多模态RAG演进-MRAG1.0->MRAG2.0->MRAG3.0
MRAG1.0
MRAG1.0是MRAG框架的初始阶段,通常被称为“伪MRAG”。它是对RAG范式的简单扩展,支持多模态数据。MRAG1.0通过利用现有的基于文本的检索和生成机制,实现了从RAG到MRAG的平稳过渡。
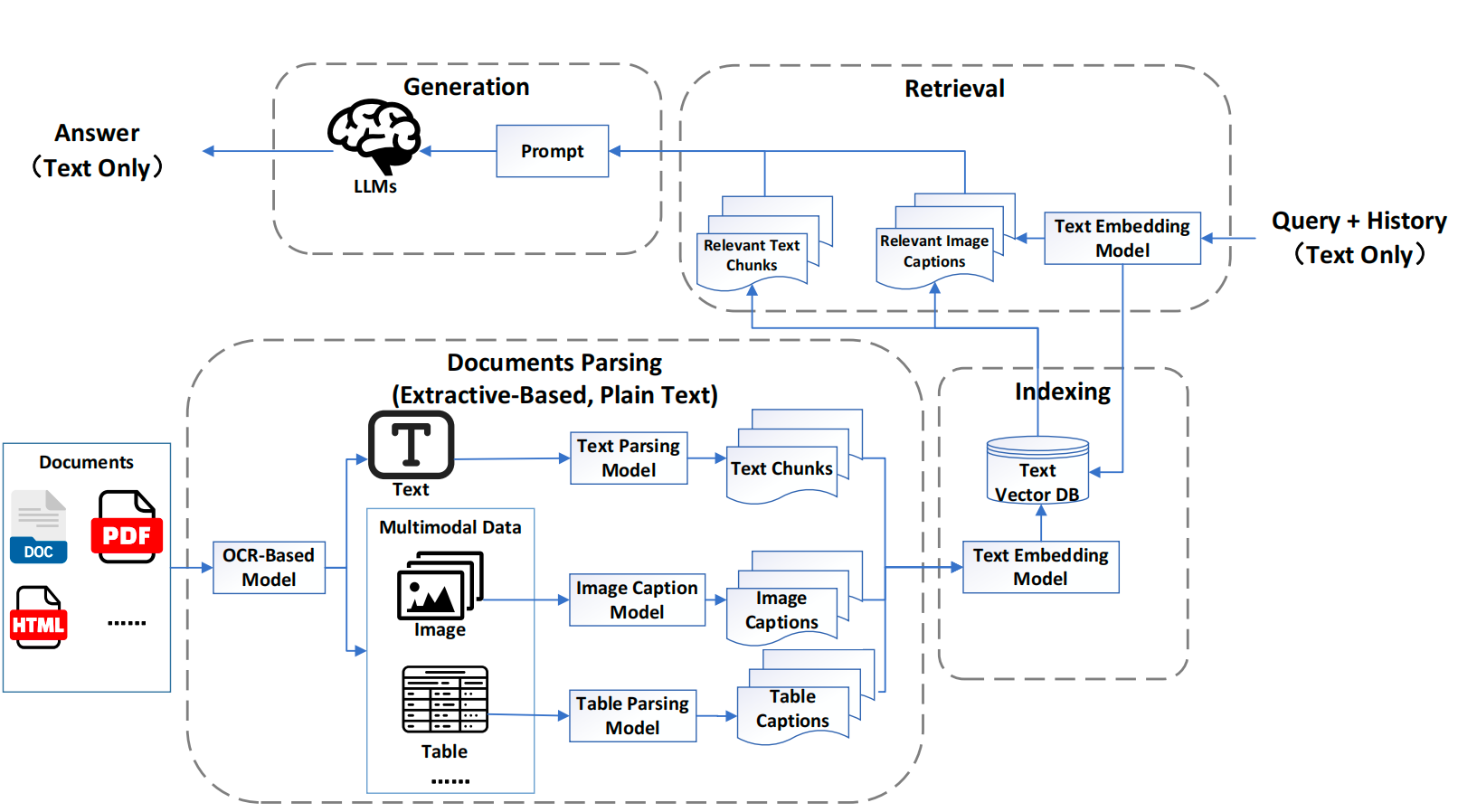
MRAG1.0的架构包括三个关键组件:
-
文档解析和索引:
-
使用《文档智能解析技术》处理多模态文档(如Word、Excel、PDF、HTML),使用OCR或特定格式的解析技术提取文本内容。
-
使用文档布局检测模型将文档分割成结构化元素(如标题、段落、图像、视频、表格、页脚)。
-
对于多模态数据,使用专门的模型生成描述图像、视频和其他非文本元素的标题。
-
索引阶段:将这些块和标题编码成向量表示,并存储在向量数据库中。
-
-
检索:
使用与索引相同的嵌入模型将用户查询编码成向量表示。如:余弦相似度、BGE等进行相似度计算从向量数据库中检索最相关的块和标题。合并重复或重叠的信息,形成外部知识的综合集合,并将其集成到生成阶段的提示中。
-
生成:
将用户查询和检索到的文档合成为一个连贯的提示。结合其参数化知识和检索到的外部信息,使用LLM生成答案。在多轮对话中,系统将对话历史记录集成到提示中,实现上下文感知和无缝交互。
局限性
-
文档解析繁琐:将多模态数据转换为文本描述增加了系统的复杂性,并导致模态特定信息的丢失。
-
检索瓶颈:文本向量检索技术虽然成熟,但在处理多模态数据时存在挑战,导致检索精度不高。
-
生成挑战:处理多模态数据和图像标题等需要有效组织这些元素,同时最小化冗余并保留相关信息。
MRAG2.0
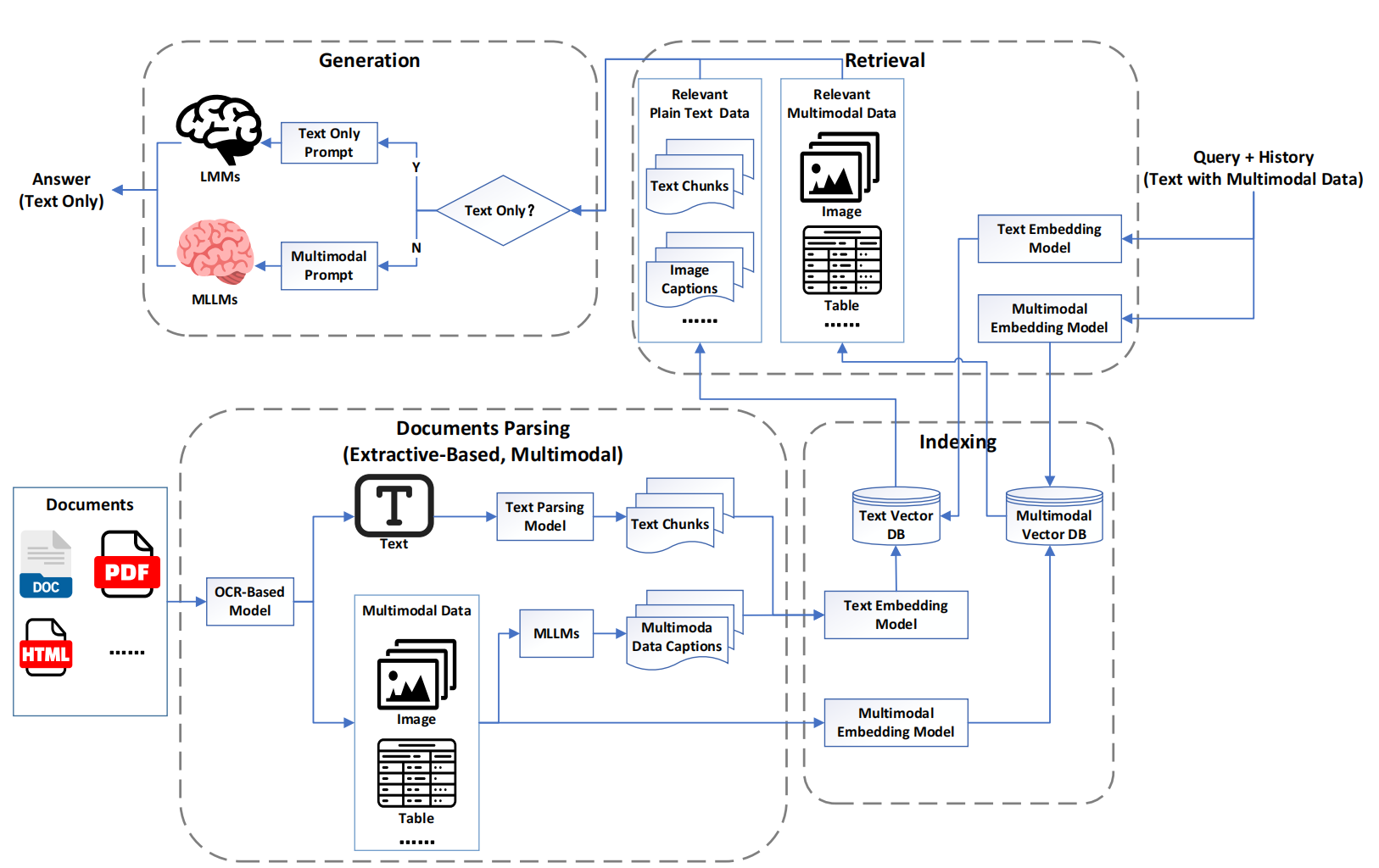
与MRAG1.0不同,MRAG2.0不仅支持多模态输入的查询,还在知识库中保留了原始的多模态数据。
