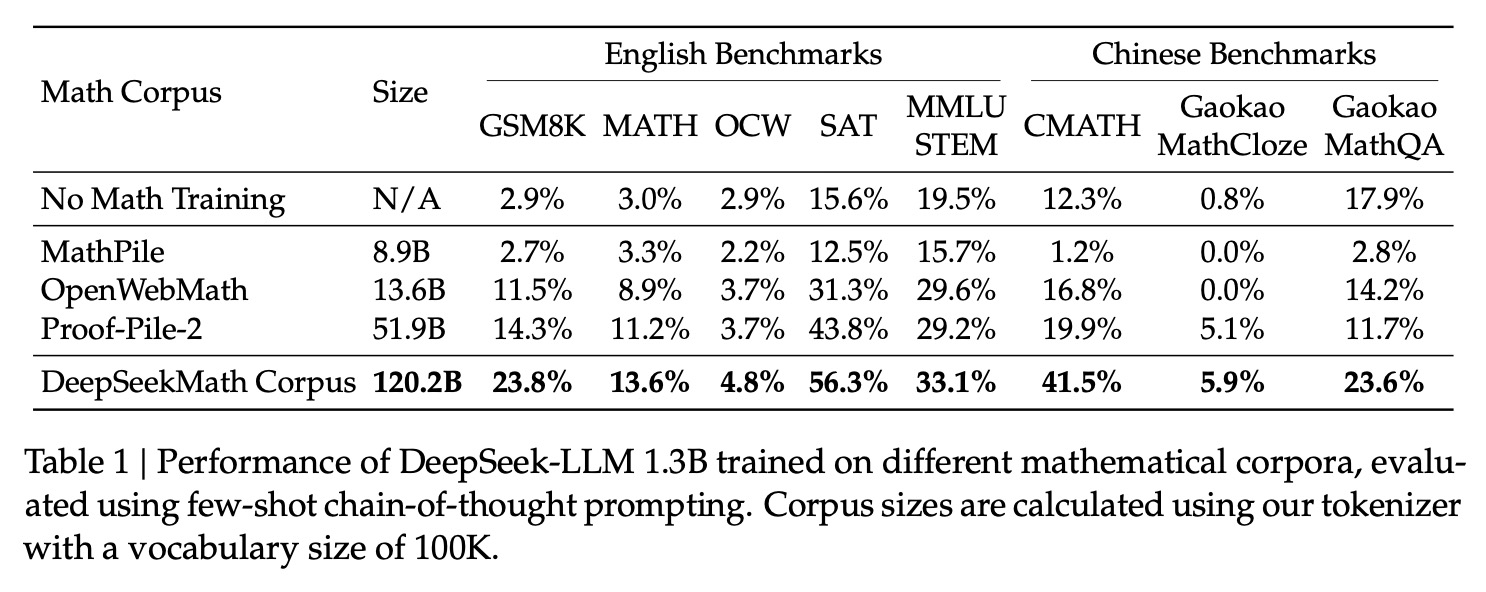
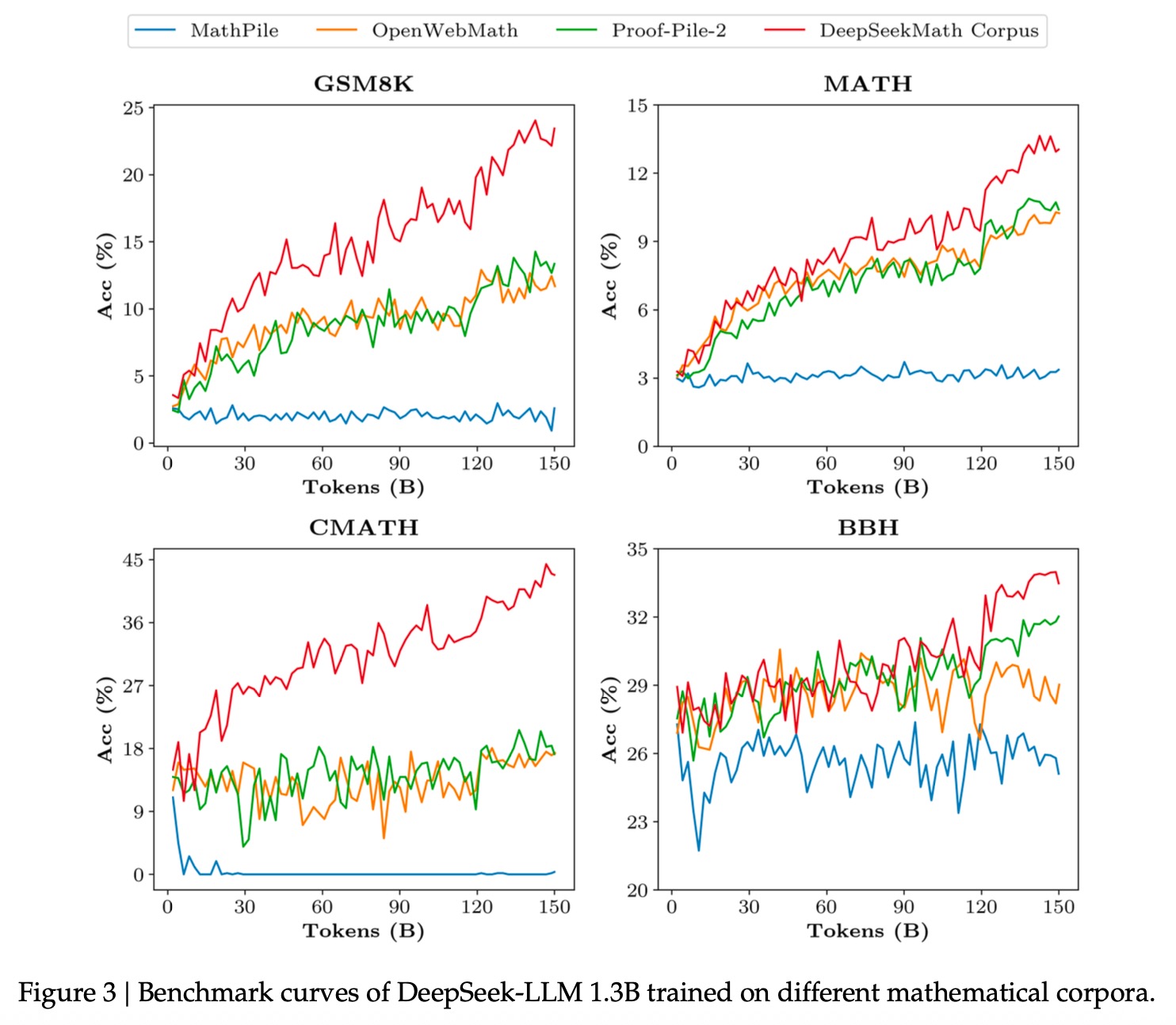
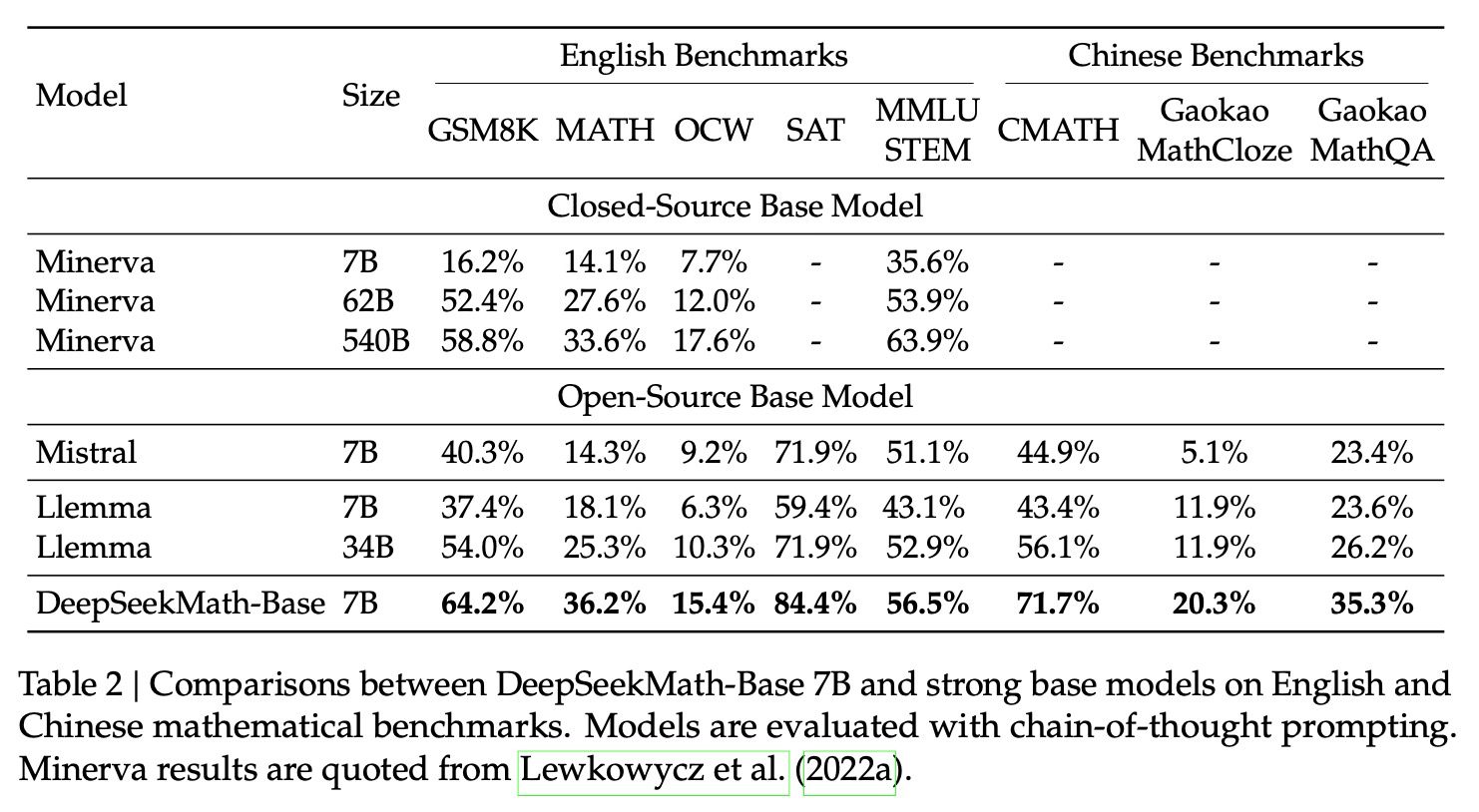
②使用120B数据集对DeepSeek-Coder-Base-v1.5 7B进行续训练,得到DeepSeekMath-Base模型,发现其学习出来的数学效果不错。
