Python的简单练习
两数的最大公约数
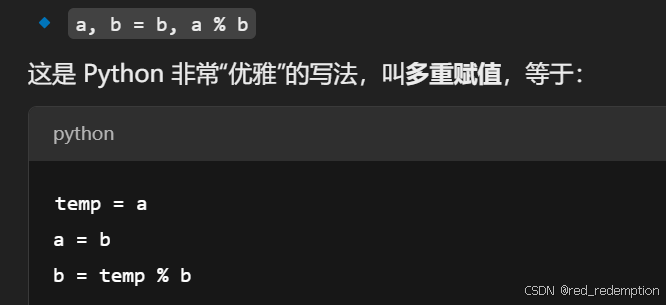
def gcd(a, b):while b != 0:a, b = b, a % breturn a# 示例
a = 36
b = 60
print(f"{a} 和 {b} 的最大公约数是: {gcd(a, b)}")while b != 0:
-
while:是 Python 的 循环语句,意思是“当...的时候一直重复做某事”。 -
b != 0:表示“只要 b 不等于 0”,就继续执行下面的代码。
对角线相连的菱形
n = int(input("请输入菱形的边长:"))# 上半部分(含中间行)
for i in range(n):for j in range(2 * n - 1):if j == n - 1 - i or j == n - 1 + i:print("*", end="")else:print(" ", end="")print()# 下半部分(不含中间行)
for i in range(n - 2, -1, -1):for j in range(2 * n - 1):if j == n - 1 - i or j == n - 1 + i:print("*", end="")else:print(" ", end="")print()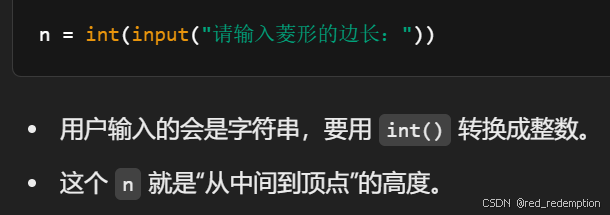
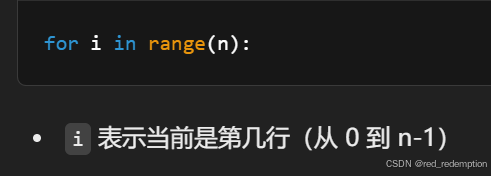
if j == n - 1 - i or j == n - 1 + i
print()直接换行
杨辉三角
def generate_yanghui_triangle(n):triangle = [] # 存储整个三角形for i in range(n):row = [1] * (i + 1) # 每一行最开始全是 1# 从第二个元素到倒数第二个元素开始计算for j in range(1, i):row[j] = triangle[i - 1][j - 1] + triangle[i - 1][j]triangle.append(row)return triangle# 显示杨辉三角
def print_triangle(triangle):n = len(triangle)for i, row in enumerate(triangle):print(" " * (n - i), end="") # 打印前导空格对齐for num in row:print(f"{num} ", end="")print()# 示例
rows = int(input("请输入杨辉三角的行数:"))
triangle = generate_yanghui_triangle(rows)
print_triangle(triangle)
triangle 实际上是一个:列表的列表
[
[1],
[1, 1],
[1, 2, 1],
[1, 3, 3, 1],
...
]
Python 不会主动去判断变量类型,也不要求变量的结构一定一致
只是遍历 triangle 这个变量。只要这个变量“像个列表”,能被遍历就行
len(triangle) 是获取 triangle 的行数
for i, row in enumerate(triangle):一边遍历列表,一边记录当前的“行号” i 和当前的“行内容” row
print(" " * (n - i), end="")让数字靠近中轴线
def func():
print("hello")
这个会报错,因为没有缩进。
def func():
print("hello", end="") # 不换行
print("world")
这个没问题,虽然不换行,但语法结构没错,因为语句都在 def 下面、缩进对齐。
统计不同字符(字母、数字、空格、其他字符)的个数
text = input("请输入一段文本:")letters = 0
digits = 0
spaces = 0
others = 0for ch in text:if ch.isalpha(): # 字母letters += 1elif ch.isdigit(): # 数字digits += 1elif ch.isspace(): # 空格spaces += 1else: # 其他字符others += 1print(f"字母: {letters} 个")
print(f"数字: {digits} 个")
print(f"空格: {spaces} 个")
print(f"其他字符: {others} 个")
检查字符串包含
text = "Life is short.I use python"if "python" in text:new_text = text.replace("python", "Python")print("替换后的字符串:", new_text)
else:print("原字符串:", text)
随机生成六位验证码
random模块
---randint(0,9)可生成一个0-9之间的随机整数
---random.choice()从参数中选择一个
string模块
---string.ascii_letters可得到所有字母
---string.digits可得到所有数字
import random
import stringdef generate_code(length=6):chars = string.ascii_letters + string.digits # 所有字母 + 数字code = ''.join(random.choice(chars) for _ in range(length))return code# 示例
print("生成的验证码是:", generate_code())random.choice(chars) for _ in range(length), 生成器表达式(generator expression)
''.join(...) 会把生成器里的字符连成一个字符串
code = ''
for _ in range(6):
code += random.choice(chars)也可以但是 .join() + 生成器写法更快、更优雅。
进度条
进度条一般以图形的方式显示已完成任务量和未完成任务量,并以动态文字的方式显示任务的完成度。要求编写程序实现文本进度条功能。
