MySQL基础关键_005_DQL(四)
目 录
一、分组函数
1.说明
2.max/min
3.sum/avg/count
二、分组查询
1.说明
2.实例
(1)查询岗位和平均薪资
(2)查询每个部门编号的不同岗位的最低薪资
3.having
(1)说明
(2)查询除部门编号为 20,其余部门的平均薪资。
(3)计算每个部门平均薪资,查询平均薪资 2000 以上的部门
4.组内排序
(1)利用 substring_index 截取字串
(2)利用 group_concat 拼接字符串
(3)查询每个职位薪资最高的两个员工
三、单表 DQL 执行次序总结
四、连接查询
1.说明
2.笛卡尔积
3.内连接
(1)等值连接
(2)非等值连接
(3)自连接
4.外连接
(1)左外连接(左连接)
(2)右外连接 (右连接)
5.全连接
6.多表连接查询
一、分组函数
1.说明
- 执行原则:先分组,然后对每一组执行分组函数。若没有 group by 分组语句,整张表数据自成一组;
- 分组函数也称多行处理函数,因为有多个输入,一个输出;
- 分组函数自动忽略 null;
- 因为执行次序,from --> where --> group by --> select --> order by。所以分组函数不能用于 where 之后;
- 以下分组函数可以组合使用。
2.max/min
查询员工的最高薪资和最低薪资。
# 最高薪资
select max(salary) from employees;# 最低薪资
select min(salary) from employees;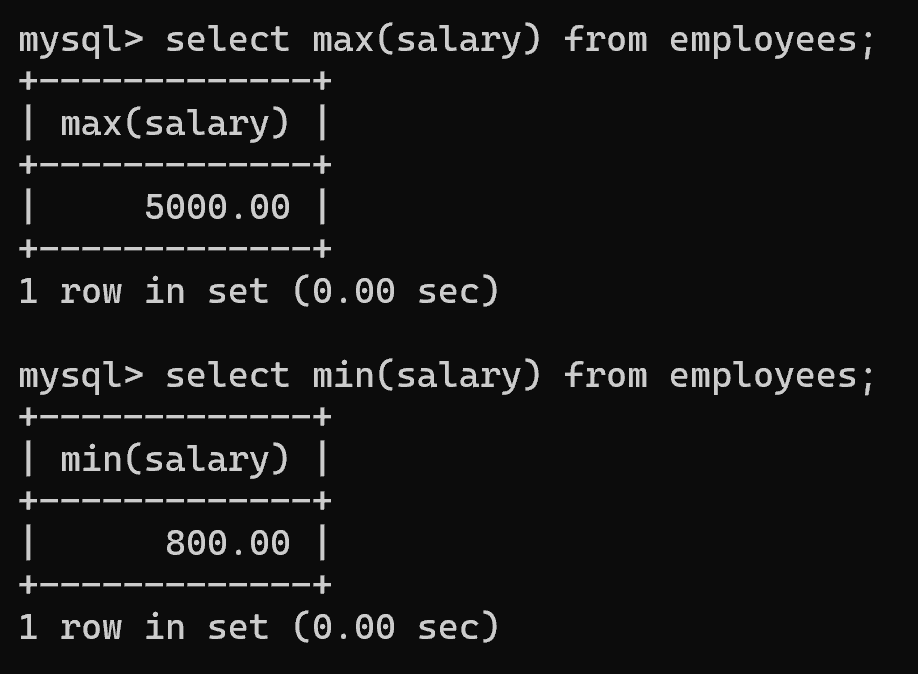
3.sum/avg/count
- 查询全体员工的总薪资、平均薪资;
- 查询总员工数、有津贴的员工数。
# 总薪资
select sum(salary) from employees;# 平均薪资
select avg(salary) from employees;# 总员工数
select count(emp_no) from employees;# 有津贴的员工数
select count(commission) from employees;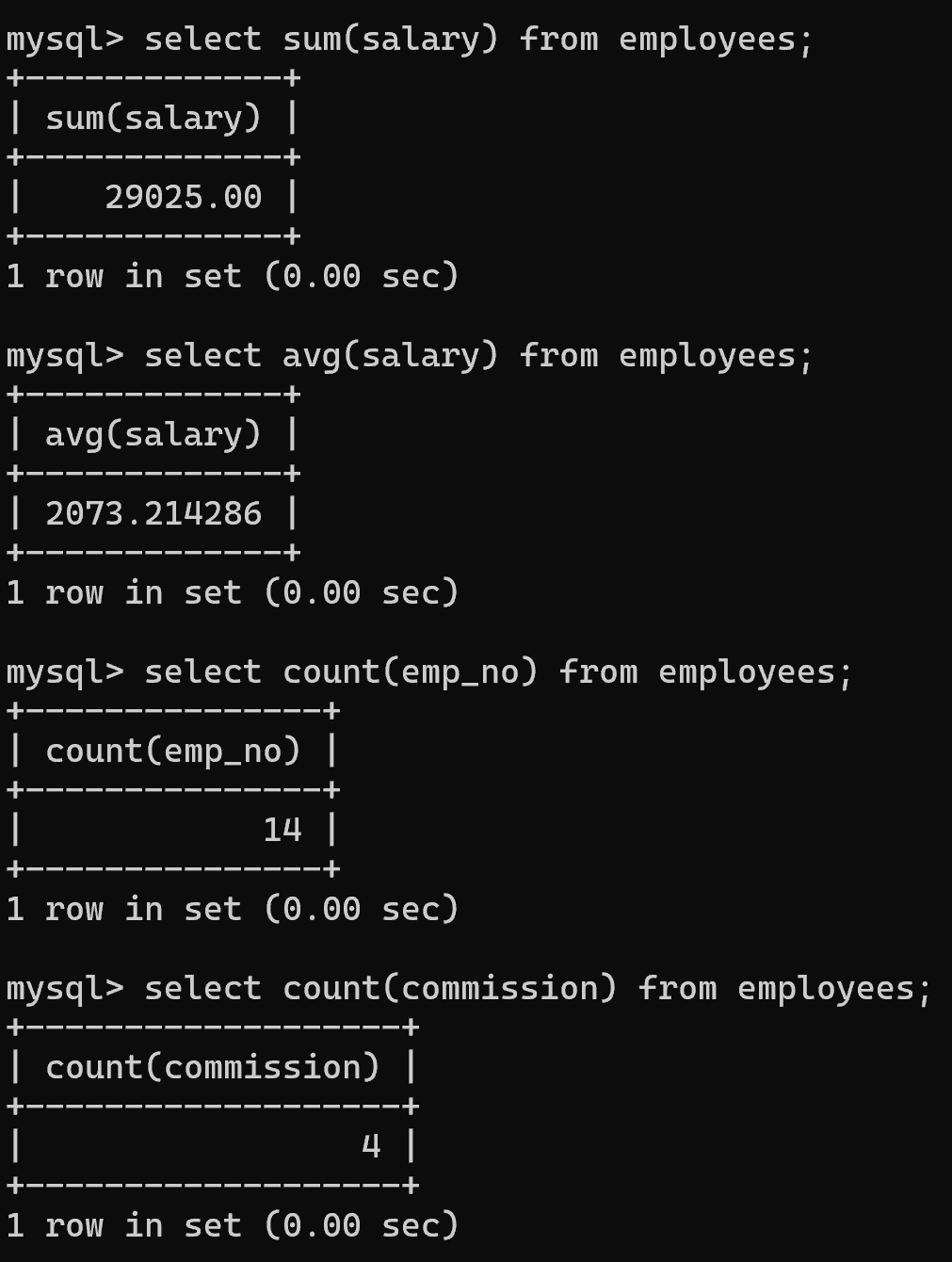
- count(*) 和 count(1) 都是统计该组中总记录行数,效果一致;
- count(字段) 统计的是该字段中不为 null 的总个数。
二、分组查询
1.说明
- 语法格式:【group by 字段1, 字段2, 字段3……】;