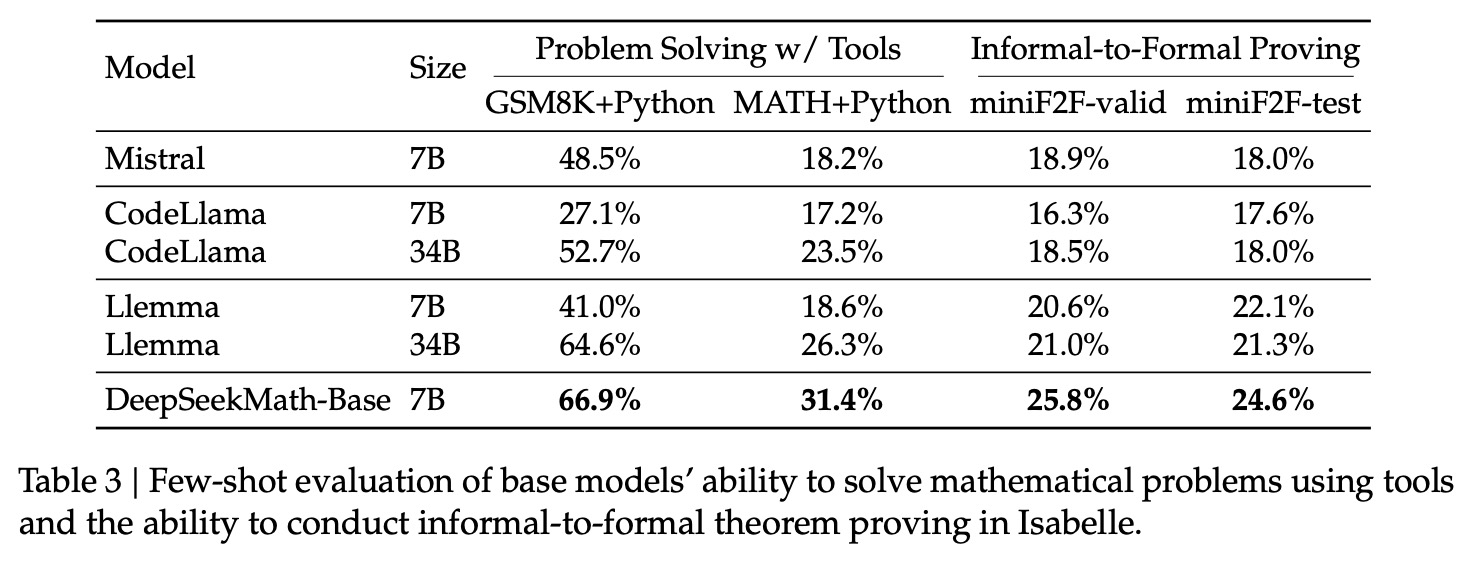
4. SFT阶段
①数据:776k个实例,包括英文和中文数据。
②SFT得到的模型是DeepSeekMath-Instruct 7B,效果不错但差于GPT-4。
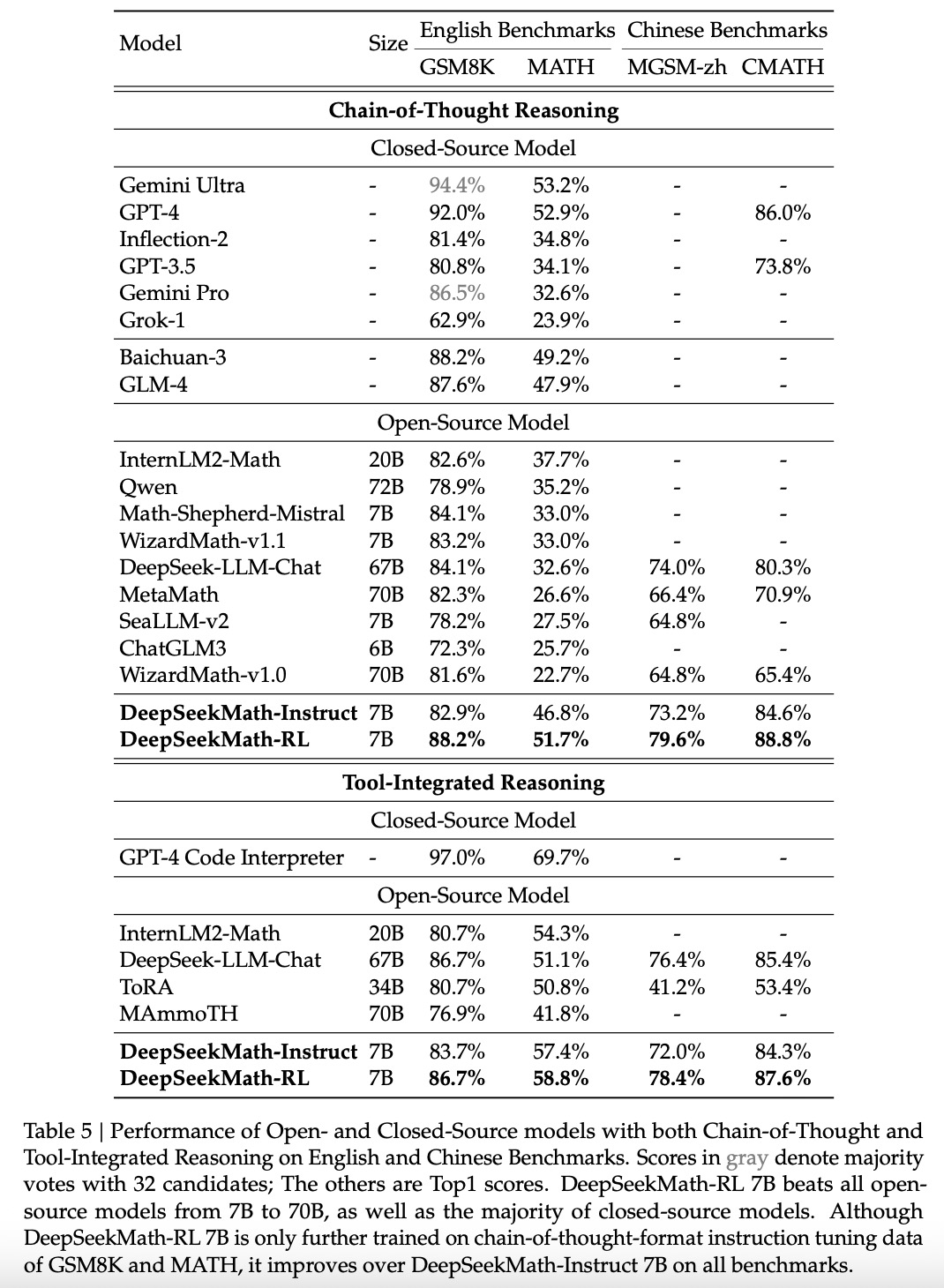
5. RL阶段:LLM在SFT后,继续进行RL能进一步提升其效果。