MRAG2.0的架构包括几个关键的优化:
-
MLLMs Captions:
利用MLLMs的表示能力,特别是Captions任务的能力,使用单个或多个MLLM从多模态文档中提取Captions。这种方法简化了文档解析模块,减少了其复杂性。 -
多模态检索:增强检索模块以支持多模态用户输入,保留原始多模态数据并实现跨模态检索。允许基于文本的查询直接检索相关的多模态数据,结合基于字幕的召回和跨模态搜索能力。
-
多模态生成:增强生成模块以处理多模态数据,通过集成MLLMs实现用户查询和检索结果的合成。当检索结果准确且输入包含原始多模态数据时,生成模块减少了模态转换中的信息损失。
局限性
-
多模态数据输入的准确性:整合多模态数据输入可能会降低传统文本查询描述的准确性。
-
数据格式的多样性:生成模块需要高效地组织这些多样化的数据形式,并清晰地定义生成输入。
MRAG3.0
MRAG3.0是MRAG的重大演变,引入了结构和功能上的创新,增强了其在多个维度上的能力。
MRAG3.0的创新主要体现在三个方面:
-
增强的文档解析:在解析过程中保留文档页面截图,最小化数据库存储中的信息损失。使用MLLMs对文档截图进行向量化并索引,实现基于用户查询的相关文档截图的高效检索。
-
真正的端到端多模态:在知识库构建和系统输入中强调多模态能力的同时,MRAG3.0引入了多模态输出能力,完成了端到端的多模态框架。
-
场景扩展:超越传统的理解能力,MRAG3.0通过模块调整和添加,将理解和生成能力结合起来。这种统一显著拓宽了系统的适用性,涵盖了视觉问答(VQA)、多模态生成和融合多模态输出等场景。
MRAG3.0支持多种场景:
- 检索增强场景:通过从外部知识库中检索相关内容来提供准确的答案。
- VQA场景:通过动态路由和检索来最小化不必要的搜索和不相关信息。
- 多模态生成场景:扩展生成任务的能力,通过检索增强(RA)显著提高生成任务的性能。