import timedef progress_bar(total=30):for i in range(total + 1):percent = int((i / total) * 100)bar = '#' * i + '-' * (total - i)print(f"\r[{bar}] {percent}%", end="")time.sleep(0.1) # 模拟加载过程print("\n任务完成!")# 示例
progress_bar()
total 表示 进度条的总长度,
i / total → 得到当前进度(比如 0.5),* 100 → 换算成百分比
\r → 回到行首,刷新当前行,end="" 避免换行,sleep() 控制速度
过滤敏感词
编写代码,实现具有过滤敏感词功能的程序。
def filter_sensitive(text, sensitive_words):for word in sensitive_words:if word in text:text = text.replace(word, "*" * len(word))return text# 示例
sensitive_list = ["暴力", "不健康", "sb", "傻瓜"]
user_input = input("请输入一段话:")filtered = filter_sensitive(user_input, sensitive_list)
print("过滤后的结果:", filtered)
将字符串的每一个字符放入列表中
text = "hello"
char_list = list(text)
print(char_list)

列表去重
li_one = [1, 2, 1, 2, 3, 5, 4, 3, 5, 7, 4, 7, 8]# 使用集合去重,再转回列表(注意顺序会改变)
li_one_unique = list(set(li_one))print("去重后的列表:", li_one_unique)set(li_one):
-
set是 Python 中的集合类型,它的特点是:-
不允许重复元素
-
元素无序
-
list(...):
-
因为集合类型
set不是列表,如果你想继续像操作列表那样使用它(比如排序、索引等),就需要转回列表类型。 -
所以用
list(set(li_one))就把“去重后的集合”变成了一个新列表。
由于集合 set 是无序的,所以转换之后的新列表 li_one_unique 的元素顺序通常会和原来 li_one 中的顺序不一致。
列表合并降序排列
li_num1 = [5, 5, 2, 7]
li_num2 = [3, 6]# 合并
merged_list = li_num1 + li_num2# 降序排序
sorted_desc = sorted(merged_list, reverse=True)print("合并后并降序排序的列表:", sorted_desc)
sorted() 是 Python 的一个内置函数,用于对任何可迭代对象进行排序(比如列表、元组、集合等)。
返回的是一个新的已排序列表,不会修改原来的 merged_list。
-
reverse是sorted()的一个可选参数。 -
当你设置
reverse=True时,表示按照降序来排列元素。 -
如果是默认的
reverse=False,就是升序排列。
8名教师随机分配办公室
import random# 老师名单
teachers = ['孙老师', '吴老师', '王老师', '钱老师', '李老师', '周老师', '赵老师', '郑老师']# 办公室,初始化为空列表
offices = [[], [], []]# 打乱老师顺序(确保分配随机性)
random.shuffle(teachers)# 分配老师:前3个给办公室1,接着3个给办公室2,剩下2个给办公室3
offices[0] = teachers[:3]
offices[1] = teachers[3:6]
offices[2] = teachers[6:]# 打印分配结果
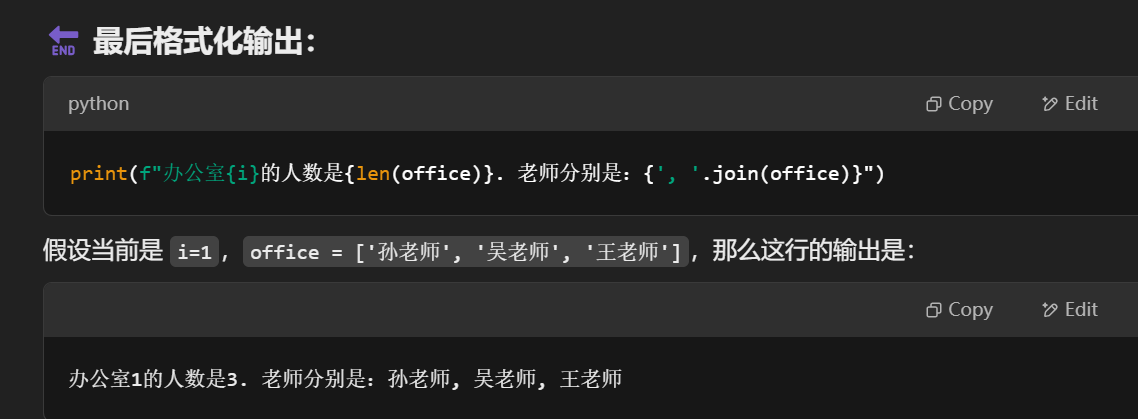
for i, office in enumerate(offices, 1):print(f"办公室{i}的人数是{len(office)}. 老师分别是:{', '.join(office)}")
enumerate(offices, 1) 会遍历每一个办公室列表,并同时给它一个“编号”:
| 第一次循环 | i = 1, office = ['孙老师', '吴老师', '王老师'] |
|---|---|
| 第二次循环 | i = 2, office = ['钱老师', '李老师', '周老师'] |
| 第三次循环 | i = 3, office = ['赵老师', '郑老师'] |
enumerate(..., 1) 的 1 是指定从1开始编号(默认是从0开始的)。
len(office) 就是这个办公室里老师的数量
join() 是一个字符串方法,用来把一个列表里的字符串连接成一个字符串,中间用逗号隔开。
office = ['孙老师', '吴老师', '王老师']
', '.join(office) → '孙老师, 吴老师, 王老师'
十大歌手评选
votes = {} # 用于记录每个歌手的得票数print("请输入你要投票的歌手名字(输入 'end' 结束):")while True:name = input("投票给:")if name.lower() == 'end':breakvotes[name] = votes.get(name, 0) + 1# 排序输出:按票数从高到低
sorted_votes = sorted(votes.items(), key=lambda x: x[1], reverse=True)print("\n投票结果:")
for singer, count in sorted_votes:print(f"{singer}: {count}票")
votes[name] = votes.get(name, 0) + 1
作用:每投一次票,票数加1。
这行是给歌手(或候选人)计票用的。
-
votes是一个字典,记录每个人的票数:
例如:{'张三': 2, '李四': 3} -
votes.get(name, 0)的意思是:-
去字典里找名字为
name的那个人的票数; -
如果还没出现过(字典里没有这个名字),就返回