①本文提出了GRPO(Group Relative Policy Optimization)方法[1],其核心思想是去掉RL中的value model,采用reward model的多次平均值去替代。
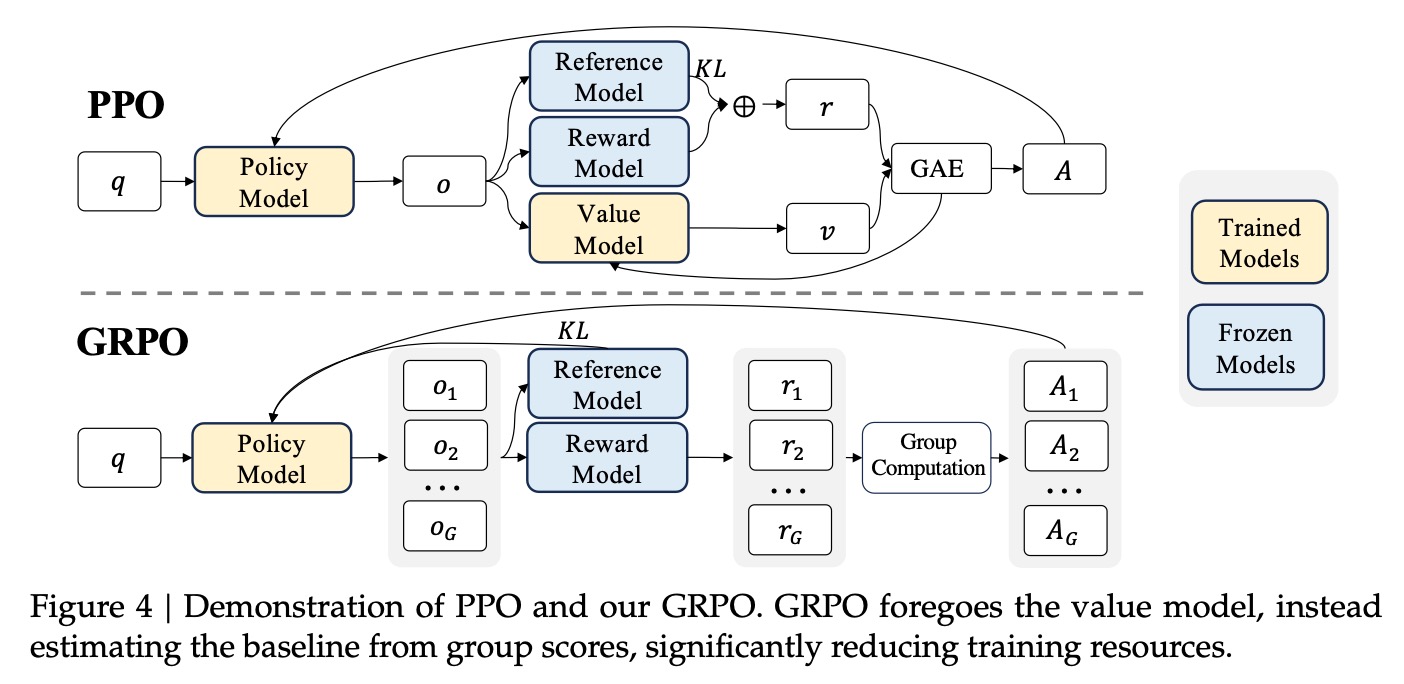
②PPO(Proximal Policy