【dify—10】工作流实战——文生图工具
目录
一、创建工作流 应用
二、安装硅基流动
三、配置硅基流动
四、API测试
(1)进入API文档
(2)复制curl代码
(3)Postman测试API
五、 建立文生图工作流
(1)建立http请求
(2)配置http请求信息编辑
(3)提示词prompt自定义
(4)添加结束回复节点
(5)测试运行
编辑 (6)调整json格式
(7)运行成功编辑
(8)查看图片
六、提取json中url数据
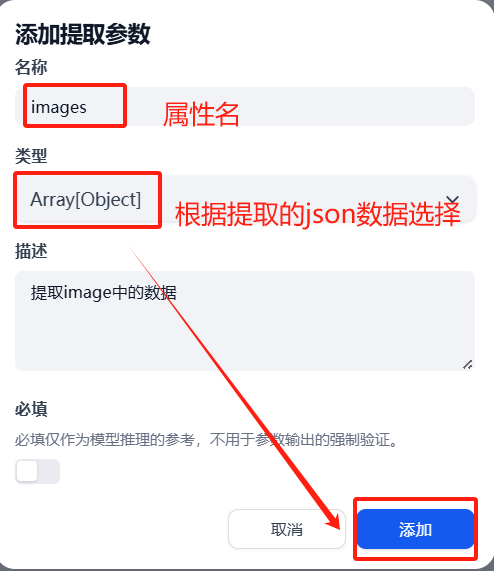
(1)添加参数提取器
(2)配置信息编辑
(3)运行测试
编辑
(4)添加代码执行
(5)输出参数
(6)运行
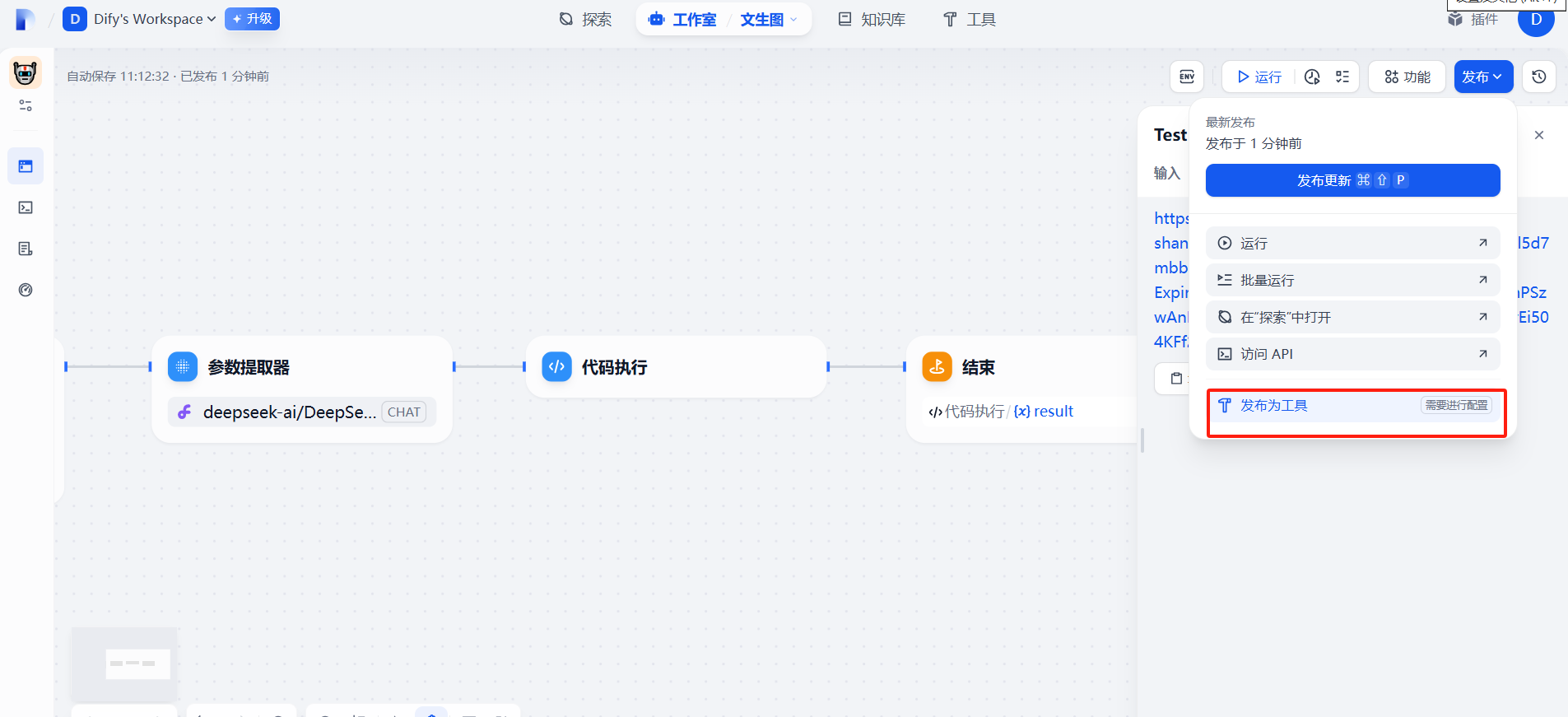
七、发布为工具

第一部分:【dify+docker安装教程】-CSDN博客
第二部分:【dify—2】docker重装-CSDN博客
第三部分:【dify—3】拉取镜像、本地访问dify-CSDN博客
第四部分:【dify—4】安装Ollama,部署Deepseek-R1模型-CSDN博客
第五部分:【dify—5】Dify关联Ollama-CSDN博客
第六部分:【dify—6】聊天模型应用实践-CSDN博客
第七部分:【dify—7】文本生成应用实战——学员周报生成-CSDN博客
第八部分:【dify—8】Agent实战——占星师-CSDN博客