- group by 的执行次序是在 where 之后;
- 当 select 语句中存在 group by,则 select 后只能有 参加分组的字段 或 分组函数。
2.实例
(1)查询岗位和平均薪资
select job_title, avg(salary) from employees group by job_title;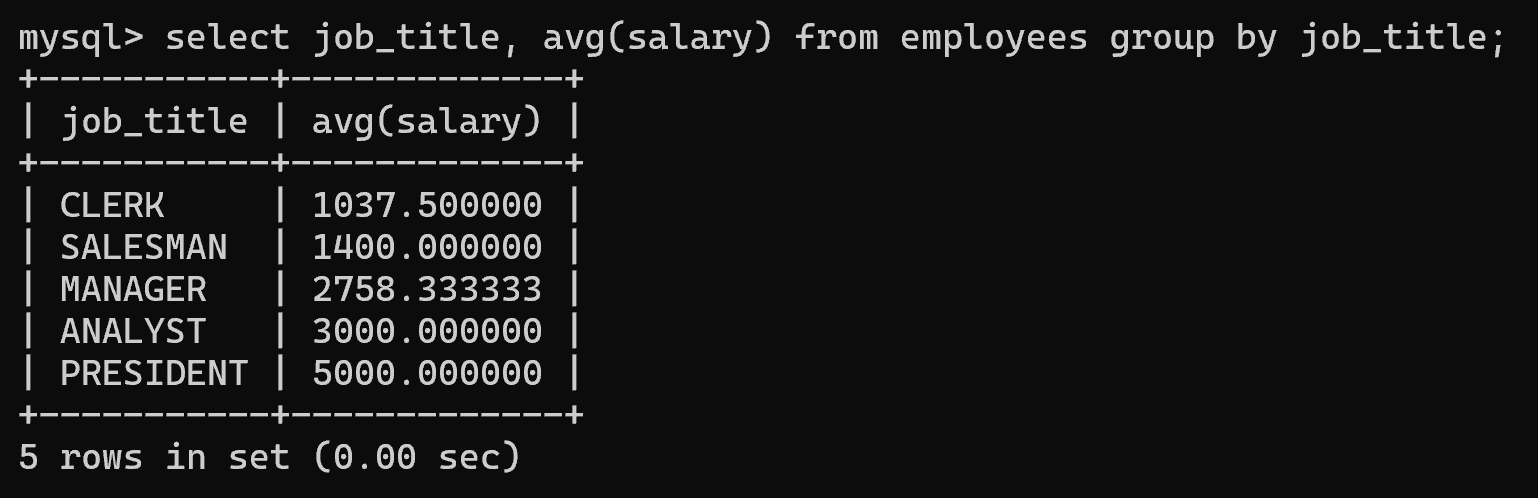
(2)查询每个部门编号的不同岗位的最低薪资
select dept_no, job_title, min(salary) from employees group by dept_no, job_title;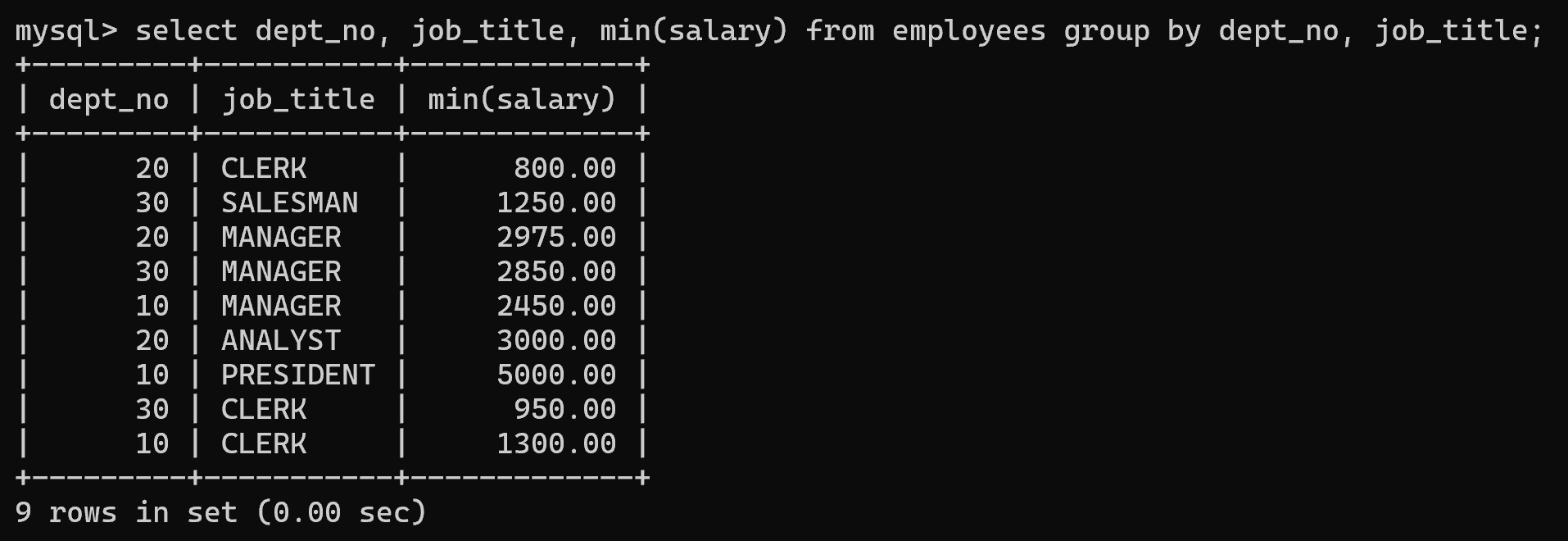
3.having
(1)说明
- having 在 group by 之后,可以对分组之后的数据进行过滤;
- 只有存在 group by,才能使用 having;
- 区别 where 过滤:where 是在分组之前过滤;
- 尽量使用 where 过滤,也就是越早过滤越好。
(2)查询除部门编号为 20,其余部门的平均薪资。