Optimization)的优化目标如下,包括Actor+Critic+裁剪+KL惩罚,意思是新策略需要比旧策略有提升,奖励有上下限,且不能偏离太远。


③GRPO的优化目标如下,Critic去掉了value model,采用reward model的多次平均值去替代,这样可以降低复杂度。其它的裁剪和KL惩罚仍然保留。
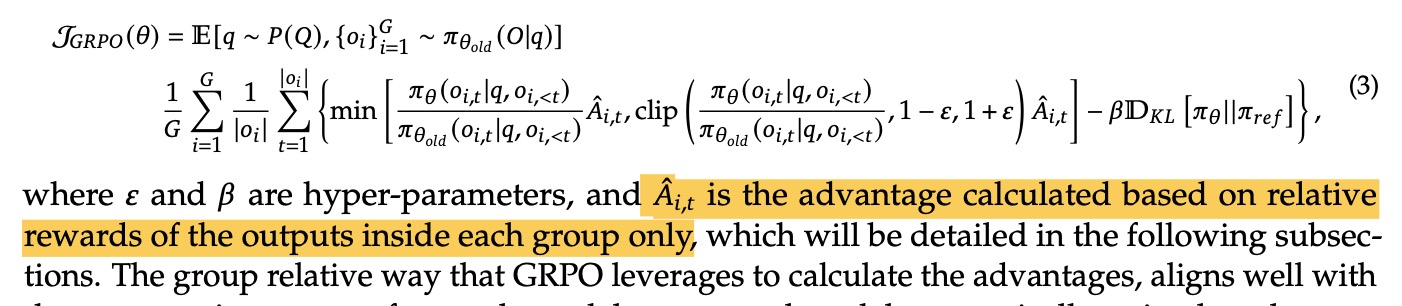
![]()