第九部分:【dify—9】Chatflow实战——博客文章生成器-CSDN博客
本文主要介绍了通过创建工作流 完成了一个文生图的简单流程。讲解了从配置硅基流动,Postman测试API,代码执行提取url地址到实现发布的全流程。
一、创建工作流应用
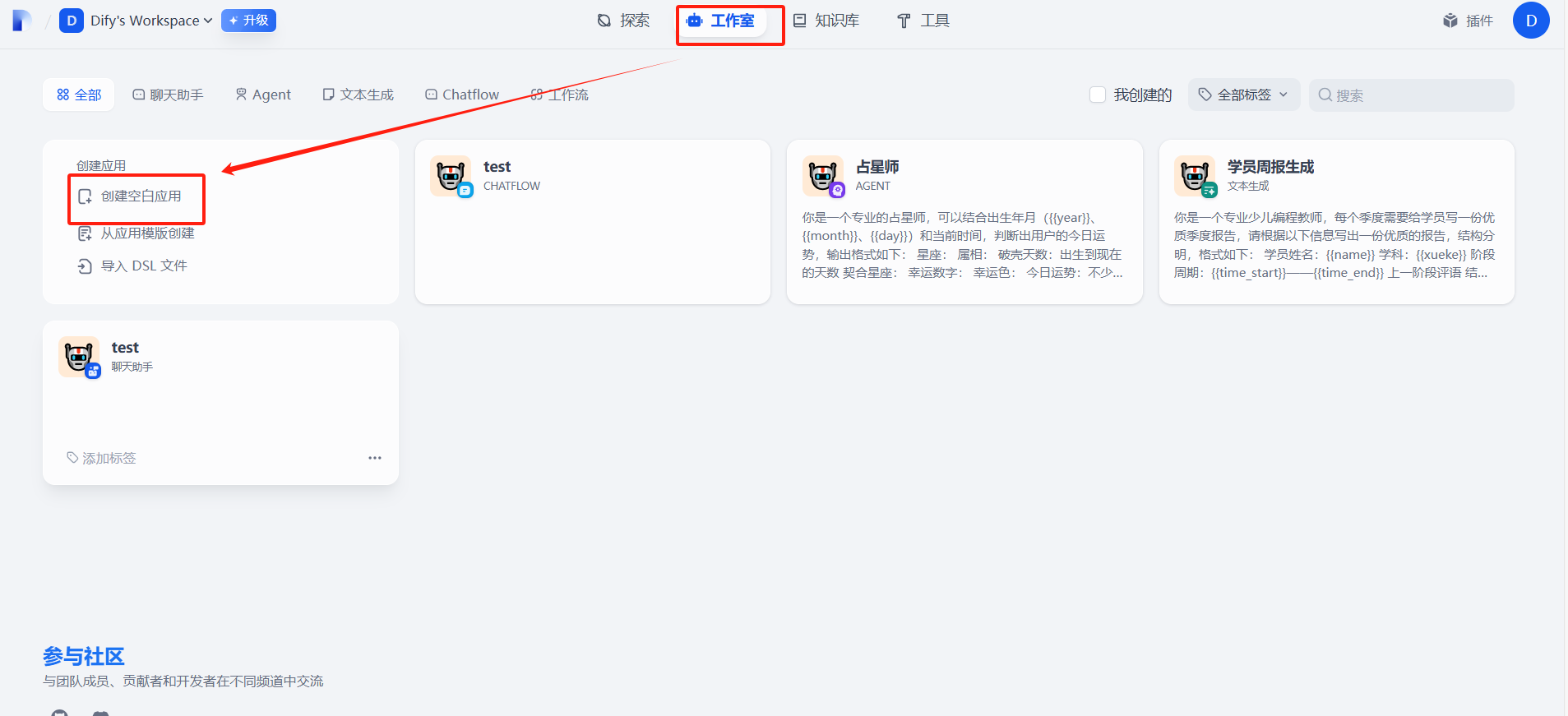
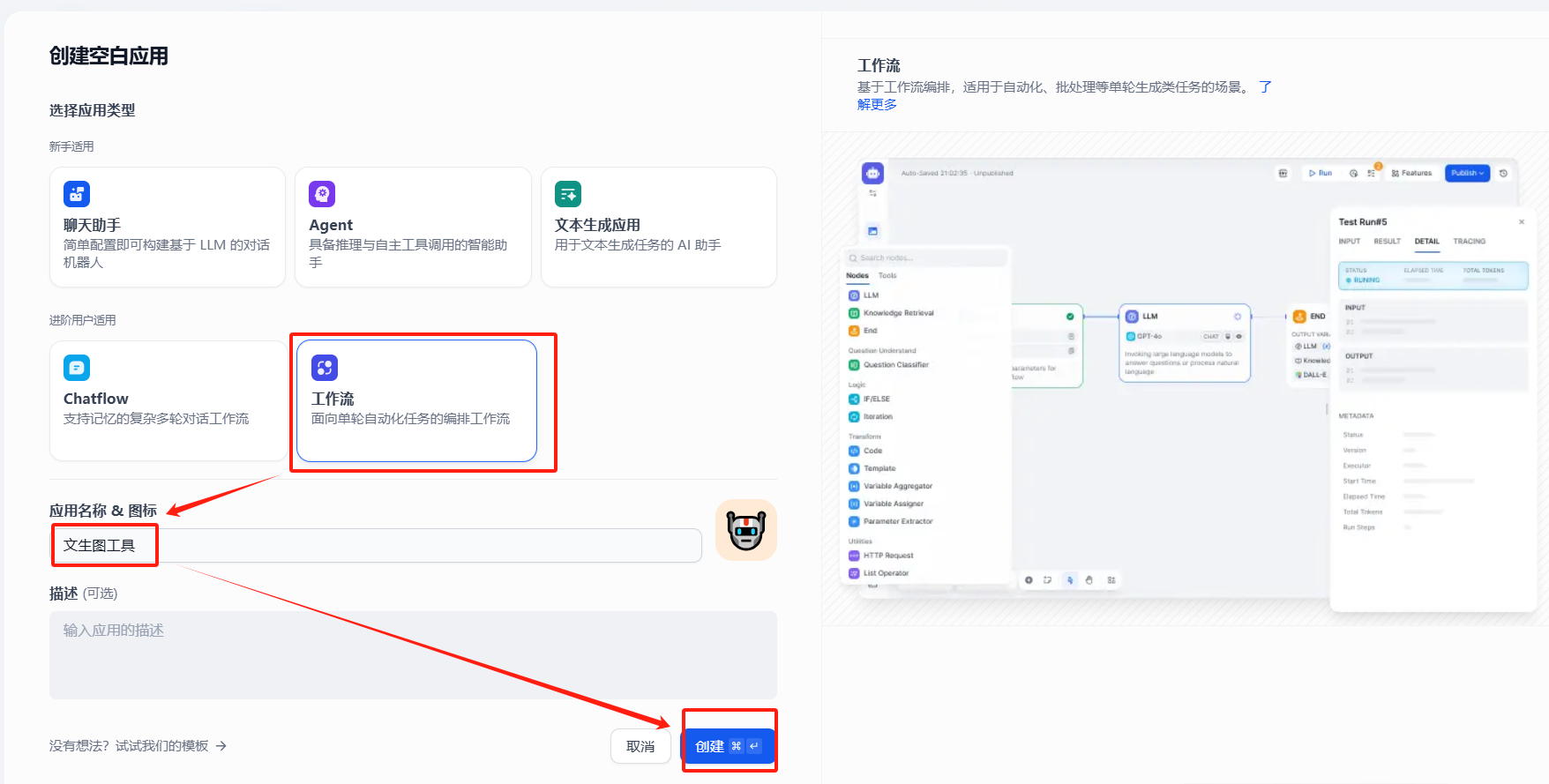
二、安装硅基流动
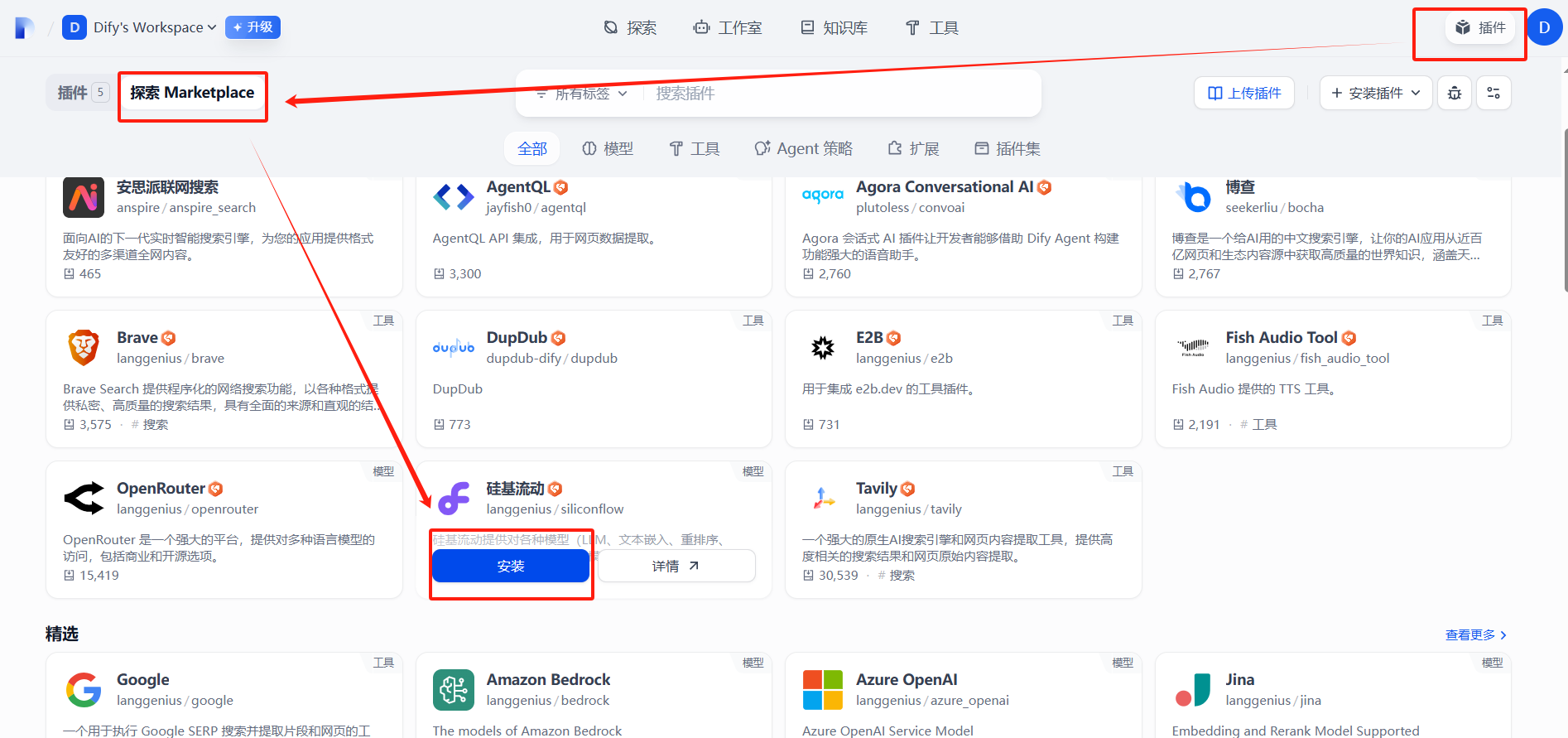
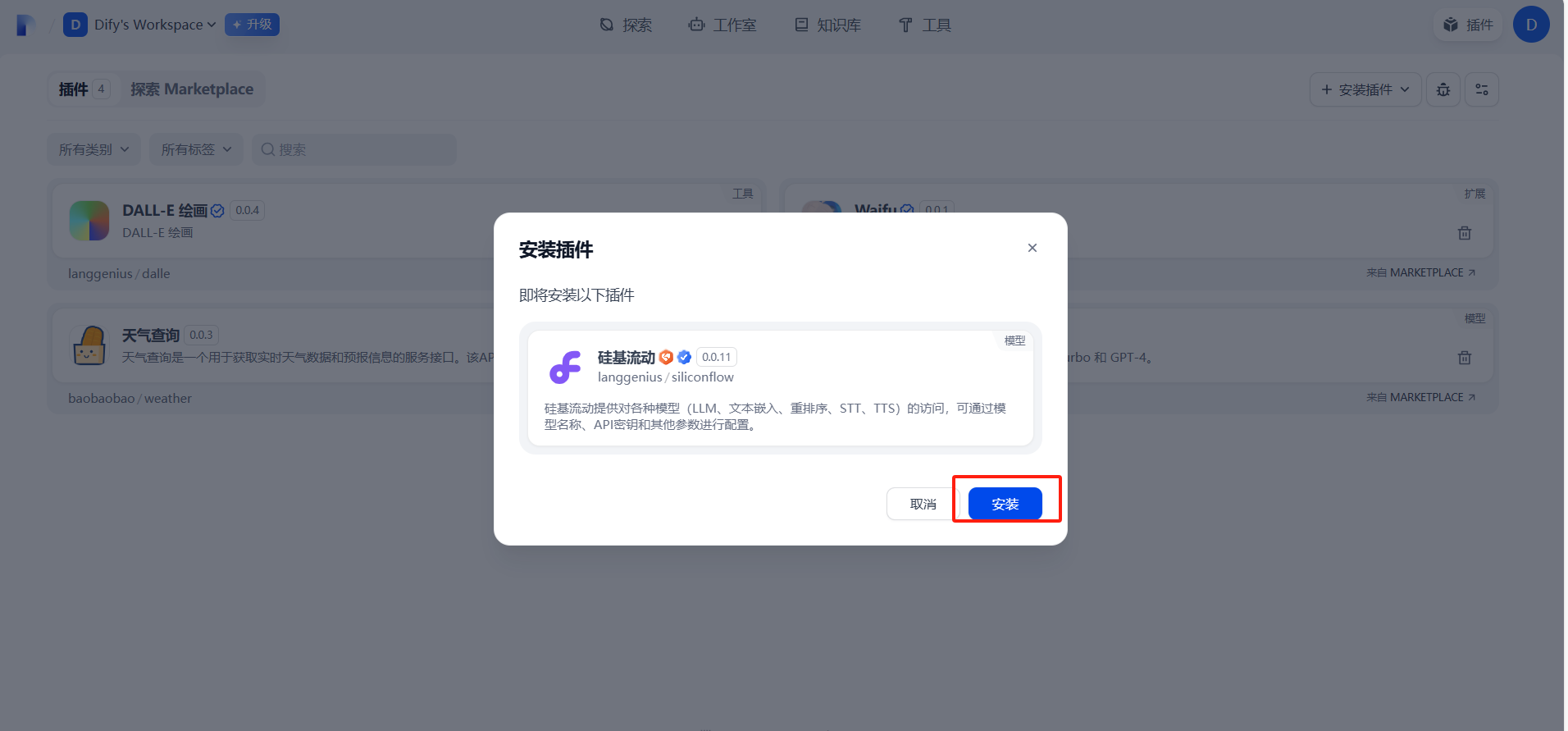
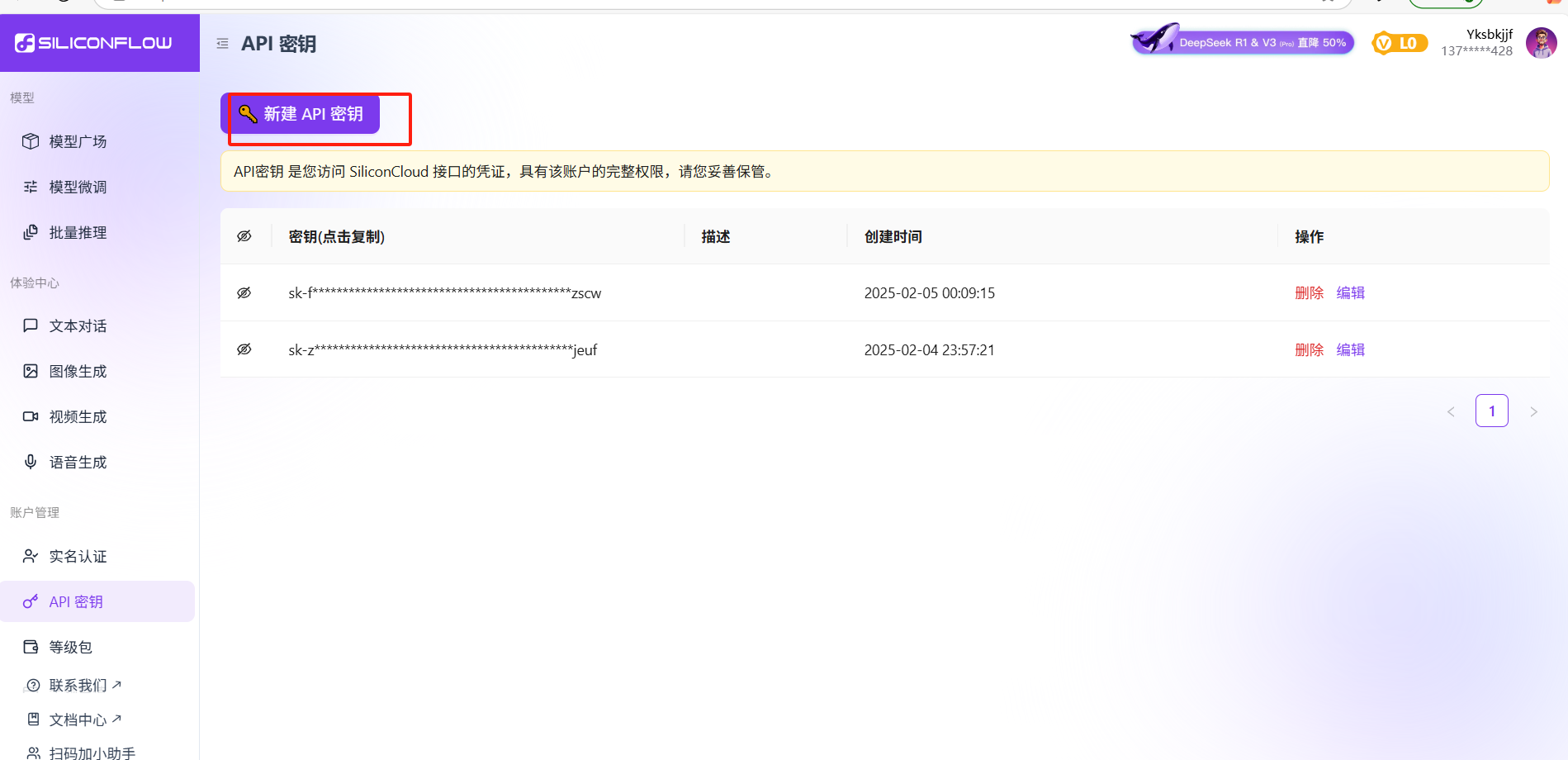
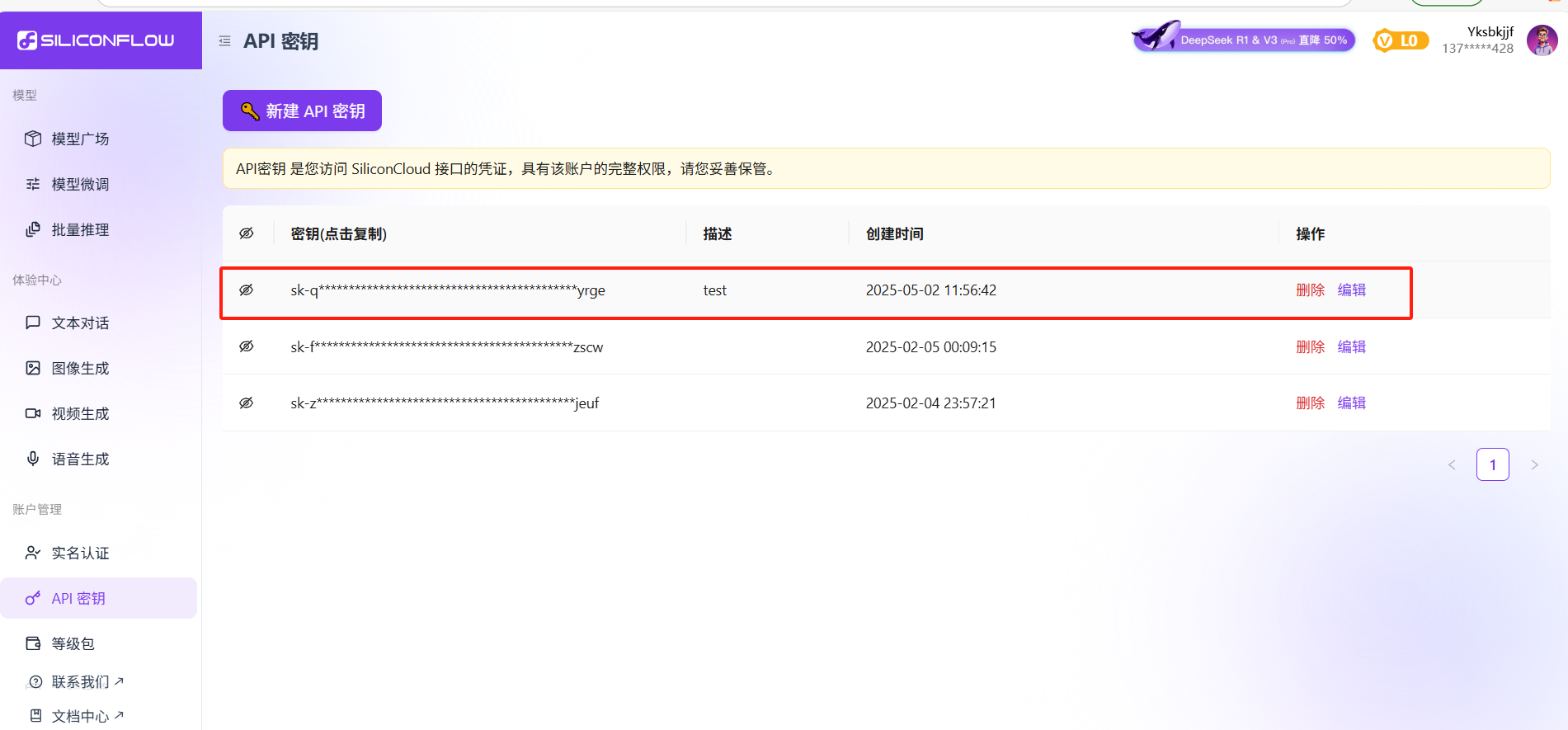
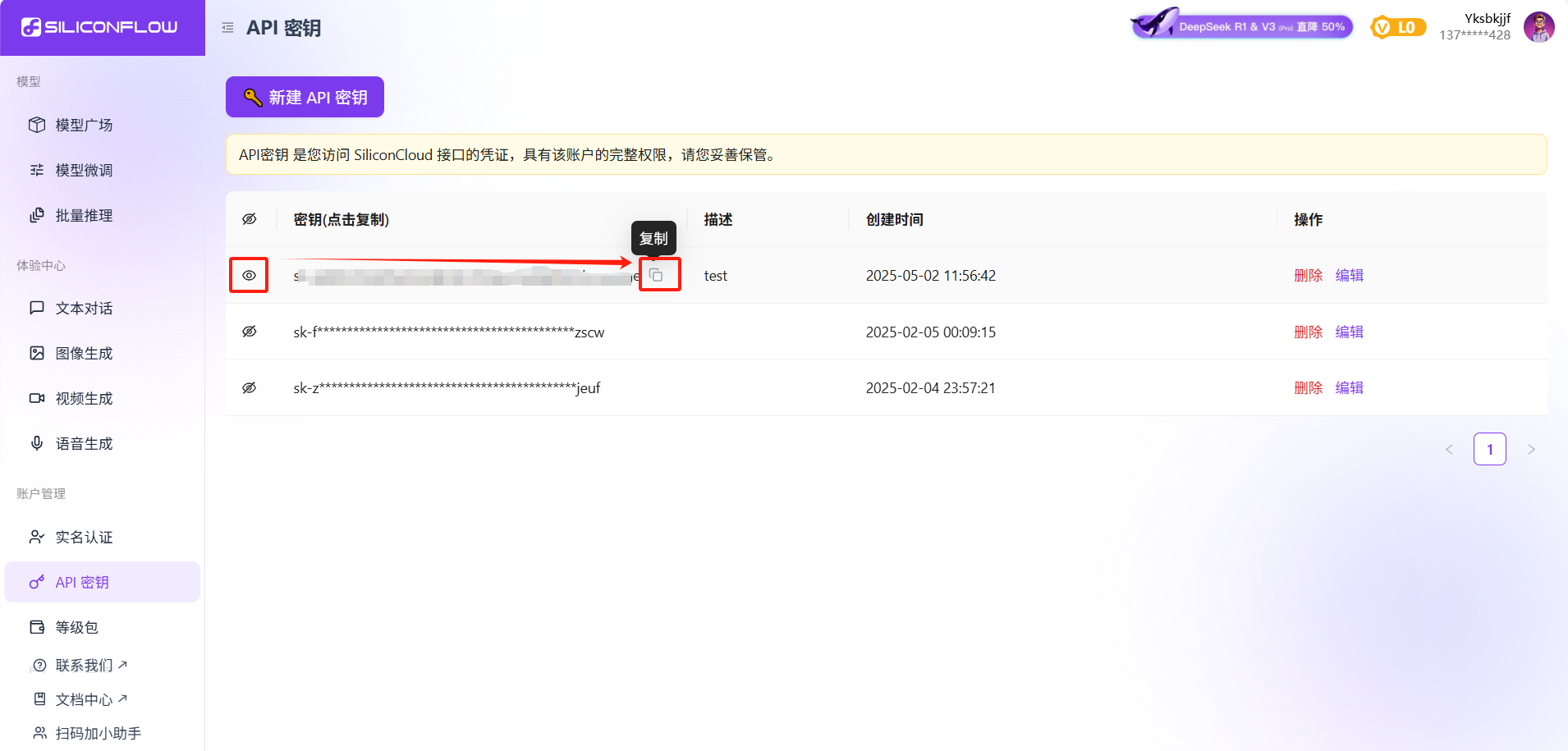
三、配置硅基流动
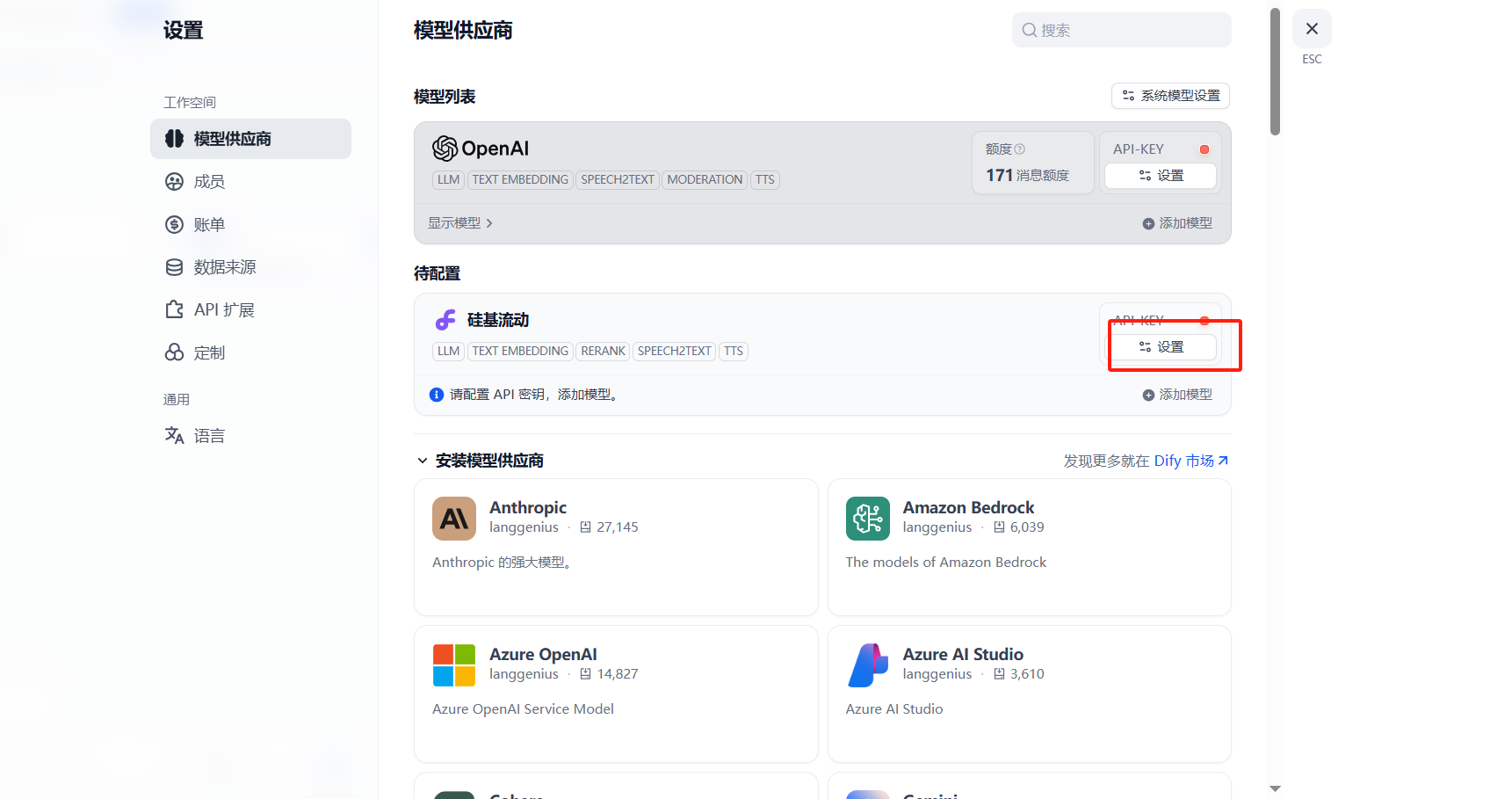
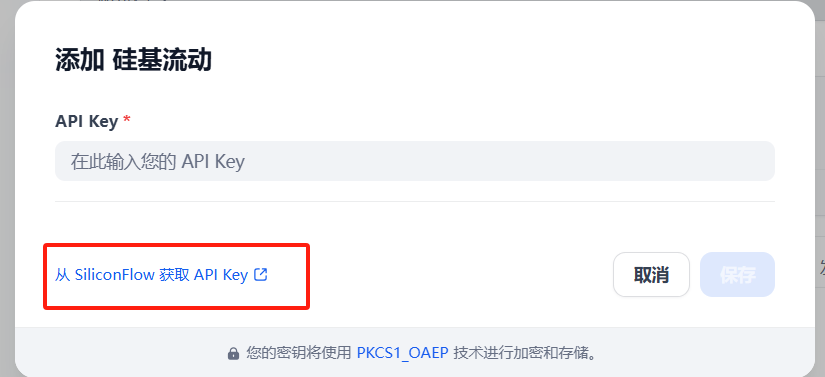

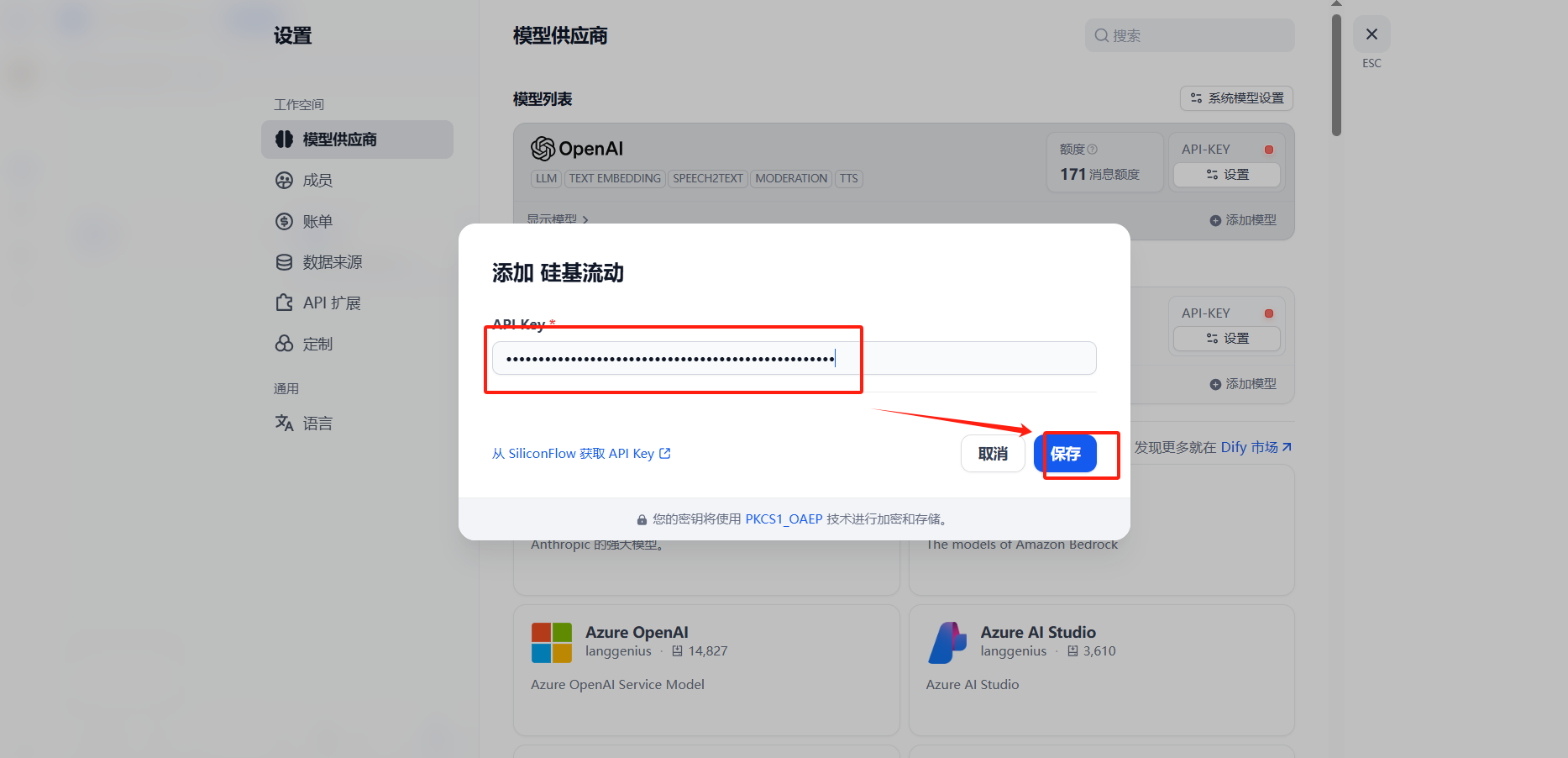
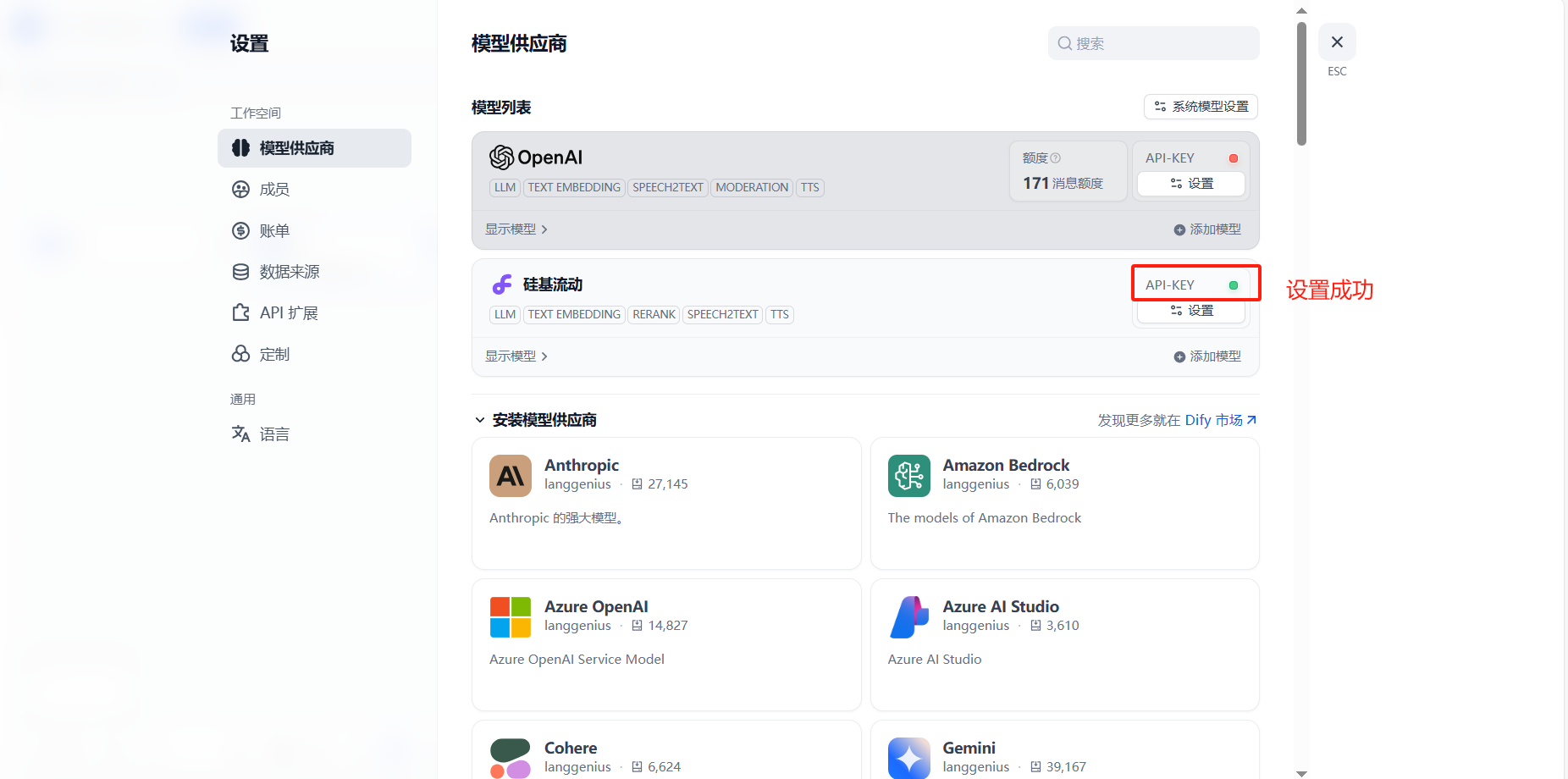
四、API测试
(1)进入API文档
回到硅基流动,进入生图模型的API文档
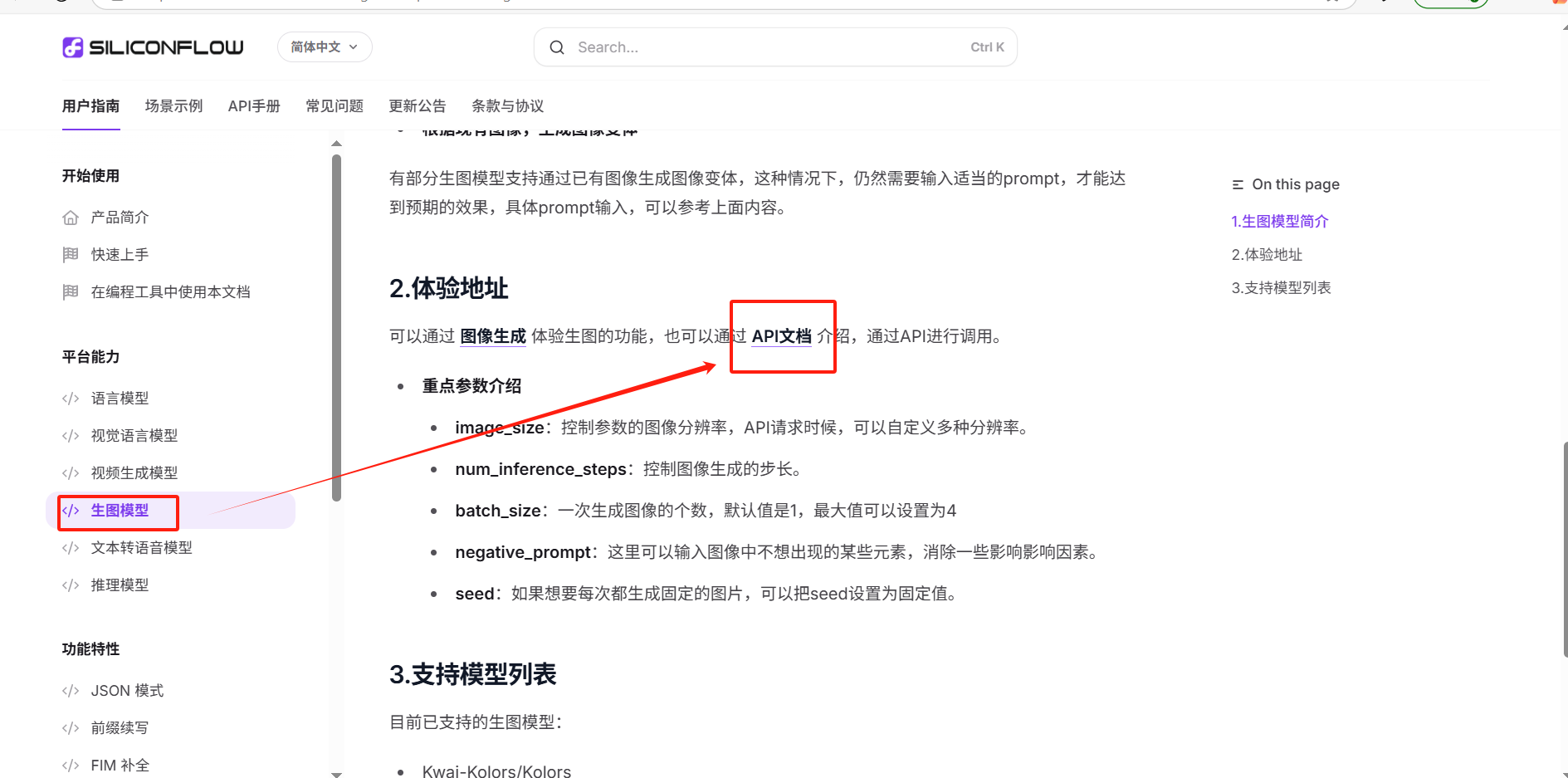