0; -
相当于默认票数是0。
-
-
然后
+1:当前票数加一。 -
最终更新写入字典:
-
如果是新的人,就新加进去;
-
如果已经有了,就在原来的基础上加1。
-
sorted_votes = sorted(votes.items(), key=lambda x: x[1], reverse=True)
作用:把投票结果按票数从高到低排序。
-
votes.items():把字典转换成一个列表,每一项是(名字, 票数)这样的元组:{'张三': 3, '李四': 1}.items() → [('张三', 3), ('李四', 1)] -
sorted(..., key=lambda x: x[1]):
排序的时候按照元组的第2个元素(也就是票数)来比较。lambda x: x[1]是匿名函数,意思是“拿到每个(名字, 票数)元组的票数”。 -
reverse=True:表示降序排列(票数多的排前面)。
分类统计字符个数
编写程序,用户输入一个字符串,以回车结束,利用字典统计其中字母和数字出现的次数(回车符代表结束)。
输入格式是一个以回车结束的字符串,例如输入abc1ab,输出{'a': 2, 'b': 2, 'c': 1, '1': 1}。
text = input("请输入一个字符串(回车结束):")
counter = {}for char in text:if char.isalnum(): # 判断是否是字母或数字counter[char] = counter.get(char, 0) + 1print(counter)
计票机制(类歌手)
candidates = ['张三', '李四', '王五']
votes = dict.fromkeys(candidates, 0)print("候选人有:", ', '.join(candidates))
print("请输入投票人名(输入 'end' 结束):")while True:name = input("投票给:")if name.lower() == 'end':breakif name in votes:votes[name] += 1else:print("无效候选人,票数不计。")# 输出最终结果
sorted_votes = sorted(votes.items(), key=lambda x: x[1], reverse=True)print("\n计票结果:")
for person, count in sorted_votes:print(f"{person}: {count}票")
votes = dict.fromkeys(candidates, 0)
作用:根据候选人列表创建一个初始“投票字典”,每个人的票数都设为 0。
candidates = ['张三', '李四', '王五']
votes = dict.fromkeys(candidates, 0) # 得到
votes = {'张三': 0, '李四': 0, '王五': 0}
name.lower()
作用:把用户输入的名字全部转成小写,通常用于不区分大小写的匹配判断。
sorted_votes = sorted(votes.items(), key=lambda x: x[1], reverse=True)
这就是你前面问过的:
-
按照**票数(x[1])**进行排序;
-
reverse=True表示 降序(票数多的排在前面); -
结果是一个列表,元素是元组
(名字, 票数)。
斗地主发牌看牌
(要求看牌时排序展示)
import random # 导入随机模块,用于洗牌# 定义花色(suits)和点数(ranks)
suits = ['♠', '♥', '♣', '♦'] # 黑桃、红桃、梅花、方块
ranks = ['3', '4', '5', '6', '7', '8', '9', '10', 'J', 'Q', 'K', 'A', '2'] # 常规牌面# 生成一副完整的扑克牌(不包括大小王的52张 + 小王 + 大王)
deck = [s + r for r in ranks for s in suits] + ['小王', '大王']# 洗牌:打乱deck中的顺序
random.shuffle(deck)# 创建三个玩家的牌堆 + 1个底牌堆
player1 = []
player2 = []
player3 = []
bottom = []# 发牌(共54张,前51张发给三位玩家,最后3张作为底牌)
for i in range(len(deck)):if i < 51:if i % 3 == 0:player1.append(deck[i]) # 玩家1每隔3张拿一张elif i % 3 == 1:player2.append(deck[i]) # 玩家2每隔3张拿一张else:player3.append(deck[i]) # 玩家3每隔3张拿一张else:bottom.append(deck[i]) # 剩下3张作为底牌# 定义一个排序函数:将玩家手牌按点数大小排序
def sort_cards(cards):# 创建一个牌面优先级映射(数字越大表示牌越大)order = {r: i for i, r in enumerate(ranks)} # 3最小,2最大(不含王)order.update({'小王': 13.5, '大王': 14}) # 王的等级高于所有普通牌# 自定义排序函数:提取每张牌的“点数”部分用于比较def card_key(card):if card in ['小王', '大王']:return order[card] # 王直接用其键值return order[card[1:]] # 从第2位开始取(排除花色)# 返回按牌面大小排序后的牌列表return sorted(cards, key=card_key)# 输出发牌结果,并按点数顺序展示每位玩家的手牌
print("\n=== 发牌结果 ===")
print("玩家1:", sort_cards(player1))
print("玩家2:", sort_cards(player2))
print("玩家3:", sort_cards(player3))
print("底牌:", sort_cards(bottom))
deck = [s + r for r in ranks for s in suits]
是花色在前,点数在后的生成方式,比如 ♠3, ♥3, ♣3, ♦3, ♠4, ...