④RL得到的模型是DeepSeekMath-RL,效果优于DeepSeekMath-Instruct 7B。
6. 本文还通过实验发现Code的训练数据加入,对Math的效果也能有帮助。
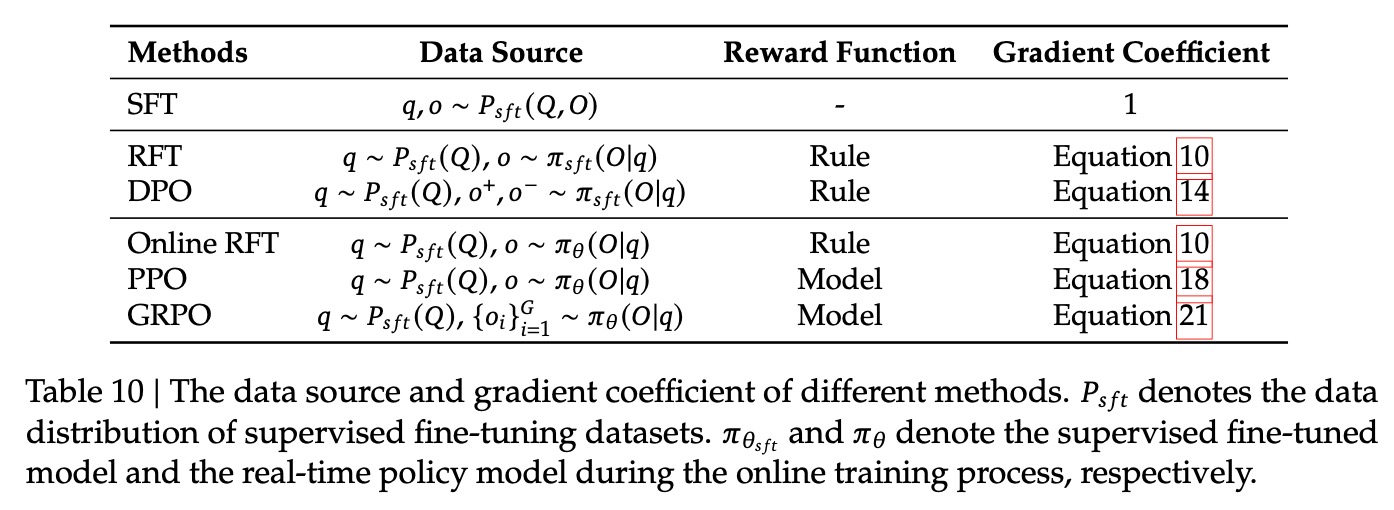
7. 本文对RL中涉及的多种方法建立了统一范式,包括SFT、RFT、DPO、Online RFT、PPO、GRPO优化算法。统一范式里有3项:数据源、奖励函数、优化算法。

