扩散模型:了解ai生图的原理
引言
在人工智能领域,生成模型一直是研究热点。从早期的GAN(生成对抗网络)到VAE(变分自编码器),再到如今大火的扩散模型(Diffusion Models),生成式AI技术正以惊人的速度发展。本文将深入探讨扩散模型的工作原理、实现细节以及其在图像生成领域的应用。
一、扩散模型简介
扩散模型是一类通过逐步破坏然后学习重建数据的生成模型。它的核心思想源于非平衡热力学中的"朗之万扩散"过程。简单来说,扩散模型包含两个主要过程:**前向扩散过程**(逐步向数据添加噪声)和**反向扩散过程**(逐步从噪声中恢复数据)。
这种方法在图像生成领域取得了惊人的成功,是Stable Diffusion、DALL-E 2和Midjourney等流行AI绘画工具背后的核心技术。
![扩散过程示意图]

*图1:扩散模型的前向(添加噪声)和反向(去噪)过程示意图*
二、数学原理:从噪声到清晰
扩散模型的魅力在于其数学原理的优雅。整个过程可以用马尔可夫链来描述,分为前向和反向两个过程。
2.1 前向扩散过程
前向过程是一个逐步将图像变为噪声的过程。如果我们用$x_0$表示原始图像,我们逐步添加高斯噪声,得到一系列越来越嘈杂的图像$x_1, x_2, ..., x_T$,当$T$足够大时,$x_T$几乎是纯高斯噪声。
这个过程由下面的方程描述:
$$q(x_t|x_{t-1}) = \mathcal{N}(x_t; \sqrt{1-\beta_t}x_{t-1}, \beta_t\mathbf{I})$$
其中$\beta_t$是一个控制噪声添加速率的参数,通常是预先设定的,从很小的值逐渐增加到接近1。
有趣的是,由于高斯分布的性质,我们可以直接从$x_0$采样任意时间步$t$的$x_t$:
$$q(x_t|x_0) = \mathcal{N}(x_t; \sqrt{\bar{\alpha}_t}x_0, (1-\bar{\alpha}_t)\mathbf{I})$$
其中$\bar{\alpha}_t = \prod_{i=1}^t (1-\beta_i)$。
2.2 反向扩散过程
扩散模型的核心在于训练一个神经网络来学习反向过程,即从噪声$x_T$逐步恢复出原始图像$x_0$。这个反向过程可以表示为:
$$p_\theta(x_{t-1}|x_t) = \mathcal{N}(x_{t-1}; \mu_\theta(x_t, t), \Sigma_\theta(x_t, t))$$
其中$\mu_\theta$和$\Sigma_\theta$是由神经网络预测的参数。有趣的是,在实践中,我们通常不直接预测$\mu_\theta$,而是预测添加的噪声$\epsilon$,然后通过噪声预测计算$\mu_\theta$。
训练目标可以简化为最小化预测噪声与实际添加噪声之间的均方误差:
$$L = \mathbb{E}_{x_0, \epsilon, t}[||\epsilon - \epsilon_\theta(x_t, t)||^2]$$
这就是为什么我们的代码中有这样一行损失计算:
loss = F.mse_loss(predicted_noise, noise)三、模型架构:U-Net的威力
在我们的实现中,采用了改进的U-Net架构作为扩散模型的主干网络。U-Net因其在图像分割领域的成功而闻名,它的特点是具有对称的编码器-解码器结构,以及跳跃连接(skip connections)。
3.1 时间步编码
扩散模型的一个关键点是,网络需要知道当前处理的是哪个时间步的图像,因为不同时间步的噪声水平不同。我们使用正弦位置编码来处理时间步:
class SinusoidalPositionEmbeddings(nn.Module):def __init__(self, dim):super().__init__()self.dim = dimdef forward(self, time):device = time.devicehalf_dim = self.dim // 2embeddings = np.log(10000) / (half_dim - 1)embeddings = torch.exp(torch.arange(half_dim, device=device) * -embeddings)embeddings = time[:, None] * embeddings[None, :]embeddings = torch.cat((embeddings.sin(), embeddings.cos()), dim=-1)return embeddings这种编码方式来源于Transformer模型,能够有效地将时间信息嵌入到网络中。
3.2 Block设计
U-Net的基本构建块包括下采样Block和上采样Block:
class Block(nn.Module):def __init__(self, in_ch, out_ch, time_emb_dim, up=False):super().__init__()self.time_mlp = nn.Linear(time_emb_dim, out_ch)self.up = upif up:# 上采样操作self.upsample = nn.ConvTranspose2d(in_ch, in_ch, 4, 2, 1)self.conv1 = nn.Conv2d(in_ch, out_ch, 3, padding=1)else:# 下采样操作self.conv1 = nn.Conv2d(in_ch, out_ch, 3, padding=1)self.downsample = nn.Conv2d(out_ch, out_ch, 4, 2, 1)# 其他层...这种设计允许网络在不同分辨率上捕获图像特征,同时通过时间步嵌入调整每个层的行为。
3.3 完整的U-Net架构
完整的U-Net结构包括一个编码器(下采样路径)、一个瓶颈层和一个解码器(上采样路径):
class UNet(nn.Module):def __init__(self, in_channels=3, model_channels=64, out_channels=3, time_dim=256):# 初始化代码...def forward(self, x, t):# 时间嵌入t = self.time_mlp(t)# 编码器路径x = self.conv_in(x)d1 = self.down1(x, t)d2 = self.down2(d1, t)d3 = self.down3(d2, t)# 瓶颈层bottleneck = self.bottleneck1(d3)bottleneck = self.bottleneck2(bottleneck)# 解码器路径up1 = self.up1(bottleneck, t)up2 = self.up2(up1, t)up3 = self.up3(up2, t)return self.conv_out(up3)![模型架构图]
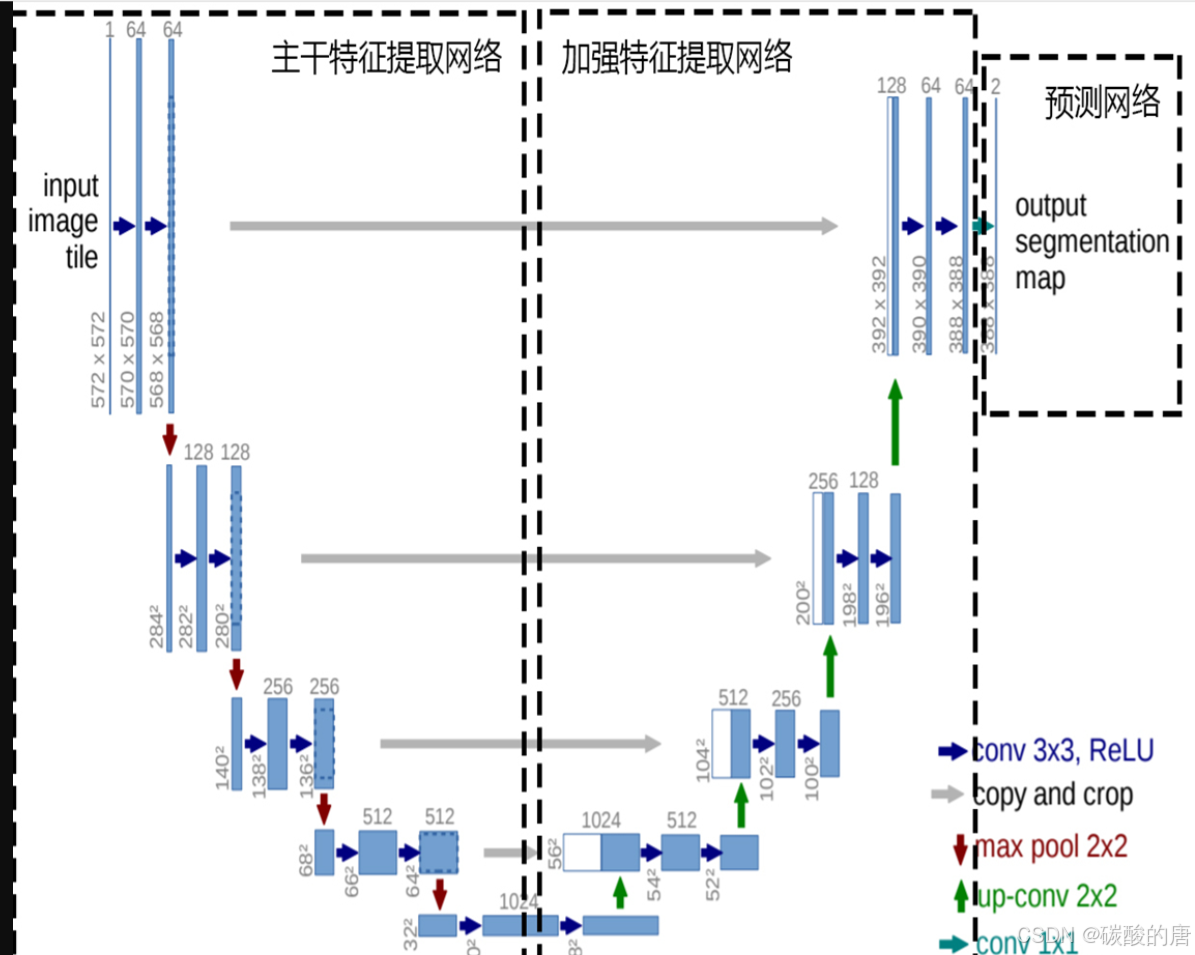
*图3:U-Net架构示意图,展示编码器-解码器结构*
四、训练过程:从噪声到艺术
训练扩散模型是一个计算密集型的过程,但我们的实现通过一些优化使其变得可行。
4.1 训练策略
训练的核心思想是:
1. 从训练数据中采样图像$x_0$
2. 随机选择时间步$t$
3. 生成噪声$\epsilon$
4. 根据公式计算$x_t$
5. 用网络预测噪声$\epsilon_\theta(x_t, t)$
6. 最小化预测噪声与实际噪声之间的差距
这个过程在我们的`train_step`方法中实现:
def train_step(self, batch, optimizer):# 获取批次图像images = batch.to(self.device)batch_size = images.shape[0]# 采样时间步和噪声t = torch.randint(0, self.timesteps, (batch_size,), device=self.device, dtype=torch.long)noise = torch.randn_like(images)# 添加噪声到图像noisy_images = self.add_noise(images, noise, t)# 预测噪声predicted_noise = self.model(noisy_images, t)# 计算损失loss = F.mse_loss(predicted_noise, noise)# 反向传播loss.backward()optimizer.step()4.2 训练结果
我们的模型在每个训练轮次后生成样本,可以直观地看到生成质量的提升。初期生成的图像往往是模糊不清的,但随着训练的进行,图像变得越来越清晰和真实。
![训练进度图]
*图4:不同训练轮次的生成结果对比,展示模型学习过程*
五、采样过程:见证奇迹的诞生
训练完成后,生成新图像的过程称为"采样"。这个过程从纯随机噪声开始,然后应用学习到的反向扩散过程,逐步去除噪声,最终得到一个清晰的图像。
@torch.no_grad()
def generate_sample(self, image_size, batch_size=1, channels=3):# 从随机噪声开始x = torch.randn((batch_size, channels, image_size, image_size), device=self.device)# 逐步去噪for t in reversed(range(self.timesteps)):t_batch = torch.full((batch_size,), t, device=self.device, dtype=torch.long)x = self.sample_timestep(x, t_batch)# 调整到[0,1]范围x = (x.clamp(-1, 1) + 1) / 2return x如果你观察这个去噪过程,会发现这是一个非常神奇的过程,从无序的噪声逐渐浮现出有结构、有意义的图像
六、应用前景:无限可能
扩散模型作为生成式AI的前沿技术,有着广泛的应用场景:
6.1 创意设计与艺术创作
扩散模型可以生成各种风格的艺术作品,为设计师和艺术家提供灵感。与传统的GAN相比,扩散模型生成的图像通常更加多样化,不容易出现"模式崩溃"问题。
6.2 数据增强
在医疗影像等数据稀缺的领域,扩散模型可以生成高质量的合成数据,用于扩充训练集,提高下游任务的性能。
6.3 图像编辑与修复
扩散模型可以用于图像修复、超分辨率和风格迁移等任务,通过控制采样过程,实现对图像的精细编辑。
七、结语
扩散模型作为生成式AI的前沿技术,以其强大的建模能力和灵活的应用场景,正在改变我们创造和理解视觉内容的方式。通过本文的实现和讲解,我们深入了解了扩散模型的工作原理和实现细节。
这个领域仍在快速发展,期待更多创新和突破。无论是对研究者还是实践者,扩散模型都提供了一个充满可能性的探索空间。
如果你对扩散模型感兴趣,可以尝试使用我们的代码,探索不同数据集和参数设置下的生成效果,或者基于此实现更复杂的条件生成模型。AI生成的未来,等待你的探索!
---
**参考资料:**
1. Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. NeurIPS.
2. Nichol, A. Q., & Dhariwal, P. (2021). Improved denoising diffusion probabilistic models. ICML.
3. Song, J., Meng, C., & Ermon, S. (2020). Denoising diffusion implicit models. ICLR.
4. Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. CVPR.