- 融合多模态输出场景:生成包含多种模态的输出,如文本、图像或视频。
修改模块
-
文档解析和索引模块:使用MLLMs对文档截图进行向量化并索引,确保高效检索相关文档截图。通过保留文档截图,解决了信息损失问题,并提高了知识库的可靠性。
-
生成:集成理解和生成能力,通过多模态输出增强子模块实现从文本到多模态输出的转变。包括原生MLLM-based输出和增强多模态输出两种方法。
新模块
多模态搜索规划:解决MRAG系统中的关键决策挑战,包括检索分类和查询重构。检索分类确定最优的检索策略,查询重构通过整合视觉信息和历史检索结果来优化查询。
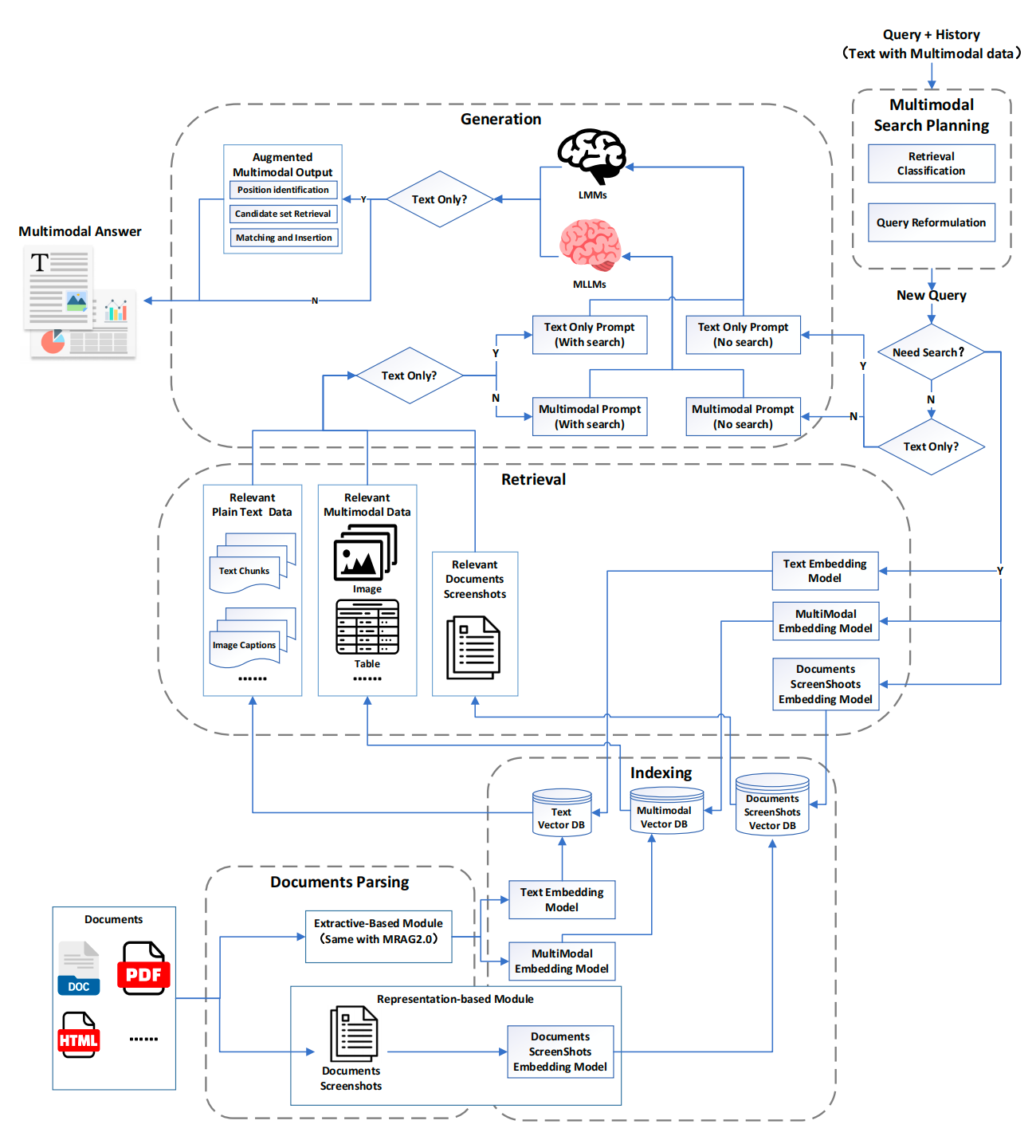
前面两个阶段的流程前期内容都有相关介绍,下面来详细看下MRAG3.0的整体过程,也就是这张架构图。
1. 文档解析(Documents Parsing)
- 输入:系统接受多种类型的文档(如PDF、HTML等)。
- 处理:
- Extractive-Based Module (Same with MRA2.0):使用提取模块(可能是基于MRA2.0的模型)将文档解析为纯文本数据(Plain Text Data)和多模态数据(Multimodal Data)。
- 纯文本数据:包括文本块(Text Chunks)。
- 多模态数据:包括图像(Image)、表格(Table)、屏幕截图(Screenshots)等。
- 图像处理:图像会生成对应的描述(Image Captions)。
- 输出:解析后的数据分为纯文本和多模态数据,准备进入索引阶段。
2. 索引(Indexing)
- 目的:将解析后的数据存储到数据库中,以便后续检索。
- 处理:
- 文本嵌入(Text Embedding Model):将纯文本数据嵌入为向量,存储到文本向量数据库(Text Vector DB)。