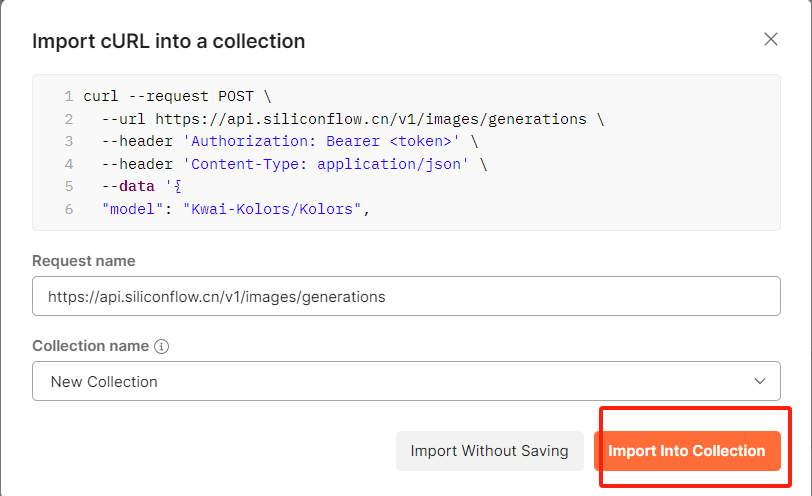
(2)复制curl代码
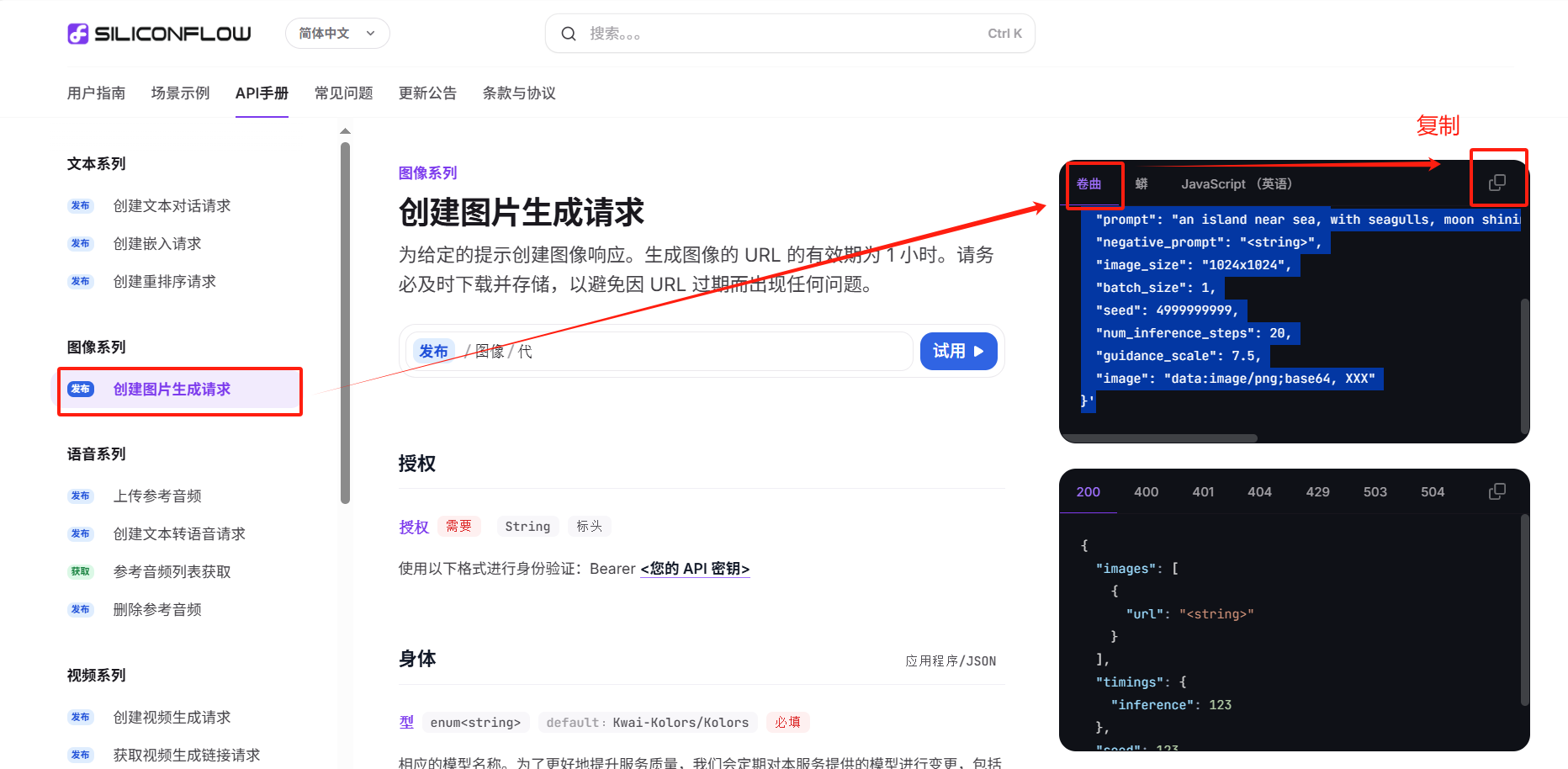
(3)Postman测试API
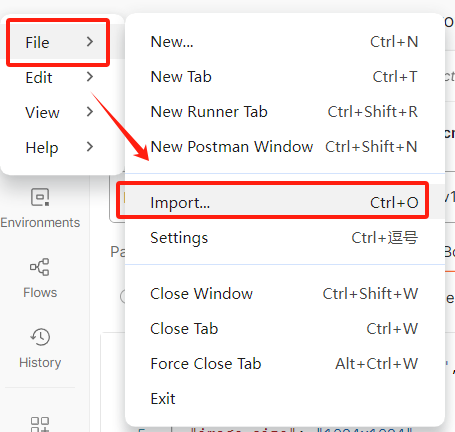
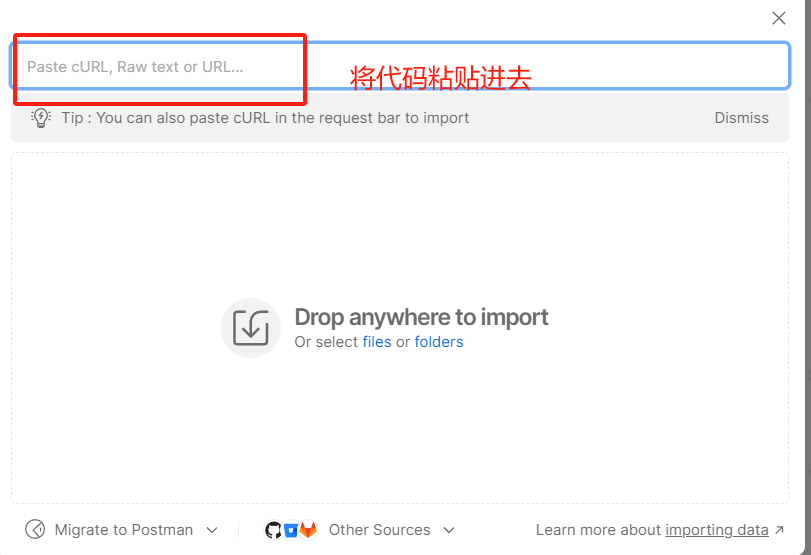
注意:需要先下载一个Postman
打开Postman
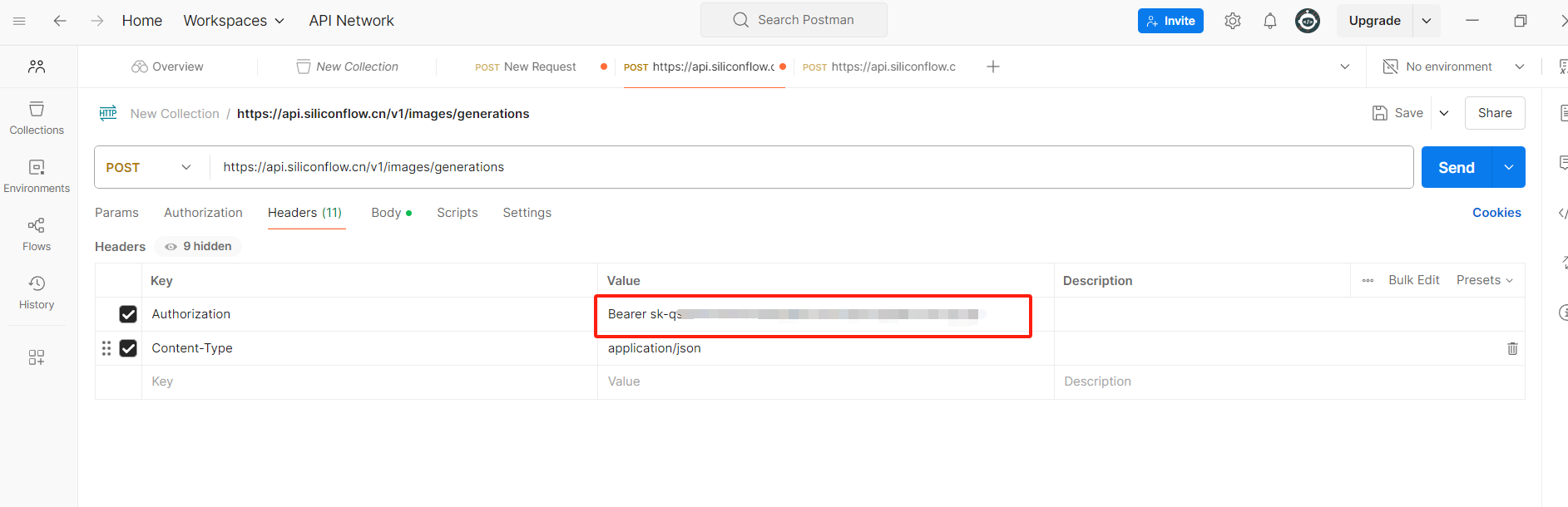
重点参数介绍
image_size:控制参数的图像分辨率,API请求时候,可以自定义多种分辨率。
num_inference_steps:控制图像生成的步长。
batch_size:一次生成图像的个数,默认值是1,最大值可以设置为4
negative_prompt:这里可以输入图像中不想出现的某些元素,消除一些影响影响因素。
seed:如果想要每次都生成固定的图片,可以把seed设置为固定值。
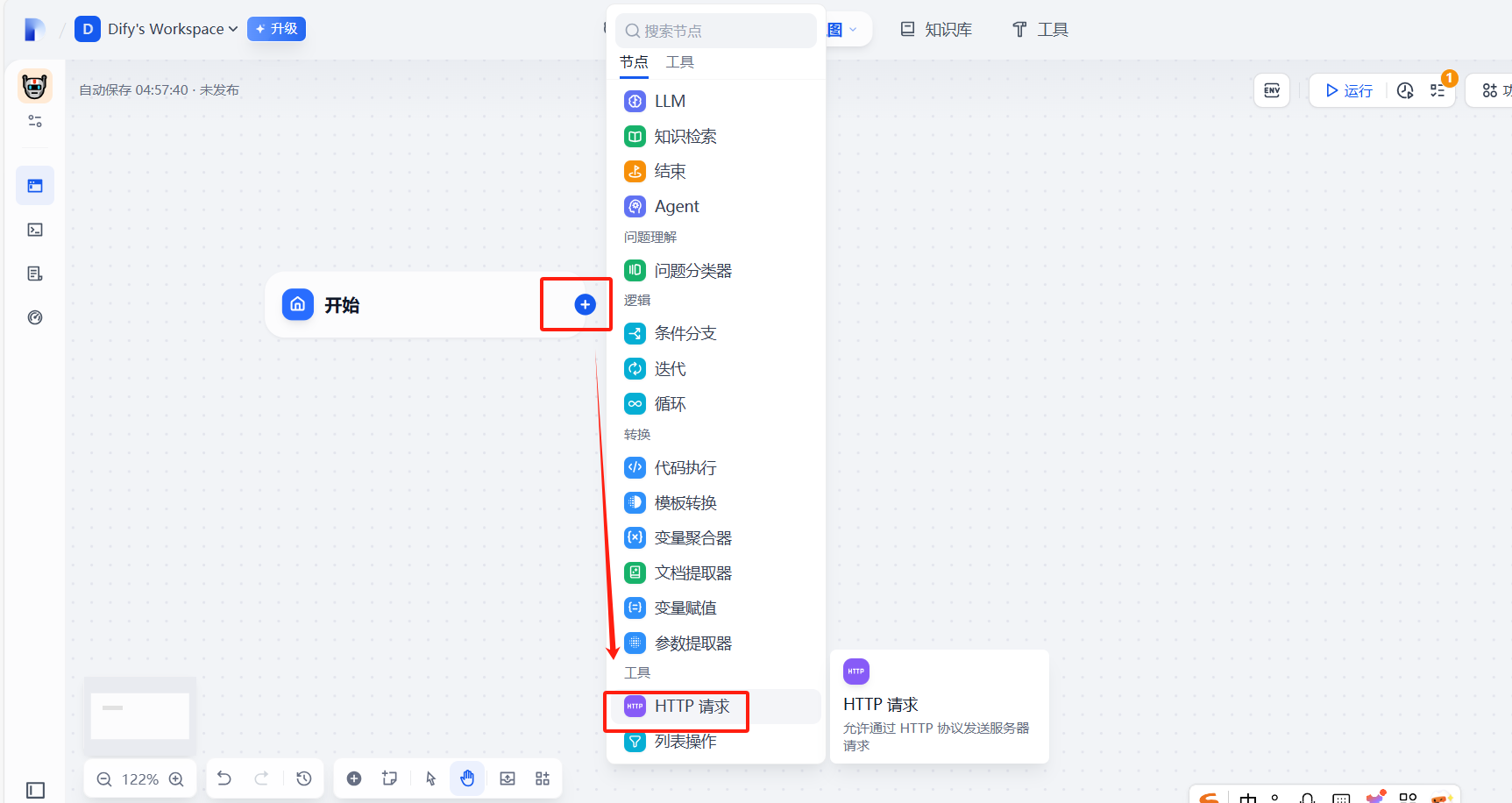
五、 建立文生图工作流
(1)建立http请求
(2)配置http请求信息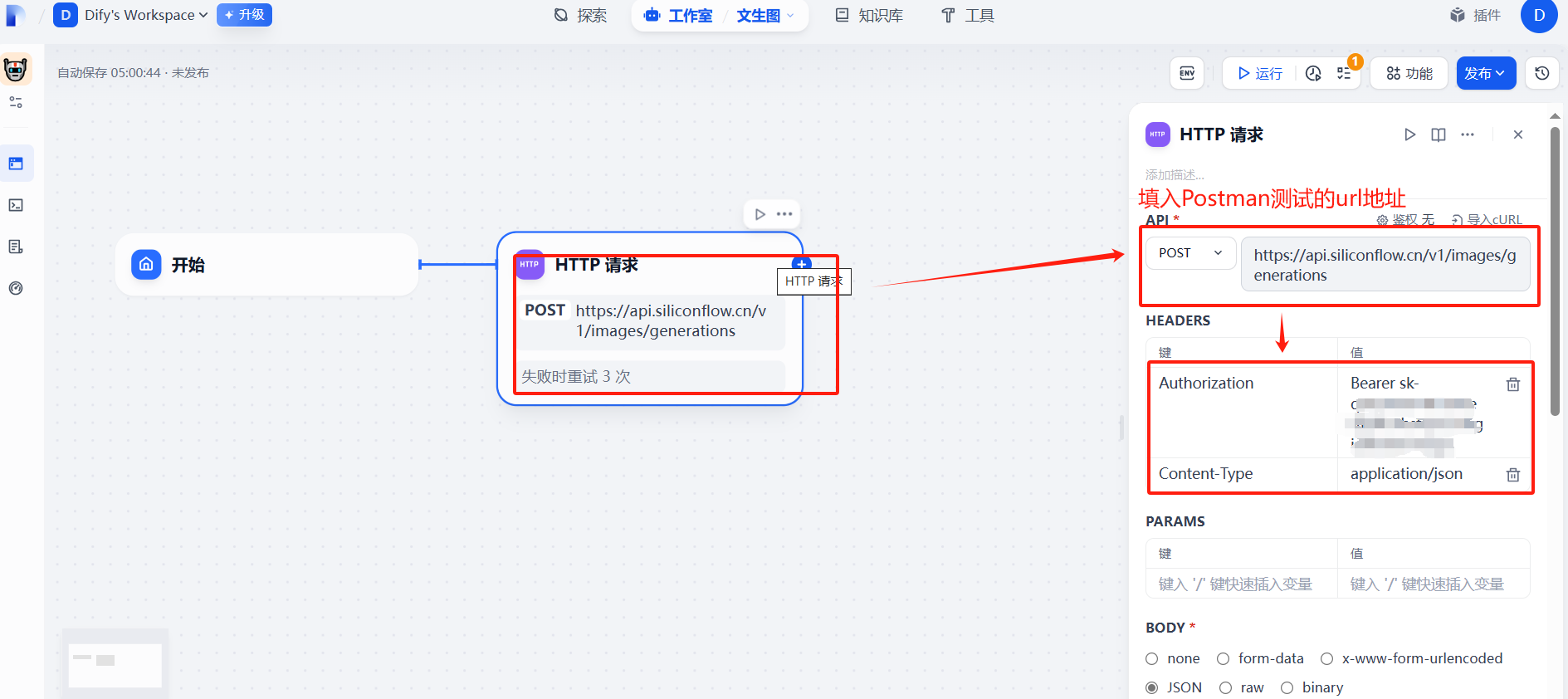
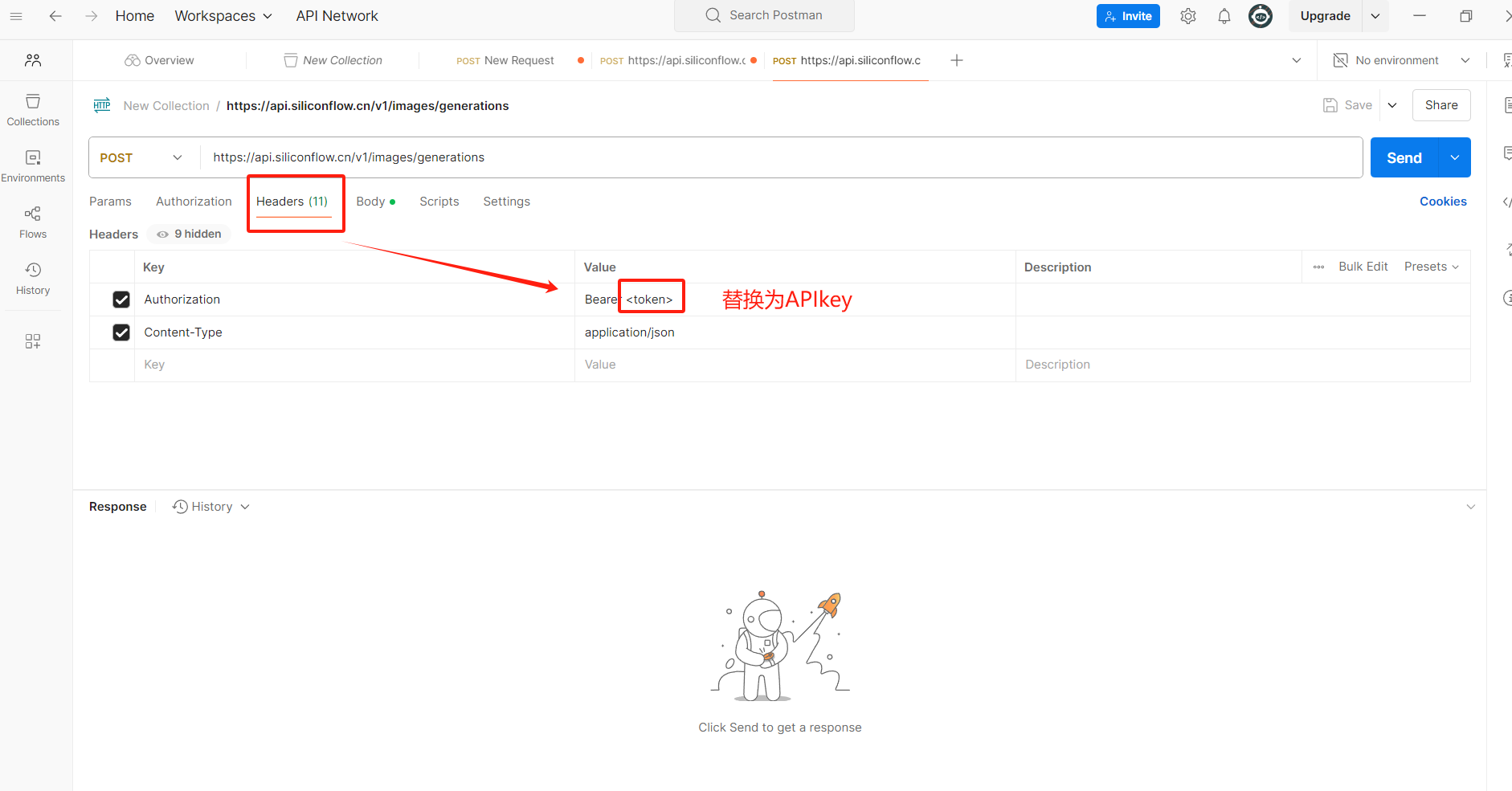
让API不以明文显示