# having
select dept_no, avg(salary) from employees group by dept_no having dept_no != 20;# where(效率高,尽量使用)
select dept_no, avg(salary) from employees where dept_no != 20 group by dept_no;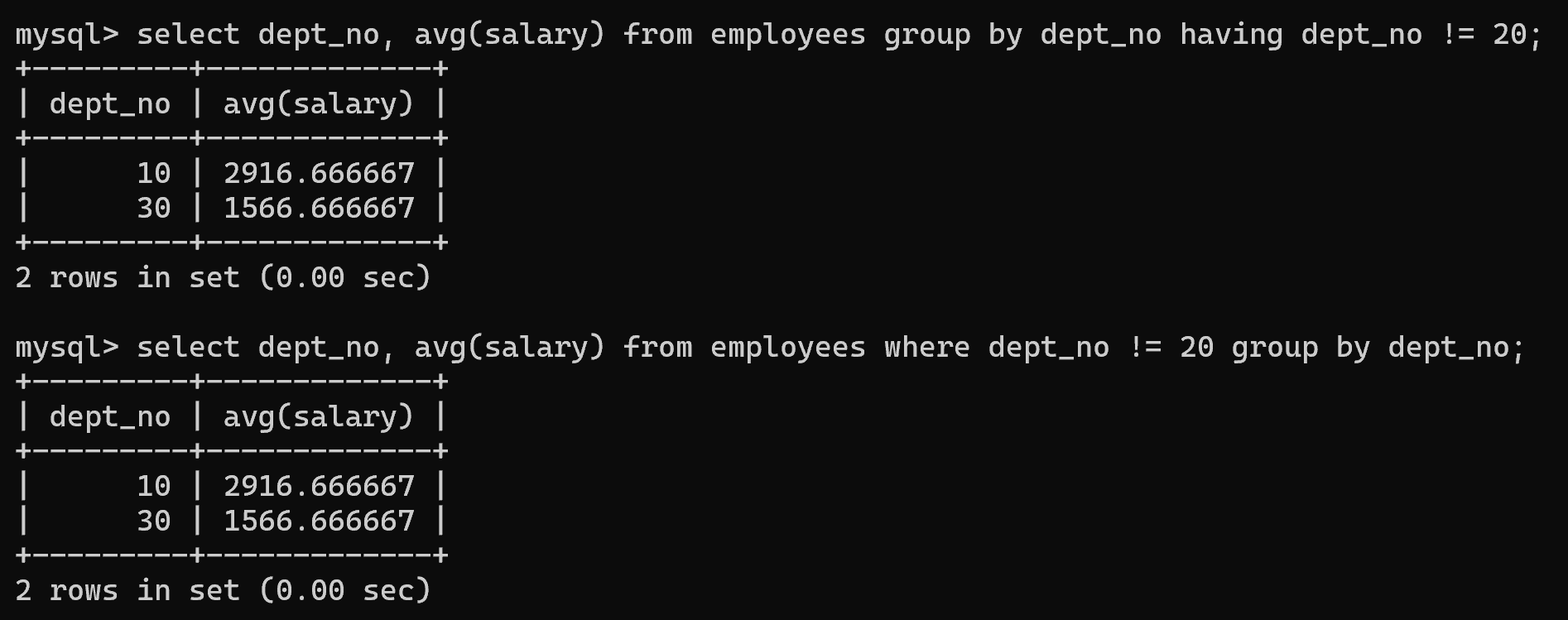
(3)计算每个部门平均薪资,查询平均薪资 2000 以上的部门
select dept_no, avg(salary) from employees group by dept_no having avg(salary) > 2000;
4.组内排序
(1)利用 substring_index 截取字串
select substring_index('I Miss You! I Miss You! I Miss You!', '!', 1);
-- 截取到第一次出现“!”的位置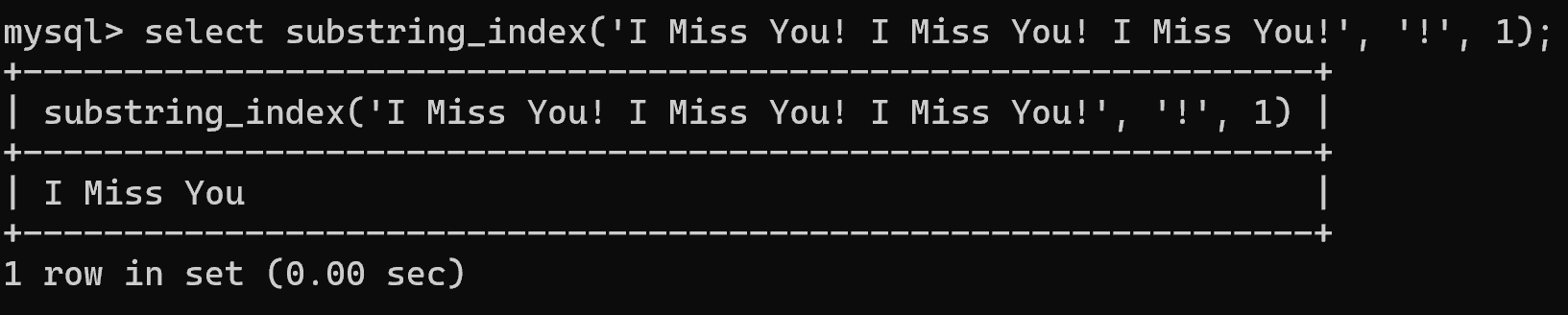
(2)利用 group_concat 拼接字符串
select group_concat('I ', 'Love ', 'You!');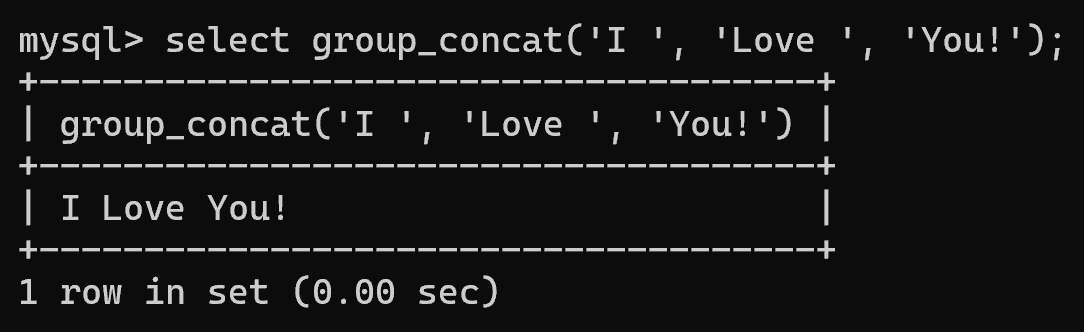