- 多模态嵌入(Multimodal Embedding Model):将多模态数据(包括图像、表格等)嵌入为向量,存储到多模态向量数据库(Multimodal Vector DB)。
- 屏幕截图嵌入(Documents/Screenshots Embedding Model):单独处理文档和屏幕截图,嵌入后存储到屏幕截图向量数据库(Documents/Screenshots Vector DB)。
- 输出:三个向量数据库(Text Vector DB、Multimodal Vector DB、Documents/Screenshots Vector DB)存储了嵌入后的数据。
3. 多模态检索规划(Multimodal Search Planning)
- 输入:用户查询(Query)及其历史数据(History)。
- 处理:
- 检索分类(Retrieval Classification):判断查询是否需要检索外部数据。
- 如果不需要(No),直接生成多模态提示(Multimodal Prompt,No search)。
- 如果需要(Yes),进一步判断是否为纯文本查询(Text Only?)。
- 纯文本查询(Yes):生成纯文本提示(Text Only Prompt)。
- 如果需要检索(With search),生成带检索的纯文本提示(Text Only Prompt, With search)。
- 如果不需要检索(No search),生成不带检索的纯文本提示(Text Only Prompt, No search)。
- 非纯文本查询(No):生成多模态提示(Multimodal Prompt, With search)。
- 纯文本查询(Yes):生成纯文本提示(Text Only Prompt)。
- 查询重构(Query Reformation):根据需要重构查询,生成新的查询(New Query)。
- 检索分类(Retrieval Classification):判断查询是否需要检索外部数据。