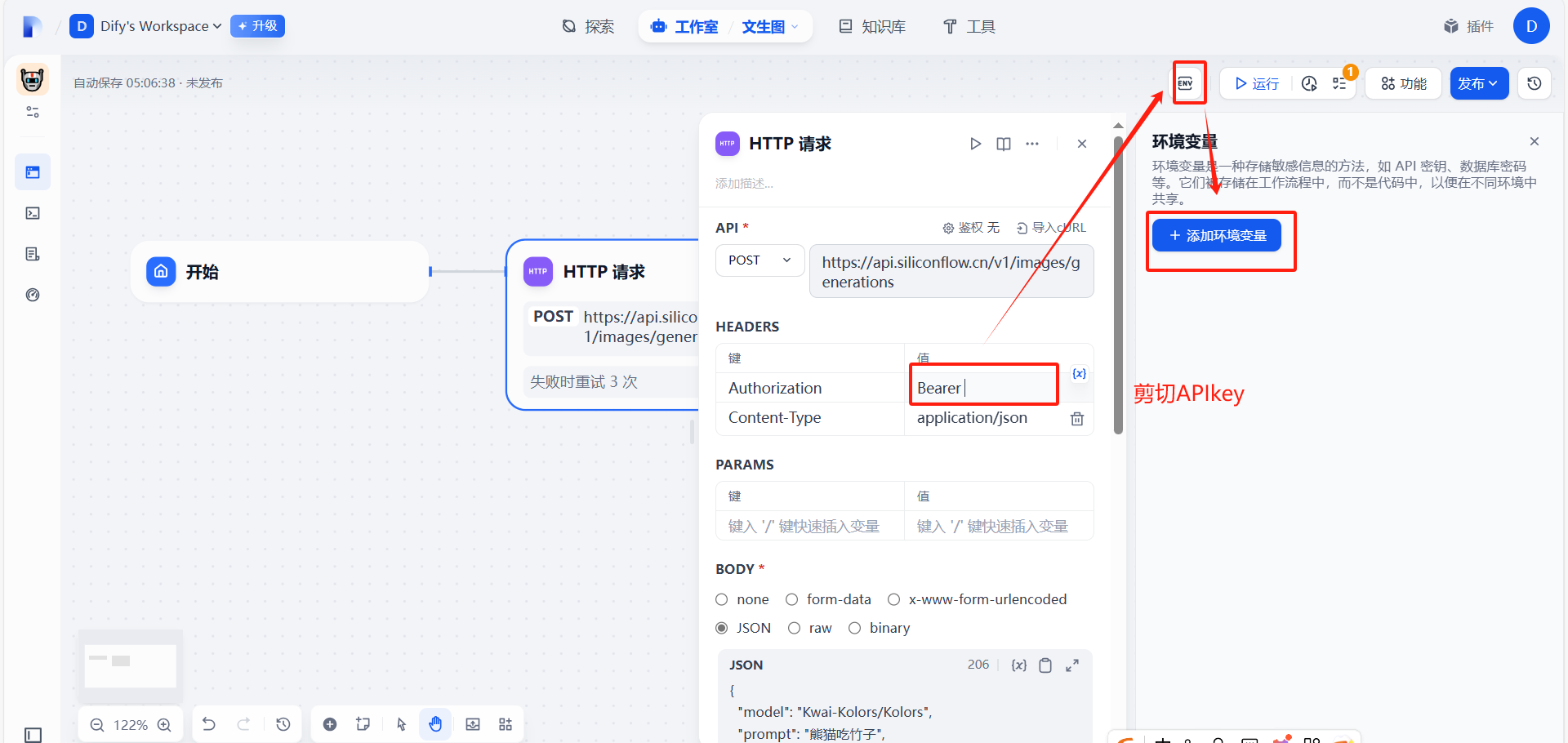
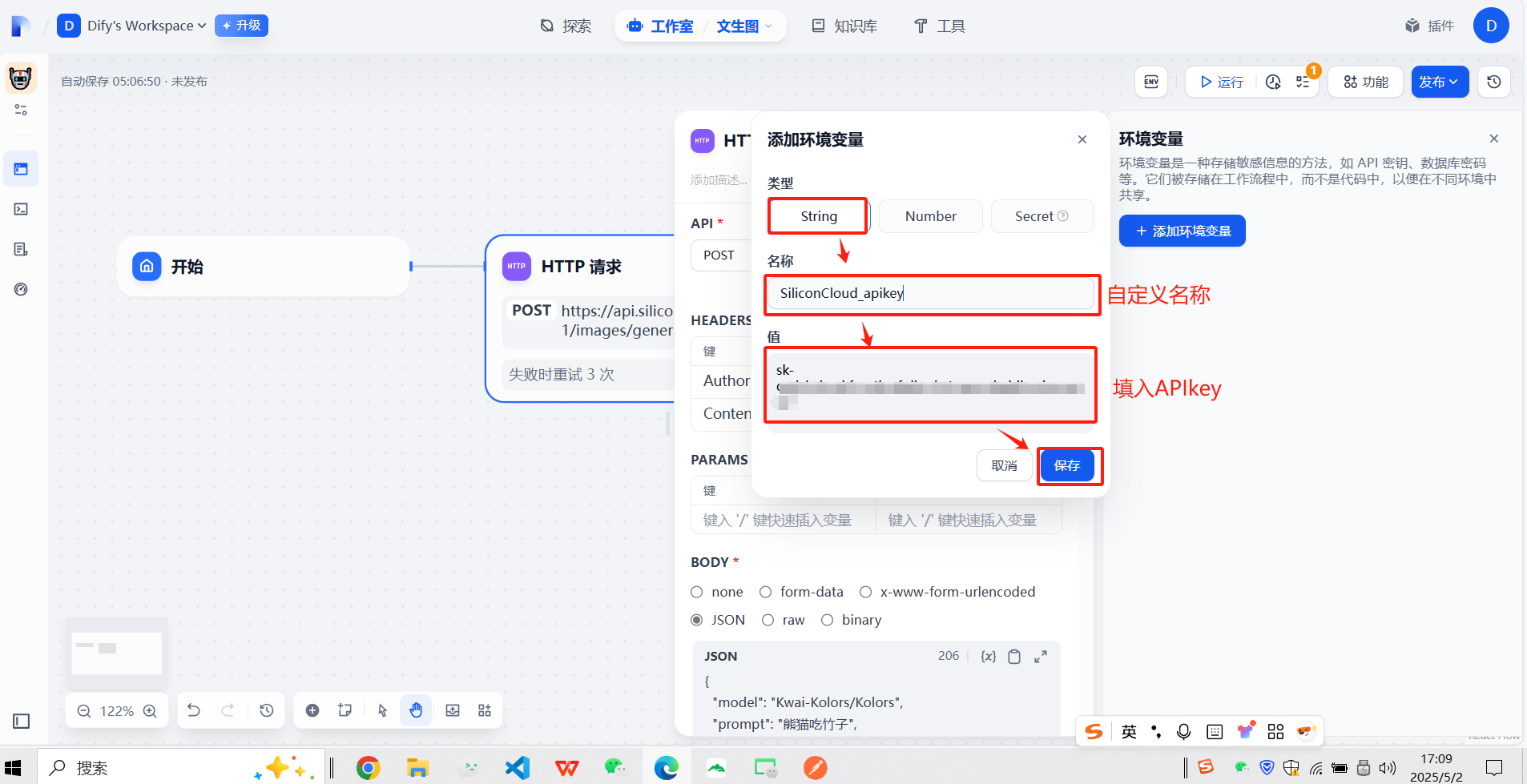
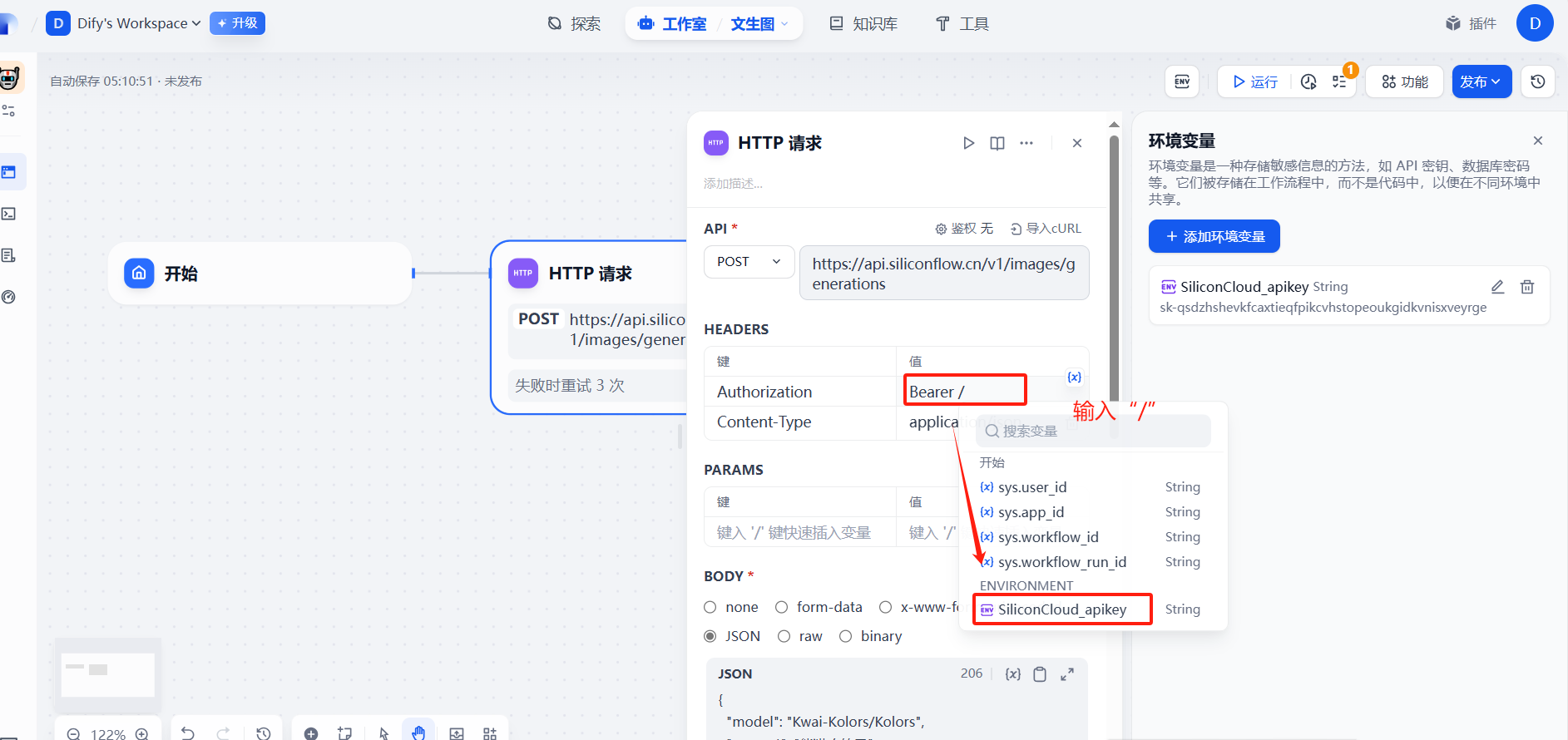
添加成功
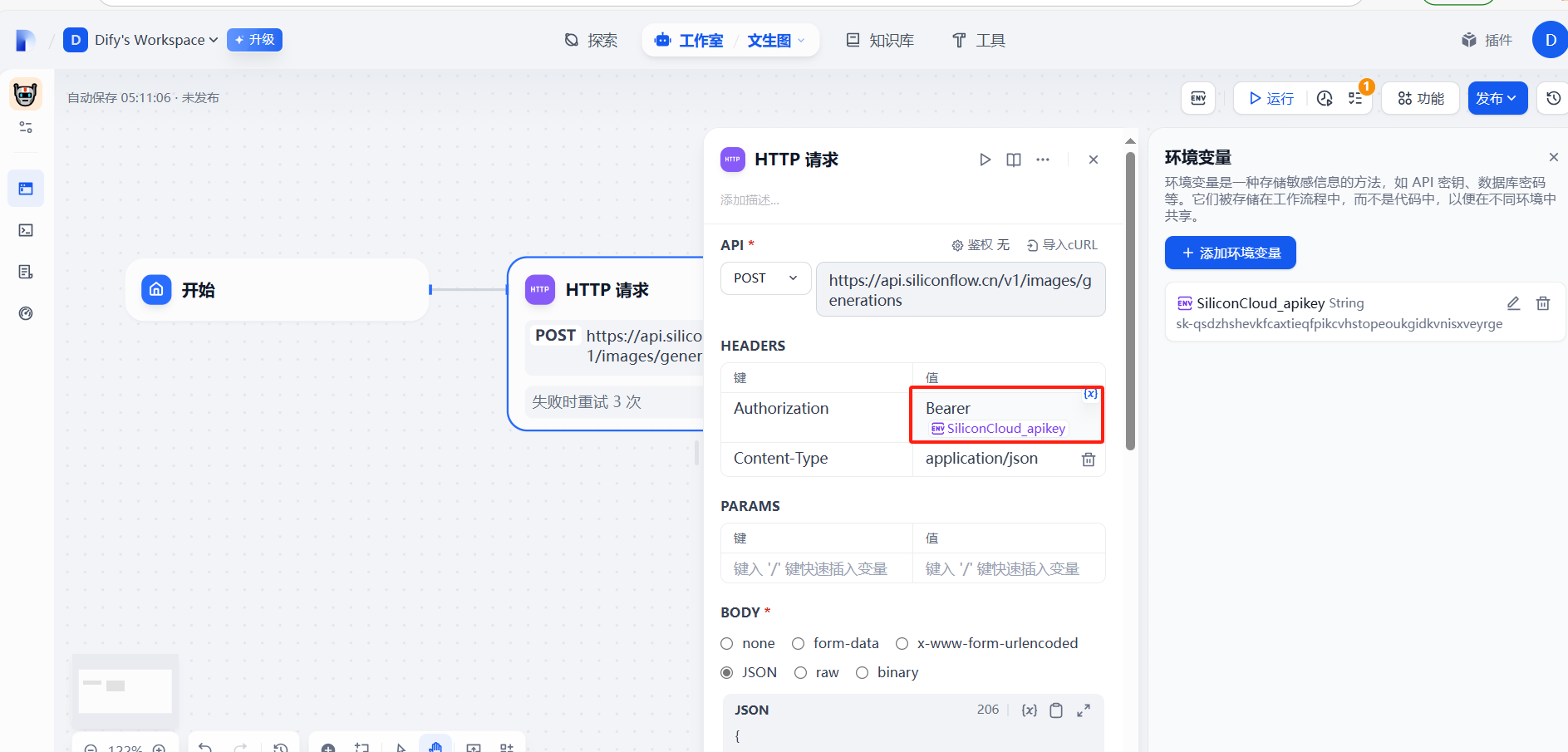
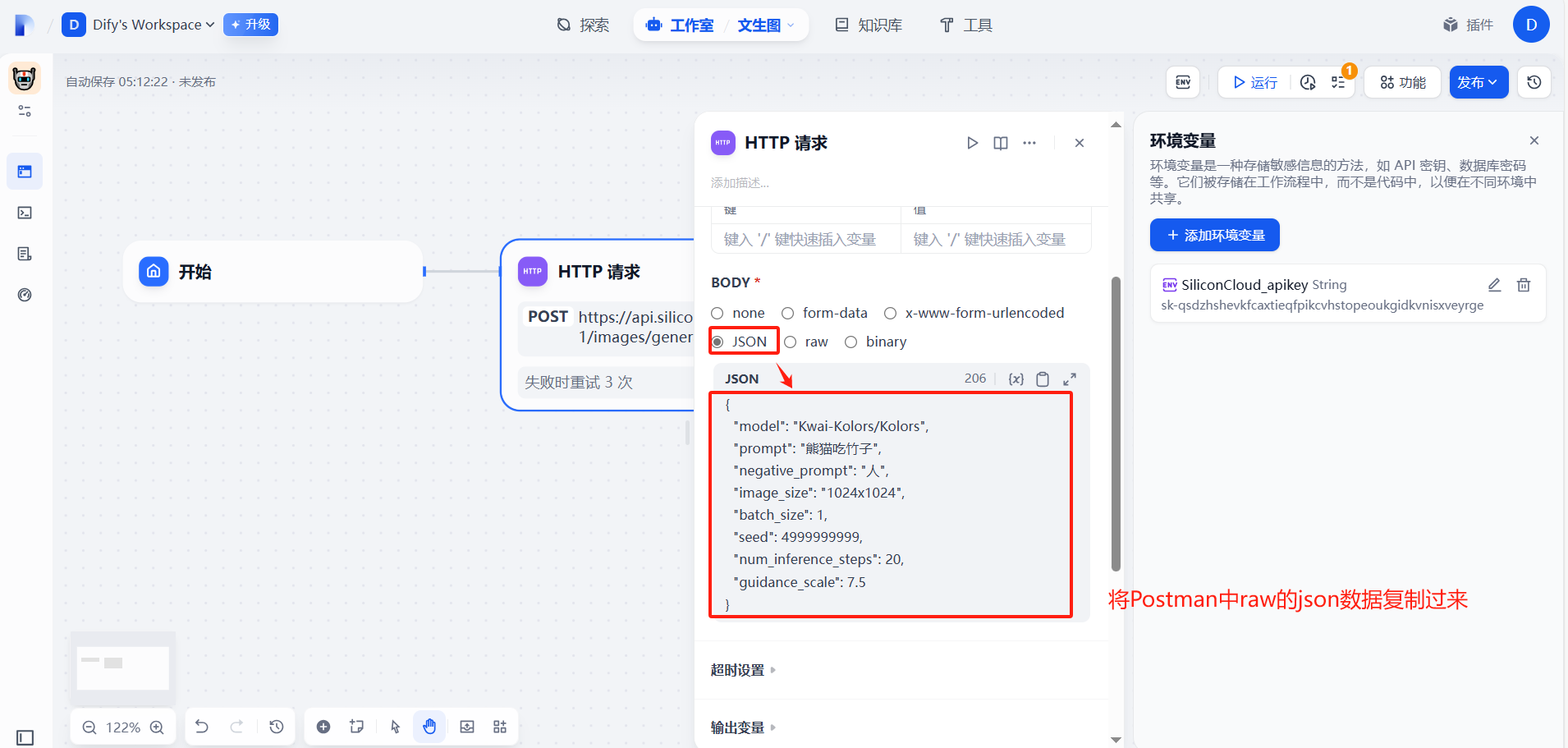
(3)提示词prompt自定义
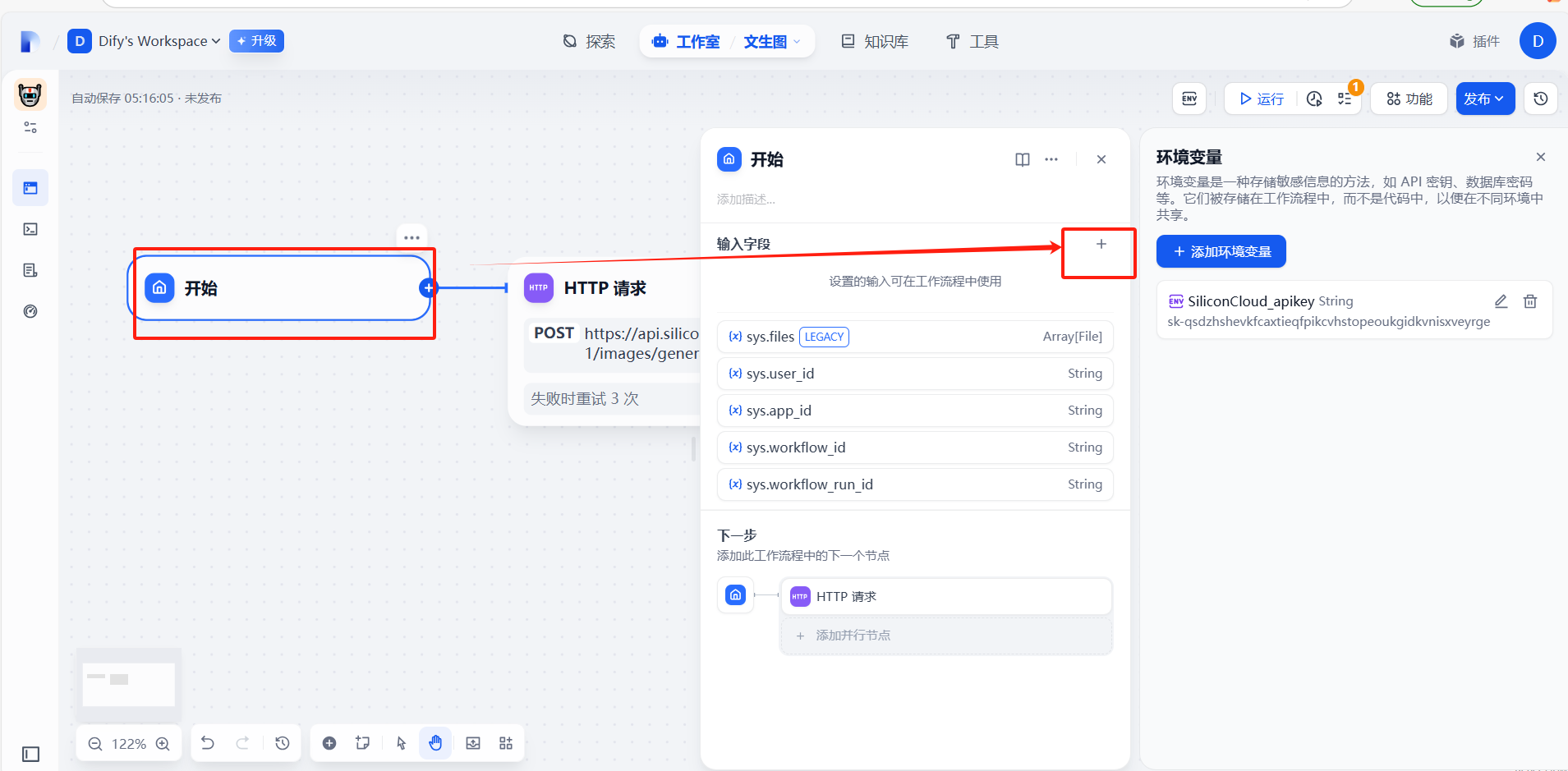
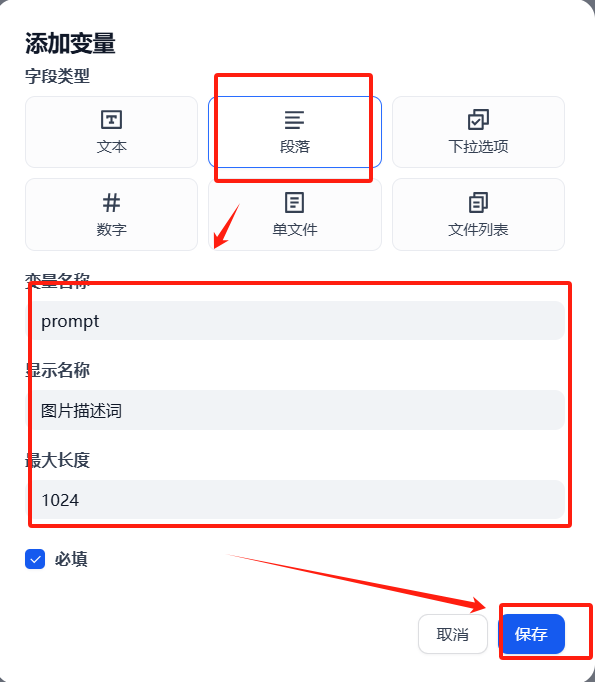
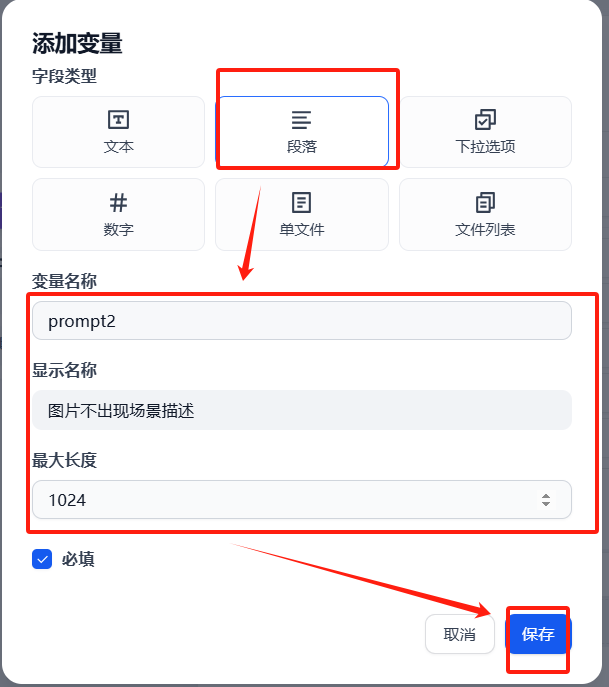
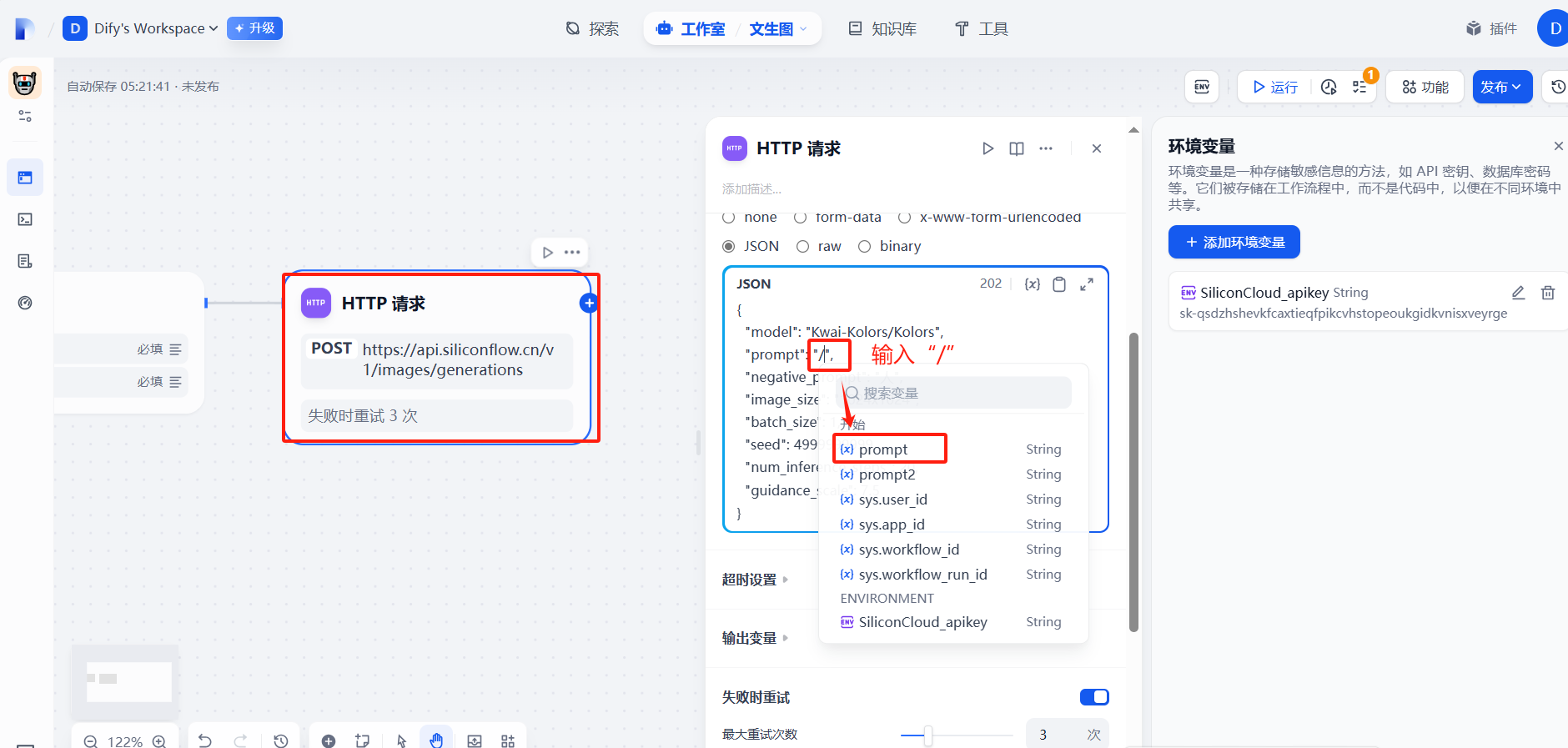
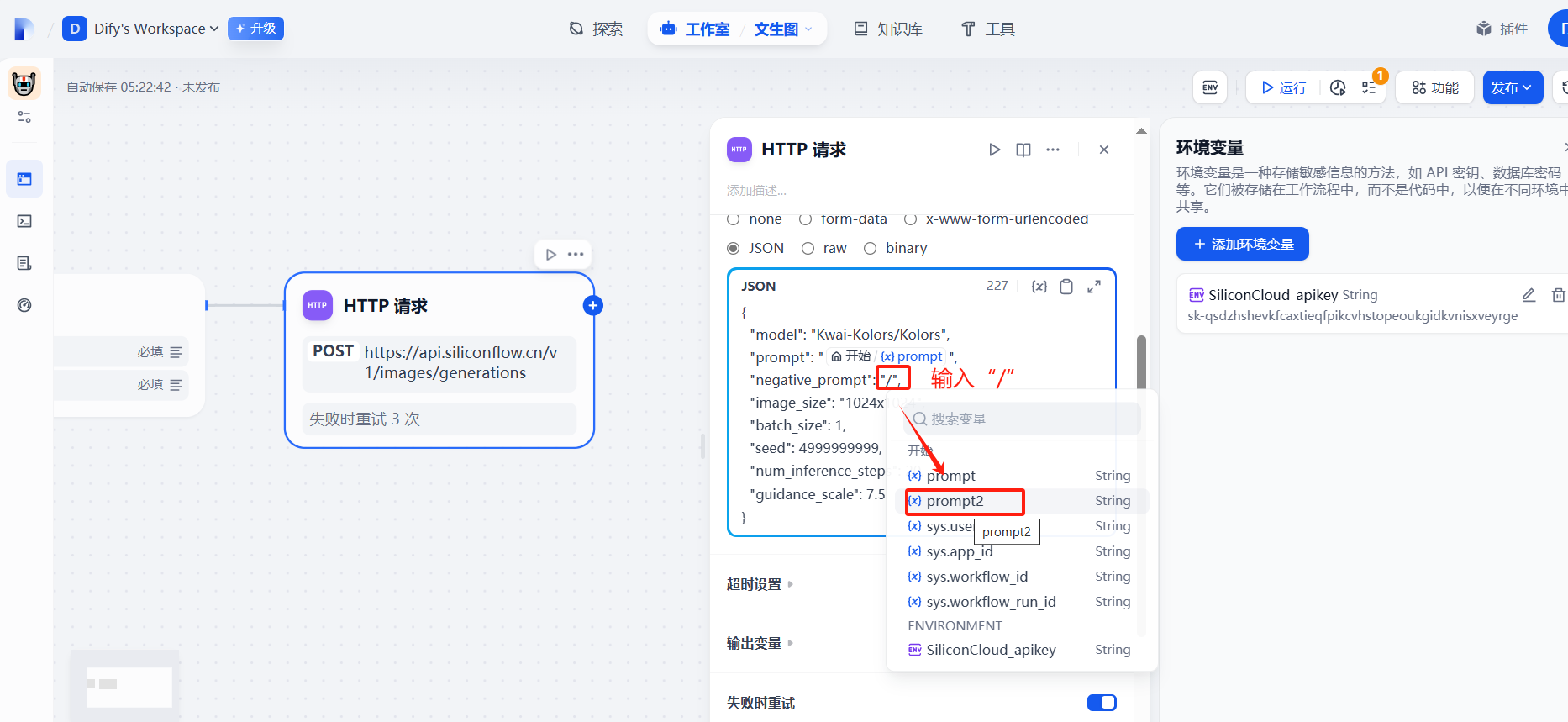
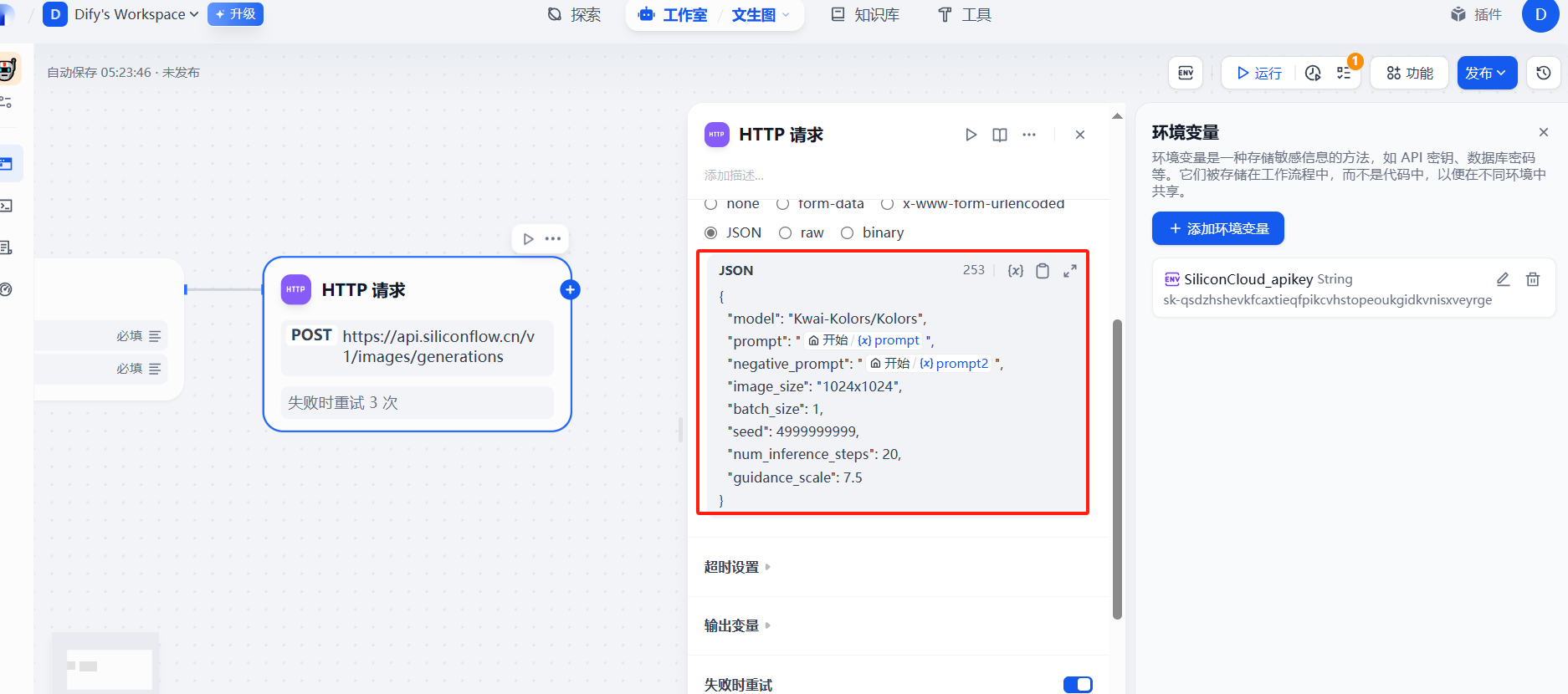
(4)添加结束回复节点
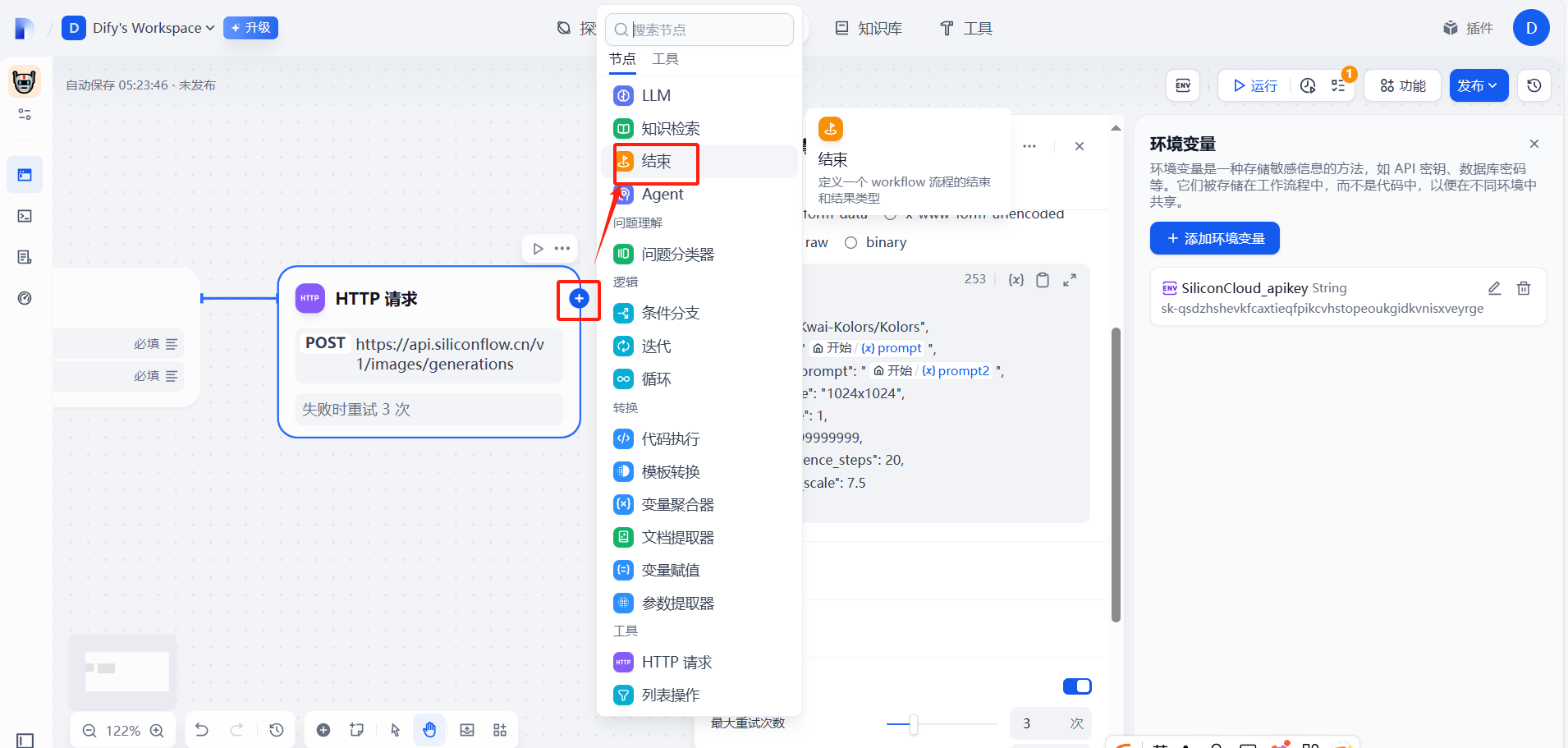
(5)测试运行
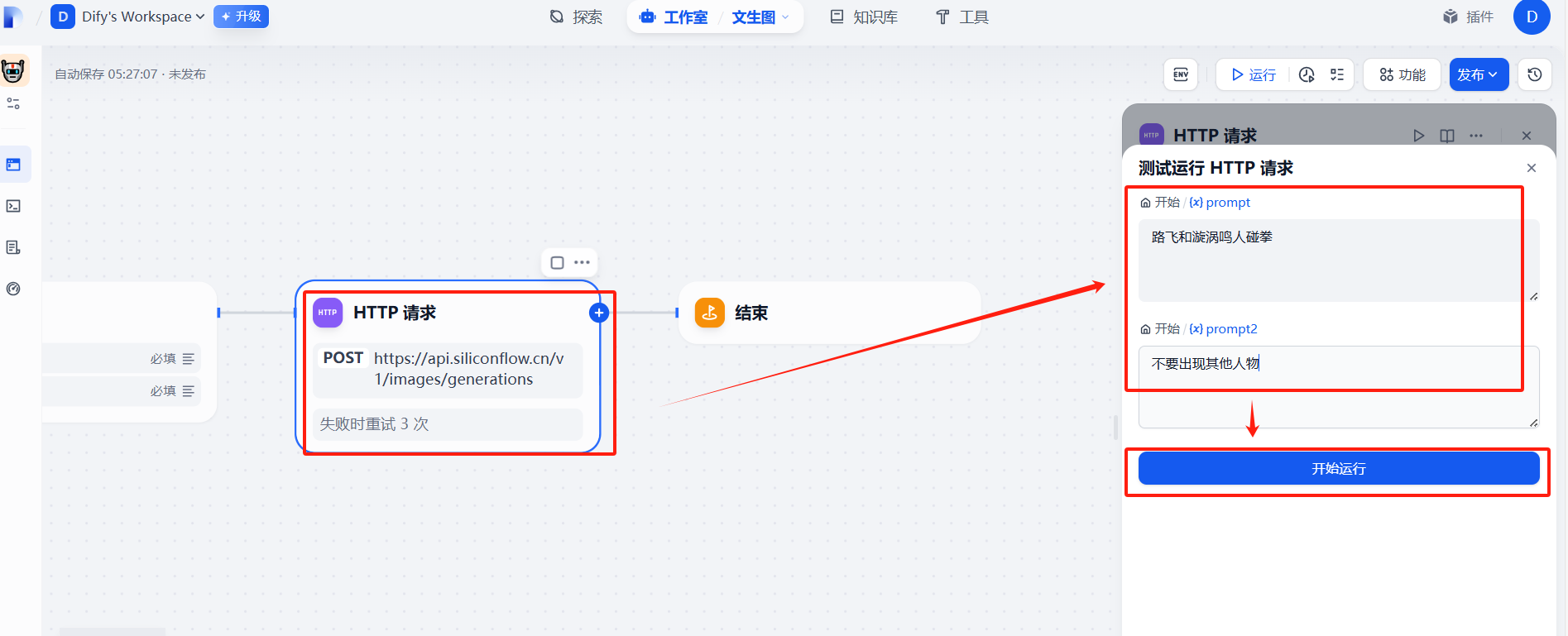
报错,这里是json数据格式会出现问题,需要处理一下
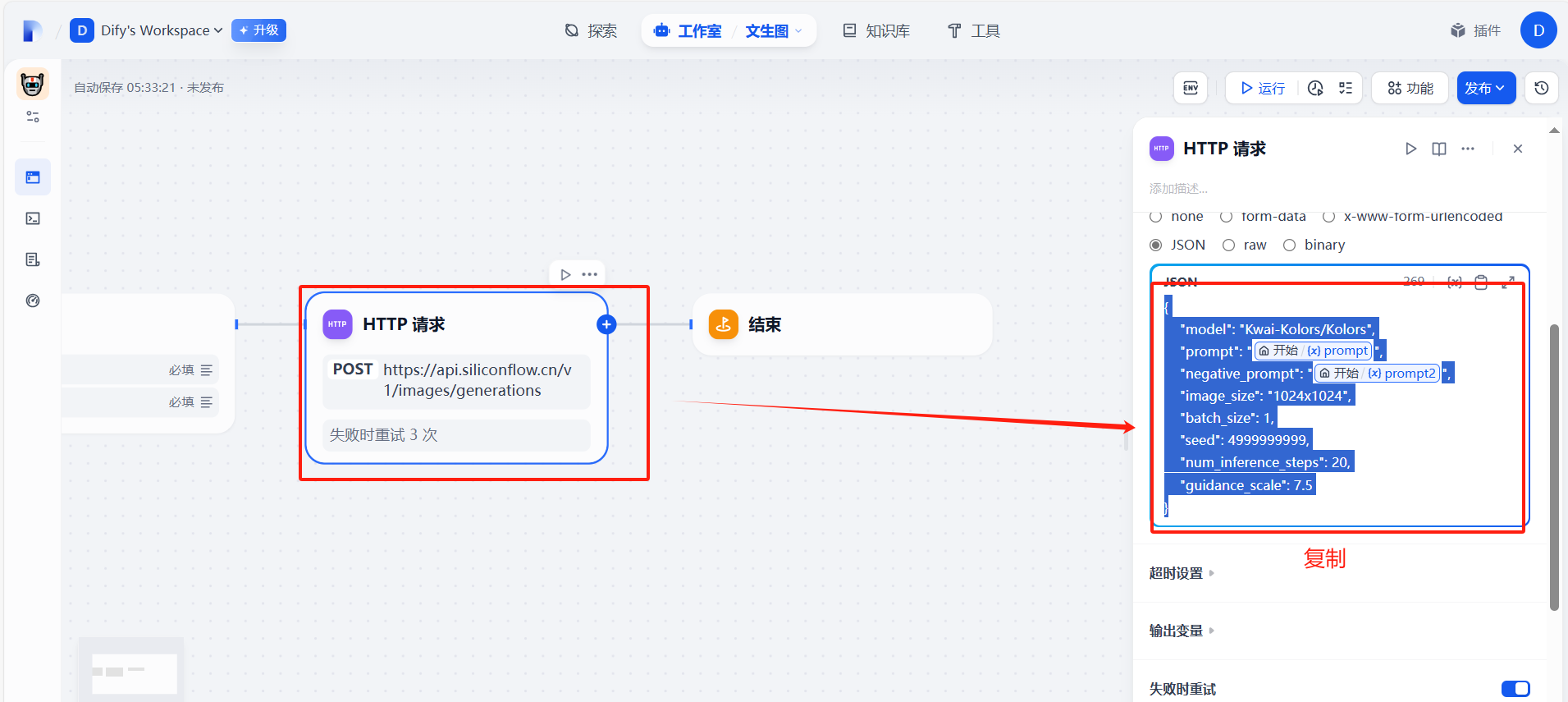
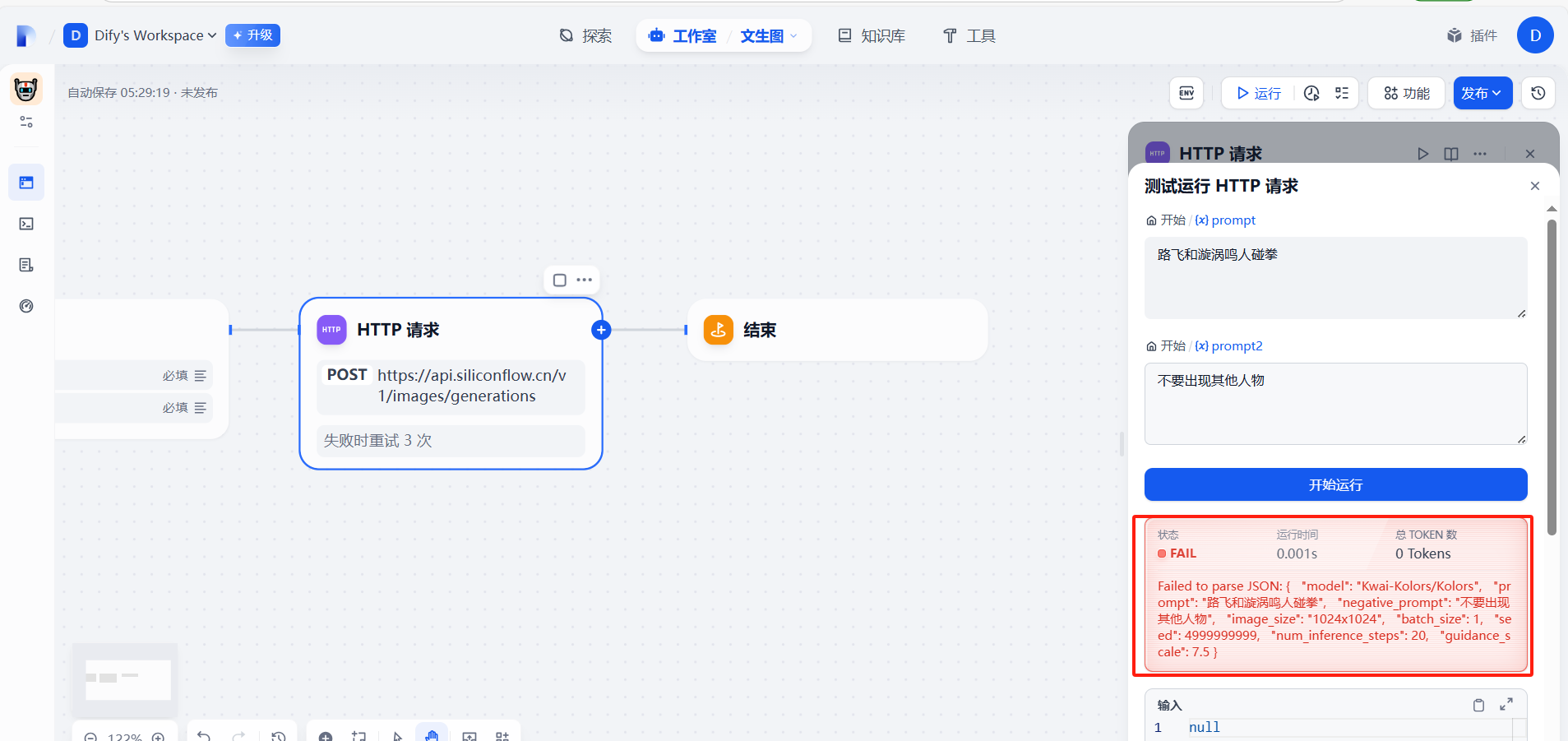 (6)调整json格式