如果你想让点数排在前(比如 3♠),只需调换一下顺序。
for i in range(len(deck)):
deck = ['♠3', '♥4', ..., '小王', '大王']
相对于for i in range(54): # i 依次是 0, 1, 2, ..., 53
-
i < 51:表示前 51 张是正常发给玩家的; -
i >= 51:表示最后 3 张是底牌。
然后再通过 i % 3 来轮流分给 3 个玩家。
order = {r: i for i, r in enumerate(ranks)}
这行用的是字典推导式,将点数与大小关系建立起来。
enumerate(ranks) 会返回每个点数及其位置编号:
ranks = ['3', '4', '5', ..., '2']
→ [('3', 0), ('4', 1), ..., ('2', 12)]所以构造出的字典是:
order = {'3': 0, '4': 1, '5': 2, '6': 3, '7': 4,'8': 5, '9': 6, '10': 7, 'J': 8, 'Q': 9,'K': 10, 'A': 11, '2': 12
}order.update({'小王': 13.5, '大王': 14})
这行的意思是:往 order 字典中再加两个键值对:比“2”还大,用来确保在排序时,“王”排到最上面。
def card_key(card):
if card in ['小王', '大王']:
return order[card]
return order[card[1:]]
return sorted(cards, key=card_key)
我们之前建立了一个排序规则 order,用于表示每张牌的大小关系:
order = {'3': 0, '4': 1, ..., '2': 12,'小王': 13.5, '大王': 14
}
现在你有一手牌,比如:
cards = ['♠3', '♦A', '小王', '♥10', '♣2']
def card_key(card): 定义一个排序时的“取键函数”。
在 Python 的 sorted(..., key=...) 中,我们可以自定义用什么“值”来排序 —— 这里我们自定义的函数名是 card_key。
if card in ['小王', '大王']: return order[card]
- 如果这张牌是 `'小王'` 或 `'大王'`,那就直接返回 `order` 中对应的数值(13.5 或 14)用于排序。
-
如果不是王,那就说明是正常的扑克牌,比如
'♠3'、'♥10'等。 -
card[1:]表示从索引1开始切取,也就是去掉前面的花色符号,只保留点数:
| 原始牌 | card[1:] | 排序用值 (order[card[1:]]) |
|---|---|---|
'♠3' | '3' | 0 |
'♦A' | 'A' | 11 |
'♥10' | '10' | 7 |
这样我们就可以用这些数值去比较牌的大小了。
return sorted(cards, key=card_key)
-
sorted(...)是 Python 内置的排序函数,会返回一个新的列表。 -
key=card_key指定了“按照什么规则排序”,也就是我们自定义的card_key函数。 -
这样就能确保牌是按照
order字典定义的大小顺序排列的。
为什么要用 card[1:] 而不是正则或者其他方式提取点数?
点数部分可能是 '10'、'J'、'Q',所以不能只取一个字符,要用切片取后面所有字符 → card[1:]。
编写函数完成角谷猜想
模拟和验证一个著名数学问题——角谷猜想(也叫冰雹猜想,英文叫 Hailstone conjecture 或 Collatz Conjecture)。
对于任意一个正整数 n,重复以下操作:
-
如果 n 是偶数:把 n 变成 n / 2
-
如果 n 是奇数:把 n 变成 3n + 1
重复这个过程,最终总会变成 1
def hailstone_sequence(n):steps = [n] # 记录整个序列(从 n 开始)while n != 1: # 不断重复直到 n 变成 1if n % 2 == 0:n = n // 2 # 偶数除以2else:n = n * 3 + 1 # 奇数乘3加1steps.append(n) # 每次结果加入列表return steps # 返回完整路径饮品自动售货机
def vending_machine():menu = {'1': ('可乐', 3),'2': ('绿茶', 2.5),'3': ('矿泉水', 2)}print("欢迎使用自动售货机:")for k, v in menu.items():print(f"{k}: {v[0]} - ¥{v[1]}")choice = input("请输入你要购买的饮品编号:")if choice not in menu:print("无效选择")returndrink, price = menu[choice]money = float(input(f"请投币(需要 ¥{price}):"))if money >= price:change = money - priceprint(f"你购买了 {drink},找零 ¥{change:.2f}")else:print("金额不足,交易取消")# 示例调用
vending_machine()
学生管理系统
students = []def add_student(name, age):students.append({'name': name, 'age': age})print(f"添加成功:{name}, 年龄{age}")def show_students():print("当前学生列表:")for s in students:print(f"{s['name']}({s['age']}岁)")# 示例
add_student('小明', 18)
add_student('小红', 17)
show_students()
两个数的最大公约数与最小公倍数
def gcd(a, b):while b:a, b = b, a % breturn adef lcm(a, b):return a * b // gcd(a, b)# 示例
print("最大公约数:", gcd(24, 36))
print("最小公倍数:", lcm(24, 36))登录验证(次数限制)
def login_system():attempts = 0while attempts < 5:username = input("用户名:")password = input("密码:")if username == 'admin' and password == 'admin123':print("登录成功")returnelse:attempts += 1print(f"请重新登录(还剩 {5 - attempts} 次)")print("账户已被锁定,请联系管理员解锁")login_system()
登录验证装饰器 + 系统操作函数
# 模拟登录状态
login_status = {"logged_in": False}# 登录验证装饰器
def require_login(func):def wrapper(*args, **kwargs):if not login_status["logged_in"]:username = input("用户名:")password = input("密码:")if username == "admin" and password == "admin123":login_status["logged_in"] = Trueprint("✅ 登录成功")else:print("❌ 登录失败,无法操作")returnreturn func(*args, **kwargs)return wrapper# 系统功能函数
@require_login
def add_data():print("数据添加成功")@require_login
def delete_data():print("数据删除成功")@require_login
def update_data():print("数据更新成功")# 测试
add_data() # 第一次需登录
delete_data() # 已登录,无需再输密码
什么是 @require_login?