(3)查询每个职位薪资最高的两个员工
select substring_index(group_concat(emp_name, salary order by salary desc), ',', 2) from employees group by job_title; 
三、单表 DQL 执行次序总结
- from;
- where;
- group by;
- having;
- select;
- order by。
四、连接查询
1.说明
- 从一张表中查数据称为单表查询。从两张以上的表查数据称为多表查询、连接查询;
- 分类:
- 语法出现时间:
- SQL 92(较少使用);
- SQL 99。
- 连接方式:
- 内连接:
- 等值连接;
- 非等值连接;
- 自连接。
- 外连接:
- 左外连接;
- 右外连接。
- 全连接(MySQL 不支持)。
2.笛卡尔积
- 当两张表进行连接查询时,若没有任何条件进行过滤,最终的查询结果是两张表数据条数的乘积,这就是笛卡尔积;
- 为了避免笛卡尔积现象的发生,就需要添加条件进行过滤;
- 但是,添加条件进行过滤后,匹配的次数并没有减少;
- 为提高执行效率和语句的可读性,建议为表起别名。
3.内连接
查询两张表中满足条件的记录,即 求两张表的交集。
(1)等值连接
- 连接时,条件为等量关系;
- 实例: 查询所有员工所在的部门、职位。
select e.emp_name, e.job_title, d.dept_name from employees e inner join departments d on e.dept_no = d.dept_no;-- inner 可以省略不写
select e.emp_name, e.job_title, d.dept_name from employees e join departments d on e.dept_no = d.dept_no;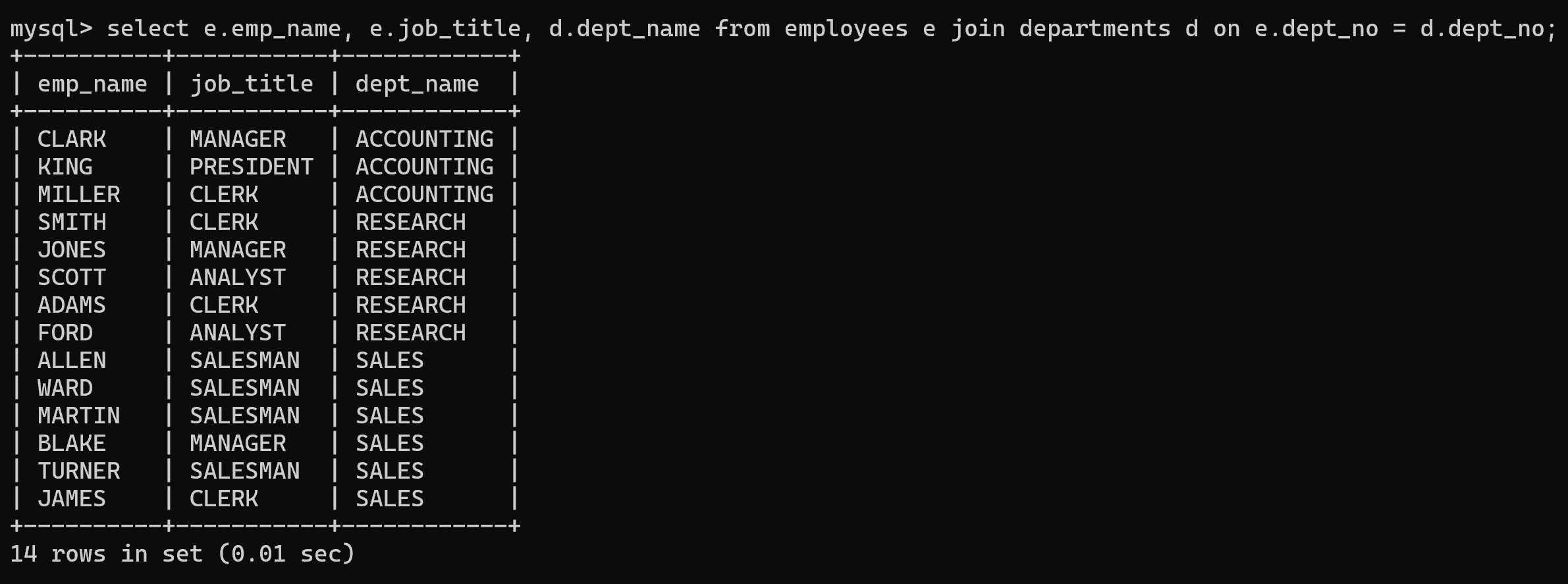
(2)非等值连接
- 连接时,条件是非等量关系;
- 实例:查询每个员工的姓名、薪资、薪资等级。
select e.emp_name, e.salary, s.grade from employees e join salary_grades s on e.salary between s.min_salary and s.max_salary;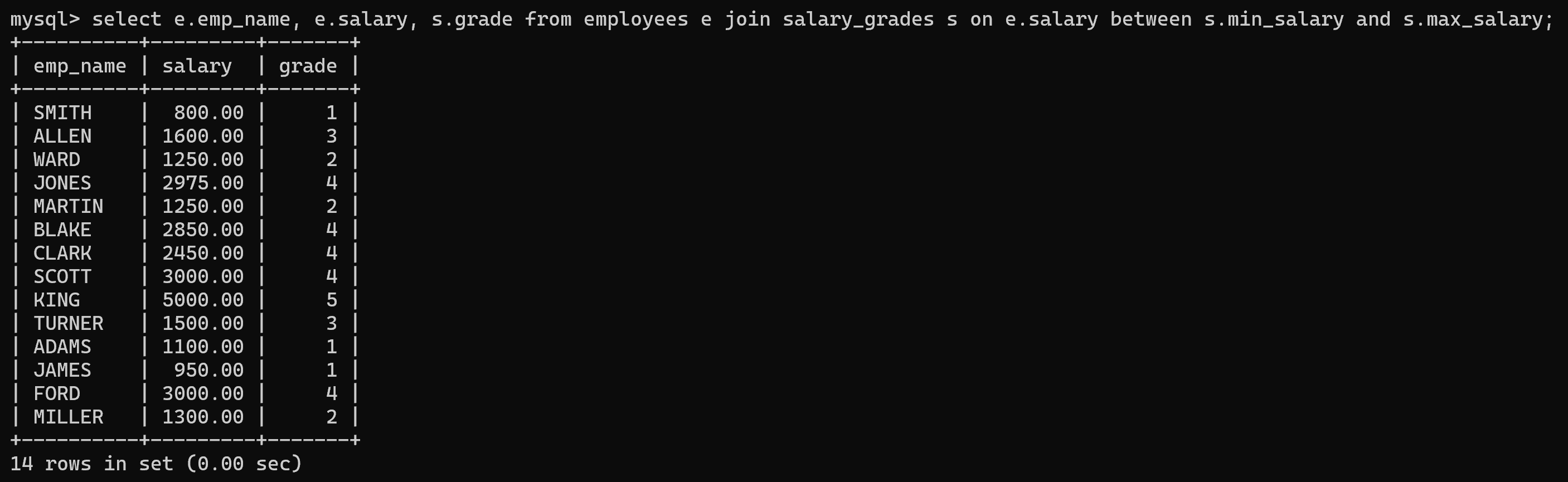
(3)自连接