(6)调整json格式
在线插件json数据格式处理:爬虫工具库-spidertools.cn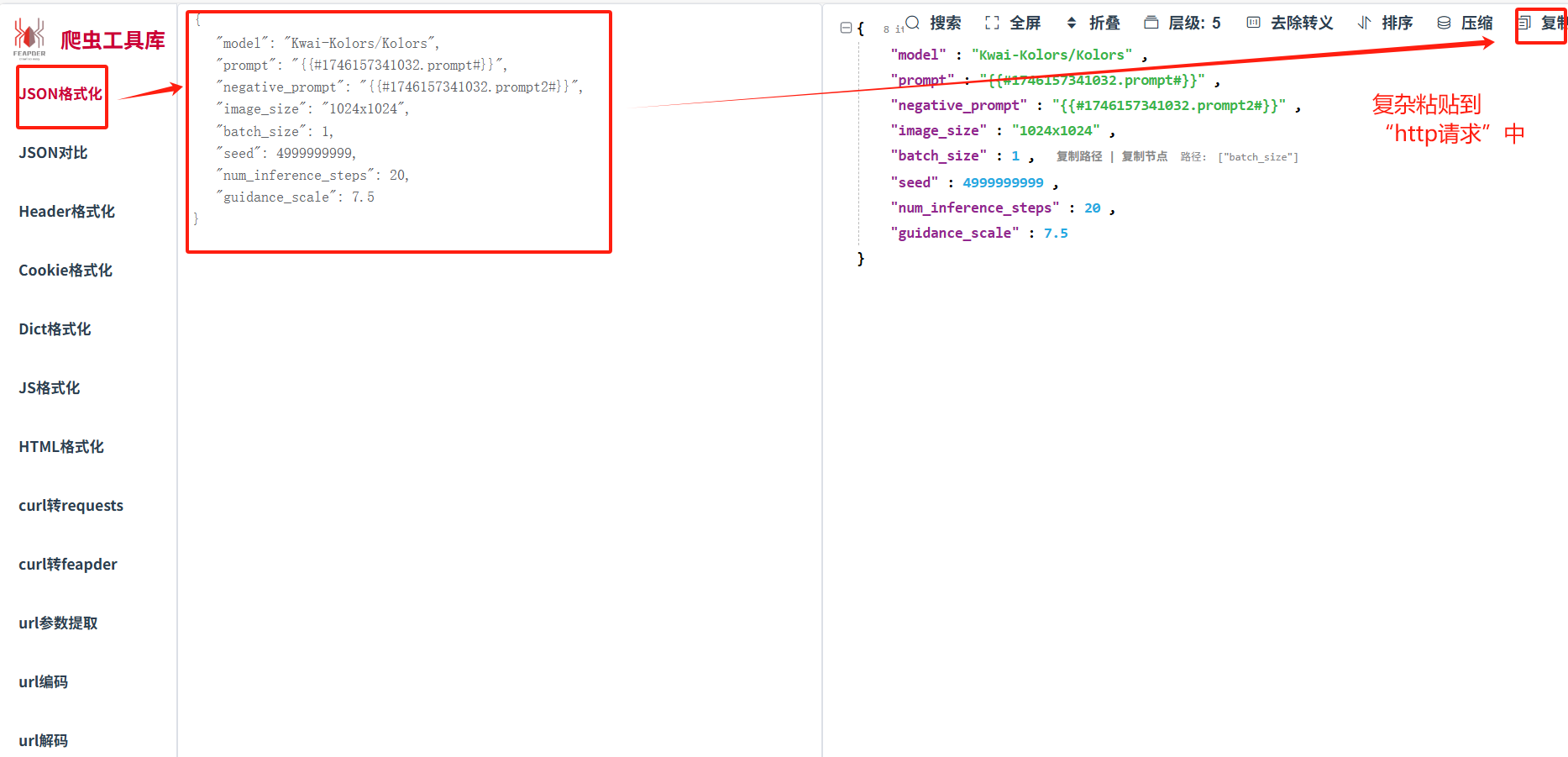
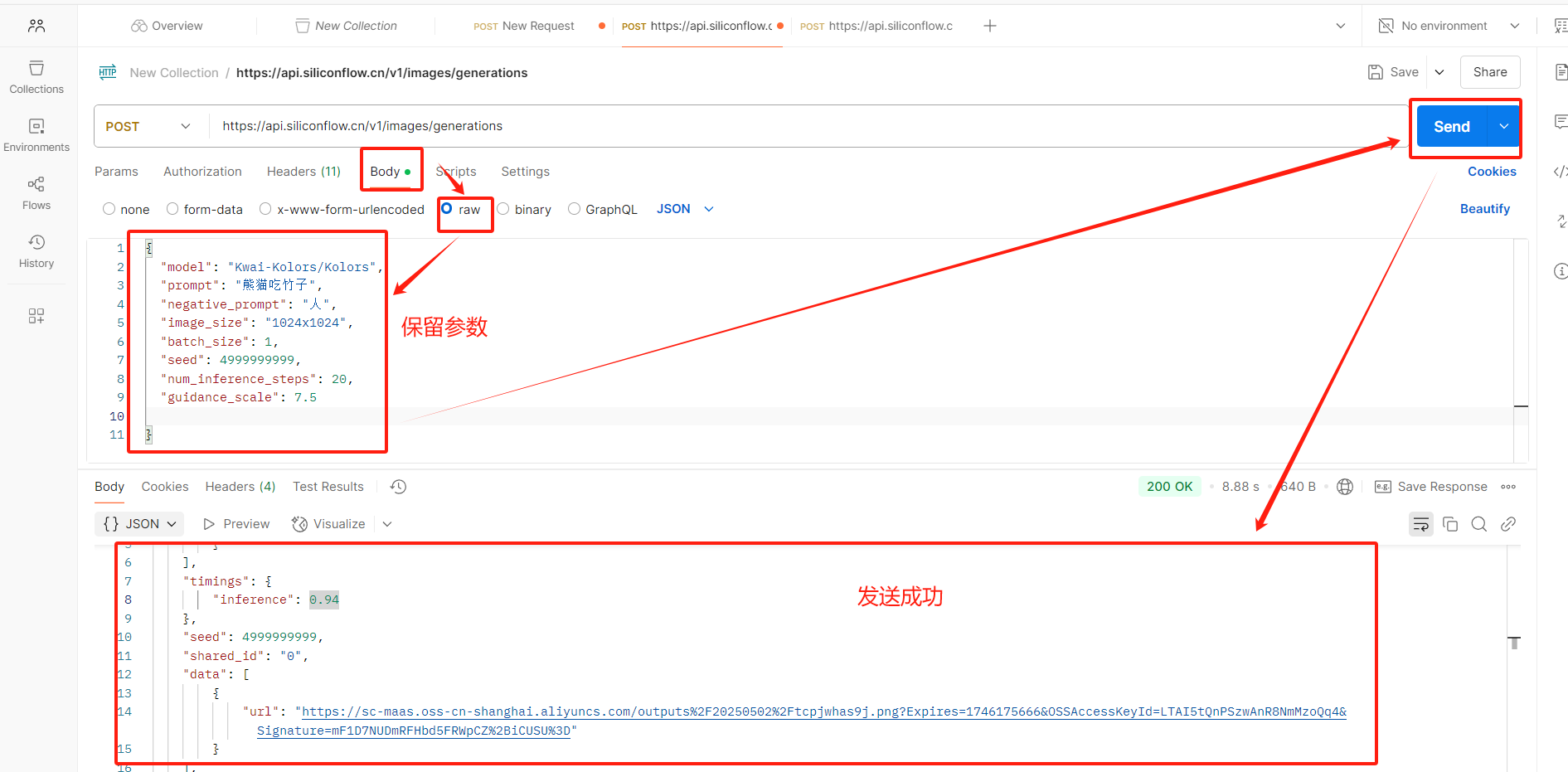
(7)运行成功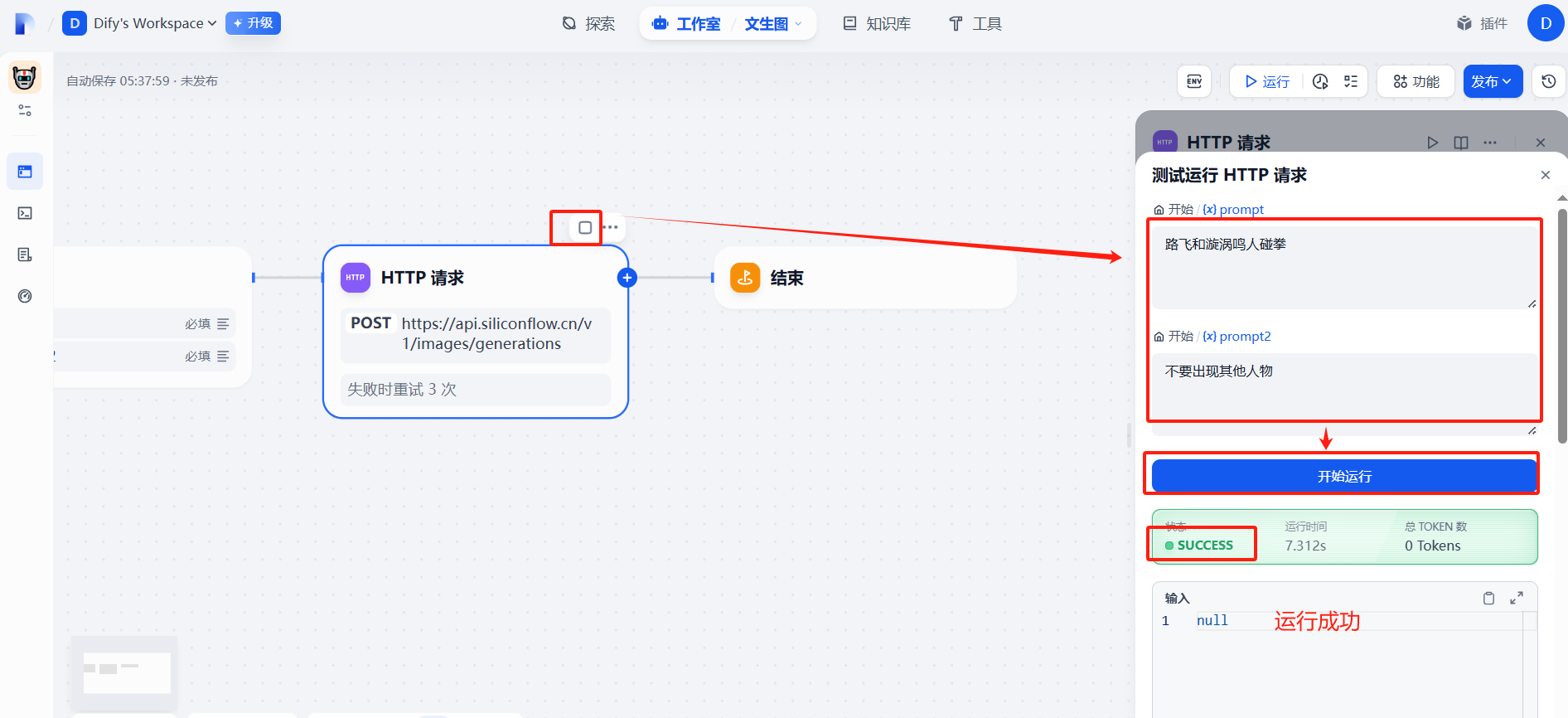
(8)查看图片
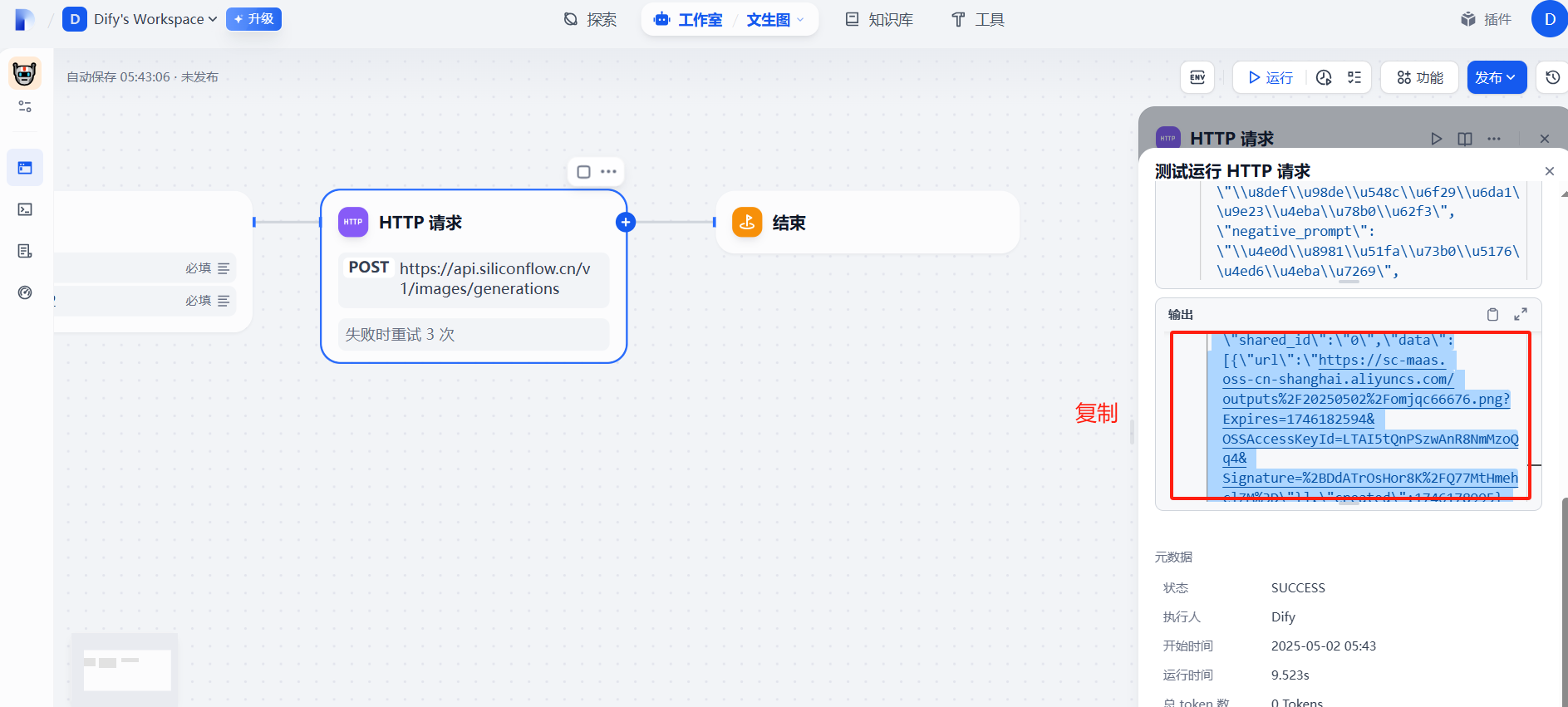
查看图片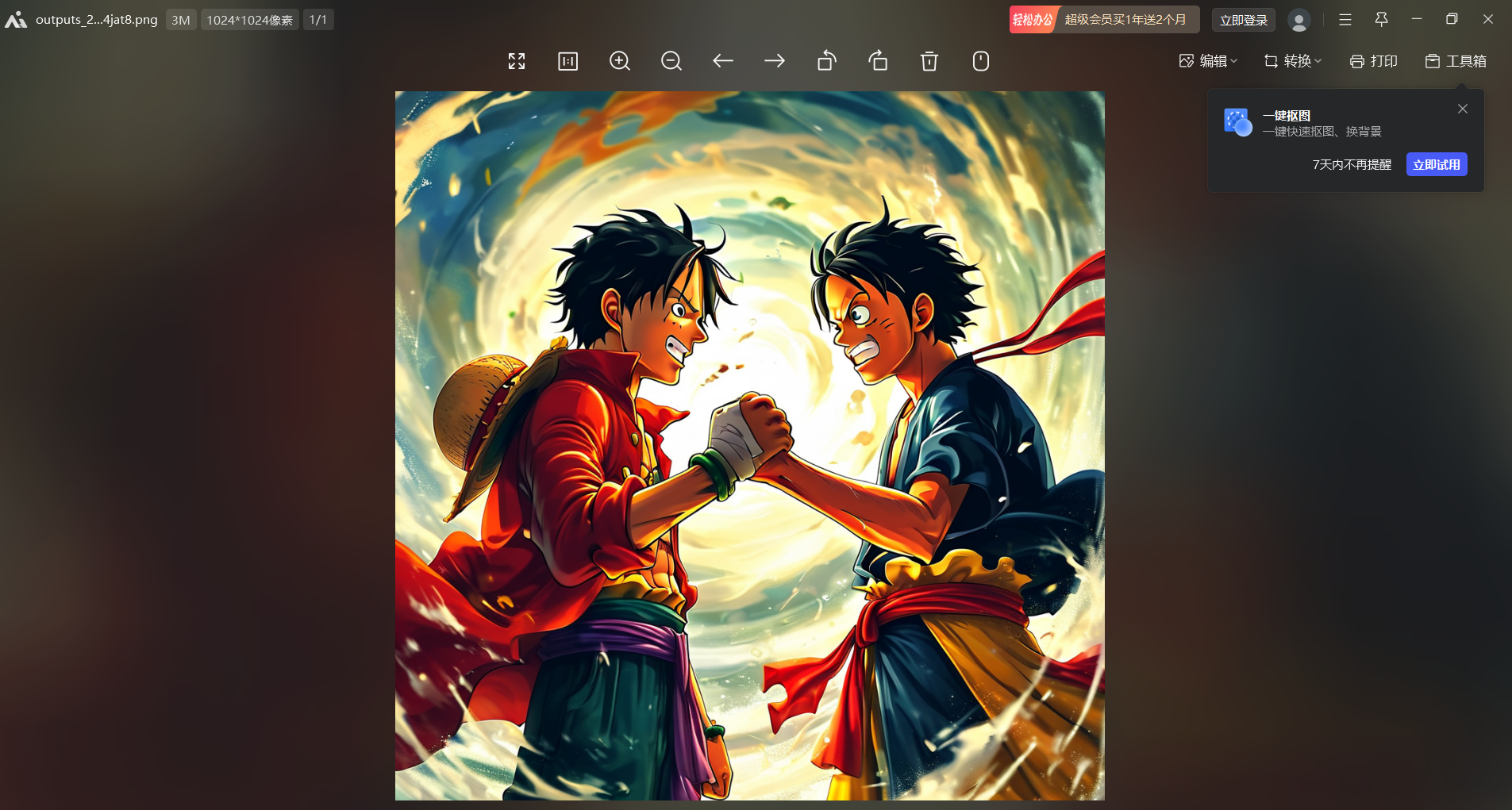
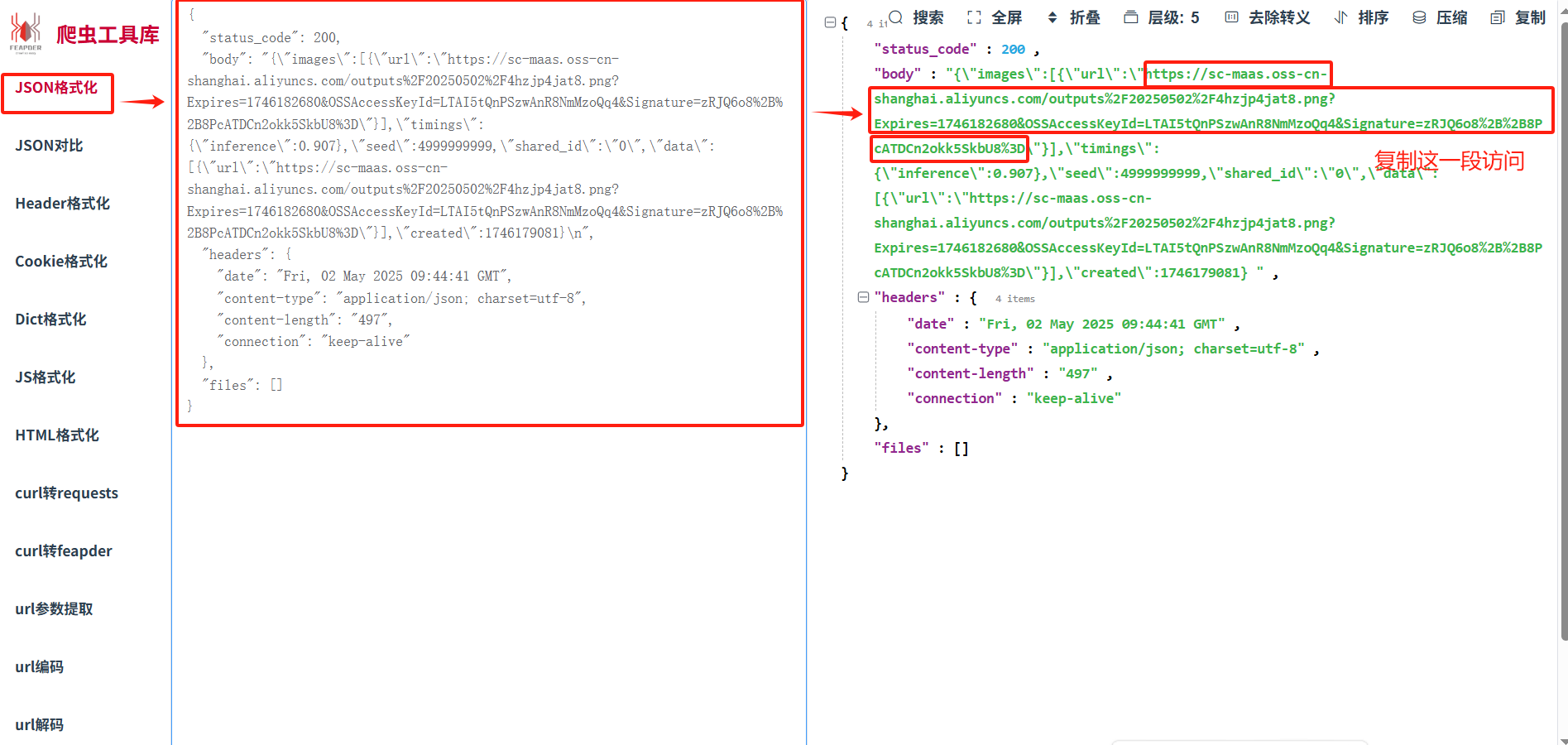
通过上面的步骤可以发现,要提取图片信息时,会掺杂很多其他数据,下面我们将对json数据去进行精化。
六、提取json中url数据
HTTP请求提取的参数
{
"status_code": 200,
"body": "{\"images\":[{\"url\":\"https://sc-maas.oss-cn-shanghai.aliyuncs.com/outputs%2F20250502%2F4hzjp4jat8.png?Expires=1746182680&OSSAccessKeyId=LTAI5tQnPSzwAnR8NmMzoQq4&Signature=zRJQ6o8%2B%2B8PcATDCn2okk5SkbU8%3D\