- 输出:生成适合检索的提示(Prompt)或重构后的新查询。
4. 检索(Retrieval)
- 输入:多模态提示(Multimodal Prompt)或纯文本提示(Text Only Prompt)。
- 处理:
- 根据提示类型,从对应的向量数据库中检索相关数据:
- 纯文本提示:从Text Vector DB中检索。
- 多模态提示:从Multimodal Vector DB和Documents/Screenshots Vector DB中检索。
- 检索结果包括:
- Position Identification:确定相关数据的位置。
- Candidate Set Retrieval:获取候选数据集合。
- Matching and Insertion:将检索到的数据与查询匹配并插入。
- 根据提示类型,从对应的向量数据库中检索相关数据:
- 输出:增强的多模态输出(Augmented Multimodal Output),包含检索到的相关数据。
5. 生成(Generation)
- 输入:增强的多模态输出。
- 处理:
- 判断是否为纯文本查询(Text Only?):
- 如果是(Yes),直接交给大语言模型(LLMs)生成纯文本回答。
- 如果不是(No),交给多模态大语言模型(MLLMs)生成多模态回答。
- 判断是否为纯文本查询(Text Only?):
- 输出:最终的多模态回答(Multimodal Answer),可能包含文本、图像、表格等。
6. 输出(Multimodal Answer)
- 形式:生成的回答可能是纯文本,也可能是多模态内容(例如文本+图像+表格)。
- 示例:图中展示了一个包含文本、图像和图表的回答。
参考文献:A Survey on Multimodal Retrieval-Augmented Generation,https://arxiv.org/pdf/2504.08748