- 连接时,一张表看作是两张表,自己和自己连接;
- 实例: 查询每个员工的姓名、直属领导姓名。
select ee.emp_name as employee_name, er.emp_name as employer_name from employees ee join employees er on ee.manager_id = er.emp_no;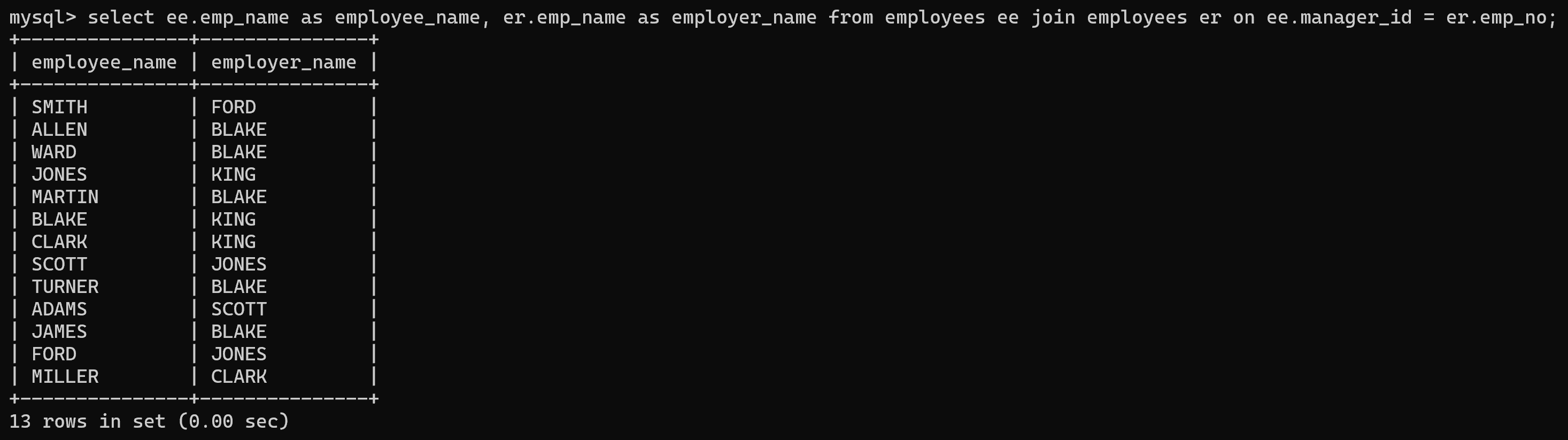
4.外连接
- 内连接是满足条件的记录,两张表的交集;
- 外连接是除了查询出满足条件的记录,再将其中的一张表的记录全部查询出来,若另一张表没有与之匹配的记录,则自动模拟 null 与之匹配;
- 任何一个左连接都可以写成右连接,反之亦然。
(1)左外连接(左连接)
查询所有部门信息,并找出每个部门下的员工。
select d.*, e.emp_name from departments d left outer join employees e on d.dept_no = e.dept_no;-- outer 可以省略不写
select d.*, e.emp_name from departments d left join employees e on d.dept_no = e.dept_no;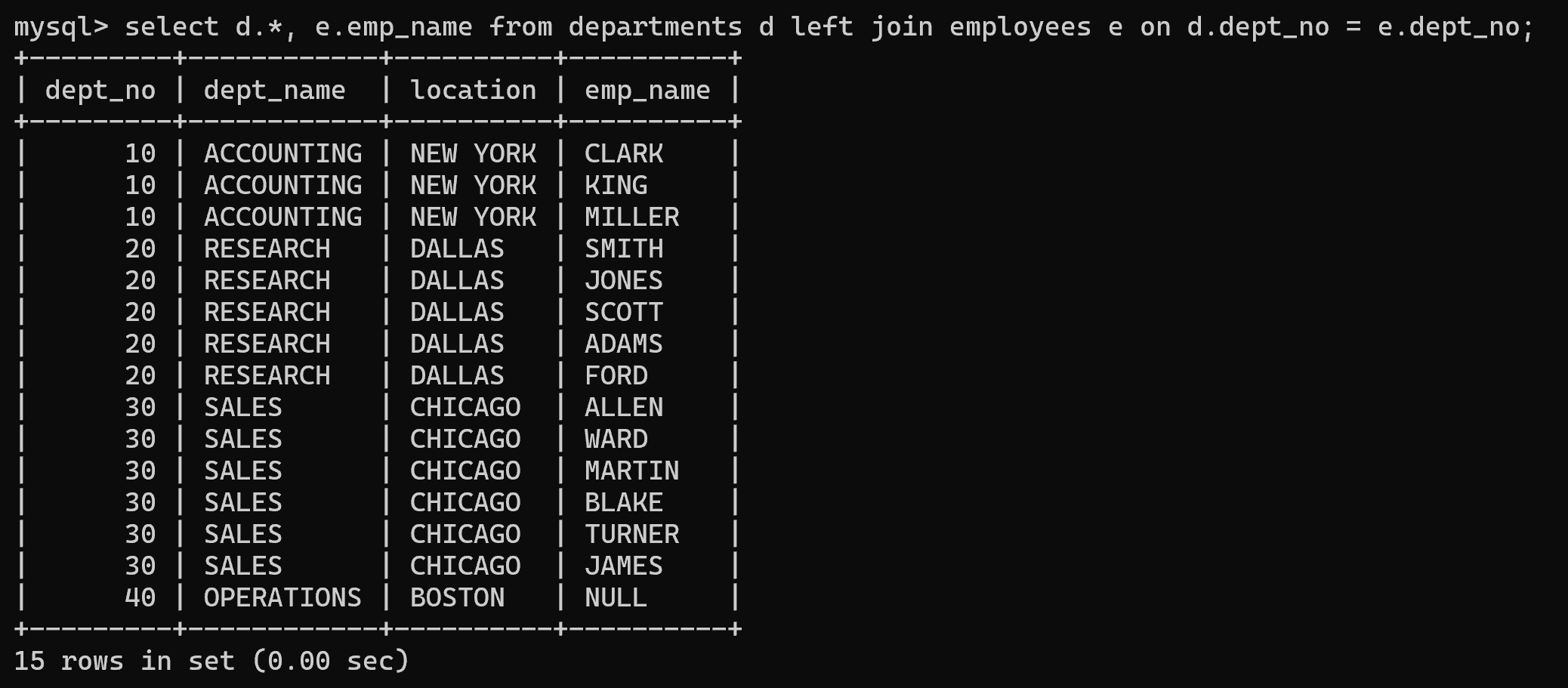