"}],\"timings\":{\"inference\":0.907},\"seed\":4999999999,\"shared_id\":\"0\",\"data\":[{\"url\":\"https://sc-maas.oss-cn-shanghai.aliyuncs.com/outputs%2F20250502%2F4hzjp4jat8.png?Expires=1746182680&OSSAccessKeyId=LTAI5tQnPSzwAnR8NmMzoQq4&Signature=zRJQ6o8%2B%2B8PcATDCn2okk5SkbU8%3D\"}],\"created\":1746179081}\n",
"headers": {
"date": "Fri, 02 May 2025 09:44:41 GMT",
"content-type": "application/json; charset=utf-8",
"content-length": "497",
"connection": "keep-alive"
},
"files": []
}
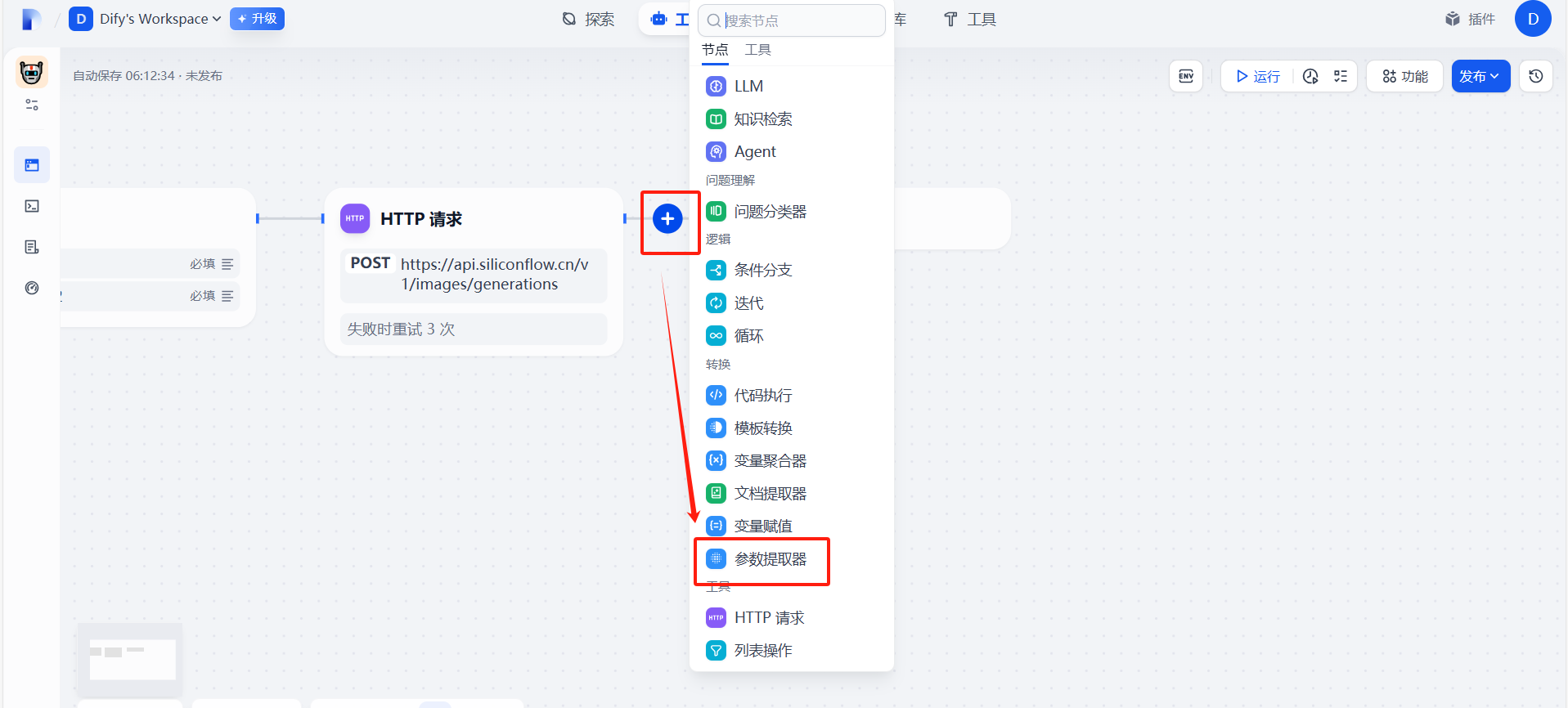
(1)添加参数提取器
(2)配置信息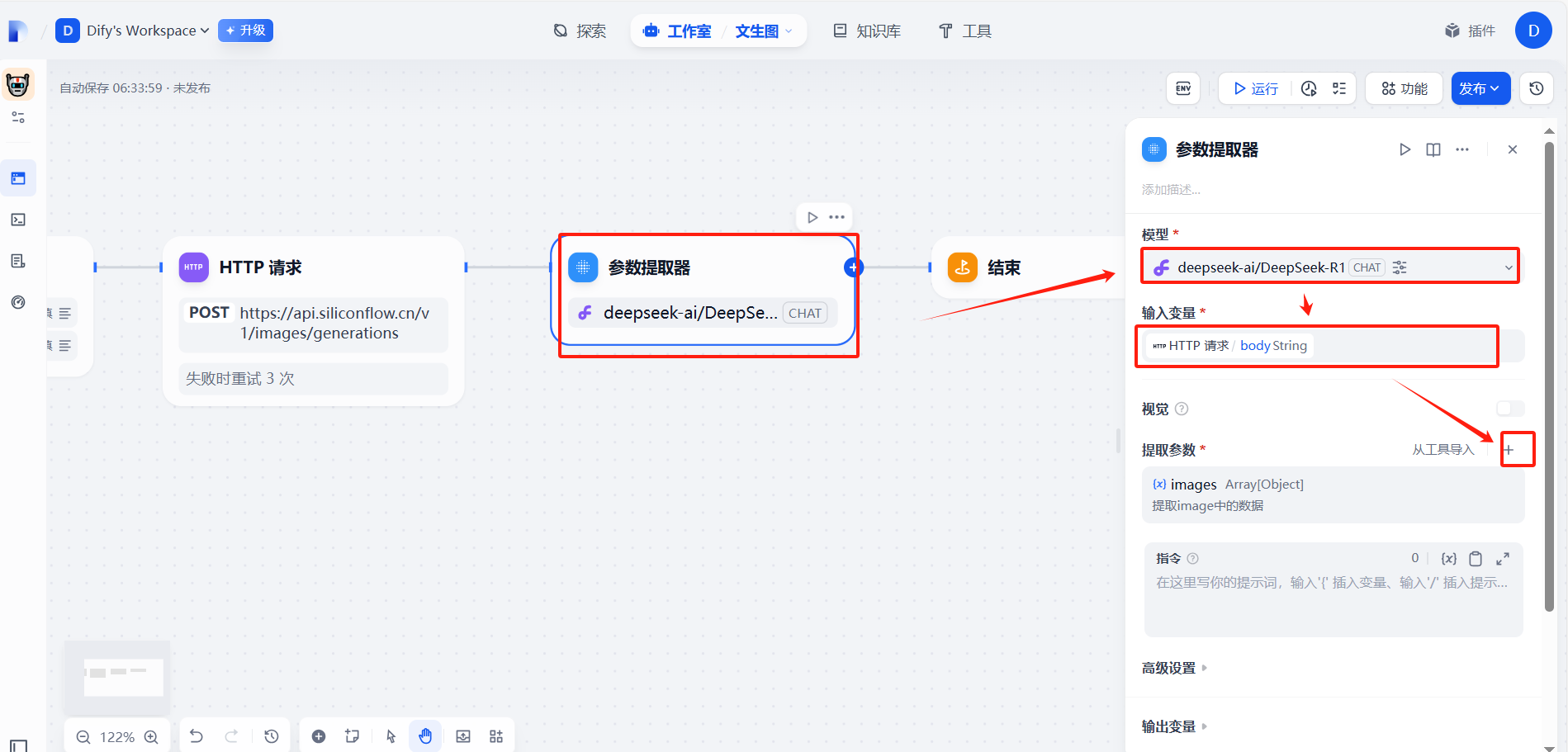
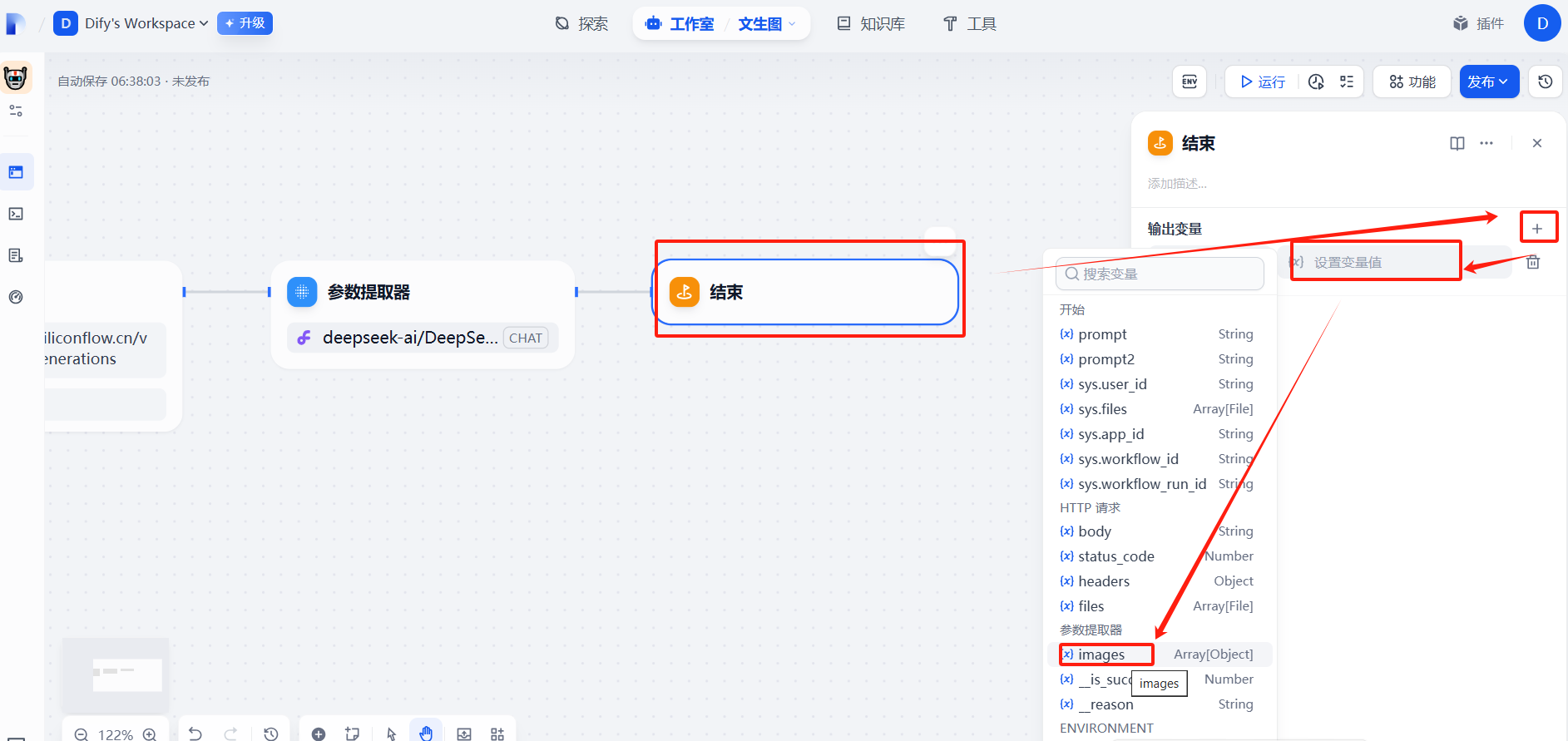
(3)运行测试