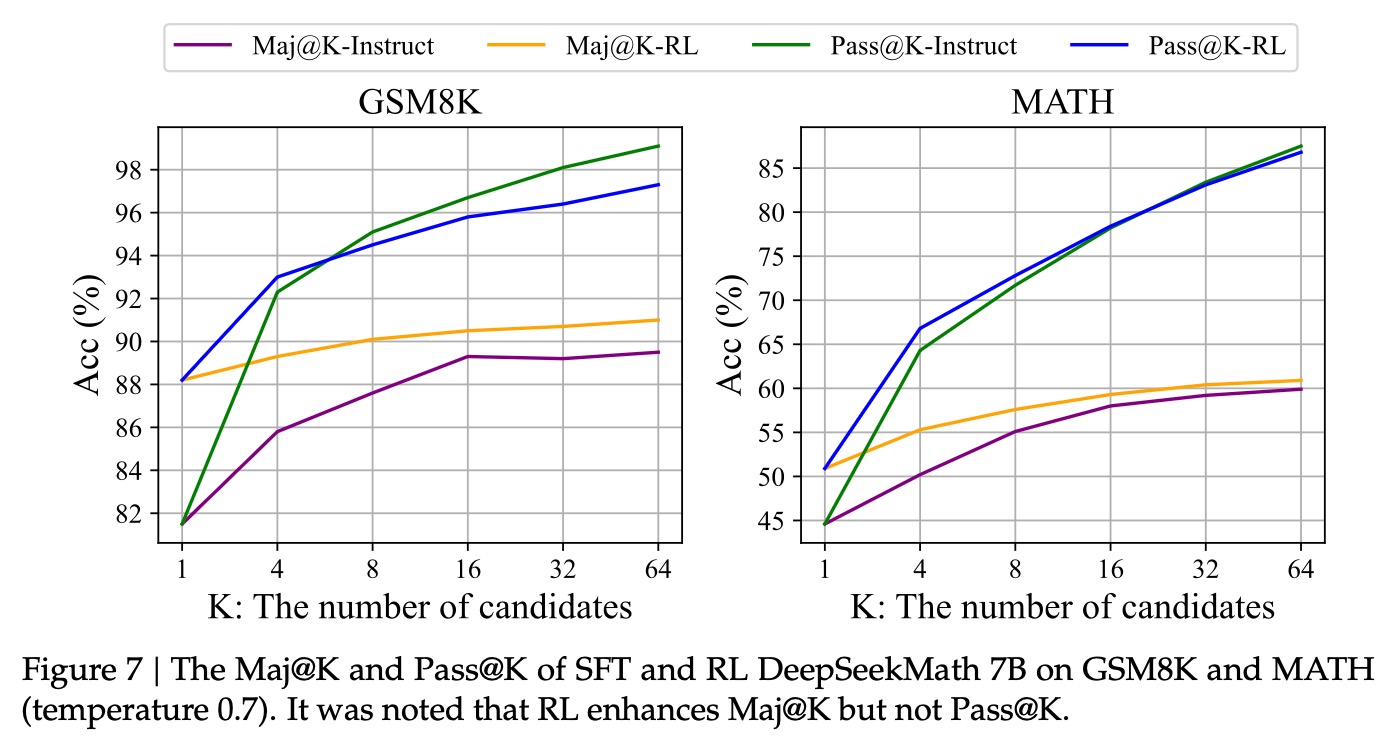
8. 【有意思的点】RL的作用是什么?
①RL核心想要的能力是开放性输出,提升模型的基本能力,但本文的实验发现并不是这样的。RL没有提升模型的基本能力,而是使得输出更鲁棒来提升效果。也就是提升了正确答案的准确率,而不是召回率。
②RL怎样才能更有效呢?Reward Function会更重要,从后续的模型看,通过将model based的reward function改为rule based,这样能提升模型泛化能力,尤其在math和code这种有明显对和错的任务上。
参考资料
[1] 无需RL基础理解 PPO 和 GRPO:https://mp.weixin.qq.com/s/YHoDl99fyNe7MP03BoRc6g
以上均为个人见解,因本人水平有限,如发现有所错漏,敬请指出,谢谢!