Python 的一个语法糖,叫做:函数装饰器(Decorator)
它的作用是:在不修改原函数代码的情况下,为函数增加额外的功能。
@require_login
def add_data():
print("数据添加成功")
等价于:add_data = require_login(add_data)
也就是说,add_data 这个函数被 require_login 装饰后,变成了它返回的 wrapper 函数。
把装饰器 给函数套了个“壳子”:
@xxx 本质上就是:把当前函数交给 xxx() 来加工
def require_login(func):def wrapper(*args, **kwargs):# 做登录验证return func(*args, **kwargs) # 如果验证通过,再运行原函数return wrapper
这段代码的意思其实是:
✨“我定义了一个叫
require_login的函数工厂,它接受一个函数func,然后给它包一层登录验证功能,最后返回这个‘增强后的函数’。”✨
第一级函数:require_login(func)
这是 你定义的装饰器函数本体。它接收另一个函数作为参数——就是你想“加功能”的那个函数(比如 add_data())。
它的作用就是返回一个新函数:wrapper。
第二级函数:wrapper(*args, **kwargs)
这是你创建的“壳函数”,负责:
-
先判断登录状态
-
如果未登录就提示并要求输入用户名密码
-
如果登录成功,再执行原函数
func(...)
它就像是在你真正的
add_data()、delete_data()等函数 外面套的一层保护壳。
为什么要返回 wrapper 而不是直接运行它?
因为你希望是“以后再用的时候”才执行验证,不是定义的时候就立即执行。
@require_login
def add_data():
...
这时只是把 add_data 换成了新的 wrapper 函数(它内部包含了登录判断 + 原始 add_data),还没有真正执行它。
这段代码是典型的:
“高阶函数 + 闭包结构”
-
高阶函数:函数接收函数作为参数,或返回函数
-
闭包:
wrapper()内部访问了func,形成了“带记忆”的函数
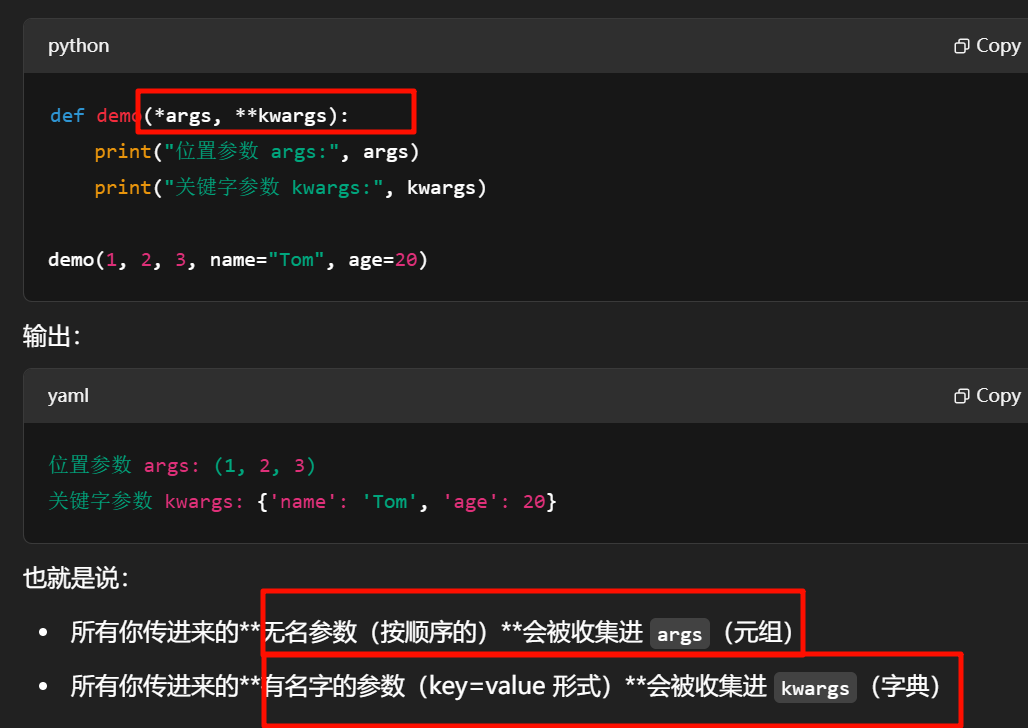
| 写法 | 意义 |
|---|---|
*args | 接收任意数量的位置参数(变成一个元组) |
**kwargs | 接收任意数量的关键字参数(变成一个字典) |
| 用法场景 | 原因 |
|---|---|
| 写装饰器 | 你不知道被包装的函数参数数量和类型 |
| 写通用函数 | 比如日志函数、统计函数,参数可变 |
| 接收动态传参 | 比如配置字典、自动调用接口 |
递归求和函数 f(n)
def f(n):if n == 1:return 1return n + f(n - 1)# 示例
print(f(10)) # 输出 55
找出所有既是回文数又是素数的 3 位数