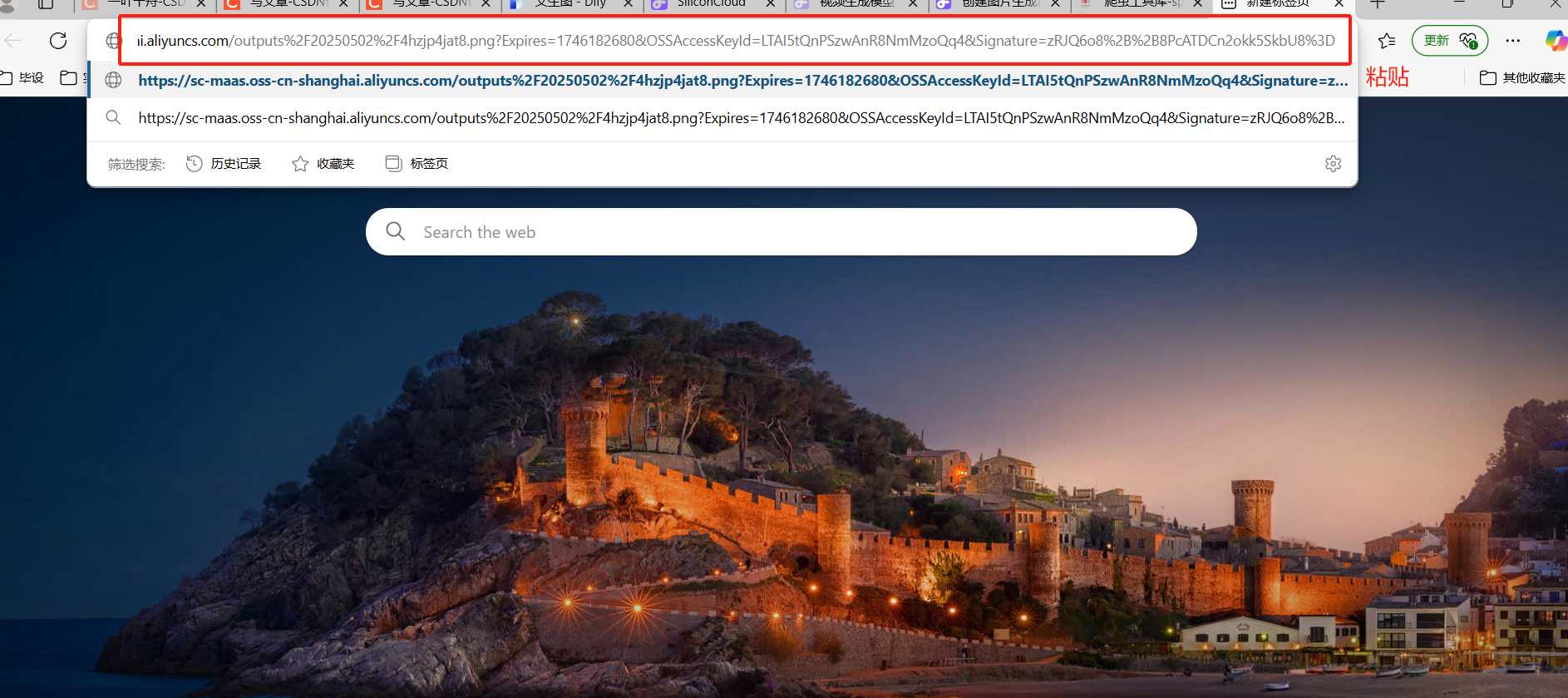
复制url中的地址信息,访问即可
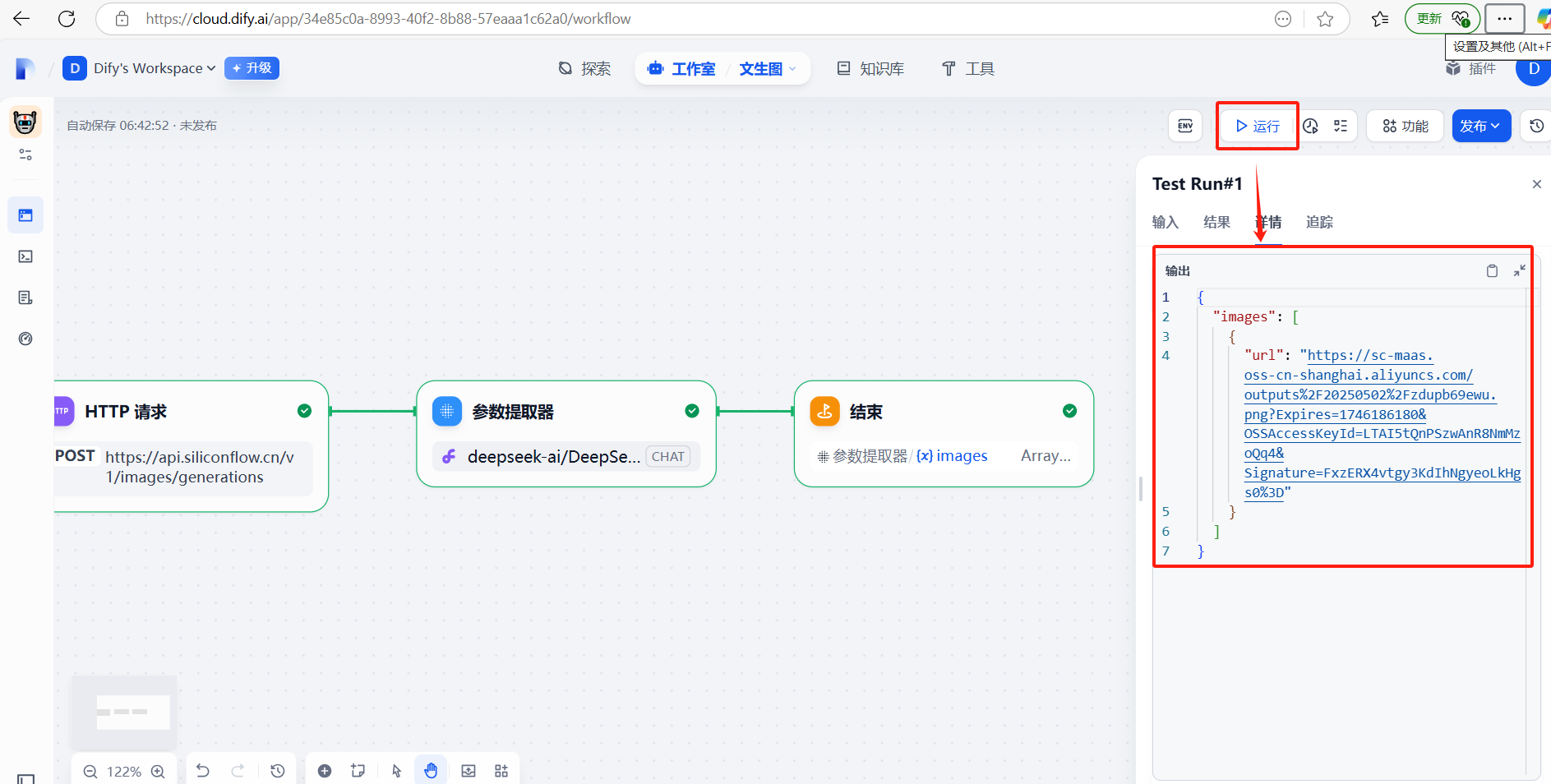

通过上面步骤,json数据已经进一步简化,但我们最终要的是只输出图片地址,接下来将通过代码对json数据做进一步处理。
(4)添加代码执行
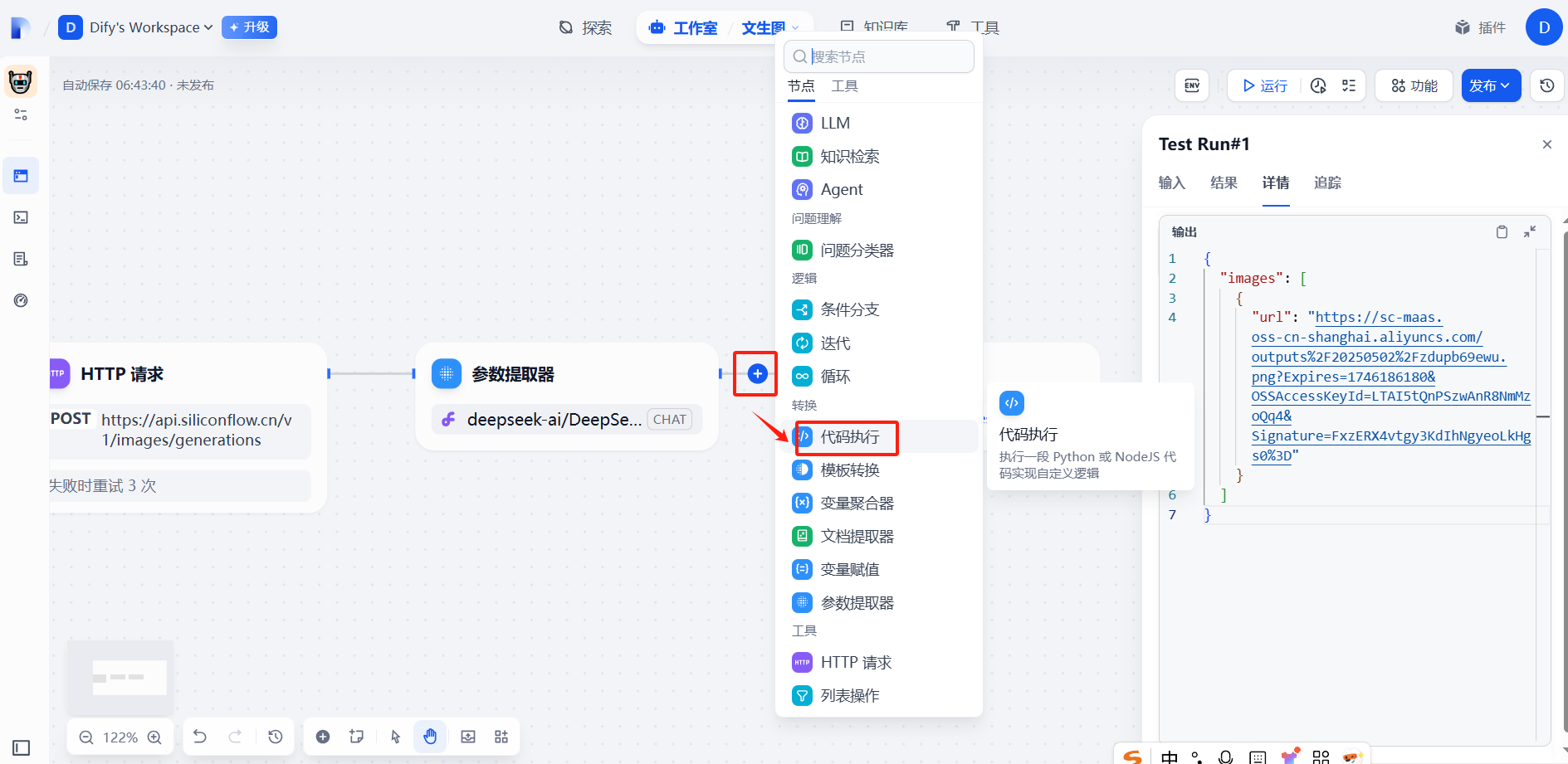
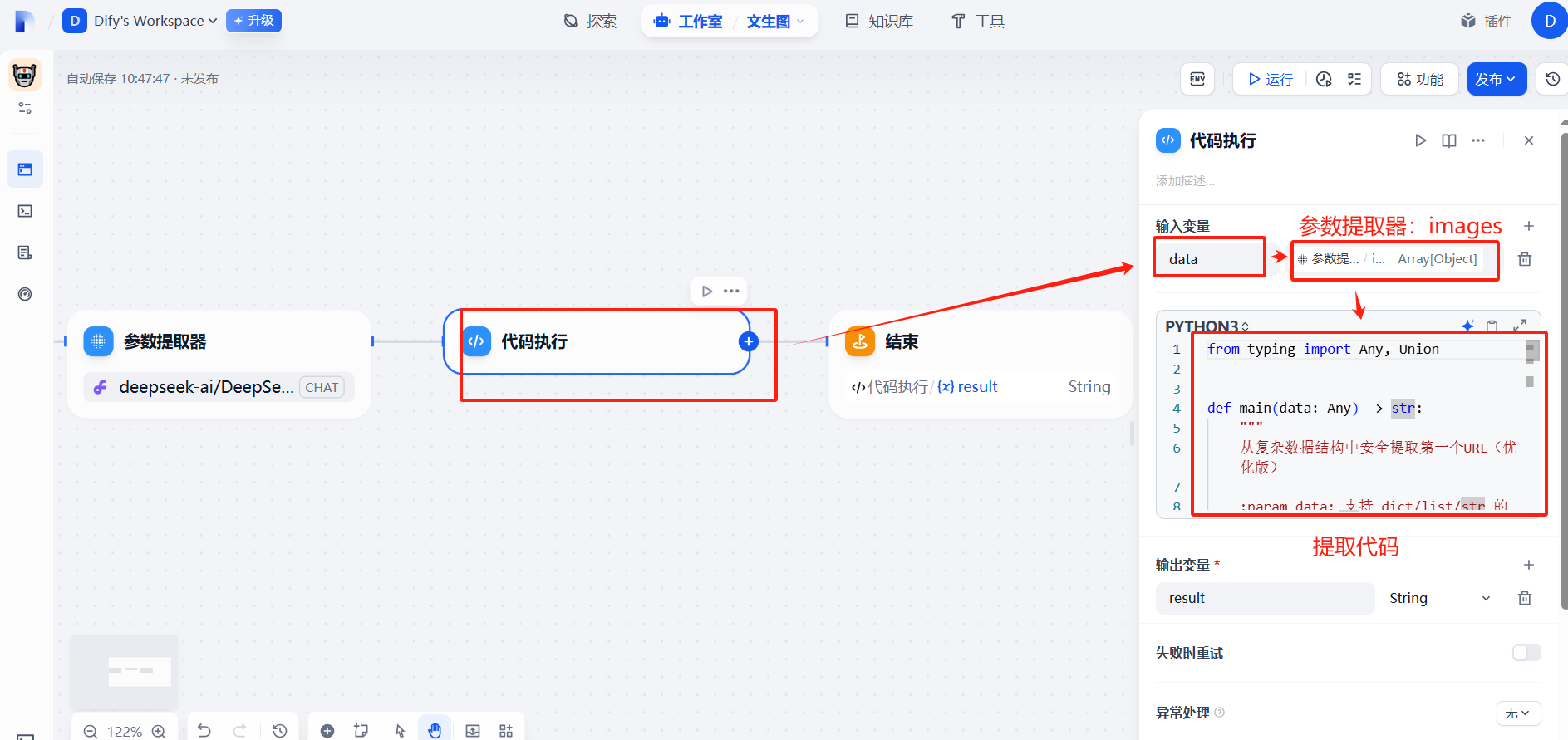
url提取代码
from typing import Any, Uniondef main(data: Any) -> str:"""从复杂数据结构中安全提取第一个URL(优化版):param data: 支持 dict/list/str 的任意嵌套数据结构:return: 总是返回字符串类型,找不到时返回空字符串"""def extract_url(value: Union[dict, list, str]) -> str:""" 递归提取的核心逻辑 """if isinstance(value, str):return value if value.startswith(('http://', 'https://', 'data:image')) else ''if isinstance(value, dict):# 优先检查单数形式字段for field in ['url', 'image', 'link', 