(2)右外连接 (右连接)
查询所有员工以及该员工的直属领导。
select ee.emp_name employee_name, er.emp_name employer_name from employees er right join employees ee on ee.manager_id = er.emp_no;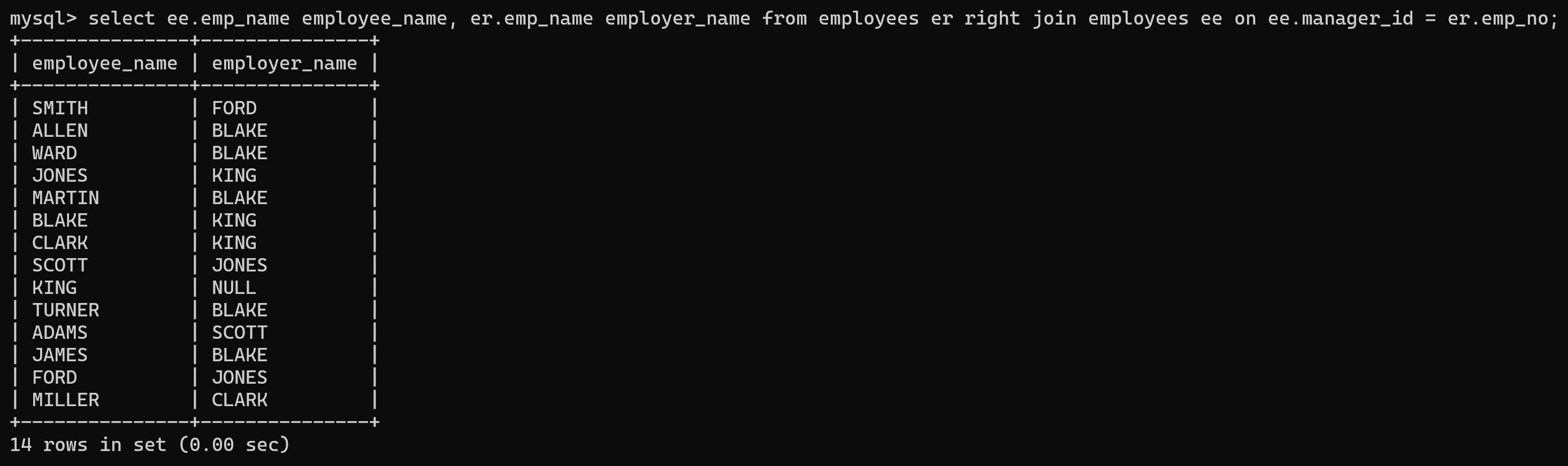
5.全连接
- 将两张表数据全部查询出来,没有匹配记录则各自为对方模拟 null 进行匹配;
- MySQL 不支持,Oracle 支持。
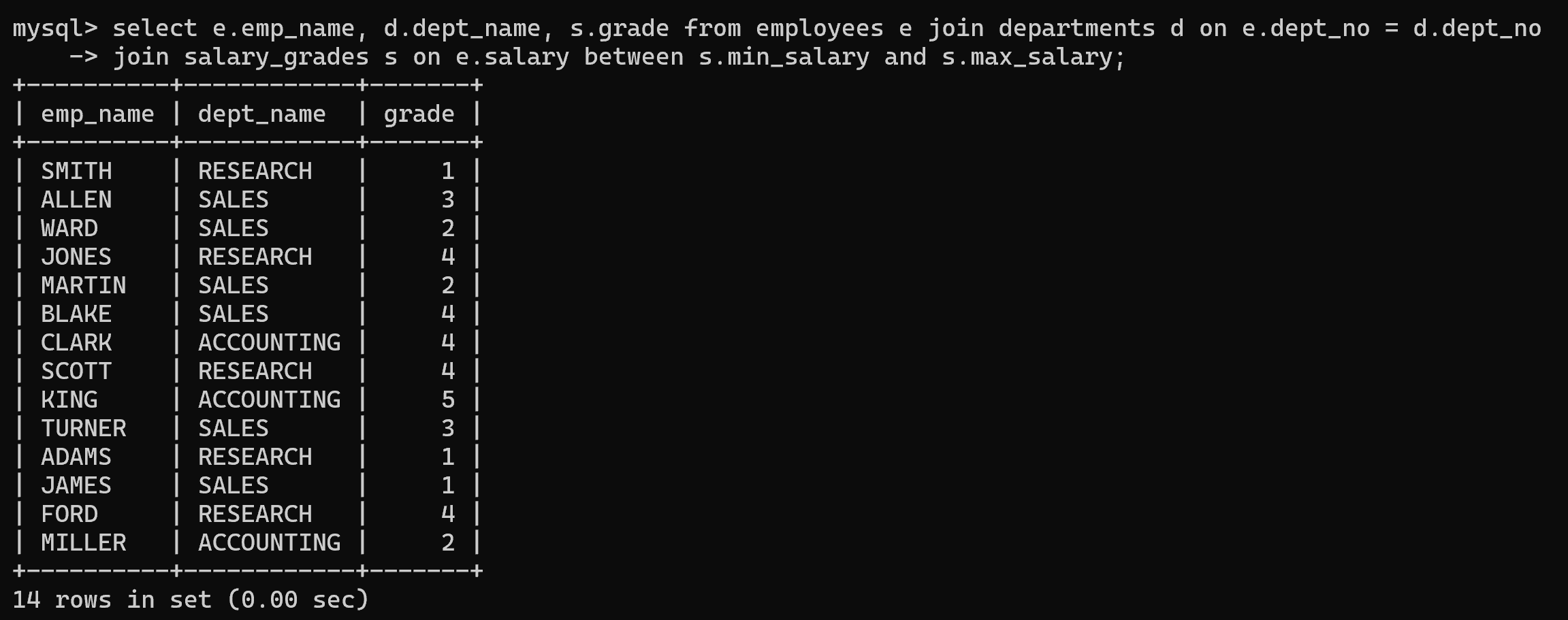
6.多表连接查询
查询员工姓名、部门名称、薪资等级。
select e.emp_name, d.dept_name, s.grade from employees e join departments d on e.dept_no = d.dept_no join salary_grades s on e.salary between s.min_salary and s.max_salary;