def is_palindrome(n):return str(n) == str(n)[::-1]def is_prime(n):if n < 2:return Falsefor i in range(2, int(n**0.5) + 1):if n % i == 0:return Falsereturn Truedef find_palindromic_primes():result = []for n in range(100, 1000):if is_palindrome(n) and is_prime(n):result.append(n)return resultprint(find_palindromic_primes())
for i in range(2, int(n**0.5) + 1):if n % i == 0:return False从
2到√n(包含)逐一检查是否能整除n,如果能整除,就不是素数。
**是根号
-
在 Python 中,
**表示 幂运算(power) -
所以
n**0.5就等于n 的 0.5 次方 -
而
n 的 0.5 次方,数学上就是√n
确保从 2 检查到 3,完整覆盖了素数判断所需范围。
range(2, 3+1) → [2, 3)
range(start, end) 的含义:
| 参数 | 含义 |
|---|---|
start | 起始值(包含) |
end | 终止值(不包含) |
模拟轮盘抽奖函数
import randomdef spin_wheel():r = random.random() # 生成 [0.0, 1.0) 的浮点数if 0 <= r < 0.08:return "🎉 恭喜你抽中一等奖!"elif 0.08 <= r < 0.3:return "🎊 恭喜你抽中二等奖!"else:return "✨ 抽中三等奖,继续加油!"# 测试多次抽奖
for _ in range(5):print(spin_wheel())
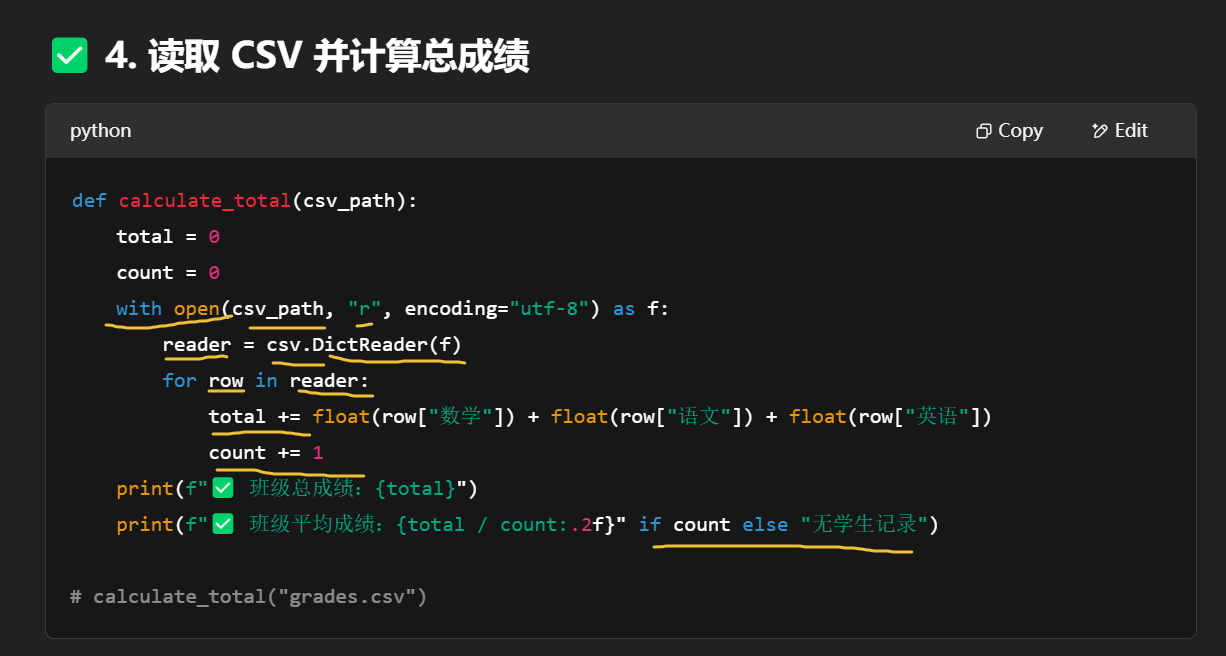
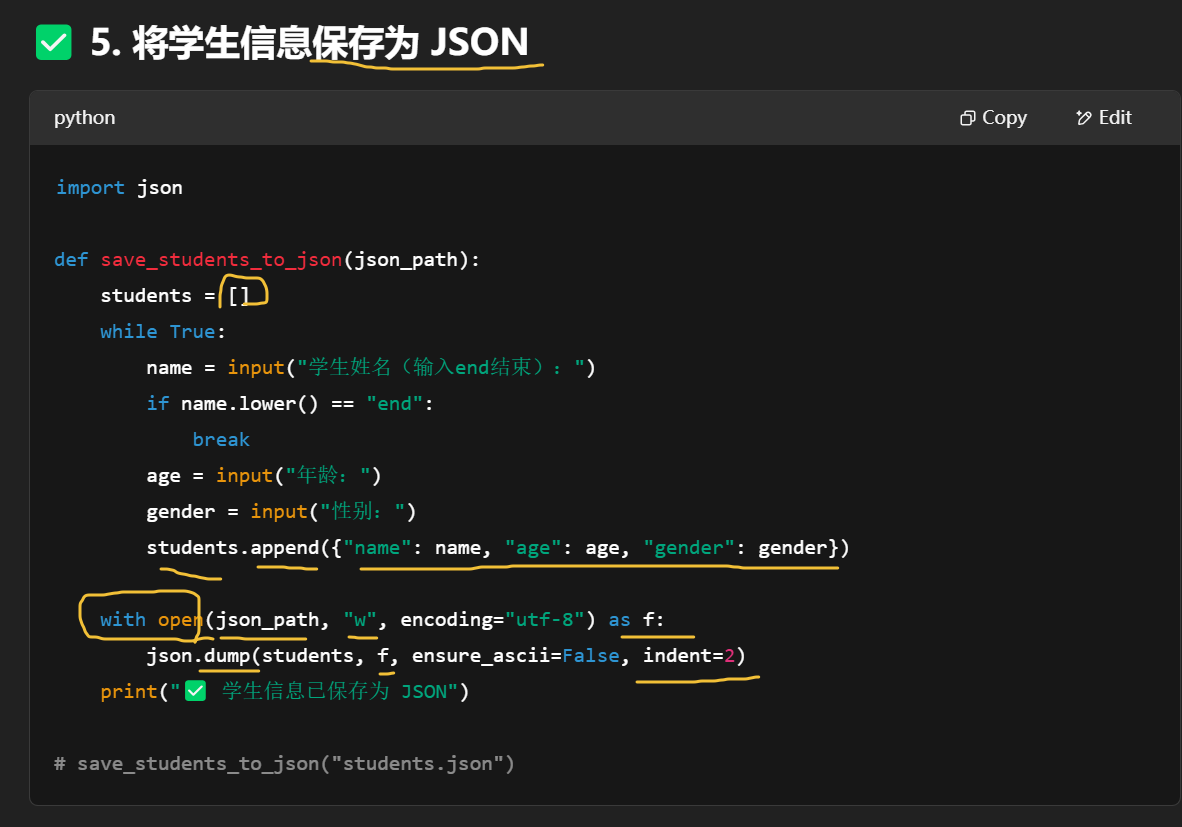
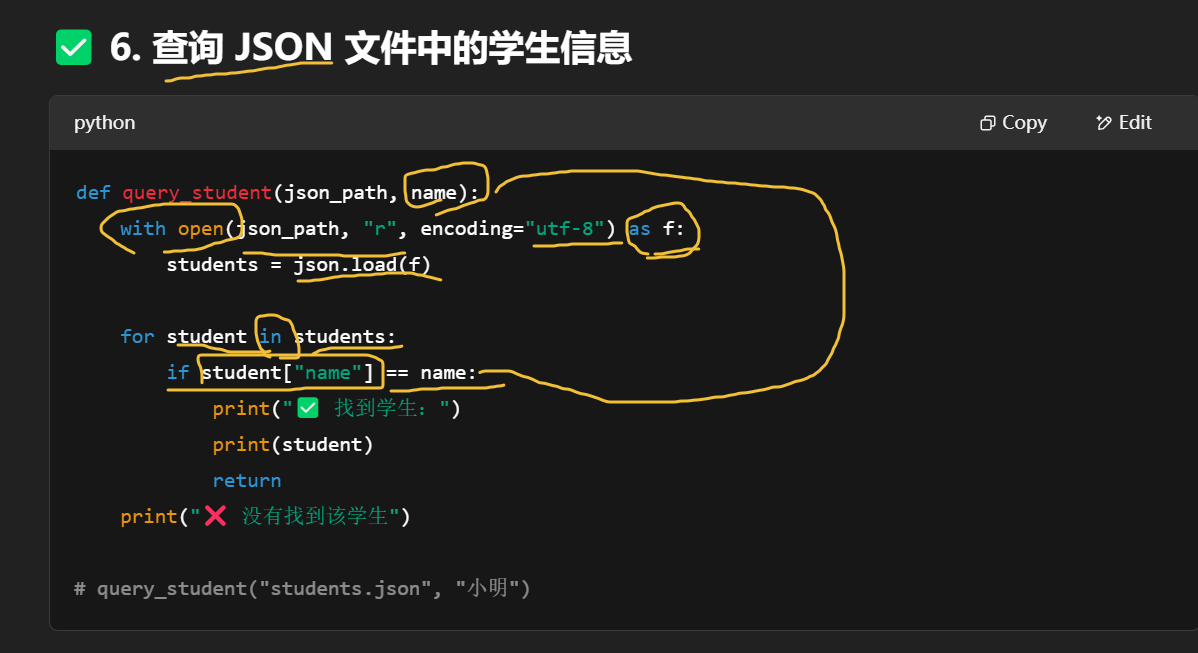
保存到你运行脚本时所在的目录下,文件名是你传入的那个 json_path。
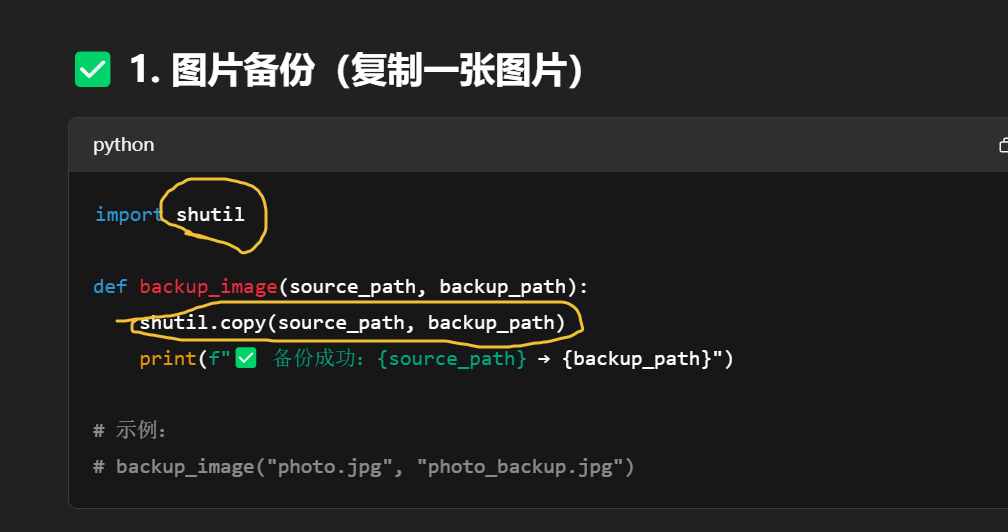
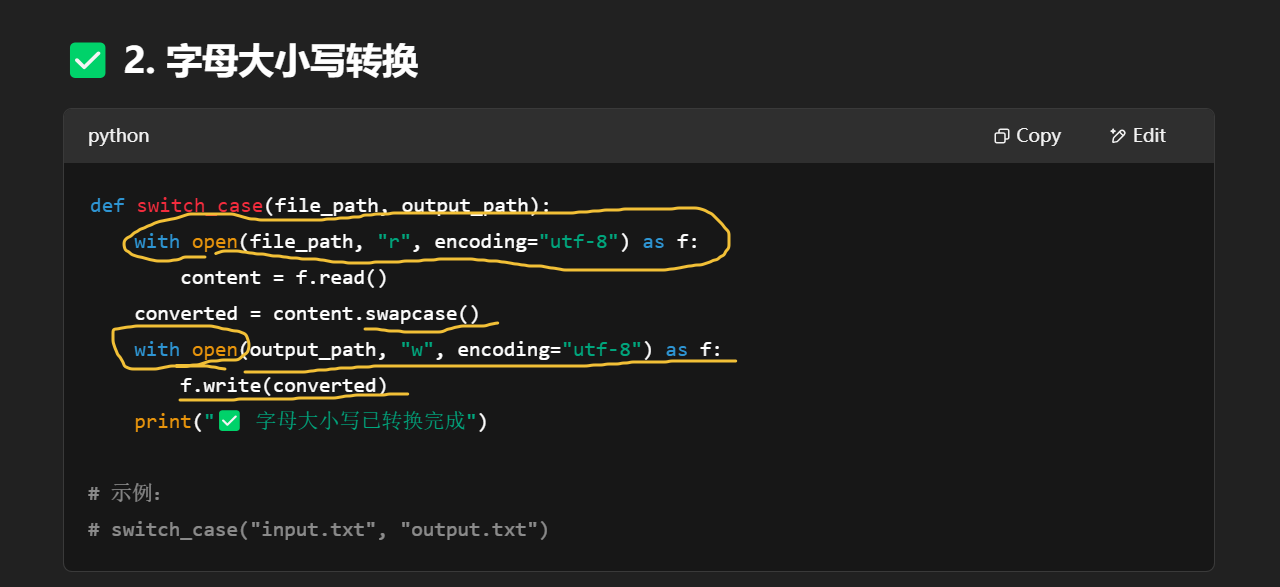
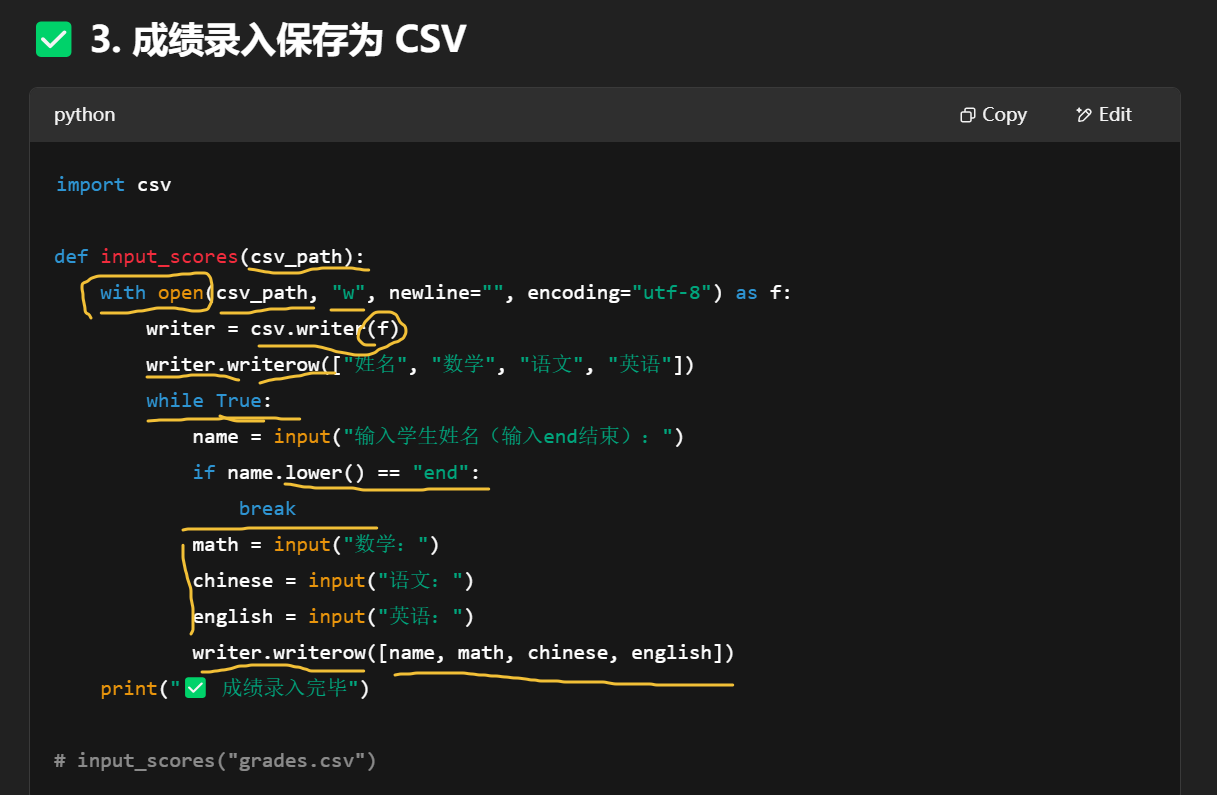
| 技能类型 | 涉及模块/函数 |
|---|---|
| 文件复制 | shutil.copy() |
| 字符操作 | .swapcase() |
| 文件读写 | open(..., "r/w") |
| CSV 写入/读取 | csv.writer / csv.DictReader |
| JSON 存取 | json.dump() / json.load() |
| 条件循环与判断 | while、if |