'src']:if field in value:found = extract_url(value[field])if found: return found# 检查复数形式字段for list_field in ['urls', 'images', 'links', 'sources']:if isinstance(value.get(list_field), list):found = extract_url(value[list_field])if found: return found# 深度搜索字典值for v in value.values():found = extract_url(v)if found: return foundif isinstance(value, list):for item in value:found = extract_url(item)if found: return foundreturn ''return {"result":extract_url(data)}(5)输出参数
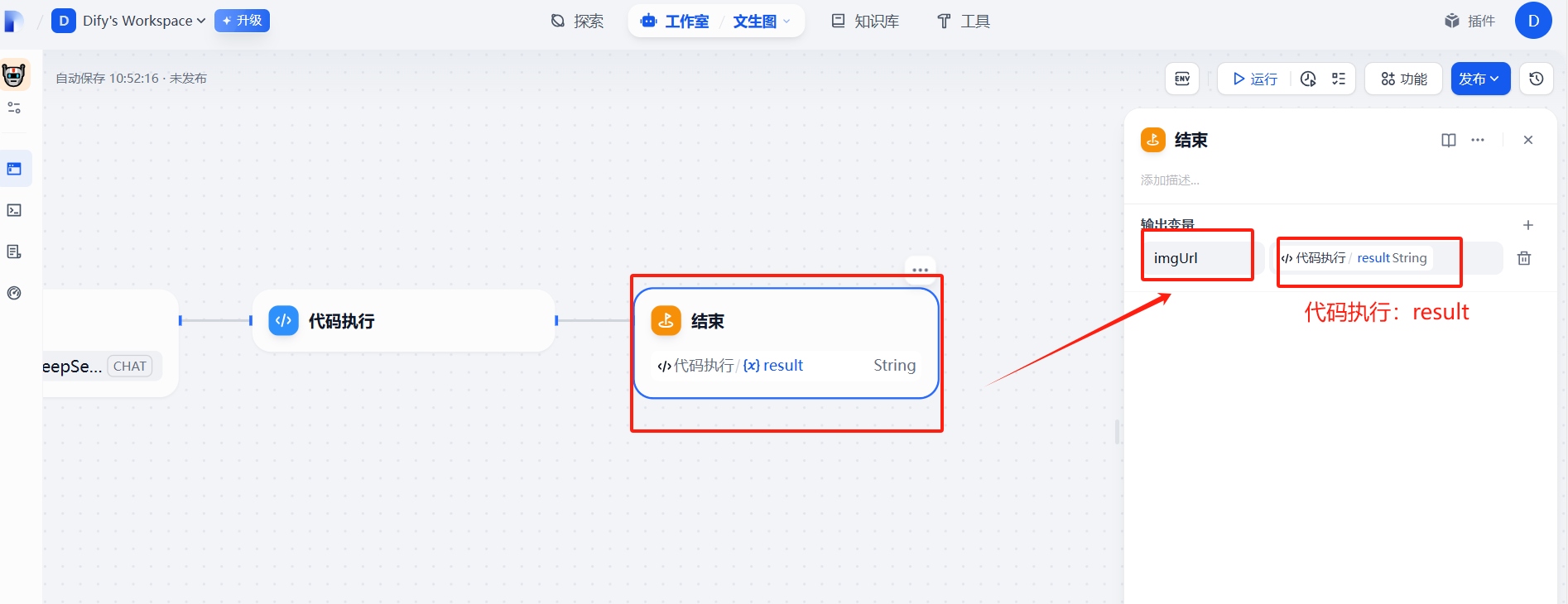
(6)运行
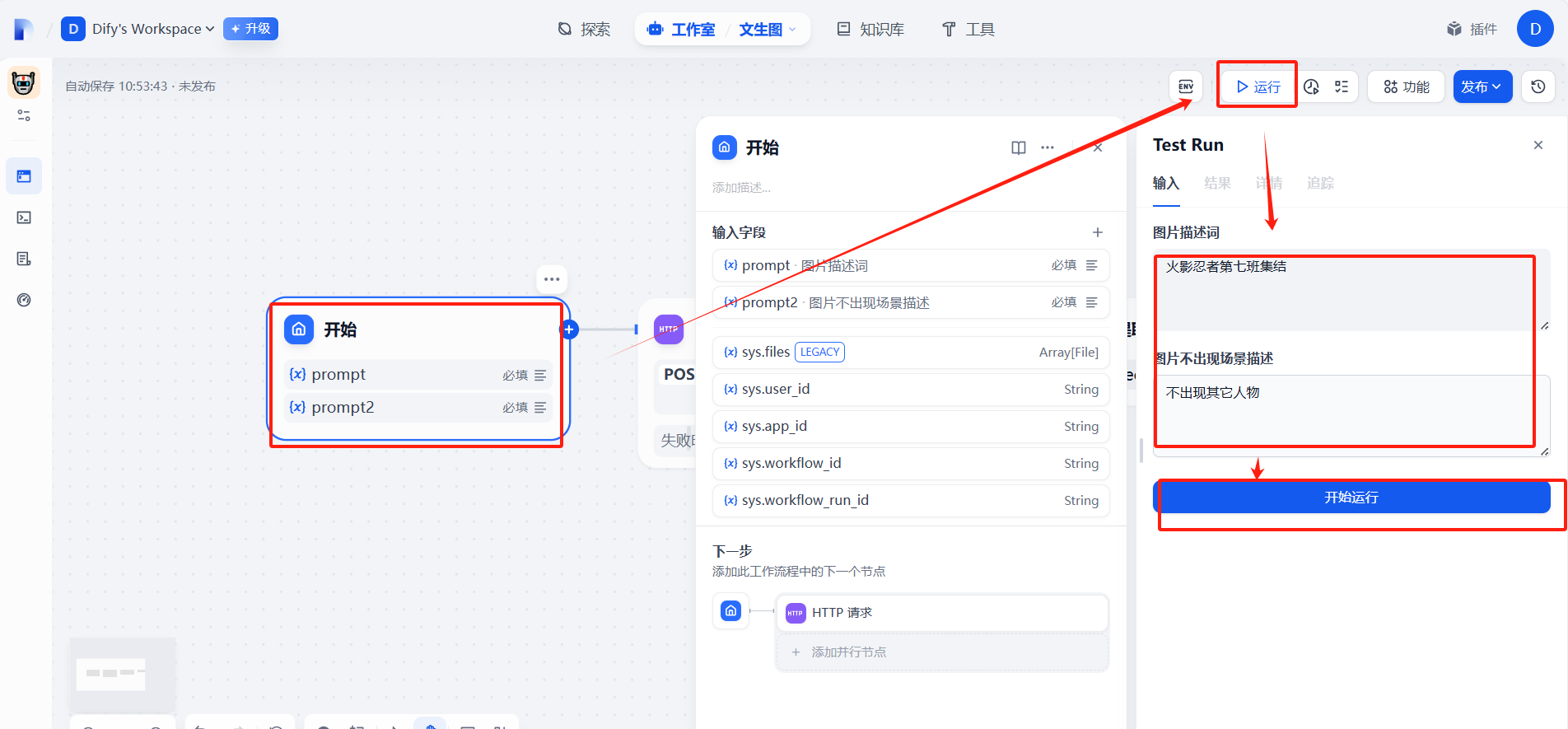
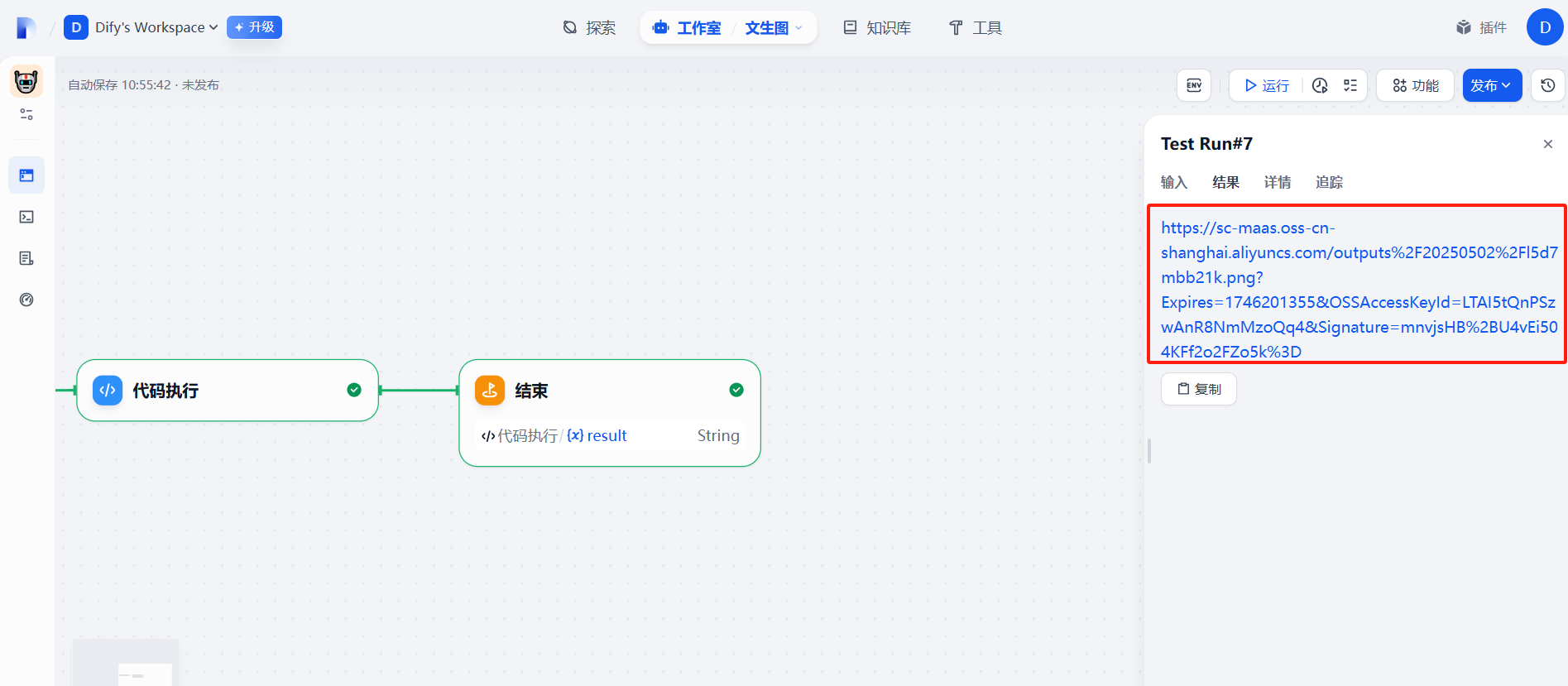

七、发布为工具
通过发布为工具后,如果我们在后续需要做更完善的文生图的项目时,可以直接导入调用该工具,节省开发步骤。